
Curso
Treinamento Eficiente de Modelos de IA com PyTorch
4 h
1.5K
Executar modelos de linguagem grandes tem custos reais. Você paga por cada token processado, cada ciclo de GPU usado e cada camada de complexidade adicionada a um modelo. Mesmo com a queda nos preços, a conta ainda fica alta quando você está lidando com aplicativos grandes, prompts longos ou atualizações frequentes.
Já vi como isso vira um problema rapidinho. As equipes acham que os custos vão continuar sob controle, mas depois percebem que estão gastando muito com modelos grandes demais, avisos ineficientes ou equipamentos parados.
É por isso que reuni 10 maneiras práticas de reduzir os custos de inferência. Da quantização e poda ao processamento em lote, cache e engenharia de prompts, essas são abordagens que eu realmente uso para manter os LLMs acessíveis sem comprometer muito o desempenho.
Quantização é um processo de redução da precisão dos pesos e ativações do modelo, normalmente de números de ponto flutuante de 32 bits para representações de bits mais baixos (por exemplo, 16 bits ou até 8 bits). Isso reduz o consumo de memória e os requisitos computacionais, permitindo uma inferência mais rápida em dispositivos com recursos limitados.
Como é feito:
Como isso ajuda:
A principal desvantagem é uma possível perda de precisão. Embora as técnicas modernas de quantização sejam muito boas, sempre existe a chance de uma pequena queda na precisão do modelo.
A poda é uma técnica pra tirar pesos menos importantes ou que já não servem mais de uma rede neural. Ao eliminar conexões que têm um impacto mínimo no desempenho do modelo, a poda reduz o tamanho e a complexidade computacional do modelo, levando a uma inferência mais rápida.
Como é feito:
Como isso ajuda:
Parecido com a quantização, a principal desvantagem é uma possível perda de precisão. Uma poda agressiva pode fazer com que o desempenho caia bastante. É super importante achar o equilíbrio certo.
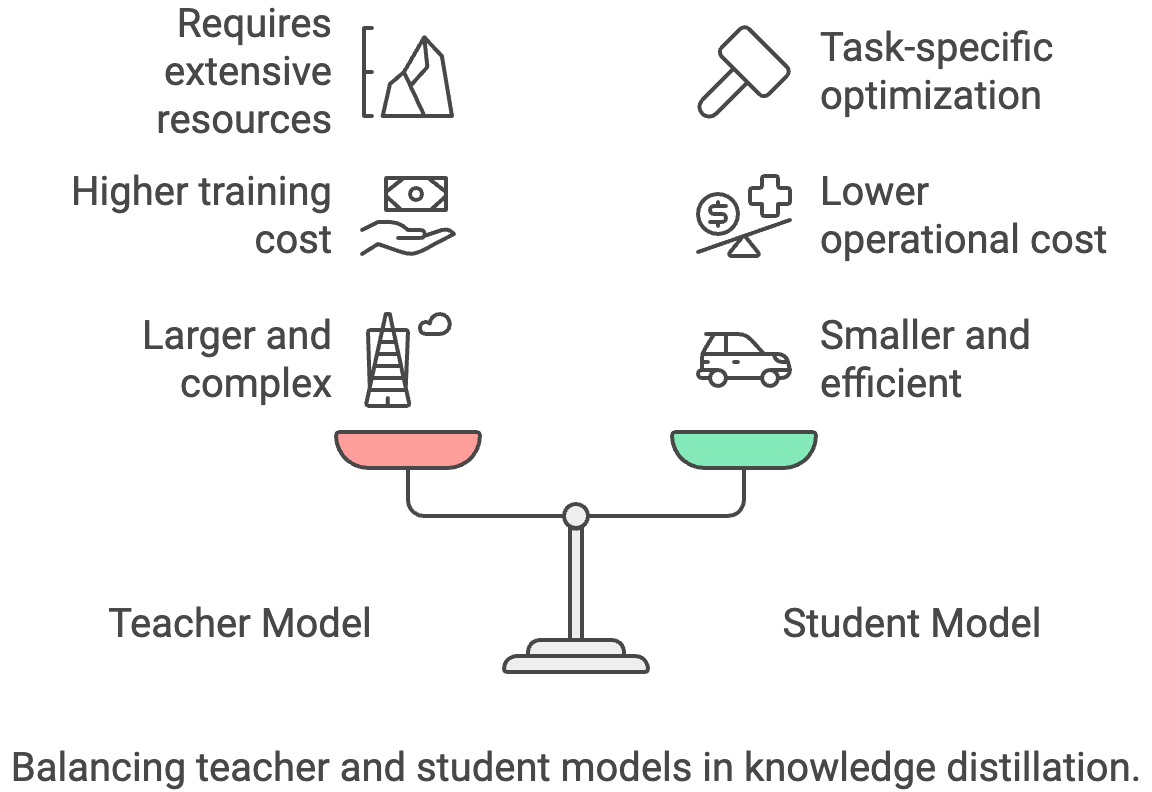
A destilação de conhecimento é o processo de passar conhecimento de um modelo “professor” grande e complexo para um modelo “aluno” menor e mais eficiente. O modelo do aluno aprende a imitar o comportamento do professor, o que permite um desempenho parecido com um tamanho menor e uma inferência mais rápida.
Como é feito:
Como isso ajuda:
A principal desvantagem é que você precisa de um modelo de professor eficiente, que pode ser caro para treinar ou usar.
O processamento em lote envolve processar várias amostras de entrada ao mesmo tempo em um lote durante a inferência. Isso melhora a eficiência usando os recursos de processamento paralelo do hardware, levando a uma inferência geral mais rápida.
Como é feito:
Como isso ajuda:
Mas, o agrupamento pode trazer um atraso extra para pedidos individuais, já que o sistema pode esperar para juntar entradas suficientes antes de processar. Para aplicações em tempo real ou de baixa latência, esse atraso adicional pode prejudicar a experiência do usuário se não for cuidadosamente ajustado. O agrupamento dinâmico ajuda a resolver o problema, mas deixa o sistema mais complicado. Também existe o risco de um agrupamento ineficiente quando o tráfego é irregular, o que pode reduzir a economia de custos esperada.
O cache é uma técnica pra guardar os resultados de cálculos anteriores e reutilizá-los quando os mesmos dados aparecem de novo durante a inferência. Isso evita cálculos desnecessários, acelerando o processo de inferência.
Como é feito:
Como isso ajuda:
Mas, o cache só é útil quando as entradas se repetem ou se sobrepõem. Em cargas de trabalho super variáveis, as taxas de acerto podem ser baixas, e o custo de manter um cache pode ser maior do que os benefícios. Resultados obsoletos ou desatualizados também podem criar problemas de consistência se as saídas armazenadas em cache não refletirem mais os dados mais relevantes. Além disso, implementar e ajustar estratégias de evicção de cache adiciona complexidade de engenharia, especialmente em sistemas distribuídos, onde a sincronização do cache se torna um desafio.
A saída antecipada envolve interromper o cálculo durante a inferência se o modelo estiver confiante o suficiente em sua previsão. Isso economiza recursos computacionais e acelera a inferência para casos mais simples, nos quais não é necessário realizar uma passagem completa.
Como é feito:
Como isso ajuda:
A desvantagem é que sair mais cedo pode fazer com que a precisão seja um pouco menor em alguns casos, principalmente para entradas complexas.
Essa técnica envolve o uso de arquiteturas de hardware e aceleradores especializados, feitos para fazer cálculos de IA de forma eficiente. Isso inclui GPUs, TPUs e outros chips de IA dedicados que oferecem melhorias significativas de desempenho em comparação com CPUs de uso geral para tarefas de inferência.
Como é feito:
Como isso ajuda:
Mas, hardware especializado geralmente exige um investimento inicial grande e pode te prender a um sistema específico de um fornecedor. GPUs, TPUs ou aceleradores personalizados também podem ser mais difíceis de provisionar de forma consistente na nuvem, especialmente durante picos de demanda. As implementações locais trazem desafios de manutenção e dimensionamento, enquanto as opções na nuvem podem acarretar custos de aluguel mais elevados. Por fim, adaptar o software para aproveitar ao máximo o hardware especializado pode aumentar a complexidade da engenharia e exigir otimização contínua.
A compressão de modelos é quando a gente usa mais de uma técnica pra diminuir o tamanho e a complexidade de um modelo sem prejudicar muito o desempenho dele. Isso pode envolver poda, quantização, destilação de conhecimento ou outros métodos que buscam criar um modelo mais compacto e eficiente para uma inferência mais rápida.
Como é feito:
Como isso ajuda:
A compressão do modelo pode prejudicar a precisão se as técnicas forem aplicadas de forma muito agressiva ou sem um ajuste cuidadoso. Combinar métodos como poda, quantização e destilação aumenta a complexidade do sistema e pode exigir mais ciclos de retreinamento ou ajuste fino. Os modelos compactados também podem ser menos flexíveis para transferência para novas tarefas, já que as otimizações muitas vezes limitam a variedade de cenários em que o modelo tem um bom desempenho. Em alguns casos, o tempo de engenharia e a sobrecarga computacional gastos na compressão podem compensar a economia de custos a curto prazo.
A inferência distribuída é uma forma de dividir a carga de trabalho de inferência entre várias máquinas ou dispositivos. Isso permite o processamento paralelo de tarefas de inferência em grande escala, reduzindo a latência e melhorando o rendimento.
Como é feito:
Como isso ajuda:
A inferência distribuída deixa o sistema bem complexo, porque coordenar a computação em várias máquinas exige uma orquestração robusta, sincronização e tolerância a falhas. A latência da rede e as limitações de largura de banda podem prejudicar o aumento de desempenho, principalmente quando é preciso trocar um monte de dados intermediários. Isso também aumenta os custos de infraestrutura, já que é preciso providenciar e manter hardware adicional e mecanismos de balanceamento de carga. Depurar e monitorar sistemas distribuídos pode ser mais complicado, o que torna a confiabilidade um desafio em comparação com configurações de nó único.
Engenharia de prompts é um processo de elaboração cuidadosa de prompts de entrada para orientar grandes modelos de linguagem (LLMs) na geração dos resultados desejados. Ao criar perguntas claras, curtas e específicas, os usuários podem melhorar a qualidade e o controle das respostas do LLM, tornando-as mais relevantes e úteis para tarefas específicas.
Como é feito:
Como isso ajuda:
A engenharia de prompts precisa de experimentação e iteração contínuas, o que pode ser demorado e inconsistente entre os casos de uso. Prompts bem elaborados podem não ser generalizáveis, obrigando você a redesenhá-los quando as tarefas ou modelos mudarem. Melhorias no design do prompt também podem ser frágeis — pequenas alterações na redação ou atualizações do modelo podem alterar os resultados de forma imprevisível. Por fim, confiar demais na engenharia de prompt sem técnicas complementares, como gerenciamento de contexto ou ajuste fino, pode limitar a escalabilidade e a economia de custos a longo prazo.
Engenharia de contexto é a prática de projetar sistemas que controlam quais informações um LLM vê antes de gerar uma resposta. Em vez de enfiar tudo na janela de contexto, você escolhe e organiza só os detalhes mais importantes — tipo histórico do usuário, documentos recuperados ou resultados de ferramentas — pra que o modelo possa raciocinar de forma mais eficiente.
Como é feito:
Como isso ajuda:
A desvantagem é que criar sistemas de contexto eficazes exige um esforço inicial de engenharia. Você precisa de pipelines de recuperação, resumo e validação, e um design ruim pode causar lacunas de contexto que prejudicam o desempenho. Mas, quando bem feita, a engenharia de contexto torna os grandes aplicativos mais confiáveis e acessíveis.
Reduzir os custos de inferência do LLM não é só um truque. É sobre juntar abordagens que fazem sentido para a sua carga de trabalho. Técnicas como quantização, poda e destilação de conhecimento reduzem o tamanho do modelo. O agrupamento, o armazenamento em cache e a inferência distribuída melhoram a forma como as solicitações são processadas. As escolhas de hardware e a compactação de modelos aumentam ainda mais a eficiência, enquanto a engenharia de prompt e contexto reduzem o uso desnecessário de tokens na fonte.
As desvantagens são reais: cada método traz complexidade, perda potencial de precisão ou sobrecarga de infraestrutura. Mas os ganhos se acumulam. Ao aplicar apenas algumas dessas técnicas, você pode manter os modelos acessíveis, dimensionar o uso sem custos descontrolados e criar sistemas que permaneçam sustentáveis à medida que os modelos e aplicativos crescem.
Aprenda IA com esses cursos!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Nisha Arya Ahmed
12 min
blog
Abid Ali Awan
8 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
