
Course
Efficient AI Model Training with PyTorch
4 hr
1.5K
Running large language models comes with real costs. You pay for every token processed, every GPU cycle used, and every layer of complexity added to a model. Even though prices have dropped, the bill still scales fast when you’re working with large applications, long prompts, or frequent updates.
I’ve seen how quickly this becomes a problem. Teams assume costs will stay manageable, only to realize they’re burning budget on oversized models, inefficient prompts, or idle hardware.
That’s why I’ve pulled together 10 practical ways to lower inference costs. From quantization and pruning to batching, caching, and prompt engineering, these are approaches I actually use to keep LLMs affordable without trading off too much performance.
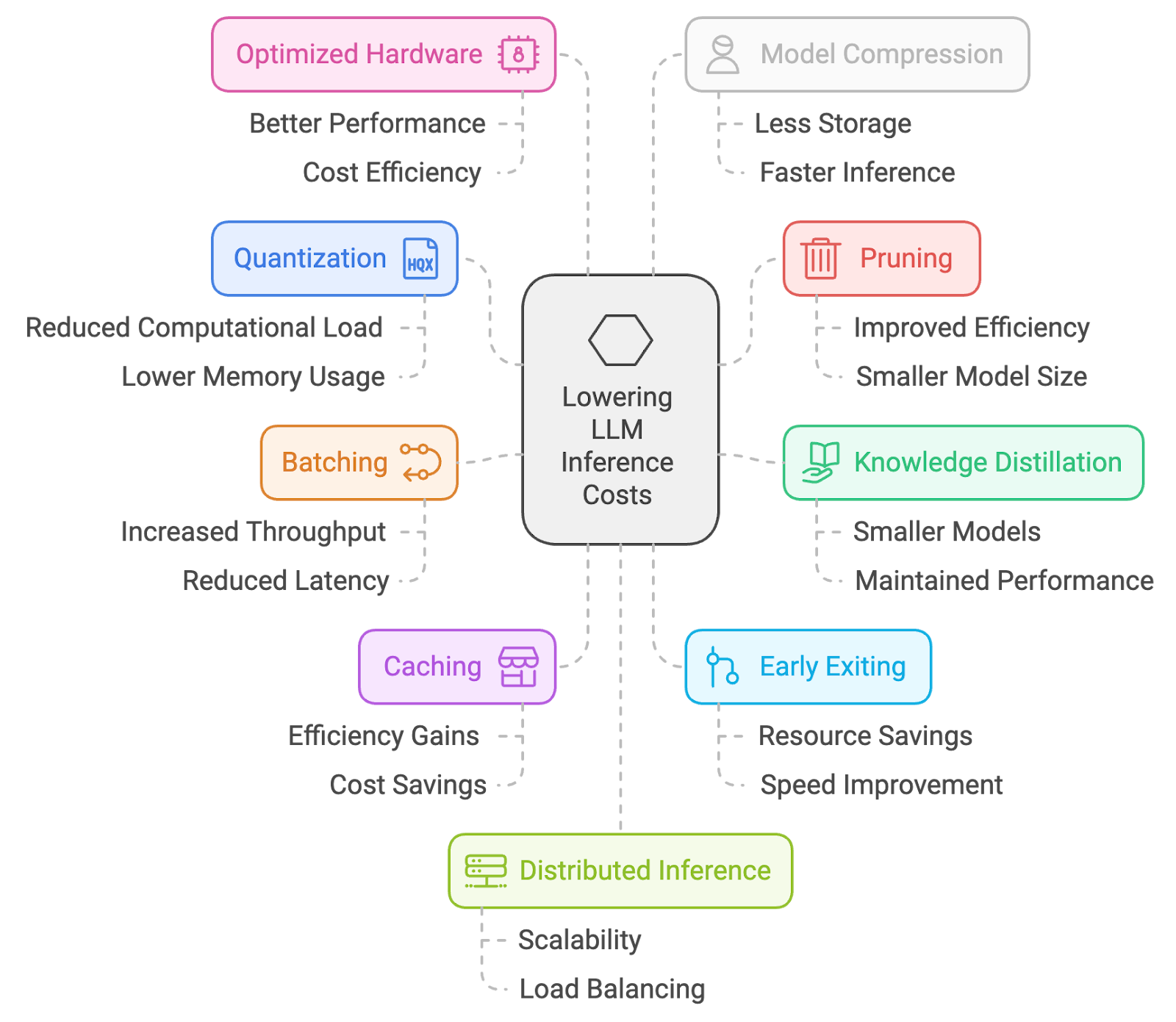
Quantization is a process of reducing the precision of model weights and activations, typically from 32-bit floating point numbers to lower-bit representations (e.g., 16-bit or even 8-bit). This reduces memory footprint and computational requirements, enabling faster inference on resource-constrained devices.
How it's done:
How it helps:
The main trade-off is a potential accuracy loss. While modern quantization techniques are quite good, there's always a chance of a slight drop in model accuracy.
Pruning is a technique of removing less important or redundant weights from a neural network. By eliminating connections that have minimal impact on the model's performance, pruning reduces the model's size and computational complexity, leading to faster inference.
How it's done:
How it helps:
Similar to quantization, the main trade-off is a potential accuracy loss. Aggressive pruning can lead to a noticeable drop in performance. It's crucial to find the right balance.
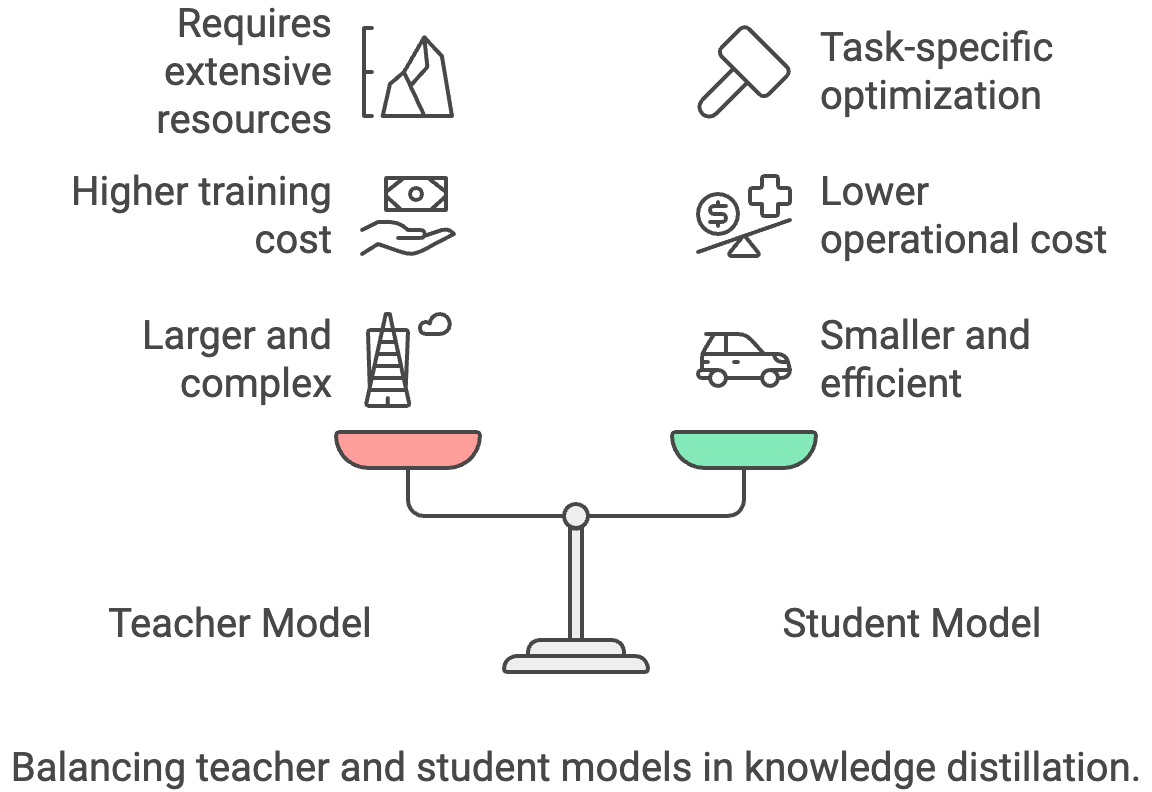
Knowledge distillation is a process of transferring knowledge from a large, complex "teacher" model to a smaller, more efficient "student" model. The student model learns to mimic the teacher's behavior, enabling it to achieve comparable performance with a smaller size and faster inference.
How it's done:
How it helps:
The main trade-off is that you need access to a powerful teacher model, which can be expensive to train or use.
Batching involves processing multiple input samples simultaneously in a batch during inference. This improves efficiency by using the parallel processing capabilities of the hardware, leading to faster overall inference.
How it's done:
How it helps:
However, batching can introduce extra latency for individual requests, since the system may wait to accumulate enough inputs before processing. For real-time or low-latency applications, this added delay can degrade user experience if not carefully tuned. Dynamic batching helps mitigate the issue but adds complexity to the system. There’s also the risk of inefficient batching when traffic is uneven, which can reduce the expected cost savings.
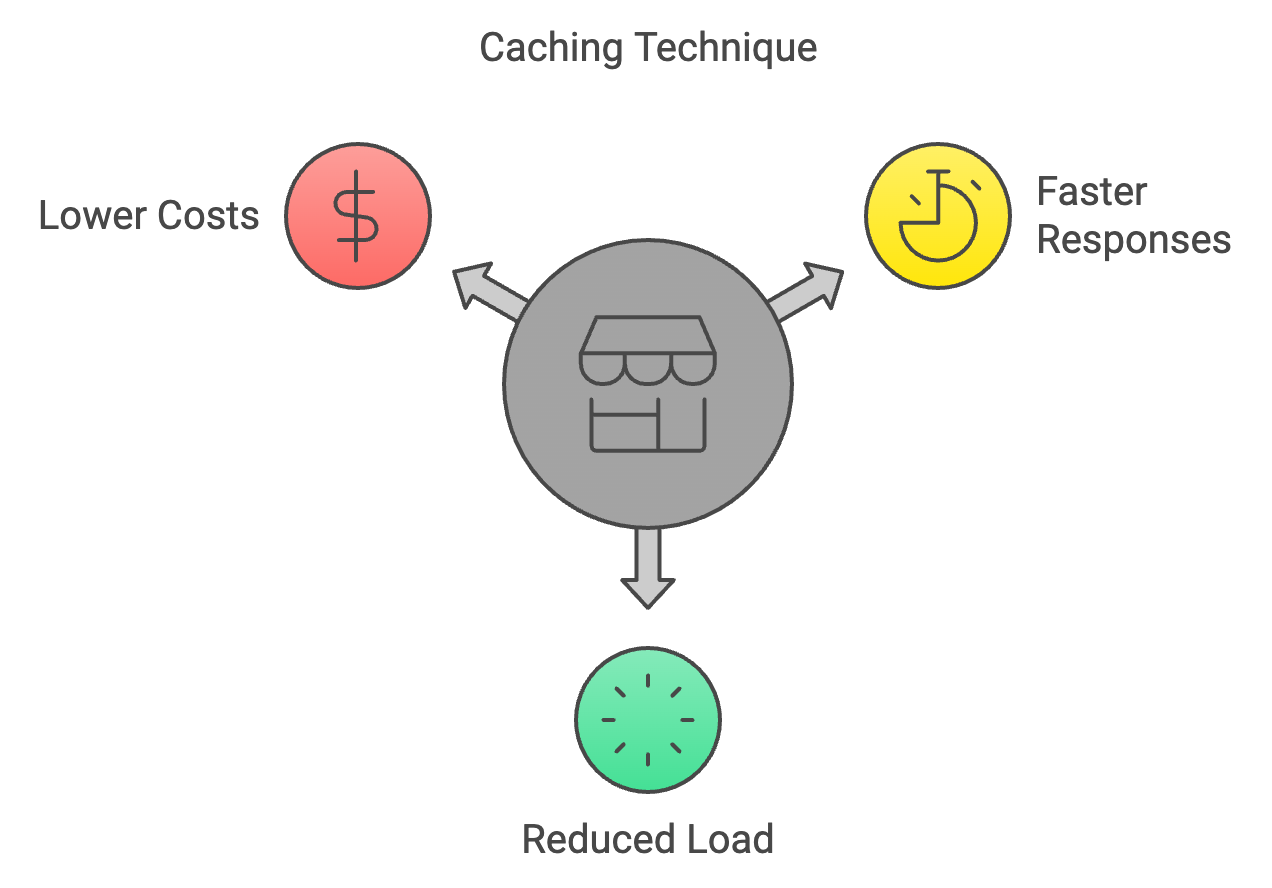
Caching is a technique of storing the results of previous computations and reusing them when encountering the same inputs again during inference. This avoids redundant calculations, speeding up the inference process.
How it's done:
How it helps:
However, caching is only useful when inputs repeat or overlap. In highly variable workloads, hit rates may be low, and the overhead of maintaining a cache can outweigh the benefits. Stale or outdated results can also create consistency issues if cached outputs no longer reflect the most relevant data. In addition, implementing and tuning cache eviction strategies adds engineering complexity, especially in distributed systems where cache synchronization becomes a challenge.
Early Exiting involves stopping the computation early during inference if the model is confident enough about its prediction. This saves computational resources and accelerates inference for simpler cases where a full forward pass is unnecessary.
How it's done:
How it helps:
The trade-off is that early exiting might lead to slightly lower accuracy in some cases, especially for complex inputs.
This technique involves utilizing specialized hardware architectures and accelerators designed for efficient AI computations. These include GPUs, TPUs, and other dedicated AI chips that offer significant performance improvements compared to general-purpose CPUs for inference tasks.
How it's done:
How it helps:
However, specialized hardware often requires significant upfront investment and may lock you into a particular vendor ecosystem. GPUs, TPUs, or custom accelerators can also be harder to provision consistently in the cloud, especially during peak demand. On-premise deployments bring maintenance and scaling challenges, while cloud options may carry higher ongoing rental costs. Finally, adapting software to fully exploit specialized hardware can add engineering complexity and require ongoing optimization.
Model compression refers to using more than one technique to reduce the size and complexity of a model without significantly compromising its performance. This can involve pruning, quantization, knowledge distillation, or other methods aimed at creating a more compact and efficient model for faster inference.
How it's done:
How it helps:
Model compression can lead to accuracy degradation if techniques are applied too aggressively or without careful tuning. Combining methods like pruning, quantization, and distillation increases system complexity and may require additional retraining or fine-tuning cycles. Compressed models can also be less flexible for transfer to new tasks, since optimizations often narrow the range of scenarios where the model performs well. In some cases, engineering time and computational overhead spent on compression may offset short-term cost savings.
Distributed inference is an approach to dividing the inference workload across multiple machines or devices. This enables parallel processing of large-scale inference tasks, reducing latency and improving throughput.
How it's done:
How it helps:
Distributed inference introduces significant system complexity, as coordinating computation across multiple machines requires robust orchestration, synchronization, and fault tolerance. Network latency and bandwidth constraints can offset the performance gains, especially when large amounts of intermediate data need to be exchanged. It also increases infrastructure costs, since additional hardware and load-balancing mechanisms must be provisioned and maintained. Debugging and monitoring distributed systems can be more difficult, making reliability a challenge compared to single-node setups.
Prompt engineering is a process of carefully crafting input prompts to guide large language models (LLMs) towards generating desired outputs. By formulating clear, concise, and specific prompts, users can improve the quality and controllability of LLM responses, making them more relevant and useful for specific tasks.
How it's done:
How it helps:
Prompt engineering requires ongoing experimentation and iteration, which can be time-consuming and inconsistent across use cases. Well-crafted prompts may not generalize, forcing you to redesign them when tasks or models change. Improvements in prompt design can also be fragile—small wording changes or model updates can alter results unpredictably. Finally, relying too heavily on prompt engineering without complementary techniques like context management or fine-tuning may limit scalability and long-term cost savings.
Context engineering is the practice of designing systems that control what information an LLM sees before generating a response. Instead of cramming everything into the context window, you select and organize only the most relevant details—such as user history, retrieved documents, or tool outputs—so the model can reason more efficiently.
How it’s done:
How it helps:
The trade-off is that building effective context systems takes upfront engineering effort. You need retrieval, summarization, and validation pipelines in place, and poor design can cause context gaps that hurt performance. But when done well, context engineering makes large applications both more reliable and more affordable.
Lowering LLM inference costs isn’t about a single trick. It’s about combining approaches that make sense for your workload. Techniques like quantization, pruning, and knowledge distillation cut down model size. Batching, caching, and distributed inference improve how requests are processed. Hardware choices and model compression push efficiency further, while prompt and context engineering reduce unnecessary token usage at the source.
The trade-offs are real: each method brings complexity, potential accuracy loss, or infrastructure overhead. But the gains add up. By applying even a few of these techniques, you can keep models affordable, scale usage without runaway costs, and build systems that remain sustainable as models and applications grow.
Learn AI with these courses!
Course
Course
Course
blog
Javier Canales Luna
12 min
blog
Amberle McKee
8 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Abid Ali Awan
10 min
Tutorial
Andrea Valenzuela
Tutorial
Josep Ferrer

