
Curso
Introducción a la ingeniería de datos
4 h
127.6K
Cuando tratamos con grandes cantidades de datos estructurados y semiestructurados procedentes de diversas fuentes, pensamos en un repositorio centralizado para almacenarlos. La perspectiva de los almacenes de datos cambia constantemente, y las soluciones basadas en la nube ofrecen un rendimiento, una flexibilidad y una escalabilidad excepcionales. Google BigQuery y Amazon Redshift son las mejores soluciones en este campo.
Las potentes funciones de procesamiento, análisis y almacenamiento de datos de ambos almacenes de datos basados en la nube permiten a los profesionales gestionar sus datos de forma más eficaz y eficiente.
En este artículo, compararé a fondo estas plataformas, incluyendo sus características, ventajas, inconvenientes y mejores prácticas. Examinemos los detalles y te ayudaremos a identificar la mejor opción para tus necesidades.
Google BigQuery es un almacén de datos totalmente gestionado y sin servidor que ofrece Google Cloud Platform (GCP). BigQuery está diseñado para manejar conjuntos de datos masivos, permitir el análisis en tiempo real y admitir flujos de trabajo de aprendizaje automático con una gestión mínima de la infraestructura. Su arquitectura sin servidor te permite utilizar consultas SQL para analizar tus datos.
BigQuery presenta los datos en tablas, filas y columnas, soportando la semántica de transacciones de bases de datos (ACID). El almacenamiento de BigQuery se replica automáticamente en varias ubicaciones para proporcionar una alta disponibilidad.
Interfaz GCP: Interfaz principal de la consola BigQuery.
Funciones principales de BigQuery:
Casos de uso de BigQuery:
Amazon Redshift es una solución de almacén de datos basada en la nube que forma parte de la plataforma más amplia de computación en la nube, Amazon Web Services (AWS). Con la arquitectura basada en clústeres de Redshift, los usuarios pueden acceder y analizar cargas de trabajo predecibles a gran escala sin necesidad de gestionar ellos mismos la infraestructura.
Redshift permite a los usuarios cargar datos y comenzar a consultarlos inmediatamente utilizando el editor de consultas v2 de Amazon Redshift o su herramienta de inteligencia empresarial (BI) preferida. El servicio ofrece la mejor relación calidad-precio y funciones SQL conocidas en un entorno fácil de usar y sin administración.
Interfaz AWS: Interfaz principal de la consola de Amazon Redshift.
Funciones principales de Redshift:
Casos de uso de Redshift:
Tras una breve descripción de estos dos almacenes de datos en la nube, examinemos de cerca sus diferencias en distintos ámbitos.
La arquitectura de la plataforma describe cómo deben funcionar los sistemas. Aquí destacaré la distinción entre el modelo de precios basado en consultas y sin servidor de BigQuery y el enfoque basado en clústeres de Redshift.
Si prefieres enfoque no intervencionista con escalado automático, BigQuery es tu solución para el almacenamiento de datos.
BigQuery te permite no gestionar ninguna infraestructura; Google se encarga de todo, desde el aprovisionamiento hasta el escalado. Con BigQuery, sólo pagas por las consultas que ejecutas y el almacenamiento que utilizas. Este enfoque de precios de pago por uso es rentable y te ayuda a no incurrir en costes de recursos ociosos.
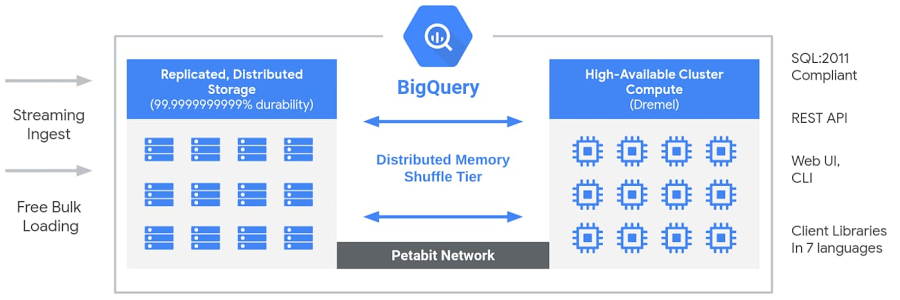
Arquitectura de BigQuery (Fuente: Google Cloud blog).
Si necesitas más control sobre tu infraestructura y puedes administrar tus clústeres con eficacia, Amazon Redshift será más adecuado para ti. Redshift requiere que configures y gestiones clusters eligiendo el tipo de instancia, el número de nodos y la configuración. Esto te da control sobre la infraestructura, pero, según mi experiencia, también añade complejidad.
Redshift ofrece un enfoque de precios tanto reservado como bajo demanda. Con las instancias reservadas, recibes un descuento y te comprometes a una capacidad específica durante un periodo predeterminado (como uno o tres años). La tarificación a la carta te permite pagar por la capacidad que utilizas cada hora, pero una gestión inadecuada puede hacerla más costosa.
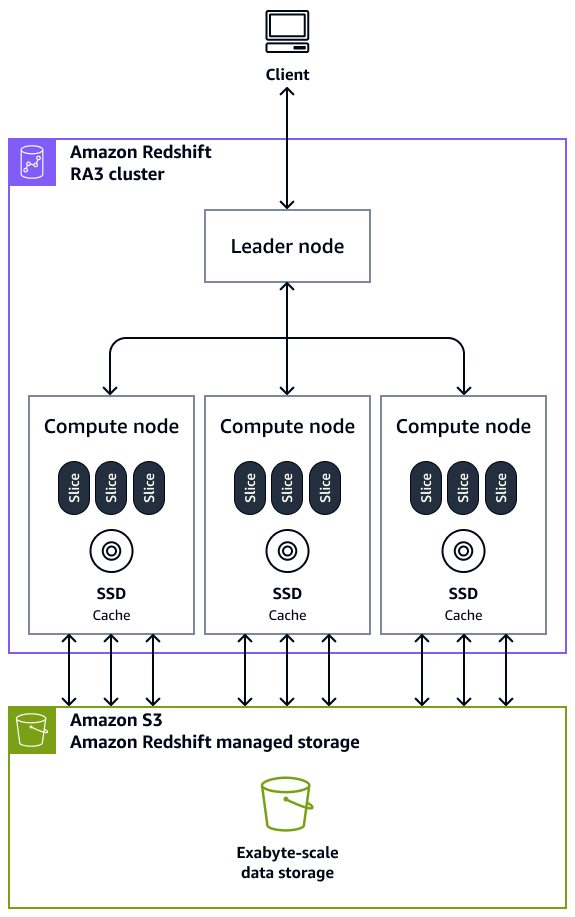
Arquitecto de Amazon Redshifture (Fuente: AWS).
Tanto Google BigQuery como Amazon Redshift ofrecen un rendimiento impresionante para consultas a gran escala, pero rinden mejor en casos diferentes. Veamos cómo gestionan el rendimiento ambas plataformas para las consultas a gran escala, destacando el rendimiento optimizado de BigQuery para las consultas ad hoc y el control de Redshift sobre los clústeres para las cargas de trabajo predecibles.
BigQuery está construido para manejar fácilmente cargas de trabajo dinámicas gracias a su arquitectura sin servidor. Esto permite a BigQuery autoescalar las cargas de trabajo, posibilitando un alto rendimiento para las consultas ad-hoc a gran escala. El almacenamiento en columnas de BigQuery es muy eficaz para las consultas analíticas. Este formato reduce la cantidad de datos leídos del disco, acelerando el rendimiento de la consulta.
Redshift puede ser una opción mejor si puedes gestionar clusters para obtener un rendimiento fiable en entornos con cargas de trabajo predecibles. Puedes ajustar los clusters para obtener un rendimiento coherente de las consultas, asegurándote de que tus recursos están optimizados para los requisitos de tu empresa.
Redshift ofrece varias opciones de ajuste del rendimiento, como claves de ordenación y distribución, para optimizar la ejecución de las consultas. Esta función puede mejorar el rendimiento de las cargas de trabajo predecibles, ¡pero sólo si sabes lo que haces! Según mi experiencia, la curva de aprendizaje puede ser pronunciada.
Comprender las estructuras de precios y costes es esencial a la hora de seleccionar un almacén de datos, porque queremos ser responsables de cada dólar que gastamos.
Repasemos cómo se comparan el modelo de pago por consulta y los gastos de almacenamiento de Google BigQuery con los precios basados en clústeres de Amazon Redshift con ahorro de instancias reservadas:
|
Factor de coste |
BigQuery |
Redshift |
|
Grada libre |
10 GB gratuitos al mes |
No hay un nivel gratuito, pero ofrece una prueba gratuita de 2 meses |
|
Costes de almacenamiento |
20 $ por TB para almacenamiento lógico activo, 10 $ para almacenamiento a largo plazo |
0,025 $ por GB al mes para SSD, 0,08 $ por GB para RA3 |
|
Costes de consulta |
5 $ por TB para consultas bajo demanda |
Basado en el uso de la instancia de cálculo y el almacenamiento |
|
Calcula los costes |
Cargos basados en el cómputo de capacidad (por hora de franja horaria) |
Facturación por horas (precios a la carta o reservados) |
|
Escalado |
Escalado automático con autoescalador |
Escalado manual con gestión de nodos |
|
Gastos de apoyo |
Cargos por almacenamiento a largo plazo más allá del nivel gratuito |
Incluido para copias de seguridad básicas, costes adicionales para más instantáneas |
|
Costes adicionales |
Ninguno para copias de seguridad o escalado |
Cargos por escalado de concurrencia tras la prueba gratuita |
Uno de los factores más importantes que debemos tener en cuenta al seleccionar nuestro almacén de datos es la escalabilidad.
Examinemos cómo BigQuery aumenta automáticamente la capacidad de almacenamiento y computación en respuesta a la demanda y cómo Redshift exige un escalado manual del clúster, que puede llevar más tiempo.
BigQuery es la plataforma preferida cuando estás seguro de que tu negocio se expandirá junto con sus cargas de trabajo e infraestructuras. La funcionalidad de autoescalado de BigQuery te libera de esta carga, ahorrándote tiempo y esfuerzo para que puedas concentrarte por completo en el análisis de datos.
En circunstancias ideales, Redshift será mejor si tu empresa tiene suficientes ingenieros de datos. Aunque Redshift exige una gestión más activa, puede ser ventajoso para tu empresa, sobre todo si necesitas un control más preciso y deseas gestionar los recursos.
El inconveniente es que la gestión requiere mucho tiempo, aunque te dé libertad. Tu flujo de trabajo puede volverse más complejo debido a la necesidad de planificar, hacer un seguimiento del rendimiento y actuar cuando sea necesario escalar.
Tanto Google BigQuery como Amazon Redshift ofrecen ventajas específicas de sus ecosistemas al integrarse con sus plataformas de computación en la nube.
BigQuery funciona sin problemas para los equipos que utilizan GCP y sus servicios, como Google Compute Engine, Cloud Storage y Cloud Run; entonces, puede ser beneficioso utilizar BigQuery para mantener tus canalizaciones de datos dentro del mismo entorno.
Esta integración con el conjunto de herramientas y servicios de Google hace que BigQuery sea la opción preferida para el almacenamiento de datos si tu empresa ya utiliza el ecosistema de Google, porque ofrece un flujo de trabajo fluido con sus servicios.
Amazon Redshift se sincronizará bien con otros servicios del ecosistema de AWS. Puede integrarse con Amazon S3, AWS Lambda y AWS Glue, facilitándote el acceso a otros servicios y recursos de AWS. En mi opinión, ¡es una gran ventaja!
La diferencia clave entre Google BigQuery y Amazon Redshift es la responsabilidad operativa que estos servicios depositan en sus clientes.
Como no tenemos que preocuparnos de gestionar la infraestructura subyacente, Google se encarga de todo, desde el aprovisionamiento hasta el escalado, utilizando BigQuery. Esta característica hace que BigQuery destaque para las empresas con pocos ingenieros de infraestructura que intentan evitar responsabilidades operativas.
Redshift, en cambio, exige más conocimientos técnicos y experiencia. Si tu equipo cuenta con ingenieros de infraestructura, habrá menos problemas para gestionar las copias de seguridad, el escalado manual y el aprovisionamiento de clusters. Como empresa, esto te da control y flexibilidad sobre tu infraestructura.
Hay varios casos de uso y escenarios en los que Google BigQuery se convierte en la solución de almacenamiento de datos a la que acudir. Elige BigQuery si
Al estar construido sobre Google Cloud Platform, BigQuery es más compatible con las personas que han invertido mucho en GCP. Supón que tienes la mayoría de tus recursos dentro de Google Cloud Platform, como Google Compute Engine, Cloud Storage y Cloud Run. Utilizar tus canalizaciones de datos dentro del mismo entorno puede ser beneficioso.
BigQuery es una potente herramienta para manejar grandes conjuntos de datos para consultas ad hoc o análisis en tiempo real. Como no tienes que preocuparte de gestionar la infraestructura, esto garantiza que tus consultas se procesen con rapidez y eficacia; tu carga de trabajo se autoescala independientemente del tamaño o la complejidad de tus datos.
Si tu equipo no dispone de los recursos DevOps necesarios, BigQuery es un claro ganador aquí. No tienes que molestarte en el tecnicismo de gestionar infraestructuras; Google lo hace por ti. Esto te ayuda a centrarte únicamente en la información de los datos.
Hay algunos escenarios y casos de uso en los que Amazon Redshift es la solución de almacenamiento de datos de elección clara. Elige Redshift si
Si tu organización ha desplegado sus recursos y se ha integrado en el ecosistema de AWS, Redshift es un ajuste natural. Amazon Redshift funcionará con otros servicios de AWS como Amazon S3, AWS Lambda y AWS Glue, lo que permitirá confiar únicamente en AWS para la gestión de datos, como el almacenamiento de datos, el procesamiento y las necesidades de automatización.
Redshift es compatible con cargas de trabajo pesadas que exigen un rendimiento constante para patrones de consulta predecibles y una ejecución fluida y eficiente. Como los clústeres de Redshift son personalizables y puedes controlar la infraestructura, puedes ajustar tu Redshift para satisfacer cualquier requisito específico de rendimiento.
Si tu equipo maneja flujos de trabajo ETL complejos con ingenieros de datos que gestionan la infraestructura, entonces Redshift es la solución adecuada. Esto se adapta bien a las empresas con experiencia en DevOps para manejar flujos de trabajo pesados; tendrás control sobre el escalado, las copias de seguridad y el rendimiento.
Ahora que hemos revisado algunos componentes significativos de ambas herramientas, repasemos sus aspectos más destacados. Esto debería ayudarte a decidir qué herramienta utilizar para tus necesidades específicas:
|
Características |
BigQuery |
Redshift |
|
Arquitectura |
La arquitectura sin servidor significa que no necesitas gestionar ninguna infraestructura. |
Funciona con una arquitectura basada en clusters en la que tienes que gestionar los clusters manualmente. |
|
Rendimiento |
Puede manejar rápidamente grandes conjuntos de datos, especialmente con análisis en tiempo real o consultas ad hoc. |
Conocido por su rendimiento fiable con patrones de consulta predecibles. |
|
Estructura de costes |
Utiliza un modelo de pago por consulta, lo que significa que pagas por los datos procesados por cada consulta. |
Utiliza instancias reservadas para descuentos de costes, en las que pagas por adelantado una cantidad específica de recursos informáticos. |
|
Escalabilidad |
La escalabilidad automática es una de las características más fuertes de BigQuery. |
Se requiere un escalado manual, por lo que debes gestionar el redimensionamiento del clúster, la asignación de recursos y el ajuste del rendimiento. |
|
Integración del ecosistema |
Su profunda integración con los servicios de Google Cloud Platform (GCP) la convierte en una opción de primer orden para los equipos que ya trabajan en el ecosistema de Google. |
Se integra perfectamente con el entorno de Amazon Web Services (AWS) y sus servicios para los equipos que ya utilizan el ecosistema de AWS. |
|
Facilidad de uso |
La arquitectura sin servidor y totalmente gestionada de BigQuery lo simplifica sin requerir profundos conocimientos de gestión de infraestructuras. |
Redshift requiere una gestión más práctica. Necesitas supervisar y gestionar los clusters, el escalado y el rendimiento. |
Este artículo explora las principales comparaciones entre BigQuery y Redshift, dos soluciones de almacenamiento de datos en la nube con ventajas y desventajas únicas. La mejor opción depende de tus necesidades, incluyendo el volumen de datos, los patrones de consulta y el presupuesto.
Si te interesa profundizar en estas plataformas, consulta Introducción a Redshift e Introducción a BigQuery en DataCamp. Estos cursos prácticos te ayudarán a dominar los fundamentos de cada herramienta y a adquirir habilidades prácticas para trabajar eficazmente con los almacenes de datos modernos.
¡Aprende más sobre ingeniería de datos y tecnologías en la nube con los siguientes cursos!
Curso
Curso
Curso
blog
Kurtis Pykes
12 min
blog
Gus Frazer
14 min
blog
Mike Shakhomirov
11 min
blog
Samuel Shaibu
10 min
