
Course
Introduction to Data Engineering
4 hr
127.6K
When dealing with large amounts of structured and semi-structured data from various sources, we think of a centralized repository to store them. The perspective on data warehouses constantly changes, and cloud-based solutions provide exceptional performance, flexibility, and scalability. Google BigQuery and Amazon Redshift are the top solutions in this field.
Both cloud-based data warehouses' powerful data processing, analytics, and storage features enable data professionals to manage their data more effectively and efficiently.
In this article, I will thoroughly compare these platforms, including their features, benefits, drawbacks, and best practices. Let's examine the specifics and help you identify the best option for your requirements!
Google BigQuery is a fully managed, serverless data warehouse offered by Google Cloud Platform (GCP). BigQuery is designed to handle massive datasets, enable real-time analysis, and support machine learning workflows with minimal infrastructure management. Its serverless architecture lets you use SQL queries to analyze your data.
BigQuery presents data in tables, rows, and columns, supporting database transaction semantics (ACID). BigQuery storage is automatically replicated across multiple locations to provide high availability.
GCP interface: BigQuery console main interface.
BigQuery core features:
BigQuery use cases:
Amazon Redshift is a cloud-based data warehouse solution that forms part of the larger cloud-computing platform, Amazon Web Services (AWS). With Redshift’s cluster-based architecture, users can access and analyze large-scale predictable workloads with the need to manage the infrastructure themselves.
Redshift lets users load data and start querying immediately using the Amazon Redshift query editor v2 or their preferred business intelligence (BI) tool. The service offers the best price-performance ratio and familiar SQL features in an easy-to-use, zero-administration environment.
AWS interface: Amazon Redshift console main interface.
Redshift core features:
Redshift use cases:
After a brief overview of these two cloud data warehouses, let’s closely examine their differences in different areas.
The platform architecture outlines how systems should function. Here, I will highlight the distinction between BigQuery's serverless, query-based pricing model and Redshift's cluster-based approach.
If you prefer a hands-off approach with automatic scaling, BigQuery is your go-to for data warehousing.
BigQuery allows you not to manage any infrastructure; Google handles everything from provisioning to scaling. With BigQuery, you only pay for the queries you run and the storage you use. This pay-as-you-go pricing approach is cost-effective and helps you not incur idle resource costs.
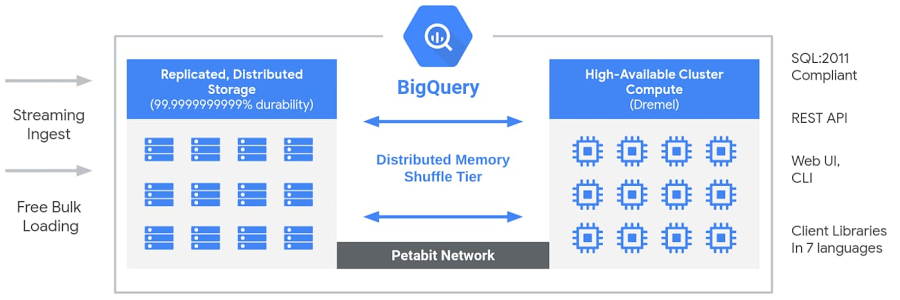
BigQuery architecture (Source: Google Cloud blog).
If you need more control over your infrastructure and can manage your clusters effectively, Amazon Redshift will be a better fit for you. Redshift requires you to set up and manage clusters by choosing the instance type, number of nodes, and configuration. This gives you control over the infrastructure, but, in my experience, it also adds complexity.
Redshift offers both a reserved and on-demand pricing approach. With reserved instances, you receive a discount and commit to a specific capacity for a predetermined period (such as one or three years). On-demand pricing allows you to pay for the capacity you use hourly, but improper management can make it more costly.
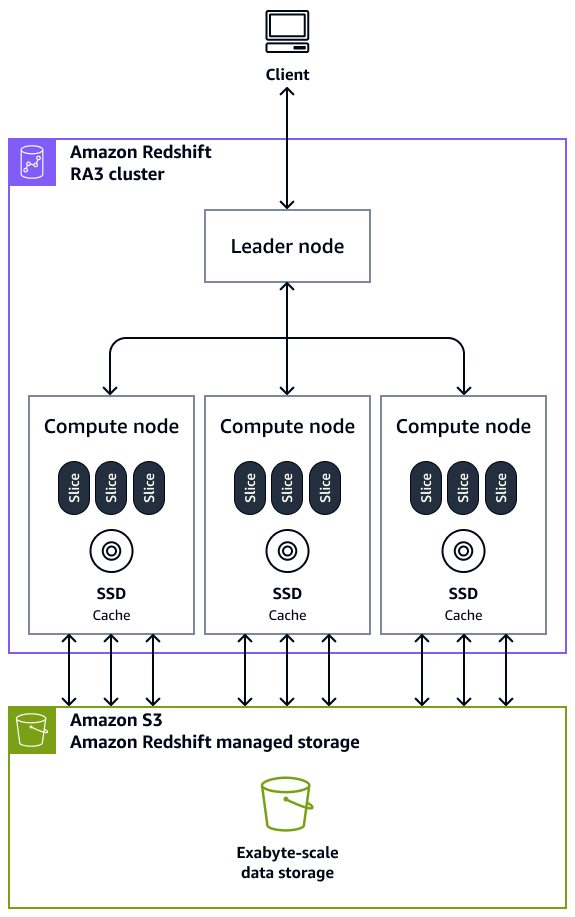
Amazon Redshift architecture (Source: AWS).
Both Google BigQuery and Amazon Redshift provide impressive performance for large-scale queries, but they perform best in different cases. Let's look at how both platforms manage performance for large-scale queries, highlighting BigQuery's optimized performance for ad-hoc queries and Redshift's control over clusters for predictable workloads.
BigQuery is built to easily handle dynamic workloads due to its serverless architecture. This allows BigQuery to autoscale workloads, enabling high performance for large-scale ad-hoc queries. BigQuery's columnar storage is highly efficient for analytical queries. This format reduces the amount of data read from the disk, speeding up query performance.
Redshift can be a better option if you can manage clusters for reliable performance in environments with predictable workloads. You can tune clusters for consistent query performance, ensuring your resources are optimized for your business requirements.
Redshift offers various performance tuning options, such as sort and distribution keys, to optimize query execution. This feature can lead to better performance for predictable workloads, but only if you know what you’re doing! In my experience, the learning curve can be steep.
Understanding price and cost structures is essential when selecting a data warehouse because we want to be responsible for every dollar we spend.
Let’s review how Google BigQuery's pay-per-query model and storage expenses compare to Amazon Redshift's cluster-based pricing with reserved instance savings:
|
Cost Factor |
BigQuery |
Redshift |
|
Free tier |
10GB free per month |
There is no free tier, but it offers a 2-month free trial |
|
Storage costs |
$20 per TB for active logical storage, $10 for long-term |
$0.025 per GB per month for SSD, $0.08 per GB for RA3 |
|
Query costs |
$5 per TB for on-demand queries |
Based on compute instance usage and storage |
|
Compute costs |
Charges based on capacity compute (by slot hour) |
Hourly billing (on-demand or reserved pricing) |
|
Scaling |
Automatic scaling with autoscaler |
Manual scaling with node management |
|
Backup costs |
Charges for long-term storage beyond the free tier |
Included for basic backups, extra costs for more snapshots |
|
Additional costs |
None for backups or scaling |
Charges for concurrency scaling after free trial |
One of the most important factors we should consider while selecting our data warehouse is scalability.
Let's examine how BigQuery automatically increases storage and computing capacity in response to demand and how Redshift demands manual cluster scaling, which can take longer.
BigQuery is the preferred platform when you are sure your business will expand along with its workloads and infrastructures. BigQuery's autoscaling functionality relieves you of this burden, saving you time and effort so you can concentrate entirely on data analysis.
In ideal circumstances, Redshift will be better if your company has enough data engineers. Although Redshift demands more active management, it might be advantageous for your company, particularly if you need more precise control and wish to manage resources.
The drawback is that management takes a lot of time, even if it gives you freedom. Your workflow may become more complex due to the requirement to plan, track performance, and act when scale is required.
Both Google BigQuery and Amazon Redshift offer benefits specific to their ecosystems when integrating with their cloud computing platforms.
BigQuery works smoothly for teams using GCP and its services, such as Google Compute Engine, Cloud Storage, and Cloud Run; then, it may be beneficial to use BigQuery to keep your data pipelines within the same environment.
This integration with Google's suite of tools and services makes BigQuery the preferred option for data warehousing if your business already uses the Google ecosystem because it offers a smooth workflow with its services.
Amazon Redshift will sync well with other services in the AWS ecosystem. It can integrate with Amazon S3, AWS Lambda, and AWS Glue, giving you easy access to other AWS services and resources. In my opinion, this is a great advantage!
The key difference between Google BigQuery and Amazon Redshift is the operational responsibility these services place on their customers.
Since we don’t need to worry about managing underlying infrastructure, Google handles everything from provisioning to scaling using BigQuery. This feature makes BigQuery stand out for businesses with few infrastructure engineers trying to avoid operational responsibilities.
Redshift, on the other hand, demands more technical know-how and expertise. If your team has infrastructure engineers, there will be fewer issues handling backups, manual scaling, and provisioning clusters. As a business, this gives you control and flexibility over your infrastructure.
There are various use cases and scenarios where Google BigQuery becomes the go-to data warehousing solution. Choose BigQuery if you:
Since it is built on the Google Cloud Platform, BigQuery is more compatible with individuals who are heavily invested in GCP. Suppose you have most of your resources within the Google Cloud Platform, such as Google Compute Engine, Cloud Storage, and Cloud Run. Using your data pipelines within the same environment may be beneficial.
BigQuery is a powerful tool for handling large datasets for ad-hoc queries or real-time analytics. Since you don’t need to worry about managing infrastructure, this ensures that your queries are processed fast and efficiently; your workload auto-scales regardless of the size or complexity of your data.
If your team doesn’t have the necessary DevOps resources, BigQuery is a clear winner here. You don’t need to bother yourself with the technicality of managing infrastructures; Google does that for you. This helps you focus solely on the data insights.
There are some scenarios and use cases where Amazon Redshift is the clear choice data warehousing solution. Choose Redshift if you:
If your organization has deployed its resources and integrated into the AWS ecosystem, Redshift is a natural fit. Amazon Redshift will work with other AWS services like Amazon S3, AWS Lambda, and AWS Glue, making it possible to rely solely on AWS for data management, such as data storage, processing, and automation needs.
Redshift is compatible with heavy workloads that demand consistent performance for predictable query patterns and a smooth and efficient run. Since Redshift’s clusters are customizable and you can control the infrastructure, you can tune your Redshift to meet any specific performance requirements.
If your team handles complex ETL workflows with data engineers who manage infrastructure, then Redshift is the right fit. This suits companies with DevOps expertise well for handling heavy workflows; you will have control over scaling, backups, and performance.
Now that we’ve reviewed some significant components of both tools let's review their key highlights. This should help in deciding which tool to utilize for your specific needs:
|
Features |
BigQuery |
Redshift |
|
Architecture |
Serverless architecture means you don’t need to manage any infrastructure. |
Operates on a cluster-based architecture where you need to manage the clusters manually. |
|
Performance |
Can handle large datasets quickly, especially with real-time analytics or ad-hoc queries. |
Known for its reliable performance with predictable query patterns. |
|
Cost structure |
It uses a pay-per-query model, meaning you pay for the data processed by each query. |
It uses reserved instances for cost discounts, where you pay a specific amount of computing resources upfront. |
|
Scalability |
Automatic scalability is one of BigQuery's strongest features. |
Manual scaling is required, so you must manage cluster resizing, resource allocation, and performance tuning. |
|
Ecosystem integration |
Deep integration with Google Cloud Platform (GCP) services makes it a top choice for teams already working within the Google ecosystem. |
Seamlessly integrates with Amazon Web Services (AWS) environment and its services for teams already using the AWS ecosystem. |
|
Ease of use |
BigQuery's fully managed, serverless architecture simplifies it without requiring deep infrastructure management skills. |
Redshift requires more hands-on management. You need to monitor and manage clusters, scaling, and performance. |
This article explored the key comparisons between BigQuery and Redshift, two cloud data warehousing solutions with unique strengths and trade-offs. The best choice depends on your needs, including data volume, query patterns, and budget.
If you're interested in diving deeper into these platforms, check out Introduction to Redshift and Introduction to BigQuery on DataCamp. These hands-on courses will help you master the fundamentals of each tool and gain practical skills to work effectively with modern data warehouses.
Learn more about data engineering and cloud technologies with the following courses!
Course
Course
Course
blog
Tim Lu
12 min
blog
Austin Chia
10 min
Tutorial
Gus Frazer
Tutorial
Josep Ferrer
Tutorial
Eduardo Oliveira
Tutorial
Zoumana Keita

