
Kurs
Einführung in das Data Engineering
4 Std.
127.6K
Wenn es um große Mengen strukturierter und halbstrukturierter Daten aus verschiedenen Quellen geht, denken wir an ein zentrales Repository, um sie zu speichern. Die Perspektive auf Data Warehouses ändert sich ständig, und cloudbasierte Lösungen bieten außergewöhnliche Leistung, Flexibilität und Skalierbarkeit. Google BigQuery und Amazon Redshift sind die besten Lösungen in diesem Bereich.
Die leistungsstarken Datenverarbeitungs-, Analyse- und Speicherfunktionen der beiden Cloud-basierten Data Warehouses ermöglichen es Datenexperten, ihre Daten effektiver und effizienter zu verwalten.
In diesem Artikel werde ich diese Plattformen gründlich vergleichen, einschließlich ihrer Funktionen, Vorteile, Nachteile und besten Praktiken. Wir gehen auf die Besonderheiten ein und helfen dir, die beste Option für deine Anforderungen zu finden!
Google BigQuery ist ein vollständig verwaltetes, serverloses Data Warehouse, das von der Google Cloud Platform (GCP) angeboten wird. BigQuery wurde entwickelt, um riesige Datenmengen zu verarbeiten, Echtzeitanalysen zu ermöglichen und maschinelle Lernprozesse mit minimalem Infrastrukturmanagement zu unterstützen. Dank der serverlosen Architektur kannst du SQL-Abfragen zur Analyse deiner Daten verwenden.
BigQuery stellt Daten in Tabellen, Zeilen und Spalten dar und unterstützt die Semantik von Datenbanktransaktionen (ACID). Der BigQuery-Speicher wird automatisch über mehrere Standorte repliziert, um eine hohe Verfügbarkeit zu gewährleisten.
GCP-Schnittstelle: Die Hauptschnittstelle der BigQuery-Konsole.
BigQuery Kernfunktionen:
BigQuery Anwendungsfälle:
Amazon Redshift ist eine cloudbasierte Data-Warehouse-Lösung, die Teil der größeren Cloud-Computing-Plattform Amazon Web Services (AWS) ist. Mit der clusterbasierten Architektur von Redshift können Nutzerinnen und Nutzer auf große, vorhersehbare Workloads zugreifen und diese analysieren, ohne die Infrastruktur selbst verwalten zu müssen.
Mit Redshift können Nutzer Daten laden und sofort mit dem Amazon Redshift Query Editor v2 oder ihrem bevorzugten Business Intelligence (BI)-Tool abfragen. Der Dienst bietet das beste Preis-Leistungs-Verhältnis und vertraute SQL-Funktionen in einer benutzerfreundlichen, verwaltungsfreien Umgebung.
AWS-Schnittstelle: Die Hauptschnittstelle der Amazon Redshift-Konsole.
Redshift Kernfunktionen:
Redshift Anwendungsfälle:
Nach einem kurzen Überblick über diese beiden Cloud Data Warehouses wollen wir ihre Unterschiede in verschiedenen Bereichen genauer untersuchen.
Die Plattformarchitektur legt fest, wie die Systeme funktionieren sollen. Hier werde ich den Unterschied zwischen dem serverlosen, abfragebasierten Preismodell von BigQuery und dem clusterbasierten Ansatz von Redshift hervorheben.
Wenn du einen Hands-on-Ansatz mit automatischer Skalierung bevorzugst, ist BigQuery deine erste Wahl für Data Warehousing.
Mit BigQuery musst du keine Infrastruktur verwalten; Google kümmert sich um alles von der Bereitstellung bis zur Skalierung. Mit BigQuery zahlst du nur für die Abfragen, die du ausführst, und den Speicherplatz, den du nutzt. Dieses Umlageverfahren ist kostengünstig und hilft dir, keine Kosten für ungenutzte Ressourcen zu verursachen.
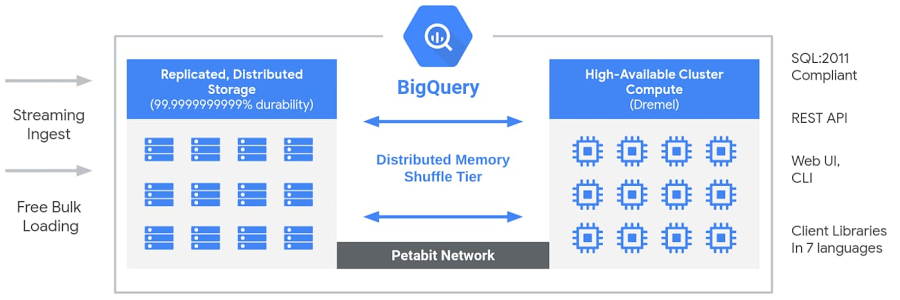
BigQuery-Architektur (Quelle: Google Cloud blog).
Wenn du mehr Kontrolle über deine Infrastruktur brauchst und deine Cluster effektivverwaltenkannst , ist Amazon Redshift die bessere Wahl für dich. Bei Redshift musst du Cluster einrichten und verwalten, indem du den Instanztyp, die Anzahl der Knoten und die Konfiguration auswählst. Das gibt dir die Kontrolle über die Infrastruktur, aber meiner Erfahrung nach erhöht es auch die Komplexität.
Redshift bietet sowohl einen reservierten als auch einen On-Demand-Preisansatz. Bei reservierten Instanzen erhältst du einen Rabatt und verpflichtest dich, eine bestimmte Kapazität für einen bestimmten Zeitraum (z. B. ein oder drei Jahre) zu nutzen. Beim On-Demand-Pricing zahlst du für die Kapazität, die du stündlich nutzt, aber eine unsachgemäße Verwaltung kann die Kosten in die Höhe treiben.
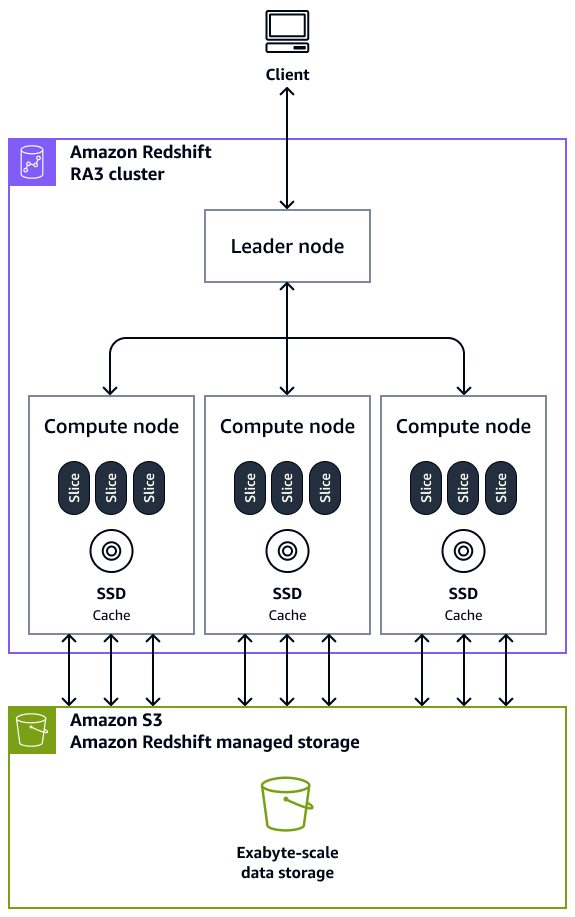
Amazon Redshift architecture (Quelle: AWS).
Sowohl Google BigQuery als auch Amazon Redshift bieten eine beeindruckende Leistung für umfangreiche Abfragen, aber sie sind in unterschiedlichen Fällen am besten. Schauen wir uns an, wie beide Plattformen die Leistung für große Abfragen verwalten. Dabei betonen wir die optimierte Leistung von BigQuery für Ad-hoc-Abfragen und die Kontrolle von Redshift über Cluster für vorhersehbare Arbeitslasten.
BigQuery ist dank seiner serverlosen Architektur in der Lage, dynamische Workloadszu verarbeiten . Dadurch kann BigQuery Workloads automatisch skalieren, was eine hohe Leistung für große Ad-hoc-Abfragen ermöglicht. Der spaltenbasierte Speicher von BigQuery ist sehr effizient für analytische Abfragen. Dieses Format reduziert die Datenmenge, die von der Festplatte gelesen wird, und beschleunigt so die Abfrageleistung.
Redshift kann eine bessere Option sein, wenn du Cluster für eine zuverlässige Leistung in Umgebungen mit vorhersehbaren Arbeitslastenverwalten kannst . Du kannst Cluster für eine gleichbleibende Abfrageleistung abstimmen und so sicherstellen, dass deine Ressourcen für deine Geschäftsanforderungen optimiert sind.
Redshift bietet verschiedene Optionen zur Leistungsoptimierung, wie z. B. Sortier- und Verteilungsschlüssel, um die Ausführung von Abfragen zu optimieren. Diese Funktion kann zu einer besseren Leistung bei vorhersehbaren Arbeitsbelastungen führen, aber nur, wenn du weißt, was du tust! Meiner Erfahrung nach kann die Lernkurve steil sein.
Bei der Auswahl eines Data Warehouse ist es wichtig, die Preis- und Kostenstrukturen zu verstehen, denn wir wollen für jeden Dollar, den wir ausgeben, verantwortlich sein.
Schauen wir uns an, wie das Pay-per-Query-Modell und die Speicherkosten von Google BigQuery im Vergleich zu den clusterbasierten Preisen von Amazon Redshift mit den Einsparungen durch reservierte Instanzen aussehen:
|
Kostenfaktor |
BigQuery |
Redshift |
|
Freie Ebene |
10 GB kostenlos pro Monat |
Es gibt keine kostenlose Stufe, aber eine 2-monatige kostenlose Testphase. |
|
Kosten für die Lagerung |
$20 pro TB für aktiven logischen Speicher, $10 für Langzeitspeicher |
$0,025 pro GB pro Monat für SSD, $0,08 pro GB für RA3 |
|
Abfragekosten |
5 $ pro TB für Abfragen auf Abruf |
Basierend auf der Nutzung von Recheninstanzen und Speicher |
|
Kosten berechnen |
Entgelte auf Basis der Kapazitätsberechnung (pro Slotstunde) |
Abrechnung auf Stundenbasis (Abruf- oder Reservierungspreise) |
|
Skalierung |
Automatische Skalierung mit Autoscaler |
Manuelle Skalierung mit Knotenmanagement |
|
Backup-Kosten |
Gebühren für Langzeitspeicher über die kostenlose Stufe hinaus |
Inbegriffen für Basis-Backups, zusätzliche Kosten für mehr Snapshots |
|
Zusätzliche Kosten |
Keine für Backups oder Skalierung |
Gebühren für Gleichzeitigkeitsskalierung nach der kostenlosen Testphase |
Einer der wichtigsten Faktoren, die wir bei der Auswahl unseres Data Warehouse berücksichtigen sollten, ist die Skalierbarkeit.
Sehen wir uns an, wie BigQuery die Speicher- und Rechnerkapazität bei Bedarf automatisch erhöht, während Redshift eine manuelle Clusterskalierung erfordert, die länger dauern kann.
BigQuery ist die bevorzugte Plattform, wenn du dir sicher bist, dass dein Unternehmen zusammen mit seinen Arbeitslasten und Infrastrukturen wachsen wird. Die Autoskalierungsfunktion von BigQuery entlastet dich von dieser Last und spart dir Zeit und Mühe, sodass du dich ganz auf die Datenanalyse konzentrieren kannst.
Im Idealfall ist Redshift besser geeignet, wenn dein Unternehmen über genügend Dateningenieure verfügt. Obwohl Redshift eine aktivere Verwaltung erfordert, kann es für dein Unternehmen von Vorteil sein, vor allem wenn du eine genauere Kontrolle brauchst und Ressourcen verwalten möchtest.
Der Nachteil ist, dass die Verwaltung viel Zeit in Anspruch nimmt, auch wenn sie dir Freiheit gibt. Dein Arbeitsablauf kann komplexer werden, weil du planen, die Leistung verfolgen und handeln musst, wenn eine Skalierung erforderlich ist.
Sowohl Google BigQuery als auch Amazon Redshift bieten bei der Integration mit ihren Cloud Computing-Plattformen spezifische Vorteile für ihre Ökosysteme.
BigQuery funktioniert reibungslos für Teams, die GCP und seine Dienste wie Google Compute Engine, Cloud Storage und Cloud Run nutzen; dann kann es von Vorteil sein, BigQuery zu verwenden, um deine Datenpipelines in derselben Umgebung zu halten.
Diese Integration in die Google-Tools und -Dienste macht BigQuery zur bevorzugten Option für Data Warehousing, wenn dein Unternehmen bereits das Google-Ökosystem nutzt, weil es einen reibungslosen Arbeitsablauf mit seinen Diensten bietet.
Amazon Redshift lässt sich gut mit anderen Diensten im AWS-Ökosystem kombinieren. Es kann in Amazon S3, AWS Lambda und AWS Glue integriert werden, sodass du einfachen Zugang zu anderen AWS-Diensten und -Ressourcen hast. Meiner Meinung nach ist das ein großer Vorteil!
Der Hauptunterschied zwischen Google BigQuery und Amazon Redshift ist die operative Verantwortung, die diese Dienste ihren Kunden auferlegen.
Da wir uns nicht um die Verwaltung der zugrunde liegenden Infrastruktur kümmern müssen, übernimmt Google alles von der Bereitstellung bis zur Skalierung mit BigQuery. Mit dieser Funktion eignet sich BigQuery besonders für Unternehmen mit wenigen Infrastrukturingenieuren, die sich vor operativen Aufgaben drücken wollen.
Redshift hingegen erfordert mehr technisches Know-how und Expertise. Wenn dein Team über Infrastrukturingenieure verfügt, gibt es weniger Probleme mit Backups, manueller Skalierung und der Bereitstellung von Clustern. Das gibt dir als Unternehmen die Kontrolle und Flexibilität über deine Infrastruktur.
Es gibt verschiedene Anwendungsfälle und Szenarien, in denen Google BigQuery die erste Wahl für Data Warehousing ist. Entscheide dich für BigQuery, wenn du:
Da es auf der Google Cloud Platform aufbaut, ist BigQuery eher mit Personen kompatibel, die stark in GCP investiert sind. Angenommen, du hast die meisten deiner Ressourcen innerhalb der Google Cloud Platform, wie Google Compute Engine, Cloud Storage und Cloud Run. Die Verwendung deiner Datenpipelines in derselben Umgebung kann von Vorteil sein.
BigQuery ist ein leistungsstarkes Tool für die Bearbeitung großer Datenmengen für Ad-hoc-Abfragen oder Echtzeitanalysen. Da du dich nicht um die Verwaltung der Infrastruktur kümmern musst, ist sichergestellt, dass deine Abfragen schnell und effizient verarbeitet werden; deine Arbeitslast skaliert automatisch, unabhängig von der Größe oder Komplexität deiner Daten.
Wenn dein Team nicht über die nötigen DevOps-Ressourcen verfügt, ist BigQuery hier der klare Sieger. Du brauchst dich nicht mit der technischen Verwaltung von Infrastrukturen zu befassen, das macht Google für dich. Das hilft dir, dich ausschließlich auf die Daten zu konzentrieren.
Es gibt einige Szenarien und Anwendungsfälle, in denen Amazon Redshift eindeutig die beste Data Warehousing-Lösung ist. Entscheide dich für Redshift, wenn du:
Wenn dein Unternehmen seine Ressourcen bereitgestellt und in das AWS-Ökosystem integriert hat, ist Redshift eine natürliche Ergänzung. Amazon Redshift wird mit anderen AWS-Diensten wie Amazon S3, AWS Lambda und AWS Glue zusammenarbeiten, sodass du dich bei der Datenverwaltung, z. B. bei der Datenspeicherung, -verarbeitung und -automatisierung, ausschließlich auf AWS verlassen kannst.
Redshift ist mit schweren Arbeitslasten kompatibel, die eine konstante Leistung für vorhersehbare Abfragemuster und einen reibungslosen und effizienten Ablauf erfordern. Da die Redshift-Cluster anpassbar sind und du die Infrastruktur kontrollieren kannst, kannst du dein Redshift so einstellen, dass es alle spezifischen Leistungsanforderungen erfüllt.
Wenn dein Team komplexe ETL-Workflows mit Dateningenieuren abwickelt, die die Infrastruktur verwalten, dann ist Redshift die richtige Wahl. Dies eignet sich gut für Unternehmen mit DevOps-Know-how zur Bewältigung umfangreicher Workflows; du hast die Kontrolle über Skalierung, Backups und Leistung.
Nachdem wir nun einige wichtige Komponenten beider Tools besprochen haben, wollen wir uns die wichtigsten Highlights ansehen. Das sollte dir bei der Entscheidung helfen, welches Tool du für deine speziellen Bedürfnisse nutzen solltest:
|
Eigenschaften |
BigQuery |
Redshift |
|
Architektur |
Serverlose Architektur bedeutet, dass du keine Infrastruktur verwalten musst. |
Arbeitet mit einer cluster-basierten Architektur, bei der du die Cluster manuell verwalten musst. |
|
Leistung |
Kann große Datenmengen schnell verarbeiten, vor allem bei Echtzeit-Analysen oder Ad-hoc-Abfragen. |
Bekannt für seine zuverlässige Leistung mit vorhersehbaren Abfragemustern. |
|
Kostenstruktur |
Es verwendet ein Pay-per-Query-Modell, d.h. du bezahlst für die Daten, die bei jeder Abfrage verarbeitet werden. |
Es verwendet reservierte Instanzen für Kostenrabatte, bei denen du eine bestimmte Menge an Rechenressourcen im Voraus bezahlst. |
|
Skalierbarkeit |
Die automatische Skalierbarkeit ist eine der stärksten Eigenschaften von BigQuery. |
Da eine manuelle Skalierung erforderlich ist, musst du die Größenänderung des Clusters, die Ressourcenzuweisung und die Leistungsoptimierung verwalten. |
|
Ökosystem-Integration |
Die enge Integration mit den Diensten der Google Cloud Platform (GCP) macht sie zur ersten Wahl für Teams, die bereits im Google-Ökosystem arbeiten. |
Nahtlose Integration in die Amazon Web Services (AWS)-Umgebung und ihre Dienste für Teams, die bereits das AWS-Ökosystem nutzen. |
|
Einfachheit der Nutzung |
Die vollständig verwaltete, serverlose Architektur von BigQuery vereinfacht die Arbeit, ohne dass tiefgreifende Kenntnisse im Infrastrukturmanagement erforderlich sind. |
Redshift erfordert mehr praktisches Management. Du musst Cluster, Skalierung und Leistung überwachen und verwalten. |
In diesem Artikel wurden die wichtigsten Vergleiche zwischen BigQuery und Redshift, zwei Cloud-Data-Warehousing-Lösungen mit einzigartigen Stärken und Gegensätzen, untersucht. Die beste Wahl hängt von deinen Bedürfnissen ab, einschließlich Datenvolumen, Abfragemuster und Budget.
Wenn du tiefer in diese Plattformen eintauchen möchtest, schau dir auf dem DataCamp "Einführung in Redshift " und "Einführung in BigQuery " an. In diesen praxisorientierten Kursen lernst du die Grundlagen der einzelnen Tools kennen und erwirbst praktische Fähigkeiten, um effektiv mit modernen Data Warehouses zu arbeiten.
Lerne in den folgenden Kursen mehr über Data Engineering und Cloud-Technologien!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
