
Cours
Introduction au data engineering
4 h
127.6K
Lorsque nous traitons de grandes quantités de données structurées et semi-structurées provenant de diverses sources, nous pensons à un référentiel centralisé pour les stocker. Le point de vue sur les entrepôts de données change constamment, et les solutions basées sur le cloud offrent des performances, une flexibilité et une évolutivité exceptionnelles. Google BigQuery et Amazon Redshift sont les meilleures solutions dans ce domaine.
Les puissantes fonctionnalités de traitement, d'analyse et de stockage des données des deux entrepôts de données basés sur le cloud permettent aux professionnels des données de gérer leurs données de manière plus efficace et efficiente.
Dans cet article, je vais comparer en détail ces plateformes, y compris leurs caractéristiques, leurs avantages, leurs inconvénients et les meilleures pratiques. Examinons les spécificités et aidons nous à identifier la meilleure option pour vos besoins !
Google BigQuery est un entrepôt de données sans serveur, entièrement géré, proposé par Google Cloud Platform (GCP). BigQuery est conçu pour traiter des ensembles de données massifs, permettre des analyses en temps réel et prendre en charge des flux de travail d'apprentissage automatique avec une gestion minimale de l'infrastructure. Son architecture sans serveur vous permet d'utiliser des requêtes SQL pour analyser vos données.
BigQuery présente les données dans des tableaux, des lignes et des colonnes, prenant en charge la sémantique des transactions de base de données (ACID). Le stockage BigQuery est automatiquement répliqué sur plusieurs sites pour assurer une haute disponibilité.
Interface GCP : Interface principale de la console BigQuery.
Fonctionnalités de base de BigQuery :
Cas d'utilisation de BigQuery :
Amazon Redshift est une solution d'entrepôt de données basée sur le cloud qui fait partie de la plateforme plus large de cloud computing, Amazon Web Services (AWS). Grâce à l'architecture en grappe de Redshift, les utilisateurs peuvent accéder à des charges de travail prévisibles à grande échelle et les analyser sans avoir à gérer eux-mêmes l'infrastructure.
Redshift permet aux utilisateurs de charger des données et de commencer à faire des recherches immédiatement en utilisant l'éditeur de requêtes Amazon Redshift v2 ou l'outil de Business Intelligence (BI) de leur choix. Ce service offre le meilleur rapport qualité-prix et des fonctionnalités SQL familières dans un environnement facile à utiliser et sans administration.
Interface AWS : Interface principale de la console Amazon Redshift.
Fonctionnalités de base de Redshift :
Cas d'utilisation de Redshift :
Après un bref aperçu de ces deux entrepôts de données dans le cloud, examinons de près leurs différences dans différents domaines.
L'architecture de la plateforme décrit le fonctionnement des systèmes. Ici, je mettrai en évidence la distinction entre le modèle de tarification de BigQuery, basé sur les requêtes et sans serveur, et l'approche de Redshift, basée sur les clusters.
Si vous préférez une approche non interventionniste avec une mise à l'échelle automatique, BigQuery est votre choix pour l'entreposage de données.
BigQuery vous permet de ne pas gérer d'infrastructure ; Google s'occupe de tout, de l'approvisionnement à la mise à l'échelle. Avec BigQuery, vous ne payez que pour les requêtes que vous exécutez et le stockage que vous utilisez. Cette approche de tarification au fur et à mesure est rentable et vous permet de ne pas subir de coûts de ressources inutilisées.
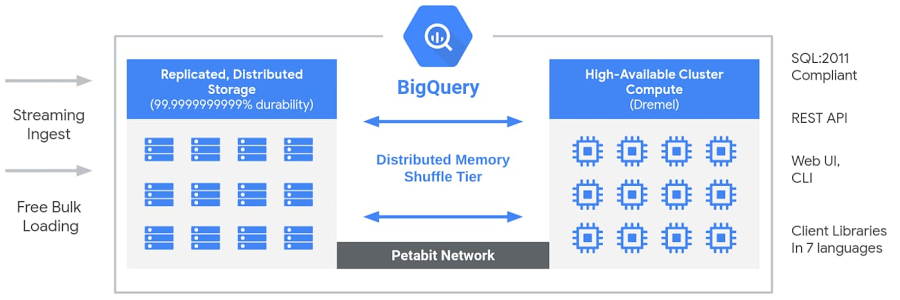
Architecture BigQuery (Source : Google Cloud blog).
Si vous avez besoin d'un plus grand contrôle sur votre infrastructure et que vous pouvez gérer efficacementvos clusters, Amazon Redshift vous conviendra mieux. Redshift vous demande de mettre en place et de gérer des clusters en choisissant le type d'instance, le nombre de nœuds et la configuration. Cela vous permet de contrôler l'infrastructure, mais, d'après mon expérience, cela ajoute également de la complexité.
Redshift propose une approche tarifaire à la fois réservée et à la demande. Avec les instances réservées, vous bénéficiez d'une réduction et vous vous engagez à utiliser une capacité spécifique pendant une période prédéterminée (un ou trois ans, par exemple). La tarification à la demande vous permet de payer pour la capacité que vous utilisez à l'heure, mais une mauvaise gestion peut la rendre plus coûteuse.
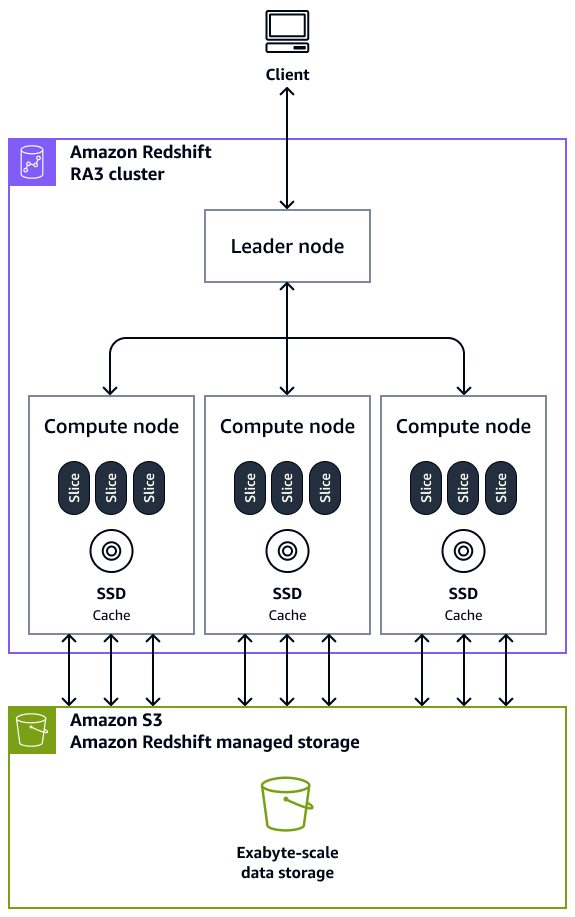
Architecte Amazon Redshifture (Source : AWS).
Google BigQuery et Amazon Redshift offrent tous deux des performances impressionnantes pour les requêtes à grande échelle, mais ils sont plus performants dans des cas différents. Voyons comment les deux plateformes gèrent les performances pour les requêtes à grande échelle, en soulignant les performances optimisées de BigQuery pour les requêtes ad hoc et le contrôle de Redshift sur les clusters pour les charges de travail prévisibles.
BigQuery est conçu pour gérer facilement les charges de travail dynamiques grâce à son architecture sans serveur. Cela permet à BigQuery d'échelonner automatiquement les charges de travail et d'obtenir des performances élevées pour les requêtes ad hoc à grande échelle. Le stockage en colonnes de BigQuery est très efficace pour les requêtes analytiques. Ce format réduit la quantité de données lues sur le disque, ce qui accélère les performances des requêtes.
Redshift peut être une meilleure option si vous pouvez gérer des clusters pour des performances fiables dans des environnements avec des charges de travail prévisibles. Vous pouvez régler les clusters pour obtenir des performances de requête constantes, en veillant à ce que vos ressources soient optimisées pour répondre aux besoins de votre entreprise.
Redshift offre diverses options de réglage des performances, telles que les clés de tri et de distribution, afin d'optimiser l'exécution des requêtes. Cette fonctionnalité peut améliorer les performances des charges de travail prévisibles, mais seulement si vous savez ce que vous faites ! D'après mon expérience, la courbe d'apprentissage peut être abrupte.
Il est essentiel de comprendre les structures de prix et de coûts lors de la sélection d'un entrepôt de données, car nous voulons être responsables de chaque dollar que nous dépensons.
Voyons comment le modèle de paiement par requête et les frais de stockage de Google BigQuery se comparent à la tarification en cluster d' Amazon Redshift, avec des économies sur les instances réservées :
|
Facteur de coût |
BigQuery |
Redshift |
|
Tiercé libre |
10GB gratuits par mois |
Il n'y a pas de niveau gratuit, mais une période d'essai de deux mois est offerte. |
|
Frais de stockage |
20 $ par TB pour le stockage logique actif, 10 $ pour le stockage à long terme. |
0,025 $ par Go par mois pour les SSD, 0,08 $ par Go pour les RA3 |
|
Coût des requêtes |
5 $ par TB pour les requêtes à la demande |
En fonction de l'utilisation des instances de calcul et du stockage |
|
Calculer les coûts |
Frais basés sur le calcul de la capacité (par heure de créneau) |
Facturation horaire (à la demande ou sur réservation) |
|
Mise à l'échelle |
Mise à l'échelle automatique avec autoscaler |
Mise à l'échelle manuelle avec gestion des nœuds |
|
Coûts de sauvegarde |
Frais de stockage à long terme au-delà du niveau gratuit |
Inclus pour les sauvegardes de base, coûts supplémentaires pour plus d'instantanés |
|
Coûts supplémentaires |
Aucune pour les sauvegardes ou la mise à l'échelle |
Frais d'échelonnement de la concurrence après l'essai gratuit |
L'un des facteurs les plus importants à prendre en compte lors de la sélection de notre entrepôt de données est l'évolutivité.
Examinons comment BigQuery augmente automatiquement la capacité de stockage et de calcul en réponse à la demande et comment Redshift exige une mise à l'échelle manuelle des clusters, ce qui peut prendre plus de temps.
BigQuery est la plateforme privilégiée lorsque vous êtes sûr que votre entreprise se développera en même temps que ses charges de travail et ses infrastructures. La fonctionnalité de mise à l'échelle automatique de BigQuery vous décharge de ce fardeau, ce qui vous permet de gagner du temps et de l'énergie pour vous concentrer entièrement sur l'analyse des données.
Dans l'idéal, Redshift sera plus performant si votre entreprise dispose d'un nombre suffisant d'ingénieurs en données. Bien que Redshift exige une gestion plus active, il peut être avantageux pour votre entreprise, en particulier si vous avez besoin d'un contrôle plus précis et souhaitez gérer les ressources.
L'inconvénient est que la gestion prend beaucoup de temps, même si elle vous donne de la liberté. Votre flux de travail peut devenir plus complexe en raison de l'obligation de planifier, de suivre les performances et d'agir lorsque l'échelle est nécessaire.
Google BigQuery et Amazon Redshift offrent tous deux des avantages spécifiques à leurs écosystèmes lorsqu'ils s'intègrent à leurs plateformes de cloud computing.
BigQuery fonctionne sans problème pour les équipes qui utilisent GCP et ses services, tels que Google Compute Engine, Cloud Storage et Cloud Run ; il peut alors être avantageux d'utiliser BigQuery pour conserver vos pipelines de données dans le même environnement.
Cette intégration avec la suite d'outils et de services de Google fait de BigQuery l'option préférée pour l'entreposage de données si votre entreprise utilise déjà l'écosystème Google, car il offre un flux de travail fluide avec ses services.
Amazon Redshift s'harmonisera bien avec les autres services de l'écosystème AWS. Il peut s'intégrer à Amazon S3, AWS Lambda et AWS Glue, ce qui vous permet d'accéder facilement à d'autres services et ressources AWS. À mon avis, c'est un grand avantage !
La principale différence entre Google BigQuery et Amazon Redshift est la responsabilité opérationnelle que ces services imposent à leurs clients.
Comme nous n'avons pas à nous préoccuper de la gestion de l'infrastructure sous-jacente, Google se charge de tout, de l'approvisionnement à la mise à l'échelle, à l'aide de BigQuery. Cette caractéristique permet à BigQuery de se démarquer pour les entreprises disposant de peu d'ingénieurs d'infrastructure et essayant d'éviter les responsabilités opérationnelles.
Redshift, en revanche, exige davantage de savoir-faire et d'expertise techniques. Si votre équipe compte des ingénieurs en infrastructure, les problèmes liés à la gestion des sauvegardes, à la mise à l'échelle manuelle et au provisionnement des grappes seront moins nombreux. En tant qu'entreprise, cela vous permet de contrôler votre infrastructure et de la rendre plus flexible.
Il existe plusieurs cas d'utilisation et scénarios dans lesquels Google BigQuery devient la solution d'entreposage de données par excellence. Choisissez BigQuery si vous :
Puisqu'il est construit sur la Google Cloud Platform, BigQuery est plus compatible avec les personnes qui sont fortement investies dans GCP. Supposons que vous disposiez de la plupart de vos ressources au sein de Google Cloud Platform, telles que Google Compute Engine, Cloud Storage et Cloud Run. L'utilisation de vos pipelines de données dans le même environnement peut s'avérer bénéfique.
BigQuery est un outil puissant qui permet de traiter de grands ensembles de données pour des requêtes ad hoc ou des analyses en temps réel. Comme vous n'avez pas à vous préoccuper de la gestion de l'infrastructure, vos requêtes sont traitées rapidement et efficacement ; votre charge de travail évolue automatiquement, quelle que soit la taille ou la complexité de vos données.
Si votre équipe ne dispose pas des ressources DevOps nécessaires, BigQuery l'emporte haut la main. Vous n'avez pas à vous préoccuper de la technicité de la gestion des infrastructures, Google s'en charge pour vous. Cela vous permet de vous concentrer uniquement sur l'analyse des données.
Il existe certains scénarios et cas d'utilisation pour lesquels Amazon Redshift est la solution d'entreposage de données de choix évident. Choisissez Redshift si vous :
Si votre organisation a déployé ses ressources et s'est intégrée à l'écosystème AWS, Redshift est une solution naturelle. Amazon Redshift fonctionnera avec d'autres services AWS comme Amazon S3, AWS Lambda et AWS Glue, ce qui permettra de s'appuyer uniquement sur AWS pour la gestion des données, comme le stockage, le traitement et les besoins d'automatisation.
Redshift est compatible avec les charges de travail lourdes qui exigent des performances constantes pour des modèles de requêtes prévisibles et une exécution fluide et efficace. Comme les clusters de Redshift sont personnalisables et que vous pouvez contrôler l'infrastructure, vous pouvez régler votre Redshift pour qu'il réponde à toutes les exigences de performance spécifiques.
Si votre équipe gère des flux de travail ETL complexes avec des ingénieurs de données qui gèrent l'infrastructure, Redshift est le bon choix. Cela convient parfaitement aux entreprises disposant d'une expertise DevOps pour gérer des flux de travail lourds ; vous aurez le contrôle sur la mise à l'échelle, les sauvegardes et les performances.
Maintenant que nous avons passé en revue certains éléments importants de ces deux outils, passons en revue leurs principales caractéristiques. Cela devrait vous aider à décider quel outil utiliser pour vos besoins spécifiques :
|
Caractéristiques |
BigQuery |
Redshift |
|
L'architecture |
L'architecture sans serveur signifie que vous n'avez pas besoin de gérer d'infrastructure. |
Fonctionne sur une architecture basée sur des clusters que vous devez gérer manuellement. |
|
Performance |
Peut traiter rapidement de grands ensembles de données, en particulier avec des analyses en temps réel ou des requêtes ad hoc. |
Connu pour ses performances fiables avec des modèles de requêtes prévisibles. |
|
Structure des coûts |
Il utilise un modèle de paiement par requête, ce qui signifie que vous payez pour les données traitées par chaque requête. |
Il utilise des instances réservées pour les réductions de coûts, où vous payez un montant spécifique de ressources informatiques à l'avance. |
|
Évolutivité |
L'évolutivité automatique est l'une des principales caractéristiques de BigQuery. |
Une mise à l'échelle manuelle est nécessaire, vous devez donc gérer le redimensionnement de la grappe, l'allocation des ressources et l'optimisation des performances. |
|
Intégration de l'écosystème |
L'intégration profonde avec les services de Google Cloud Platform (GCP) en fait un choix de premier ordre pour les équipes qui travaillent déjà au sein de l'écosystème Google. |
Intégration transparente avec l'environnement Amazon Web Services (AWS) et ses services pour les équipes qui utilisent déjà l'écosystème AWS. |
|
Facilité d'utilisation |
L'architecture sans serveur et entièrement gérée de BigQuery la simplifie sans nécessiter de compétences approfondies en matière de gestion d'infrastructure. |
Redshift nécessite une gestion plus pratique. Vous devez surveiller et gérer les grappes, la mise à l'échelle et les performances. |
Cet article a exploré les principales comparaisons entre BigQuery et Redshift, deux solutions d'entreposage de données dans le cloud présentant des atouts et des compromis uniques. Le meilleur choix dépend de vos besoins, notamment du volume de données, des modèles d'interrogation et du budget.
Si vous souhaitez plonger plus profondément dans ces plateformes, consultez Introduction à Redshift et Introduction à BigQuery sur DataCamp. Ces cours pratiques vous aideront à maîtriser les principes fondamentaux de chaque outil et à acquérir des compétences pratiques pour travailler efficacement avec les entrepôts de données modernes.
Apprenez-en plus sur l'ingénierie des données et les technologies cloud avec les cours suivants !
Cours
Cours
Cours