
Curso
Comprender la computación en la nube
2 h
235.2K
Si te estás preparando para una entrevista de trabajo como ingeniero de nube, has llegado al lugar adecuado. Este artículo responde a algunas de las preguntas más frecuentes para ayudarte a practicar y ganar confianza. Tanto si aspiramos a un puesto en ingeniería de nube, DevOps o MLOps, estas preguntas pondrán a prueba nuestros conocimientos sobre los conceptos, la arquitectura y las mejores prácticas de la nube.
Para que esta guía sea aún más práctica, he incluido ejemplos de servicios de los principales proveedores de nube (AWS, Azure y GCP) para que puedas ver cómo abordan las soluciones en la nube las diferentes plataformas. ¡Vamos a ello!
Estas preguntas fundamentales evalúan tu comprensión de los conceptos, servicios y modelos de implementación de la nube. Tu entrevista normalmente comenzará con algunas preguntas similares.
Los tres modelos principales de nube son:
Estas son algunas de las ventajas más importantes de la nube:
Hay cuatro modelos principales:

Modelos de implementación en la nube. Imagen del autor.
La virtualización es el proceso de crear instancias virtuales de recursos informáticos, como servidores, almacenamiento y redes, en una única máquina física. Permite la nube al facilitar una asignación eficiente de recursos, la multitenencia y la escalabilidad.
Tecnologías como Hyper-V, VMware y KVM se utilizan habitualmente para la virtualización en entornos nube.
Una región de nube es un área geográficamente diferenciada en la que los proveedores de servicios en la nube alojan varios centros de datos. Una zona de disponibilidad (AZ) es un centro de datos físicamente independiente dentro de una región diseñado para ofrecer redundancia y alta disponibilidad.
Por ejemplo, AWS tiene varias regiones en todo el mundo, cada una de las cuales contiene dos o más AZ para la recuperación ante desastres y la tolerancia a fallos.
A continuación se indican las diferencias entre estos dos conceptos:
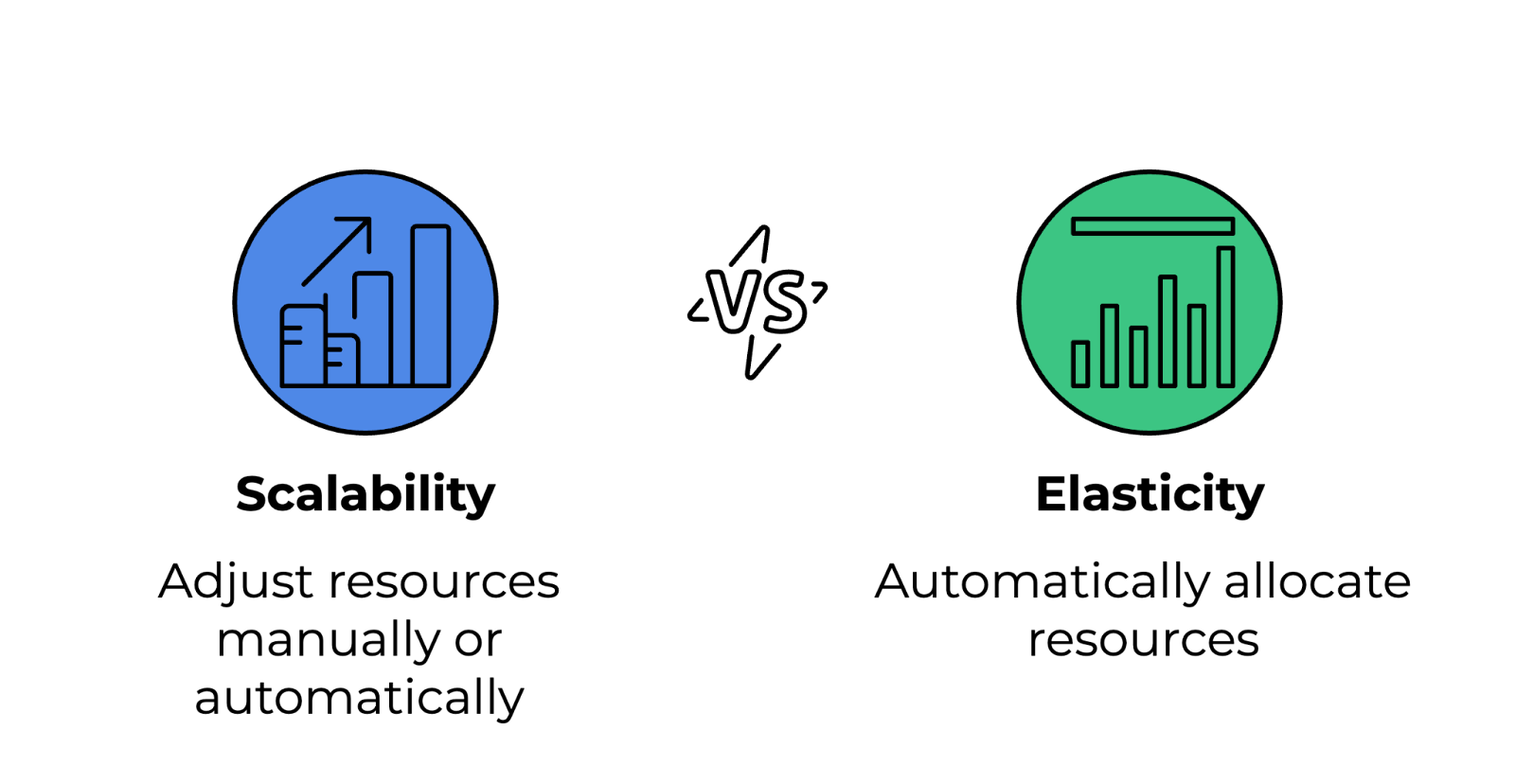
Diferencia entre escalabilidad y elasticidad. Imagen del autor.
La siguiente tabla enumera los principales proveedores de nube, sus puntos fuertes y casos de uso:
|
Proveedor de servicios en la nube |
Puntos fuertes |
Casos de uso |
|
Amazon Web Services (AWS) |
El mayor proveedor de servicios en la nube con una amplia gama de servicios. |
Nube de uso general, sin servidor, DevOps. |
|
Microsoft Azure |
Especializados en soluciones empresariales y de nube híbrida. |
Aplicaciones empresariales, nube híbrida, integración del ecosistema de Microsoft. |
|
Plataforma Google Nube (GCP) |
Especializado en big data, IA/ML y Kubernetes. |
machine learning, análisis de datos, orquestación de contenedores. |
|
IBM Nube |
Se centra en soluciones de inteligencia artificial y nube empresarial. |
Aplicaciones basadas en inteligencia artificial, transformación empresarial en la nube. |
|
Oracle Nube |
Experiencia en bases de datos y aplicaciones empresariales. |
Gestión de bases de datos, aplicaciones ERP, cargas de trabajo empresariales. |
La computación sin servidor es un modelo de ejecución en la nube en el que el proveedor de nube gestiona la infraestructura de forma automática, lo que permite a los programadores centrarse en escribir código. Los usuarios solo pagan por el tiempo de ejecución real, en lugar de por la provisión de recursos fijos. Algunos ejemplos son:
El almacenamiento de objetos es una arquitectura de almacenamiento de datos en la que los archivos se almacenan como objetos discretos dentro de un espacio de nombres plano, en lugar de en sistemas de archivos jerárquicos. Es altamente escalable y se utiliza para datos no estructurados, copias de seguridad y almacenamiento multimedia. Algunos ejemplos son:
Una CDN es una red de servidores distribuidos que almacenan en caché y entregan contenido (por ejemplo, imágenes, vídeos, páginas web) a los usuarios en función de su ubicación geográfica. Esto reduce la latencia, mejora el rendimiento del sitio web y aumenta la disponibilidad. Entre las CDN más populares se incluyen:
Estas preguntas profundizan en las redes en la nube, la seguridad, la automatización y la optimización del rendimiento, y ponen a prueba tu capacidad para diseñar, gestionar y resolver problemas en entornos en la nube de forma eficaz.
Una nube privada virtual (VPC) es una sección aislada lógicamente de una nube pública que permite a los usuarios iniciar recursos en un entorno de red privada. Proporciona un mayor control sobre las configuraciones de red, las políticas de seguridad y la gestión de accesos.
En una VPC, los usuarios pueden definir rangos de direcciones IP utilizando bloques CIDR. Se pueden crear subredes para separar los recursos públicos y privados, y los grupos de seguridad y las ACL de red ayudan a aplicar las políticas de acceso a la red.
Los equilibradores de carga distribuyen el tráfico de red entrante entre varios servidores para garantizar una alta disponibilidad, tolerancia a fallos y un mejor rendimiento.
Existen diferentes tipos de equilibradores de carga:
IAM es un marco que controla quién puede acceder a los recursos en la nube y qué acciones pueden realizar. Ayuda a aplicar el principio del mínimo privilegio y protege los entornos en la nube.
En IAM, los usuarios y los roles definen identidades con permisos específicos, las políticas conceden o deniegan el acceso mediante reglas basadas en JSON, y la autenticación multifactorial (MFA) añade una capa de seguridad adicional para las operaciones críticas.
Los grupos de seguridad y las ACL (listas de control de acceso) de red controlan el tráfico entrante y saliente hacia los recursos de nube, pero funcionan a diferentes niveles.
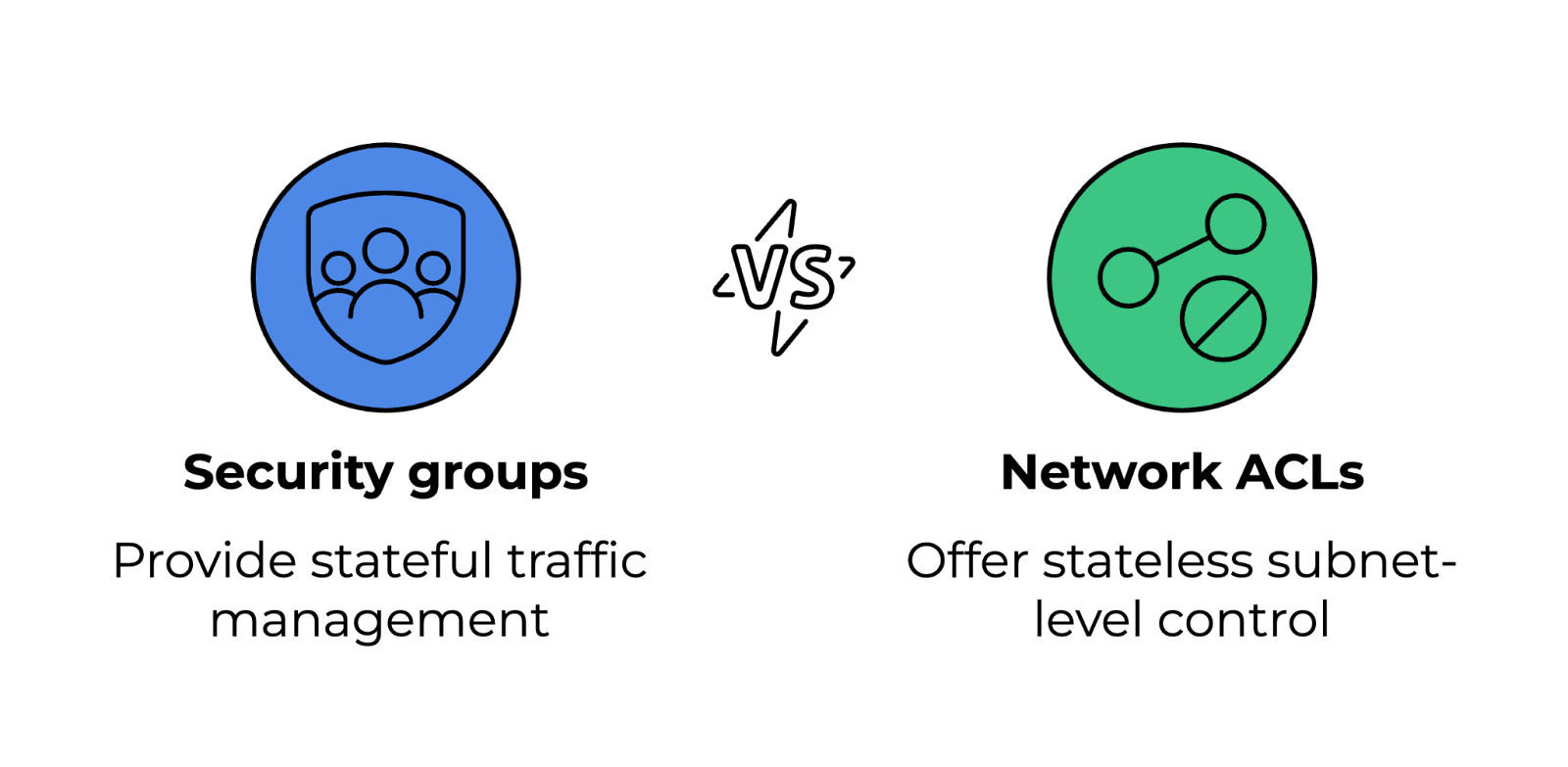
Comparación entre grupos de seguridad y ACL de red. Imagen del autor.
Un host bastión es un servidor de salto seguro para acceder a recursos en la nube en una red privada. En lugar de exponer todos los servidores a Internet, actúa como puerta de enlace para las conexiones remotas.
Para mejorar la seguridad, debe contar con reglas de firewall estrictas, que solo permitan el acceso SSH o RDP desde direcciones IP de confianza. Para garantizar un acceso seguro, se debe utilizar la autenticación multifactorial (MFA) y la autenticación basada en claves, y se debe habilitar el registro y la supervisión para rastrear los intentos de inicio de sesión no autorizados.
El autoescalado permite a los entornos en la nube ajustar dinámicamente los recursos en función de la demanda, lo que garantiza la rentabilidad y el rendimiento. Funciona de dos maneras:
Los proveedores de nube ofrecen grupos de autoescalado, que funcionan con equilibradores de carga para distribuir el tráfico de manera eficaz.
Para gestionar los costes de la nube de forma eficaz, es necesario supervisar el uso y seleccionar los modelos de precios adecuados. Las estrategias de optimización de costes incluyen:
¿Quieres dominar la seguridad de AWS y optimizar los costes de la nube? Echa un vistazo al curso Seguridad y gestión de costes de AWS para aprender las prácticas recomendadas esenciales.

Optimización de los costes de la nube: cuatro pilares. Imagen del autor.
Terraform y AWS CloudFormation son herramientas de infraestructura como código (IaC), pero tienen algunas diferencias:
|
Característica |
Terraform |
AWS CloudFormation |
|
Soporte en la nube |
Independiente de la nube, compatible con AWS, Azure, GCP y otros. |
Específico para AWS, diseñado exclusivamente para recursos de AWS. |
|
Lenguaje de configuración |
Utiliza el lenguaje de configuración de HashiCorp (HCL). |
Utiliza plantillas JSON/YAML. |
|
Gestión estatal |
Mantiene un archivo de estado para realizar un seguimiento de los cambios en la infraestructura. |
Utiliza pilas para gestionar y programar las implementaciones. |
Las herramientas de supervisión ayudan a detectar cuellos de botella en el rendimiento, amenazas de seguridad y uso excesivo de recursos. Las soluciones de supervisión habituales incluyen:
Los contenedores empaquetan aplicaciones con dependencias, lo que las hace ligeras, portátiles y escalables. En comparación con las máquinas virtuales, los contenedores utilizan menos recursos, ya que se pueden ejecutar varios contenedores en un solo sistema operativo.
Docker y Kubernetes permiten una implementación y una reversión más rápidas. Además, se adaptan fácilmente con herramientas de orquestación como Kubernetes y Amazon ECS/EKS.
¿Quieres perfeccionar tus habilidades en contenedorización? T El programa sobre contenedorización y virtualización abarcaDocker, Kubernetes y mucho más para ayudarte a crear aplicaciones en la nube escalables.
Una malla de servicios es una capa de infraestructura que gestiona la comunicación entre servicios en aplicaciones en la nube basadas en microservicios. Proporciona:
Entre las soluciones de malla de servicios más populares se incluyen Istio, Linkerd y AWS App Mesh.
Una estrategia multinube implica utilizar varios proveedores de nube (AWS, Azure, GCP) para evitar la dependencia de un único proveedor y mejorar la resiliencia.
Las empresas eligen este enfoque cuando necesitan redundancia geográfica para la recuperación ante desastres, quieren aprovechar servicios únicos de diferentes proveedores (por ejemplo, AWS para la computación, GCP para la IA) o deben cumplir con normativas regionales que restringen las opciones de proveedores de nube.

Ventajas y desventajas de la estrategia en nubes. Imagen del autor.
Estas preguntas evalúan tu capacidad para diseñar soluciones escalables, gestionar infraestructuras complejas en la nube y manejar situaciones críticas.
Una arquitectura multirregional garantiza un tiempo de inactividad mínimo y la continuidad del negocio mediante la distribución de los recursos en múltiples ubicaciones geográficas.
A la hora de diseñar una arquitectura de este tipo, hay que tener en cuenta varios factores. Estos son algunos de ellos:
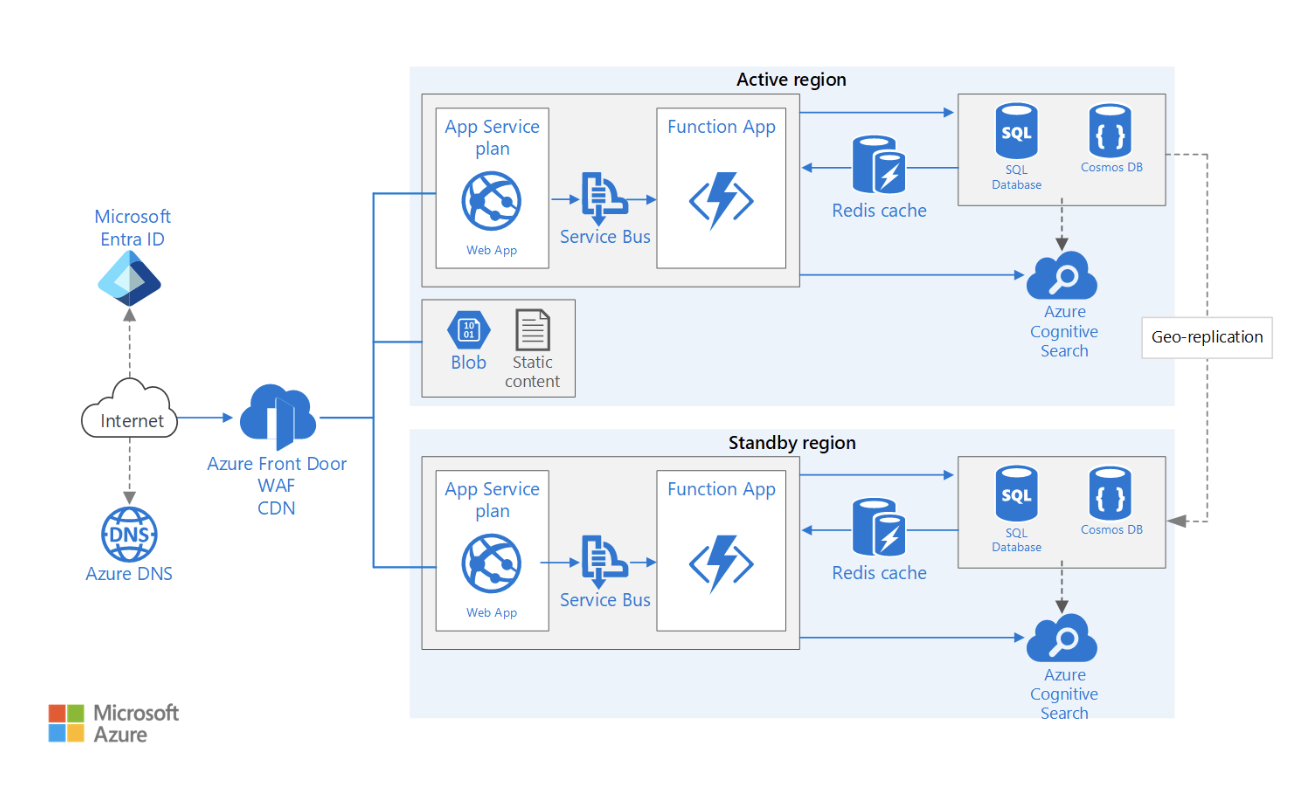
Ejemplo de arquitectura de aplicación web multirregional de alta disponibilidad. Fuente de la imagen: Microsoft Learn
El modelo de confianza cero parte de la base de que no se debe confiar por defecto en ninguna entidad, ya sea dentro o fuera de la red.
Para implementar el modelo de confianza cero en entornos nube:
Una estrategia exitosa comienza con la asignación y el etiquetado de costes, donde las organizaciones aplican un etiquetado estructurado (por ejemplo, departamento, proyecto, propietario) para realizar un seguimiento del gasto entre los equipos y mejorar la visibilidad financiera.
Las alertas presupuestariasautomatizadas deben configurarse utilizando herramientas como AWS Budgets, Azure Cost Management o GCP Billing Alerts para evitar gastos inesperados. Estas soluciones proporcionan supervisión en tiempo real y notificaciones cuando el uso se aproxima a los umbrales predefinidos.
Otro aspecto es el redimensionamiento y las instancias reservadas. Mediante el análisis continuo de métricas de utilización de instancias, como la CPU y la memoria, los equipos pueden determinar si las cargas de trabajo deben ajustarse o migrarse a instancias reservadas o instancias spot, lo que supone un importante ahorro de costes.
La implementación de las mejores prácticas deFinOps mejora aún más la rentabilidad. Las herramientas automatizadas de detección de anomalías en los costes, como Kubecost (para entornos Kubernetes) y AWS Compute Optimizer, ayudan a identificar de forma proactiva los recursos infrautilizados y a optimizarlos.
Por último, las políticas de apagado automático desempeñan un papel esencial en la reducción de residuos. Las funciones sin servidor, como AWS Lambda o Azure Functions, pueden apagar automáticamente los recursos infrautilizados fuera del horario laboral, evitando gastos innecesarios.
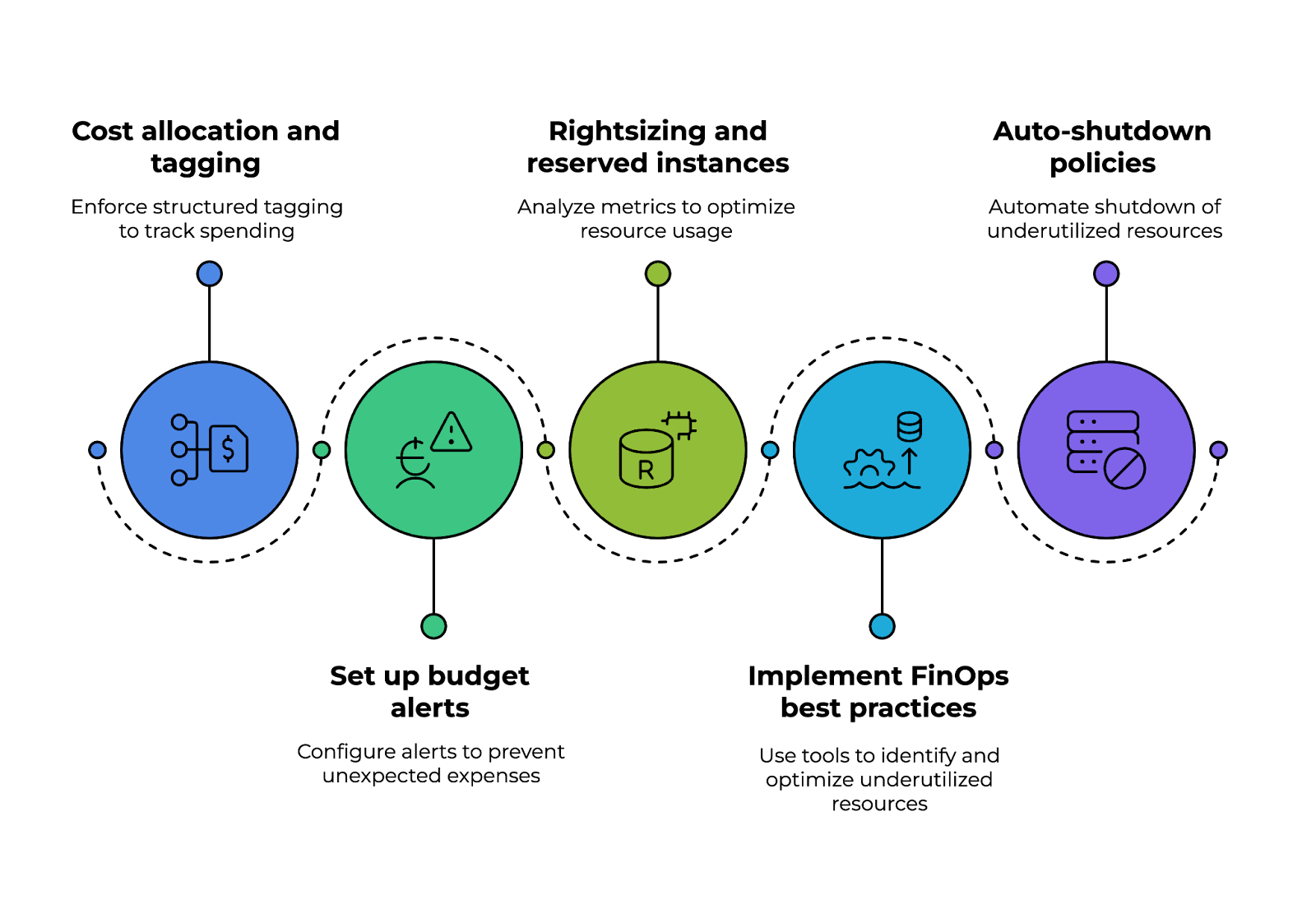
Pilares para la implementación de una estrategia de control de costes en la nube. Imagen del autor.
Un lago de datos requiere un almacenamiento, una recuperación y un procesamiento eficientes de datos a escala de petabytes. Algunas estrategias de optimización incluyen:
Uno de los aspectos fundamentalesde un proceso de CI/CD es el control de versiones del código y la gestión del repositorio, lo que permite una colaboración eficiente y el seguimiento de los cambios. Herramientas como GitHub Actions, AWS CodeCommit o Azure Repos ayudan a gestionar el código fuente, aplicar estrategias de ramificación y optimizar los flujos de trabajo de las solicitudes de extracción.
La automatizaciónde la compilación y la gestión de artefactos desempeñan un papel crucial en el mantenimiento de la coherencia y la fiabilidad de las compilaciones de software. Mediante compilaciones basadas en Docker, JFrog Artifactory o AWS CodeArtifact, los equipos pueden crear compilaciones reproducibles, almacenar artefactos de forma segura y garantizar el control de versiones en todos los entornos de desarrollo.
La seguridad es otro aspecto fundamental a tener en cuenta. La integración de herramientas SAST (pruebas de seguridad de aplicaciones estáticas) , como SonarQube o Snyk, permite detectar de forma temprana las vulnerabilidades en el código base. Además, la aplicación de imágenes de contenedor firmadas garantiza que solo se implementen artefactos verificados y de confianza.
Una sólida estrategia de implementación en varias etapas ayuda a minimizar los riesgos asociados con los lanzamientos de software. Enfoques como las implementaciones canario, azul-verde o progresivas permiten lanzamientos graduales, lo que reduce el tiempo de inactividad y permite supervisar el rendimiento en tiempo real. Mediante el uso de indicadores de funciones, los equipos pueden controlar qué usuarios prueban las nuevas funciones antes de su lanzamiento completo.
Por último, la integración de Infraestructura como Código (IaC) es esencial para automatizar y estandarizar los entornos en la nube. Mediante el uso de Terraform, AWS CloudFormation o Pulumi, los equipos pueden definir la infraestructura en código, mantener la coherencia entre las implementaciones y habilitar el aprovisionamiento de recursos en la nube.
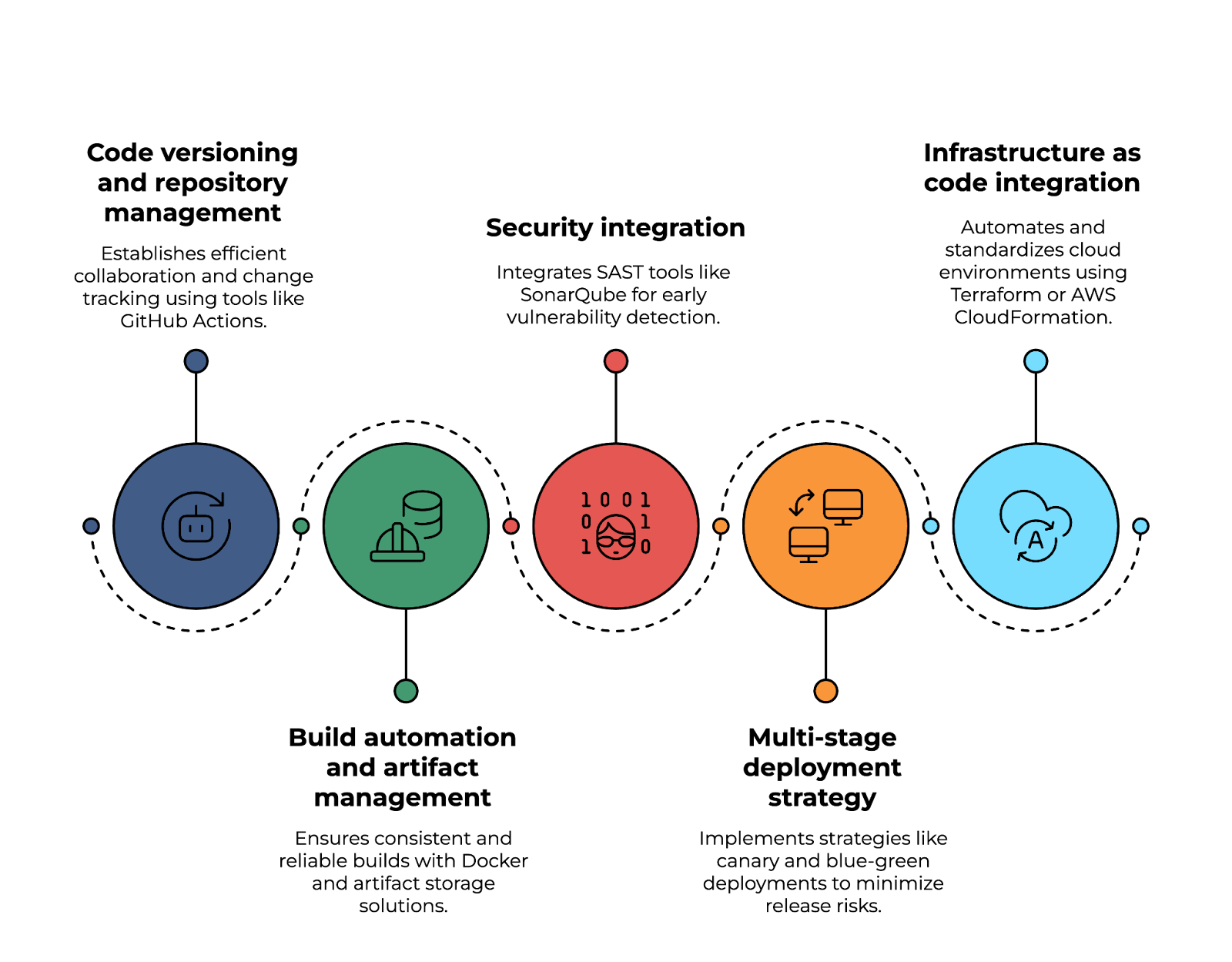
Implementación de un canal de CI/CD nativo en la nube. Imagen del autor.
La recuperación ante desastres (DR) es esencial para garantizar la continuidad del negocio en caso de interrupciones, ataques o fallos de hardware. Un plan de recuperación ante desastres sólido incluye lo siguiente:
La gestión de clústeres Kubernetes (K8s) a gran escala plantea retos operativos y de rendimiento. Las áreas clave que hay que abordar incluyen:
Las preguntas basadas en escenarios evalúan tu capacidad para analizar retos reales relacionados con la nube, resolver problemas y tomar decisiones arquitectónicas bajo diferentes restricciones.
Tus respuestas deben demostrar experiencia práctica, capacidad de toma de decisiones y capacidad para encontrar soluciones de compromiso a la hora de resolver problemas relacionados con la nube. Dado que no hay respuestas correctas o incorrectas, he incluido algunos ejemplos para guiar tu proceso de reflexión.
Ejemplo de respuesta:
La alta latencia en una aplicación en la nube puede deberse a varios factores, entre ellos la congestión de la red, consultas ineficientes a la base de datos, una ubicación subóptima de las instancias o configuraciones incorrectas del equilibrio de carga.
Para diagnosticar el problema, empezaría por aislar el cuello de botella utilizando herramientas de supervisión de nube. El primer paso sería analizar los tiempos de respuesta de la aplicación y la latencia de la red comprobando los registros, los tiempos de solicitud-respuesta y los códigos de estado HTTP. Si el problema está relacionado con la red, utilizaría una prueba de traceroute o ping para comprobar si ha aumentado el tiempo de ida y vuelta entre los usuarios y la aplicación. Si existe un problema, habilitar una CDN podría ayudar a almacenar en caché el contenido estático más cerca de los usuarios y reducir la latencia.
Si las consultas a la base de datos están causando retrasos, yo analizaría las consultas lentasy las optimizaría mediante unñadiendo la indexación adecuada o desnormalizando las tablas. Además, si la aplicación tiene un tráfico elevado, habilitar el escalado horizontal con grupos de autoescalado o réplicas de lectura puede reducir la carga en la base de datos principal.
Si los problemas de latencia persisten, comprobaría los recursos informáticos de la aplicación, asegurándome de que se ejecuta en la zona de disponibilidad correcta más cercana a los usuarios finales. Si fuera necesario, migraría las cargas de trabajo a una configuración multirregional o utilizaría soluciones de computación periférica para procesar las solicitudes más cerca de la fuente.
Ejemplo de respuesta:
El primer paso es realizar una evaluación de la preparación para la nube, en la que se evalúe si la aplicación se puede migrar tal cual o si requiere modificaciones. Un enfoque consiste en utilizar las «6 R de la migración a la nube»:
Un enfoque de «lift-and-shift» sería ideal si el objetivo es una migración rápida con cambios mínimos. Si la optimización del rendimiento y la rentabilidad son prioridades, consideraría cambiar la plataforma trasladando la aplicación a contenedores o a la computación sin servidor, lo que permitiría una mejor escalabilidad. Para aplicaciones con arquitecturas monolíticas, puede ser necesario refactorizar en microservicios para mejorar el rendimiento y la facilidad de mantenimiento.
También me centraría en la migración de datos, asegurándome de que las bases de datos se replican en la nube con un tiempo de inactividad mínimo.
La seguridad y el cumplimiento normativo serían otra preocupación importante. Antes de la implementación, me aseguraría de que la aplicación cumpla con los requisitos normativos (por ejemplo, HIPAA, RGPD) mediante la implementación de cifrado, políticas de IAM y aislamiento de VPC.
Por último, realizaría pruebas y validaciones en un entorno de ensayo antes de cambiar el tráfico de producción.
Ejemplo de respuesta:
A nivel de infraestructura, implementaría el clúster de Kubernetes en varias zonas de disponibilidad (AZ). Esto garantiza que el tráfico se pueda redirigir a otra zona si una AZ deja de funcionar. Utilizaría Kubernetes Federation para gestionar implementaciones multiclúster para configuraciones locales o híbridas.
Dentro del clúster, implementaría la resiliencia a nivel de pod configurando ReplicaSets y autoscalers horizontales de pod (HPA) para escalar las cargas de trabajo de forma dinámica en función de la utilización de la CPU y la memoria. Además, los presupuestos de interrupción de pods (PDB) garantizarían que un número mínimo de pods permaneciera disponible durante las actualizaciones o el mantenimiento.
Para las redes, utilizaría una malla de servicios para gestionar la comunicación entre servicios, aplicando políticas de reintentos, interrupción de circuitos y modelado del tráfico. Un equilibrador de carga global distribuiría el tráfico externo de manera eficiente entre varias regiones.
El almacenamiento persistente es otro aspecto fundamental. Si los microservicios requieren persistencia de datos, utilizaría soluciones de almacenamiento nativas para contenedores. Configuraría copias de seguridad entre regiones y políticas de instantáneas automatizadas para evitar la pérdida de datos.
Por último, la supervisión y el registro son esenciales para mantener una alta disponibilidad. Integraría Prometheus y Grafana para supervisar el rendimiento en tiempo real y utilizaría ELK Stack o AWS CloudWatch Logs para realizar un seguimiento del estado de las aplicaciones y detectar fallos de forma proactiva.
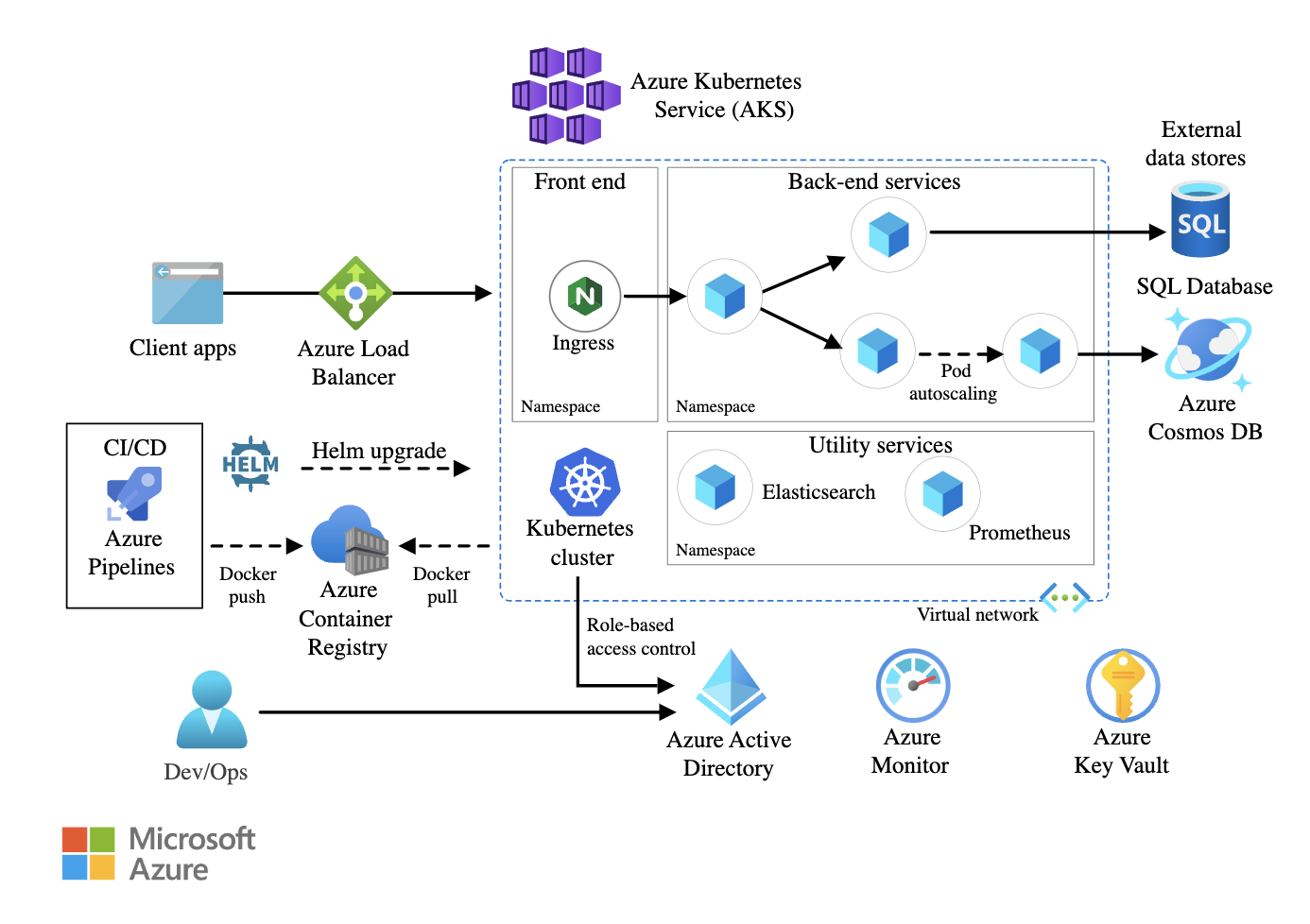
Ejemplo de una arquitectura de microservicios que utiliza Azure Kubernetes Service (AKS). Fuente de la imagen: Microsoft Learn
Ejemplo de respuesta:
Al detectar una brecha de seguridad, tu respuesta inmediata sería contener el incidente, identificar el vector de ataque y evitar que se siguiera explotando. En primer lugar, aislaría los sistemas afectados para limitar el daño revocando las credenciales IAM comprometidas, restringiendo el acceso a los recursos afectados y aplicando las reglas del grupo de seguridad.
El siguiente paso sería el análisis e investigación de los registros. Los registros de auditoría revelarían actividades sospechosas, como intentos de acceso no autorizados, escaladas de privilegios o llamadas API inesperadas. Si un atacante aprovechara una política de seguridad mal configurada, identificaría y corregiría la vulnerabilidad.
Para mitigar el impacto, rotaría las credenciales, revocaría las claves API comprometidas y aplicaría la autenticación multifactorial (MFA) para todas las cuentas con privilegios. Si la violación implicara la filtración de datos, analizaría los registros para rastrear el movimiento de datos y notificaría a las autoridades pertinentes si se viera afectado el cumplimiento normativo.
Una vez que se confirme la contención, llevaría a cabo una revisión posterior al incidente para reforzar las políticas de seguridad.
Ejemplo de respuesta:
Para diseñar una arquitectura de nuves, yo empezaría por un marco común de gestión de identidades y accesos (IAM), como Okta, AWS IAM Federation o Azure AD, con el fin de garantizar la autenticación entre nuves. Esto evitaría el control de acceso aislado y reduciría la proliferación de identidades.
Las redes son un reto clave en los entornos de nube múltiple. Utilizaría servicios de interconexión como AWS Transit Gateway, Azure Virtual WAN o Google Cloud Interconnect para facilitar una comunicación segura entre nubes. Además, implementaría una malla de servicios para estandarizar la gestión del tráfico y las políticas de seguridad.
La coherencia de los datos entre las nubes es otro factor crítico. Garantizaría la replicación entre nubes utilizando bases de datos globales como Spanner, Cosmos DB o AWS Aurora Global Database. Si las aplicaciones sensibles a la latencia requieren la localización de datos, utilizaría soluciones de computación periférica para reducir la transferencia de datos entre nubes.
Por último, el control de los costes y la gobernanza serían esenciales para evitar la expansión descontrolada de la nube. Mediante herramientas FinOps como CloudHealth, AWS Cost Explorer y Azure Cost Management, haría un seguimiento del gasto, aplicaría límites presupuestarios y optimizaría la asignación de recursos de forma dinámica.
Para prepararse para una entrevista de trabajo como ingeniero de nube, es necesario tener un conocimiento sólido de los fundamentos, la arquitectura, la seguridad y las mejores prácticas de la nube. Sigue explorando los servicios en la nube, mantente al día de las tendencias del sector y, lo más importante, adquiere experiencia práctica con AWS, Azure o GCP.
El programa AWS Cloud Practitioner es un excelente punto de partida si deseas obtener más información sobre AWS. Si eres nuevo en Microsoft Azure, el programa Fundamentos de Azure (AZ-900) te ayudará a adquirir una base sólida. Y para aquellos que quieran sumergirse en Google Cloud Platform (GCP), el curso Introducción a GCP es el punto de partida perfecto.
¡Buena suerte con tu entrevista!
¡Aprende más sobre la nube con estos cursos!
Curso
Curso
Curso