
Course
Understanding Cloud Computing
2 hr
234.6K
If you’re preparing for a cloud engineering interview, you’ve come to the right place. This article covers some of the most commonly asked questions to help you practice and build confidence. Whether you aim for a role in cloud engineering, DevOps, or MLOps, these questions will test your understanding of cloud concepts, architecture, and best practices.
To make this guide even more practical, I’ve included examples of services from the biggest cloud providers—AWS, Azure, and GCP—so you can see how different platforms approach cloud solutions. Let’s dive in!
These fundamental questions check your understanding of cloud computing concepts, services, and deployment models. Your interview will normally start with a few similar questions.
The three main cloud computing models are:
These are some of the most important benefits of cloud computing:
There are four main models:

Cloud deployment models. Image by Author.
Virtualization is the process of creating virtual instances of computing resources, such as servers, storage, and networks, on a single physical machine. It enables cloud computing by allowing efficient resource allocation, multi-tenancy, and scalability.
Technologies like Hyper-V, VMware, and KVM are commonly used for virtualization in cloud environments.
A cloud region is a geographically distinct area where cloud providers host multiple data centers. An availability zone (AZ) is a physically separate data center within a region designed to offer redundancy and high availability.
For example, AWS has multiple regions worldwide, each containing two or more AZs for disaster recovery and fault tolerance.
Here are the distinctions between these two concepts:
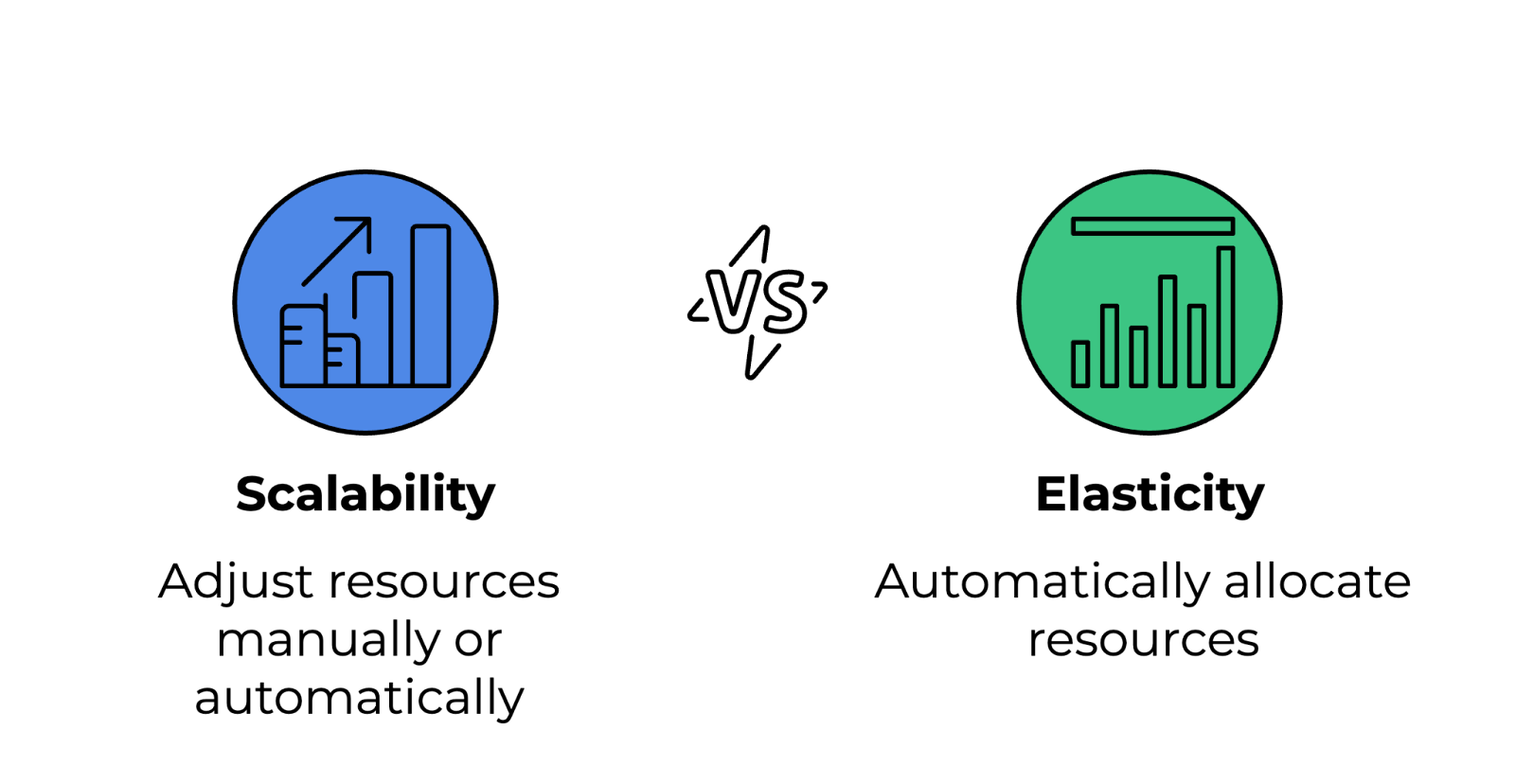
Difference between scalability and elasticity. Image by Author.
The following table lists the major cloud providers, their strengths, and use cases:
|
Cloud provider |
Strengths |
Use cases |
|
Amazon Web Services (AWS) |
Largest cloud provider with a vast range of services. |
General-purpose cloud computing, serverless, DevOps. |
|
Microsoft Azure |
Strong in enterprise and hybrid cloud solutions. |
Enterprise applications, hybrid cloud, Microsoft ecosystem integration. |
|
Google Cloud Platform (GCP) |
Specializes in big data, AI/ML, and Kubernetes. |
Machine learning, data analytics, container orchestration. |
|
IBM Cloud |
Focuses on AI and enterprise cloud solutions. |
AI-driven applications, enterprise cloud transformation. |
|
Oracle Cloud |
Strong in databases and enterprise applications. |
Database management, ERP applications, enterprise workloads. |
Serverless computing is a cloud execution model where the cloud provider manages infrastructure automatically, allowing developers to focus on writing code. Users only pay for actual execution time rather than provisioning fixed resources. Examples include:
Object storage is a data storage architecture where files are stored as discrete objects within a flat namespace instead of hierarchical file systems. It is highly scalable and used for unstructured data, backups, and multimedia storage. Examples include:
A CDN is a network of distributed servers that cache and deliver content (e.g., images, videos, web pages) to users based on their geographic location. This reduces latency, improves website performance, and enhances availability. Popular CDNs include:
These questions dive deeper into cloud networking, security, automation, and performance optimization, testing your ability to effectively design, manage, and troubleshoot cloud environments.
A virtual private cloud (VPC) is a logically isolated section of a public cloud that allows users to launch resources in a private network environment. It provides greater control over networking configurations, security policies, and access management.
In a VPC, users can define IP address ranges using CIDR blocks. Subnets can be created to separate public and private resources, and security groups and network ACLs help enforce network access policies.
Load balancers distribute incoming network traffic across multiple servers to ensure high availability, fault tolerance, and better performance.
There are different types of load balancers:
IAM is a framework that controls who can access cloud resources and what actions they can perform. It helps enforce the principle of least privilege and secures cloud environments.
In IAM, users and roles define identities with specific permissions, policies grant or deny access using JSON-based rules, and multi-factor authentication (MFA) adds an extra security layer for critical operations.
Security groups and network ACLs (access control lists) control inbound and outbound traffic to cloud resources but function at different levels.
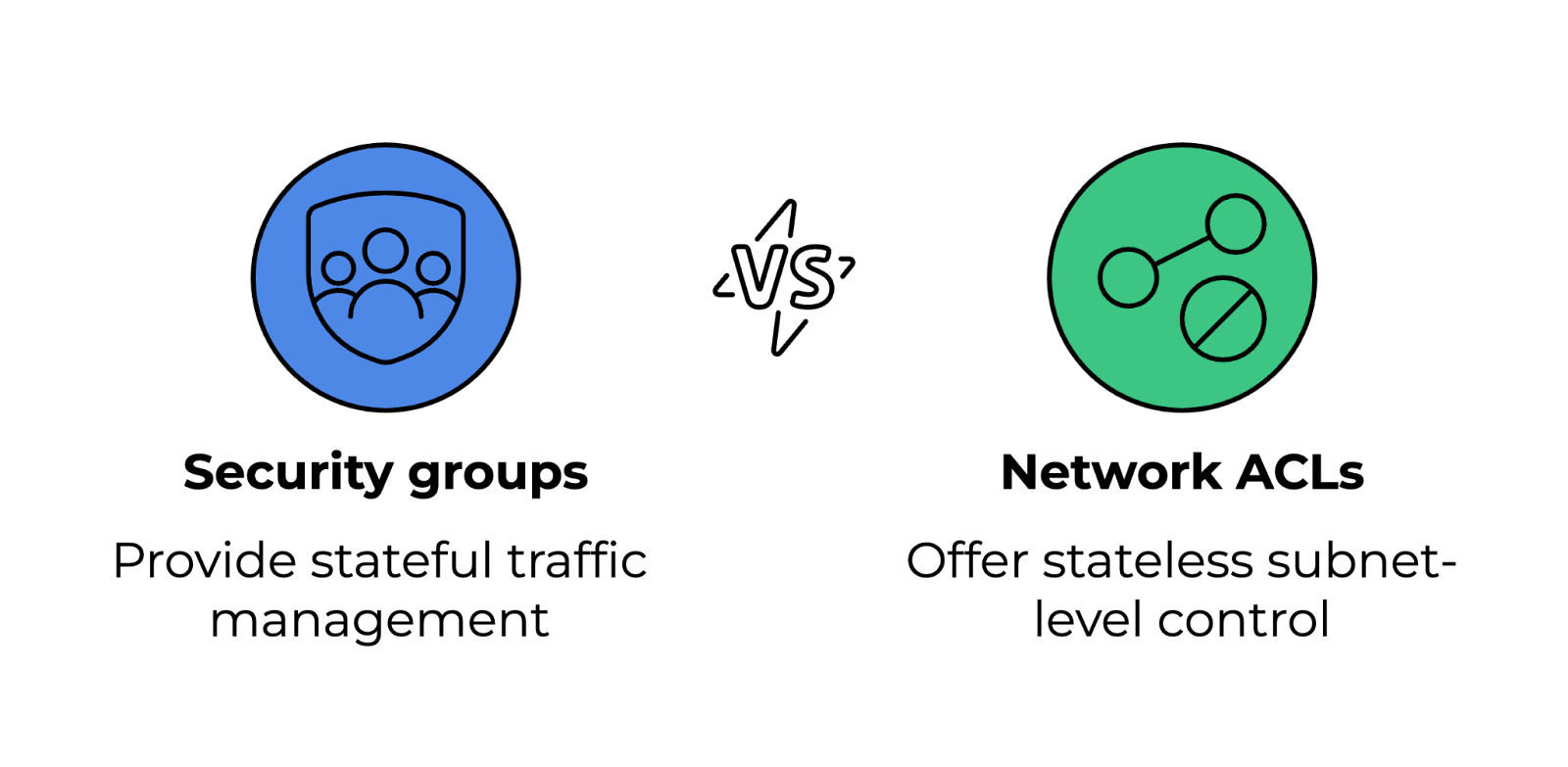
Comparing security groups and network ACLs. Image by Author.
A bastion host is a secure jump server for accessing cloud resources in a private network. Instead of exposing all servers to the internet, it acts as a gateway for remote connections.
To enhance security, it should have strict firewall rules, allowing SSH or RDP access only from trusted IPs. Multi-factor authentication (MFA) and key-based authentication should be used for secure access, and logging and monitoring should be enabled to track unauthorized login attempts.
Autoscaling allows cloud environments to dynamically adjust resources based on demand, ensuring cost efficiency and performance. It works in two ways:
Cloud providers offer autoscaling groups, which work with load balancers to distribute traffic effectively.
Managing cloud costs effectively requires monitoring usage and selecting the right pricing models. Cost optimization strategies include:
Want to master AWS security and optimize cloud costs? Check out the AWS Security and Cost Management course to learn essential best practices.

Optimizing cloud costs four pillars. Image by Author.
Terraform and AWS CloudFormation are both infrastructure-as-code (IaC) tools, but they have some differences:
|
Feature |
Terraform |
AWS CloudFormation |
|
Cloud support |
Cloud-agnostic, supports AWS, Azure, GCP, and others. |
AWS-specific, designed exclusively for AWS resources. |
|
Configuration language |
Uses HashiCorp configuration language (HCL). |
Uses JSON/YAML templates. |
|
State management |
Maintains a state file to track infrastructure changes. |
Uses stacks to manage and track deployments. |
Monitoring tools help detect performance bottlenecks, security threats, and resource overuse. Common monitoring solutions include:
Containers package applications with dependencies, making them lightweight, portable, and scalable. Compared to virtual machines, containers use fewer resources since multiple containers can run on a single OS.
Docker and Kubernetes allow faster deployment and rollback. Additionally, they scale easily with orchestration tools like Kubernetes and Amazon ECS/EKS.
Looking to sharpen your containerization skills? The Containerization and Virtualization track covers Docker, Kubernetes, and more to help you build scalable cloud applications.
A service mesh is an infrastructure layer that manages service-to-service communication in microservices-based cloud applications. It provides:
Popular service mesh solutions include Istio, Linkerd, and AWS App Mesh.
A multi-cloud strategy involves using multiple cloud providers (AWS, Azure, GCP) to avoid vendor lock-in and improve resilience.
Companies choose this approach when they need geographic redundancy for disaster recovery, want to leverage unique services from different providers (e.g., AWS for compute, GCP for AI), or require compliance with regional regulations that restrict cloud provider choices.

Multi-cloud strategy pros and cons. Image by Author.
These questions test your ability to design scalable solutions, manage complex cloud infrastructures, and handle critical scenarios.
A multi-region architecture ensures minimal downtime and business continuity by distributing resources across multiple geographic locations.
When designing such an architecture, several factors must be considered. These are some of them:
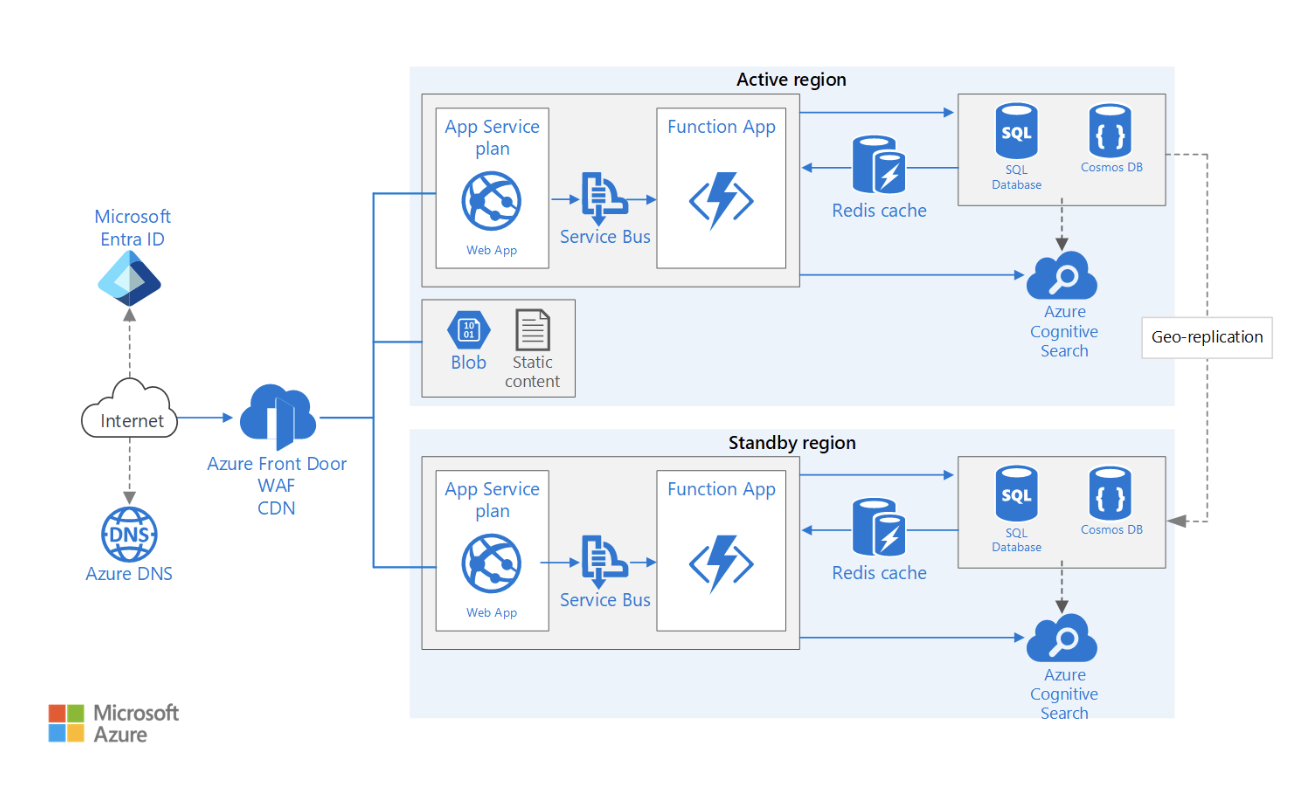
Highly available multi-region web application architecture example. Image source: Microsoft Learn
The zero trust model assumes no entity, whether inside or outside the network, should be trusted by default.
To implement zero trust in cloud environments:
A successful strategy starts with cost allocation and tagging, where organizations enforce structured tagging (e.g., department, project, owner) to track spending across teams and improve financial visibility.
Automated budget alerts should be set up using tools like AWS Budgets, Azure Cost Management, or GCP Billing Alerts to prevent unexpected expenses. These solutions provide real-time monitoring and notifications when usage approaches predefined thresholds.
Another aspect is rightsizing and reserved instances. By continuously analyzing instance utilization metrics such as CPU and memory, teams can determine whether workloads should be adjusted or migrated to reserved instances or spot instances, which offer significant cost savings.
Implementing FinOps best practices further enhances cost efficiency. Automated cost anomaly detection tools like Kubecost (for Kubernetes environments) and AWS Compute Optimizer help proactively identify underutilized resources and optimize them.
Finally, auto-shutdown policies play an essential role in reducing waste. Serverless functions, such as AWS Lambda or Azure Functions, can automatically shut down underutilized resources outside business hours, preventing unnecessary expenses.
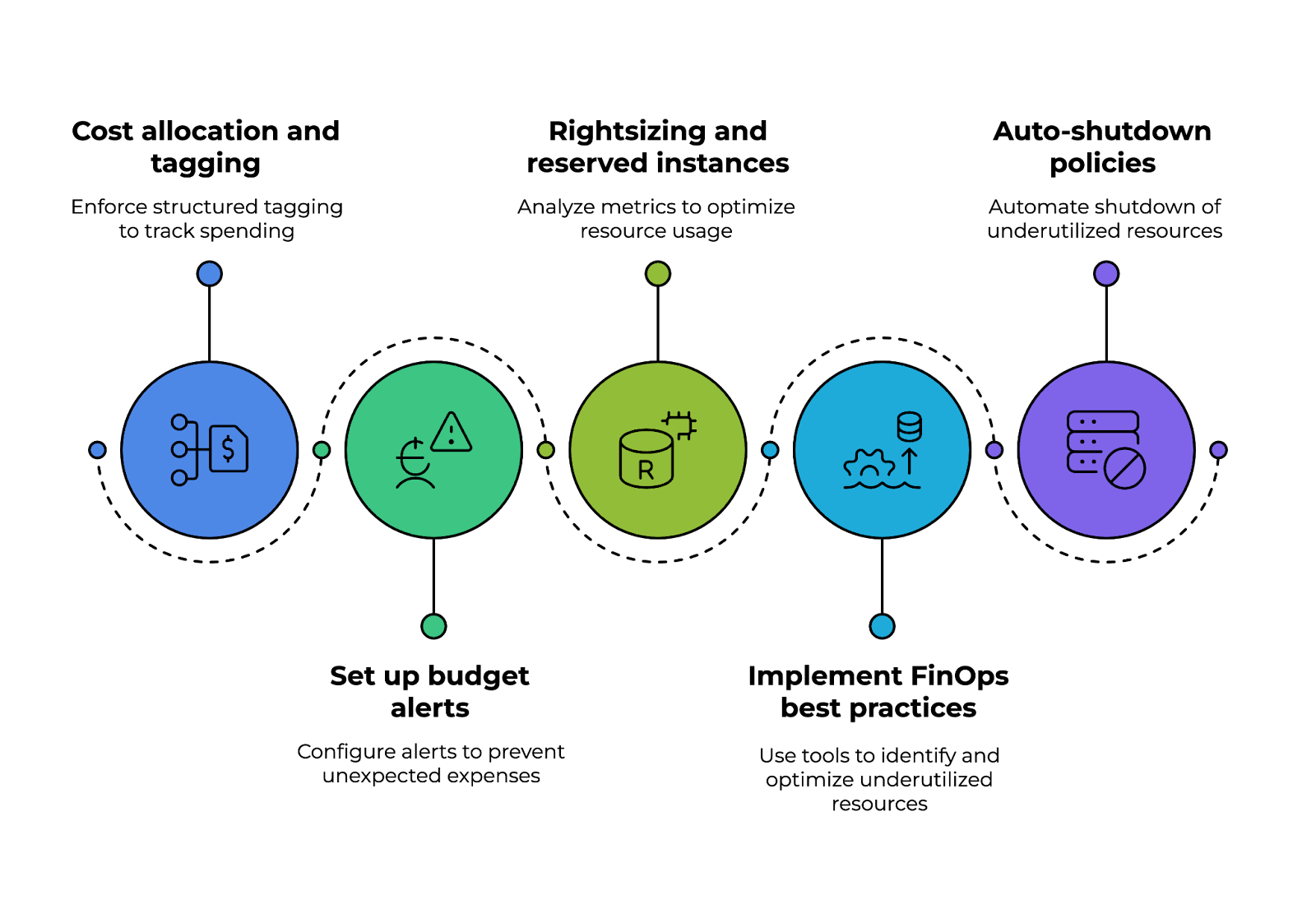
Cloud cost governance strategy implementation pillars. Image by Author.
A data lake requires efficient storage, retrieval, and processing of petabyte-scale data. Some optimization strategies include:
One of the foundational aspects of a CI/CD pipeline is code versioning and repository management, which enables efficient collaboration and change tracking. Tools like GitHub Actions, AWS CodeCommit, or Azure Repos help manage source code, enforce branching strategies, and streamline pull request workflows.
Build automation and artifact management play crucial roles in maintaining consistency and reliability in software builds. Using Docker-based builds, JFrog Artifactory, or AWS CodeArtifact, teams can create reproducible builds, store artifacts securely, and ensure version control across development environments.
Security is another critical consideration. Integrating SAST (static application security testing) tools, such as SonarQube or Snyk, allows early detection of vulnerabilities in the codebase. Additionally, enforcing signed container images ensures that only verified and trusted artifacts are deployed.
A robust multi-stage deployment strategy helps minimize risks associated with software releases. Approaches like canary, blue-green, or rolling deployments enable gradual rollouts, reducing downtime and allowing real-time performance monitoring. Using feature flags, teams can control which users experience new features before a full release.
Finally, Infrastructure as Code (IaC) integration is essential for automating and standardizing cloud environments. By using Terraform, AWS CloudFormation, or Pulumi, teams can define infrastructure in code, maintain consistency across deployments, and enable the provisioning of cloud resources.
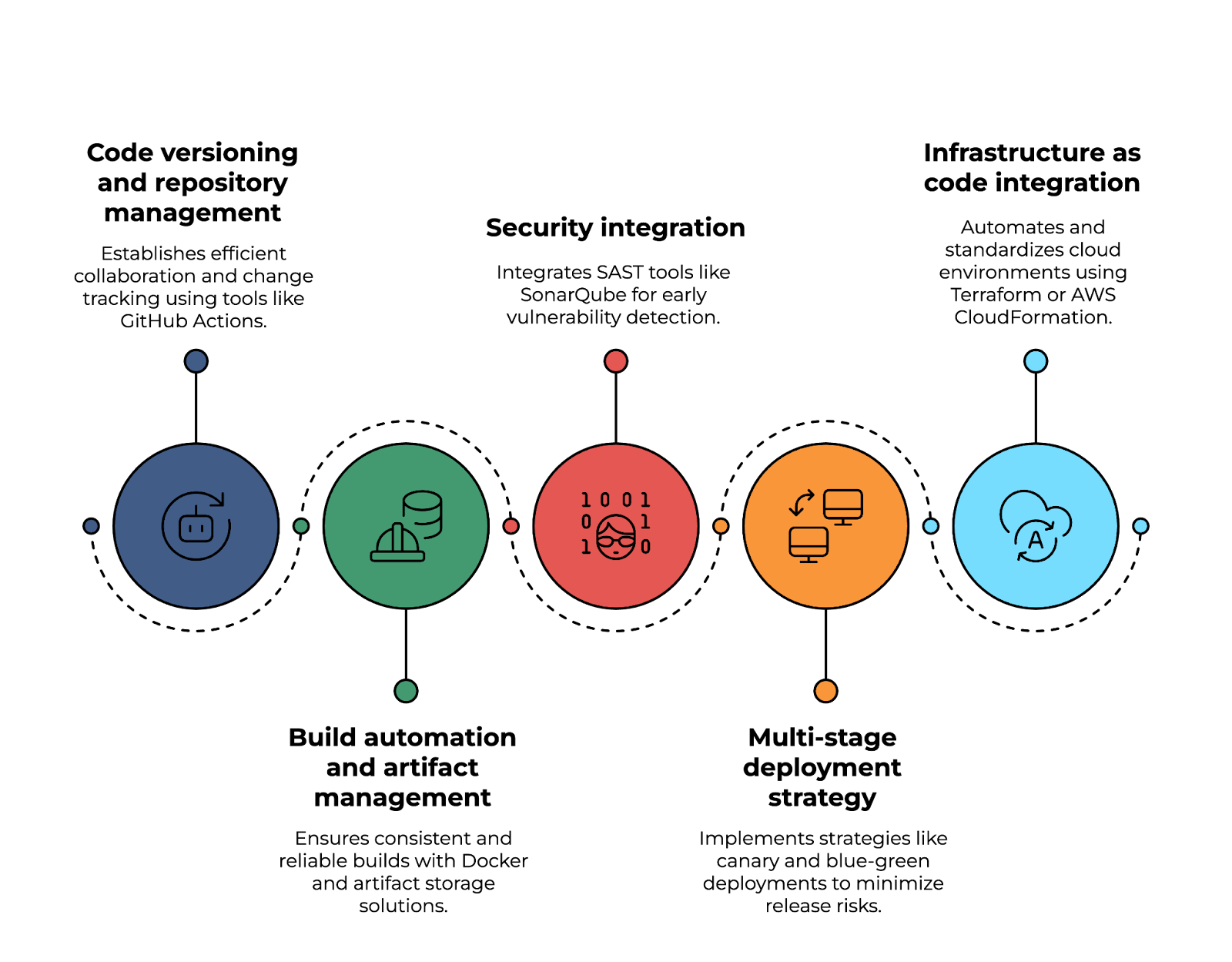
Implementing a cloud-native CI/CD pipeline. Image by Author.
Disaster recovery (DR) is essential for ensuring business continuity in case of outages, attacks, or hardware failures. A strong DR plan includes the following:
Managing large-scale Kubernetes (K8s) clusters presents operational and performance challenges. Key areas to address include:
Scenario-based questions evaluate your ability to analyze real-world cloud challenges, troubleshoot issues, and make architectural decisions under different constraints.
Your responses should demonstrate practical experience, decision-making, and trade-offs when solving cloud problems. Since there are no right or wrong answers, I included some examples to guide your thinking process.
Example answer:
High latency in a cloud application can be caused by several factors, including network congestion, inefficient database queries, suboptimal instance placement, or load balancing misconfigurations.
To diagnose the issue, I would start by isolating the bottleneck using cloud monitoring tools. The first step would be to analyze the application response times and network latency by checking logs, request-response times, and HTTP status codes. If the issue is network-related, I would use a traceroute or ping test to check for increased round-trip times between users and the application. If a problem exists, enabling a CDN could help cache static content closer to users and reduce latency.
If the database queries are causing delays, I would profile slow queries and optimize them by adding proper indexing or denormalizing tables. Additionally, if the application is under high traffic, enabling horizontal scaling with autoscaling groups or read replicas can reduce the load on the primary database.
If latency issues persist, I would check the application's compute resources, ensuring it runs in the correct availability zone closest to end users. If necessary, I would migrate workloads to a multi-region setup or use edge computing solutions to process requests closer to the source.
Example answer:
The first step is to conduct a cloud readiness assessment, evaluating whether the application can be migrated as-is or requires modifications. One approach is to use the “6 R’s of cloud migration”:
A lift-and-shift approach would be ideal if the goal is a quick migration with minimal changes. If performance optimization and cost efficiency are priorities, I would consider re-platforming by moving the application to containers or serverless computing, allowing better scalability. For applications with monolithic architectures, refactoring into microservices may be necessary to enhance performance and maintainability.
I would also focus on data migration, ensuring that databases are replicated to the cloud with minimal downtime.
Security and compliance would be another major concern. Before deployment, I would ensure that the application meets regulatory requirements (e.g., HIPAA, GDPR) by implementing encryption, IAM policies, and VPC isolation.
Finally, I would perform testing and validation in a staging environment before switching over production traffic.
Example answer:
At the infrastructure level, I would deploy the Kubernetes cluster across multiple availability zones (AZs). This ensures that traffic can be routed to another zone if one AZ goes down. I would use Kubernetes Federation to manage multi-cluster deployments for on-prem or hybrid setups.
Within the cluster, I would implement pod-level resilience by setting up ReplicaSets and horizontal pod autoscalers (HPA) to scale workloads dynamically based on CPU/memory utilization. Additionally, pod disruption budgets (PDBs) would ensure that a minimum number of pods remain available during updates or maintenance.
For networking, I would use a service mesh to manage service-to-service communication, enforcing retries, circuit breaking, and traffic shaping policies. A global load balancer would distribute external traffic efficiently across multiple regions.
Persistent storage is another critical aspect. If the microservices require data persistence, I would use container-native storage solutions. I would configure cross-region backups and automated snapshot policies to prevent data loss.
Finally, monitoring and logging are essential for maintaining high availability. I would integrate Prometheus and Grafana for real-time performance monitoring and use ELK stack or AWS CloudWatch Logs to track application health and detect failures proactively.
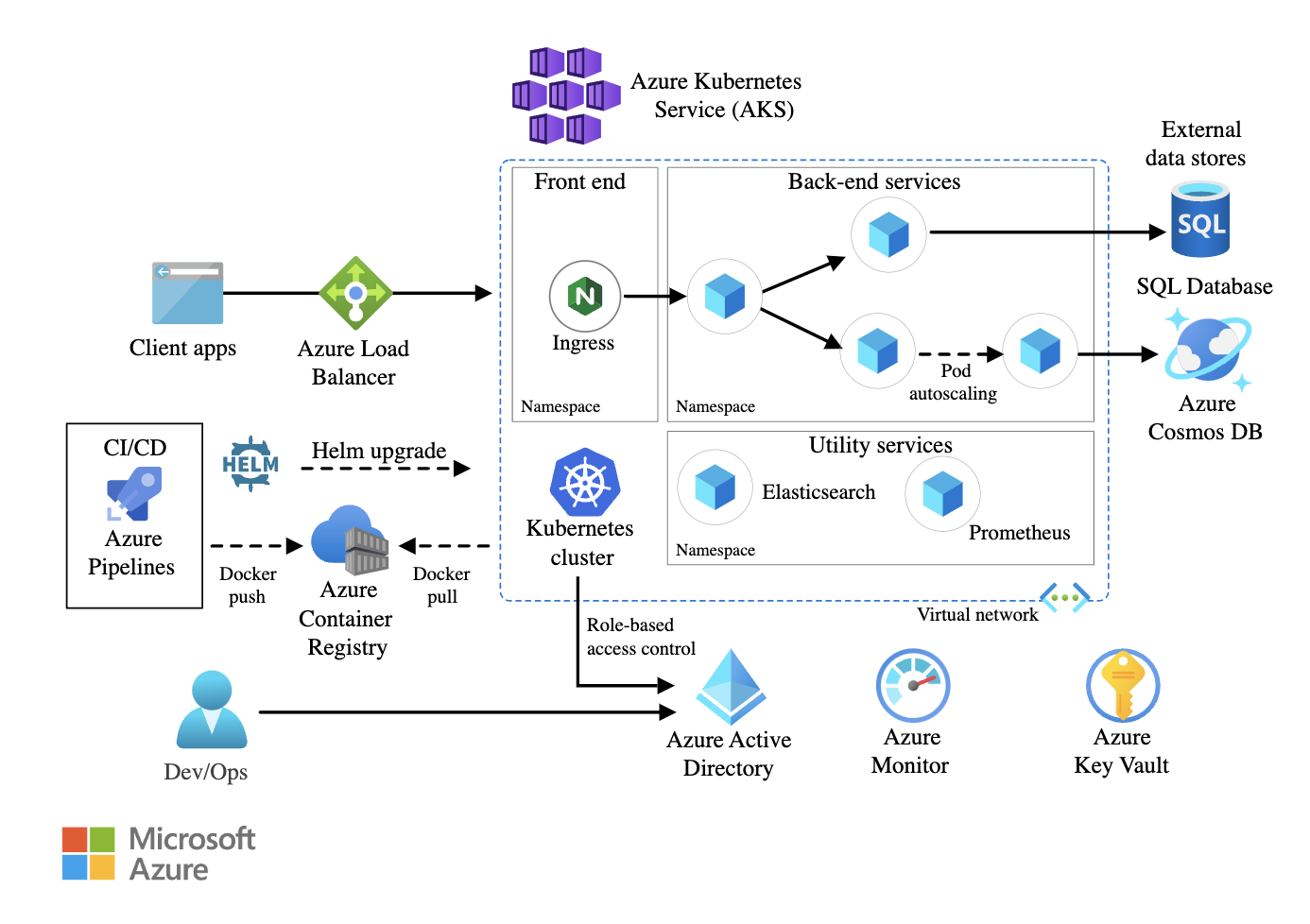
Example of a microservices architecture using Azure Kubernetes Service (AKS). Image source: Microsoft Learn
Example answer:
Upon detecting a security breach, my immediate response would be to contain the incident, identify the attack vector, and prevent further exploitation. I would first isolate the affected systems to limit the damage by revoking compromised IAM credentials, restricting access to the affected resources, and enforcing security group rules.
The next step would be log analysis and investigation. Audit logs would reveal suspicious activities such as unauthorized access attempts, privilege escalations, or unexpected API calls. If an attacker exploited a misconfigured security policy, I would identify and patch the vulnerability.
To mitigate the impact, I would rotate credentials, revoke compromised API keys, and enforce MFA for all privileged accounts. If the breach involved data exfiltration, I would analyze logs to trace data movement and notify relevant authorities if regulatory compliance was affected.
Once containment is confirmed, I would conduct a post-incident review to strengthen security policies.
Example answer:
To design a multi-cloud architecture, I would start with a common identity and access management (IAM) framework, such as Okta, AWS IAM Federation, or Azure AD, to ensure authentication across clouds. This would prevent siloed access control and reduce identity sprawl.
Networking is a key challenge in multi-cloud environments. I would use interconnect services like AWS Transit Gateway, Azure Virtual WAN, or Google Cloud Interconnect to facilitate secure cross-cloud communication. Additionally, I would implement a service mesh to standardize traffic management and security policies.
Data consistency across clouds is another critical factor. I would ensure cross-cloud replication using global databases like Spanner, Cosmos DB, or AWS Aurora Global Database. If latency-sensitive applications require data locality, I would use edge computing solutions to reduce inter-cloud data transfer.
Finally, cost monitoring and governance would be essential to prevent cloud sprawl. Using FinOps tools like CloudHealth, AWS Cost Explorer, and Azure Cost Management, I would track spending, enforce budget limits, and optimize resource allocation dynamically.
Preparing for a cloud engineer interview requires a solid understanding of cloud fundamentals, architecture, security, and best practices. Keep exploring cloud services, stay updated with industry trends, and, most importantly, get hands-on experience with AWS, Azure, or GCP.
The AWS Cloud Practitioner track is a great place to start if you want to know more about AWS. If you're new to Microsoft Azure, the Azure Fundamentals (AZ-900) track will help you build a strong foundation. And for those looking to dive into Google Cloud Platform (GCP), the Introduction to GCP course is the perfect starting point.
Good luck with your interview!
Learn more about cloud computing with these courses!
Course
Course
Course
blog
Marie Fayard
15 min
blog
Zoumana Keita
15 min
blog
Laiba Siddiqui
15 min
blog
Kurtis Pykes
15 min
blog
Marie Fayard
12 min
blog
Josep Ferrer
15 min