
Kurs
Cloud Computing verstehen
2 Std.
234.6K
Wenn du dich auf ein Vorstellungsgespräch im Bereich Cloud Engineering vorbereitest, bist du hier genau richtig. Dieser Artikel geht auf ein paar der häufigsten Fragen ein, um dir beim Üben zu helfen und dein Selbstvertrauen zu stärken. Egal, ob du eine Stelle im Bereich Cloud-Engineering, DevOps oder MLOps anstrebst, diese Fragen testen dein Verständnis von Cloud-Konzepten, Architektur und Best Practices.
Um diesen Leitfaden noch praktischer zu machen, habe ich Beispiele für Dienste der größten Cloud-Anbieter – AWS, Azure und GCP – aufgenommen, damit du sehen kannst, wie verschiedene Plattformen Cloud-Lösungen angehen. Los geht's!
Diese grundlegenden Fragen testen, ob du die Konzepte, Dienste und Bereitstellungsmodelle der Cloud verstehst. Dein Vorstellungsgespräch fängt normalerweise mit ein paar ähnlichen Fragen an.
Die drei wichtigsten Cloud-Computing-Modelle sind:
Hier sind ein paar der wichtigsten Vorteile von Cloud:
Es gibt vier Hauptmodelle:

Cloud-Bereitstellungsmodelle. Bild vom Autor.
Virtualisierung ist der Prozess, bei dem virtuelle Instanzen von Computerressourcen wie Servern, Speichern und Netzwerken auf einem einzigen physischen Rechner erstellt werden. Es macht Cloud möglich, indem es eine effiziente Ressourcenzuteilung, Multi-Tenancy und Skalierbarkeit ermöglicht.
Technologien wie Hyper-V, VMware und KVM werden oft für die Virtualisierung in Cloud-Umgebungen genutzt.
Eine Cloud-Region ist ein bestimmter geografischer Bereich, in dem Cloud-Anbieter mehrere Rechenzentren haben. Eine Verfügbarkeitszone (AZ) ist ein physisch separates Rechenzentrum innerhalb einer Region, das Redundanz und hohe Verfügbarkeit bieten soll.
Zum Beispiel hat AWS mehrere Regionen auf der ganzen Welt, von denen jede zwei oder mehr AZs für Disaster Recovery und Fehlertoleranz hat.
Hier sind die Unterschiede zwischen diesen beiden Konzepten:
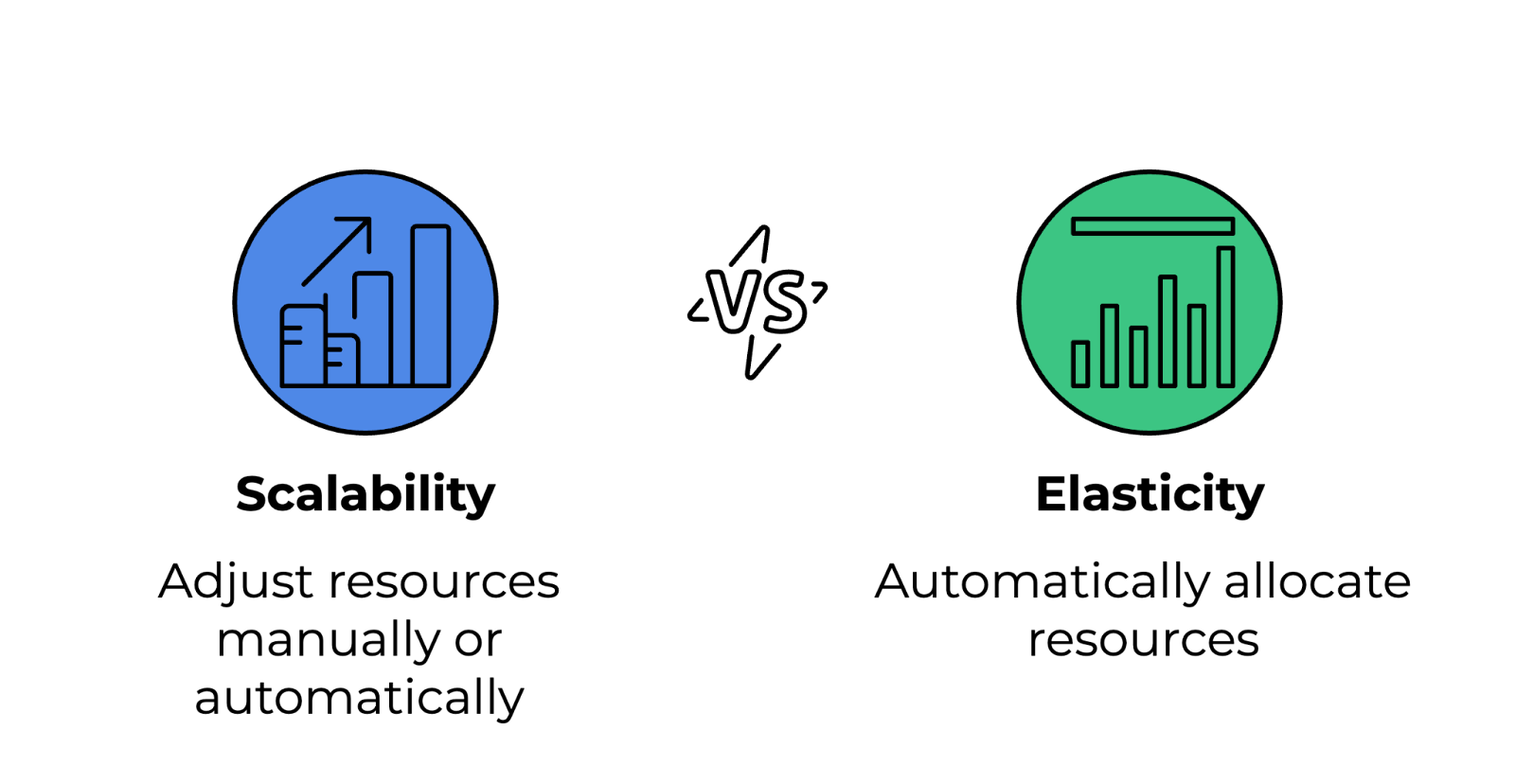
Unterschied zwischen Skalierbarkeit und Elastizität. Bild vom Autor.
Die folgende Tabelle zeigt die wichtigsten Cloud-Anbieter, ihre Stärken und Anwendungsfälle:
|
Cloud-Anbieter |
Stärken |
Anwendungsfälle |
|
Amazon Web Services (AWS) |
Die größte Cloud mit einer riesigen Auswahl an Services. |
Allgemeines Cloud Computing, Serverless, DevOps. |
|
Microsoft Azure |
Wir sind echt gut in Unternehmens- und Hybrid-Cloud-Lösungen. |
Unternehmensanwendungen, Hybrid Cloud, Integration in das Microsoft-Ökosystem. |
|
Google Cloud Platform (GCP) |
Spezialisiert auf Big Data, KI/ML und Kubernetes. |
Maschinelles Lernen, Datenanalyse, Container-Orchestrierung. |
|
IBM Cloud |
Konzentriert sich auf KI und Cloud-Lösungen für Unternehmen. |
KI-gesteuerte Anwendungen, Cloud-Transformation für Unternehmen. |
|
Oracle Cloud |
Gut in Datenbanken und Unternehmensanwendungen. |
Datenbankverwaltung, ERP-Anwendungen, Unternehmens-Workloads. |
Serverless Computing ist ein Cloud-Ausführungsmodell, bei dem der Cloud-Anbieter die Infrastruktur automatisch verwaltet, sodass sich Entwickler ganz aufs Schreiben von Code konzentrieren können. Die Nutzer zahlen nur für die tatsächliche Ausführungszeit und nicht für die Bereitstellung fester Ressourcen. Beispiele sind:
Objektspeicherung ist eine Art von Datenspeicher, bei der Dateien als einzelne Objekte in einem flachen Namensraum statt in hierarchischen Dateisystemen gespeichert werden. Es ist super skalierbar und wird für unstrukturierte Daten, Backups und Multimedia-Speicher genutzt. Beispiele sind:
Ein CDN ist ein Netzwerk von Servern, die Inhalte (wie Bilder, Videos, Webseiten) zwischenspeichern und an Nutzer je nach ihrem Standort liefern. Das verringert die Latenz, macht die Website schneller und sorgt für mehr Verfügbarkeit. Beliebte CDNs sind:
Diese Fragen gehen genauer auf Cloud-Netzwerke, Sicherheit, Automatisierung und Leistungsoptimierung ein und testen, wie gut du Cloud-Umgebungen effektiv entwerfen, verwalten und Fehler beheben kannst.
Eine virtuelle private Cloud (VPC) ist ein logisch abgegrenzter Teil einer öffentlichen Cloud, der es Leuten ermöglicht, Ressourcen in einer privaten Netzwerkumgebung zu starten. Es gibt dir mehr Kontrolle über Netzwerkkonfigurationen, Sicherheitsrichtlinien und die Zugriffsverwaltung.
In einer VPC können Nutzer IP-Adressbereiche mit CIDR-Blöcken festlegen. Man kann Subnetze einrichten, um öffentliche und private Ressourcen zu trennen, und Sicherheitsgruppen und Netzwerk-ACLs helfen dabei, die Netzwerkzugriffsrichtlinien durchzusetzen.
Load Balancer verteilen den eingehenden Netzwerkverkehr auf mehrere Server, um hohe Verfügbarkeit, Fehlertoleranz und bessere Leistung zu gewährleisten.
Es gibt verschiedene Arten von Load Balancern:
IAM ist ein System, das regelt, wer auf Cloud-Ressourcen zugreifen darf und was man dort machen kann. Es hilft dabei, das Prinzip der geringsten Privilegien durchzusetzen und Cloud-Umgebungen sicher zu machen.
Bei IAM legen Benutzer und Rollen Identitäten mit bestimmten Berechtigungen fest, Richtlinien erlauben oder verweigern den Zugriff anhand von JSON-basierten Regeln, und die Multi-Faktor-Authentifizierung (MFA) sorgt für eine zusätzliche Sicherheitsebene bei wichtigen Vorgängen.
Sicherheitsgruppen und Netzwerk-ACLs (Zugriffskontrolllisten) regeln den ein- und ausgehenden Datenverkehr zu Cloud-Ressourcen, arbeiten aber auf verschiedenen Ebenen.
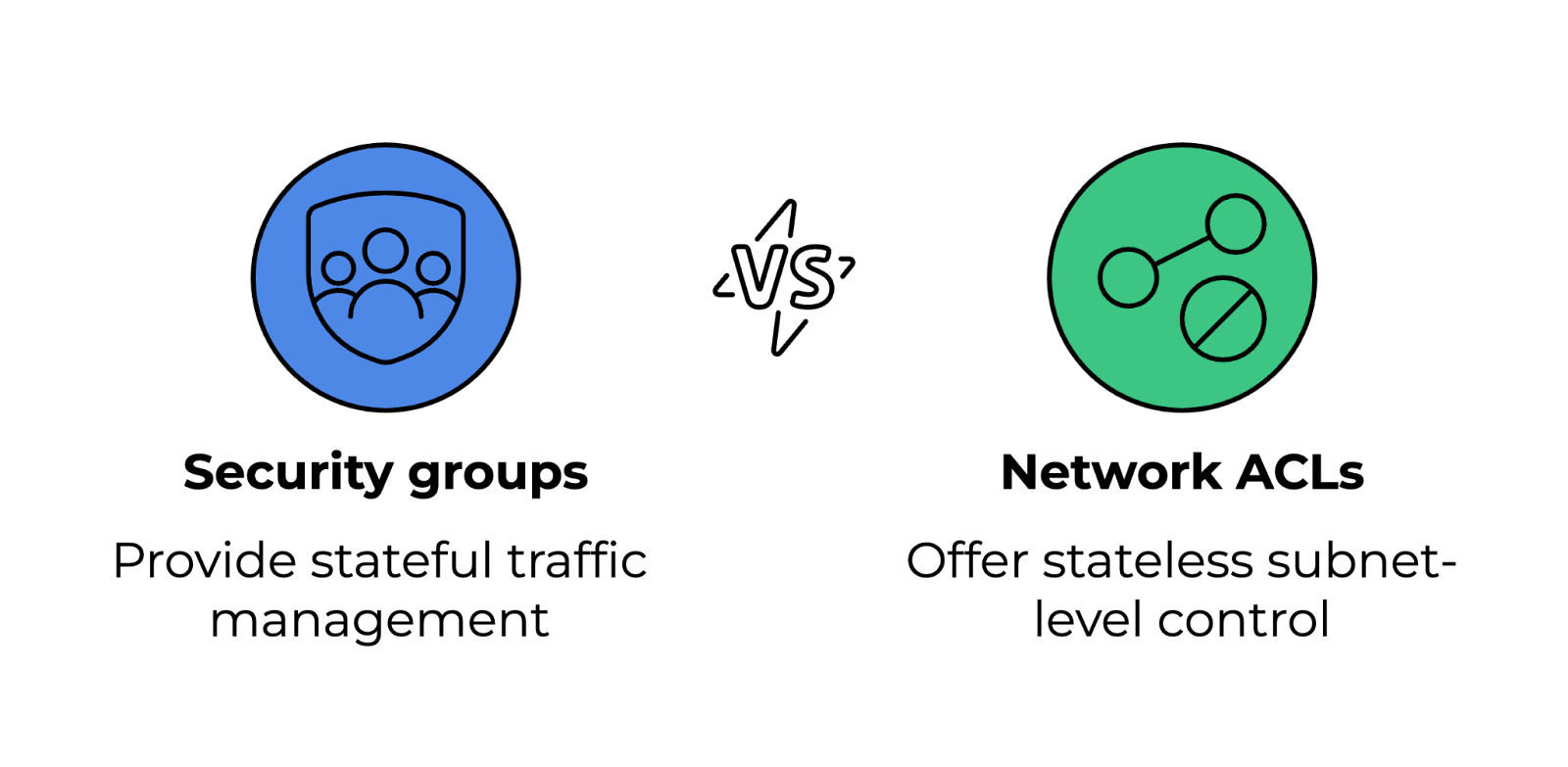
Sicherheitsgruppen und Netzwerk-ACLs vergleichen. Bild vom Autor.
Ein Bastion-Host ist ein sicherer Jump-Server, mit dem man in einem privaten Netzwerk auf Cloud-Ressourcen zugreifen kann. Anstatt alle Server dem Internet auszusetzen, fungiert es als Gateway für Fernverbindungen.
Um die Sicherheit zu verbessern, sollte es strenge Firewall-Regeln geben, die SSH- oder RDP-Zugriff nur von vertrauenswürdigen IP-Adressen zulassen. Für einen sicheren Zugang sollte man Multi-Faktor-Authentifizierung (MFA) und schlüsselbasierte Authentifizierung nutzen. Außerdem sollte man Protokollierung und Überwachung aktivieren, um unbefugte Anmeldeversuche zu verfolgen.
Mit der automatischen Skalierung können Cloud-Umgebungen ihre Ressourcen je nach Bedarf dynamisch anpassen, was für Kosteneffizienz und Leistung sorgt. Es funktioniert auf zwei Arten:
Cloud-Anbieter haben Autoscaling-Gruppen, die zusammen mit Load Balancern den Datenverkehr gut verteilen.
Um die Kosten der Cloud gut im Griff zu haben, muss man die Nutzung im Auge behalten und die richtigen Preismodelle auswählen. Strategien zur Kostenoptimierung umfassen:
Willst du AWS-Sicherheit meistern und Cloud-Kosten optimieren? Schau dir den Kurs „AWS Security and Cost Management“ an, um wichtige Best Practices zu lernen.

Vier wichtige Punkte, um die Cloud-Kosten zu optimieren. Bild vom Autor.
Terraform und AWS CloudFormation sind beide Infrastructure-as-Code-Tools (IaC), aber es gibt ein paar Unterschiede:
|
Feature |
Terraform |
AWS CloudFormation |
|
Cloud-Support |
Cloud-unabhängig, funktioniert mit AWS, Azure, GCP und anderen. |
Speziell für AWS entwickelt, nur für AWS-Ressourcen. |
|
Konfigurationssprache |
Verwendet die HashiCorp-Konfigurationssprache (HCL). |
Verwendet JSON/YAML-Vorlagen. |
|
Staatsverwaltung |
Verwalte eine Statusdatei, um Änderungen an der Infrastruktur zu verfolgen. |
Nutzt Stacks, um Bereitstellungen zu verwalten und zu verfolgen. |
Überwachungs-Tools helfen dabei, Leistungsengpässe, Sicherheitsrisiken und übermäßigen Ressourcenverbrauch zu erkennen. Zu den gängigen Überwachungslösungen gehören:
Container packen Anwendungen mit Abhängigkeiten, wodurch sie leicht, portabel und skalierbar sind. Im Vergleich zu virtuellen Maschinen brauchen Container weniger Ressourcen, weil mehrere Container auf einem einzigen Betriebssystem laufen können.
Docker und Kubernetes machen die Bereitstellung und das Zurücksetzen schneller. Außerdem lassen sie sich mit Orchestrierungstools wie Kubernetes und Amazon ECS/EKS ganz einfach skalieren.
Willst du deine Containerisierungskenntnisse verbessern? TDer Track „Containerisierung und Virtualisierung” behandeltDocker, Kubernetes und mehr, um dir beim Aufbau skalierbarer Cloud-Anwendungen zu helfen.
Ein Service Mesh ist eine Infrastruktur-Schicht, die die Kommunikation zwischen Services in Cloud-Anwendungen mit Microservices regelt. Es bietet:
Beliebte Service-Mesh-Lösungen sind Istio, Linkerd und AWS App Mesh.
Bei einer Multi-Cloud-Strategie nutzt man mehrere Cloud-Anbieter (AWS, Azure, GCP), um sich nicht an einen Anbieter zu binden und die Ausfallsicherheit zu verbessern.
Unternehmen entscheiden sich für diesen Ansatz, wenn sie geografische Redundanz für die Notfallwiederherstellung brauchen, einzigartige Dienste von verschiedenen Anbietern nutzen wollen (z. B. AWS für Rechenleistung, GCP für KI) oder regionale Vorschriften einhalten müssen, die die Auswahl an Cloud-Anbietern einschränken.

Vor- und Nachteile einer Multi-Cloud-Strategie. Bild vom Autor.
Diese Fragen testen deine Fähigkeit, skalierbare Lösungen zu entwickeln, komplexe Cloud-Infrastrukturen zu verwalten und mit kritischen Szenarien umzugehen.
Eine Architektur mit mehreren Regionen sorgt für minimale Ausfallzeiten und Geschäftskontinuität, indem sie die Ressourcen auf mehrere Standorte verteilt.
Beim Entwurf einer solchen Architektur müssen mehrere Faktoren berücksichtigt werden. Hier sind ein paar davon:
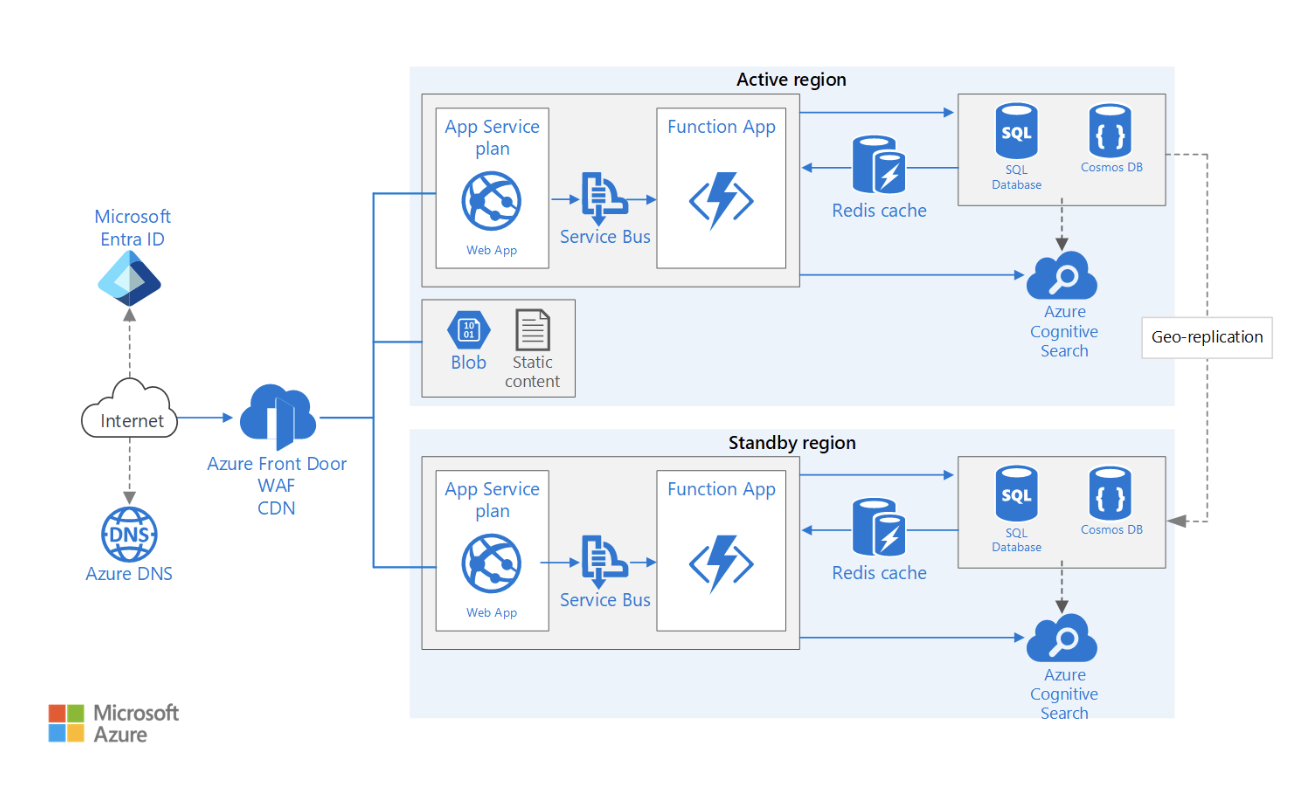
Beispiel für eine hochverfügbare Webanwendungsarchitektur in mehreren Regionen. Bildquelle: Microsoft Lernen
Das Zero-Trust-Modell geht davon aus, dass man grundsätzlich keiner Instanz innerhalb oder außerhalb des Netzwerks vertrauen sollte.
So setzt man Zero Trust in Cloud-Umgebungen um:
Eine gute Strategie fängt mit Kostenverteilung und -kennzeichnung, bei der Unternehmen strukturierte Kennzeichnungen (z. B. Abteilung, Projekt, Eigentümer) verwenden, um die Ausgaben aller Teams zu verfolgen und die finanzielle Transparenz zu verbessern.
Automatische Budgetwarnungen sollten mit Tools wie AWS Budgets, Azure Cost Management oder GCP Billing Alerts eingerichtet werden, um unerwartete Ausgaben zu vermeiden. Diese Lösungen bieten Echtzeitüberwachung und Benachrichtigungen, wenn die Nutzung bestimmte Schwellenwerte erreicht.
Ein weiterer Punkt ist die richtige Dimensionierung und reservierte Instanzen. Durch die ständige Analyse von Nutzungsdaten wie CPU und Speicher können Teams entscheiden, ob Workloads angepasst oder auf reservierte Instanzen oder Spot-Instanzen verschoben werden sollten, was echt viel Geld sparen kann.
Die Umsetzung von FinOps-Best-Practices macht die Kosteneffizienz noch besser. Automatisierte Tools zur Erkennung von Kostenanomalien wie Kubecost (für Kubernetes-Umgebungen) und AWS Compute Optimizer helfen dabei, nicht ausgelastete Ressourcen proaktiv zu identifizieren und zu optimieren.
Schließlich sindRichtlinien zum automatischen Herunterfahren echt wichtig, um Verschwendung zu vermeiden. Serverlose Funktionen wie AWS Lambda oder Azure Functions können nicht genutzte Ressourcen außerhalb der Geschäftszeiten automatisch abschalten und so unnötige Kosten vermeiden.
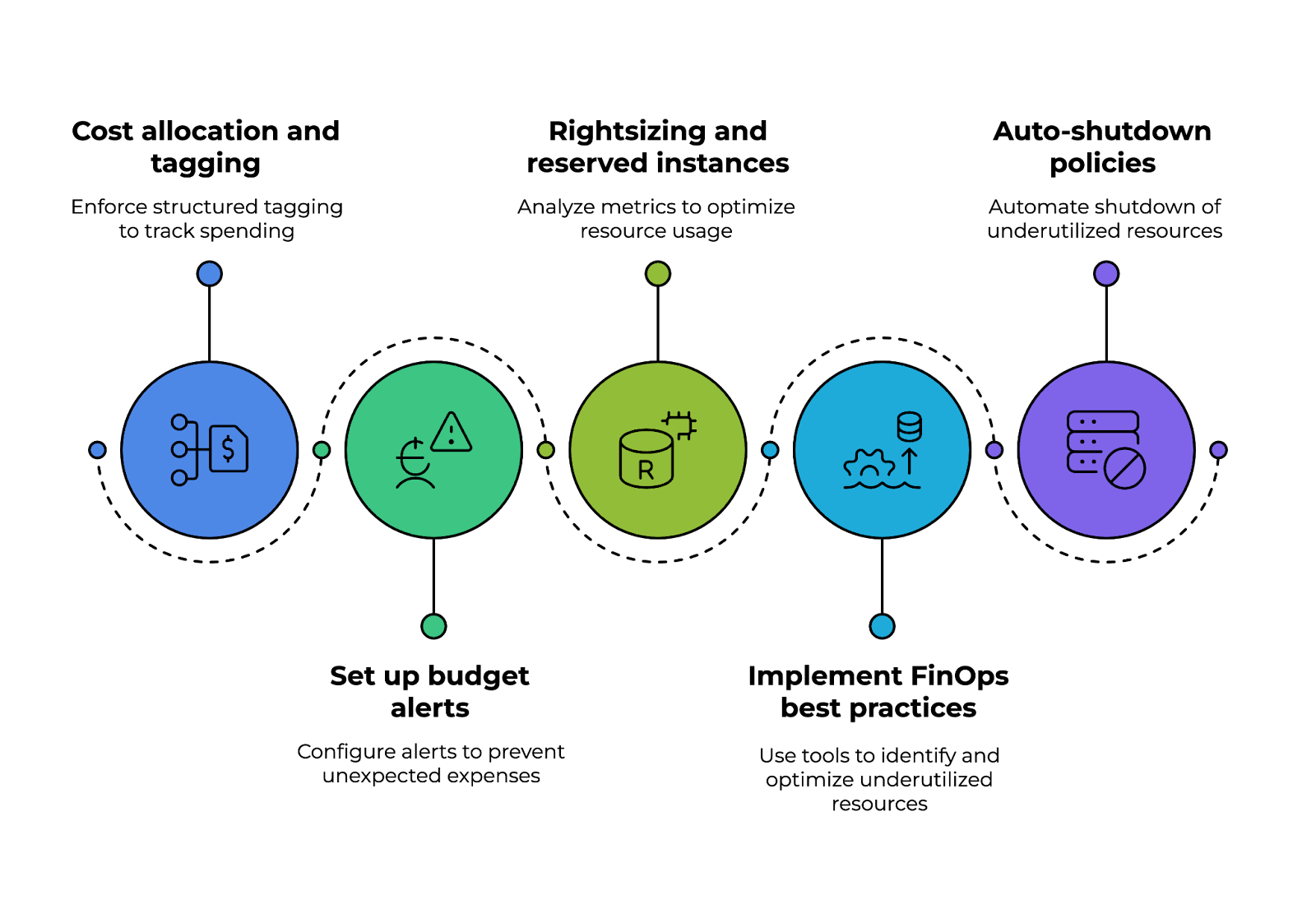
Die wichtigsten Punkte für die Umsetzung einer Strategie zur Kostenkontrolle in der Cloud. Bild vom Autor.
Ein Data Lake braucht effiziente Speicherung, Abruf und Verarbeitung von Daten im Petabyte-Bereich. Einige Optimierungsstrategien sind:
Einer der grundlegenden Aspekteeiner CI/CD-Pipeline ist die Code-Versionierung und das Repository-Management, das eine effiziente Zusammenarbeit und Änderungsverfolgung ermöglicht. Tools wie GitHub Actions, AWS CodeCommit oder Azure Repos helfen dabei, den Quellcode zu verwalten, Verzweigungsstrategien durchzusetzen und Pull-Request-Workflows zu optimieren.
Build-Automatisierung und Artefaktmanagement- s sind echt wichtig, um die Konsistenz und Zuverlässigkeit von Software-Builds zu sichern. Mit Docker-basierten Builds, JFrog Artifactory oder AWS CodeArtifact können Teams reproduzierbare Builds erstellen, Artefakte sicher speichern und die Versionskontrolle über alle Entwicklungsumgebungen hinweg sicherstellen.
Sicherheit ist auch ein wichtiger Punkt. integrieren Mit SAST-Tools (Statische Anwendungssicherheitstests) wie SonarQube oder Snyk kann man Schwachstellen im Code frühzeitig erkennen. Außerdem sorgt die Durchsetzung signierter Container-Images dafür, dass nur geprüfte und vertrauenswürdige Artefakte eingesetzt werden.
Eine solide Strategie für die mehrstufige Bereitstellung hilft dabei, die Risiken bei Software-Releases zu minimieren. Ansätze wie Canary-, Blue-Green- oder Rolling-Deployments machen schrittweise Rollouts möglich, reduzieren Ausfallzeiten und erlauben eine Echtzeit-Leistungsüberwachung. Mit Feature-Flags können Teams steuern, welche Nutzer neue Funktionen schon vor der offiziellen Veröffentlichung nutzen können.
Und schließlich istdie Integration von Infrastructure as Code (IaC) echt wichtig, um Cloud-Umgebungen zu automatisieren und zu standardisieren. Mit Terraform, AWS CloudFormation oder Pulumi können Teams die Infrastruktur in Code festlegen, für einheitliche Bereitstellungen sorgen und Cloud-Ressourcen bereitstellen.
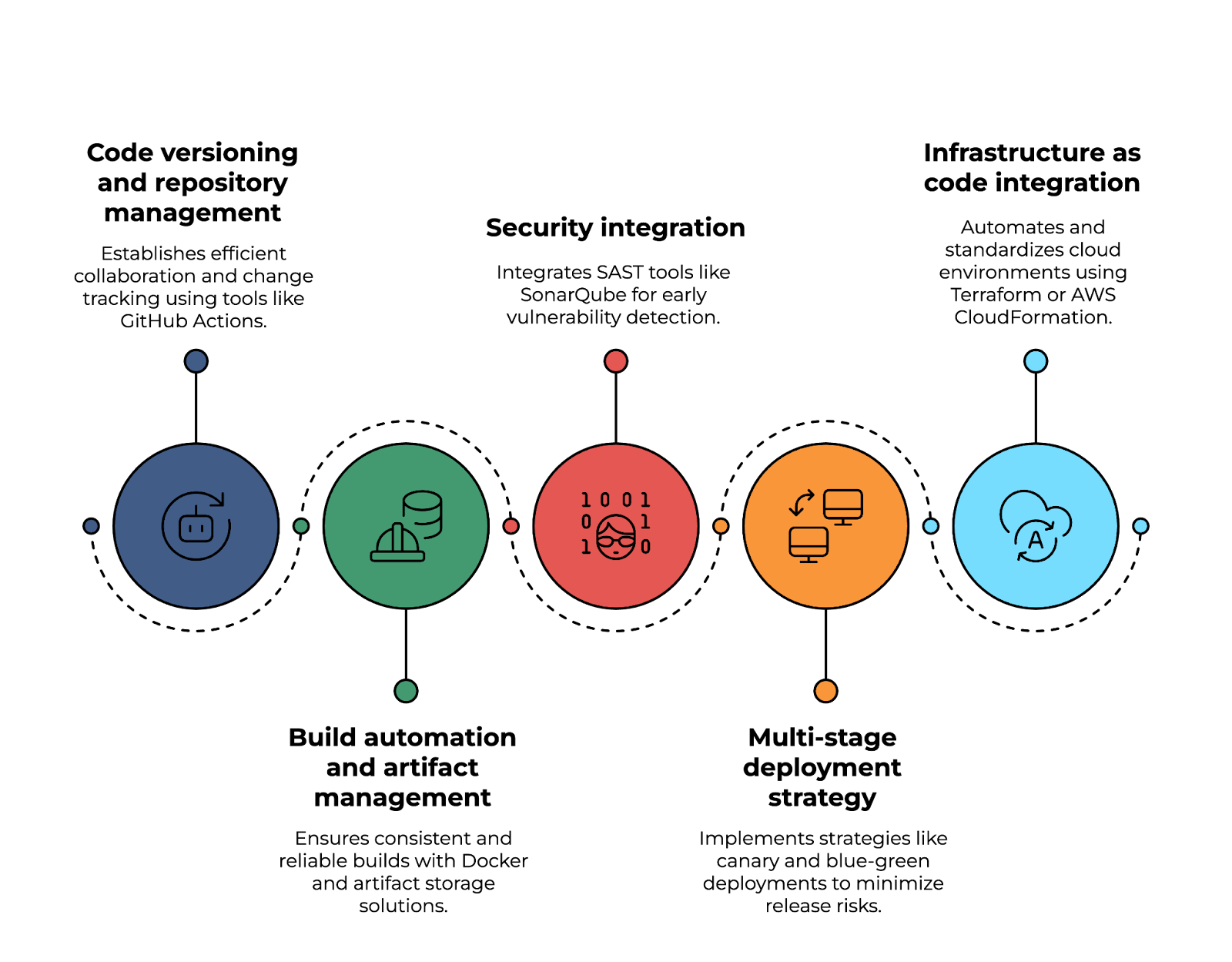
Eine Cloud-native CI/CD-Pipeline einrichten. Bild vom Autor.
Disaster Recovery (DR) ist super wichtig, um den Geschäftsbetrieb bei Ausfällen, Angriffen oder Hardwareproblemen am Laufen zu halten. Ein guter DR-Plan sollte Folgendes beinhalten:
Das Verwalten von großen Kubernetes (K8s)-Clustern bringt Herausforderungen beim Betrieb und bei der Leistung mit sich. Wichtige Bereiche, die angegangen werden müssen, sind:
Szenariobasierte Fragen checken, wie gut du echte Cloud-Herausforderungen analysieren, Probleme lösen und Architekturentscheidungen unter verschiedenen Einschränkungen treffen kannst.
Deine Antworten sollten praktische Erfahrungen, Entscheidungsfindung und Kompromisse bei der Lösung von Cloud-Problemen zeigen. Da es keine richtigen oder falschen Antworten gibt, habe ich ein paar Beispiele eingefügt, um dir beim Nachdenken zu helfen.
Beispielantwort:
Hohe Latenz in einer Cloud-Anwendung kann durch verschiedene Sachen passieren, wie zum Beispiel ein überlastetes Netzwerk, ineffiziente Datenbankabfragen, nicht optimale Instanzplatzierung oder falsche Konfigurationen beim Lastenausgleich.
Um das Problem zu finden, würde ich erst mal versuchen, den Engpass mit Cloud-Überwachungstools zu lokalisieren. Der erste Schritt wäre, die Antwortzeiten der Anwendung und die Netzwerklatenz zu checken, indem man die Protokolle, die Anfrage-Antwort-Zeiten und die HTTP-Statuscodes anschaut. Wenn das Problem mit dem Netzwerk zu tun hat, würde ich einen Traceroute- oder Ping-Test machen, um zu sehen, ob die Roundtrip-Zeiten zwischen den Benutzern und der Anwendung länger geworden sind. Wenn es ein Problem gibt, könnte die Aktivierung eines CDN helfen, statische Inhalte näher an den Nutzern zwischenzuspeichern und die Latenz zu verringern.
Wenn die Datenbankabfragen zu Verzögerungen führen, würde ich langsame Abfragen analysierenund sie durch eine Optimierung der Datenbank () optimieren, indem ich eine geeignete Indizierung hinzufüge oder Tabellen denormalisiert. Wenn die Anwendung viel Traffic hat, kann das Aktivieren der horizontalen Skalierung mit Autoscaling-Gruppen oder Lesereplikaten die Belastung der Primärdatenbank verringern.
Wenn die Latenzprobleme weiter bestehen, würde ich die Rechenressourcen der Anwendung checken und sicherstellen, dass sie in der richtigen Verfügbarkeitszone läuft, die den Endnutzern am nächsten ist. Wenn nötig, würde ich Workloads auf ein Setup mit mehreren Regionen umstellen oder Edge-Computing-Lösungen nutzen, um Anfragen näher an der Quelle zu bearbeiten.
Beispielantwort:
Als Erstes muss man schauen, ob die App so wie sie ist in die Cloud verschoben werden kann oder ob man was daran ändern muss. Ein Ansatz ist, die „6 R's der Cloud-Migration“ zu nutzen:
Ein Lift-and-Shift-Ansatz wäre super, wenn du schnell und mit möglichst wenig Änderungen migrieren willst. Wenn es dir vor allem um Performance-Optimierung und Kosteneffizienz geht, würde ich überlegen, die Plattform zu wechseln, indem ich die Anwendung auf Container oder Serverless Computing umstelle, was eine bessere Skalierbarkeit ermöglicht. Bei Anwendungen mit monolithischen Architekturen kann es sein, dass man sie in Microservices umbauen muss, um die Leistung und Wartbarkeit zu verbessern.
Ich würde mich auch auf die Datenmigration konzentrieren und dafür sorgen, dass die Datenbanken mit möglichst wenig Ausfallzeit in die Cloud kopiert werden.
Sicherheit und Compliance wären ein weiteres großes Problem. Vor der Bereitstellung würde ich sicherstellen, dass die Anwendung die gesetzlichen Anforderungen erfüllt (z. B. HIPAA, DSGVO) erfüllt, indem ich Verschlüsselung, IAM-Richtlinien und VPC-Isolation einsetzte.
Zum Schluss würde ich Tests und Validierungen in einer Staging-Umgebung machen, bevor ich den Produktionsverkehr umstelle.
Beispielantwort:
Auf der Infrastruktur-Ebene würde ich den Kubernetes-Cluster über mehrere Verfügbarkeitszonen (AZs) verteilen. Dadurch wird sichergestellt, dass der Datenverkehr zu einer anderen Zone umgeleitet werden kann, wenn eine AZ ausfällt. Ich würde Kubernetes Federation nutzen, um Multi-Cluster-Bereitstellungen für lokale oder hybride Setups zu verwalten.
Innerhalb des Clusters würde ich die Ausfallsicherheit auf Pod-Ebene umsetzen, indem ich ReplicaSets und horizontale Pod-Autoscaler (HPA) einrichte, um die Workloads dynamisch basierend auf der CPU-/Speicherauslastung zu skalieren. Außerdem würden Pod-Disruption-Budgets (PDBs) dafür sorgen, dass während Updates oder Wartungsarbeiten immer eine Mindestanzahl an Pods verfügbar bleibt.
Für die Vernetzung würde ich ein Service Mesh nutzen, um die Kommunikation zwischen den Services zu verwalten und dabei Wiederholungsversuche, Circuit Breaking und Traffic Shaping-Richtlinien durchzusetzen. Ein globaler Load Balancer würde den externen Datenverkehr effizient auf mehrere Regionen verteilen.
Persistenter Speicher ist auch ein wichtiger Punkt. Wenn die Microservices Datenpersistenz brauchen, würde ich container-native Speicherlösungen nehmen. Ich würde regionenübergreifende Backups und automatische Snapshot-Richtlinien einrichten, um Datenverluste zu vermeiden.
Schließlich sind Überwachung und Protokollierung wichtig, um eine hohe Verfügbarkeit zu sichern. Ich würde Prometheus und Grafana für die Echtzeit-Leistungsüberwachung einbinden und den ELK-Stack oder AWS CloudWatch Logs nutzen, um den Zustand der Anwendungen zu verfolgen und Fehler proaktiv zu erkennen.
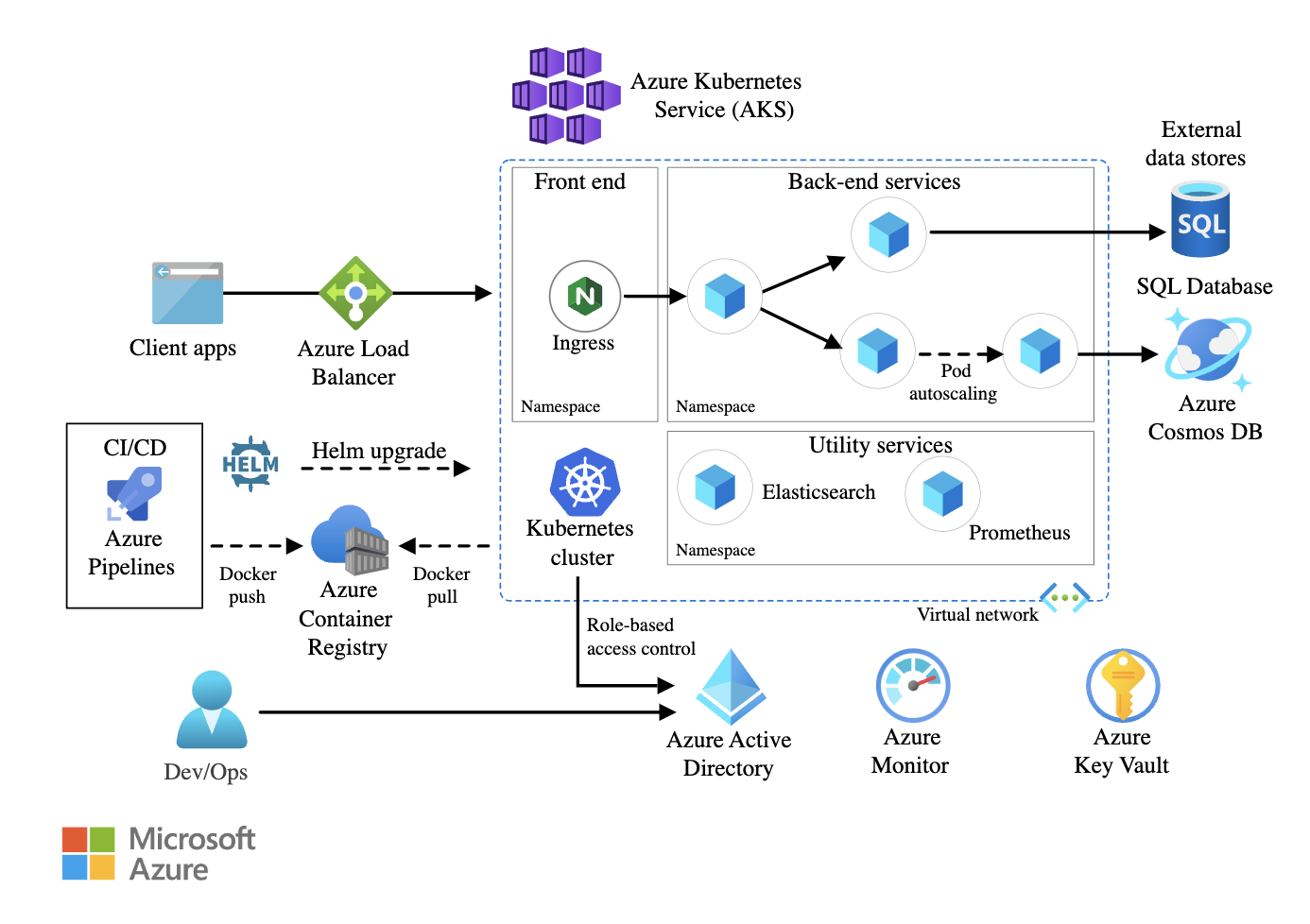
Beispiel für eine Microservices-Architektur mit Azure Kubernetes Service (AKS). Bildquelle: Microsoft Lernen
Beispielantwort:
Wenn ich eine Sicherheitslücke finde, würde ich sofort versuchen, den Vorfall einzudämmen, herauszufinden, wo der Angriff herkommt, und verhindern, dass es weiter ausgenutzt wird. Ich würde zuerst die betroffenen Systeme isolieren, um den Schaden zu begrenzen, indem ich kompromittierte IAM-Anmeldedaten widerrufe, den Zugriff auf die betroffenen Ressourcen einschränke und Sicherheitsgruppenregeln durchsetze.
Der nächste Schritt wäre die Analyse und Untersuchung der Protokolle. Audit-Protokolle würden verdächtige Aktivitäten wie unbefugte Zugriffsversuche, Privilegienerweiterungen oder unerwartete API-Aufrufe aufdecken. Wenn jemand eine falsch eingestellte Sicherheitsrichtlinie ausnutzt, würde ich die Schwachstelle finden und beheben.
Um die Auswirkungen zu verringern, würde ich die Anmeldedaten regelmäßig ändern, kompromittierte API-Schlüssel sperren und für alle privilegierten Konten eine Multi-Faktor-Authentifizierung (MFA) einrichten. Wenn bei dem Verstoß Daten abgezogen wurden, würde ich die Protokolle checken, um zu sehen, wie die Daten bewegt wurden, und die zuständigen Behörden informieren, falls die Einhaltung von Vorschriften beeinträchtigt wurde.
Sobald die Eindämmung sicher ist, würde ich eine Nachbesprechung machen, um die Sicherheitsmaßnahmen zu verbessern.
Beispielantwort:
Um eine Multi-Cloud-Architektur zu entwerfen, würde ich mit einem gängigen Identitäts- und Zugriffsmanagement-Framework (IAM) wie Okta, AWS IAM Federation oder Azure AD anfangen, um die Authentifizierung über Clouds hinweg sicherzustellen. Das würde isolierte Zugriffskontrollen verhindern und die Identitätsverteilung reduzieren.
Vernetzung ist eine der größten Herausforderungen in Multi-Cloud-Umgebungen. Ich würde Interconnect-Dienste wie AWS Transit Gateway, Azure Virtual WAN oder Google Cloud Interconnect nutzen, um eine sichere Cloud-übergreifende Kommunikation zu ermöglichen. Außerdem würde ich ein Service Mesh einrichten, um das Datenverkehrsmanagement und die Sicherheitsrichtlinien zu vereinheitlichen.
Die Datenkonsistenz über Clouds hinweg ist auch ein wichtiger Faktor. Ich würde die Cloud-übergreifende Replikation mit globalen Datenbanken wie Spanner, Cosmos DB oder AWS Aurora Global Database sicherstellen. Wenn Anwendungen, die auf Latenz angewiesen sind, Datenlokalität brauchen, würde ich Edge-Computing-Lösungen nutzen, um den Datenaustausch zwischen Clouds zu reduzieren.
Schließlich wären Kostenüberwachung und Governance wichtig, um eine unkontrollierte Ausbreitung der Cloud zu verhindern. Mit FinOps-Tools wie CloudHealth, AWS Cost Explorer und Azure Cost Management würde ich die Ausgaben im Auge behalten, Budgetgrenzen durchsetzen und die Ressourcenzuteilung dynamisch optimieren.
Um dich auf ein Vorstellungsgespräch als Cloud-Ingenieur vorzubereiten, musst du die Grundlagen der Cloud, die Architektur, die Sicherheit und die Best Practices gut verstehen. Probier weiter Cloud-Dienste aus, bleib über die neuesten Trends in der Branche auf dem Laufenden und, was am wichtigsten ist, sammle praktische Erfahrungen mit AWS, Azure oder GCP.
Der AWS Cloud Practitioner Lernpfad ist ein super Einstieg, wenn du mehr über AWS erfahren willst. Wenn du neu bei Microsoft Azure bist, hilft dir der Lernpfad „Azure Fundamentals (AZ-900) “, eine solide Grundlage aufzubauen. Und für alle, die sich mit der Google Cloud Platform (GCP) beschäftigen wollen, ist der Kurs „Einführung in GCP“ der perfekte Einstieg.
Viel Glück bei deinem Vorstellungsgespräch!
Lerne mit diesen Kursen mehr über Cloud Computing!
Kurs
Kurs
Kurs