
Cours
Comprendre le cloud
2 h
234.6K
Si vous vous préparez à un entretien d'embauche dans le domaine de l'ingénierie cloud, vous êtes au bon endroit. Cet article aborde certaines des questions les plus fréquemment posées afin de vous aider à vous exercer et à renforcer votre confiance. Que vous aspiriez à un poste dans l'ingénierie cloud, le DevOps ou le MLOps, ces questions évalueront votre compréhension des concepts, de l'architecture et des meilleures pratiques du cloud.
Afin de rendre ce guide encore plus pratique, j'ai inclus des exemples de services proposés par les principaux fournisseurs de cloud computing (AWS, Azure et GCP) afin que vous puissiez observer comment différentes plateformes abordent les solutions cloud. Commençons sans plus attendre.
Ces questions fondamentales évaluent votre compréhension des concepts, des services et des modèles de déploiement du cloud computing. Votre entretien commencera généralement par quelques questions similaires.
Les trois principaux modèles de cloud sont les suivants :
Voici quelques-uns des principaux avantages du cloud computing :
Il existe quatre modèles principaux :

Modèles de déploiement dans le cloud. Image fournie par l'auteur.
La virtualisation est le processus qui consiste à créer des instances virtuelles de ressources informatiques, telles que des serveurs, des systèmes de stockage et des réseaux, sur une seule machine physique. Il facilite le cloud computing en permettant une allocation efficace des ressources, la mutualisation et l'évolutivité.
Les technologies telles que Hyper-V, VMware et KVM sont couramment utilisées pour la virtualisation dans les environnements cloud.
Une région cloud est une zone géographique distincte où les fournisseurs de services cloud hébergent plusieurs centres de données. Une zone de disponibilité (AZ) est un centre de données physiquement distinct au sein d'une région, conçu pour offrir redondance et haute disponibilité.
Par exemple, AWS dispose de plusieurs régions à travers le monde, chacune contenant au moins deux zones de disponibilité (AZ) pour la reprise après sinistre et la tolérance aux pannes.
Voici les différences entre ces deux concepts :
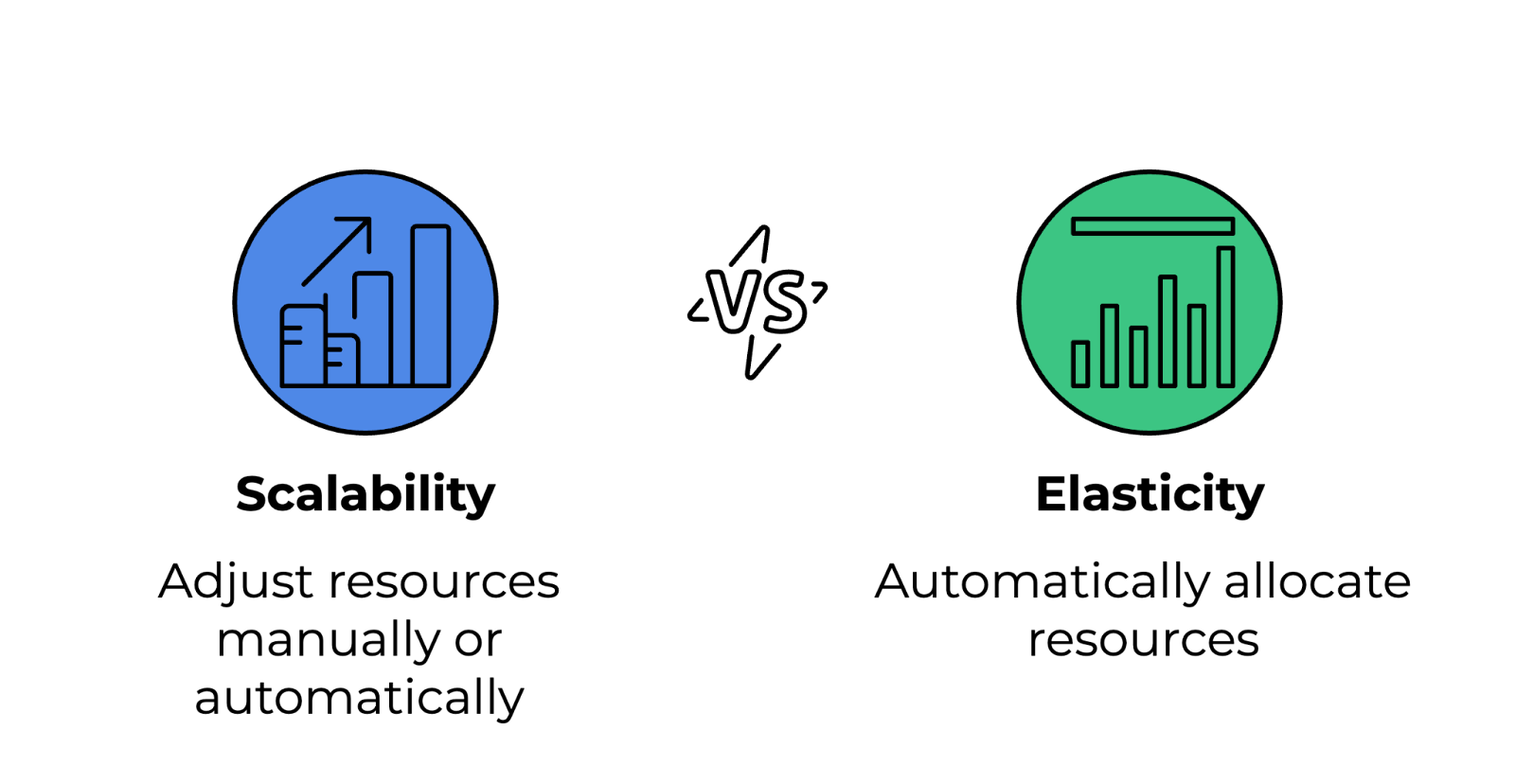
Différence entre évolutivité et élasticité. Image fournie par l'auteur.
Le tableau suivant répertorie les principaux fournisseurs de services cloud, leurs points forts et leurs cas d'utilisation :
|
Fournisseur de services cloud |
Points forts |
Cas d'utilisation |
|
Amazon Web Services (AWS) |
Le plus important fournisseur de services cloud proposant une vaste gamme de services. |
Informatique en cloud à usage général, sans serveur, DevOps. |
|
Microsoft Azure |
Spécialisé dans les solutions cloud d'entreprise et hybrides. |
Applications d'entreprise, cloud hybride, intégration de l'écosystème Microsoft. |
|
Plateforme Google Cloud (GCP) |
Spécialisé dans le big data, l'IA/ML et Kubernetes. |
Apprentissage automatique, analyse de données, orchestration de conteneurs. |
|
IBM Cloud |
Spécialisé dans l'intelligence artificielle et les solutions cloud pour les entreprises. |
Applications basées sur l'intelligence artificielle, transformation cloud des entreprises. |
|
Oracle Cloud |
Fort en bases de données et applications d'entreprise. |
Gestion de bases de données, applications ERP, charges de travail d'entreprise. |
Le calcul sans serveur est un modèle d'exécution dans le cloud où le fournisseur de cloud gère automatiquement l'infrastructure, permettant ainsi aux développeurs de se concentrer sur l'écriture de code. Les utilisateurs ne paient que pour le temps d'exécution réel plutôt que pour la mise à disposition de ressources fixes. Voici quelques exemples :
Le stockage objet est une architecture de stockage de données dans laquelle les fichiers sont stockés sous forme d'objets distincts dans un espace de noms plat plutôt que dans des systèmes de fichiers hiérarchiques. Il est hautement évolutif et utilisé pour les données non structurées, les sauvegardes et le stockage multimédia. Voici quelques exemples :
Un CDN est un réseau de serveurs distribués qui mettent en cache et fournissent du contenu (par exemple, des images, des vidéos, des pages Web) aux utilisateurs en fonction de leur emplacement géographique. Cela permet de réduire la latence, d'améliorer les performances du site Web et d'augmenter la disponibilité. Les CDN les plus populaires sont les suivants :
Ces questions approfondissent les thèmes du réseau cloud, de la sécurité, de l'automatisation et de l'optimisation des performances, évaluant votre capacité à concevoir, gérer et dépanner efficacement des environnements cloud.
Un cloud privé virtuel (VPC) est une section logiquement isolée d'un cloud public qui permet aux utilisateurs de déployer des ressources dans un environnement réseau privé. Il offre un contrôle accru sur les configurations réseau, les politiques de sécurité et la gestion des accès.
Dans un VPC, les utilisateurs peuvent définir des plages d'adresses IP à l'aide de blocs CIDR. Des sous-réseaux peuvent être créés pour séparer les ressources publiques et privées, tandis que les groupes de sécurité et les listes de contrôle d'accès réseau contribuent à appliquer les politiques d'accès au réseau.
Les équilibreurs de charge répartissent le trafic réseau entrant entre plusieurs serveurs afin de garantir une haute disponibilité, une tolérance aux pannes et de meilleures performances.
Il existe différents types d'équilibreurs de charge :
IAM est un cadre qui contrôle qui peut accéder aux ressources cloud et quelles actions ils peuvent effectuer. Il contribue à appliquer le principe du moindre privilège et sécurise les environnements cloud.
Dans l'IAM, les utilisateurs et les rôles définissent des identités avec des autorisations spécifiques, les politiques accordent ou refusent l'accès à l'aide de règles basées sur JSON, et l'authentification multifactorielle (MFA) ajoute une couche de sécurité supplémentaire pour les opérations critiques.
Les groupes de sécurité et les listes de contrôle d'accès réseau (ACL) gèrent le trafic entrant et sortant vers les ressources cloud, mais fonctionnent à différents niveaux.
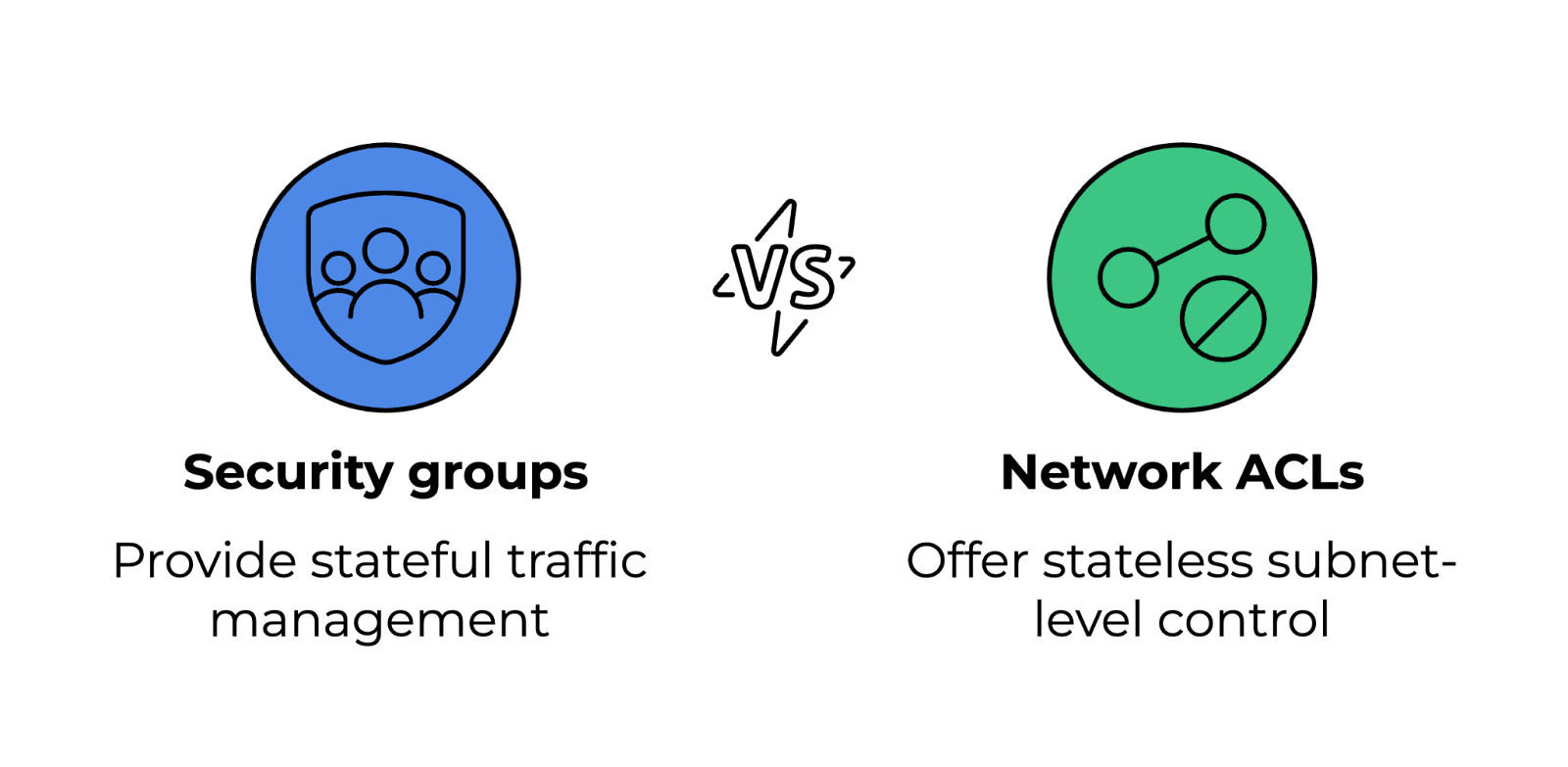
Comparaison des groupes de sécurité et des listes de contrôle d'accès réseau. Image fournie par l'auteur.
Un hôte bastion est un serveur relais sécurisé permettant d'accéder aux ressources cloud dans un réseau privé. Au lieu d'exposer tous les serveurs à Internet, il agit comme une passerelle pour les connexions à distance.
Afin de renforcer la sécurité, il est recommandé de mettre en place des règles de pare-feu strictes, n'autorisant l'accès SSH ou RDP qu'à partir d'adresses IP fiables. L'authentification multifactorielle (MFA) et l'authentification par clé doivent être utilisées pour sécuriser l'accès, et la journalisation et la surveillance doivent être activées afin de suivre les tentatives de connexion non autorisées.
L'autoscaling permet aux environnements cloud d'ajuster dynamiquement les ressources en fonction de la demande, garantissant ainsi rentabilité et performances. Il fonctionne de deux manières :
Les fournisseurs de cloud proposent des groupes à dimensionnement automatique qui fonctionnent avec des équilibreurs de charge afin de répartir efficacement le trafic.
Une gestion efficace des coûts du cloud nécessite de surveiller l'utilisation et de sélectionner les modèles de tarification appropriés. Les stratégies d'optimisation des coûts comprennent :
Souhaitez-vous maîtriser la sécurité AWS et optimiser les coûts liés au cloud ? Nous vous invitons à consulter le cours AWS Security and Cost Management pour découvrir les meilleures pratiques essentielles.

Optimisation des coûts du cloud : quatre piliers. Image fournie par l'auteur.
Terraform et AWS CloudFormation sont tous deux des outils d'infrastructure en tant que code (IaC), mais ils présentent certaines différences :
|
Caractéristique |
Terraform |
AWS CloudFormation |
|
Assistance cloud |
Indépendant du cloud, compatible avec AWS, Azure, GCP et d'autres. |
Spécifique à AWS, conçu exclusivement pour les ressources AWS. |
|
Langage de configuration |
Utilise le langage de configuration HashiCorp (HCL). |
Utilise des modèles JSON/YAML. |
|
Gestion de l'État |
Gère un fichier d'état pour suivre les modifications apportées à l'infrastructure. |
Utilise des piles pour gérer et suivre les déploiements. |
Les outils de surveillance permettent de détecter les goulots d'étranglement en matière de performances, les menaces de sécurité et la surutilisation des ressources. Les solutions de surveillance courantes comprennent :
Les conteneurs regroupent des applications avec leurs dépendances, ce qui les rend légers, portables et évolutifs. Par rapport aux machines virtuelles, les conteneurs utilisent moins de ressources, car plusieurs conteneurs peuvent fonctionner sur un seul système d'exploitation.
Docker et Kubernetes permettent un déploiement et une restauration plus rapides. De plus, ils s'adaptent facilement à des outils d'orchestration tels que Kubernetes et Amazon ECS/EKS.
Souhaitez-vous perfectionner vos compétences en matière de conteneurisation ? , le cursus « Conteneurisation et virtualisation » couvreDocker, Kubernetes et bien d'autres thèmes pour vous aider à créer des applications cloud évolutives.
Un maillage de services est une couche d'infrastructure qui gère la communication entre services dans les applications cloud basées sur des microservices. Il prévoit :
Parmi les solutions de maillage de services les plus populaires, on peut citer Istio, Linkerd et AWS App Mesh.
Une stratégie multicloud consiste à utiliser plusieurs fournisseurs de cloud (AWS, Azure, GCP) afin d'éviter la dépendance vis-à-vis d'un seul fournisseur et d'améliorer la résilience.
Les entreprises optent pour cette approche lorsqu'elles ont besoin d'une redondance géographique pour la reprise après sinistre, souhaitent tirer parti des services uniques de différents fournisseurs (par exemple, AWS pour le calcul, GCP pour l'IA) ou doivent se conformer à des réglementations régionales qui limitent le choix des fournisseurs de cloud.

Avantages et inconvénients de la stratégie multicloud. Image fournie par l'auteur.
Ces questions évaluent votre capacité à concevoir des solutions évolutives, à gérer des infrastructures cloud complexes et à traiter des scénarios critiques.
Une architecture multirégionale garantit un temps d'indisponibilité minimal et la continuité des activités en répartissant les ressources sur plusieurs sites géographiques.
Lors de la conception d'une telle architecture, plusieurs facteurs doivent être pris en compte. Voici quelques-uns d'entre eux :
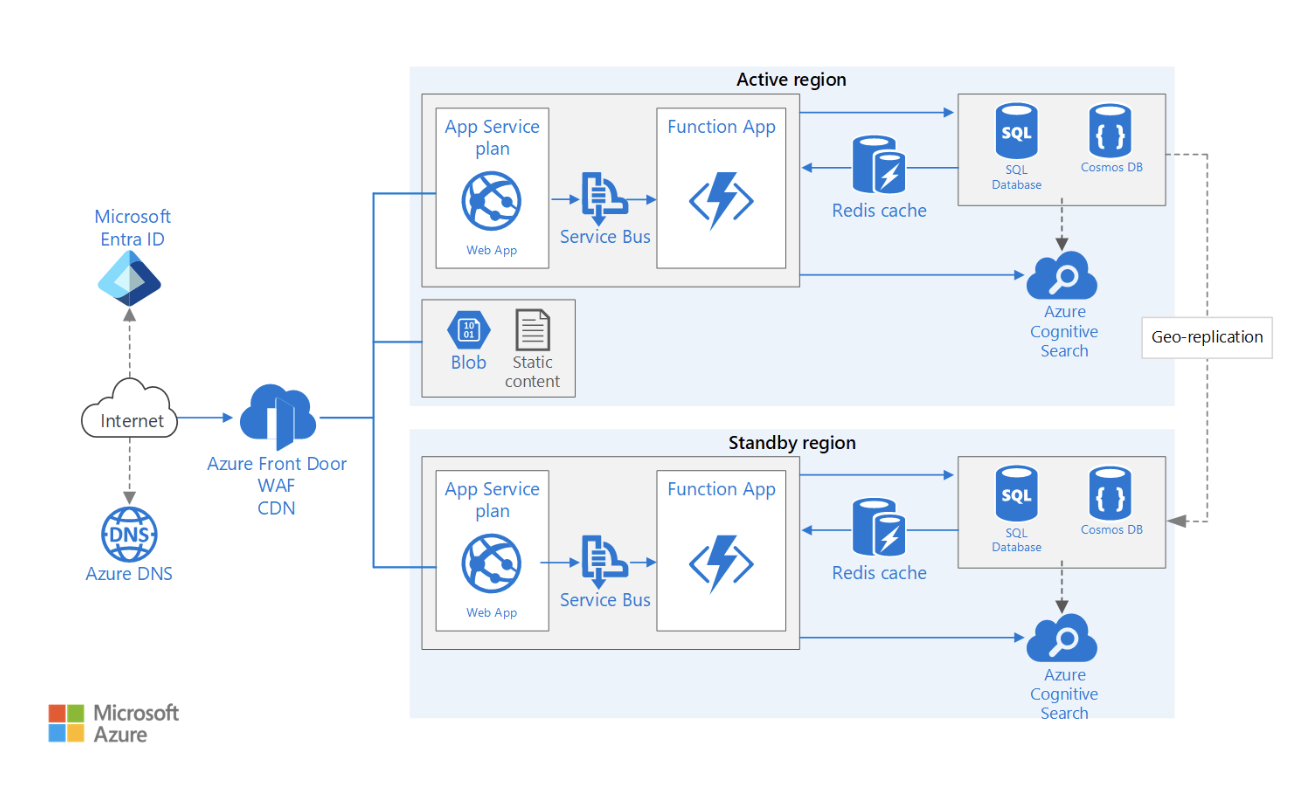
Exemple d'architecture d'application web multirégionale à haute disponibilité. Source de l'image : Microsoft Learn
Le modèle « zero trust » part du principe qu'aucune entité, qu'elle soit interne ou externe au réseau, ne doit être considérée comme fiable par défaut.
Pour mettre en œuvre le modèle Zero Trust dans les environnements cloud :
Une stratégie efficace commence par répartition et au marquage des coûts, où les organisations appliquent un étiquetage structuré (par exemple, département, projet, propriétaire) pour suivre les dépenses entre les équipes et améliorer la visibilité financière.
Il est recommandé de configurerdes alertes budgétairesautomatisées à l'aide d'outils tels que AWS Budgets, Azure Cost Management ou GCP Billing Alerts afin d'éviter les dépenses imprévues. Ces solutions offrent une surveillance en temps réel et des notifications lorsque l'utilisation approche des seuils prédéfinis.
Un autre aspect concerne le dimensionnement optimal et les instances réservées. En analysant en permanence les indicateurs d'utilisation des instances, tels que le CPU et la mémoire, les équipes peuvent déterminer si les charges de travail doivent être ajustées ou migrées vers des instances réservées ou des instances spot, qui permettent de réaliser des économies significatives.
La mise en œuvre des meilleures pratiques FinOps améliore encore davantage la rentabilité. Les outils automatisés de détection des anomalies de coûts, tels que Kubecost (pour les environnements Kubernetes) et AWS Compute Optimizer, permettent d'identifier de manière proactive les ressources sous-utilisées et de les optimiser.
Enfin, les politiques d'arrêt automatique jouent un rôle essentiel dans la réduction des déchets. Les fonctions sans serveur, telles qu'AWS Lambda ou Azure Functions, peuvent automatiquement désactiver les ressources sous-utilisées en dehors des heures de bureau, évitant ainsi des dépenses inutiles.
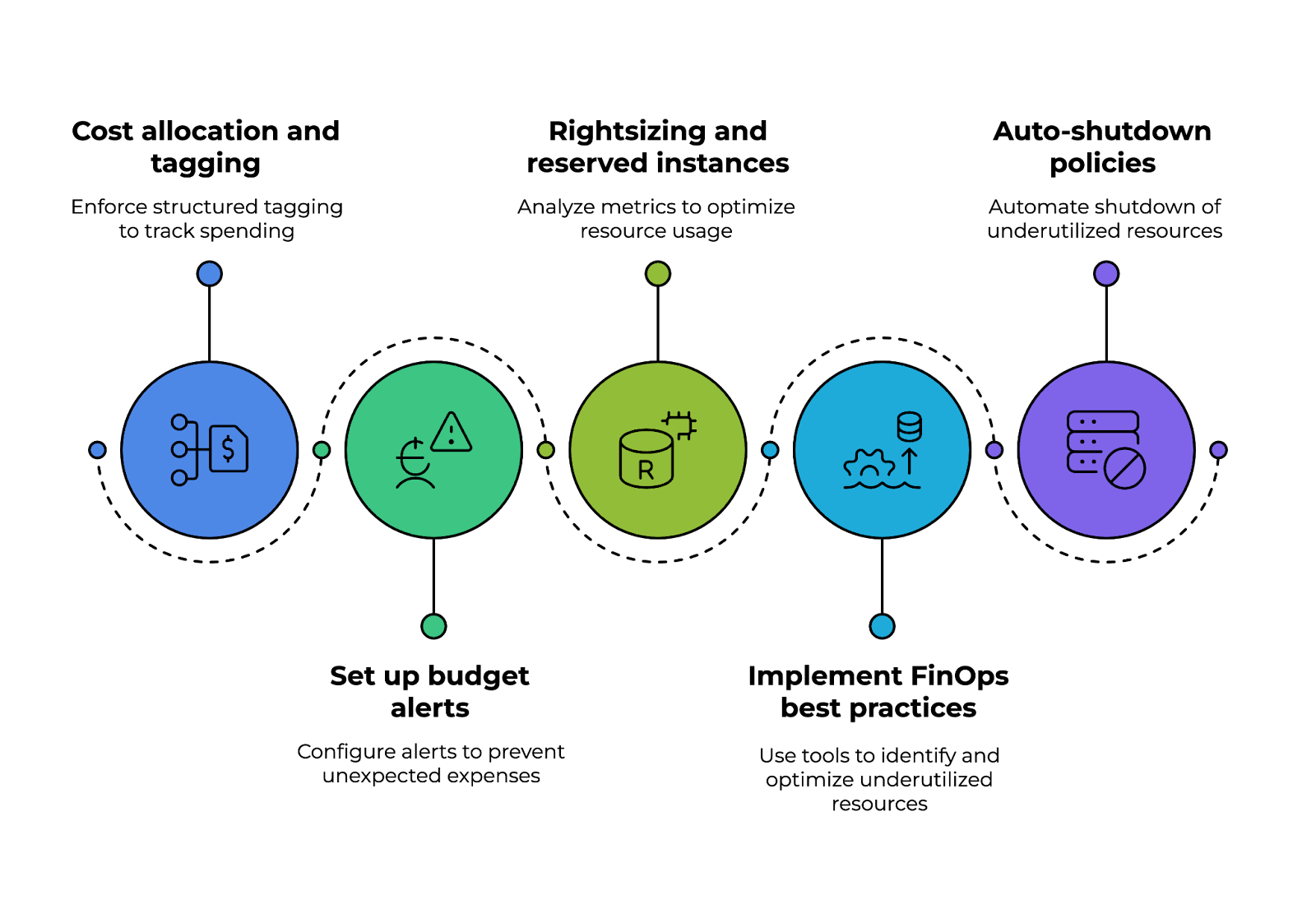
Piliers de la mise en œuvre de la stratégie de gouvernance des coûts du cloud. Image fournie par l'auteur.
Un lac de données nécessite un stockage, une récupération et un traitement efficaces de données à l'échelle du pétaoctet. Certaines stratégies d'optimisation comprennent :
L'un des aspects fondamentauxd'un pipeline CI/CD est la gestion des versions de code et des référentiels, qui permet une collaboration efficace et le suivi des modifications. Des outils tels que GitHub Actions, AWS CodeCommit ou Azure Repos facilitent la gestion du code source, la mise en œuvre de stratégies de branchement et la rationalisation des workflows de pull request.
Les s d'automatisationde la construction et de gestion des artefacts jouent un rôle crucial dans le maintien de la cohérence et de la fiabilité des constructions logicielles. Grâce aux builds basés sur Docker, JFrog Artifactory ou AWS CodeArtifact, les équipes peuvent créer des builds reproductibles, stocker des artefacts en toute sécurité et garantir le contrôle des versions dans tous les environnements de développement.
La sécurité est un autre aspect essentiel à prendre en considération. L'intégration d'outils SAST (tests de sécurité statiques des applications) tels que SonarQube ou Snyk permet une détection précoce des vulnérabilités dans le code source. De plus, l'application des images de conteneur signées garantit que seuls les artefacts vérifiés et fiables sont déployés.
Une stratégie de déploiementrobuste en plusieurs étapes contribue à minimiser les risques associés aux versions logicielles. Des approches telles que les déploiements canary, bleu-vert ou progressifs permettent des mises en œuvre graduelles, réduisant ainsi les temps d'arrêt et permettant une surveillance des performances en temps réel. Grâce aux indicateurs de fonctionnalité, les équipes peuvent déterminer quels utilisateurs auront accès aux nouvelles fonctionnalités avant leur lancement complet.
Enfin, l'intégration de l'infrastructure en tant que code (IaC) est essentielle pour automatiser et standardiser les environnements cloud. En utilisant Terraform, AWS CloudFormation ou Pulumi, les équipes peuvent définir l'infrastructure dans le code, maintenir la cohérence entre les déploiements et permettre l'approvisionnement des ressources cloud.
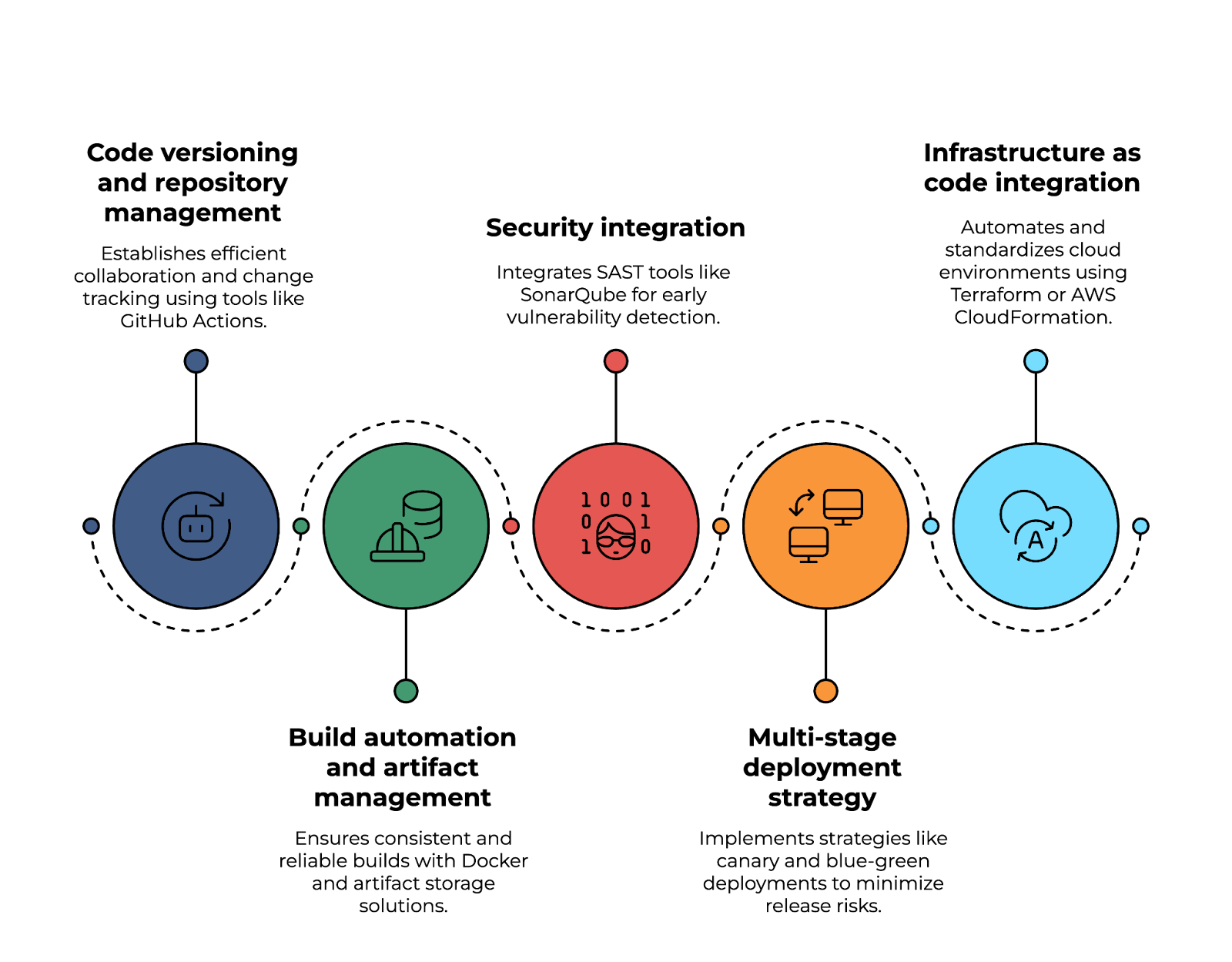
Mise en œuvre d'un pipeline CI/CD natif du cloud. Image fournie par l'auteur.
La reprise après sinistre (DR) est essentielle pour assurer la continuité des activités en cas de pannes, d'attaques ou de défaillances matérielles. Un plan de reprise après sinistre efficace comprend les éléments suivants :
La gestion de clusters Kubernetes (K8s) à grande échelle présente des défis opérationnels et de performance. Les principaux domaines à traiter sont les suivants :
Les questions basées sur des scénarios évaluent votre capacité à analyser les défis réels du cloud, à résoudre les problèmes et à prendre des décisions architecturales dans le cadre de différentes contraintes.
Vos réponses doivent démontrer votre expérience pratique, votre capacité à prendre des décisions et à faire des compromis lors de la résolution de problèmes liés au cloud. Étant donné qu'il n'existe pas de bonnes ou de mauvaises réponses, j'ai inclus quelques exemples pour vous aider dans votre réflexion.
Exemple de réponse :
Une latence élevée dans une application cloud peut être causée par plusieurs facteurs, notamment la congestion du réseau, des requêtes de base de données inefficaces, un placement d'instance sous-optimal ou des erreurs de configuration de l'équilibrage de charge.
Pour diagnostiquer le problème, je commencerais par isoler le goulot d'étranglement à l'aide d'outils de surveillance cloud. La première étape consisterait à analyser les temps de réponse des applications et la latence du réseau en examinant les journaux, les temps de réponse aux requêtes et les codes d'état HTTP. Si le problème est lié au réseau, je recommanderais d'utiliser un test traceroute ou ping afin de vérifier si les temps d'aller-retour entre les utilisateurs et l'application ont augmenté. Si un problème se présente, l'activation d'un CDN pourrait contribuer à mettre en cache le contenu statique plus près des utilisateurs et à réduire la latence.
Si les requêtes de la base de données entraînent des retards, je recommanderais de profiler les requêtes lenteset de les optimiser à l'aide d's ajoutant un indexage approprié ou en dénormalisant les tables. De plus, si l'application est soumise à un trafic important, l'activation de la mise à l'échelle horizontale avec des groupes de mise à l'échelle automatique ou des répliques en lecture peut réduire la charge sur la base de données principale.
Si les problèmes de latence persistent, je recommanderais de vérifier les ressources informatiques de l'application, en s'assurant qu'elle fonctionne dans la zone de disponibilité appropriée la plus proche des utilisateurs finaux. Si nécessaire, je transférerais les charges de travail vers une configuration multirégionale ou j'utiliserais des solutions informatiques de pointe pour traiter les demandes plus près de la source.
Exemple de réponse :
La première étape consiste à réaliser une évaluation de la préparation au cloud, afin de déterminer si l'application peut être migrée telle quelle ou si des modifications sont nécessaires. Une approche consiste à appliquer les « 6 R de la migration vers le cloud » :
Une approche « lift-and-shift » serait idéale si l'objectif est une migration rapide avec un minimum de changements. Si l'optimisation des performances et la rentabilité sont des priorités, je recommanderais de envisager une refonte de la plateforme en transférant l'application vers des conteneurs ou un environnement informatique sans serveur, ce qui permettrait une meilleure évolutivité. Pour les applications dotées d'architectures monolithiques, une refonte en microservices peut s'avérer nécessaire afin d'améliorer les performances et la maintenabilité.
Je me concentrerais également sur la migration des données, en veillant à ce que les bases de données soient répliquées dans le cloud avec un temps d'arrêt minimal.
La sécurité et la conformité constitueraient une autre préoccupation majeure. Avant le déploiement, je m'assurerais que l'application respecte les exigences réglementaires (par exemple, HIPAA, RGPD) en mettant en œuvre le chiffrement, les politiques IAM et l'isolation VPC.
Enfin, je procéderais à des tests et à une validation dans un environnement de préproduction avant de transférer le trafic de production.
Exemple de réponse :
Au niveau de l'infrastructure, je déploierais le cluster Kubernetes sur plusieurs zones de disponibilité (AZ). Cela garantit que le trafic peut être redirigé vers une autre zone si une zone de disponibilité tombe en panne. J'utiliserais Kubernetes Federation pour gérer les déploiements multi-clusters pour les configurations sur site ou hybrides.
Au sein du cluster, je mettrais en œuvre la résilience au niveau des pods en configurant des ReplicaSets et des autoscalers horizontaux de pods (HPA) afin de faire évoluer les charges de travail de manière dynamique en fonction de l'utilisation du processeur et de la mémoire. De plus, les budgets de perturbation des pods (PDB) garantiraient qu'un nombre minimum de pods reste disponible pendant les mises à jour ou la maintenance.
Pour la mise en réseau, je recommanderais d'utiliser un maillage de services afin de gérer la communication entre les services, en appliquant des politiques de réessais, de coupure de circuit et de régulation du trafic. Un équilibreur de charge mondial permettrait de répartir efficacement le trafic externe entre plusieurs régions.
Le stockage persistant est un autre aspect essentiel. Si les microservices nécessitent la persistance des données, je recommanderais d'utiliser des solutions de stockage natives pour conteneurs. Je configurerais des sauvegardes interrégionales et des politiques de snapshots automatisés afin de prévenir toute perte de données.
Enfin, la surveillance et la journalisation sont essentielles pour maintenir une haute disponibilité. J'intégrerais Prometheus et Grafana pour la surveillance des performances en temps réel et j'utiliserais ELK stack ou AWS CloudWatch Logs pour suivre la santé des applications et détecter les défaillances de manière proactive.
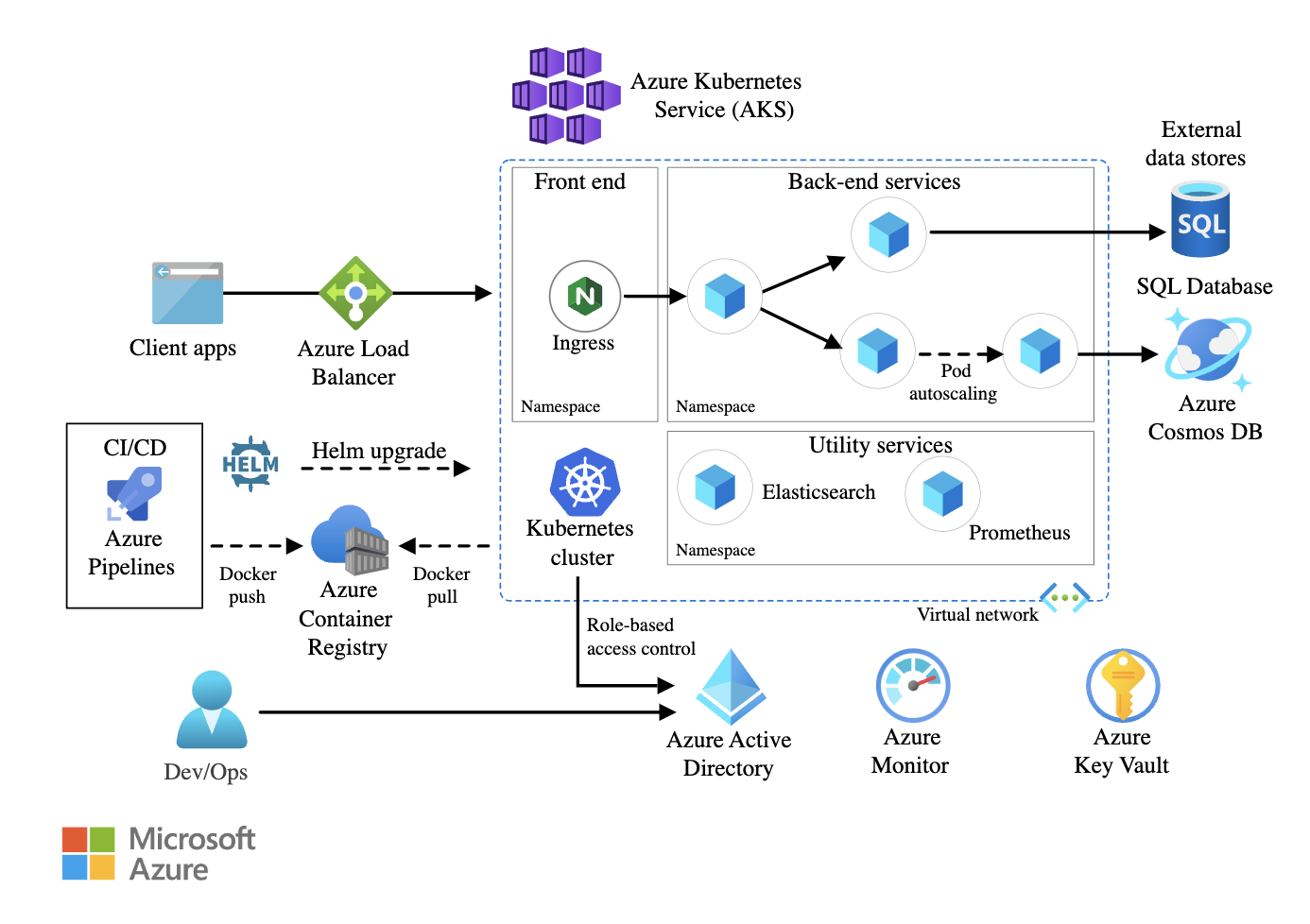
Exemple d'architecture de microservices utilisant Azure Kubernetes Service (AKS). Source de l'image : Microsoft Learn
Exemple de réponse :
En cas de détection d'une faille de sécurité, ma réponse immédiate serait de contenir l'incident, d'identifier le vecteur d'attaque et d'empêcher toute nouvelle exploitation. Je commencerais par isoler les systèmes affectés afin de limiter les dommages en révoquant les identifiants IAM compromis, en restreignant l'accès aux ressources concernées et en appliquant les règles du groupe de sécurité.
La prochaine étape consisterait en une analyse des journaux et une enquête. Les journaux d'audit permettraient de détecter les activités suspectes telles que les tentatives d'accès non autorisées, les élévations de privilèges ou les appels API inattendus. Si un attaquant exploitait une politique de sécurité mal configurée, je procéderais à l'identification et à la correction de la vulnérabilité.
Afin d'atténuer l'impact, je recommanderais de changer régulièrement les identifiants, de révoquer les clés API compromises et d'appliquer l'authentification multifactorielle (MFA) pour tous les comptes privilégiés. Si la violation impliquait l'exfiltration de données, j'analyserais les journaux pour retracer les mouvements de données et informerais les autorités compétentes si la conformité réglementaire était affectée.
Une fois le confinement confirmé, je procéderais à un examen post-incident afin de renforcer les politiques de sécurité.
Exemple de réponse :
Pour concevoir une architecture multicloud, je commencerais par un cadre commun de gestion des identités et des accès (IAM), tel qu'Okta, AWS IAM Federation ou Azure AD, afin de garantir l'authentification entre les clouds. Cela permettrait d'éviter un contrôle d'accès cloisonné et de réduire la prolifération des identités.
La mise en réseau représente un défi majeur dans les environnements multi-cloud. Je recommanderais d'utiliser des services d'interconnexion tels qu'AWS Transit Gateway, Azure Virtual WAN ou Google Cloud Interconnect afin de faciliter une communication sécurisée entre les clouds. De plus, je mettrais en place un maillage de services afin de standardiser la gestion du trafic et les politiques de sécurité.
La cohérence des données entre les clouds est un autre facteur essentiel. Je garantirais la réplication inter-cloud à l'aide de bases de données mondiales telles que Spanner, Cosmos DB ou AWS Aurora Global Database. Si des applications sensibles à la latence nécessitent la localisation des données, je recommanderais d'utiliser des solutions d'informatique en périphérie afin de réduire le transfert de données entre les clouds.
Enfin, le contrôle des coûts et la gouvernance seraient essentiels pour éviter la prolifération du cloud. À l'aide d'outils FinOps tels que CloudHealth, AWS Cost Explorer et Azure Cost Management, je suivrais les dépenses, appliquerais les limites budgétaires et optimiserais l'allocation des ressources de manière dynamique.
La préparation à un entretien pour un poste d'ingénieur cloud nécessite une solide compréhension des principes fondamentaux du cloud, de son architecture, de sa sécurité et des meilleures pratiques. Continuez à explorer les services cloud, restez informé des tendances du secteur et, surtout, acquérez une expérience pratique avec AWS, Azure ou GCP.
Le cursus AWS Cloud Practitioner constitue un excellent point de départ si vous souhaitez approfondir vos connaissances sur AWS. Si vous débutez avec Microsoft Azure, le cursus Azure Fundamentals (AZ-900) vous aidera à acquérir des bases solides. Pour ceux qui souhaitent se familiariser avec Google Cloud Platform (GCP), le cours Introduction à GCP constitue un excellent point de départ.
Nous vous souhaitons bonne chance pour votre entretien.
Veuillez approfondir vos connaissances sur le cloud grâce à ces cours.
Cours
Cours
Cours