Curso
Comprender la computación en la nube
2 h
234.6K
En la informática distribuida, utilizamos varios ordenadores para trabajar juntos en un mismo problema. En lugar de depender de una sola máquina, dividimos las tareas en trozos más pequeños y los asignamos a una red de ordenadores, que llamamos "nodos". Estos nodos comparten la carga de trabajo de procesamiento y el almacenamiento de datos, trabajando en colaboración para completar las tareas.
Este enfoque es útil cuando se trata de problemas a gran escala o conjuntos de datos demasiado grandes o complejos para que los maneje un solo ordenador. Por ejemplo, un sistema informático distribuido puede procesar petabytes de datos para motores de búsqueda, ejecutar simulaciones para la investigación científica o alimentar modelos financieros para el análisis de mercados.
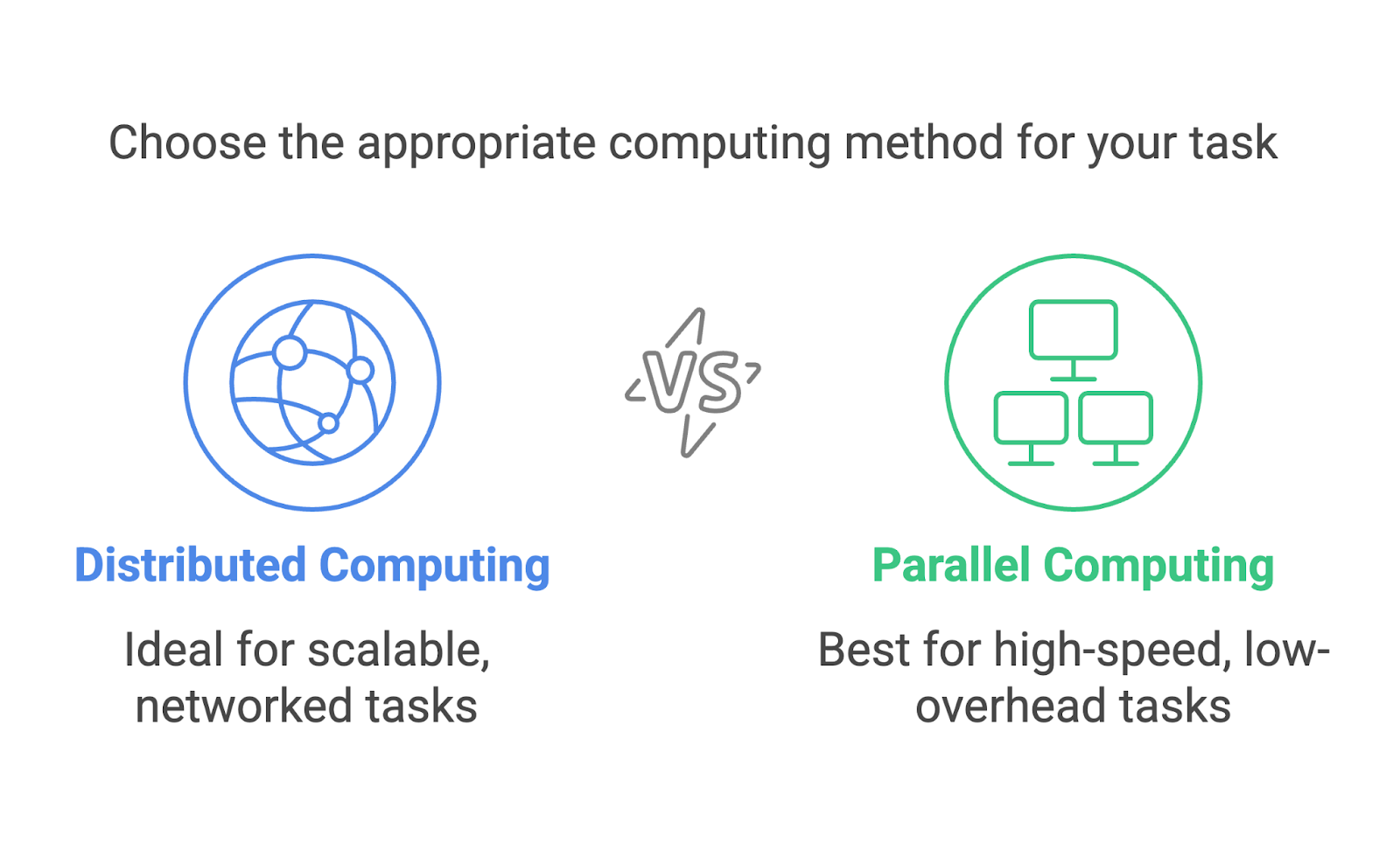
La informática distribuida y la informática paralela se confunden a menudo y podrían parecer intercambiables. Ambos implican múltiples procesos que trabajan hacia un único objetivo, pero son enfoques distintos diseñados para escenarios diferentes.
La informática distribuida se centra en el uso de una red de máquinas independientes, a menudo dispersas geográficamente, para resolver problemas de forma colaborativa. Cada máquina funciona como un nodo independiente con su propia memoria y capacidad de procesamiento. La comunicación entre los nodos se realiza a través de una red, y las tareas se dividen para que puedan ejecutarse en diferentes máquinas.
La informática paralela, en cambio, suele tener lugar dentro de un único sistema. Utiliza varios procesadores o núcleos dentro de un ordenador para ejecutar tareas simultáneamente. Estos procesadores comparten la misma memoria y a menudo trabajan en estrecha colaboración para dividir los cálculos.
Pongamos un ejemplo práctico y digamos que estamos ordenando un conjunto de datos masivo. En computación paralela, dividiríamos el conjunto de datos en trozos, y cada procesador de la misma máquina se encargaría de un trozo. En la informática distribuida, el conjunto de datos se dividiría y se enviaría a distintas máquinas, cada una de las cuales ordenaría su parte de forma independiente. A continuación, se fusionarán las piezas clasificadas.
Ambos métodos son increíblemente útiles, pero se adaptan a tareas diferentes. La computación paralela es ideal para tareas que necesitan un cálculo de alta velocidad con una sobrecarga de comunicación mínima, como la ejecución de simulaciones en un superordenador. La informática distribuida es más adecuada cuando se amplía, como cuando se procesan datos en sistemas basados en la nube o a través de redes globales.
La informática distribuida impulsa algunas de las aplicaciones más impactantes de nuestro mundo actual. Echemos un vistazo a tres casos de uso común: motores de búsqueda, investigación científica y modelización financiera.
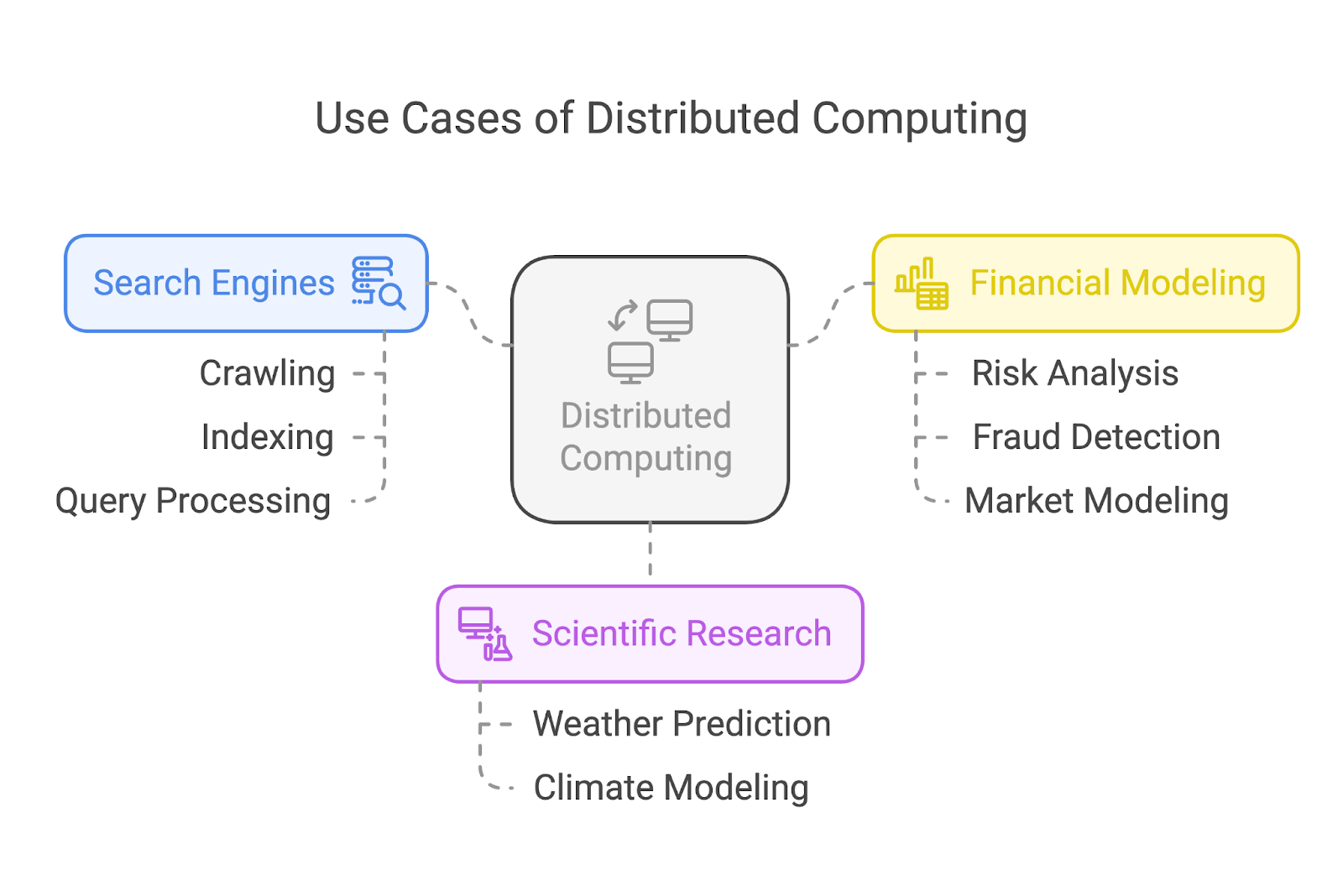
Los motores de búsqueda como Google dependen en gran medida de la informática distribuida para rastrear e indexar miles de millones de páginas web. En lugar de asignar la tarea a una sola máquina, estos sistemas dividen la carga de trabajo entre muchísimos nodos.
Algunos nodos se centran en rastrear páginas web, otros se encargan de la indexación y otro grupo procesa las consultas de los usuarios en tiempo real. Esta división del trabajo garantiza resultados de búsqueda rápidos y eficaces, sea cual sea la envergadura de la tarea.
En la investigación científica, la informática distribuida permite grandes avances mediante la ejecución de simulaciones complejas y el análisis de enormes conjuntos de datos. Por ejemplo, los climatólogos utilizan sistemas distribuidos para modelar y predecir patrones meteorológicos o simular los efectos del calentamiento global.
El sector financiero confía en la informática distribuida para tareas como el análisis de riesgos, la detección de fraudes y el modelado de mercados.
El procesamiento de los enormes conjuntos de datos generados por los mercados financieros mundiales exige sistemas capaces de trabajar las 24 horas del día y con gran rapidez. La informática distribuida permite a las empresas financieras analizar datos, probar modelos y generar ideas a velocidades que las mantienen competitivas en los mercados en tiempo real.
La informática distribuida se basa en algunos componentes fundamentales: nodos, una red y un sistema de archivos distribuido (DFS).
Los nodos son las máquinas individuales que realizan cálculos dentro de un sistema distribuido. Cada nodo puede actuar de forma independiente, procesando sus tareas asignadas y comunicándose con otros nodos para compartir los resultados. En algunos casos, los nodos pueden tener funciones especializadas, como gestionar tareas o almacenar datos.
La red es la infraestructura de comunicación que conecta los distintos nodos. Les permite intercambiar datos y coordinar tareas. Dependiendo del tamaño del sistema, esto puede implicar redes de área local (LAN) o redes de área amplia (WAN) para nodos geográficamente dispersos.
Un sistema de archivos distribuido es una solución de almacenamiento que permite acceder a los datos a través de varios nodos. Un ejemplo popular es el Sistema de Archivos Distribuidos Hadoop (HDFS), que está diseñado para manejar grandes conjuntos de datos y proporcionar tolerancia a fallos replicando los datos en varios nodos.
Bien, tenemos una carga de trabajo distribuida a diferentes nodos a través de una red, y todos los nodos tienen acceso a los datos a través de un DFS. Pero, ¿quién decide qué nodo hace qué?
No hay una respuesta única a estas preguntas, porque los sistemas informáticos distribuidos pueden organizarse de varias maneras. Dicho esto, hay tres arquitecturas comunes: maestro-esclavo, peer-to-peer y cliente-servidor.
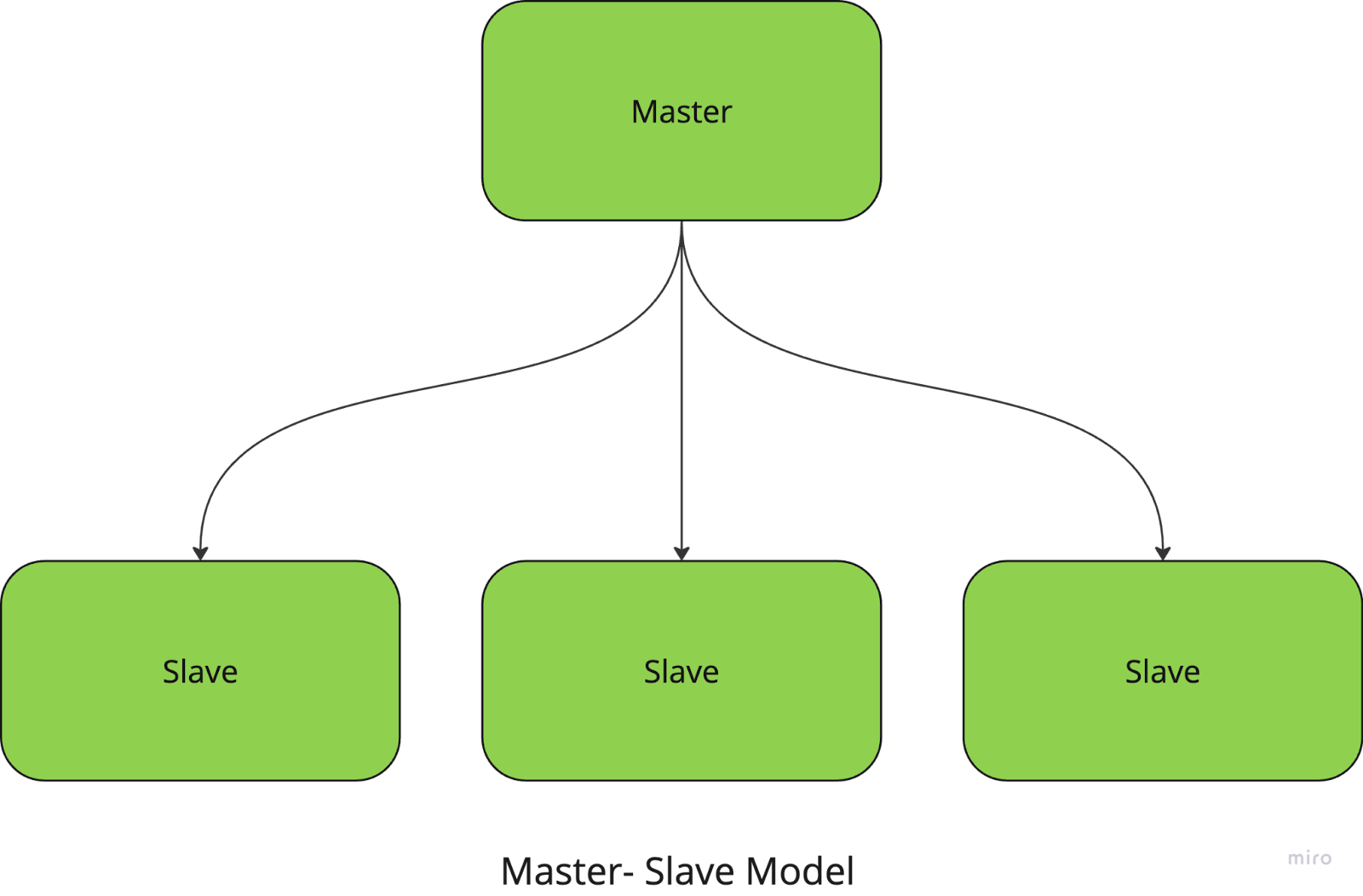
En el modelo maestro-esclavo, un nodo central (el nodo maestro) gestiona y coordina las tareas, mientras que los nodos esclavos ejecutan los cálculos reales. El maestro se encarga de dividir las tareas en trozos más pequeños, distribuirlos a los esclavos y recoger los resultados.
Por ejemplo, si estás ejecutando una tarea de procesamiento de imágenes a gran escala, el nodo maestro asigna a cada nodo esclavo una parte específica de las imágenes que debe procesar. Una vez completadas las tareas, el maestro reúne los resultados y los combina en el resultado final.
Este enfoque simplifica la gestión y coordinación de las tareas, pero tiene un fuerte inconveniente: el sistema tiene un único punto de fallo, ya que depende totalmente del nodo maestro.
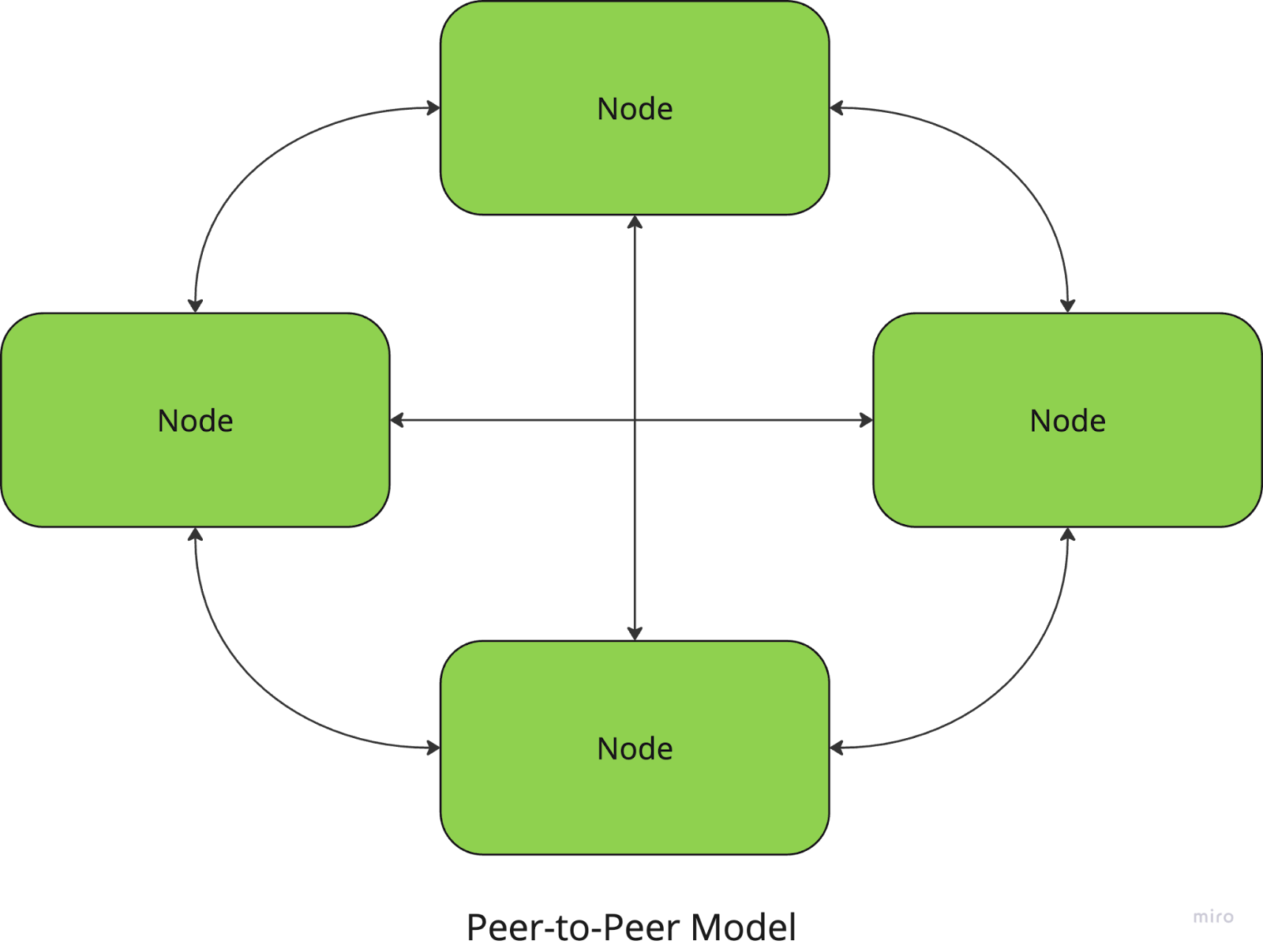
En la arquitectura peer-to-peer, todos los nodos son iguales, y no hay un coordinador central. Cada nodo puede actuar como cliente y como servidor, compartiendo recursos y comunicándose directamente con otros nodos.
Por ejemplo, las redes de intercambio de archivos como BitTorrent utilizan un enfoque P2P, en el que los usuarios descargan y suben fragmentos de archivos directamente de y a otros pares.
En el lado positivo, estos sistemas no tienen un punto central de fallo, lo que los hace resistentes y escalables, pero la coordinación entre nodos (para garantizar la coherencia de los datos, por ejemplo) puede ser más compleja.
En el modelo cliente-servidor, uno o varios servidores proporcionan recursos o servicios a varios nodos cliente. Los clientes envían peticiones al servidor, que las procesa y devuelve los resultados. Esta arquitectura se utiliza habitualmente en aplicaciones web y bases de datos.
Puede sonar parecido al modelo maestro-esclavo, en el que el servidor desempeña el papel de maestro, pero hay una diferencia: el servidor suele ser más pasivo y no divide ni delega tareas: sólo responde a las peticiones del cliente.
Con este modelo, la gestión y el control centralizados facilitan el mantenimiento y la actualización del sistema, pero el servidor es un cuello de botella que puede limitar la escalabilidad. La inactividad del servidor también puede perturbar todo el sistema.
Estas tres arquitecturas son algunas de las más comunes en los sistemas distribuidos, pero hay otros modelos con los que puede que te hayas topado (¡seguro que has oído hablar de la arquitectura basada en la nube!).
Cada modelo responde a necesidades diferentes, y la elección de la arquitectura puede tener un gran impacto en el rendimiento del sistema, la tolerancia a fallos y la escalabilidad, por lo que es importante trazar el problema que estás resolviendo antes de decidirte por un enfoque. Pero lo bueno es que ¡no tienes que elegir sólo uno! La mayoría de los sistemas modernos, especialmente en computación en la nubeutilizan una versión híbrida de estas arquitecturas para combinar sus mejores características.
Ahora que ya hemos cubierto la teoría de la informática distribuida, veamos cómo configurar realmente un sistema informático distribuido.
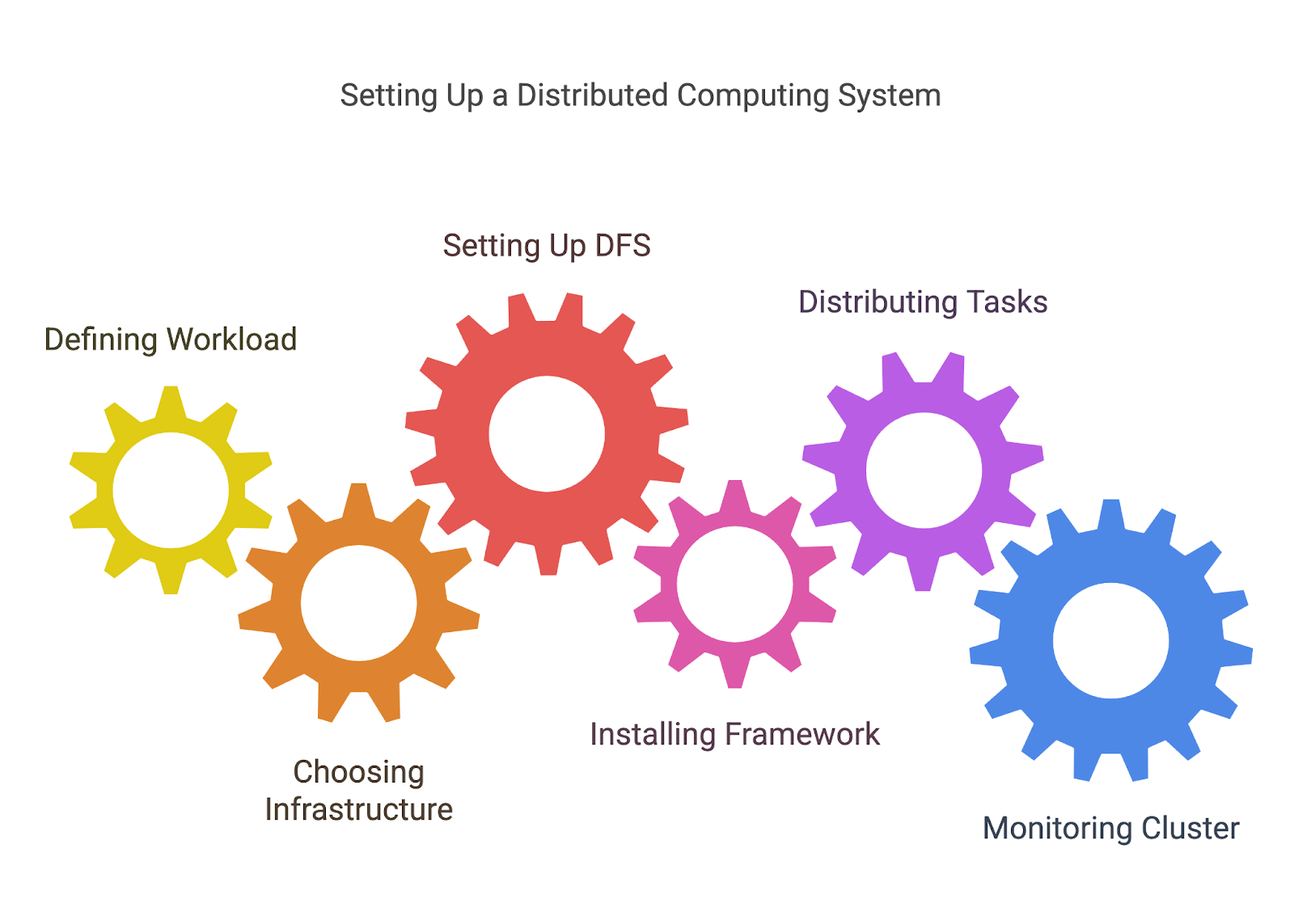
Antes de distribuir tareas, tienes que definir qué tareas vas a distribuir. Esto suele implicar descomponer un problema mayor en unidades de trabajo más pequeñas e independientes que puedan procesarse en paralelo o distribuirse entre nodos.
Por ejemplo, si estás procesando un gran conjunto de datos, puedes dividirlos en trozos que puedan ser manejados por diferentes máquinas o procesadores.
La informática distribuida requiere una red de máquinas, ya sean servidores locales, instancias en la nube (como AWS, Azureo Google Cloud), o incluso una mezcla de ambos. Tendrás que decidir cómo instalar y configurar estas máquinas, asegurándote de que están conectadas y pueden comunicarse entre sí.
Como hemos dicho antes, uno de los elementos más importantes de la informática distribuida es garantizar que todos los nodos tengan acceso a los datos que necesitan. HDFS de Hadoop u otras soluciones DFS te permiten almacenar grandes conjuntos de datos en varios nodos, con redundancia para garantizar que los datos no se pierdan si falla un nodo.
Una vez establecida tu infraestructura, tienes que configurar la herramienta que hayas elegido para la informática distribuida. Cada marco tendrá su propio proceso de instalación y configuración, pero esto puede implicar:
Una vez que tu entorno esté listo, puedes empezar a distribuir tareas entre tus nodos. La mayoría de las herramientas te ayudarán a gestionar este proceso dividiendo la carga de trabajo y asignando tareas a distintos nodos.
Normalmente tendrás que escribir código que defina cómo deben dividirse las tareas (trabajos MapReduce para Hadoop, transformaciones y acciones para Spark, etc.) o utilizar las API del marco para gestionar la distribución y comunicación entre nodos.
Los sistemas distribuidos pueden llegar a ser complejos, y hacer un seguimiento del rendimiento, los fallos y el uso de recursos es fundamental para asegurarse de que todo funciona correctamente. Muchas herramientas proporcionan cuadros de mando integrados para la supervisión, pero también puedes necesitar soluciones de supervisión adicionales (como Prometheus o Grafana) para realizar un seguimiento de la salud del nodo, el rendimiento y el progreso del trabajo.
Como acabamos de ver, la herramienta adecuada puede ayudarte a configurar la informática distribuida y hacer gran parte del trabajo pesado a la hora de gestionar tus entornos distribuidos. Echemos un vistazo a algunos de los más populares.
Apache Hadoop es un marco de código abierto diseñado para procesar enormes cantidades de datos en un clúster distribuido de ordenadores. Utiliza el modelo de programación MapReduce, que descompone las grandes tareas en trozos más pequeños y paralelizables.
Hadoop es especialmente útil para manejar petabytes de datos, y es genial por su escalabilidad, tolerancia a fallos y flexibilidad en el almacenamiento. Su ecosistema incluye varios componentes, como el Sistema de Archivos Distribuidos Hadoop (HDFS) para el almacenamiento distribuido y herramientas para el procesamiento por lotes, por lo que es una de las soluciones a las que recurren muchas aplicaciones de big data.
La configuración de la infraestructura en sí puede ser compleja, ya que sigue siendo necesario configurar los nodos, gestionar los recursos del clúster y garantizar la tolerancia a fallos.
Para saber más sobre Hadoop, lee este artículo sobre Preguntas de la entrevista sobre Hadoop. Es útil para preparar una entrevista y también está lleno de datos interesantes sobre la herramienta y sus casos de uso.
Apache Spark es un motor rápido y de propósito general para el procesamiento de datos a gran escala.
Al estar basado en Hadoop, Spark puede ejecutarse sobre clusters Hadoop existentes o sobre su propio gestor de clusters. Aunque a diferencia de Hadoop, que utiliza almacenamiento basado en disco, Spark ofrece computación en memoria, y puede procesar los datos significativamente más rápido.
Puede utilizarse para una amplia gama de tareas de procesamiento, como el procesamiento por lotes, el streaming en tiempo real, el aprendizaje automático y el procesamiento de gráficos. Admite lenguajes como Python, Scalay Java y se integra con plataformas en la nube como AWS y Azure.
¿Recuerdas cuando hablamos de la computación paralela? Bien, Dask es una biblioteca de computación paralela en Python diseñada para escalar desde una sola máquina hasta grandes clusters distribuidos.
Es una opción ideal para manejar grandes conjuntos de datos y tareas computacionales complejas, ya que se integra con otras bibliotecas de Python como NumPy, Pandas y Scikit-learn, y ofrece un entorno familiar para los usuarios de Python.
Su capacidad para trabajar tanto en entornos distribuidos como locales significa que puedes utilizarlo cuando trabajes en un proyecto pequeño o en una canalización de datos masiva. Todavía requiere cierto nivel de configuración para la computación distribuida, aunque gran parte de esto está automatizado en comparación con Hadoop y Spark.
Espero que hayas disfrutado aprendiendo los fundamentos de la informática distribuida. Pero este artículo es sólo el punto de partida. En el campo de la informática distribuida surgen cada año innumerables herramientas, marcos y técnicas.
Si quieres probar a crear sistemas distribuidos, te recomendaría que te dieras de alta en un proveedor en la nube como AWS o GCP. Ambos dan créditos al registrarse, ¡así que puedes probar su infraestructura y montar pequeños proyectos gratis!
Si ya te sientes cómodo con los conceptos básicos y quieres impulsar tu carrera en el campo de los datos, podrías cursar una de las muchas certificaciones Apache Spark disponibles en Internet.
¡Feliz codificación!
Aprende sobre la nube con estos cursos
Curso
Curso
Curso
blog
Mike Shakhomirov
11 min
blog
Zoumana Keita
14 min
blog
Matt Crabtree
15 min
Tutorial
Natassha Selvaraj
