Kurs
Cloud Computing verstehen
2 Std.
235.2K
Beim verteilten Rechnen arbeiten mehrere Computer gemeinsam an einem einzigen Problem. Anstatt sich auf eine einzige Maschine zu verlassen, teilen wir die Aufgaben in kleinere Stücke auf und weisen sie einem Netzwerk von Computern zu, die wir "Knoten" nennen. Diese Knotenpunkte teilen sich die Verarbeitungslast und die Datenspeicherung und arbeiten gemeinsam an der Erfüllung von Aufgaben.
Dieser Ansatz ist nützlich, wenn es um große Probleme oder Datensätze geht, die zu groß oder zu komplex sind, als dass ein einzelner Computer sie bearbeiten könnte. Ein verteiltes Rechensystem kann zum Beispiel Petabytes an Daten für Suchmaschinen verarbeiten, Simulationen für die wissenschaftliche Forschung durchführen oder Finanzmodelle für Marktanalysen betreiben.
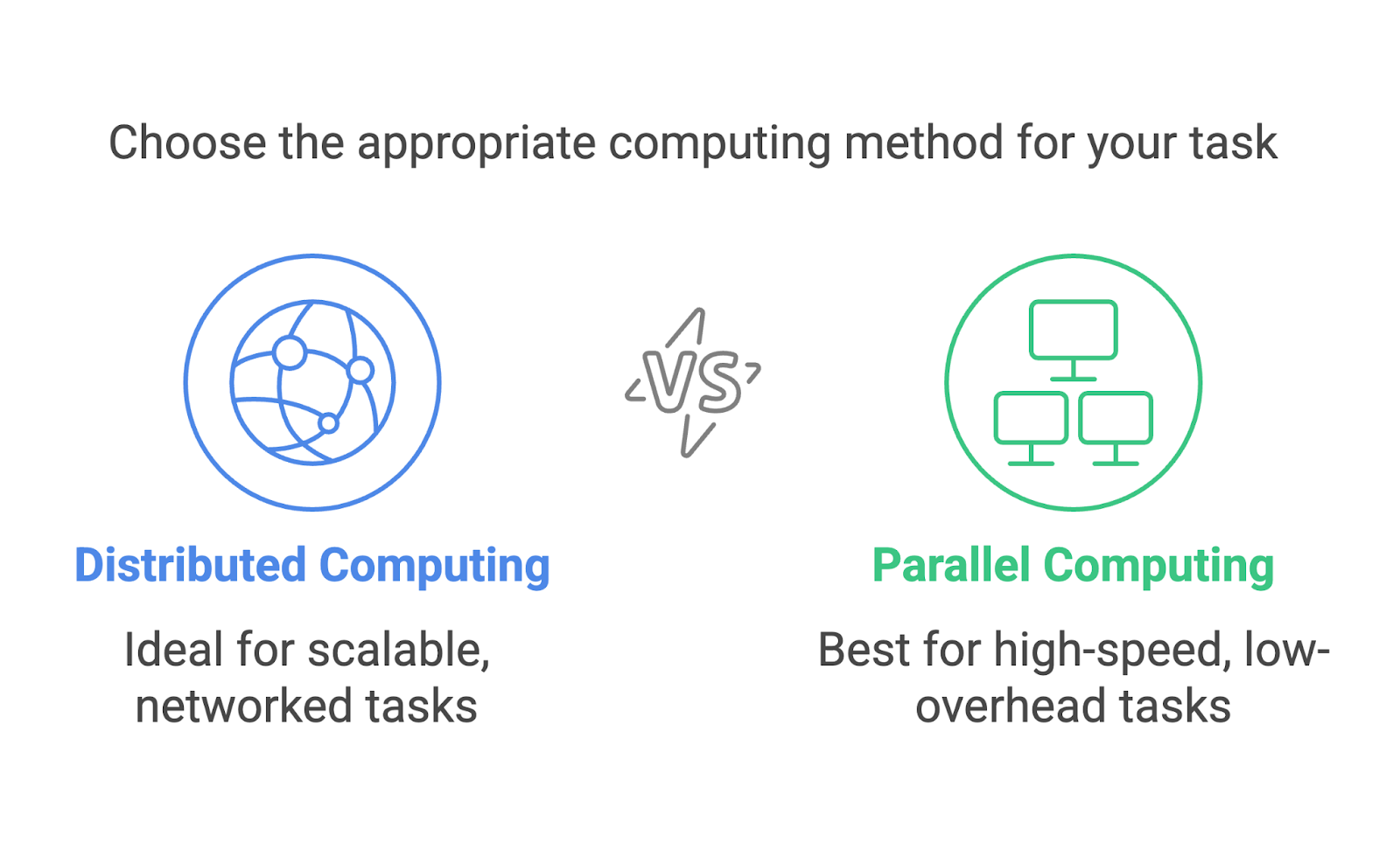
Verteiltes Rechnen und paralleles Rechnen werden oft verwechselt und scheinen austauschbar zu sein. Beide beinhalten mehrere Prozesse, die auf ein einziges Ziel hinarbeiten, aber sie sind unterschiedliche Ansätze, die für verschiedene Szenarien entwickelt wurden.
Verteiltes Rechnen konzentriert sich auf die Nutzung eines Netzwerks von einzelnen Rechnern, die oft geografisch verteilt sind, um gemeinsam Probleme zu lösen. Jede Maschine arbeitet als unabhängiger Knotenpunkt mit eigenem Speicher und eigener Rechenleistung. Die Kommunikation zwischen den Knoten erfolgt über ein Netzwerk, und die Aufgaben werden aufgeteilt, damit sie auf verschiedenen Rechnern laufen können.
Paralleles Rechnen hingegen findet normalerweise in einem einzigen System statt. Sie nutzt mehrere Prozessoren oder Kerne innerhalb eines Computers, um Aufgaben gleichzeitig auszuführen. Diese Prozessoren teilen sich denselben Speicher und arbeiten oft eng zusammen, um Berechnungen aufzuteilen.
Nehmen wir ein praktisches Beispiel und sagen wir, wir sortieren einen riesigen Datensatz. Beim parallelen Rechnen würden wir den Datensatz in Chunks aufteilen, und jeder Prozessor desselben Rechners würde einen Chunk bearbeiten. Bei der verteilten Datenverarbeitung wird der Datensatz aufgeteilt und an verschiedene Rechner geschickt, von denen jeder seinen Teil unabhängig sortiert. Die sortierten Teile werden dann zusammengeführt.
Beide Methoden sind unglaublich nützlich, aber sie eignen sich für unterschiedliche Aufgaben. Paralleles Rechnen ist ideal für Aufgaben, die eine hohe Rechengeschwindigkeit bei minimalem Kommunikationsaufwand erfordern, wie zum Beispiel Simulationen auf einem Supercomputer. Verteiltes Rechnen eignet sich besser für die Skalierung, z. B. bei der Verarbeitung von Daten in cloudbasierten Systemen oder in globalen Netzwerken.
Verteiltes Rechnen ist die Grundlage für einige der wichtigsten Anwendungen in unserer heutigen Welt. Werfen wir einen Blick auf drei gängige Anwendungsfälle: Suchmaschinen, wissenschaftliche Forschung und Finanzmodellierung.
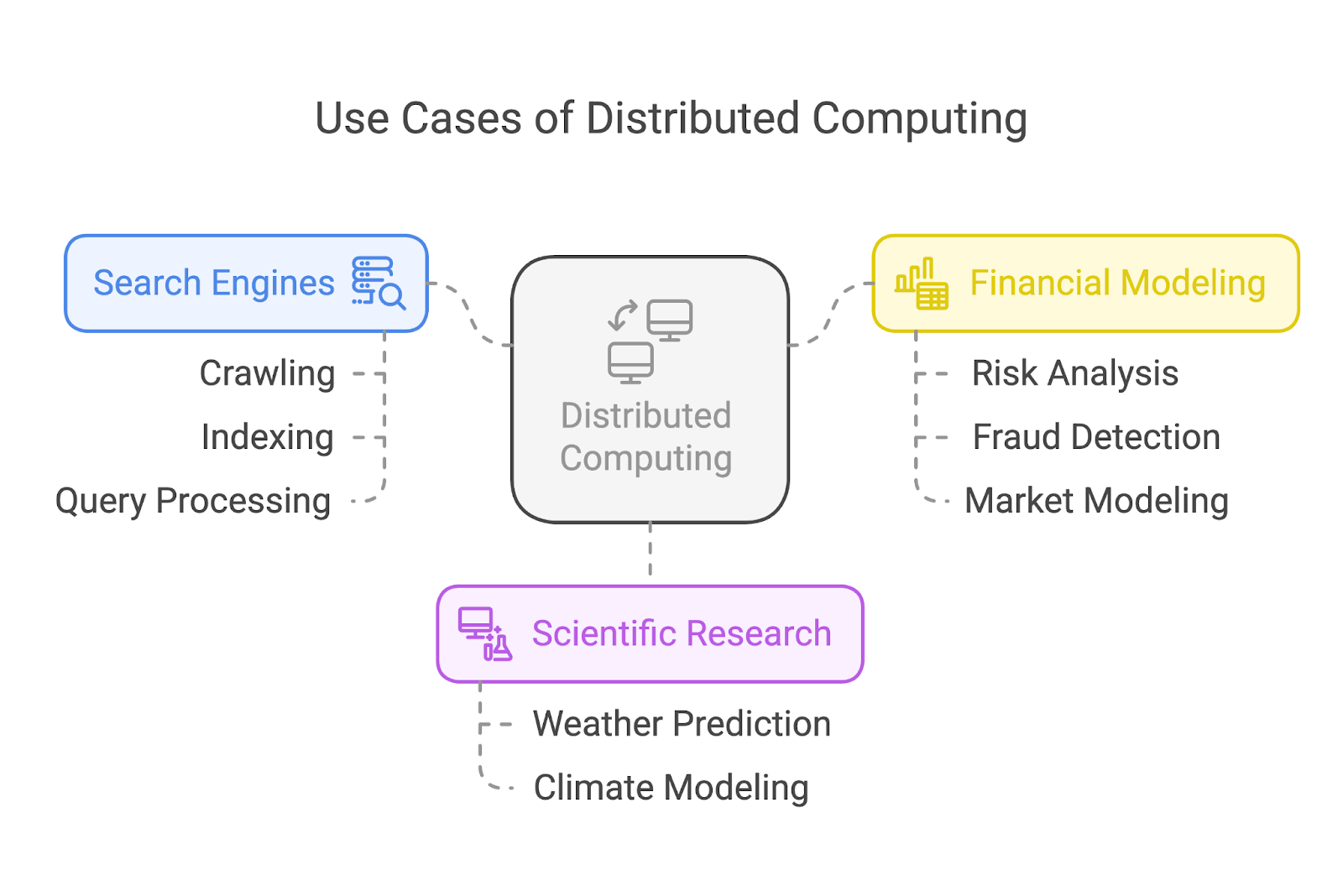
Suchmaschinen wie Google verlassen sich stark auf verteiltes Computing, um Milliarden von Webseiten zu crawlen und zu indizieren. Anstatt die Aufgabe einer einzelnen Maschine zuzuweisen, verteilen diese Systeme die Arbeitslast auf viele, viele Knotenpunkte.
Einige Knotenpunkte konzentrieren sich auf das Crawlen von Webseiten, andere kümmern sich um die Indizierung, und eine weitere Gruppe bearbeitet Nutzeranfragen in Echtzeit. Diese Arbeitsteilung sorgt für schnelle und effiziente Suchergebnisse, egal wie groß die Aufgabe ist.
In der wissenschaftlichen Forschung ermöglicht verteiltes Rechnen Durchbrüche, indem es komplexe Simulationen durchführt und riesige Datensätze analysiert. Klimawissenschaftler/innen nutzen zum Beispiel verteilte Systeme, um Wettermuster zu modellieren und vorherzusagen oder die Auswirkungen der globalen Erwärmung zu simulieren.
Die Finanzbranche setzt auf verteiltes Rechnen für Aufgaben wie Risikoanalyse, Betrugserkennung und Marktmodellierung.
Die Verarbeitung der riesigen Datenmengen, die die globalen Finanzmärkte erzeugen, erfordert Systeme, die rund um die Uhr und sehr schnell arbeiten können. Verteiltes Rechnen ermöglicht es Finanzunternehmen, Daten zu analysieren, Modelle zu testen und Erkenntnisse in einer Geschwindigkeit zu gewinnen, die sie auf Echtzeitmärkten wettbewerbsfähig macht.
Verteiltes Rechnen basiert auf einigen grundlegenden Bausteinen: Knoten, einem Netzwerk und einem verteilten Dateisystem (DFS).
Knotenpunkte sind die einzelnen Maschinen, die in einem verteilten System Berechnungen durchführen. Jeder Knotenpunkt kann unabhängig agieren, die ihm zugewiesenen Aufgaben bearbeiten und mit anderen Knotenpunkten kommunizieren, um Ergebnisse auszutauschen. In einigen Fällen können die Knotenpunkte spezielle Aufgaben haben, wie die Verwaltung von Aufgaben oder die Speicherung von Daten.
Das Netzwerk ist die Kommunikationsinfrastruktur, die die verschiedenen Knotenpunkte miteinander verbindet. Es ermöglicht ihnen, Daten auszutauschen und Aufgaben zu koordinieren. Je nach Größe des Systems kann es sich dabei um lokale Netzwerke (LANs) oder Weitverkehrsnetze (WANs) für geografisch verteilte Knotenpunkte handeln.
Ein verteiltes Dateisystem ist eine Speicherlösung, die den Zugriff auf Daten über mehrere Knotenpunkte hinweg ermöglicht. Ein beliebtes Beispiel ist das Hadoop Distributed File System (HDFS), das für große Datenmengen und Fehlertoleranz durch Replikation der Daten auf mehrere Knoten ausgelegt ist.
Okay, wir haben also eine Arbeitslast, die über ein Netzwerk auf verschiedene Knoten verteilt ist, und alle Knoten haben über ein DFS Zugriff auf die Daten. Aber wer entscheidet, welcher Knotenpunkt was tut?
Auf diese Fragen gibt es keine einheitliche Antwort, denn verteilte Computersysteme können auf unterschiedliche Weise organisiert werden. Dabei gibt es drei gängige Architekturen: Master-Slave, Peer-to-Peer und Client-Server.
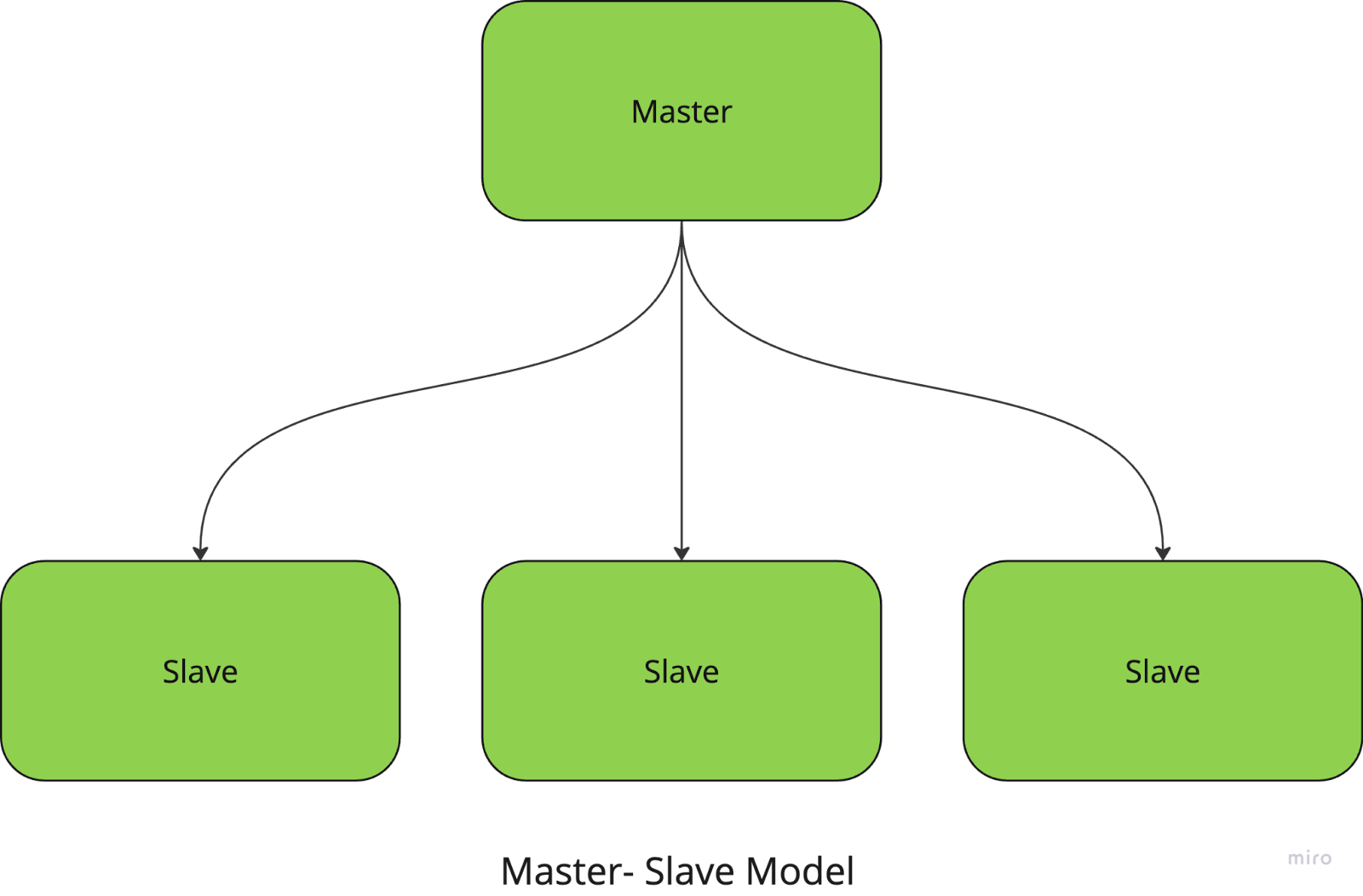
Beim Master-Slave-Modell verwaltet und koordiniert ein zentraler Knoten (der Master-Knoten) die Aufgaben, während die Slave-Knoten die eigentlichen Berechnungen durchführen. Der Master ist dafür verantwortlich, die Aufgaben in kleinere Stücke zu unterteilen, sie an die Slaves zu verteilen und die Ergebnisse zu sammeln.
Wenn du zum Beispiel eine große Bildverarbeitungsaufgabe durchführst, weist der Master-Knoten jedem Slave-Knoten einen bestimmten Teil der zu verarbeitenden Bilder zu. Sobald die Aufgaben erledigt sind, sammelt der Meister die Ergebnisse und fügt sie zum endgültigen Ergebnis zusammen.
Dieser Ansatz vereinfacht die Aufgabenverwaltung und -koordinierung, hat aber einen großen Nachteil: Das System hat einen Single Point of Failure, da es vollständig vom Masterknoten abhängt.
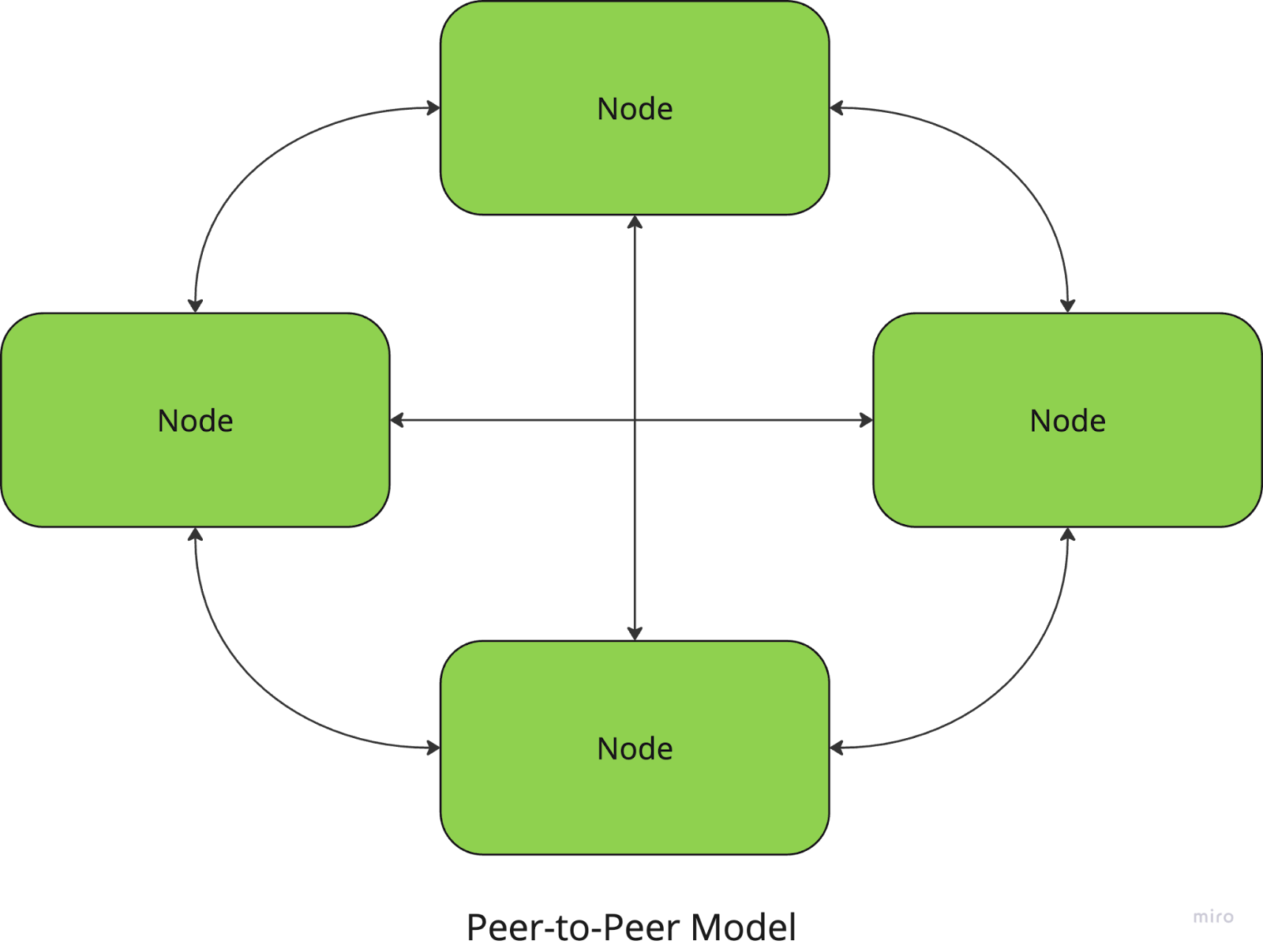
In der Peer-to-Peer-Architektur sind alle Knotenpunkte gleichberechtigt, und es gibt keinen zentralen Koordinator. Jeder Knotenpunkt kann sowohl als Client als auch als Server fungieren, Ressourcen gemeinsam nutzen und direkt mit anderen Knotenpunkten kommunizieren.
Filesharing-Netzwerke wie BitTorrent verwenden beispielsweise einen P2P-Ansatz, bei dem Nutzer/innen Dateien direkt von anderen Peers herunterladen und hochladen.
Der Vorteil ist, dass diese Systeme keinen zentralen Ausfallpunkt haben, was sie widerstandsfähig und skalierbar macht, aber die Koordination zwischen den Knotenpunkten (z. B. zur Gewährleistung der Datenkonsistenz) kann komplexer sein.
Beim Client-Server-Modell stellen ein oder mehrere Server Ressourcen oder Dienste für mehrere Client-Knoten bereit. Die Kunden senden Anfragen an den Server, der sie bearbeitet und die Ergebnisse zurücksendet. Diese Architektur wird häufig in Webanwendungen und Datenbanken verwendet.
Es klingt vielleicht ähnlich wie das Master-Slave-Modell, bei dem der Server die Rolle des Masters spielt, aber es gibt einen Unterschied: Der Server ist normalerweise passiver und teilt oder delegiert keine Aufgaben - er antwortet nur auf Client-Anfragen.
Bei diesem Modell erleichtert die zentrale Verwaltung und Kontrolle die Wartung und Aktualisierung des Systems, aber der Server ist ein Engpass, der die Skalierbarkeit einschränken kann. Ein Serverausfall kann auch das gesamte System stören.
Diese drei Architekturen gehören zu den gebräuchlichsten in verteilten Systemen, aber es gibt auch noch andere Modelle, die du vielleicht schon kennengelernt hast (ich bin sicher, du hast schon von der Cloud-basierten Architektur gehört!)
Jedes Modell erfüllt unterschiedliche Anforderungen, und die Wahl der Architektur kann sich stark auf die Systemleistung, Fehlertoleranz und Skalierbarkeit auswirken. Deshalb ist es wichtig, das Problem, das du lösen willst, genau zu beschreiben, bevor du dich für einen Ansatz entscheidest. Aber das Gute daran ist, dass du dich nicht nur für eine entscheiden musst! Die meisten modernen Systeme, insbesondere im Cloud Computingverwenden eine hybride Version dieser Architekturen, um ihre besten Eigenschaften zu kombinieren.
Nachdem wir uns nun mit der Theorie des verteilten Rechnens befasst haben, wollen wir uns ansehen, wie man ein verteiltes Rechensystem tatsächlich einrichtet.
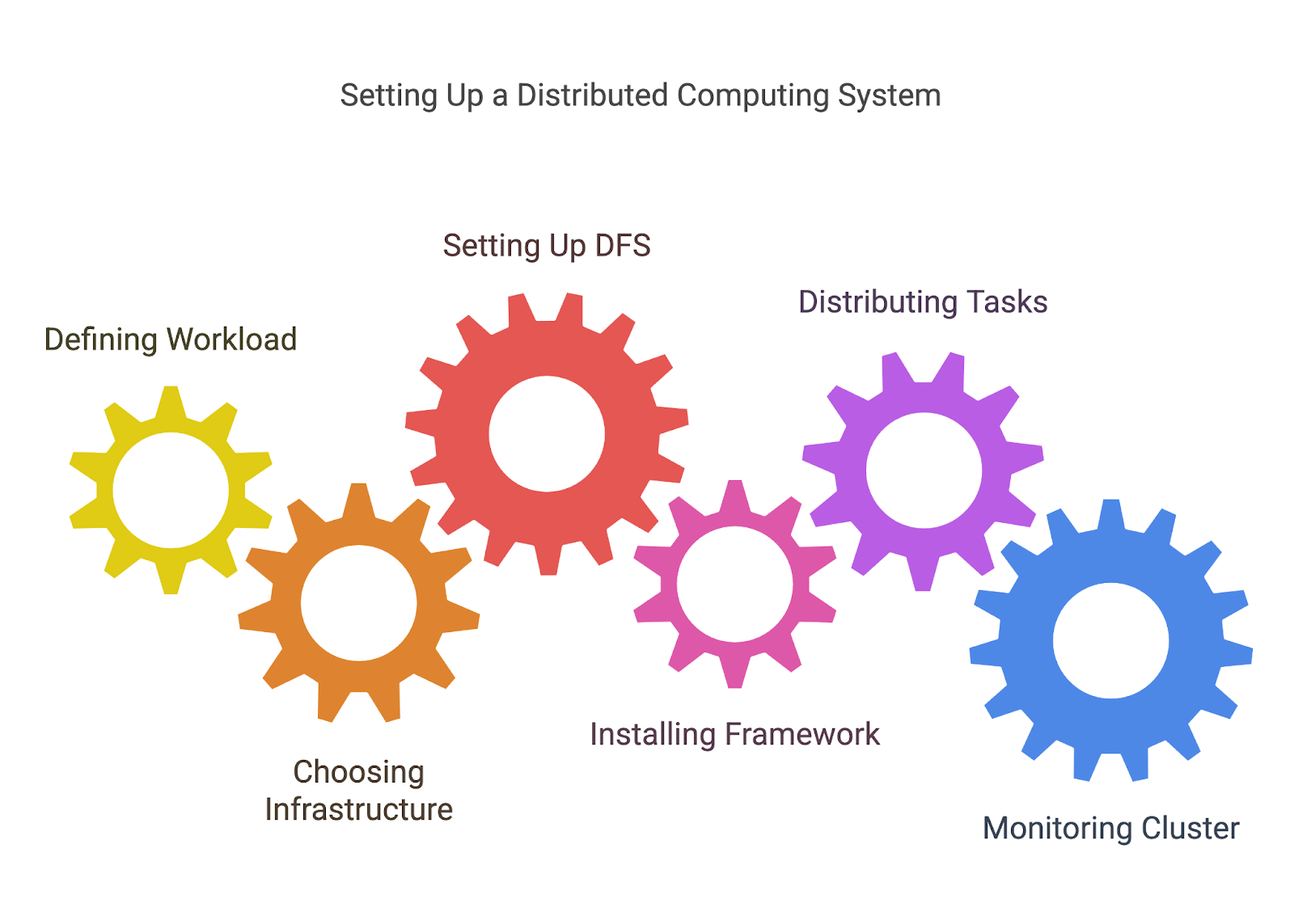
Bevor du Aufgaben verteilen kannst, musst du festlegen, welche Aufgaben du verteilst. Dabei wird ein größeres Problem oft in kleinere, unabhängige Arbeitseinheiten zerlegt, die parallel oder über Knotenpunkte verteilt bearbeitet werden können.
Wenn du zum Beispiel einen großen Datensatz verarbeitest, kannst du die Daten in Teile aufteilen, die von verschiedenen Maschinen oder Prozessoren bearbeitet werden können.
Verteiltes Rechnen erfordert ein Netzwerk von Rechnern, egal ob es sich um Server vor Ort, Cloud-Instanzen (wie AWS, Azure, oder Google Cloud), oder sogar eine Mischung aus beidem. Du musst entscheiden, wie du diese Maschinen einrichtest und konfigurierst, damit sie miteinander verbunden sind und miteinander kommunizieren können.
Wie wir bereits besprochen haben, ist es eines der wichtigsten Elemente beim verteilten Rechnen, sicherzustellen, dass alle Knotenpunkte Zugang zu den Daten haben, die sie benötigen. Hadoop's HDFS oder andere DFS-Lösungen ermöglichen es dir, große Datenmengen auf mehreren Knoten zu speichern, wobei Redundanz gewährleistet, dass die Daten nicht verloren gehen, wenn ein Knoten ausfällt.
Sobald deine Infrastruktur steht, musst du das Tool einrichten, das du für das verteilte Rechnen ausgewählt hast. Jedes Framework hat seinen eigenen Installations- und Konfigurationsprozess, der jedoch Folgendes beinhalten kann:
Sobald deine Umgebung fertig ist, kannst du damit beginnen, die Aufgaben auf deine Knotenpunkte zu verteilen. Die meisten Tools helfen dir bei diesem Prozess, indem sie deine Arbeitslast aufteilen und die Aufgaben verschiedenen Knotenpunkten zuweisen.
In der Regel musst du Code schreiben, der festlegt, wie Aufgaben aufgeteilt werden sollen (MapReduce-Jobs für Hadoop, Transformationen und Aktionen für Spark usw.), oder die APIs des Frameworks nutzen, um die Verteilung und Kommunikation zwischen den Knoten zu regeln.
Verteilte Systeme können sehr komplex werden, und es ist wichtig, die Leistung, Ausfälle und Ressourcennutzung im Auge zu behalten, um sicherzustellen, dass alles reibungslos funktioniert. Viele Tools bieten integrierte Dashboards für die Überwachung, aber Sie benötigen möglicherweise auch zusätzliche Überwachungslösungen (wie Prometheus oder Grafana), um den Zustand der Knoten, die Leistung und den Arbeitsfortschritt zu überwachen.
Wie wir gerade gesehen haben, kann dir das richtige Tool bei der Einrichtung des verteilten Computings helfen und dir einen Großteil der schweren Arbeit bei der Verwaltung deiner verteilten Umgebungen abnehmen. Schauen wir uns einige der beliebtesten genauer an.
Apache Hadoop ist ein Open-Source-Framework, das entwickelt wurde, um große Datenmengen in einem verteilten Cluster von Computern zu verarbeiten. Es verwendet das MapReduce-Programmiermodell, das große Aufgaben in kleinere, parallelisierbare Teile zerlegt.
Hadoop eignet sich besonders gut für die Verarbeitung von Petabytes an Daten und zeichnet sich durch Skalierbarkeit, Fehlertoleranz und Flexibilität bei der Speicherung aus. Sein Ökosystem umfasst verschiedene Komponenten wie das Hadoop Distributed File System (HDFS) für die verteilte Speicherung und Tools für die Stapelverarbeitung, weshalb es eine der bevorzugten Lösungen für viele Big Data-Anwendungen ist.
Die Einrichtung der Infrastruktur selbst kann komplex sein, da die Konfiguration der Knoten, die Verwaltung der Cluster-Ressourcen und die Sicherstellung der Fehlertoleranz erforderlich sind.
Um mehr über Hadoop zu erfahren, lies diesen Artikel über Hadoop Interview Fragen. Sie ist nützlich, wenn du dich auf ein Vorstellungsgespräch vorbereitest und enthält außerdem viele interessante Fakten über das Tool und seine Anwendungsfälle.
Apache Spark ist eine schnelle und universell einsetzbare Engine für die Verarbeitung großer Datenmengen.
Da es auf Hadoop basiert, kann Spark auf bestehenden Hadoop-Clustern oder auf einem eigenen Cluster-Manager laufen. Im Gegensatz zu Hadoop, das auf Festplattenspeicher basiert, bietet Spark In-Memory-Berechnungen und kann Daten deutlich schneller verarbeiten.
Sie kann für eine breite Palette von Verarbeitungsaufgaben eingesetzt werden, darunter Stapelverarbeitung, Echtzeit-Streaming, maschinelles Lernen und Graphenverarbeitung. Es unterstützt Sprachen wie Python, Scalaund Java und lässt sich mit Cloud-Plattformen wie AWS und Azure integrieren.
Erinnerst du dich, als wir über paralleles Rechnen gesprochen haben? Nun, Dask ist eine Bibliothek für parallele Berechnungen in Python, die für die Skalierung von einer einzelnen Maschine bis zu großen verteilten Clustern entwickelt wurde.
Es ist die ideale Wahl für die Bearbeitung großer Datenmengen und komplexer Berechnungsaufgaben, da es sich mit anderen Python-Bibliotheken wie NumPy, Pandas und Scikit-learn integrieren lässt und Python-Nutzern eine vertraute Umgebung bietet.
Dank seiner Fähigkeit, sowohl mit verteilten als auch mit lokalen Umgebungen zu arbeiten, kannst du es sowohl für kleine Projekte als auch für große Datenpipelines einsetzen. Für verteiltes Rechnen ist immer noch ein gewisses Maß an Konfiguration erforderlich, obwohl vieles davon im Vergleich zu Hadoop und Spark automatisiert ist.
Ich hoffe, es hat dir gefallen, mehr über die Grundlagen des verteilten Rechnens zu erfahren! Dieser Artikel ist jedoch nur der Ausgangspunkt. Im Bereich des verteilten Rechnens entstehen jedes Jahr unzählige Tools, Frameworks und Techniken.
Wenn du versuchen willst, verteilte Systeme zu erstellen, würde ich dir empfehlen, dich bei einem Cloud-Anbieter wie AWS oder GCP anzumelden. Beide geben bei der Anmeldung Credits, sodass du ihre Infrastruktur ausprobieren und kleine Projekte kostenlos einrichten kannst!
Wenn du bereits mit den Grundlagen vertraut bist und deine Datenkarriere vorantreiben möchtest, kannst du eine der vielen Apache Spark-Zertifizierungen die online verfügbar sind.
Viel Spaß beim Codieren!
Lerne die Cloud mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
