
Course
Understanding Cloud Computing
2 hr
234.6K
In distributed computing, we use multiple computers to work together on a single problem. Instead of relying on a single machine, we divide tasks into smaller chunks and assign them to a network of computers, which we call “nodes.” These nodes share the processing workload and data storage, working collaboratively to complete tasks.
This approach is useful when dealing with large-scale problems or datasets that are too big or complex for a single computer to handle. For example, a distributed computing system can process petabytes of data for search engines, run simulations for scientific research, or power financial models for market analysis.
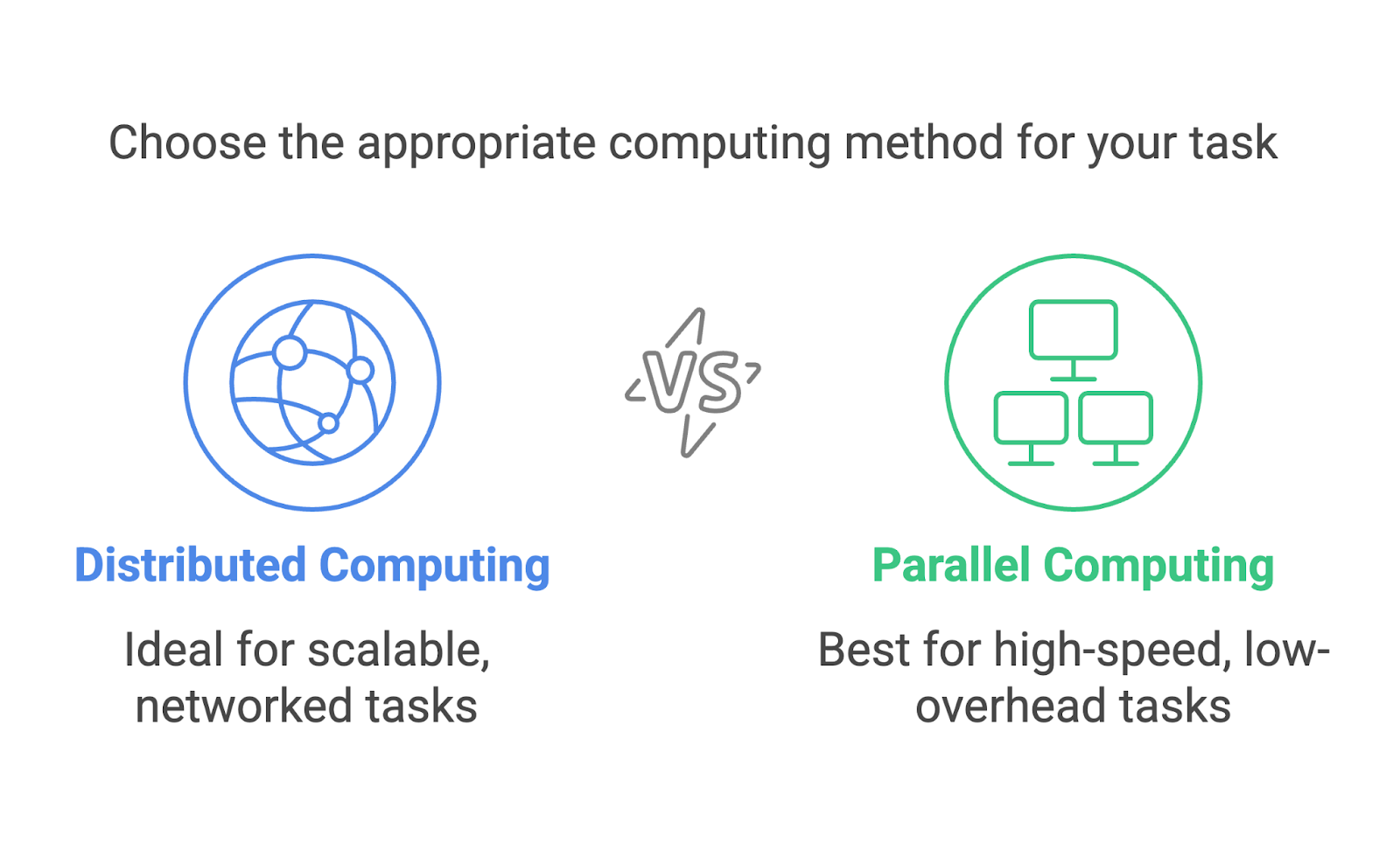
Distributed computing and parallel computing are often confused and might seem interchangeable. They both involve multiple processes working towards a single goal, but they are distinct approaches designed for different scenarios.
Distributed computing focuses on using a network of separate machines, often geographically dispersed, to solve problems collaboratively. Each machine operates as an independent node with its own memory and processing power. Communication between nodes happens over a network, and tasks are divided so they can run on different machines.
Parallel computing, on the other hand, typically takes place within a single system. It uses multiple processors or cores within one computer to execute tasks simultaneously. These processors share the same memory and often work closely together to split up computations.
Let’s take a practical example and say that we are sorting a massive dataset. In parallel computing, we would split the dataset into chunks, and each processor in the same machine will handle a chunk. In distributed computing, the dataset would be split and sent to different machines, each of which would then sort its portion independently. The sorted pieces will then be merged.
Both methods are incredibly useful but are suited to different tasks. Parallel computing is ideal for tasks that need high-speed computation with minimal communication overhead, like running simulations on a supercomputer. Distributed computing is better suited when scaling out, like when processing data in cloud-based systems or across global networks.
Distributed computing powers some of the most impactful applications in our world today. Let’s take a look at three common use cases: search engines, scientific research, and financial modeling.
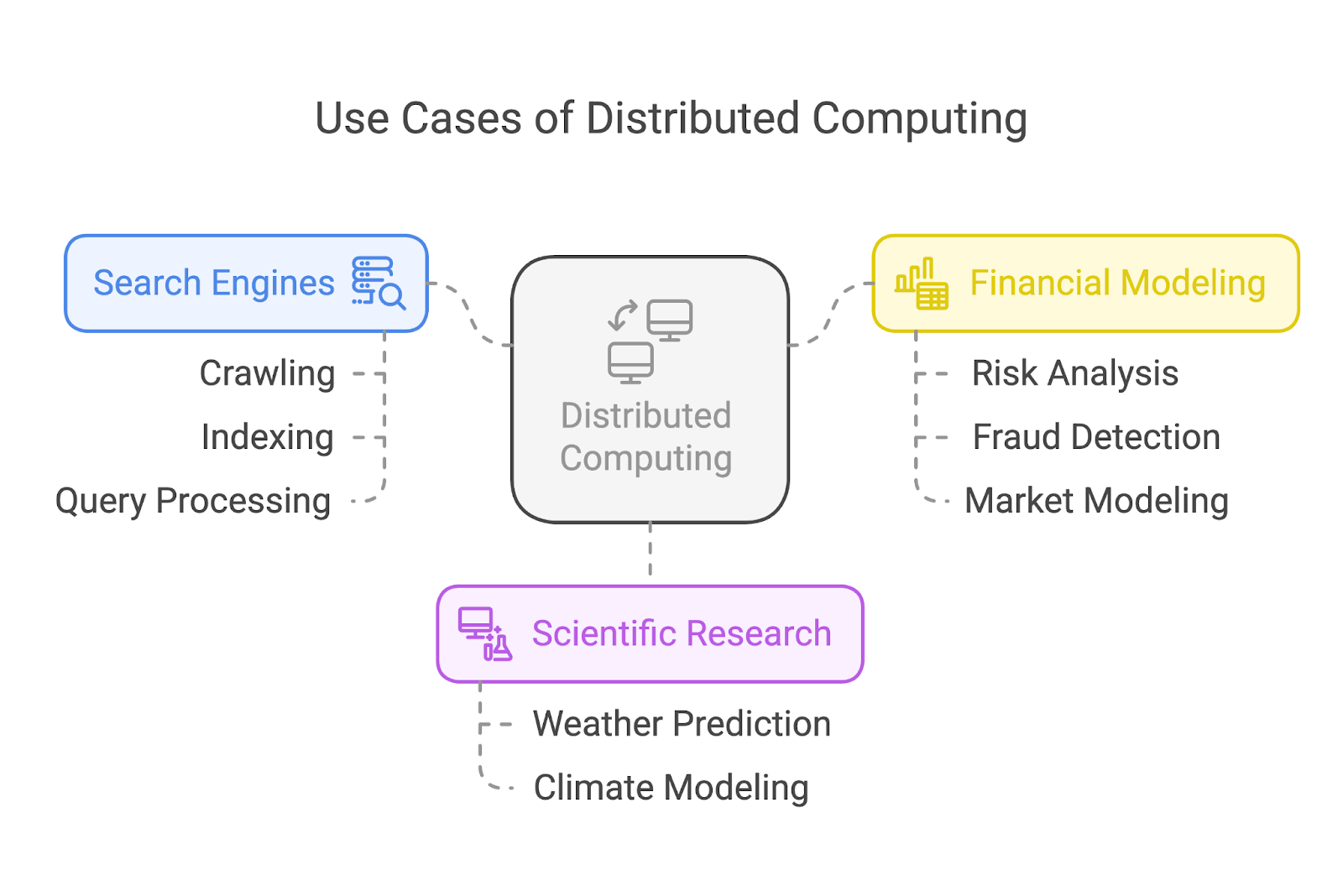
Search engines like Google rely heavily on distributed computing to crawl and index billions of web pages. Instead of assigning the task to a single machine, these systems divide the workload among many, many nodes.
Some nodes focus on crawling web pages, others handle indexing, and another group processes user queries in real time. This division of labor ensures fast and efficient search results, no matter the scale of the task.
In scientific research, distributed computing enables breakthroughs by running complex simulations and analyzing huge datasets. For instance, climate scientists use distributed systems to model and predict weather patterns or simulate the effects of global warming.
The financial industry relies on distributed computing for tasks like risk analysis, fraud detection, and market modeling.
Processing the huge datasets generated by global financial markets demands systems capable of working around the clock and very quickly. Distributed computing allows financial firms to analyze data, test models, and generate insights at speeds that keep them competitive in real-time markets.
Distributed computing relies on some fundamental building blocks: nodes, a network, and a distributed file system (DFS).
Nodes are the individual machines that perform computations within a distributed system. Each node can act independently, processing its assigned tasks and communicating with other nodes to share results. In some cases, nodes may have specialized roles, like managing tasks or storing data.
The network is the communication infrastructure that connects the different nodes. It allows them to exchange data and coordinate tasks. Depending on the system size, this can involve local area networks (LANs) or wide area networks (WANs) for geographically dispersed nodes.
A distributed file system is a storage solution that allows data to be accessed across multiple nodes. One popular example is the Hadoop Distributed File System (HDFS), which is designed to handle large datasets and provide fault tolerance by replicating data across multiple nodes.
Okay, so we have a workload distributed to different nodes through a network, and all the nodes have access to the data via a DFS. But who decides which node does what?
There is not a single answer to these questions because distributed computing systems can be organized in various ways. That said, there are three common architectures: master-slave, peer-to-peer, and client-server.
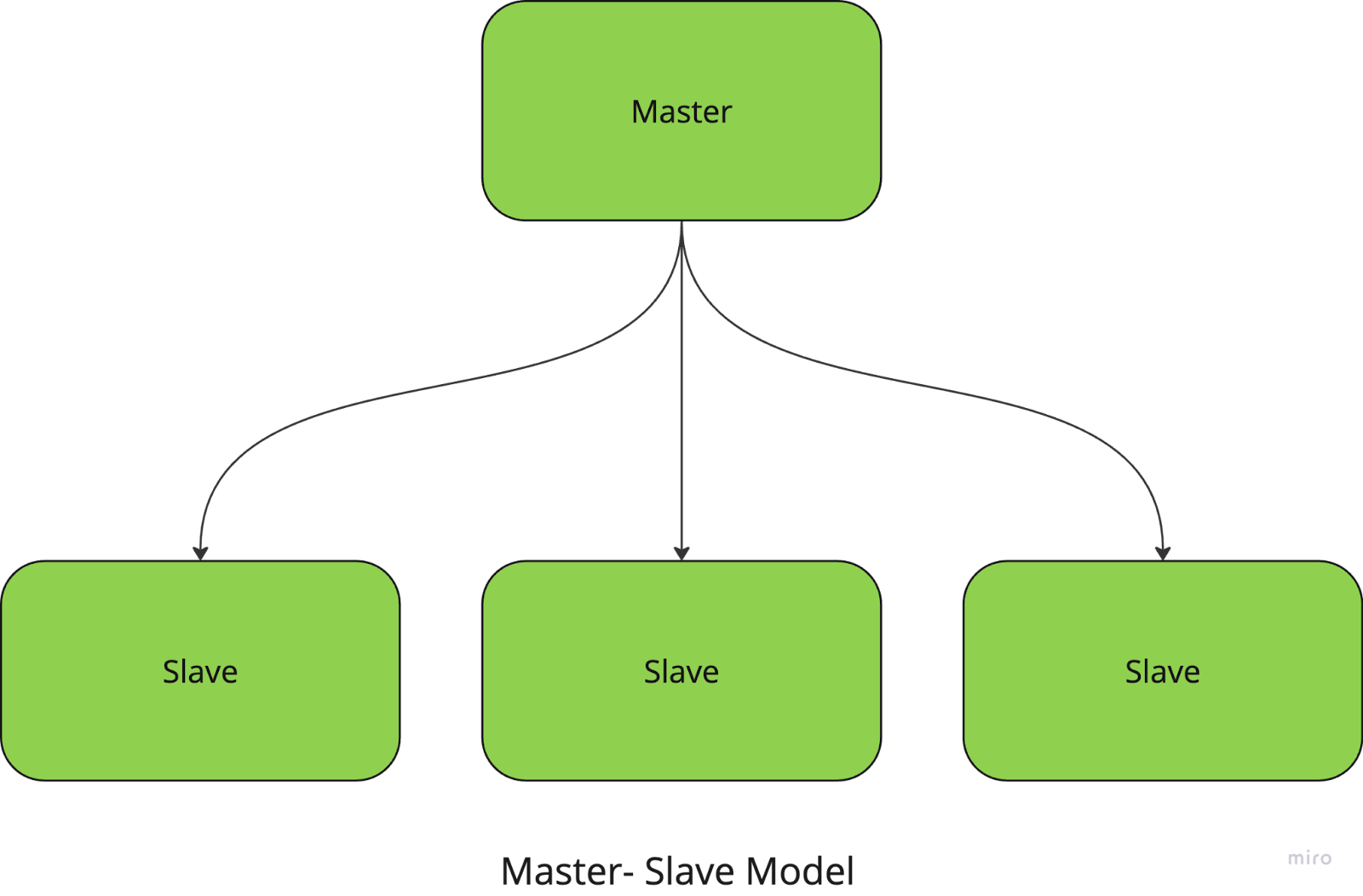
In the master-slave model, one central node (the master node) manages and coordinates tasks while the slave nodes execute the actual computations. The master is responsible for dividing tasks into smaller chunks, distributing them to slaves, and collecting the results.
For instance, if you’re running a large-scale image processing task, the master node assigns each slave node a specific portion of the images to process. Once the tasks are complete, the master gathers the results and combines them into the final output.
This approach simplifies task management and coordination but has a strong drawback: the system has a single point of failure since it depends entirely on the master node.
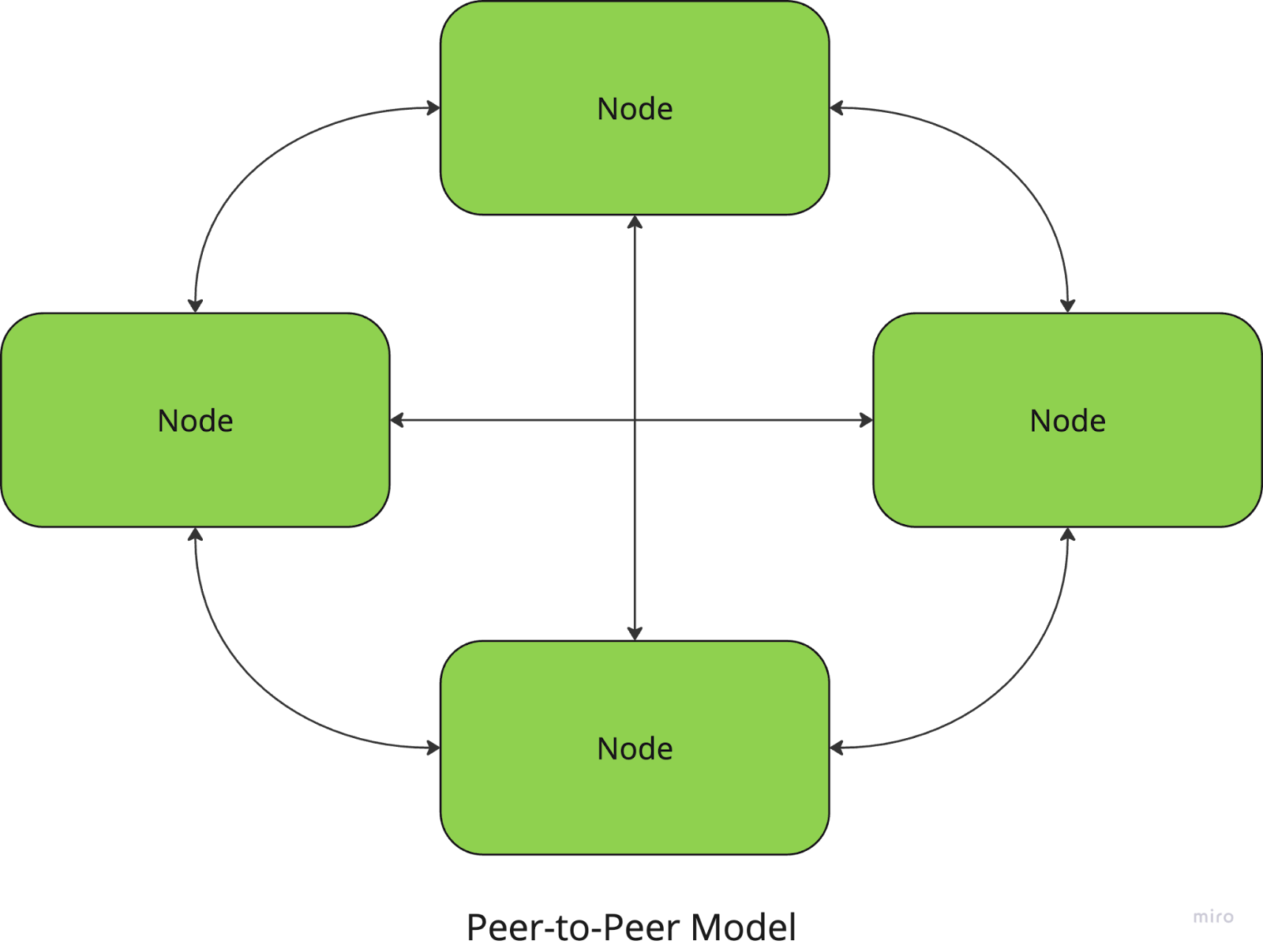
In peer-to-peer architecture, all nodes are equal, and there is no central coordinator. Each node can act as both a client and a server, sharing resources and communicating directly with other nodes.
For example, file-sharing networks like BitTorrent use a P2P approach, where users download and upload pieces of files directly from and to other peers.
On the plus side, these systems have no central point of failure, making them resilient and scalable, but the coordination between nodes (to ensure data consistency, for instance) can be more complex.
In the client-server model, one or more servers provide resources or services to multiple client nodes. Clients send requests to the server, which processes them and returns the results. This architecture is commonly used in web applications and databases.
It might sound similar to the master-slave model, with the server playing the role of the master, but there is a difference: the server is usually more passive and doesn’t split or delegate tasks—it just responds to client requests.
With this model, the centralized management and control make it easier to maintain and update the system, but the server is a bottleneck that can limit scalability. Server downtime can also disrupt the entire system.
These three architectures are some of the most common in distributed systems, but there are other models you may have come across (I am sure you have heard of cloud-based architecture!).
Each model serves different needs, and the choice of architecture can have a big impact on system performance, fault tolerance, and scalability, so it's important to map out the problem you're solving before deciding on an approach. But the good thing is, you don’t have to choose just one! Most modern systems, especially in cloud computing, use a hybrid version of these architectures to combine their best features.
Now that we’ve covered the theory behind distributed computing, let’s look at how to actually set up a distributed computing system.
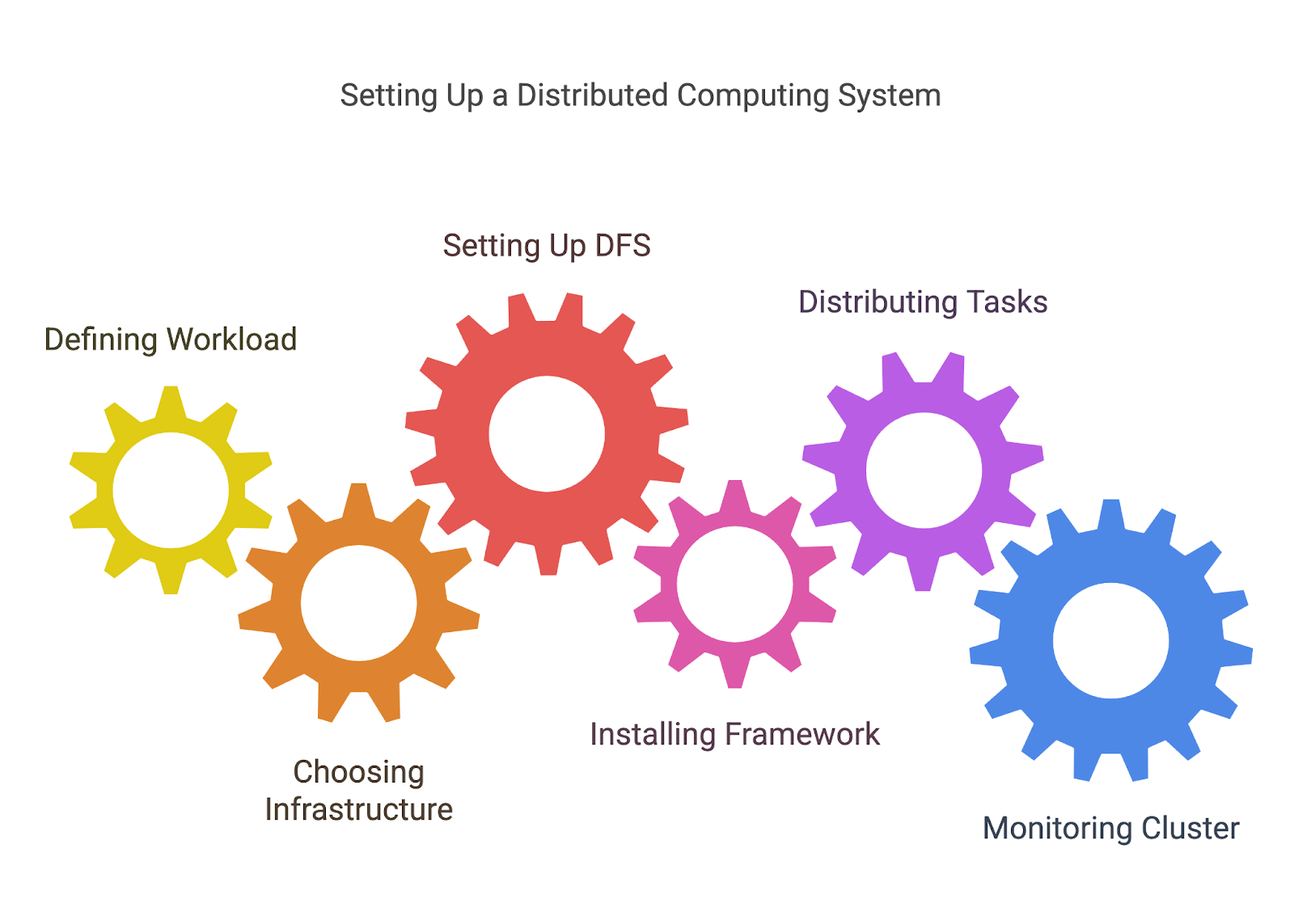
Before you can distribute tasks, you need to define what tasks you're distributing. This often involves breaking down a larger problem into smaller, independent units of work that can be processed in parallel or distributed across nodes.
For instance, if you're processing a large dataset, you might divide the data into chunks that can be handled by different machines or processors.
Distributed computing requires a network of machines, whether they're on-premises servers, cloud instances (like AWS, Azure, or Google Cloud), or even a mix of both. You’ll need to decide how to set up and configure these machines, ensuring they’re connected and can communicate with each other.
As we have discussed before, one of the most important elements in distributed computing is ensuring that all nodes have access to the data they need. Hadoop’s HDFS or other DFS solutions allow you to store large datasets across multiple nodes, with redundancy to ensure data isn’t lost if a node fails.
Once your infrastructure is in place, you need to set up the tool you’ve chosen for distributed computing. Each framework will have its own installation and configuration process, but this might involve:
Once your environment is ready, you can begin distributing tasks across your nodes. Most tools will help you manage this process by splitting your workload and assigning tasks to different nodes.
You’ll usually need to write code that defines how tasks should be split (MapReduce jobs for Hadoop, transformations and actions for Spark, etc.) or use the framework’s APIs to handle the distribution and communication between nodes.
Distributed systems can become complex, and keeping track of performance, failures, and resource usage is critical to make sure everything is running smoothly. Many tools provide built-in dashboards for monitoring, but you may also need additional monitoring solutions (like Prometheus or Grafana) to keep track of node health, performance, and job progress.
As we have just seen, the right tool can help you get set up with distributed computing and do much of the heavy lifting when managing your distributed environments. Let’s take a closer look at some of the most popular ones.
Apache Hadoop is an open-source framework designed to process huge amounts of data across a distributed cluster of computers. It uses the MapReduce programming model, which breaks down large tasks into smaller, parallelizable chunks.
Hadoop is particularly useful for handling petabytes of data, and is great for scalability, fault tolerance, and flexibility in storage. Its ecosystem includes various components like the Hadoop Distributed File System (HDFS) for distributed storage and tools for batch processing, which is why it is one of the go-to solutions for many big data applications.
The infrastructure setup itself can be complex, as it still requires configuring the nodes, managing cluster resources, and ensuring fault tolerance.
To learn more about Hadoop, read this article on Hadoop Interview Questions. It is useful when preparing for an interview and is also full of interesting facts about the tool and its use cases.
Apache Spark is a fast and general-purpose engine for large-scale data processing.
Because it is based on Hadoop, Spark can run on top of existing Hadoop clusters or on its own cluster manager. Though unlike Hadoop, which uses disk-based storage, Spark offers in-memory computation, and can process data significantly faster.
It can be used for a wide range of processing tasks, including batch processing, real-time streaming, machine learning, and graph processing. It supports languages like Python, Scala, and Java and integrates with cloud platforms like AWS and Azure.
Remember when we talked about parallel computing? Well, Dask is a parallel computing library in Python that is designed to scale from a single machine to large distributed clusters.
It is an ideal choice for handling large datasets and complex computational tasks since it integrates with other Python libraries like NumPy, Pandas, and Scikit-learn and offers a familiar environment for Python users.
Its ability to work with both distributed and local environments means you can use it when working on a small project or a massive data pipeline. It still requires some level of configuration for distributed computing, although much of this is automated compared to Hadoop and Spark.
I hope you enjoyed learning about the basics of distributed computing! This article is only the starting point, though. The field of distributed computing has countless tools, frameworks, and techniques emerging every year.
If you want to try creating distributed systems, I would recommend signing up to a cloud provider like AWS or GCP. They both give credits on sign up, so you can try their infrastructure and set up small projects for free!
If you are already comfortable with the basics and want to boost your data career, you could take one of the many Apache Spark certifications available online.
Happy coding!
Learn cloud with these courses!
Course
Course
Course
blog
Alex Castrounis
13 min
blog
Adejumo Ridwan Suleiman
13 min
blog
Alex Casalboni
12 min
blog
Kurtis Pykes
13 min
Tutorial
DataCamp Team
Tutorial
Kurtis Pykes
