Curso
Entendendo a computação em nuvem
2 h
235.2K
Na computação distribuída, usamos vários computadores para trabalhar juntos em um único problema. Em vez de depender de uma única máquina, dividimos as tarefas em partes menores e as atribuímos a uma rede de computadores, que chamamos de "nós". Esses nós compartilham a carga de trabalho de processamento e o armazenamento de dados, trabalhando de forma colaborativa para concluir as tarefas.
Essa abordagem é útil quando você lida com problemas de grande escala ou conjuntos de dados que são grandes ou complexos demais para serem tratados por um único computador. Por exemplo, um sistema de computação distribuída pode processar petabytes de dados para mecanismos de pesquisa, executar simulações para pesquisa científica ou alimentar modelos financeiros para análise de mercado.
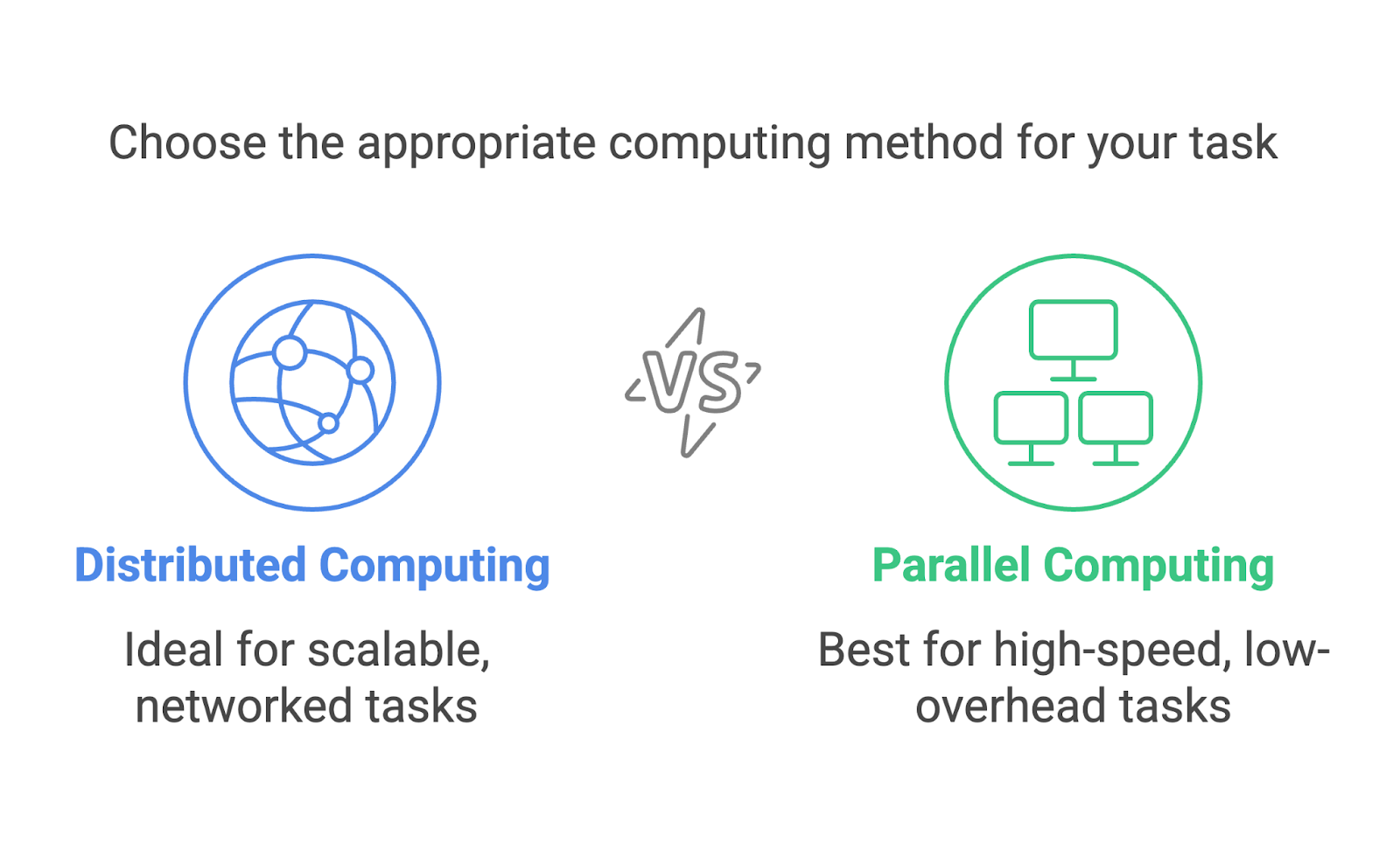
A computação distribuída e a computação paralela são frequentemente confundidas e podem parecer intercambiáveis. Ambas envolvem vários processos que trabalham para atingir um único objetivo, mas são abordagens distintas projetadas para cenários diferentes.
A computação distribuída se concentra no uso de uma rede de máquinas separadas, geralmente dispersas geograficamente, para resolver problemas de forma colaborativa. Cada máquina opera como um nó independente com sua própria memória e capacidade de processamento. A comunicação entre os nós ocorre por meio de uma rede, e as tarefas são divididas para que possam ser executadas em máquinas diferentes.
A computação paralela, por outro lado, geralmente ocorre em um único sistema. Ele usa vários processadores ou núcleos em um computador para executar tarefas simultaneamente. Esses processadores compartilham a mesma memória e geralmente trabalham em conjunto para dividir os cálculos.
Vamos dar um exemplo prático e dizer que estamos classificando um grande conjunto de dados. Na computação paralela, dividiríamos o conjunto de dados em partes, e cada processador na mesma máquina lidaria com uma parte. Na computação distribuída, o conjunto de dados seria dividido e enviado a diferentes máquinas, cada uma das quais classificaria sua parte independentemente. Em seguida, as partes classificadas serão mescladas.
Ambos os métodos são incrivelmente úteis, mas são adequados para tarefas diferentes. A computação paralela é ideal para tarefas que precisam de computação de alta velocidade com sobrecarga mínima de comunicação, como a execução de simulações em um supercomputador. A computação distribuída é mais adequada para o dimensionamento, como no processamento de dados em sistemas baseados em nuvem ou em redes globais.
A computação distribuída alimenta alguns dos aplicativos mais impactantes do mundo atual. Vamos dar uma olhada em três casos de uso comuns: mecanismos de busca, pesquisa científica e modelagem financeira.
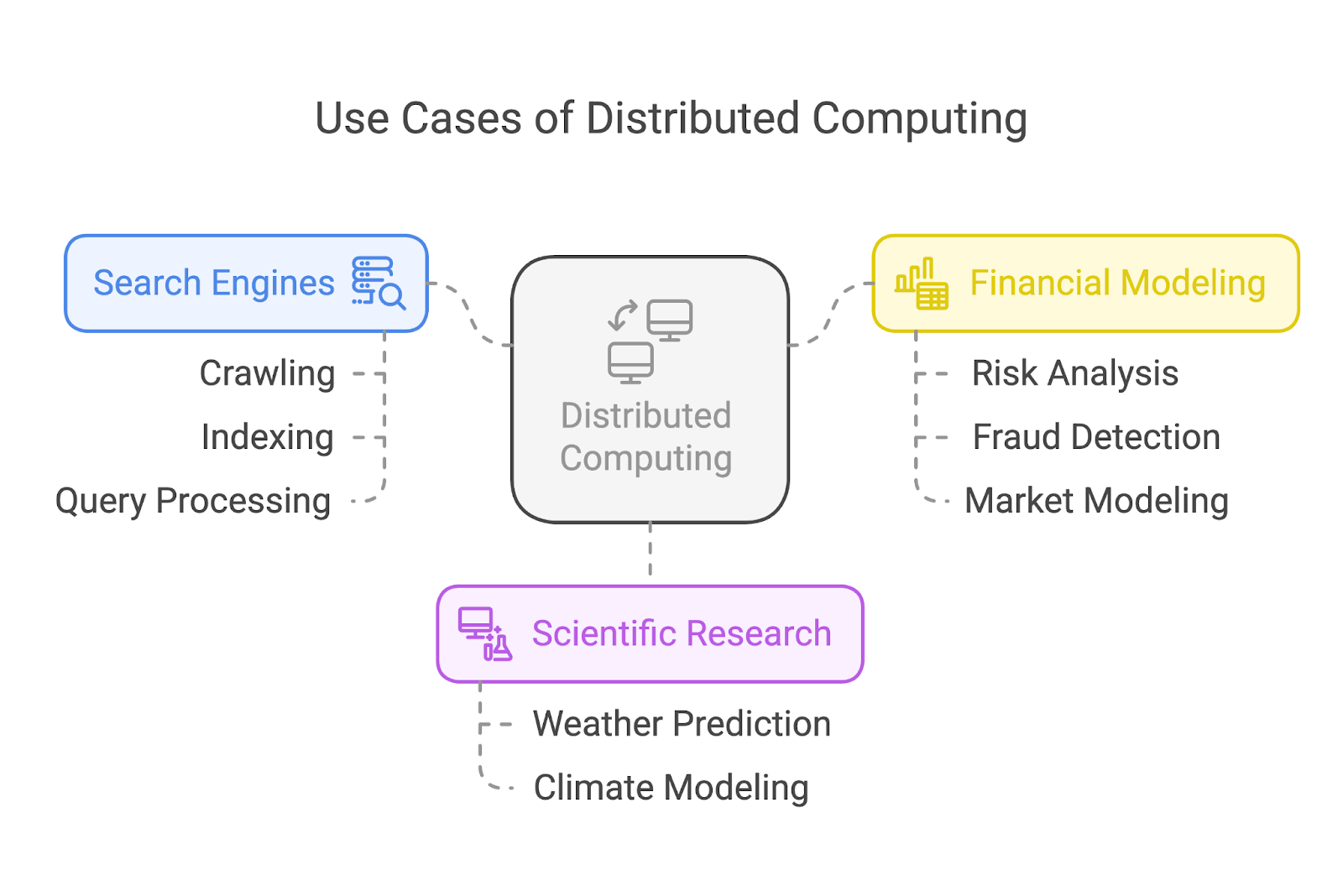
Mecanismos de pesquisa como o Google dependem muito da computação distribuída para rastrear e indexar bilhões de páginas da Web. Em vez de atribuir a tarefa a uma única máquina, esses sistemas dividem a carga de trabalho entre muitos, muitos nós.
Alguns nós se concentram no rastreamento de páginas da Web, outros lidam com a indexação e outro grupo processa as consultas dos usuários em tempo real. Essa divisão de trabalho garante resultados de pesquisa rápidos e eficientes, independentemente da escala da tarefa.
Na pesquisa científica, a computação distribuída permite avanços ao executar simulações complexas e analisar enormes conjuntos de dados. Por exemplo, os cientistas do clima usam sistemas distribuídos para modelar e prever padrões climáticos ou simular os efeitos do aquecimento global.
O setor financeiro depende da computação distribuída para tarefas como análise de risco, detecção de fraude e modelagem de mercado.
O processamento dos enormes conjuntos de dados gerados pelos mercados financeiros globais exige sistemas capazes de trabalhar 24 horas por dia e com muita rapidez. A computação distribuída permite que as empresas financeiras analisem dados, testem modelos e gerem percepções em velocidades que as mantenham competitivas em mercados em tempo real.
A computação distribuída depende de alguns blocos de construção fundamentais: nós, uma rede e um sistema de arquivos distribuídos (DFS).
Os nós são as máquinas individuais que realizam cálculos em um sistema distribuído. Cada nó pode agir independentemente, processando suas tarefas atribuídas e comunicando-se com outros nós para compartilhar resultados. Em alguns casos, os nós podem ter funções especializadas, como gerenciar tarefas ou armazenar dados.
A rede é a infraestrutura de comunicação que conecta os diferentes nós. Isso permite que eles troquem dados e coordenem tarefas. Dependendo do tamanho do sistema, isso pode envolver redes de área local (LANs) ou redes de área ampla (WANs) para nós geograficamente dispersos.
Um sistema de arquivos distribuído é uma solução de armazenamento que permite que os dados sejam acessados em vários nós. Um exemplo popular é o HDFS (Hadoop Distributed File System), que foi projetado para lidar com grandes conjuntos de dados e oferecer tolerância a falhas por meio da replicação de dados em vários nós.
Então, temos uma carga de trabalho distribuída para diferentes nós por meio de uma rede, e todos os nós têm acesso aos dados por meio de um DFS. Mas quem decide qual nó faz o quê?
Não há uma única resposta para essas perguntas porque os sistemas de computação distribuída podem ser organizados de várias maneiras. Dito isso, há três arquiteturas comuns: mestre-escravo, ponto a ponto e cliente-servidor.
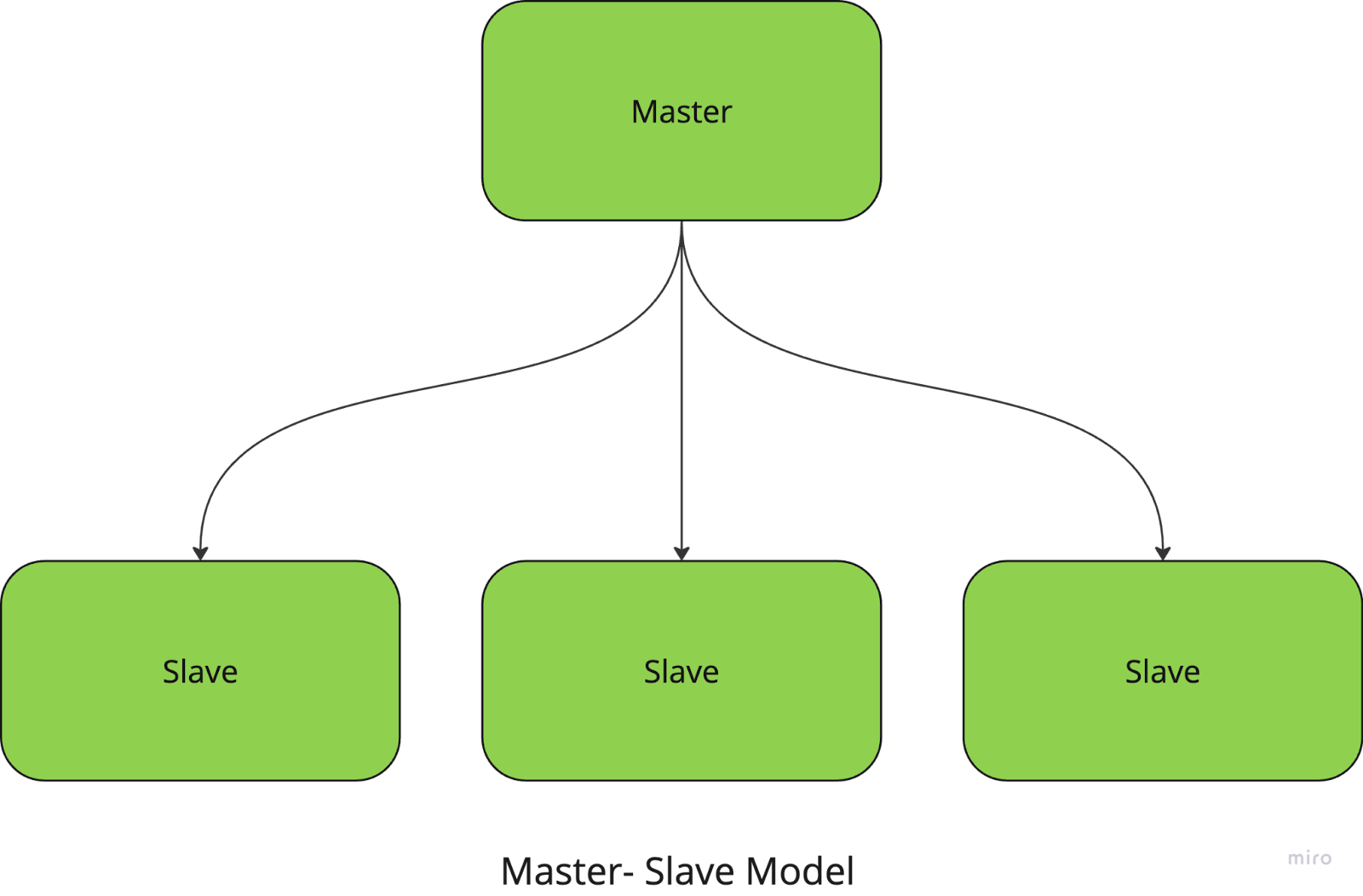
No modelo mestre-escravo, um nó central (o nó mestre) gerencia e coordena as tarefas, enquanto os nós escravos executam os cálculos reais. O mestre é responsável por dividir as tarefas em partes menores, distribuí-las aos escravos e coletar os resultados.
Por exemplo, se você estiver executando uma tarefa de processamento de imagens em grande escala, o nó mestre atribui a cada nó escravo uma parte específica das imagens a serem processadas. Depois que as tarefas são concluídas, o mestre reúne os resultados e os combina no resultado final.
Essa abordagem simplifica o gerenciamento e a coordenação de tarefas, mas tem uma grande desvantagem: o sistema tem um único ponto de falha, pois depende totalmente do nó mestre.
Na arquitetura ponto a ponto, todos os nós são iguais e não há um coordenador central. Cada nó pode atuar tanto como cliente quanto como servidor, compartilhando recursos e comunicando-se diretamente com outros nós.
Por exemplo, redes de compartilhamento de arquivos como a BitTorrent usam uma abordagem P2P, em que os usuários fazem download e upload de partes de arquivos diretamente de e para outros pares.
O lado positivo é que esses sistemas não têm um ponto central de falha, o que os torna resilientes e dimensionáveis, mas a coordenação entre os nós (para garantir a consistência dos dados, por exemplo) pode ser mais complexa.
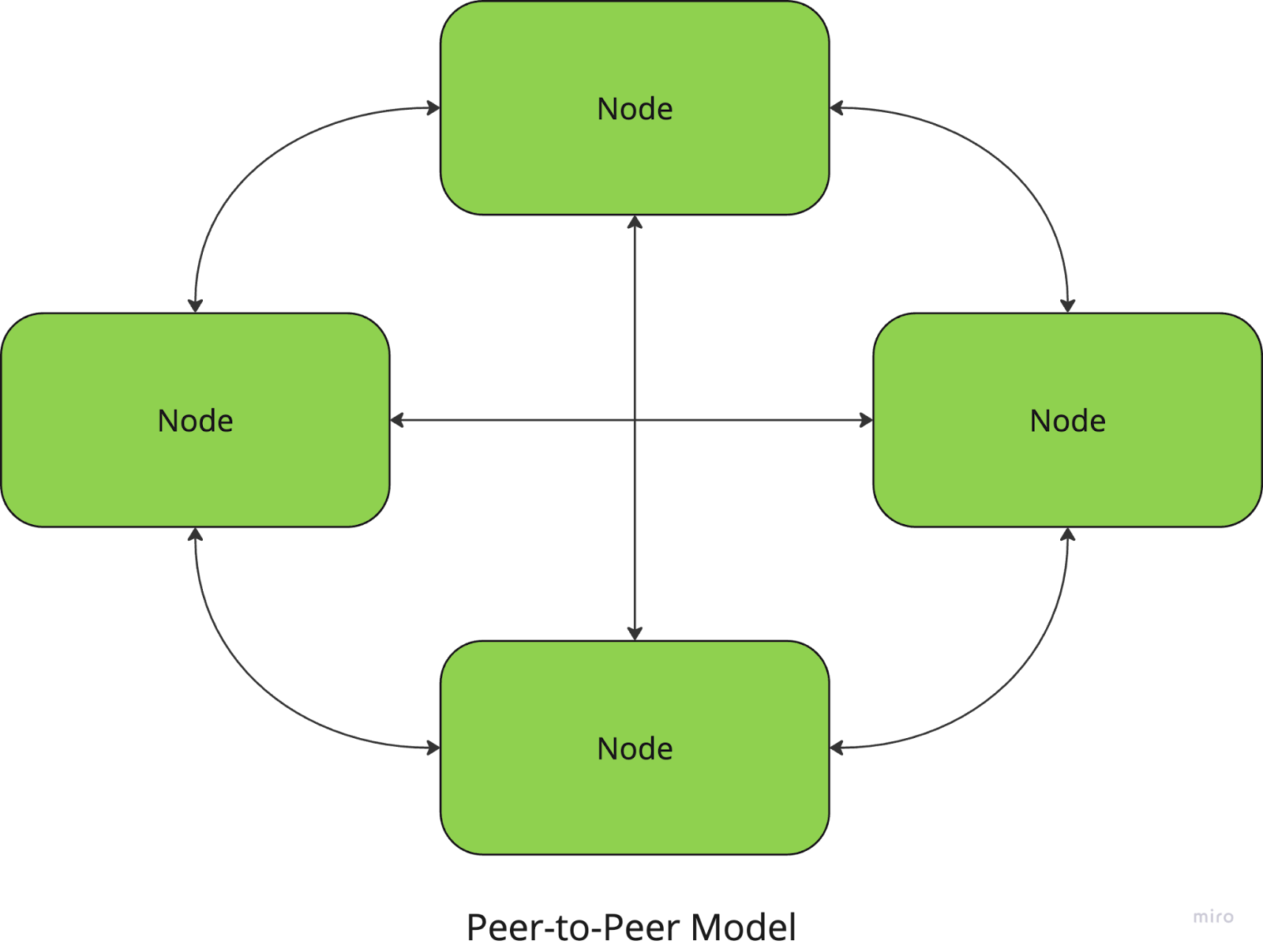
No modelo cliente-servidor, um ou mais servidores fornecem recursos ou serviços a vários nós de clientes. Os clientes enviam solicitações ao servidor, que as processa e retorna os resultados. Essa arquitetura é comumente usada em aplicativos da Web e bancos de dados.
Pode parecer semelhante ao modelo mestre-escravo, com o servidor desempenhando o papel de mestre, mas há uma diferença: o servidor geralmente é mais passivo e não divide nem delega tarefas - ele apenas responde às solicitações do cliente.
Com esse modelo, o gerenciamento e o controle centralizados facilitam a manutenção e a atualização do sistema, mas o servidor é um gargalo que pode limitar a escalabilidade. O tempo de inatividade do servidor também pode interromper todo o sistema.
Essas três arquiteturas são algumas das mais comuns em sistemas distribuídos, mas há outros modelos com os quais você já deve ter se deparado (tenho certeza de que você já ouviu falar da arquitetura baseada em nuvem!).
Cada modelo atende a necessidades diferentes, e a escolha da arquitetura pode ter um grande impacto no desempenho do sistema, na tolerância a falhas e na escalabilidade, por isso é importante mapear o problema que você está resolvendo antes de decidir sobre uma abordagem. Mas a boa notícia é que você não precisa escolher apenas um! A maioria dos sistemas modernos, especialmente na computação em nuvemusam uma versão híbrida dessas arquiteturas para combinar seus melhores recursos.
Agora que já abordamos a teoria por trás da computação distribuída, vamos ver como você pode realmente configurar um sistema de computação distribuída.
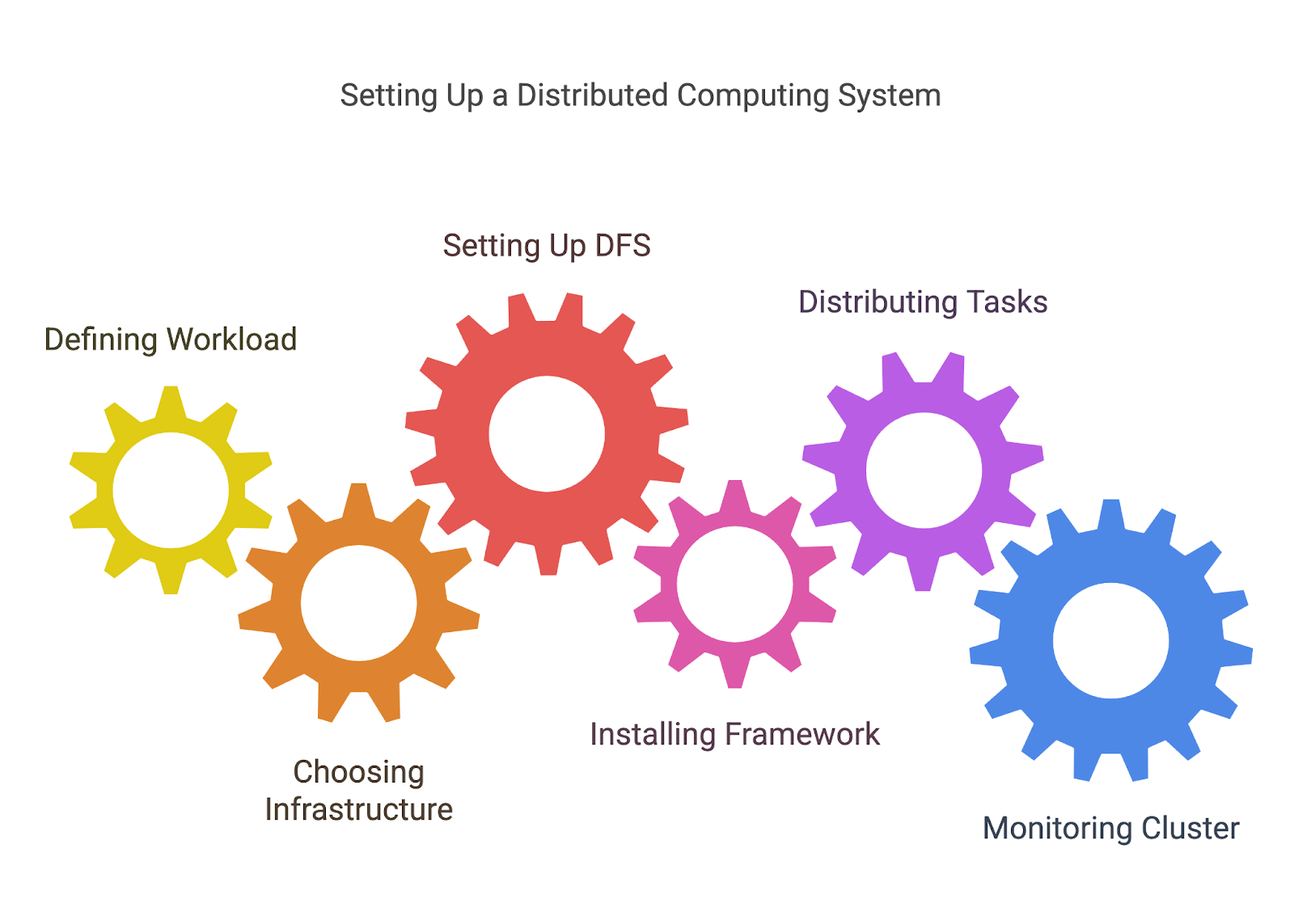
Antes de distribuir tarefas, você precisa definir quais tarefas estão sendo distribuídas. Isso geralmente envolve a divisão de um problema maior em unidades de trabalho menores e independentes que podem ser processadas em paralelo ou distribuídas entre nós.
Por exemplo, se estiver processando um grande conjunto de dados, você pode dividi-los em partes que podem ser tratadas por diferentes máquinas ou processadores.
A computação distribuída requer uma rede de máquinas, sejam elas servidores locais, instâncias de nuvem (como o AWS, Azureou Google Cloud), ou até mesmo uma combinação de ambos. Você precisará decidir como instalar e configurar essas máquinas, garantindo que elas estejam conectadas e possam se comunicar entre si.
Como discutimos anteriormente, um dos elementos mais importantes da computação distribuída é garantir que todos os nós tenham acesso aos dados de que precisam. O HDFS do Hadoop ou outras soluções DFS permitem que você armazene grandes conjuntos de dados em vários nós, com redundância para garantir que os dados não sejam perdidos se um nó falhar.
Quando a infraestrutura estiver pronta, você precisará configurar a ferramenta escolhida para a computação distribuída. Cada estrutura terá seu próprio processo de instalação e configuração, mas isso pode envolver:
Quando o ambiente estiver pronto, você poderá começar a distribuir tarefas entre os nós. A maioria das ferramentas ajudará você a gerenciar esse processo, dividindo a carga de trabalho e atribuindo tarefas a nós diferentes.
Normalmente, você precisará escrever um código que defina como as tarefas devem ser divididas (trabalhos de MapReduce para o Hadoop, transformações e ações para o Spark etc.) ou usar as APIs da estrutura para lidar com a distribuição e a comunicação entre os nós.
Os sistemas distribuídos podem se tornar complexos, e acompanhar o desempenho, as falhas e o uso de recursos é fundamental para garantir que tudo esteja funcionando sem problemas. Muitas ferramentas fornecem painéis integrados para monitoramento, mas você também pode precisar de soluções de monitoramento adicionais (como o Prometheus ou Grafana) para que você possa acompanhar a integridade do nó, o desempenho e o progresso do trabalho.
Como acabamos de ver, a ferramenta certa pode ajudar você a se preparar para a computação distribuída e fazer grande parte do trabalho pesado ao gerenciar seus ambientes distribuídos. Vamos dar uma olhada mais de perto em alguns dos mais populares.
O Apache Hadoop é uma estrutura de código aberto projetada para processar grandes quantidades de dados em um cluster distribuído de computadores. Ele usa o modelo de programação MapReduce, que divide tarefas grandes em partes menores e paralelizáveis.
O Hadoop é particularmente útil para lidar com petabytes de dados e é excelente para escalabilidade, tolerância a falhas e flexibilidade no armazenamento. Seu ecossistema inclui vários componentes, como o HDFS (Hadoop Distributed File System) para armazenamento distribuído e ferramentas para processamento em lote, e é por isso que ele é uma das soluções ideais para muitos aplicativos de Big Data.
A configuração da infraestrutura em si pode ser complexa, pois ainda requer a configuração dos nós, o gerenciamento dos recursos do cluster e a garantia de tolerância a falhas.
Para saber mais sobre o Hadoop, leia este artigo sobre Perguntas da entrevista sobre o Hadoop. Ele é útil na preparação para uma entrevista e também está repleto de fatos interessantes sobre a ferramenta e seus casos de uso.
O Apache Spark é um mecanismo rápido e de uso geral para processamento de dados em grande escala.
Por ser baseado no Hadoop, o Spark pode ser executado em clusters existentes do Hadoop ou em seu próprio gerenciador de clusters. Embora, ao contrário do Hadoop, que usa armazenamento baseado em disco, o Spark oferece computação na memória e pode processar dados com muito mais rapidez.
Ele pode ser usado para uma ampla gama de tarefas de processamento, incluindo processamento em lote, streaming em tempo real, aprendizado de máquina e processamento de gráficos. Ele oferece suporte a linguagens como Python, Scalae Java e se integra a plataformas de nuvem como AWS e Azure.
Você se lembra de quando falamos sobre computação paralela? Bem, Dask é uma biblioteca de computação paralela em Python que foi projetada para ser dimensionada de uma única máquina para grandes clusters distribuídos.
É a opção ideal para lidar com grandes conjuntos de dados e tarefas computacionais complexas, pois se integra a outras bibliotecas Python, como NumPy, Pandas e Scikit-learn, e oferece um ambiente familiar para os usuários de Python.
Sua capacidade de trabalhar com ambientes distribuídos e locais significa que você pode usá-lo ao trabalhar em um projeto pequeno ou em um pipeline de dados enorme. Ele ainda exige algum nível de configuração para computação distribuída, embora grande parte disso seja automatizada em comparação com o Hadoop e o Spark.
Espero que você tenha gostado de aprender sobre os conceitos básicos da computação distribuída! No entanto, este artigo é apenas o ponto de partida. O campo da computação distribuída tem inúmeras ferramentas, estruturas e técnicas que surgem a cada ano.
Se você quiser tentar criar sistemas distribuídos, recomendo que se inscreva em um provedor de nuvem como AWS ou GCP. Ambos dão créditos na inscrição, para que você possa experimentar a infraestrutura deles e configurar pequenos projetos gratuitamente!
Se você já estiver familiarizado com os conceitos básicos e quiser impulsionar sua carreira em dados, poderá fazer uma das muitas certificações do Apache Spark disponíveis on-line.
Boa codificação!
Aprenda a usar a nuvem com estes cursos!
Curso
Curso
Curso
blog
Mike Shakhomirov
11 min
blog
Moez Ali
15 min
blog
Abid Ali Awan
7 min
blog
Matt Crabtree
15 min
blog
DataCamp Team
11 min


