Cours
Comprendre le cloud
2 h
234.6K
Dans l'informatique distribuée, nous utilisons plusieurs ordinateurs pour travailler ensemble sur un même problème. Au lieu de dépendre d'une seule machine, nous divisons les tâches en petits morceaux et les assignons à un réseau d'ordinateurs, que nous appelons "nœuds". Ces nœuds partagent la charge de travail et le stockage des données et travaillent en collaboration pour accomplir les tâches.
Cette approche est utile lorsqu'il s'agit de traiter des problèmes à grande échelle ou des ensembles de données trop volumineux ou trop complexes pour être traités par un seul ordinateur. Par exemple, un système informatique distribué peut traiter des pétaoctets de données pour les moteurs de recherche, exécuter des simulations pour la recherche scientifique ou alimenter des modèles financiers pour l'analyse des marchés.
L'informatique distribuée et l'informatique parallèle sont souvent confondues et peuvent sembler interchangeables. Elles impliquent toutes deux des processus multiples visant un objectif unique, mais il s'agit d'approches distinctes conçues pour des scénarios différents.
L'informatique distribuée se concentre sur l'utilisation d'un réseau de machines distinctes, souvent dispersées géographiquement, pour résoudre des problèmes en collaboration. Chaque machine fonctionne comme un nœud indépendant avec sa propre mémoire et sa propre puissance de traitement. La communication entre les nœuds se fait par l'intermédiaire d'un réseau, et les tâches sont divisées de manière à pouvoir être exécutées sur différentes machines.
Le calcul parallèle, quant à lui, s'effectue généralement au sein d'un système unique. Il utilise plusieurs processeurs ou cœurs au sein d'un ordinateur pour exécuter des tâches simultanément. Ces processeurs partagent la même mémoire et travaillent souvent en étroite collaboration pour diviser les calculs.
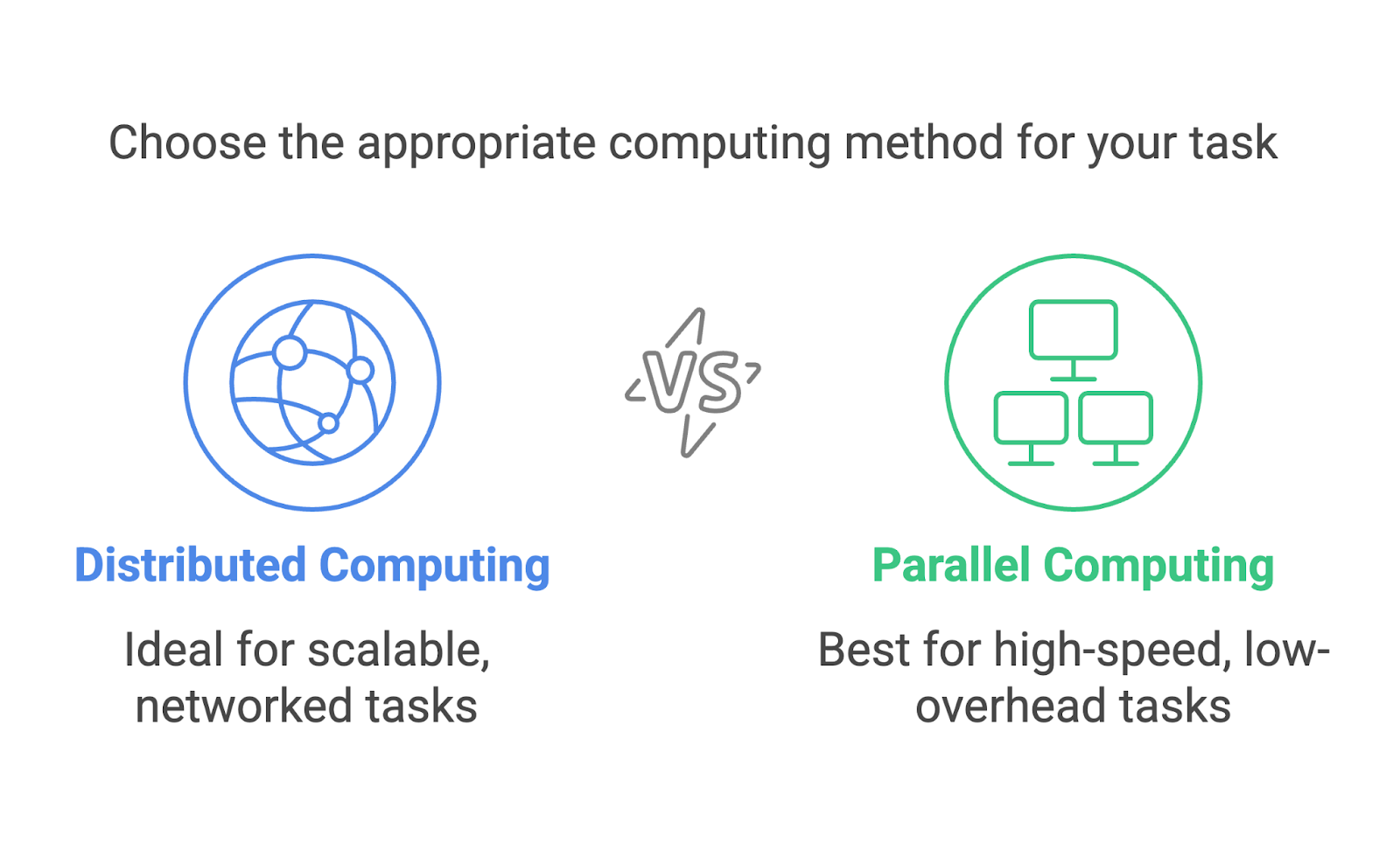
Prenons un exemple pratique et disons que nous trions un énorme ensemble de données. En informatique parallèle, nous divisons l'ensemble de données en morceaux, et chaque processeur de la même machine traite un morceau. Dans le cadre de l'informatique distribuée, l'ensemble de données est divisé et envoyé à différentes machines, chacune d'entre elles triant ensuite sa partie de manière indépendante. Les pièces triées seront ensuite fusionnées.
Les deux méthodes sont extrêmement utiles, mais elles sont adaptées à des tâches différentes. L'informatique parallèle est idéale pour les tâches qui nécessitent des calculs à grande vitesse avec un minimum de communication, comme l'exécution de simulations sur un superordinateur. L'informatique distribuée est mieux adaptée à la mise à l'échelle, comme le traitement de données dans des systèmes basés sur le cloud ou sur des réseaux mondiaux.
L'informatique distribuée est à l'origine de certaines des applications les plus importantes dans le monde d'aujourd'hui. Examinons trois cas d'utilisation courants : les moteurs de recherche, la recherche scientifique et la modélisation financière.
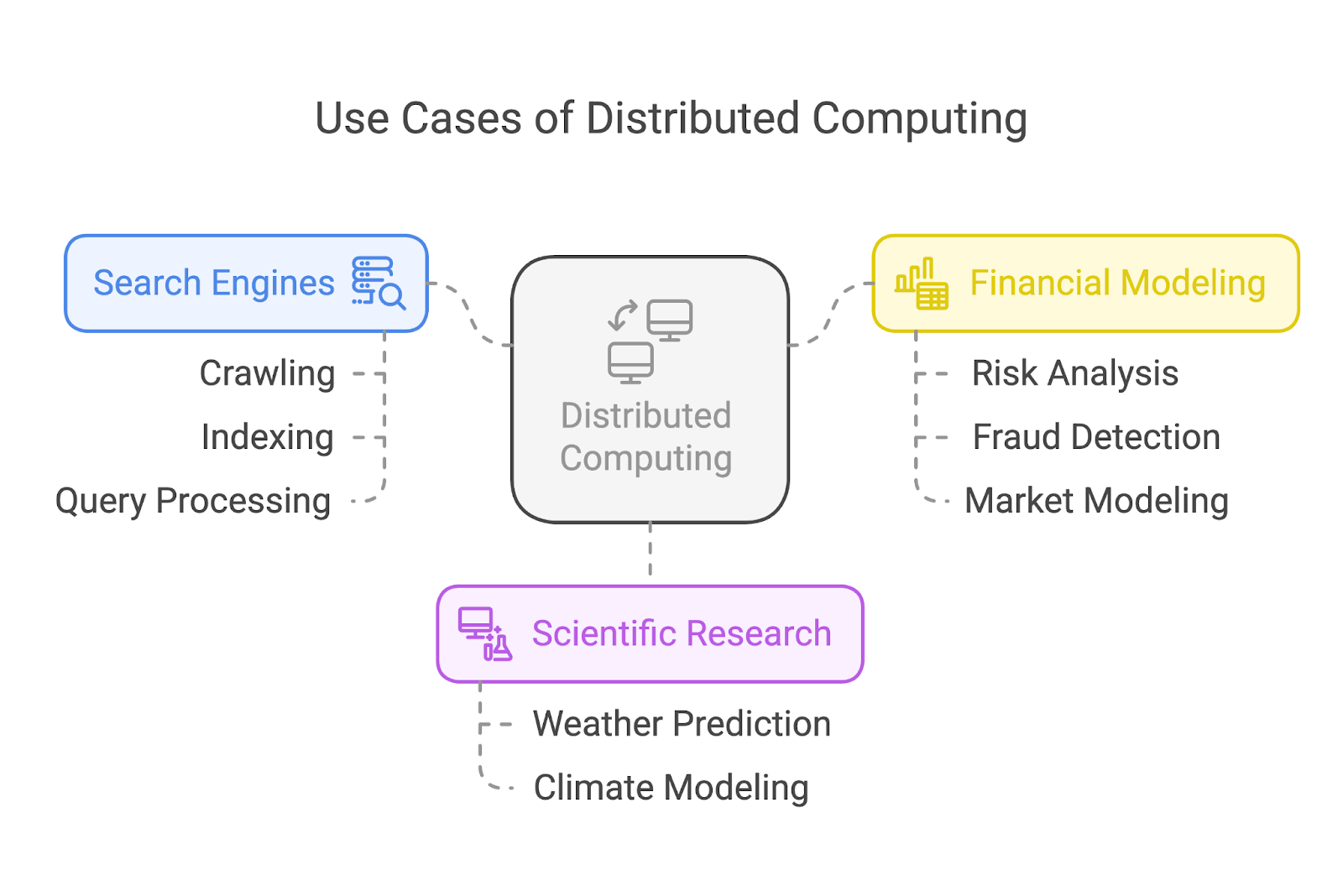
Les moteurs de recherche comme Google s'appuient fortement sur l'informatique distribuée pour explorer et indexer des milliards de pages web. Au lieu d'assigner la tâche à une seule machine, ces systèmes répartissent la charge de travail entre de très nombreux nœuds.
Certains nœuds se concentrent sur l'exploration des pages web, d'autres s'occupent de l'indexation et un autre groupe traite les requêtes des utilisateurs en temps réel. Cette répartition des tâches garantit des résultats de recherche rapides et efficaces, quelle que soit l'ampleur de la tâche.
Dans le domaine de la recherche scientifique, l'informatique distribuée permet de réaliser des percées en exécutant des simulations complexes et en analysant d'énormes ensembles de données. Par exemple, les climatologues utilisent des systèmes distribués pour modéliser et prévoir les phénomènes météorologiques ou simuler les effets du réchauffement climatique.
Le secteur financier s'appuie sur l'informatique distribuée pour des tâches telles que l'analyse des risques, la détection des fraudes et la modélisation des marchés.
Le traitement des énormes ensembles de données générés par les marchés financiers mondiaux exige des systèmes capables de travailler 24 heures sur 24 et très rapidement. L'informatique distribuée permet aux entreprises financières d'analyser des données, de tester des modèles et de générer des informations à des vitesses qui leur permettent de rester compétitives sur les marchés en temps réel.
L'informatique distribuée repose sur quelques éléments fondamentaux : des nœuds, un réseau et un système de fichiers distribués (DFS).
Les nœuds sont les machines individuelles qui effectuent des calculs au sein d'un système distribué. Chaque nœud peut agir indépendamment, traiter les tâches qui lui sont assignées et communiquer avec les autres nœuds pour partager les résultats. Dans certains cas, les nœuds peuvent avoir des rôles spécialisés, comme la gestion de tâches ou le stockage de données.
Le réseau est l'infrastructure de communication qui relie les différents nœuds. Il leur permet d'échanger des données et de coordonner des tâches. Selon la taille du système, il peut s'agir de réseaux locaux (LAN) ou de réseaux étendus (WAN) pour les nœuds géographiquement dispersés.
Un système de fichiers distribués est une solution de stockage qui permet d'accéder aux données sur plusieurs nœuds. Un exemple courant est le système de fichiers distribués Hadoop (HDFS), qui est conçu pour traiter de grands ensembles de données et offrir une tolérance aux pannes en répliquant les données sur plusieurs nœuds.
Nous avons donc une charge de travail distribuée à différents nœuds via un réseau, et tous les nœuds ont accès aux données par l'intermédiaire d'un DFS. Mais qui décide quel nœud fait quoi ?
Il n'existe pas de réponse unique à ces questions, car les systèmes informatiques distribués peuvent être organisés de différentes manières. Cela dit, il existe trois architectures courantes : maître-esclave, pair-à-pair et client-serveur.
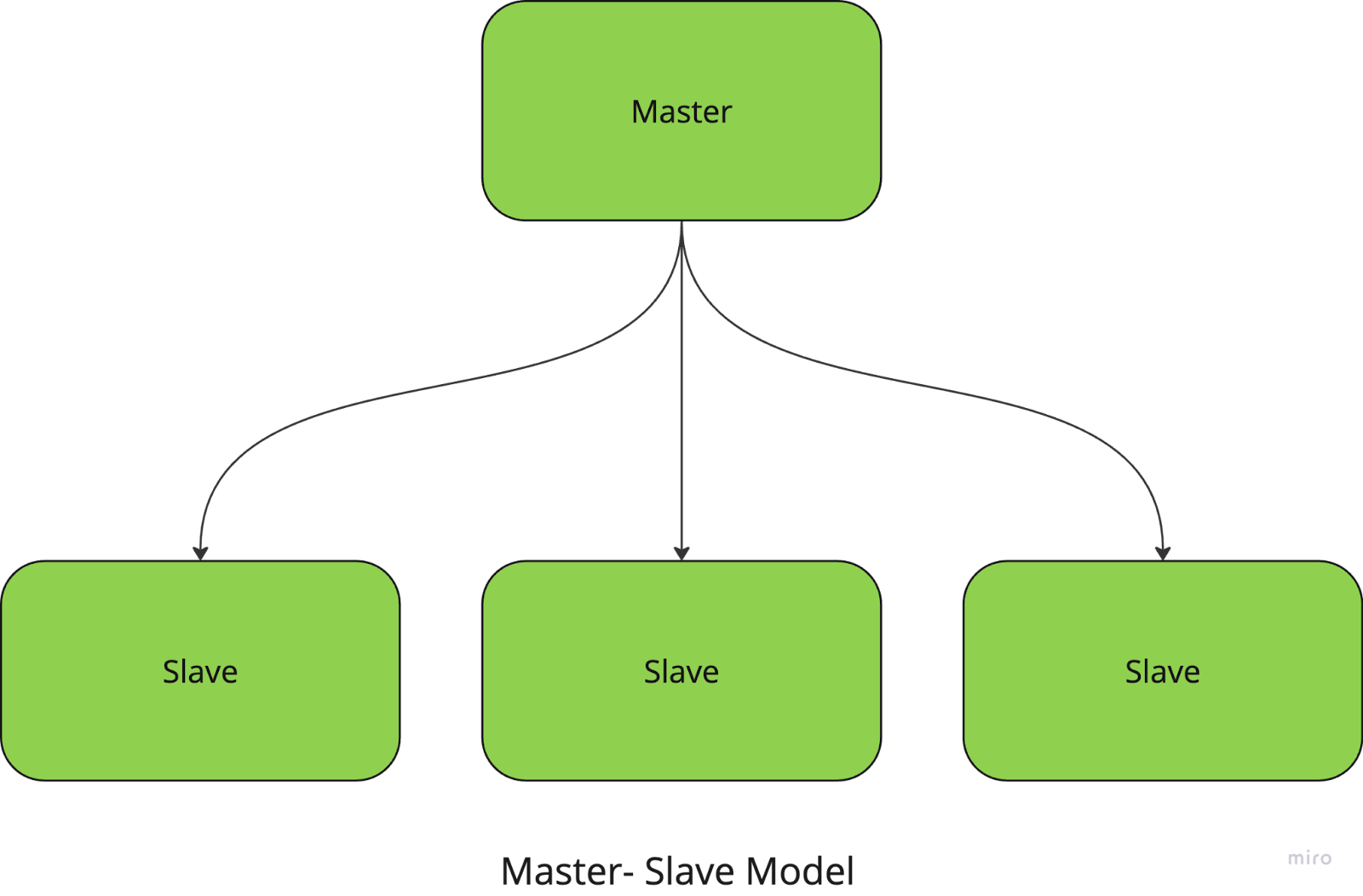
Dans le modèle maître-esclave, un nœud central (le nœud maître) gère et coordonne les tâches, tandis que les nœuds esclaves exécutent les calculs proprement dits. Le maître est chargé de diviser les tâches en petits morceaux, de les distribuer aux esclaves et de collecter les résultats.
Par exemple, si vous exécutez une tâche de traitement d'images à grande échelle, le nœud maître attribue à chaque nœud esclave une partie spécifique des images à traiter. Une fois les tâches accomplies, le maître rassemble les résultats et les combine pour obtenir le produit final.
Cette approche simplifie la gestion et la coordination des tâches mais présente un inconvénient majeur : le système a un seul point de défaillance puisqu'il dépend entièrement du nœud maître.
Dans l'architecture pair-à-pair, tous les nœuds sont égaux et il n'y a pas de coordinateur central. Chaque nœud peut agir à la fois comme client et comme serveur, en partageant des ressources et en communiquant directement avec d'autres nœuds.
Par exemple, les réseaux de partage de fichiers tels que BitTorrent utilisent une approche P2P, dans laquelle les utilisateurs téléchargent et envoient des morceaux de fichiers directement depuis et vers d'autres pairs.
En revanche, la coordination entre les nœuds (pour assurer la cohérence des données, par exemple) peut s'avérer plus complexe.
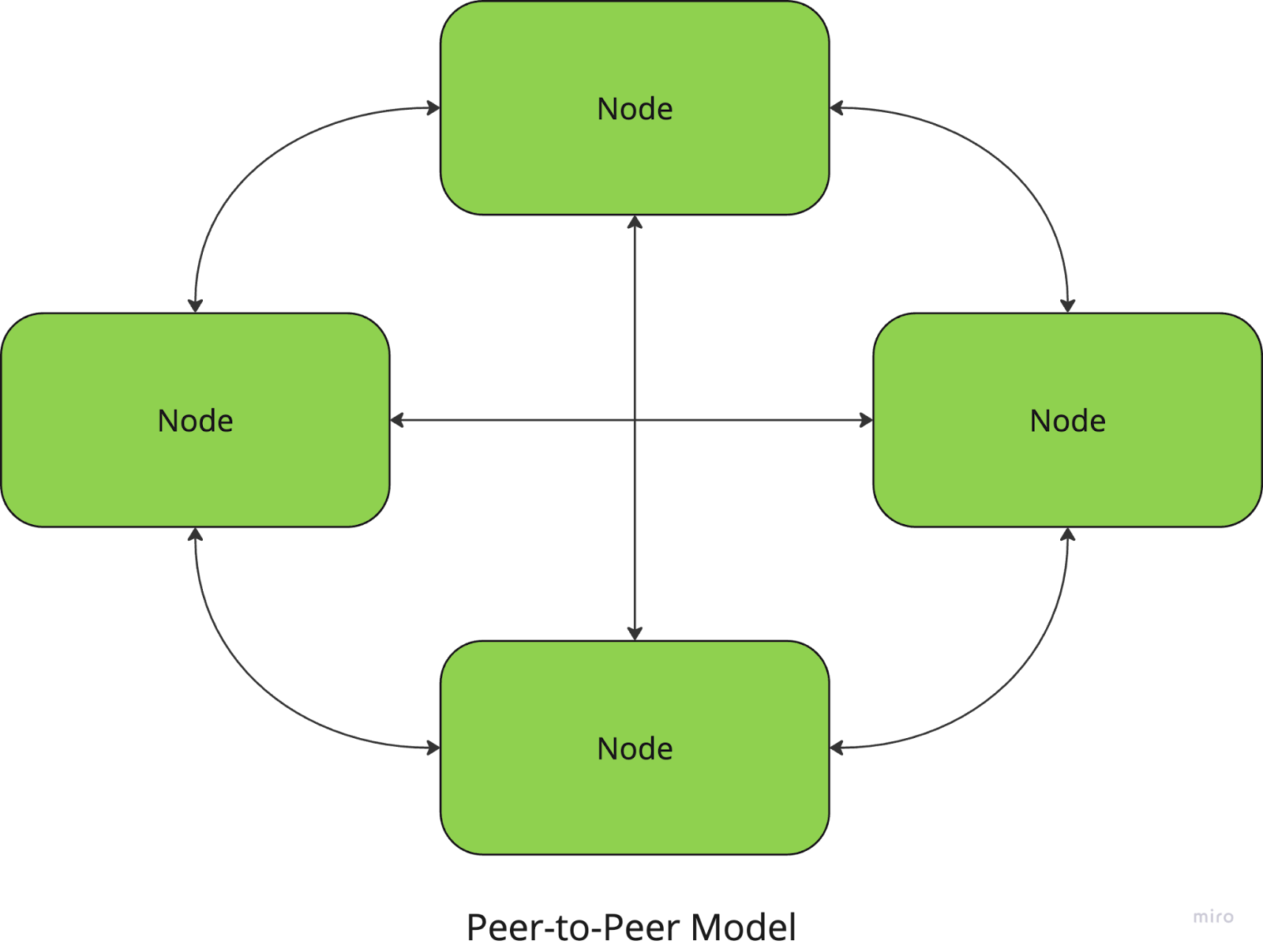
Dans le modèle client-serveur, un ou plusieurs serveurs fournissent des ressources ou des services à plusieurs nœuds clients. Les clients envoient des demandes au serveur, qui les traite et renvoie les résultats. Cette architecture est couramment utilisée dans les applications web et les bases de données.
Cela peut sembler similaire au modèle maître-esclave, le serveur jouant le rôle du maître, mais il y a une différence : le serveur est généralement plus passif et ne répartit ni ne délègue les tâches - il se contente de répondre aux demandes des clients.
Avec ce modèle, la gestion et le contrôle centralisés facilitent la maintenance et la mise à jour du système, mais le serveur est un goulot d'étranglement qui peut limiter l'évolutivité. L'indisponibilité du serveur peut également perturber l'ensemble du système.
Ces trois architectures sont parmi les plus courantes dans les systèmes distribués, mais il existe d'autres modèles que vous avez peut-être rencontrés (je suis sûr que vous avez entendu parler de l'architecture basée sur le cloud !).
Chaque modèle répond à des besoins différents et le choix de l'architecture peut avoir un impact important sur les performances du système, la tolérance aux pannes et l'évolutivité. Il est donc important de définir le problème à résoudre avant de décider d'une approche. Mais ce qui est bien, c'est que vous n'avez pas à en choisir un seul ! La plupart des systèmes modernes, en particulier dans le domaine de l cloud computingutilisent une version hybride de ces architectures pour combiner leurs meilleures caractéristiques.
Maintenant que nous avons abordé la théorie de l'informatique distribuée, voyons comment mettre en place un système d'informatique distribuée.
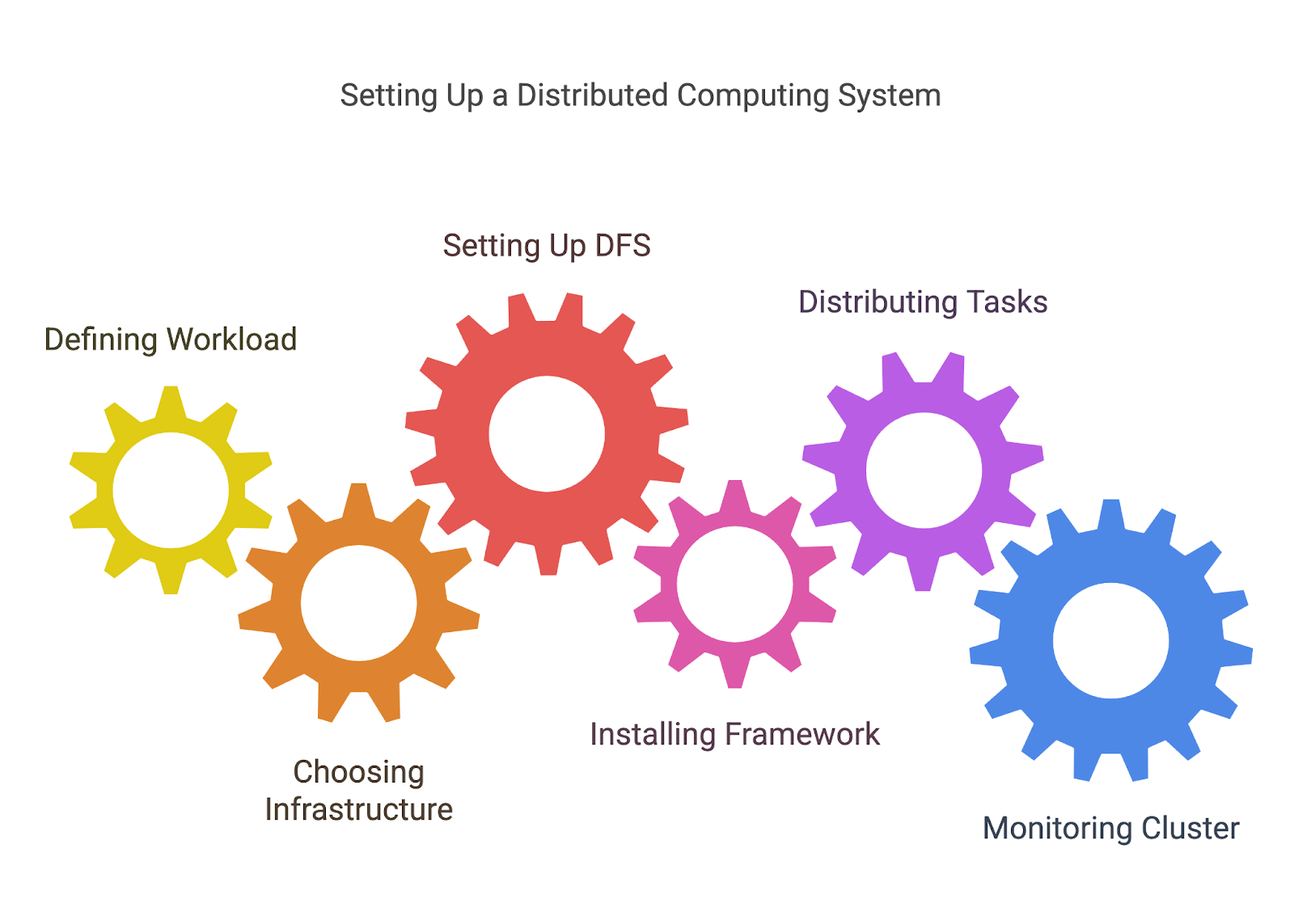
Avant de distribuer des tâches, vous devez définir les tâches que vous distribuez. Il s'agit souvent de décomposer un problème plus important en unités de travail plus petites et indépendantes qui peuvent être traitées en parallèle ou réparties entre les nœuds.
Par exemple, si vous traitez un grand ensemble de données, vous pouvez diviser les données en morceaux qui peuvent être traités par différentes machines ou processeurs.
L'informatique distribuée nécessite un réseau de machines, qu'il s'agisse de serveurs sur site, d'instances dans le cloud (comme AWS, Azureou Google Cloud), ou même un mélange des deux. Vous devrez décider comment installer et configurer ces machines, en veillant à ce qu'elles soient connectées et puissent communiquer entre elles.
Comme nous l'avons vu précédemment, l'un des éléments les plus importants de l'informatique distribuée est de s'assurer que tous les nœuds ont accès aux données dont ils ont besoin. HDFS de Hadoop ou d'autres solutions DFS vous permettent de stocker de grands ensembles de données sur plusieurs nœuds, avec une redondance qui garantit que les données ne sont pas perdues en cas de défaillance d'un nœud.
Une fois votre infrastructure en place, vous devez configurer l'outil que vous avez choisi pour l'informatique distribuée. Chaque cadre a son propre processus d'installation et de configuration, mais il peut s'agir d'un processus d'installation et de configuration :
Une fois que votre environnement est prêt, vous pouvez commencer à distribuer les tâches sur vos nœuds. La plupart des outils vous aideront à gérer ce processus en divisant votre charge de travail et en assignant des tâches à différents nœuds.
Vous devrez généralement écrire du code qui définit comment les tâches doivent être réparties (jobs MapReduce pour Hadoop, transformations et actions pour Spark, etc.) ou utiliser les API du framework pour gérer la distribution et la communication entre les nœuds.
Les systèmes distribués peuvent devenir complexes, et il est essentiel de suivre les performances, les défaillances et l'utilisation des ressources pour s'assurer que tout fonctionne correctement. De nombreux outils fournissent des tableaux de bord intégrés pour la surveillance, mais vous pouvez également avoir besoin de solutions de surveillance supplémentaires (comme Prometheus ou Grafana) pour suivre l'état de santé des nœuds, les performances et la progression des tâches.
Comme nous venons de le voir, le bon outil peut vous aider à mettre en place l'informatique distribuée et à prendre en charge une grande partie de la gestion de vos environnements distribués. Examinons de plus près quelques-uns des plus populaires d'entre eux.
Apache Hadoop est un cadre open-source conçu pour traiter d'énormes quantités de données sur une grappe distribuée d'ordinateurs. Il utilise le modèle de programmation MapReduce, qui décompose les tâches de grande envergure en morceaux plus petits et parallélisables.
Hadoop est particulièrement utile pour traiter des pétaoctets de données et offre une grande évolutivité, une tolérance aux pannes et une grande souplesse de stockage. Son écosystème comprend divers composants tels que le système de fichiers distribués Hadoop (HDFS) pour le stockage distribué et des outils pour le traitement par lots, ce qui en fait l'une des solutions de choix pour de nombreuses applications de big data.
La mise en place de l'infrastructure elle-même peut être complexe, car il faut encore configurer les nœuds, gérer les ressources de la grappe et assurer la tolérance aux pannes.
Pour en savoir plus sur Hadoop, lisez cet article sur Questions d'entretien sur Hadoop. Il est utile pour se préparer à un entretien et regorge d'informations intéressantes sur l'outil et ses cas d'utilisation.
Apache Spark est un moteur rapide et polyvalent pour le traitement de données à grande échelle.
Parce qu'il est basé sur Hadoop, Spark peut fonctionner au-dessus des clusters Hadoop existants ou sur son propre gestionnaire de clusters. Bien que contrairement à Hadoop, qui utilise un stockage sur disque, Spark offre un calcul en mémoire et peut traiter les données beaucoup plus rapidement.
Il peut être utilisé pour un large éventail de tâches de traitement, y compris le traitement par lots, la diffusion en continu en temps réel, l'apprentissage automatique et le traitement des graphes. Il prend en charge des langages tels que Python, Scalaet Java et s'intègre à des plateformes cloud comme AWS et Azure.
Vous souvenez-vous de l'époque où nous parlions de l'informatique parallèle ? Bien, Dask est une bibliothèque de calcul parallèle en Python conçue pour passer d'une machine unique à de grandes grappes distribuées.
C'est un choix idéal pour traiter les grands ensembles de données et les tâches de calcul complexes car il s'intègre à d'autres bibliothèques Python comme NumPy, Pandas et Scikit-learn et offre un environnement familier aux utilisateurs de Python.
Sa capacité à travailler avec des environnements distribués et locaux signifie que vous pouvez l'utiliser pour travailler sur un petit projet ou sur un énorme pipeline de données. Il nécessite encore un certain niveau de configuration pour le calcul distribué, bien qu'une grande partie soit automatisée par rapport à Hadoop et Spark.
J'espère que vous avez apprécié d'apprendre les bases de l'informatique distribuée ! Cet article n'est cependant qu'un point de départ. Dans le domaine de l'informatique distribuée, d'innombrables outils, cadres et techniques voient le jour chaque année.
Si vous voulez essayer de créer des systèmes distribués, je vous recommande de vous inscrire auprès d'un fournisseur de cloud comme AWS ou GCP. Ils offrent tous deux des crédits lors de l'inscription, ce qui vous permet d'essayer leur infrastructure et de mettre en place de petits projets gratuitement !
Si vous maîtrisez déjà les bases et que vous souhaitez donner un coup de pouce à votre carrière dans le domaine des données, vous pouvez suivre l'une des nombreuses formations suivantes certifications Apache Spark disponibles en ligne.
Bon codage !
Apprenez le cloud avec ces cours !
Cours
Cours
Cours