
programa
Contenedores y virtualización con Docker y Kubernetes
13 h
Podmanrepresenta el desafío más directo al enfoque arquitectónico de Docker.
Imagen 1: página de inicio de Podman.
Red Hat lo desarrolló específicamente para abordar el modelo de seguridad basado en demonios de Docker, al tiempo que se mantiene la compatibilidad con los flujos de trabajo existentes.
Si necesitas una comparación más detallada entre Docker y Podman, nuestra entrada de blog te revelará qué plataforma de contenedorización es la más adecuada para ti.
La mayor diferencia entre Podman y Docker es que el primeroelimina por completoel demonio. En lugar de enrutar los comandos a través de un servicio central, Podman utiliza un modelo fork-exec en el que cada contenedor se ejecuta como un proceso secundario directo del usuario que lo ha iniciado. Esto significa que no hay ningún servicio en segundo plano persistente, ningún punto único de fallo y ningún demonio de nivel raíz que gestione tus contenedores.
Esta arquitectura se integra de forma natural con systemd, el gestor de servicios estándar de Linux. Puedes generar archivos de unidad systemd directamente desde contenedores Podman, lo que permite que tus contenedores se inicien automáticamente al arrancar el sistema, se reinicien en caso de fallo y se integren con el registro del sistema. Es un enfoque mucho más limpio que la capa de orquestación independiente de Docker.
Podman mantiene la total compatibilidad con OCI, por lo que ejecuta las mismas imágenes de contenedor que Docker sin modificaciones. El tiempo de ejecución utiliza las mismas tecnologías subyacentes ( runc para la ejecución de contenedores y varios controladores de almacenamiento para la gestión de imágenes), pero las empaqueta de forma diferente.
El funcionamiento sin privilegios es la característica de seguridad más destacada de Podman. Cuando ejecutas contenedores con Podman, , estos se ejecutan bajo tu cuenta de usuario en lugar de requerir privilegios de root. Esto se lleva a cabo mediante la asignación del espacio de nombres de usuario, donde el usuario raíz del contenedor se asigna a tu ID de usuario sin privilegios en el sistema host.
Esto elimina el vector de ataque en el que una fuga del contenedor podría comprometer todo el sistema host. Incluso si un atacante escapa del contenedor, seguirá estando limitado por los permisos de tu usuario, en lugar de tener acceso root a la máquina.
En los sistemas Red Hat Enterprise Linux y Fedora, Podman se integra perfectamente con SELinux (Security-Enhanced Linux). SELinux proporciona controles de acceso obligatorios que restringen lo que los contenedores pueden acceder en el sistema host, incluso si están comprometidos. Esto crea múltiples capas de seguridad: los espacios de nombres de usuario evitan la escalada de privilegios, mientras que SELinux impide el acceso no autorizado al sistema de archivos.
Las implementaciones empresariales suelen combinar estas características con herramientas adicionales de análisis de seguridad y aplicación de políticas para estrategias de defensa en profundidad.
Podman mantiene la compatibilidad con la CLI de Docker a través de su comando ` podman `, que acepta los mismos argumentos que ` docker`. Puedes crear un alias (alias docker=podman) y la mayoría de los scripts existentes funcionarán sin necesidad de modificarlos. Esto hace que la migración desde Docker sea mucho más sencilla que cambiar a cadenas de herramientas completamente diferentes.
La interfaz gráfica de usuario Podman Desktop GUI ofrece una alternativa a Docker Desktop para los programadores que prefieren las interfaces gráficas. Incluye gestión de contenedores, capacidades de creación de imágenes e integración con Kubernetes para el desarrollo local. La aplicación de escritorio puede conectarse a instancias remotas de Podman y ofrece una funcionalidad similar a la del panel de control de Docker Desktop.
Para los flujos de trabajo de Kubernetes, Podman puede generar manifiestos YAML de Kubernetes a partir de contenedores en ejecución y admite la gestión de pods, es decir, la ejecución de varios contenedores que comparten red y almacenamiento, de forma similar a los pods de Kubernetes.
La compatibilidad con Windows sigue siendo la mayor limitación de Podman. Aunque Podman Machine ofrece compatibilidad con Windows a través de la virtualización, no es tan fluida como la integración WSL2 de Docker Desktop. Los programadores de Windows pueden encontrar la configuración más compleja.
Las redes sin raíz tienen implicaciones en el rendimiento. Sin privilegios de root, Podman no puede crear redes puente directamente, por lo que utiliza redes en modo usuario (slirp4netns), lo que añade latencia. Esto rara vez se nota en las cargas de trabajo de desarrollo, pero las aplicaciones de red de alto rendimiento pueden experimentar una reducción del rendimiento.
La compatibilidad con Docker Compose existe a través de podman-compose, pero no es 100 % completa en cuanto a funciones. Es posible que los archivos Compose complejos requieran modificaciones, y algunas funciones de red avanzadas no son compatibles con el modo sin raíz. Los equipos que hayan realizado una gran inversión en flujos de trabajo de Docker Compose deben realizar pruebas exhaustivas antes de migrar.
¿En qué se diferencia Docker Compose de Kubernetes? Nuestra comparación detallada te ofrece toda la información que necesitas.
Mientras que Podman tiene como objetivo la compatibilidad con Docker, CRI-O y containerd se centran específicamente en entornos de producción de Kubernetes. Estos entornos de ejecución eliminan las funciones innecesarias para optimizar las cargas de trabajo orquestadas.
Todos los programadores deben conocer estas diferencias entre Docker y Kubernetes.
CRI-O se creó desde cero para implementar la interfaz de tiempo de ejecución de contenedores (CRI) de Kubernetes.

Imagen 2: página de inicio de CRI-O.
Incluye solo lo que Kubernetes necesita: sin creación de imágenes, sin gestión de volúmenes más allá de lo que requieren los pods y sin gestión de contenedores independientes. Este enfoque específico da como resultado una menor sobrecarga de memoria y tiempos de arranque más rápidos en comparación con Docker.
La eficiencia de recursos del tiempo de ejecución proviene de su diseño minimalista. CRI-O no mantiene un demonio con API extensas ni servicios en segundo plano. Inicia contenedores, gestiona su ciclo de vida según las instrucciones de Kubernetes y se mantiene al margen. Esto lo hace ideal para entornos con recursos limitados o implementaciones a gran escala en las que cada megabyte de memoria es importante.
CRI-O admite cualquier tiempo de ejecución compatible con OCI como su ejecutor de bajo nivel. Aunque el valor predeterminado es runc, puedes cambiarlo por alternativas como crun (escrito en C para un mejor rendimiento) o gVisor (para un mayor aislamiento) sin cambiar la configuración de Kubernetes. Esta flexibilidad te permite optimizar requisitos específicos de seguridad o rendimiento en el nivel de tiempo de ejecución.
El proyecto mantiene una estricta compatibilidad con los ciclos de lanzamiento de Kubernetes, lo que garantiza que las nuevas funciones y actualizaciones de seguridad se ajusten a las versiones de tu clúster.
Containerd comenzó como el tiempo de ejecución subyacente de Docker antes de convertirse en un proyecto independiente bajo la Cloud Native Computing Foundation.

Imagen 3: página de inicio de Containerd.
Docker sigue utilizando containerd internamente, pero puedes ejecutarlo directamente para eliminar las capas adicionales y la sobrecarga de Docker.
La arquitectura se centra en una API shim que proporciona interfaces estables para la gestión de contenedores. Cada contenedor tiene su propio proceso de ajuste, que gestiona el ciclo de vida del contenedor de forma independiente. Si el demonio containerd principal se reinicia, los contenedores en ejecución continúan sin interrupción, una característica fundamental para las cargas de trabajo de producción que no pueden tolerar tiempos de inactividad.
Este diseño hace que containerd sea extremadamente estable para aplicaciones empresariales de larga duración. La arquitectura Shim también permite funciones como la migración en vivo y las actualizaciones sin tiempo de inactividad, en las que puedes actualizar el tiempo de ejecución sin afectar a los contenedores en funcionamiento.
Containerd incluye gestión de imágenes integrada, instantáneas para un almacenamiento eficiente de capas y sistemas de complementos para ampliar la funcionalidad. Los principales proveedores de nube, como AWS EKS, Google GKE y Azure AKS, utilizan containerd como su tiempo de ejecución predeterminado debido a esta arquitectura reforzada para la producción.
A continuación se muestra una comparación de estos tiempos de ejecución para implementaciones de Kubernetes en producción:
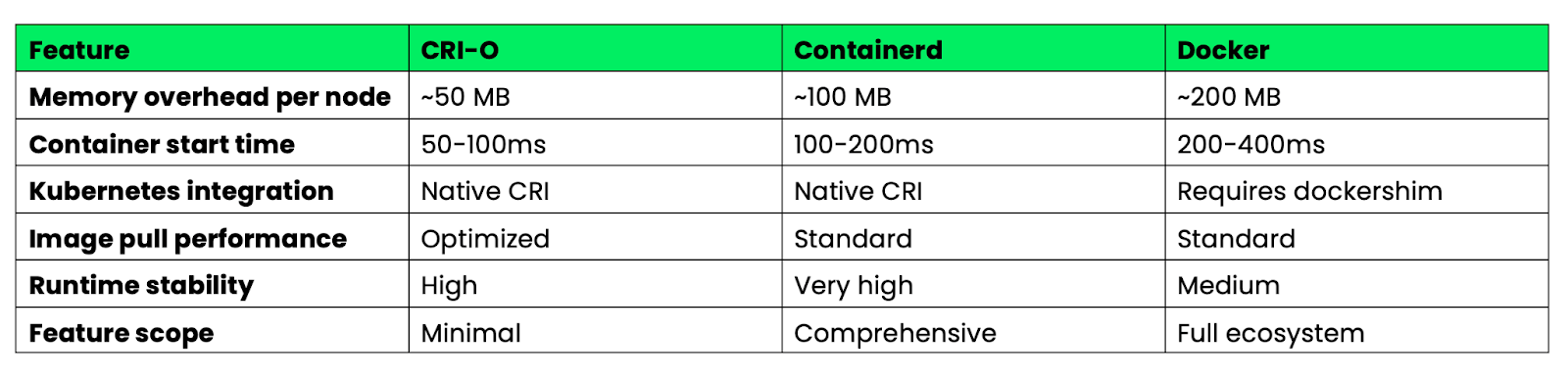
Imagen 4: Características de rendimiento de Docker, CRI-O y Containerd.
CRI-O destaca por su eficiencia en el uso de recursos y su velocidad de arranque gracias a su diseño minimalista. Containerd ofrece el mejor equilibrio entre funciones y estabilidad para entornos empresariales. Docker ofrece más funciones, pero con una sobrecarga mayor que resulta innecesaria en entornos Kubernetes.
Para los clústeres de Kubernetes de producción, tanto CRI-O como containerd eliminan la capa de compatibilidad dockershim, lo que reduce la complejidad y mejora el rendimiento en comparación con las configuraciones basadas en Docker.
Mientras que los entornos de ejecución de alto nivel, como Podman y containerd, se encargan de la gestión de imágenes y las API, los entornos de ejecución de bajo nivel se centran exclusivamente en la ejecución de contenedores. Estas herramientas constituyen la base que impulsa la mayoría de las plataformas de contenedorización.
runC sirve como implementación de referencia de la especificación OCI Runtime Specification: es el ejemplo canónico de cómo deben ejecutarse realmente los contenedores. La mayoría de las plataformas de contenedores utilizan runC como motor de ejecución, incluyendo Docker, containerd, CRI-O y Podman. Cuando inicias un contenedor con cualquiera de estas herramientas, es probable que runC se encargue de la creación y el aislamiento reales del proceso.
El tiempo de ejecución implementa primitivas básicas del contenedor: creación de espacios de nombres Linux para el aislamiento, configuración de cgroups para los límites de recursos y configuración de contextos de seguridad. Está escrito en Go y diseñado para ser sencillo, fiable y compatible con las especificaciones, en lugar de ofrecer numerosas funciones.
runC destaca en sistemas integrados y pilas de contenedores personalizadas en los que se necesita un comportamiento predecible y dependencias mínimas. Dado que solo gestiona la ejecución de contenedores, puedes crear plataformas de contenedores especializadas a tu alrededor sin heredar una complejidad innecesaria. Los dispositivos IoT, las plataformas de computación periférica y los sistemas de orquestación personalizados suelen utilizar runC directamente en lugar de entornos de ejecución de nivel superior.
La herramienta funciona como una utilidad de línea de comandos que lee las especificaciones del paquete OCI y crea contenedores en consecuencia. Esto lo hace perfecto para integrarlo en sistemas existentes o crear herramientas personalizadas de gestión de contenedores.
Youki reimplementala especificación OCI Runtime en Rust, centrándose en la seguridad de la memoria y el rendimiento. La implementación de Rust elimina clases enteras de vulnerabilidades de seguridad que pueden afectar a los entornos de ejecución de C y Go, al tiempo que mejora los tiempos de inicio de los contenedores gracias a una mejor gestión de la memoria y una reducción de la sobrecarga.
Las pruebas de rendimiento muestran que Youki inicia los contenedores más rápido que runC en muchos casos, aunque la mejora exacta varía según la carga de trabajo. Esta mejora proviene de las abstracciones de coste cero de Rust y de los patrones de asignación de memoria más eficientes. Para aplicaciones que crean y destruyen muchos contenedores de corta duración, estas mejoras en el tiempo de inicio pueden ser significativas.
Youki mantiene una compatibilidad total con la especificación OCI Runtime, por lo que funciona como sustituto directo de runC en la mayoría de las plataformas de contenedores. Docker Engine, containerd y otros entornos de ejecución de alto nivel pueden utilizar Youki sin necesidad de modificar su configuración ni sus API.
El tiempo de ejecución beneficia a las cargas de trabajo críticas para el rendimiento, como las funciones sin servidor, los procesos de CI/CD con muchas compilaciones de contenedores y las arquitecturas de microservicios con eventos de escalado frecuentes. Los tiempos de arranque más rápidos se traducen directamente en una reducción de la latencia de arranque en frío y una mejora en la utilización de los recursos en estos escenarios.
Youki también incluye características como la optimización de cgroup v2 y la compatibilidad mejorada con contenedores sin raíz, que aprovechan el sistema de tipos de Rust para evitar errores de configuración en tiempo de compilación.
No todas las contenedorizaciones deben centrarse en aplicaciones únicas; a veces es necesario ejecutar sistemas operativos completos en contenedores. LXC y LXD proporcionan una contenedorización a nivel de sistema que es fundamentalmente diferente del enfoque centrado en las aplicaciones de Docker.
LXC (Linux Containers)crea contenedores que se comportan como sistemas Linux completos en lugar de procesos de aplicaciones aislados.
Imagen 5: página de inicio de LXC.
Cada contenedor LXC ejecuta su propio sistema de inicio, puede alojar múltiples servicios y proporciona un entorno de espacio de usuario completo que es casi indistinguible de una máquina virtual.
Este enfoque destaca en cargas de trabajo heredadas que no fueron diseñadas para la contenedorización. Las aplicaciones que necesitan escribir en /etc, ejecutar servicios del sistema o interactuar con toda la jerarquía del sistema de archivos funcionan a la perfección en contenedores LXC. Puedes trasladar configuraciones completas de servidores a LXC sin necesidad de refactorizar aplicaciones para arquitecturas de microservicios.
Los contenedores LXC comparten el kernel del host, pero mantienen un aislamiento más fuerte que los contenedores de aplicaciones. Cada contenedor tiene su propia pila de red, árbol de procesos y espacio de nombres del sistema de archivos, lo que crea un aislamiento similar al de una máquina virtual sin la sobrecarga de la virtualización de hardware.
LXD, ahora bajo el paraguas de Canonical (), añade una potente capa de gestión sobre LXC. LXD proporciona API REST, gestión de imágenes y funciones avanzadas como la migración en vivo entre hosts. Puedes mover contenedores en ejecución entre máquinas físicas sin tiempo de inactividad, de forma similar a VMware vMotion, pero con contenedores.
Las capacidades de paso de hardware permiten a los contenedores LXD acceder directamente a GPU, dispositivos USB y otro hardware. Esto lo hace adecuado para cargas de trabajo que necesitan acceso a hardware especializado, al tiempo que mantiene las ventajas de los contenedores, como la densidad y el rápido aprovisionamiento.
LXD también admite la agrupación en clústeres, lo que te permite gestionar varios hosts como una única unidad lógica con capacidades automatizadas de ubicación y conmutación por error.
A continuación se muestra una comparación entre los contenedores de sistema y los contenedores de aplicaciones en función de sus características principales:
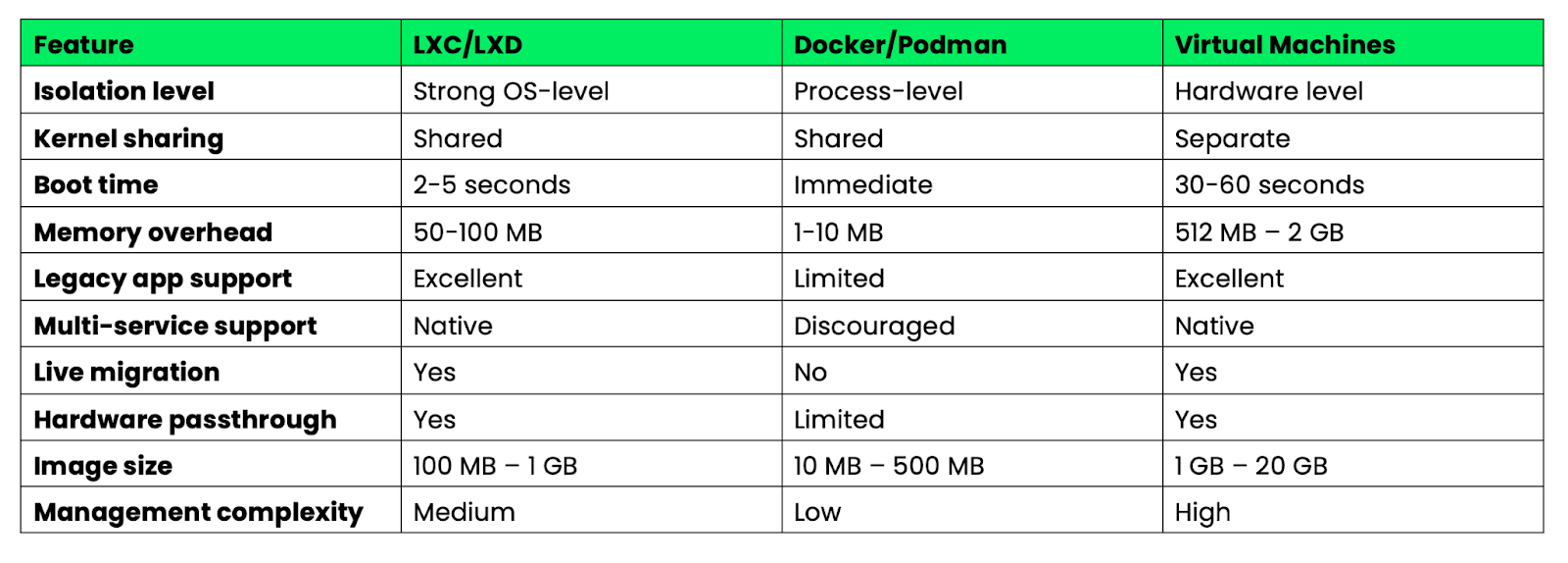
Imagen 6: Resumen de las características principales de Docker, LXC y máquinas virtuales.
Los contenedores de sistemas llenan el vacío entre los contenedores de aplicaciones ligeros y las máquinas virtuales pesadas. Son ideales cuando necesitas capacidades similares a las de una máquina virtual con la eficiencia de un contenedor, o cuando migras aplicaciones heredadas que no se pueden descomponer fácilmente en microservicios.
La elección entre contenedores de sistema y de aplicación depende de las características de tu carga de trabajo y de tus requisitos operativos, más que de la superioridad técnica, ya que resuelven problemas diferentes en el ámbito de la contenedorización.
La seguridad ha pasado de ser una cuestión secundaria a convertirse en un principio básico del diseño de los entornos de ejecución de contenedores modernos. Las plataformas actuales implementan estrategias de defensa en profundidad que asumen que los contenedores se verán comprometidos y se centran en limitar el radio de impacto.
Los contenedores sin raíz eliminan el mayor riesgo de seguridad de las implementaciones tradicionales de Docker: el demonio raíz. Podman fue pionero en este enfoque al ejecutar contenedores íntegramente con privilegios de usuario, utilizando espacios de nombres de usuario de Linux para asignar el usuario root del contenedor a un ID de usuario sin privilegios en el sistema host.
La implementación se basa en rangos de ID de usuarios y grupos subordinados (/etc/subuid y /etc/subgid) que permiten a los usuarios sin privilegios crear espacios de nombres aislados. Cuando un proceso contenedor cree que se está ejecutando como root (UID 0), el kernel lo asigna a tu ID de usuario real (por ejemplo, UID 1000) en el host. Incluso si un atacante escapa del contenedor, no puede escalar más allá de los permisos de tus usuarios.
Containerd ha implementado capacidades similares sin raíz a través de su modo sin raíz, que utiliza las mismas técnicas de asignación de espacios de nombres de usuario. El tiempo de ejecución puede iniciar contenedores, gestionar imágenes y manejar redes sin necesidad de privilegios de root en el sistema host.
Kubernetes ahora admite el funcionamiento sin root de forma nativa a travésdel proyecto Kubernetes-in-Rootless-Docker (KIND)ct y la integración de containerd sin root. Esto significa que los clústeres completos de Kubernetes pueden ejecutarse sin privilegios de root, lo que reduce drásticamente la superficie de ataque para entornos multitenant y despliegues periféricos en los que no se aplican los modelos de seguridad tradicionales.
El impacto en la seguridad va más allá de la prevención de la escalada de privilegios. Los contenedores sin raíces no pueden conectarse a puertos privilegiados (por debajo de 1024), no pueden acceder a la mayoría de los sistemas de archivos /proc y /sys, y no pueden realizar operaciones que requieran capacidades del núcleo. Esto crea límites naturales que contienen posibles brechas de seguridad.
Los entornos de ejecución modernos integran eBPF (extended Berkeley Packet Filter) para la aplicación de políticas de seguridad en tiempo real que van más allá de los controles de acceso tradicionales. Los programas eBPF se ejecutan en el espacio del kernel y pueden supervisar, filtrar o modificar las llamadas del sistema a medida que se producen, lo que proporciona una visibilidad y un control sin precedentes sobre el comportamiento de los contenedores.
Los perfiles Seccomp (Secure Computing) utilizan BPF para filtrar las llamadas al sistema a nivel del núcleo. En lugar de permitir que los contenedores accedan a las más de 300 llamadas al sistema Linux, los perfiles seccomp definen exactamente qué llamadas están permitidas. El perfil seccomp predeterminado de Docker bloquea las llamadas al sistema potencialmente peligrosas, mientras que los perfiles personalizados pueden ser aún más restrictivos en función de los requisitos de la aplicación.
La integración avanzada de eBPF permite la supervisión del comportamiento en tiempo real. Herramientas como Falco utilizan programas eBPF para detectar comportamientos anómalos en los contenedores, como conexiones de red inusuales, patrones de acceso a archivos inesperados o intentos de utilizar llamadas al sistema bloqueadas. Estas detecciones se producen en tiempo real con una sobrecarga mínima del rendimiento, ya que la supervisión se lleva a cabo en el espacio del núcleo.
La aplicación de políticas de red a través de eBPF proporciona un control granular del tráfico a nivel de paquetes. Cilium, un popular CNI de Kubernetes, utiliza eBPF para implementar políticas de red que pueden filtrar el tráfico basándose en protocolos de capa de aplicación, y no solo en direcciones IP y puertos. Esto significa que puedes crear políticas como «permitir solicitudes HTTP GET a /api/v1/users pero bloquear solicitudes POST» directamente en el núcleo.
La seguridad basada en eBPF también permite una supervisión consciente de los contenedores que comprende la relación entre los procesos, los contenedores y los pods de Kubernetes. Las herramientas de supervisión tradicionales ven procesos individuales, pero los programas eBPF pueden correlacionar las llamadas al sistema con los metadatos de los contenedores para proporcionar información de seguridad contextualizada.
Estas capacidades transforman la seguridad, pasando de la aplicación reactiva de parches a la aplicación proactiva de políticas, en la que los comportamientos sospechosos se bloquean automáticamente antes de que puedan causar daños.
El rendimiento de los contenedores es lo más importante cuando ejecutas cientos o miles de contenedores en tu infraestructura. Exploremos estrategias que minimicen la sobrecarga de recursos y la latencia de inicio.
El tiempo de arranque en frío, es decir, el retraso entre la solicitud de un contenedor y el momento en que está listo para servir el tráfico, afecta directamente a la experiencia del usuario y a la eficiencia de los recursos. Han surgido técnicas para minimizar estos retrasos en diferentes arquitecturas de tiempo de ejecución.
Las imágenes precargadas eliminan el tiempo de descarga al mantener las imágenes de contenedor utilizadas con frecuencia almacenadas en caché en los nodos. Los DaemonSets de Kubernetes pueden extraer previamente imágenes críticas, mientras que registros como Harbor admiten la replicación de imágenes en ubicaciones periféricas. Esta técnica puede reducir los inicios en frío de segundos a milisegundos para las imágenes almacenadas en caché.
La optimización de capas de imagen reduce la cantidad de datos que deben transferirse y extraerse. Las compilaciones en varias etapas crean imágenes finales más pequeñas, mientras que herramientas como dive ayudan a identificar capas innecesarias. Las imágenes sin distribución de Google eliminan los gestores de paquetes y los terminales, lo que a menudo reduce considerablemente el tamaño de las imágenes.
La carga diferida con proyectos como Stargz permite que los contenedores de se inicien antes de que se descargue toda la imagen. El tiempo de ejecución solo obtiene los archivos necesarios para el inicio inicial y descarga capas adicionales según sea necesario. Esto puede reducir los tiempos de arranque en frío de varios segundos a menos de 1 segundo para imágenes grandes.
La optimización del tiempo de ejecución varía según la implementación. La implementación de Rust de Youki muestra un rendimiento de arranque mejorado en comparación con runC gracias a una mejor gestión de la memoria. Crun, escrito en C, logra mejoras similares al eliminar la sobrecarga de la recolección de basura de Go durante la creación de contenedores.
Compartir instantáneas en containerd permite que varios contenedores compartan instantáneas del sistema de archivos de solo lectura, lo que reduce tanto el almacenamiento como la sobrecarga de memoria. Al iniciar varios contenedores desde la misma imagen, solo las capas grabables necesitan una asignación separada.
La optimización del proceso de inicio puede reducir el tiempo de arranque mediante el uso de sistemas de inicio ligeros como tini o mediante el diseño cuidadoso de secuencias de inicio de aplicaciones para minimizar el trabajo de inicialización.
La sobrecarga de memoria varía según los tiempos de ejecución de los contenedores, y las diferencias se vuelven críticas en entornos con recursos limitados o implementaciones de alta densidad.
La sobrecarga de referencia en tiempo de ejecución difieren sustancialmente:
La deduplicación de capas de imagen ahorra memoria cuando se ejecutan varios contenedores a partir de imágenes relacionadas. Los tiempos de ejecución de contenedores utilizan sistemas de archivos de copia en escritura, en los que las capas compartidas consumen memoria una sola vez en todos los contenedores. Un clúster que ejecuta muchos contenedores a partir de imágenes base similares puede lograr un ahorro significativo de memoria mediante la deduplicación.
La optimización del mapeo de memoria en los entornos de ejecución modernos reduce el uso de memoria residente. Herramientas como crun ejecutan archivos directamente desde el almacenamiento en lugar de cargarlos en la memoria, lo que reduce el consumo de memoria de los contenedores con binarios de gran tamaño.
La contabilidad de memoria Cgroup proporciona un control preciso sobre los límites de memoria de los contenedores, pero los diferentes tiempos de ejecución gestionan la presión de memoria de forma diferente. Algunos entornos de ejecución implementan una mejor recuperación de memoria bajo presión, mientras que otros proporcionan informes más precisos sobre el uso de la memoria para tomar decisiones de autoescalado.
La sobrecarga de memoria sin raíces sacrifica algo de eficiencia en favor de la seguridad. Los contenedores sin raíz requieren procesos adicionales para la gestión del espacio de nombres de usuario y las redes, lo que suele suponer una sobrecarga en comparación con el funcionamiento con raíz.
La elección entre entornos de ejecución suele reducirse a encontrar el equilibrio entre la eficiencia de la memoria y los requisitos de las funciones. CRI-O proporciona una sobrecarga baja para las cargas de trabajo de Kubernetes, mientras que Podman sacrifica algo de eficiencia a cambio de ventajas en materia de seguridad y compatibilidad.
El mejor tiempo de ejecución de contenedores no sirve de nada si no se adapta a tu flujo de trabajo de desarrollo. Las alternativas a Docker han implementado herramientas que a menudo superan la experiencia de programación de Docker en escenarios específicos.
El desarrollo local de Kubernetes ha ido más allá del enfoque de máquina virtual de minikube para ofrecer soluciones más eficientes que se integran directamente con los tiempos de ejecución de contenedores. La elección del entorno local tiene un impacto significativo en la velocidad de desarrollo y el consumo de recursos.
Kind (Kubernetes en Docker) crea clústeres de Kubernetes utilizando nodos de contenedores en lugar de máquinas virtuales. El tiempo de configuración suele ser de 1 a 2 minutos, con una sobrecarga de memoria moderada por nodo. Kind funciona con cualquier tiempo de ejecución compatible con Docker, por lo que puedes utilizarlo con Podman (kind create cluster --runtime podman) para el desarrollo de Kubernetes sin root.
K3s ofrece una opción ligera, que ejecuta una distribución completa de Kubernetes con un uso mínimo de memoria. Se inicia rápidamente e incluye almacenamiento integrado, redes y controladores de entrada. K3s funciona bien con containerd y puede ejecutarse en máquinas de desarrollo con recursos limitados.
MicroK8s de Canonical ofrece un término medio con un uso moderado de la memoria y complementos modulares. Se integra bien con containerd y ofrece funciones similares a las de producción sin la sobrecarga de las máquinas virtuales. El tiempo de arranque es razonable para un clúster completo.
Rancher Desktop combina K3s con backends containerd o Dockerd, lo que ofrece una alternativa a Docker Desktop que utiliza menos recursos. Incluye escaneo de imágenes integrado e integración con el panel de control de Kubernetes.
Los pods de Podman ofrecen una alternativa única: puedes desarrollar aplicaciones multicontener utilizando el concepto de pod de Podman, que refleja el comportamiento de los pods de Kubernetes. Genera Kubernetes YAML directamente desde pods en ejecución utilizando podman generate kube, creando una ruta fluida desde el desarrollo local hasta la implementación del clúster.
Las canalizaciones CI/CD tradicionales basadas en Docker se enfrentan a limitaciones en entornos contenedorizados, donde ejecutar Docker-in-Docker plantea retos de seguridad y rendimiento. Las alternativas modernas ofrecen mejores soluciones para crear y enviar imágenes de contenedores en sistemas de integración continua (CI).
Buildah excele en entornos de CI porque no requiere un demonio ni privilegios de root. Puedes crear imágenes compatibles con OCI utilizando scripts de terminal, que son más auditables que los archivos Dockerfile. El enfoque de scripting de Buildah permite la construcción dinámica de imágenes basada en variables CI, lo que lo hace ideal para procesos de compilación complejos que necesitan lógica condicional.

Imagen 7: página de inicio de Buildah.
A modo de comparación, los archivos Dockerfile tradicionales utilizan instrucciones declarativas:
FROM alpine:latest
RUN apk add --no-cache nodejs npm
COPY package.json /app/
WORKDIR /appBuildah utiliza comandos imperativos de terminal que pueden incluir variables y lógica condicional:
# Buildah scripting approach with CI integration
buildah from alpine:latest
buildah run $container apk add --no-cache nodejs npm
buildah copy $container package.json /app/
buildah config --workingdir /app $container
buildah commit $container myapp:${CI_COMMIT_SHA}Esta flexibilidad de scripting te permite elegir dinámicamente imágenes base, instalar paquetes de forma condicional en función de los nombres de las ramas o modificar los pasos de compilación en función de las variables de entorno de CI, capacidades que requieren soluciones alternativas complejas en los Dockerfiles tradicionales.
Kaniko resuelve el problema de «» y «Docker-in-Docker» creando imágenes completamente en el espacio de usuario dentro de un contenedor. Se ejecuta en pods de Kubernetes sin necesidad de acceso privilegiado ni demonio Docker. Kaniko es eficaz en los procesos de GitLab CI y Jenkins X, donde las políticas de seguridad impiden el uso de contenedores con privilegios.
La herramienta extrae imágenes base, aplica instrucciones Dockerfile de forma aislada y envía los resultados directamente a los registros. Los tiempos de compilación son comparables a los de Docker, pero con una postura de seguridad mucho mejor en entornos orquestados.
Nerdctl proporciona una compatibilidad de CLI de Dock e para containerd, lo que lo convierte en un excelente sustituto de Docker en los sistemas de CI. Admite los mismos comandos de compilación, envío y extracción que Docker, pero utiliza containerd como backend. Esto elimina el demonio Docker al tiempo que mantiene los flujos de trabajo habituales.
Nerdctl incluye funciones avanzadas como la extracción diferida y las imágenes cifradas que pueden mejorar el rendimiento de la integración continua. Para los equipos que utilizan containerd en producción, nerdctl crea consistencia entre los entornos de CI y de tiempo de ejecución.
Comparación del rendimiento en canalizaciones de CI:
La elección depende de tus requisitos de seguridad, la infraestructura existente y las necesidades de rendimiento. Kaniko funciona mejor en entornos Kubernetes centrados en la seguridad, mientras que Buildah destaca cuando necesitas una lógica de compilación compleja que es difícil de expresar en Dockerfiles.
Las implementaciones de contenedores empresariales requieren algo más que elegir el tiempo de ejecución adecuado: necesitas plataformas que gestionen el cumplimiento normativo, la gobernanza y las operaciones multiclúster a gran escala. Las alternativas de contenedores que elijas deben integrarse con las herramientas de gestión empresarial y cumplir con los requisitos normativos.
La gestión de contenedores en múltiples clústeres, nubes y ubicaciones periféricas requiere plataformas de orquestación sofisticadas que vayan más allá del Kubernetes básico. Las soluciones empresariales proporcionan una gestión centralizada, la aplicación de políticas y la coherencia operativa en entornos diversos.
Red Hat OpenShift crea un e en Kubernetes con opciones de tiempo de ejecución de contenedores orientadas a las empresas. OpenShift utiliza CRI-O de forma predeterminada para ofrecer mayor seguridad y eficiencia de recursos en comparación con las implementaciones basadas en Docker. La plataforma incluye escaneo de imágenes integrado, aplicación de políticas y flujos de trabajo para programadores que funcionan de manera consistente, ya sea que se utilice AWS, Azure o una infraestructura local.

Imagen 8: página de inicio de Red Hat OpenShift.
La gestión multiclúster de OpenShift se encarga de la estandarización del tiempo de ejecución en todos los entornos. Puedes exigir que todos los clústeres utilicen CRI-O con políticas de seguridad específicas, lo que garantiza un comportamiento coherente independientemente de si los contenedores se ejecutan en entornos de desarrollo, prueba o producción.
Rancher proporcionauna interfaz unificada para gestionar clústeres de Kubernetes independientemente de su tiempo de ejecución de contenedores subyacente. Rancher es compatible con clústeres que ejecutan Docker, containerd o CRI-O, lo que te permite migrar los entornos de ejecución gradualmente sin interrumpir las operaciones. La plataforma incluye supervisión centralizada, copias de seguridad y análisis de seguridad en todos los clústeres gestionados.
Imagen 9: página de inicio de Rancher.
El enfoque de Rancher resulta muy útil cuando se dispone de entornos mixtos: algunos clústeres pueden utilizar containerd para mejorar el rendimiento, mientras que otros utilizan CRI-O para cumplir con los requisitos de seguridad. La capa de gestión abstrae estas diferencias al tiempo que proporciona herramientas operativas coherentes.
Mirantis Kubernetes Engine se centra en entornos Docker empresariales, pero admite la migración a implementaciones basadas en containerd. La plataforma proporciona soporte empresarial, refuerzo de la seguridad y herramientas de cumplimiento normativo que funcionan en diferentes entornos de ejecución de contenedores.
Imagen 10: página de inicio de Mirantis.
Estas plataformas resuelven la complejidad operativa que supone ejecutar diferentes tiempos de ejecución de contenedores en tu infraestructura, al tiempo que mantienen una gobernanza centralizada y políticas de seguridad.
Los entornos empresariales suelen exigir el cumplimiento de normativas como FIPS 140-2, SOC 2 o RGPD, que influyen directamente en la selección y configuración del tiempo de ejecución de los contenedores. El cumplimiento normativo no se limita al tiempo de ejecución, sino que se extiende a los registros de imágenes, los análisis de seguridad y los registros de auditoría.
La validación FIPS (Federal Information Processing Standards) requiere módulos criptográficos que cumplan con los estándares de seguridad del gobierno. No todos los tiempos de ejecución de contenedores admiten bibliotecas criptográficas validadas por FIPS. Red Hat Enterprise Linux ofrece versiones de CRI-O y Podman que cumplen con la norma FIPS, mientras que las instalaciones estándar de Docker suelen requerir una configuración adicional para cumplir con dicha norma.
El cumplimiento de FIPS afecta a la firma de imágenes, las comunicaciones TLS y el almacenamiento cifrado. Las plataformas de contenedores deben utilizar bibliotecas criptográficas validadas por FIPS para todas las operaciones de seguridad, desde la extracción de imágenes hasta el establecimiento de conexiones de red entre contenedores.
El cumplimiento del RGPD afecta a la forma en que las plataformas de contenedores gestionan los datos personales en los registros, las métricas y los metadatos de las imágenes. Los registros de contenedores empresariales como Harbor, Quay y AWS ECR ofrecen funciones como controles de residencia de datos, registros de auditoría y políticas de retención de datos automatizadas.
Los tiempos de ejecución de contenedores deben admitir funciones de cumplimiento como:
El cumplimiento de SOC 2 exige controles de seguridad demostrables en materia de gestión del acceso, supervisión del sistema y protección de datos. Las plataformas de contenedores deben integrarse con los proveedores de identidad corporativos, proporcionar registros de auditoría detallados y admitir la aplicación automatizada de políticas de seguridad.
Los entornos de ejecución de contenedores modernos, como CRI-O y containerd, proporcionan una base de cumplimiento normativo mejor que Docker, ya que ofrecen controles de seguridad más granulares, un mejor registro de auditoría y una separación más clara entre los componentes del entorno de ejecución y las interfaces de gestión.
El cumplimiento normativo también se extiende a la seguridad de la cadena de suministro, garantizando que las imágenes de los contenedores procedan de fuentes fiables y no hayan sido manipuladas. Herramientas como Sigstore e in-toto proporcionan verificación criptográfica del origen de las imágenes de contenedores, mientras que los controladores de admisión pueden garantizar que solo se ejecuten imágenes firmadas y escaneadas en los clústeres de producción.
El panorama de la contenedorización sigue evolucionando más allá de los contenedores Linux tradicionales hacia nuevos modelos de ejecución y paradigmas de observabilidad. Estas tecnologías emergentes prometen abordar las limitaciones fundamentales de las arquitecturas de contenedores actuales.
WebAssembly (WASM) se está convirtiendo en una alternativa atractiva a los contenedores OCI tradicionales para cargas de trabajo específicas. A diferencia de los contenedores que empaquetan todo el espacio de usuario del sistema operativo, WebAssembly proporciona un entorno de ejecución ligero y aislado que funciona a velocidades casi nativas en diferentes arquitecturas.
Los módulos WASM se inician mucho más rápido que los contenedores tradicionales, lo que los hace ideales para funciones sin servidor y computación periférica, donde el tiempo de arranque en frío afecta directamente a la experiencia del usuario. Un módulo WebAssembly puede gestionar muchas más solicitudes que un contenedor con tiempos de inicialización más lentos.
El modelo de seguridad difiere fundamentalmente del de los contenedores. WebAssembly proporciona seguridad basada en capacidades, en la que los módulos solo pueden acceder a los recursos que se les han concedido explícitamente. No hay una superficie de kernel compartida como en los contenedores tradicionales: los módulos WASM se ejecutan en un entorno aislado que evita muchos tipos de vulnerabilidades de seguridad.
Los tiempos de ejecución de contenedores están empezando a admitir directamente las cargas de trabajo de WebAssembly. Wasmtime integra con containerd como un shim de tiempo de ejecución, lo que te permite implementar módulos WASM utilizando YAML estándar de Kubernetes. Esto significa que puedes mezclar contenedores tradicionales y cargas de trabajo de WebAssembly en el mismo clúster en función de los requisitos de rendimiento y seguridad.
La contrapartida es la madurez del ecosistema. WebAssembly tiene una compatibilidad lingüística limitada en comparación con los contenedores: Rust, C/C++ y AssemblyScript funcionan bien, mientras que lenguajes como Python y Java requieren capas de tiempo de ejecución adicionales que reducen las ventajas de rendimiento.
WASM destaca por sus cargas de trabajo computacionales, funciones sin servidor y computación periférica, pero no está preparado para sustituir a los contenedores en aplicaciones complejas que requieren una amplia integración con el sistema operativo.
eBPF (extended Berkeley Packet Filter) está transformando la observabilidad de los contenedores al proporcionar información a nivel del núcleo sin necesidad de modificar las aplicaciones ni utilizar contenedores sidecar. A diferencia de la supervisión tradicional, que se basa en métricas exportadas por las aplicaciones, los programas eBPF observan las llamadas al sistema, el tráfico de red y los eventos del núcleo en tiempo real.
La supervisión consciente de contenedores a través de eBPF correlaciona los eventos del sistema de bajo nivel con los metadatos de contenedores y Kubernetes de alto nivel. Herramientas de supervisión de tráfico HTTP como Pixie y Cilium Hubble puedenmostrarte exactamente qué solicitudes HTTP fluyen entre pods específicos, incluyendo la latencia de las solicitudes, la inspección de la carga útil y las tasas de error, todo ello sin modificar tus aplicaciones.
Este enfoque proporciona una visibilidad sin precedentes de los patrones de comunicación de los microservicios. Puedes generar mapas de servicio automáticamente observando los flujos reales de la red en lugar de basarte en una configuración estática. Cuando un servicio comienza a comunicarse con una nueva dependencia, las herramientas basadas en eBPF lo detectan inmediatamente y actualizan la topología del servicio en tiempo real.
El perfilado del rendimiento a través de eBPF identifica los cuellos de botella a nivel de contenedor. En lugar de intentar adivinar por qué un pod es lento, puedes ver exactamente qué llamadas al sistema están tardando más tiempo, a qué archivos se está accediendo y cómo la latencia de la red afecta al rendimiento de la aplicación. Estos datos se recopilan de forma continua con una sobrecarga mínima, normalmente inferior al 1 % del uso de la CPU.
La supervisión de la seguridad se beneficia de la capacidad de eBPF para detectar patrones de comportamiento anómalos. En lugar de analizar los registros después de un incidente, los programas eBPF pueden detectar llamadas al sistema sospechosas, conexiones de red inesperadas o patrones de acceso a archivos a medida que se producen. Esto permite la detección de amenazas en tiempo real que tiene en cuenta el contexto de los límites de los contenedores y la identidad de la carga de trabajo de Kubernetes.
La integración entre eBPF y los tiempos de ejecución de contenedores sigue profundizándose. Cilium proporciona redes basadas en eBPF para Kubernetes que son más rápidas y observables que los complementos CNI tradicionales. Falco utiliza eBPF para la supervisión de la seguridad en tiempo de ejecución, que comprende el contexto de los contenedores de forma nativa.
Esta tendencia hacia la observabilidad a nivel del núcleo representa un cambio fundamental, pasando de la supervisión de caja negra a la transparencia completa del sistema, lo que hace que los entornos de contenedores sean más fáciles de depurar y más seguros por defecto.
Elegir la alternativa adecuada a Docker no consiste en encontrar un único sustituto, sino en encontrar las herramientas que mejor se adapten a los casos de uso específicos de tus entornos de desarrollo y producción. El ecosistema de contenedorización ha madurado hasta convertirse en un conjunto de soluciones que destacan en diferentes escenarios.
Para la experiencia de los programadores, Podman ofrece la ruta de migración más fluida gracias a su compatibilidad con la CLI de Docker, al tiempo que proporciona una seguridad superior mediante un funcionamiento sin root. Si estás muy involucrado en los flujos de trabajo de Docker Desktop, Rancher Desktop con containerd ofrece una funcionalidad similar con una mayor eficiencia de recursos. Los equipos que crean complejos procesos de CI/CD se benefician de la flexibilidad de los scripts de Buildah o del enfoque seguro y sin demonios de Kaniko.
A escala de producción,, containerd y CRI-O ofrecen un mejor rendimiento y una mayor eficiencia de recursos que Docker Engine. Containerd destaca en entornos empresariales que necesitan estabilidad y amplios conjuntos de funciones, mientras que CRI-O ofrece la opción más eficiente para implementaciones centradas en Kubernetes. Para la computación periférica o los sistemas integrados, los entornos de ejecución ligeros como runC o Youki ofrecen la sobrecarga mínima necesaria para entornos con recursos limitados.
Las organizaciones preocupadas por la seguridad deben dar prioridad a entornos de ejecución sin privilegios de root, como Podman o containerd sin privilegios de root. La combinación del aislamiento del espacio de nombres de usuario, la supervisión basada en eBPF y la reducción de la superficie de ataque proporciona una defensa en profundidad que las implementaciones tradicionales de Docker no pueden igualar. En el caso de los sectores regulados, asegúrate de que el tiempo de ejecución elegido sea compatible con FIPS y se integre con los sistemas de registro de auditoría de la empresa.
En la práctica, un enfoque híbrido suele funcionar mejor. Utiliza Podman para el desarrollo local y benefíciate de la seguridad sin root y la compatibilidad con Docker. Implementa cargas de trabajo de producción en containerd o CRI-O para obtener una integración y un rendimiento óptimos de Kubernetes. Utiliza herramientas especializadas como Buildah para los procesos de CI/CD, donde la seguridad y la flexibilidad son más importantes que la compatibilidad.
¿Buscas ideas para proyectos relacionados con Docker y la contenedorización? Estos 10 te ayudarán a empezar.
De cara al futuro, WebAssembly y eBPF representan la próxima evolución en la contenedorización. Los rápidos tiempos de inicio y las sólidas garantías de seguridad de WebAssembly probablemente dominarán las cargas de trabajo de computación sin servidor y en el borde. La observabilidad a nivel del núcleo de eBPF ya está transformando la forma en que supervisamos y protegemos las aplicaciones en contenedores. Estas tecnologías no sustituirán por completo a los contenedores tradicionales, pero crearán nuevas categorías de cargas de trabajo en las que no se aplicarán las limitaciones actuales de los contenedores.
La clave es mantener la flexibilidad a medida que estas tecnologías maduran y comprender que la mejor estrategia de contenedorización combina múltiples herramientas en lugar de depender de una única solución.
Si deseas obtener más información sobre Docker, la contenedorización, la virtualización y Kubernetes, estos cursos son el siguiente paso perfecto:
¡Aprende más sobre Docker con estos cursos!
programa
Curso
Curso
blog
Kurtis Pykes
13 min
blog
Javier Canales Luna
13 min
blog
Elena Kosourova
14 min
blog
Gus Frazer
11 min
Tutorial
Bex Tuychiev
Tutorial
Adel Nehme

