
Programa
Containerização e virtualização com o Docker e o Kubernetes
13 h
O Podmané o desafio mais direto à abordagem arquitetônica do Docker.
Imagem 1 - Página inicial do Podman
A Red Hat desenvolveu isso especialmente para lidar com o modelo de segurança baseado em daemon do Docker, mantendo a compatibilidade com os fluxos de trabalho existentes.
Se você precisa de uma comparação mais detalhada entre o Docker e o Podman, nossa postagem no blog vai te ajudar a descobrir qual plataforma de conteinerização é a mais adequada para você.
A maior diferença entre o Podman e o Docker é que ele elimina completamenteo daemon. Em vez de passar os comandos por um serviço central, o Podman usa um modelo fork-exec, onde cada contêiner rola como um processo filho direto do usuário que o iniciou. Isso quer dizer que não tem nenhum serviço persistente em segundo plano, nenhum ponto único de falha e nenhum daemon de nível raiz cuidando dos seus contêineres.
Essa arquitetura se integra naturalmente ao systemd, o gerenciador de serviços padrão do Linux. Você pode criar arquivos de unidade systemd direto dos contêineres Podman, o que faz com que seus contêineres comecem automaticamente na inicialização, reiniciem em caso de falha e se integrem ao registro do sistema. É uma abordagem bem mais simples do que a camada de orquestração separada do Docker.
O Podman mantém total conformidade com a OCI, portanto, executa as mesmas imagens de contêiner que o Docker, sem modificações. O tempo de execução usa as mesmas tecnologias de base — runc para execução de contêineres e vários drivers de armazenamento para gerenciamento de imagens —, mas as empacota de maneira diferente.
A operação sem privilégios é o recurso de segurança que mais se destaca no Podman. Quando você usa contêineres com o Podman, eles rodam na sua conta de usuário, sem precisar de privilégios de root. Isso rola através do mapeamento do namespace do usuário, onde o usuário root do contêiner é mapeado para o seu ID de usuário sem privilégios no sistema host.
Isso elimina o vetor de ataque em que uma invasão do contêiner poderia comprometer todo o sistema host. Mesmo que um invasor consiga escapar do contêiner, ele ainda vai ficar limitado às permissões do seu usuário, em vez de ter acesso root à máquina.
Nos sistemas Red Hat Enterprise Linux e Fedora, o Podman se integra perfeitamente ao SELinux (Security-Enhanced Linux). O SELinux oferece controles de acesso obrigatórios que limitam o que os contêineres podem acessar no sistema host, mesmo que eles sejam comprometidos. Isso cria várias camadas de segurança — os namespaces de usuário evitam a escalação de privilégios, enquanto o SELinux impede o acesso não autorizado ao sistema de arquivos.
As implementações empresariais geralmente juntam esses recursos com ferramentas extras de verificação de segurança e aplicação de políticas para estratégias de defesa em profundidade.
O Podman mantém a compatibilidade com a CLI do Docker por meio do comando ` podman `, que aceita os mesmos argumentos que ` docker`. Você pode criar um alias (alias docker=podman) e a maioria dos scripts existentes vai funcionar sem precisar mexer em nada. Isso torna a migração do Docker muito mais fácil do que mudar para conjuntos de ferramentas completamente diferentes.
A interface gráfica do Podman Desktop oferece uma alternativa ao Docker Desktop para desenvolvedores que curtem interfaces gráficas. Inclui gerenciamento de contêineres, recursos de criação de imagens e integração com o Kubernetes para desenvolvimento local. O aplicativo para desktop pode se conectar a instâncias remotas do Podman e oferece funcionalidades parecidas com o painel do Docker Desktop.
Para fluxos de trabalho do Kubernetes, o Podman pode gerar manifestos YAML do Kubernetes a partir de contêineres em execução e oferece suporte ao gerenciamento de pods — executando vários contêineres que compartilham rede e armazenamento, parecido com os pods do Kubernetes.
O suporte ao Windows continua sendo a maior limitação do Podman. Embora o Podman Machine ofereça compatibilidade com o Windows por meio da virtualização, ele não é tão simples quanto a integração do WSL2 do Docker Desktop. Os desenvolvedores do Windows podem achar a configuração mais complicada.
A rede sem raiz tem implicações no desempenho. Sem privilégios de root, o Podman não consegue criar redes bridge diretamente, então ele usa a rede em modo de usuário (slirp4netns), o que aumenta a latência. Isso raramente é perceptível para cargas de trabalho de desenvolvimento, mas aplicativos de rede de alto rendimento podem apresentar desempenho reduzido.
A compatibilidade com o Docker Compose existe através do podman-compose, mas não tem todos os recursos 100% completos. Arquivos complexos do Compose podem precisar de ajustes, e alguns recursos avançados de rede não são suportados no modo sem root. As equipes que investiram pesadamente nos fluxos de trabalho do Docker Compose devem fazer testes completos antes de migrar.
Qual é a diferença entre o Docker Compose e o Kubernetes? Nossa comparação detalhada tem tudo o que você precisa.
Enquanto o Podman visa a compatibilidade com o Docker, o CRI-O e o containerd focam especificamente em ambientes de produção do Kubernetes. Esses tempos de execução eliminam recursos desnecessários para otimizar cargas de trabalho orquestradas.
Todo desenvolvedor precisa saber essas diferenças entre o Docker e o Kubernetes.
O CRI-O foi criado do zero para implementar a Interface de Tempo de Execução de Contêiner (CRI) do Kubernetes.

Imagem 2 - Página inicial do CRI-O
Inclui só o que o Kubernetes precisa — sem criação de imagens, sem gerenciamento de volume além do que os pods exigem e sem gerenciamento de contêineres independentes. Essa abordagem focada resulta em menor sobrecarga de memória e tempos de inicialização mais rápidos em comparação com o Docker.
A eficiência dos recursos do tempo de execução vem do seu design minimalista. O CRI-O não mantém um daemon com APIs extensas ou serviços em segundo plano. Ele inicia contêineres, gerencia seu ciclo de vida de acordo com as instruções do Kubernetes e sai de cena. Isso o torna ideal para ambientes com recursos limitados ou implantações em grande escala, onde cada megabyte de memória é importante.
O CRI-O suporta qualquer tempo de execução compatível com OCI como seu executor de baixo nível. Embora o padrão seja runc, você pode trocar por alternativas como crun (escrito em C para melhor desempenho) ou gVisor (para isolamento aprimorado) sem alterar sua configuração do Kubernetes. Essa flexibilidade permite que você otimize requisitos específicos de segurança ou desempenho no nível de tempo de execução.
O projeto mantém uma compatibilidade rigorosa com os ciclos de lançamento do Kubernetes, garantindo que os novos recursos e atualizações de segurança estejam alinhados com as versões do seu cluster.
O Containerd começou como o tempo de execução subjacente do Docker antes de se tornar um projeto independente sob a Cloud Native Computing Foundation.

Imagem 3 - Página inicial do Containerd
O Docker ainda usa o containerd internamente, mas você pode executá-lo diretamente para eliminar as camadas adicionais e a sobrecarga do Docker.
A arquitetura gira em torno de uma API shim que oferece interfaces estáveis para gerenciar contêineres. Cada contêiner tem seu próprio processo de shim, que cuida do ciclo de vida do contêiner de forma independente. Se o daemon containerd principal reiniciar, os contêineres em execução continuam sem interrupção — um recurso essencial para cargas de trabalho de produção que não podem ficar paradas.
Esse design torna o containerd super estável para aplicativos empresariais de longa duração. A arquitetura shim também permite recursos como migração ao vivo e atualizações sem tempo de inatividade, onde você pode atualizar o tempo de execução sem afetar os contêineres em execução.
O Containerd inclui gerenciamento de imagens integrado, instantâneos para armazenamento eficiente de camadas e sistemas de plug-ins para ampliar as funcionalidades. Os principais provedores de nuvem, como AWS EKS, Google GKE e Azure AKS, usam o containerd como seu tempo de execução padrão por causa dessa arquitetura reforçada para produção.
Veja como esses tempos de execução se comparam para implantações de Kubernetes em produção:
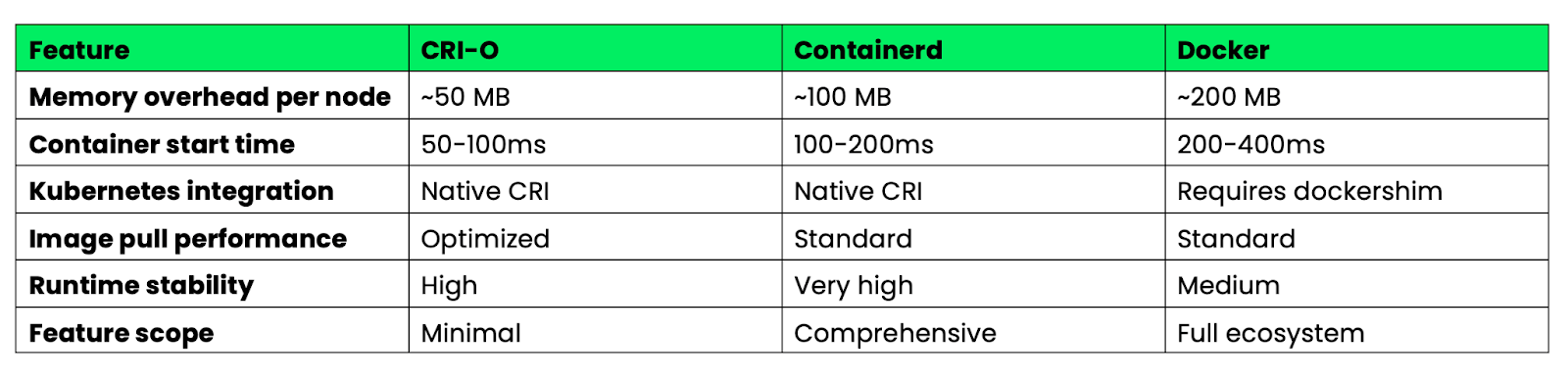
Imagem 4 - Características de desempenho do Docker vs CRI-O vs Containerd
O CRI-O é ótimo em eficiência de recursos e velocidade de inicialização por causa do seu design simples. O Containerd oferece o melhor equilíbrio entre recursos e estabilidade para ambientes corporativos. O Docker tem mais recursos, mas com uma sobrecarga maior que não é necessária nos ambientes Kubernetes.
Para clusters Kubernetes de produção, tanto o CRI-O quanto o containerd eliminam a camada de compatibilidade dockershim, reduzindo a complexidade e melhorando o desempenho em comparação com configurações baseadas em Docker.
Enquanto os runtimes de alto nível, como Podman e containerd, cuidam do gerenciamento de imagens e APIs, os runtimes de baixo nível focam só na execução de contêineres. Essas ferramentas são a base que faz a maioria das plataformas de conteinerização funcionar.
O runC é tipo a implementação de referência da Especificação de Tempo de Execução OCI — é o exemplo clássico de como os contêineres devem realmente funcionar. A maioria das plataformas de contêineres usa o runC como mecanismo de execução, incluindo Docker, containerd, CRI-O e Podman. Quando você inicia um contêiner com qualquer uma dessas ferramentas, o runC provavelmente está cuidando da criação e do isolamento do processo.
O tempo de execução implementa primitivas básicas do contêiner: criação de namespaces Linux para isolamento, configuração de cgroups para limites de recursos e configuração de contextos de segurança. Ele foi escrito em Go e projetado para ser simples, confiável e compatível com as especificações, em vez de rico em recursos.
O runC é ótimo pra sistemas embarcados e pilhas de contêineres personalizadas, onde você precisa de um comportamento previsível e dependências mínimas. Como ele só lida com a execução de contêineres, você pode criar plataformas de contêineres especializadas sem pegar complexidade desnecessária. Dispositivos IoT, plataformas de computação de ponta e sistemas de orquestração personalizados costumam usar o runC diretamente, em vez de tempos de execução de nível superior.
A ferramenta funciona como um utilitário de linha de comando que lê as especificações do pacote OCI e cria contêineres de acordo com elas. Isso o torna perfeito para integrar em sistemas já existentes ou criar ferramentas personalizadas de gerenciamento de contêineres.
Youki reimplementaa especificação OCI Runtime em Rust, com foco na segurança da memória e no desempenho. A implementação do Rust elimina classes inteiras de vulnerabilidades de segurança que podem afetar os tempos de execução do C e do Go, ao mesmo tempo em que melhora os tempos de inicialização dos contêineres por meio de um gerenciamento de memória mais eficiente e uma redução da sobrecarga.
Os benchmarks mostram que o Youki inicia os contêineres mais rápido que o runC em muitos casos, embora a melhoria exata varie de acordo com a carga de trabalho. Essa melhoria vem das abstrações de custo zero do Rust e dos padrões de alocação de memória mais eficientes. Para aplicativos que criam e destroem muitos contêineres de curta duração, essas melhorias no tempo de inicialização podem ser significativas.
O Youki é totalmente compatível com a especificação OCI Runtime, então funciona como um substituto direto para o runC na maioria das plataformas de contêineres. O Docker Engine, o containerd e outros runtimes de alto nível podem usar o Youki sem precisar mexer na configuração ou nas APIs deles.
O tempo de execução traz vantagens para cargas de trabalho que exigem muito desempenho, como funções sem servidor, pipelines de CI/CD com muitas compilações de contêineres e arquiteturas de microsserviços com eventos de dimensionamento frequentes. Os tempos de inicialização mais rápidos significam menos tempo de espera e melhor uso dos recursos nesses casos.
O Youki também tem recursos como otimização do cgroup v2 e suporte melhorado para contêineres rootless, que aproveitam o sistema de tipos do Rust pra evitar erros de configuração na hora da compilação.
Nem toda a conteinerização precisa se concentrar em aplicativos únicos — às vezes, você precisa executar sistemas operacionais inteiros em contêineres. O LXC e o LXD oferecem uma containerização em nível de sistema que é bem diferente da abordagem focada em aplicativos do Docker.
O LXC (Linux Containers)cria contêineres que funcionam como sistemas Linux completos, em vez de processos de aplicativos isolados.
Imagem 5 - Página inicial do LXC
Cada contêiner LXC tem seu próprio sistema init, pode hospedar vários serviços e oferece um ambiente completo de espaço do usuário que é quase igual a uma máquina virtual.
Essa abordagem é excelente para cargas de trabalho legadas que não foram projetadas para conteinerização. Os aplicativos que precisam gravar em /etc, rodar serviços do sistema ou interagir com toda a hierarquia do sistema de arquivos funcionam perfeitamente em contêineres LXC. Você pode transferir configurações completas de servidor para o LXC sem precisar refatorar aplicativos para arquiteturas de microsserviços.
Os contêineres LXC compartilham o kernel do host, mas têm um isolamento mais forte do que os contêineres de aplicativos. Cada contêiner tem sua própria pilha de rede, árvore de processos e namespace do sistema de arquivos, criando um isolamento semelhante ao de uma VM sem a sobrecarga da virtualização de hardware.
O LXD, agora uma da Canonical, adiciona uma poderosa camada de gerenciamento ao LXC. O LXD oferece APIs REST, gerenciamento de imagens e recursos avançados, como migração ao vivo entre hosts. Você pode mover contêineres em execução entre máquinas físicas sem tempo de inatividade, parecido com o VMware vMotion, mas com contêineres.
Os recursos de passagem de hardware permitem que os contêineres LXD acessem GPUs, dispositivos USB e outros hardwares diretamente. Isso o torna adequado para cargas de trabalho que precisam de acesso a hardware especializado, mantendo os benefícios do contêiner, como densidade e provisionamento rápido.
O LXD também suporta clustering, permitindo que você gerencie vários hosts como uma única unidade lógica com recursos automatizados de posicionamento e failover.
Veja como os contêineres de sistema se comparam aos contêineres de aplicativos em relação às principais características:
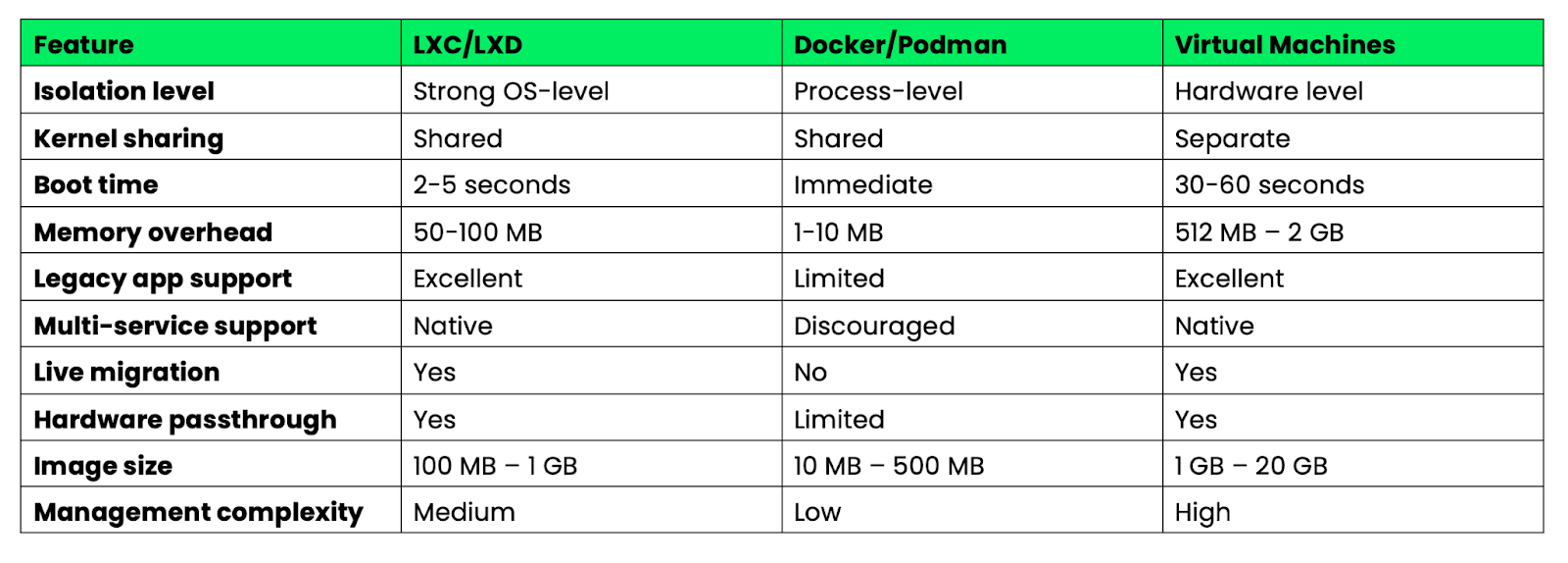
Imagem 6 - Visão geral das principais características do Docker, LXC e máquinas virtuais
Os contêineres de sistema preenchem a lacuna entre os contêineres de aplicativos leves e as máquinas virtuais pesadas. São ideais quando você precisa de recursos semelhantes aos de uma VM com a eficiência de um contêiner ou ao migrar aplicativos legados que não podem ser facilmente decompostos em microsserviços.
A escolha entre contêineres de sistema e de aplicativos depende mais das características da sua carga de trabalho e dos requisitos operacionais do que da superioridade técnica — eles resolvem problemas diferentes no espectro da conteinerização.
A segurança passou de algo secundário para um princípio básico de design nos tempos de execução de contêineres modernos. As plataformas de hoje usam estratégias de defesa em profundidade que acham que os contêineres vão ser comprometidos e se concentram em limitar o alcance do dano.
Os contêineres sem raiz eliminam o maior risco de segurança nas implantações tradicionais do Docker: o daemon root. O Podman foi o primeiro a usar essa abordagem, rodando contêineres totalmente com privilégios de usuário, usando namespaces de usuário do Linux para mapear o usuário root do contêiner para um ID de usuário sem privilégios no sistema host.
A implementação depende de intervalos de IDs de usuários e grupos subordinados (/etc/subuid e /etc/subgid) que permitem que usuários sem privilégios criem namespaces isolados. Quando um processo de contêiner acha que está rodando como root (UID 0), o kernel mapeia isso para o seu ID de usuário real (digamos, UID 1000) no host. Mesmo que um invasor consiga escapar do contêiner, ele não vai conseguir ir além das permissões do seu usuário.
O Containerd implementou recursos sem raiz parecidos com o seu modo sem raiz, que usa as mesmas técnicas de mapeamento de namespace do usuário. O tempo de execução pode iniciar contêineres, gerenciar imagens e lidar com redes sem precisar de privilégios de root no sistema host.
O Kubernetes agora suporta operação sem root de forma nativa atravésdo projeto Kubernetes-in-Rootless-Docker (KIND) e da integração com o containerd sem root. Isso significa que clusters Kubernetes inteiros podem ser executados sem privilégios de root, reduzindo drasticamente a superfície de ataque para ambientes multilocatários e implantações de borda onde os modelos de segurança tradicionais não se aplicam.
O impacto na segurança vai além da prevenção da escalada de privilégios. Os contêineres sem raiz não podem se conectar a portas privilegiadas (abaixo de 1024), não podem acessar a maioria dos sistemas de arquivos /proc e /sys e não podem fazer operações que precisam de recursos do kernel. Isso cria limites naturais que evitam possíveis falhas de segurança.
Os tempos de execução modernos têm o eBPF (extended Berkeley Packet Filter) para aplicar políticas de segurança em tempo real, indo além dos controles de acesso tradicionais. Os programas eBPF rodam no espaço do kernel e podem monitorar, filtrar ou modificar chamadas do sistema enquanto elas acontecem, oferecendo uma visibilidade e um controle sem igual sobre o comportamento dos contêineres.
Os perfis Seccomp (Secure Computing) usam BPF para filtrar chamadas do sistema no nível do kernel. Em vez de deixar os contêineres acessarem todas as mais de 300 chamadas do sistema Linux, os perfis seccomp definem exatamente quais chamadas são permitidas. O perfil seccomp padrão do Docker bloqueia chamadas de sistema potencialmente perigosas, enquanto perfis personalizados podem ser ainda mais restritivos com base nos requisitos da aplicação.
A integração avançada do eBPF permite monitorar o comportamento em tempo real. Ferramentas como o Falco usam programas eBPF pra detectar comportamentos anômalos em contêineres — conexões de rede incomuns, padrões inesperados de acesso a arquivos ou tentativas de usar chamadas de sistema bloqueadas. Essas detecções acontecem em tempo real com um impacto mínimo no desempenho, já que o monitoramento rola no espaço do kernel.
A aplicação da política de rede por meio do eBPF oferece um controle de tráfego bem detalhado no nível do pacote. O Cilium, um CNI popular do Kubernetes, usa eBPF pra implementar políticas de rede que podem filtrar o tráfego com base nos protocolos da camada de aplicação, não só nos endereços IP e portas. Isso quer dizer que você pode criar políticas como “permitir solicitações HTTP GET para /api/v1/users, mas bloquear solicitações POST” diretamente no kernel.
A segurança baseada em eBPF também permite o monitoramento consciente de contêineres, que entende a relação entre processos, contêineres e pods do Kubernetes. As ferramentas de monitoramento tradicionais veem processos individuais, mas os programas eBPF podem correlacionar chamadas do sistema com metadados de contêineres para fornecer insights de segurança sensíveis ao contexto.
Esses recursos transformam a segurança de uma aplicação reativa de patches para uma aplicação proativa de políticas, onde comportamentos suspeitos são bloqueados automaticamente antes que possam causar danos.
O desempenho dos contêineres é super importante quando você está rodando centenas ou milhares deles na sua infraestrutura. Vamos ver estratégias que minimizam o consumo de recursos e a latência de inicialização.
O tempo de inicialização a frio — o tempo que leva entre pedir um contêiner e ele ficar pronto para servir o tráfego — afeta diretamente a experiência do usuário e a eficiência dos recursos. Técnicas surgiram para minimizar esses atrasos em diferentes arquiteturas de tempo de execução.
Imagens pré-baixadas eliminam o tempo de download, mantendo as imagens de contêiner usadas com frequência armazenadas em cache nos nós. Os DaemonSets do Kubernetes podem fazer o pré-download de imagens importantes, enquanto registros como o Harbor ajudam na replicação de imagens para locais de ponta. Essa técnica pode reduzir o tempo de inicialização a frio de segundos para milissegundos para imagens armazenadas em cache.
A otimização da camada de imagem reduz a quantidade de dados que precisam ser transferidos e extraídos. As composições em várias etapas criam imagens finais menores, enquanto ferramentas como o dive ajudam a identificar camadas desnecessárias. As imagens sem distribuição do Google eliminam os gerenciadores de pacotes e shells, muitas vezes reduzindo significativamente o tamanho das imagens.
O carregamento lento com projetos como o Stargz permite que os contêineres sejam iniciados antes que toda a imagem seja baixada. O tempo de execução só pega os arquivos necessários para a inicialização inicial, baixando camadas adicionais quando precisar. Isso pode reduzir o tempo de inicialização a frio de vários segundos para menos de 1 segundo para imagens grandes.
A otimização do tempo de execução varia de acordo com a implementação. A implementação do Rust por Youki mostra um desempenho de inicialização melhor em comparação com o runC, graças a um gerenciamento de memória mais eficiente. O Crun, escrito em C, consegue melhorias parecidas ao eliminar a sobrecarga da coleta de lixo do Go durante a criação de contêineres.
Compartilhamento de instantâneos O recurso no containerd permite que vários contêineres compartilhem instantâneos do sistema de arquivos somente leitura, reduzindo a sobrecarga de armazenamento e memória. Ao iniciar vários contêineres a partir da mesma imagem, só as camadas graváveis precisam de alocação separada.
Otimização do processo de inicialização pode reduzir o tempo de inicialização usando sistemas de inicialização leves, como o tini, ou projetando cuidadosamente as sequências de inicialização dos aplicativos para minimizar o trabalho de inicialização.
A sobrecarga de memória varia entre os tempos de execução dos contêineres, com as diferenças se tornando críticas em ambientes com recursos limitados ou implantações de alta densidade.
A sobrecarga da linha de base de tempo de execução difere substancialmente:
A deduplicação de camadas de imagem economiza memória quando você está rodando vários contêineres a partir de imagens relacionadas. Os tempos de execução dos contêineres usam sistemas de arquivos copy-on-write, nos quais as camadas compartilhadas usam memória apenas uma vez em todos os contêineres. Um cluster que roda muitos contêineres a partir de imagens base parecidas pode economizar bastante memória com a deduplicação.
A otimização do mapeamento de memória em tempos de execução modernos reduz o uso de memória residente. Ferramentas como o crun mapeiam arquivos executáveis diretamente do armazenamento, em vez de carregá-los na memória, reduzindo o consumo de memória para contêineres com binários grandes.
A contabilidade de memória Cgroup dá um controle preciso sobre os limites de memória do contêiner, mas diferentes tempos de execução lidam com a pressão de memória de maneiras diferentes. Alguns runtimes fazem uma melhor recuperação de memória sob pressão, enquanto outros oferecem relatórios mais precisos sobre o uso da memória para decisões de autoescalonamento.
O overhead de memória sem raiz troca um pouco de eficiência por segurança. Os contêineres sem root precisam de processos extras para gerenciar o namespace do usuário e a rede, o que geralmente aumenta a sobrecarga em comparação com a operação com root.
A escolha entre os tempos de execução geralmente se resume a equilibrar a eficiência da memória com os requisitos de recursos. O CRI-O oferece baixo overhead para cargas de trabalho do Kubernetes, enquanto o Podman sacrifica um pouco da eficiência em troca de benefícios de segurança e compatibilidade.
O melhor tempo de execução de contêiner não vale nada se não se encaixar no seu fluxo de trabalho de desenvolvimento. As alternativas ao Docker têm implementado ferramentas que muitas vezes superam a experiência do desenvolvedor do Docker em cenários específicos.
O desenvolvimento local do Kubernetes foi além da abordagem de máquina virtual do minikube para soluções mais eficientes que se integram diretamente com os tempos de execução de contêineres. A escolha do ambiente local tem um impacto significativo na velocidade de desenvolvimento e no consumo de recursos.
Kind (Kubernetes no Docker) O cria clusters Kubernetes usando nós de contêiner em vez de máquinas virtuais. O tempo de configuração é normalmente de 1 a 2 minutos, com uma sobrecarga moderada de memória por nó. O Kind funciona com qualquer tempo de execução compatível com o Docker, então você pode usá-lo com o Podman (kind create cluster --runtime podman) para desenvolvimento Kubernetes sem root.
O K3s oferece uma opção leve, rodando uma distribuição Kubernetes completa com o mínimo de uso de memória. Ele inicia rapidamente e inclui armazenamento integrado, rede e controladores de entrada. O K3s funciona bem com o containerd e pode ser executado em máquinas de desenvolvimento com recursos limitados.
O MicroK8s da Canonical oferece um meio-termo com uso moderado de memória e complementos modulares. Ele se integra bem com o containerd e oferece recursos parecidos com os de produção, sem a sobrecarga da máquina virtual. O tempo de inicialização é razoável para um cluster completo.
O Rancher Desktop junta o K3s com os backends containerd ou Dockerd, oferecendo uma alternativa ao Docker Desktop que usa menos recursos. Inclui digitalização de imagens integrada e integração com o painel do Kubernetes.
Os pods do Podman oferecem uma alternativa única: você pode desenvolver aplicativos com vários contêineres usando o conceito de pod do Podman, que é parecido com o comportamento do pod do Kubernetes. Gere Kubernetes YAML direto dos pods em execução usando o podman generate kube, criando um caminho tranquilo do desenvolvimento local até a implantação do cluster.
Os pipelines tradicionais de CI/CD baseados em Docker têm limitações em ambientes conteinerizados, onde rodar o Docker-in-Docker traz desafios de segurança e desempenho. As alternativas modernas oferecem soluções melhores para criar e enviar imagens de contêineres em sistemas de CI.
O Buildah se destaca em ambientes de CI porque não precisa de um daemon ou privilégios de root. Você pode criar imagens compatíveis com OCI usando scripts de shell, que são mais fáceis de auditar do que os Dockerfiles. A abordagem de script do Buildah permite a construção dinâmica de imagens com base em variáveis CI, tornando-o ideal para processos de compilação complexos que precisam de lógica condicional.

Imagem 7 - Página inicial do Buildah
Pra comparar, os Dockerfiles tradicionais usam instruções declarativas:
FROM alpine:latest
RUN apk add --no-cache nodejs npm
COPY package.json /app/
WORKDIR /appO Buildah usa comandos imperativos do shell que podem incluir variáveis e lógica condicional:
# Buildah scripting approach with CI integration
buildah from alpine:latest
buildah run $container apk add --no-cache nodejs npm
buildah copy $container package.json /app/
buildah config --workingdir /app $container
buildah commit $container myapp:${CI_COMMIT_SHA}Essa flexibilidade de script permite que você escolha dinamicamente imagens base, instale pacotes condicionalmente com base nos nomes dos branches ou modifique etapas de compilação com base nas variáveis de ambiente CI — recursos que exigem soluções alternativas complexas nos Dockerfiles tradicionais.
O Kaniko resolve o problema do Docker-in-Docker () criando imagens inteiramente no espaço do usuário dentro de um contêiner. Ele rola em pods do Kubernetes sem precisar de acesso privilegiado ou do daemon do Docker. O Kaniko é eficaz em pipelines GitLab CI e Jenkins X, onde as políticas de segurança impedem contêineres privilegiados.
A ferramenta pega imagens base, aplica instruções do Dockerfile de forma isolada e manda os resultados direto para os registros. Os tempos de compilação são parecidos com os do Docker, mas com uma postura de segurança muito melhor em ambientes orquestrados.
O Nerdctl oferece compatibilidade com a CLI do Docker ( ) para o containerd, o que o torna um excelente substituto para o Docker em sistemas de CI. Ele suporta os mesmos comandos de compilação, envio e extração que o Docker, mas usa o containerd como backend. Isso elimina o daemon do Docker, mas mantém os fluxos de trabalho que você já conhece.
O Nerdctl tem recursos avançados, tipo lazy pulling e imagens criptografadas, que podem melhorar o desempenho da CI. Para equipes que usam o containerd na produção, o nerdctl cria consistência entre os ambientes de CI e de tempo de execução.
Comparando o desempenho em pipelines de CI:
A escolha depende dos seus requisitos de segurança, da infraestrutura existente e das necessidades de desempenho. O Kaniko funciona melhor em ambientes Kubernetes focados em segurança, enquanto o Buildah é ótimo quando você precisa de uma lógica de compilação complexa que é difícil de expressar em Dockerfiles.
A implantação de contêineres corporativos exige mais do que só escolher o tempo de execução certo — você precisa de plataformas que cuidem da conformidade, governança e operações em vários clusters em grande escala. As alternativas de contêiner que você escolher precisam se integrar às ferramentas de gerenciamento empresarial e atender aos requisitos regulatórios.
Gerenciar contêineres em vários clusters, nuvens e locais de borda precisa de plataformas de orquestração sofisticadas que vão além do Kubernetes básico. As soluções empresariais oferecem gerenciamento centralizado, aplicação de políticas e consistência operacional em vários ambientes.
O Red Hat OpenShift cria um e no Kubernetes com opções de tempo de execução de contêiner voltadas para empresas. O OpenShift usa o CRI-O por padrão pra garantir mais segurança e eficiência de recursos em comparação com as implantações baseadas no Docker. A plataforma inclui digitalização de imagens integrada, aplicação de políticas e fluxos de trabalho de desenvolvedores que funcionam de maneira consistente, independentemente de você estar executando na AWS, no Azure ou em uma infraestrutura local.

Imagem 8 - Página inicial do Red Hat OpenShift
O gerenciamento de vários clusters do OpenShift cuida da padronização do tempo de execução em todos os ambientes. Você pode fazer com que todos os clusters usem o CRI-O com políticas de segurança específicas, garantindo um comportamento consistente, seja os contêineres rodando em ambientes de desenvolvimento, teste ou produção.
O Rancher oferece uma interface unificada para gerenciar clusters do Kubernetes, independentemente do tempo de execução do contêiner subjacente. O Rancher dá suporte a clusters que rodam Docker, containerd ou CRI-O, permitindo que você migre os tempos de execução aos poucos, sem atrapalhar as operações. A plataforma inclui monitoramento centralizado, backup e verificação de segurança em todos os clusters gerenciados.
Imagem 9 - Página inicial do Rancher
A abordagem do Rancher é útil quando você tem ambientes mistos — alguns clusters podem usar o containerd por causa do desempenho, enquanto outros usam o CRI-O por causa da conformidade de segurança. A camada de gerenciamento abstrai essas diferenças, ao mesmo tempo em que fornece ferramentas operacionais consistentes.
O Mirantis Kubernetes Engine foca em ambientes Docker empresariais, mas dá suporte à migração para implantações baseadas em containerd. A plataforma oferece suporte empresarial, reforço de segurança e ferramentas de conformidade que funcionam em diferentes tempos de execução de contêineres.
Imagem 10 - Página inicial da Mirantis
Essas plataformas resolvem a complexidade operacional de executar diferentes tempos de execução de contêineres em toda a sua infraestrutura, mantendo a governança centralizada e as políticas de segurança.
Os ambientes empresariais muitas vezes precisam seguir regras como FIPS 140-2, SOC 2 ou GDPR, que afetam diretamente a escolha e a configuração do tempo de execução do contêiner. A conformidade não é só sobre o tempo de execução em si — ela vai além, abrangendo registros de imagens, varreduras de segurança e registros de auditoria.
A validação FIPS (Federal Information Processing Standards) precisa de módulos criptográficos que cumpram as normas de segurança do governo. Nem todos os tempos de execução de contêineres suportam bibliotecas criptográficas validadas pela FIPS. O Red Hat Enterprise Linux oferece versões compatíveis com FIPS do CRI-O e do Podman, enquanto as instalações padrão do Docker geralmente precisam de configurações extras para ficarem em conformidade com o FIPS.
A conformidade com FIPS afeta a assinatura de imagens, as comunicações TLS e o armazenamento criptografado. As plataformas de contêineres precisam usar bibliotecas criptográficas validadas pela FIPS para todas as operações de segurança, desde a extração de imagens até o estabelecimento de conexões de rede entre contêineres.
A conformidade com o GDPR afeta como as plataformas de contêineres lidam com dados pessoais em registros, métricas e metadados de imagens. Registros de contêineres empresariais como Harbor, Quay e AWS ECR oferecem recursos como controles de residência de dados, registros de auditoria e políticas automatizadas de retenção de dados.
Os tempos de execução dos contêineres precisam ter recursos de conformidade, tipo:
A conformidade com a SOC 2 exige controles de segurança comprováveis em torno do gerenciamento de acesso, monitoramento do sistema e proteção de dados. As plataformas de contêineres precisam se integrar com os provedores de identidade corporativos, fornecer trilhas de auditoria detalhadas e oferecer suporte à aplicação automatizada de políticas de segurança.
Os tempos de execução de contêineres modernos, como CRI-O e containerd, oferecem uma base de conformidade melhor do que o Docker, porque têm controles de segurança mais detalhados, registros de auditoria melhores e uma separação mais clara entre os componentes de tempo de execução e as interfaces de gerenciamento.
A conformidade também se estende à segurança da cadeia de suprimentos, garantindo que as imagens dos contêineres venham de fontes confiáveis e não tenham sido adulteradas. Ferramentas como Sigstore e in-toto fazem a verificação criptográfica da origem da imagem do contêiner, enquanto os controladores de admissão podem garantir que só imagens assinadas e verificadas sejam executadas nos clusters de produção.
O cenário da conteinerização continua evoluindo além dos contêineres Linux tradicionais, rumo a novos modelos de execução e paradigmas de observabilidade. Essas tecnologias novas prometem resolver as limitações básicas das arquiteturas de contêineres atuais.
O WebAssembly (WASM) está surgindo como uma alternativa atraente aos contêineres OCI tradicionais para cargas de trabalho específicas. Diferente dos contêineres que empacotam todo o espaço do usuário do sistema operacional, o WebAssembly oferece um ambiente de execução leve e isolado que funciona quase na velocidade nativa em diferentes arquiteturas.
Os módulos WASM iniciam muito mais rápido do que os contêineres tradicionais, tornando-os ideais para funções sem servidor e computação de ponta, onde o tempo de inicialização a frio afeta diretamente a experiência do usuário. Um módulo WebAssembly consegue lidar com muito mais solicitações do que um contêiner com tempos de inicialização mais lentos.
O modelo de segurança é bem diferente dos contêineres. O WebAssembly oferece segurança baseada em recursos, onde os módulos só podem acessar recursos explicitamente concedidos. Não tem área de kernel compartilhada como nos contêineres tradicionais — os módulos WASM rodam em um ambiente sandbox que evita vários tipos de vulnerabilidades de segurança.
Os tempos de execução de contêineres estão começando a suportar cargas de trabalho WebAssembly diretamente. O Wasmtime junta o com o containerd como um shim de tempo de execução, permitindo que você implemente módulos WASM usando o YAML padrão do Kubernetes. Isso quer dizer que você pode misturar contêineres tradicionais e cargas de trabalho WebAssembly no mesmo cluster, dependendo dos requisitos de desempenho e segurança.
A contrapartida é a maturidade do ecossistema. O WebAssembly tem suporte limitado a linguagens em comparação com os contêineres — Rust, C/C++ e AssemblyScript funcionam bem, enquanto linguagens como Python e Java precisam de camadas de tempo de execução adicionais que diminuem os benefícios de desempenho.
O WASM é ótimo para cargas de trabalho computacionais, funções sem servidor e computação de ponta, mas ainda não está pronto para substituir os contêineres em aplicativos complexos que precisam de muita integração com o sistema operacional.
O eBPF (extended Berkeley Packet Filter) está mudando a observabilidade dos contêineres, oferecendo insights no nível do kernel sem precisar mexer nas aplicações ou usar contêineres sidecar. Diferente do monitoramento tradicional, que depende de métricas exportadas por aplicativos, os programas eBPF observam chamadas do sistema, tráfego de rede e eventos do kernel em tempo real.
O monitoramento com reconhecimento de contêineres por meio do eBPF conecta eventos de baixo nível do sistema com metadados de alto nível do contêiner e do Kubernetes. Ferramentas de monitoramento de tráfego de aplicativos (ools) como Pixie e Cilium Hubble podemmostrar exatamente quais solicitações HTTP fluem entre pods específicos, incluindo latência de solicitação, inspeção de carga útil e taxas de erro, tudo isso sem precisar mexer nos seus aplicativos.
Essa abordagem oferece uma visibilidade sem precedentes dos padrões de comunicação dos microsserviços. Você pode criar mapas de serviço automaticamente observando os fluxos reais da rede, em vez de depender de uma configuração estática. Quando um serviço começa a se comunicar com uma nova dependência, as ferramentas baseadas em eBPF detectam isso imediatamente e atualizam a topologia do serviço em tempo real.
A análise de desempenho por meio do eBPF identifica gargalos no nível do contêiner. Em vez de ficar tentando adivinhar por que um pod está lento, você pode ver exatamente quais chamadas de sistema estão demorando, quais arquivos estão sendo acessados e como a latência da rede afeta o desempenho do aplicativo. Esses dados são coletados de forma contínua com um consumo mínimo de recursos, normalmente menos de 1% do uso da CPU.
O monitoramento de segurança aproveita a capacidade do eBPF de detectar padrões de comportamento anômalos. Em vez de analisar registros após um incidente, os programas eBPF podem detectar chamadas de sistema suspeitas, conexões de rede inesperadas ou padrões de acesso a arquivos assim que eles acontecem. Isso permite a detecção de ameaças em tempo real, levando em conta os limites dos contêineres e a identidade da carga de trabalho do Kubernetes.
A integração entre eBPF e tempos de execução de contêineres continua se aprofundando. O Cilium oferece uma rede baseada em eBPF para o Kubernetes que é mais rápida e mais fácil de ver do que os plug-ins CNI tradicionais. O Falco usa eBPF para monitoramento de segurança em tempo de execução que entende o contexto do contêiner de forma nativa.
Essa tendência em direção à observabilidade no nível do kernel representa uma mudança fundamental do monitoramento de caixa preta para a transparência total do sistema, tornando os ambientes de contêineres mais fáceis de depurar e seguros por padrão.
Escolher a alternativa certa ao Docker não é só achar um substituto único — é mais sobre combinar as ferramentas com casos de uso específicos nos seus ambientes de desenvolvimento e produção. O mundo da contêinerização amadureceu e virou um monte de soluções que são ótimas em diferentes situações.
Para a experiência do desenvolvedor, o Podman oferece o caminho de migração mais tranquilo com sua compatibilidade com a CLI do Docker, ao mesmo tempo em que oferece segurança superior por meio da operação sem root. Se você investiu pesadamente nos fluxos de trabalho do Docker Desktop, o Rancher Desktop com containerd oferece funcionalidades parecidas com uma eficiência melhor dos recursos. Equipes que criam pipelines complexos de CI/CD aproveitam a flexibilidade de script do Buildah ou a abordagem segura e sem daemon do Kaniko.
Em escala de produção, o, o containerd e o CRI-O oferecem melhor desempenho e eficiência de recursos do que o Docker Engine. O Containerd é ótimo pra ambientes corporativos que precisam de estabilidade e um monte de recursos, enquanto o CRI-O é a opção mais eficiente pra implantações focadas no Kubernetes. Para computação de ponta ou sistemas incorporados, tempos de execução leves como runC ou Youki oferecem a sobrecarga mínima necessária para ambientes com recursos limitados.
Organizações preocupadas com a segurança devem priorizar tempos de execução sem root, como Podman ou containerd sem root. A combinação de isolamento do namespace do usuário, monitoramento baseado em eBPF e redução da superfície de ataque oferece uma defesa profunda que as implantações tradicionais do Docker não conseguem igualar. Para setores regulamentados, certifique-se de que o tempo de execução escolhido seja compatível com a conformidade FIPS e se integre aos sistemas de registro de auditoria empresarial.
Uma abordagem híbrida costuma funcionar melhor na prática. Use o Podman para desenvolvimento local e aproveite a segurança sem root e a compatibilidade com o Docker. Implemente cargas de trabalho de produção no containerd ou CRI-O para integração e desempenho ideais do Kubernetes. Mantenha ferramentas especializadas como o Buildah para pipelines de CI/CD, onde segurança e flexibilidade são mais importantes do que compatibilidade.
Procurando ideias para projetos com Docker e conteinerização? Esses 10 vão te ajudar a começar.
Olhando para o futuro, WebAssembly e eBPF são a próxima evolução na containerização. Os tempos de inicialização rápidos e as fortes garantias de segurança do WebAssembly provavelmente vão dominar as cargas de trabalho de computação sem servidor e de borda. A observabilidade no nível do kernel do eBPF já está mudando a forma como monitoramos e protegemos aplicativos em contêineres. Essas tecnologias não vão substituir totalmente os contêineres tradicionais, mas vão criar novas categorias de cargas de trabalho onde as limitações atuais dos contêineres não se aplicam.
O segredo é manter a flexibilidade à medida que essas tecnologias amadurecem e entender que a melhor estratégia de conteinerização combina várias ferramentas, em vez de depender de uma única solução.
Se você quer saber mais sobre Docker, conteinerização, virtualização e Kubernetes, esses cursos são o próximo passo perfeito:
Aprenda mais sobre o Docker com esses cursos!
Programa
Curso
Curso
blog
Matt Crabtree
8 min
blog
Kurtis Pykes
13 min
blog
Javier Canales Luna
13 min
blog
Karlijn Willems
15 min
Tutorial
Bex Tuychiev

