
Track
Containerization and Virtualization with Docker and Kubernetes
13 hr
Podman represents the most direct challenge to Docker's architectural approach.
Image 1 - Podman home page
Red Hat developed it specifically to address Docker's daemon-based security model while maintaining compatibility with existing workflows.
>If you need a more in-depth comparison of Docker and Podman, our blog post will reveal which containerization platform is right for you.
Podman's biggest departure from Docker is eliminating the daemon entirely. Instead of routing commands through a central service, Podman uses a fork-exec model where each container runs as a direct child process of the user who started it. This means no persistent background service, no single point of failure, and no root-level daemon managing your containers.
This architecture integrates naturally with systemd, Linux's standard service manager. You can generate systemd unit files directly from Podman containers, which lets your containers start automatically on boot, restart on failure, and integrate with system logging. It's a much cleaner approach than Docker's separate orchestration layer.
Podman maintains full OCI compliance, so it runs the same container images as Docker without modification. The runtime uses the same underlying technologies - runc for container execution and various storage drivers for image management - but packages them differently.
Rootless operation is Podman's standout security feature. When you run containers with Podman, they execute under your user account rather than requiring root privileges. This happens through user namespace mapping, where the container's root user maps to your unprivileged user ID on the host system.
This eliminates the attack vector where a container breakout could compromise the entire host system. Even if an attacker escapes the container, they're still confined to your user's permissions rather than having root access to the machine.
On Red Hat Enterprise Linux and Fedora systems, Podman integrates tightly with SELinux (Security-Enhanced Linux). SELinux provides mandatory access controls that restrict what containers can access on the host system, even if they're compromised. This creates multiple layers of security - user namespaces prevent privilege escalation, while SELinux prevents unauthorized file system access.
Enterprise deployments often combine these features with additional security scanning and policy enforcement tools for defense-in-depth strategies.
Podman maintains Docker CLI compatibility through its podman command, which accepts the same arguments as docker. You can create an alias (alias docker=podman) and most existing scripts will work without modification. This makes migration from Docker much smoother than switching to completely different toolchains.
The Podman Desktop GUI provides a Docker Desktop alternative for developers who prefer graphical interfaces. It includes container management, image building capabilities, and Kubernetes integration for local development. The desktop application can connect to remote Podman instances and provides similar functionality to Docker Desktop's dashboard.
For Kubernetes workflows, Podman can generate Kubernetes YAML manifests from running containers and supports pod management - running multiple containers that share networking and storage, similar to Kubernetes pods.
Windows support remains Podman's biggest limitation. While Podman Machine provides Windows compatibility through virtualization, it's not as seamless as Docker Desktop's WSL2 integration. Windows developers might find the setup more complex.
Rootless networking has performance implications. Without root privileges, Podman can't create bridge networks directly, so it uses user-mode networking (slirp4netns), which adds latency. This is rarely noticeable for development workloads, but high-throughput network applications might see reduced performance.
Docker Compose compatibility exists through podman-compose, but it's not 100% feature-complete. Complex Compose files might require modifications, and some advanced networking features aren't supported in rootless mode. Teams heavily invested in Docker Compose workflows should test thoroughly before migrating.
>How does Docker Compose differ from Kubernetes? Our detailed comparison has you covered.
While Podman targets Docker compatibility, CRI-O and containerd focus specifically on Kubernetes production environments. These runtimes strip away unnecessary features to optimize for orchestrated workloads.
>Every developer should know these differences between Docker and Kubernetes.
CRI-O was built from the ground up to implement Kubernetes' Container Runtime Interface (CRI).

Image 2 - CRI-O home page
It includes only what Kubernetes needs - no image building, no volume management beyond what pods require, and no standalone container management. This focused approach results in lower memory overhead and faster startup times compared to Docker.
The runtime's resource efficiency comes from its minimal design. CRI-O doesn't maintain a daemon with extensive APIs or background services. It starts containers, manages their lifecycle according to Kubernetes' instructions, and gets out of the way. This makes it ideal for resource-constrained environments or large-scale deployments where every megabyte of memory matters.
CRI-O supports any OCI-compliant runtime as its low-level executor. While it defaults to runc, you can swap in alternatives like crun (written in C for better performance) or gVisor (for enhanced isolation) without changing your Kubernetes configuration. This flexibility lets you optimize for specific security or performance requirements at the runtime level.
The project maintains strict compatibility with Kubernetes release cycles, ensuring new features and security updates align with your cluster versions.
Containerd started as Docker's underlying runtime before becoming a standalone project under the Cloud Native Computing Foundation.

Image 3 - Containerd home page
Docker still uses containerd internally, but you can run it directly to eliminate Docker's additional layers and overhead.
The architecture centers around a shim API that provides stable interfaces for container management. Each container gets its own shim process, which handles the container's lifecycle independently. If the main containerd daemon restarts, running containers continue without interruption - a critical feature for production workloads that can't tolerate downtime.
This design makes containerd extremely stable for long-running enterprise applications. The shim architecture also enables features like live migration and zero-downtime updates, where you can upgrade the runtime without affecting running containers.
Containerd includes built-in image management, snapshots for efficient layer storage, and plugin systems for extending functionality. Major cloud providers like AWS EKS, Google GKE, and Azure AKS use containerd as their default runtime because of this production-hardened architecture.
Here's how these runtimes compare for production Kubernetes deployments:
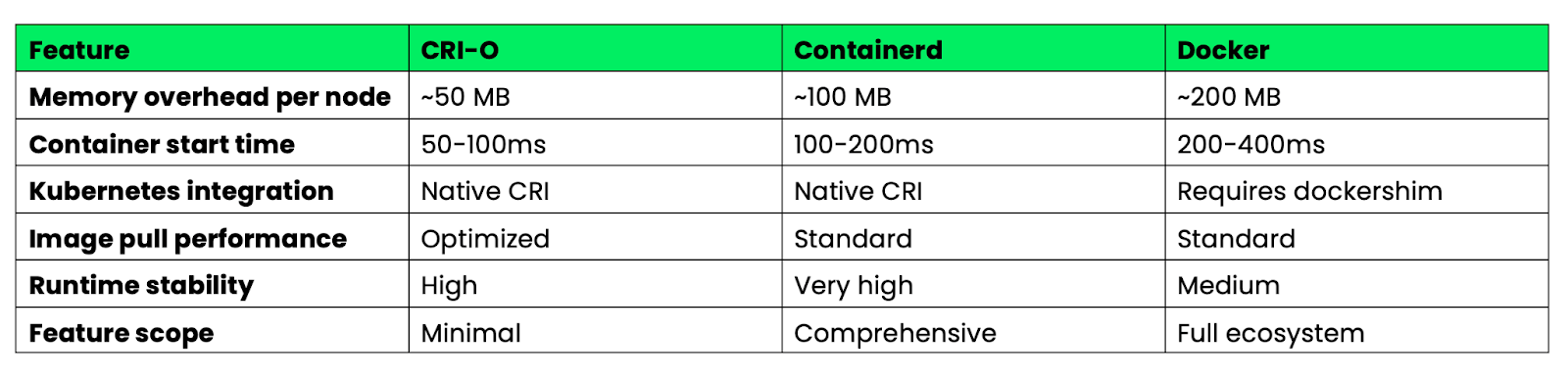
Image 4 - Docker vs CRI-O vs Containerd performance characteristics
CRI-O wins on resource efficiency and startup speed due to its minimal design. Containerd offers the best balance of features and stability for enterprise environments. Docker provides the most features, but with higher overhead that's unnecessary in Kubernetes environments.
For production Kubernetes clusters, both CRI-O and containerd eliminate the dockershim compatibility layer, reducing complexity and improving performance compared to Docker-based setups.
While high-level runtimes like Podman and containerd handle image management and APIs, low-level runtimes focus purely on container execution. These tools represent the foundation that powers most containerization platforms.
runC serves as the reference implementation of the OCI Runtime Specification - it's the canonical example of how containers should actually run. Most container platforms use runC as their execution engine, including Docker, containerd, CRI-O, and Podman. When you start a container with any of these tools, runC is likely handling the actual process creation and isolation.
The runtime implements core container primitives: creating Linux namespaces for isolation, setting up cgroups for resource limits, and configuring security contexts. It's written in Go and designed to be simple, reliable, and spec-compliant rather than feature-rich.
runC excels in embedded systems and custom container stacks where you need predictable behavior and minimal dependencies. Since it only handles container execution, you can build specialized container platforms around it without inheriting unnecessary complexity. IoT devices, edge computing platforms, and custom orchestration systems often use runC directly rather than higher-level runtimes.
The tool operates as a command-line utility that reads OCI bundle specifications and creates containers accordingly. This makes it perfect for integrating into existing systems or building custom container management tools.
Youki reimplements the OCI Runtime Specification in Rust, focusing on memory safety and performance. The Rust implementation eliminates entire classes of security vulnerabilities that can affect C and Go runtimes, while also improving container startup times through better memory management and reduced overhead.
Benchmarks show Youki starting containers faster than runC in many cases, though the exact improvement varies by workload. This improvement comes from Rust's zero-cost abstractions and more efficient memory allocation patterns. For applications that create and destroy many short-lived containers, these startup time improvements can be significant.
Youki maintains full compatibility with the OCI Runtime Specification, so it works as a drop-in replacement for runC in most container platforms. Docker Engine, containerd, and other high-level runtimes can use Youki without modification to their configuration or APIs.
The runtime benefits performance-critical workloads like serverless functions, CI/CD pipelines with many container builds, and microservices architectures with frequent scaling events. The faster startup times directly translate to reduced cold start latency and improved resource utilization in these scenarios.
Youki also includes features like cgroup v2 optimization and improved rootless container support that take advantage of Rust's type system to prevent configuration errors at compile time.
Not all containerization needs to focus on single applications - sometimes you need to run entire operating systems in containers. LXC and LXD provide system-level containerization that's fundamentally different from Docker's application-focused approach.
LXC (Linux Containers) creates containers that behave like complete Linux systems rather than isolated application processes.
Image 5 - LXC home page
Each LXC container runs its own init system, can host multiple services, and provides a full userspace environment that's nearly indistinguishable from a virtual machine.
This approach excels for legacy workloads that weren't designed for containerization. Applications that expect to write to /etc, run system services, or interact with the full filesystem hierarchy work seamlessly in LXC containers. You can lift-and-shift entire server configurations into LXC without refactoring applications for microservices architectures.
LXC containers share the host kernel but maintain stronger isolation than application containers. Each container gets its own network stack, process tree, and filesystem namespace, creating VM-like isolation without the overhead of hardware virtualization.
LXD, now under Canonical, adds a powerful management layer on top of LXC. LXD provides REST APIs, image management, and advanced features like live migration between hosts. You can move running containers across physical machines without downtime, similar to VMware vMotion but with containers.
Hardware passthrough capabilities allow LXD containers to access GPUs, USB devices, and other hardware directly. This makes it suitable for workloads that need specialized hardware access while maintaining container benefits like density and rapid provisioning.
LXD also supports clustering, allowing you to manage multiple hosts as a single logical unit with automated placement and failover capabilities.
Here's how system containers compare to application containers across key characteristics:
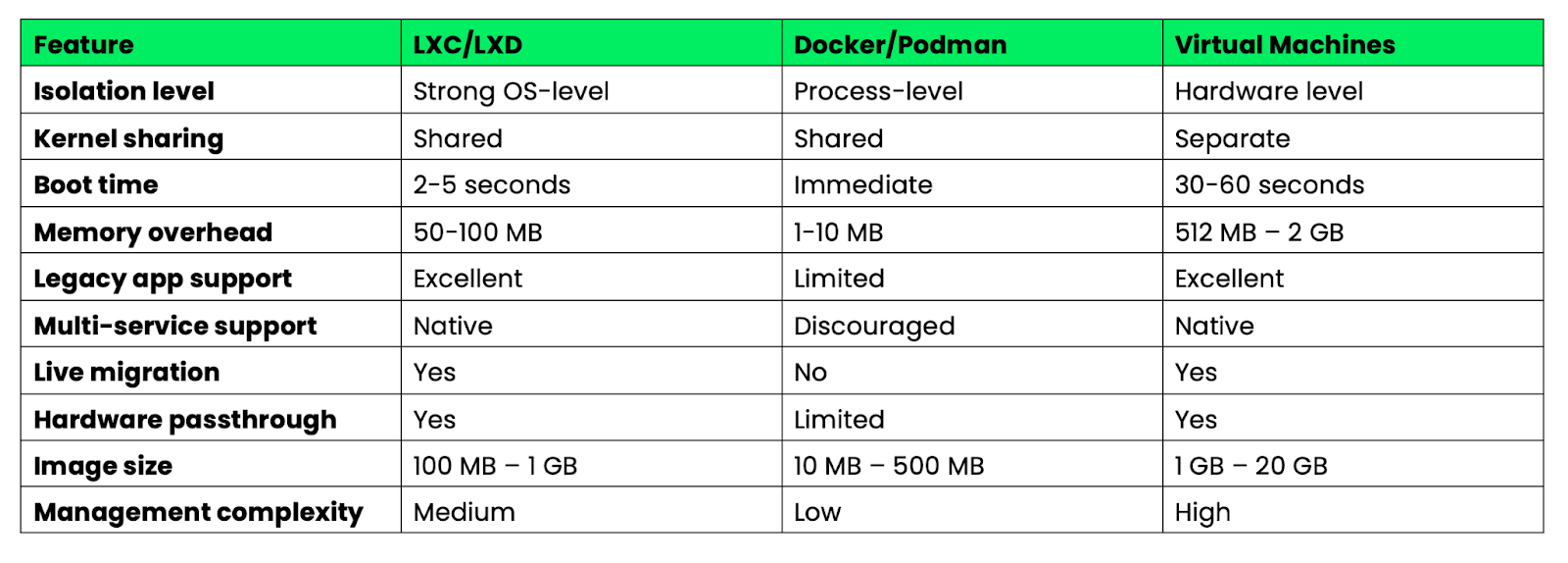
Image 6 - Docker vs LXC vs Virtual machines key characteristics overview
System containers fill the gap between lightweight application containers and heavy virtual machines. They're ideal when you need VM-like capabilities with container efficiency, or when migrating legacy applications that can't be easily decomposed into microservices.
The choice between system and application containers depends on your workload characteristics and operational requirements rather than technical superiority - they solve different problems in the containerization spectrum.
Security has evolved from an afterthought to a core design principle in modern container runtimes. Today's platforms implement defense-in-depth strategies that assume containers will be compromised and focus on limiting blast radius.
Rootless containers eliminate the biggest security risk in traditional Docker deployments - the root daemon. Podman pioneered this approach by running containers entirely under user privileges, using Linux user namespaces to map the container's root user to an unprivileged user ID on the host system.
The implementation relies on subordinate user and group ID ranges (/etc/subuid and /etc/subgid) that allow unprivileged users to create isolated namespaces. When a container process thinks it's running as root (UID 0), the kernel maps that to your actual user ID (say, UID 1000) on the host. Even if an attacker escapes the container, they can't escalate beyond your user's permissions.
Containerd has implemented similar rootless capabilities through its rootless mode, which uses the same user namespace mapping techniques. The runtime can start containers, manage images, and handle networking without requiring root privileges on the host system.
Kubernetes now supports rootless operation natively through the Kubernetes-in-Rootless-Docker (KIND) project and rootless containerd integration. This means entire Kubernetes clusters can run without root privileges, dramatically reducing the attack surface for multi-tenant environments and edge deployments where traditional security models don't apply.
The security impact extends beyond privilege escalation prevention. Rootless containers can't bind to privileged ports (below 1024), can't access most /proc and /sys filesystems, and can't perform operations that require kernel capabilities. This creates natural boundaries that contain potential security breaches.
Modern runtimes integrate eBPF (extended Berkeley Packet Filter) for real-time security policy enforcement that goes beyond traditional access controls. eBPF programs run in kernel space and can monitor, filter, or modify system calls as they happen, providing unprecedented visibility and control over container behavior.
Seccomp (Secure Computing) profiles use BPF to filter system calls at the kernel level. Instead of allowing containers access to all 300+ Linux system calls, seccomp profiles define exactly which calls are permitted. Docker's default seccomp profile blocks potentially dangerous system calls, while custom profiles can be even more restrictive based on application requirements.
Advanced eBPF integration enables real-time behavioral monitoring. Tools like Falco use eBPF programs to detect anomalous container behavior - unusual network connections, unexpected file access patterns, or attempts to use blocked system calls. These detections happen in real-time with minimal performance overhead since the monitoring occurs in kernel space.
Network policy enforcement through eBPF provides granular traffic control at the packet level. Cilium, a popular Kubernetes CNI, uses eBPF to implement network policies that can filter traffic based on application layer protocols, not just IP addresses and ports. This means you can create policies like "allow HTTP GET requests to /api/v1/users but block POST requests" directly in the kernel.
eBPF-based security also enables container-aware monitoring that understands the relationship between processes, containers, and Kubernetes pods. Traditional monitoring tools see individual processes, but eBPF programs can correlate system calls with container metadata to provide context-aware security insights.
These capabilities transform security from reactive patching to proactive policy enforcement, where suspicious behavior gets blocked automatically before it can cause damage.
Container performance matters most when you're running hundreds or thousands of containers across your infrastructure. Let's explore strategies that minimize resource overhead and startup latency.
Cold start time - the delay between requesting a container and having it ready to serve traffic - directly impacts user experience and resource efficiency. Techniques have emerged to minimize these delays across different runtime architectures.
Pre-pulled images eliminate download time by keeping frequently used container images cached on nodes. Kubernetes DaemonSets can pre-pull critical images, while registries like Harbor support image replication to edge locations. This technique can reduce cold starts from seconds to milliseconds for cached images.
Image layer optimization reduces the amount of data that needs to be transferred and extracted. Multi-stage builds create smaller final images, while tools like dive help identify unnecessary layers. Distroless images from Google eliminate package managers and shells, often reducing image sizes significantly.
Lazy loading with projects like Stargz allows containers to start before the entire image downloads. The runtime fetches only the files needed for initial startup, downloading additional layers on demand. This can reduce cold start times from multiple seconds to under 1 second for large images.
Runtime optimization varies by implementation. Youki's Rust implementation shows improved startup performance compared to runC through better memory management. Crun, written in C, achieves similar improvements by eliminating Go's garbage collection overhead during container creation.
Snapshot sharing in containerd allows multiple containers to share read-only filesystem snapshots, reducing both storage and memory overhead. When starting multiple containers from the same image, only the writable layers need separate allocation.
Init process optimization can reduce startup time by using lightweight init systems like tini or by carefully designing application startup sequences to minimize initialization work.
Memory overhead varies across container runtimes, with the differences becoming critical in resource-constrained environments or high-density deployments.
Runtime baseline overhead differs substantially:
Image layer deduplication saves memory when running multiple containers from related images. Container runtimes use copy-on-write filesystems where shared layers consume memory only once across all containers. A cluster running many containers from similar base images can achieve significant memory savings through deduplication.
Memory mapping optimization in modern runtimes reduces resident memory usage. Tools like crun map executable files directly from storage rather than loading them into memory, reducing the memory footprint for containers with large binaries.
Cgroup memory accounting provides precise control over container memory limits, but different runtimes handle memory pressure differently. Some runtimes implement better memory reclamation under pressure, while others provide more accurate memory usage reporting for autoscaling decisions.
Rootless memory overhead trades some efficiency for security. Rootless containers require additional processes for user namespace management and networking, typically adding overhead compared to rootful operation.
The choice between runtimes often comes down to balancing memory efficiency against feature requirements. CRI-O provides low overhead for Kubernetes workloads, while Podman sacrifices some efficiency for security and compatibility benefits.
The best container runtime is worthless if it doesn't fit your development workflow. Docker alternatives have implemented tooling that often surpasses Docker's developer experience in specific scenarios.
Local Kubernetes development has moved beyond minikube's virtual machine approach to more efficient solutions that integrate directly with container runtimes. The choice of local environment significantly impacts development velocity and resource consumption.
Kind (Kubernetes in Docker) creates Kubernetes clusters using container nodes instead of virtual machines. Setup time is typically 1-2 minutes with moderate memory overhead per node. Kind works with any Docker-compatible runtime, so you can use it with Podman (kind create cluster --runtime podman) for rootless Kubernetes development.
K3s provides a lightweight option, running a complete Kubernetes distribution with minimal memory usage. It starts quickly and includes built-in storage, networking, and ingress controllers. K3s works well with containerd and can run on resource-constrained development machines.
MicroK8s from Canonical offers a middle ground with moderate memory usage and modular add-ons. It integrates well with containerd and provides production-like features without virtual machine overhead. Startup time is reasonable for a full cluster.
Rancher Desktop combines K3s with containerd or Dockerd backends, providing a Docker Desktop alternative that uses fewer resources. It includes built-in image scanning and Kubernetes dashboard integration.
Podman pods offer a unique alternative - you can develop multi-container applications using Podman's pod concept, which mirrors Kubernetes pod behavior. Generate Kubernetes YAML directly from running pods using podman generate kube, creating a seamless path from local development to cluster deployment.
Traditional Docker-based CI/CD pipelines face limitations in containerized environments where running Docker-in-Docker creates security and performance challenges. Modern alternatives provide better solutions for building and pushing container images in CI systems.
Buildah excels in CI environments because it doesn't require a daemon or root privileges. You can build OCI-compliant images using shell scripts that are more auditable than Dockerfiles. Buildah's scripting approach allows dynamic image construction based on CI variables, making it ideal for complex build processes that need conditional logic.

Image 7 - Buildah home page
For comparison, traditional Dockerfiles use declarative instructions:
FROM alpine:latest
RUN apk add --no-cache nodejs npm
COPY package.json /app/
WORKDIR /appBuildah uses imperative shell commands that can include variables and conditional logic:
# Buildah scripting approach with CI integration
buildah from alpine:latest
buildah run $container apk add --no-cache nodejs npm
buildah copy $container package.json /app/
buildah config --workingdir /app $container
buildah commit $container myapp:${CI_COMMIT_SHA}This scripting flexibility lets you dynamically choose base images, conditionally install packages based on branch names, or modify build steps based on CI environment variables - capabilities that require complex workarounds in traditional Dockerfiles.
Kaniko solves the Docker-in-Docker problem by building images entirely in userspace within a container. It runs in Kubernetes pods without requiring privileged access or Docker daemon. Kaniko is effective in GitLab CI and Jenkins X pipelines where security policies prevent privileged containers.
The tool extracts base images, applies Dockerfile instructions in isolation, and pushes results directly to registries. Build times are comparable to Docker but with much better security posture in orchestrated environments.
Nerdctl provides Docker CLI compatibility for containerd, which makes it an excellent drop-in replacement for Docker in CI systems. It supports the same build, push, and pull commands as Docker but uses containerd as the backend. This eliminates the Docker daemon while maintaining familiar workflows.
Nerdctl includes advanced features like lazy pulling and encrypted images that can improve CI performance. For teams using containerd in production, nerdctl creates consistency between CI and runtime environments.
Performance comparison in CI pipelines:
The choice depends on your security requirements, existing infrastructure, and performance needs. Kaniko works best in security-focused Kubernetes environments, while Buildah excels when you need complex build logic that's hard to express in Dockerfiles.
Enterprise container deployments require more than just choosing the right runtime - you need platforms that handle compliance, governance, and multi-cluster operations at scale. The container alternatives you choose must integrate with enterprise management tools and meet regulatory requirements.
Managing containers across multiple clusters, clouds, and edge locations requires sophisticated orchestration platforms that go beyond basic Kubernetes. Enterprise solutions provide centralized management, policy enforcement, and operational consistency across diverse environments.
Red Hat OpenShift builds on Kubernetes with enterprise-focused container runtime choices. OpenShift defaults to CRI-O for better security and resource efficiency compared to Docker-based deployments. The platform includes built-in image scanning, policy enforcement, and developer workflows that work consistently whether you're running on AWS, Azure, or on-premises infrastructure.

Image 8 - Red Hat OpenShift home page
OpenShift's multi-cluster management handles runtime standardization across environments. You can enforce that all clusters use CRI-O with specific security policies, ensuring consistent behavior whether containers run in development, staging, or production environments.
Rancher provides a unified interface for managing Kubernetes clusters regardless of their underlying container runtime. Rancher supports clusters running Docker, containerd, or CRI-O, allowing you to migrate runtimes gradually without disrupting operations. The platform includes centralized monitoring, backup, and security scanning across all managed clusters.
Image 9 - Rancher home page
Rancher's approach is valuable when you have mixed environments - some clusters might use containerd for performance while others use CRI-O for security compliance. The management layer abstracts these differences while providing consistent operational tools.
Mirantis Kubernetes Engine focuses on enterprise Docker environments but supports migration to containerd-based deployments. The platform provides enterprise support, security hardening, and compliance tooling that works across different container runtimes.
Image 10 - Mirantis home page
These platforms solve the operational complexity of running different container runtimes across your infrastructure while maintaining centralized governance and security policies.
Enterprise environments often require compliance with regulations like FIPS 140-2, SOC 2, or GDPR, which directly impact container runtime selection and configuration. Compliance isn't just about the runtime itself - it extends to image registries, security scanning, and audit logging.
FIPS (Federal Information Processing Standards) validation requires cryptographic modules that meet government security standards. Not all container runtimes support FIPS-validated crypto libraries. Red Hat Enterprise Linux provides FIPS-compliant versions of CRI-O and Podman, while standard Docker installations often require additional configuration to achieve FIPS compliance.
FIPS compliance affects image signing, TLS communications, and encrypted storage. Container platforms must use FIPS-validated cryptographic libraries for all security operations, from pulling images to establishing network connections between containers.
GDPR compliance impacts how container platforms handle personal data in logs, metrics, and image metadata. Enterprise container registries like Harbor, Quay, and AWS ECR provide features like data residency controls, audit logging, and automated data retention policies.
Container runtimes must support compliance features like:
SOC 2 compliance requires demonstrable security controls around access management, system monitoring, and data protection. Container platforms must integrate with enterprise identity providers, provide detailed audit trails, and support automated security policy enforcement.
Modern container runtimes like CRI-O and containerd provide better compliance foundation than Docker because they offer more granular security controls, better audit logging, and cleaner separation between runtime components and management interfaces.
Compliance also extends to supply chain security - ensuring container images come from trusted sources and haven't been tampered with. Tools like Sigstore and in-toto provide cryptographic verification of container image provenance, while admission controllers can enforce that only signed, scanned images run in production clusters.
The containerization landscape continues evolving beyond traditional Linux containers toward new execution models and observability paradigms. These emerging technologies promise to address fundamental limitations in current container architectures.
WebAssembly (WASM) is emerging as a compelling alternative to traditional OCI containers for specific workloads. Unlike containers that package an entire operating system userspace, WebAssembly provides a lightweight, sandboxed execution environment that runs at near-native speeds across different architectures.
WASM modules start much faster than traditional containers, making them ideal for serverless functions and edge computing, where cold start time directly impacts user experience. A WebAssembly module can handle significantly more requests than a container with slower initialization times.
The security model differs fundamentally from containers. WebAssembly provides capability-based security where modules can only access explicitly granted resources. There's no shared kernel surface area like in traditional containers - WASM modules run in a sandboxed environment that prevents many classes of security vulnerabilities.
Container runtimes are beginning to support WebAssembly workloads directly. Wasmtime integrates with containerd as a runtime shim, allowing you to deploy WASM modules using standard Kubernetes YAML. This means you can mix traditional containers and WebAssembly workloads in the same cluster based on performance and security requirements.
The tradeoff is ecosystem maturity. WebAssembly has limited language support compared to containers - Rust, C/C++, and AssemblyScript work well, while languages like Python and Java require additional runtime layers that reduce the performance benefits.
WASM excels for computational workloads, serverless functions, and edge computing, but isn't ready to replace containers for complex applications that need extensive operating system integration.
eBPF (extended Berkeley Packet Filter) is transforming container observability by providing kernel-level insights without requiring application modifications or sidecar containers. Unlike traditional monitoring that relies on metrics exported by applications, eBPF programs observe system calls, network traffic, and kernel events in real-time.
Container-aware monitoring through eBPF correlates low-level system events with higher-level container and Kubernetes metadata. Tools like Pixie and Cilium Hubble can show you exactly which HTTP requests flow between specific pods, including request latency, payload inspection, and error rates, all without modifying your applications.
This approach provides unprecedented visibility into microservice communication patterns. You can generate service maps automatically by observing actual network flows rather than relying on static configuration. When a service starts communicating with a new dependency, the eBPF-based tools detect it immediately and update the service topology in real-time.
Performance profiling through eBPF identifies bottlenecks at the container level. Instead of guessing why a pod is slow, you can see exactly which system calls are taking time, which files are being accessed, and how network latency affects application performance. This data is collected continuously with minimal overhead, typically less than 1% CPU usage.
Security monitoring benefits from eBPF's ability to detect anomalous behavior patterns. Instead of analyzing logs after an incident, eBPF programs can detect suspicious system calls, unexpected network connections, or file access patterns as they happen. This enables real-time threat detection that's contextually aware of container boundaries and Kubernetes workload identity.
The integration between eBPF and container runtimes continues deepening. Cilium provides eBPF-based networking for Kubernetes that's both faster and more observable than traditional CNI plugins. Falco uses eBPF for runtime security monitoring that understands container context natively.
This trend toward kernel-level observability represents a fundamental shift from black-box monitoring to complete system transparency, making container environments more debuggable and secure by default.
Choosing the right Docker alternative isn't about finding a single replacement - it's about matching tools to specific use cases across your development and production environments. The containerization ecosystem has matured into a collection of solutions that excel in different scenarios.
For developer experience, Podman offers the smoothest migration path with its Docker CLI compatibility while providing superior security through rootless operation. If you're heavily invested in Docker Desktop workflows, Rancher Desktop with containerd provides similar functionality with better resource efficiency. Teams building complex CI/CD pipelines benefit from Buildah's scripting flexibility or Kaniko's secure, daemon-free approach.
At production scale, containerd and CRI-O deliver better performance and resource efficiency than Docker Engine. Containerd excels in enterprise environments that need stability and extensive feature sets, while CRI-O provides the most efficient option for Kubernetes-focused deployments. For edge computing or embedded systems, lightweight runtimes like runC or Youki offer the minimal overhead required for resource-constrained environments.
Security-conscious organizations should prioritize rootless runtimes like Podman or rootless containerd. The combination of user namespace isolation, eBPF-based monitoring, and reduced attack surface provides defense-in-depth that traditional Docker deployments can't match. For regulated industries, ensure your chosen runtime supports FIPS compliance and integrates with enterprise audit logging systems.
A hybrid approach often works best in practice. Use Podman for local development to benefit from rootless security and Docker compatibility. Deploy production workloads on containerd or CRI-O for optimal Kubernetes integration and performance. Keep specialized tools like Buildah for CI/CD pipelines where security and flexibility matter more than compatibility.
>Looking for Docker and containerization project ideas? These 10 will get you started.
Looking ahead, WebAssembly and eBPF represent the next evolution in containerization. WebAssembly's fast startup times and strong security guarantees will likely dominate serverless and edge computing workloads. eBPF's kernel-level observability is already transforming how we monitor and secure containerized applications. These technologies won't replace traditional containers entirely, but they'll create new categories of workloads where current container limitations don't apply.
The key is staying flexible as these technologies mature and understanding that the best containerization strategy combines multiple tools rather than depending on any single solution.
If you're looking to learn more about Docker, containerization, virtualization, and Kubernetes, these courses are a perfect next step:
Learn more about Docker with these courses!
Track
Course
Course
blog
Jake Roach
9 min
blog
Moez Ali
15 min
blog
Derrick Mwiti
9 min
blog
Laiba Siddiqui
15 min
blog
Aashish Nair
10 min
Tutorial
Moez Ali
