
Cursus
Conteneurisation et virtualisation avec Docker et Kubernetes
13 h
Podmanreprésente le défi le plus direct à l'approche architecturale de Docker.
Image 1 - Page d'accueil de Podman
Red Hat l'a développé spécifiquement pour répondre au modèle de sécurité basé sur les démons de Docker tout en conservant la compatibilité avec les flux de travail existants.
Si vous souhaitez une comparaison plus approfondie entre Docker et Podman, notre article de blog vous aidera à déterminer quelle plateforme de conteneurisation est la mieux adaptée à vos besoins.
La principale différence entre Podman et Docker réside dans la suppression totale de l' du démon. Au lieu d'acheminer les commandes via un service central, Podman utilise un modèle fork-exec dans lequel chaque conteneur s'exécute en tant que processus enfant direct de l'utilisateur qui l'a lancé. Cela signifie qu'il n'y a pas de service d'arrière-plan persistant, pas de point de défaillance unique et pas de démon au niveau racine gérant vos conteneurs.
Cette architecture s'intègre naturellement à systemd, le gestionnaire de services standard de Linux. Vous pouvez générer des fichiers d'unité systemd directement à partir des conteneurs Podman, ce qui permet à vos conteneurs de démarrer automatiquement au démarrage, de redémarrer en cas de défaillance et de s'intégrer à la journalisation du système. Il s'agit d'une approche beaucoup plus claire que la couche d'orchestration distincte de Docker.
Podman est entièrement conforme à l'OCI, ce qui lui permet d'exécuter les mêmes images de conteneurs que Docker sans modification. Le runtime utilise les mêmes technologies sous-jacentes ( runc ) pour l'exécution des conteneurs et divers pilotes de stockage pour la gestion des images), mais les regroupe différemment.
Le fonctionnement sans droits root est la fonctionnalité de sécurité distinctive de Podman. Lorsque vous exécutez des conteneurs avec Podman, , ceux-ci s'exécutent sous votre compte utilisateur plutôt que de nécessiter des privilèges root. Cela se fait par le biais du mappage de l'espace de noms utilisateur, où l'utilisateur root du conteneur est mappé à votre ID utilisateur non privilégié sur le système hôte.
Cela élimine le vecteur d'attaque où une intrusion dans un conteneur pourrait compromettre l'ensemble du système hôte. Même si un attaquant parvient à s'échapper du conteneur, il reste limité aux autorisations de votre utilisateur et ne dispose pas d'un accès root à la machine.
Sur les systèmes Red Hat Enterprise Linux et Fedora, Podman s'intègre étroitement à SELinux (Security-Enhanced Linux). SELinux fournit des contrôles d'accès obligatoires qui limitent ce à quoi les conteneurs peuvent accéder sur le système hôte, même s'ils sont compromis. Cela crée plusieurs niveaux de sécurité : les espaces de noms utilisateur empêchent l'escalade des privilèges, tandis que SELinux empêche tout accès non autorisé au système de fichiers.
Les déploiements en entreprise associent souvent ces fonctionnalités à des outils supplémentaires d'analyse de sécurité et d'application des politiques pour mettre en place des stratégies de défense en profondeur.
Podman maintient la compatibilité avec l'interface CLI de Docker grâce à sa commande ` podman `, qui accepte les mêmes arguments que ` docker`. Vous pouvez créer un alias (alias docker=podman) et la plupart des scripts existants fonctionneront sans modification. Cela rend la migration depuis Docker beaucoup plus fluide que le passage à des chaînes d'outils complètement différentes.
L'interface graphique Podman Desktop ( ) offre une alternative à Docker Desktop pour les développeurs qui préfèrent les interfaces graphiques. Il comprend la gestion des conteneurs, des fonctionnalités de création d'images et l'intégration de Kubernetes pour le développement local. L'application de bureau peut se connecter à des instances Podman distantes et offre des fonctionnalités similaires à celles du tableau de bord de Docker Desktop.
Pour les workflows Kubernetes, Podman peut générer des manifestes YAML Kubernetes à partir de conteneurs en cours d'exécution et prend en charge la gestion des pods, c'est-à-dire l'exécution de plusieurs conteneurs qui partagent le réseau et le stockage, de manière similaire aux pods Kubernetes.
La prise en charge de Windows reste la principale limitation de Podman.. Bien que Podman Machine assure la compatibilité avec Windows grâce à la virtualisation, cette solution n'est pas aussi transparente que l'intégration WSL2 de Docker Desktop. Les développeurs Windows pourraient trouver la configuration plus complexe.
Le réseautage sans racine a des implications sur les performances. Sans privilèges root, Podman ne peut pas créer directement de réseaux ponts. Il utilise donc le mode réseau utilisateur (slirp4netns), ce qui ajoute une latence. Ceci est rarement perceptible pour les charges de travail de développement, mais les applications réseau à haut débit peuvent connaître une baisse de performances.
La compatibilité avec Docker Compose est assurée par podman-compose, mais toutes les fonctionnalités ne sont pas encore disponibles à 100 %.. Les fichiers Compose complexes peuvent nécessiter des modifications, et certaines fonctionnalités réseau avancées ne sont pas prises en charge en mode rootless. Les équipes qui ont investi de manière significative dans les workflows Docker Compose sont invitées à effectuer des tests approfondis avant la migration.
En quoi Docker Compose diffère-t-il de Kubernetes? Notre comparaison détaillée vous fournit toutes les informations nécessaires.
Alors que Podman vise la compatibilité avec Docker, CRI-O et containerd se concentrent spécifiquement sur les environnements de production Kubernetes. Ces environnements d'exécution suppriment les fonctionnalités superflues afin d'optimiser les charges de travail orchestrées.
Chaque développeur devrait être conscient des différences entre Docker et Kubernetes.
CRI-O a été entièrement conçu pour implémenter l'interface d'exécution de conteneurs (CRI) de Kubernetes.

Image 2 - Page d'accueil du CRI-O
Il ne comprend que ce dont Kubernetes a besoin : pas de création d'images, pas de gestion des volumes au-delà des besoins des pods et pas de gestion autonome des conteneurs. Cette approche ciblée permet de réduire la charge mémoire et d'accélérer les temps de démarrage par rapport à Docker.
L'efficacité énergétique du runtime découle de sa conception minimaliste. CRI-O ne gère pas de démon avec des API étendues ou des services en arrière-plan. Il démarre les conteneurs, gère leur cycle de vie conformément aux instructions de Kubernetes, puis se retire. Cela le rend idéal pour les environnements aux ressources limitées ou les déploiements à grande échelle où chaque mégaoctet de mémoire est important.
CRI-O prend en charge tout environnement d'exécution compatible OCI en tant qu'exécuteur de bas niveau. Bien que la valeur par défaut soit runc, il est possible de remplacer cette option par d'autres alternatives telles que crun (écrit en C pour de meilleures performances) ou gVisor (pour une isolation améliorée) sans modifier la configuration Kubernetes. Cette flexibilité vous permet d'optimiser les exigences spécifiques en matière de sécurité ou de performances au niveau de l'exécution.
Le projet maintient une compatibilité stricte avec les cycles de publication de Kubernetes, garantissant ainsi que les nouvelles fonctionnalités et les mises à jour de sécurité sont alignées sur les versions de votre cluster.
Containerd a débuté en tant que runtime sous-jacent de Docker avant de devenir un projet autonome sous l'égide de la Cloud Native Computing Foundation.

Image 3 - Page d'accueil de Containerd
Docker utilise toujours containerd en interne, mais il est possible de l'exécuter directement afin d'éliminer les couches supplémentaires et la surcharge de Docker.
L'architecture s'articule autour d'une API Shim qui fournit des interfaces stables pour la gestion des conteneurs. Chaque conteneur dispose de son propre processus de calage, qui gère indépendamment le cycle de vie du conteneur. Si le démon containerd principal redémarre, les conteneurs en cours d'exécution continuent sans interruption, ce qui est essentiel pour les charges de travail de production qui ne peuvent tolérer aucun temps d'arrêt.
Cette conception rend containerd extrêmement stable pour les applications d'entreprise à exécution longue. L'architecture Shim permet également des fonctionnalités telles que la migration en direct et les mises à jour sans interruption de service, grâce auxquelles vous pouvez mettre à niveau le runtime sans affecter les conteneurs en cours d'exécution.
Containerd intègre une gestion des images, des instantanés pour un stockage efficace des couches et des systèmes de plugins pour étendre ses fonctionnalités. Les principaux fournisseurs de services cloud tels qu'AWS EKS, Google GKE et Azure AKS utilisent containerd comme environnement d'exécution par défaut en raison de cette architecture éprouvée en production.
Voici une comparaison des durées d'exécution pour les déploiements Kubernetes en production :
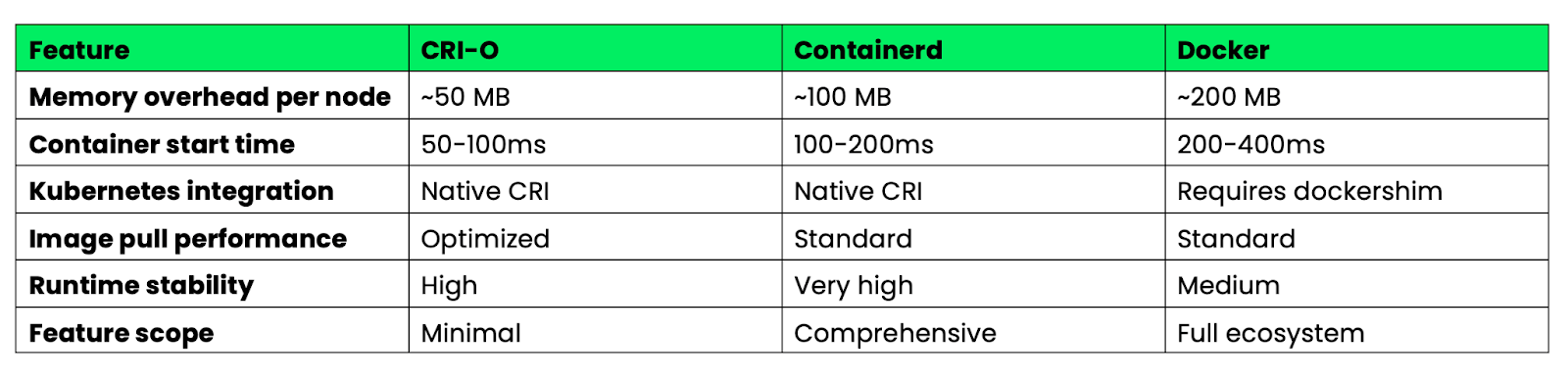
Image 4 - Caractéristiques de performance de Docker, CRI-O et Containerd
CRI-O se distingue par son efficacité en matière de ressources et sa rapidité de démarrage grâce à sa conception minimaliste. Containerd offre le meilleur équilibre entre fonctionnalités et stabilité pour les environnements d'entreprise. Docker offre le plus grand nombre de fonctionnalités, mais avec une charge supplémentaire plus importante qui n'est pas nécessaire dans les environnements Kubernetes.
Pour les clusters Kubernetes de production, CRI-O et containerd suppriment la couche de compatibilité dockershim, ce qui réduit la complexité et améliore les performances par rapport aux configurations basées sur Docker.
Alors que les environnements d'exécution de haut niveau tels que Podman et containerd gèrent la gestion des images et les API, les environnements d'exécution de bas niveau se concentrent exclusivement sur l'exécution des conteneurs. Ces outils constituent la base qui alimente la plupart des plateformes de conteneurisation.
runC sert d'implémentation de référence de l' pour la spécification OCI Runtime. Il s'agit d'un exemple standard illustrant la manière dont les conteneurs devraient fonctionner. La plupart des plateformes de conteneurs utilisent runC comme moteur d'exécution, notamment Docker, containerd, CRI-O et Podman. Lorsque vous démarrez un conteneur à l'aide de l'un de ces outils, runC est susceptible de gérer la création et l'isolation réelles du processus.
Le runtime implémente les primitives de conteneur de base : création d'espaces de noms Linux pour l'isolation, configuration de cgroups pour les limites de ressources et configuration des contextes de sécurité. Il est écrit en Go et conçu pour être simple, fiable et conforme aux spécifications plutôt que riche en fonctionnalités.
runC est particulièrement performant dans les systèmes embarqués et les piles de conteneurs personnalisées où un comportement prévisible et des dépendances minimales sont requis. Comme il ne gère que l'exécution des conteneurs, il est possible de créer des plateformes de conteneurs spécialisées autour de lui sans hériter d'une complexité inutile. Les appareils IoT, les plateformes informatiques de pointe et les systèmes d'orchestration personnalisés utilisent souvent runC directement plutôt que des environnements d'exécution de niveau supérieur.
Cet outil fonctionne comme un utilitaire en ligne de commande qui lit les spécifications des paquets OCI et crée des conteneurs en conséquence. Cela le rend idéal pour l'intégration dans des systèmes existants ou pour la création d'outils personnalisés de gestion des conteneurs.
Youki réimplémentela spécification OCI Runtime dans Rust, en mettant l'accent sur la sécurité de la mémoire et les performances. L'implémentation Rust élimine des catégories entières de vulnérabilités de sécurité pouvant affecter les environnements d'exécution C et Go, tout en améliorant les temps de démarrage des conteneurs grâce à une meilleure gestion de la mémoire et à une réduction de la surcharge.
Les tests de performance indiquent que Youki démarre les conteneurs plus rapidement que runC dans de nombreux cas, bien que l'amélioration exacte varie en fonction de la charge de travail. Cette amélioration est due aux abstractions sans coût et aux modèles d'allocation de mémoire plus efficaces de Rust. Pour les applications qui créent et détruisent de nombreux conteneurs à courte durée de vie, ces améliorations du temps de démarrage peuvent être significatives.
Youki est entièrement compatible avec la spécification OCI Runtime, ce qui lui permet de remplacer runC dans la plupart des plateformes de conteneurs. Docker Engine, containerd et d'autres environnements d'exécution de haut niveau peuvent utiliser Youki sans modification de leur configuration ou de leurs API.
Le runtime offre des avantages pour les charges de travail critiques en termes de performances, telles que les fonctions sans serveur, les pipelines CI/CD avec de nombreuses constructions de conteneurs et les architectures de microservices avec des événements de mise à l'échelle fréquents. Dans ces scénarios, des temps de démarrage plus rapides se traduisent directement par une réduction de la latence au démarrage à froid et une meilleure utilisation des ressources.
Youki inclut également des fonctionnalités telles que l'optimisation cgroup v2 et une prise en charge améliorée des conteneurs rootless qui exploitent le système de types de Rust pour éviter les erreurs de configuration lors de la compilation.
La conteneurisation ne doit pas nécessairement se concentrer sur des applications individuelles ; il est parfois nécessaire d'exécuter des systèmes d'exploitation complets dans des conteneurs. LXC et LXD offrent une conteneurisation au niveau du système qui diffère fondamentalement de l'approche axée sur les applications de Docker.
LXC (Linux Containers)crée des conteneurs qui se comportent comme des systèmes Linux complets plutôt que comme des processus d'application isolés.
Image 5 - Page d'accueil de LXC
Chaque conteneur LXC exécute son propre système d'initialisation, peut héberger plusieurs services et fournit un environnement utilisateur complet qui est pratiquement impossible à distinguer d'une machine virtuelle.
Cette approche est particulièrement efficace pour les charges de travail existantes qui n'ont pas été conçues pour la conteneurisation. Les applications qui prévoient d'écrire dans le répertoire d'accueil ( /etc), d'exécuter des services système ou d'interagir avec l'intégralité de la hiérarchie du système de fichiers fonctionnent de manière transparente dans les conteneurs LXC. Il est possible de transférer l'intégralité des configurations de serveurs vers LXC sans avoir à refactoriser les applications pour les architectures de microservices.
Les conteneurs LXC partagent le noyau hôte, mais offrent une isolation plus forte que les conteneurs d'applications. Chaque conteneur dispose de sa propre pile réseau, de son propre arbre de processus et de son propre espace de noms de système de fichiers, créant ainsi une isolation similaire à celle d'une machine virtuelle sans la surcharge liée à la virtualisation matérielle.
LXD, désormais disponible sursous Canonical, ajoute une couche de gestion puissante au-dessus de LXC. LXD fournit des API REST, la gestion des images et des fonctionnalités avancées telles que la migration en direct entre les hôtes. Vous pouvez déplacer des conteneurs en cours d'exécution d'une machine physique à une autre sans interruption de service, de manière similaire à VMware vMotion, mais avec des conteneurs.
Les capacités de transfert matériel permettent aux conteneurs LXD d'accéder directement aux GPU, aux périphériques USB et à d'autres matériels. Cela le rend adapté aux charges de travail qui nécessitent un accès matériel spécialisé tout en conservant les avantages des conteneurs, tels que la densité et le provisionnement rapide.
LXD prend également en charge la mise en cluster, ce qui vous permet de gérer plusieurs hôtes comme une seule unité logique avec des capacités de placement et de basculement automatisés.
Voici une comparaison entre les conteneurs système et les conteneurs d'application en fonction de leurs principales caractéristiques :
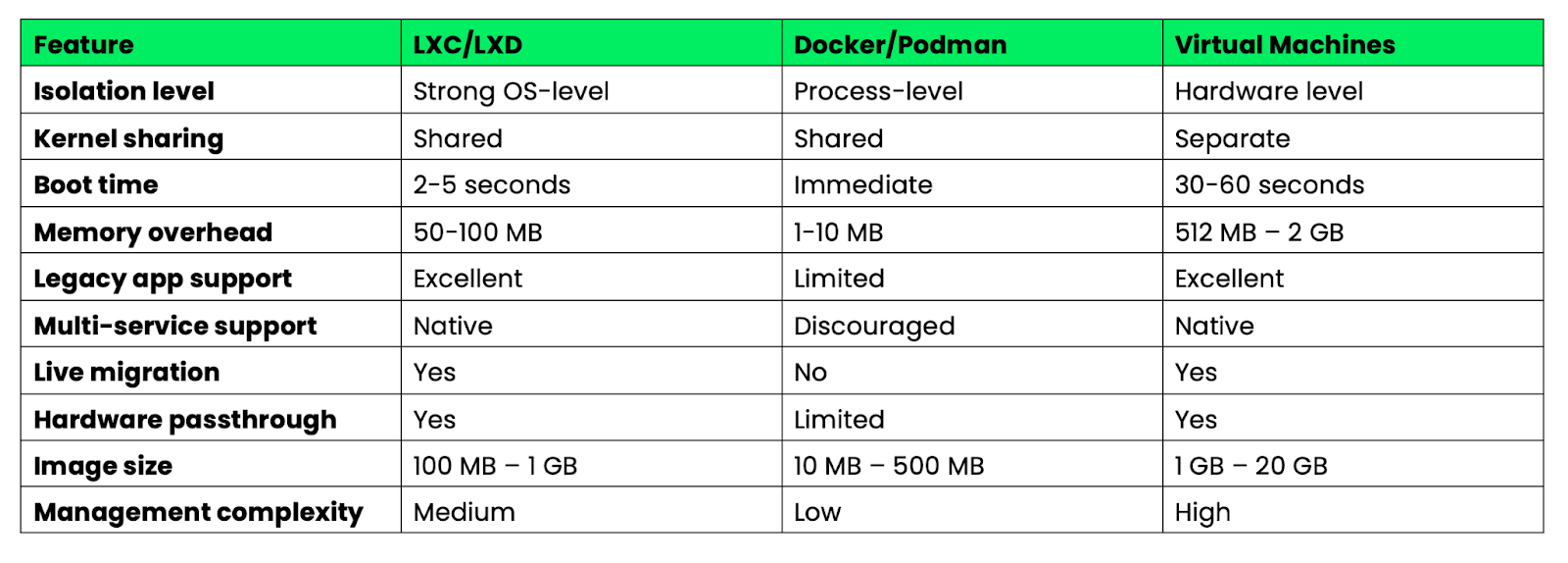
Image 6 - Aperçu des principales caractéristiques de Docker, LXC et des machines virtuelles
Les conteneurs système comblent le fossé entre les conteneurs d'applications légers et les machines virtuelles lourdes. Ils sont particulièrement adaptés lorsque vous avez besoin de fonctionnalités similaires à celles d'une machine virtuelle avec l'efficacité d'un conteneur, ou lorsque vous migrez des applications existantes qui ne peuvent pas être facilement décomposées en microservices.
Le choix entre les conteneurs système et les conteneurs d'application dépend davantage des caractéristiques de votre charge de travail et de vos exigences opérationnelles que de leur supériorité technique. Ils répondent à des besoins différents dans le domaine de la conteneurisation.
La sécurité est passée d'une considération secondaire à un principe de conception fondamental dans les environnements d'exécution de conteneurs modernes. Les plateformes actuelles mettent en œuvre des stratégies de défense en profondeur qui partent du principe que les conteneurs seront compromis et se concentrent sur la limitation du rayon d'action.
Les conteneurs sans racine éliminent le principal risque de sécurité des déploiements Docker traditionnels : le démon racine. Podman a été le premier à adopter cette approche en exécutant les conteneurs entièrement sous les privilèges utilisateur, en utilisant les espaces de noms utilisateur Linux pour mapper l'utilisateur root du conteneur à un identifiant utilisateur non privilégié sur le système hôte.
La mise en œuvre repose sur des plages d'identifiants d'utilisateurs et de groupes subordonnés (/etc/subuid et /etc/subgid) qui permettent aux utilisateurs non privilégiés de créer des espaces de noms isolés. Lorsqu'un processus conteneur pense s'exécuter en tant que root (UID 0), le noyau le mappe à votre ID utilisateur réel (par exemple, UID 1000) sur l'hôte. Même si un attaquant parvient à s'échapper du conteneur, il ne peut pas dépasser les autorisations de votre utilisateur.
Containerd a mis en œuvre des fonctionnalités similaires sans accès root grâce à son mode sans accès root, qui utilise les mêmes techniques de mappage d'espace de noms utilisateur. Le runtime peut démarrer des conteneurs, gérer des images et gérer le réseau sans nécessiter de privilèges root sur le système hôte.
Kubernetes prend désormais en charge le fonctionnement sans root de manière native grâceau projet Kubernetes-in-Rootless-Docker (KIND) et à l'intégration de containerd sans root. Cela signifie que des clusters Kubernetes entiers peuvent fonctionner sans privilèges root, ce qui réduit considérablement la surface d'attaque pour les environnements multi-locataires et les déploiements périphériques où les modèles de sécurité traditionnels ne s'appliquent pas.
L'impact sur la sécurité va au-delà de la prévention de l'escalade des privilèges. Les conteneurs sans racine ne peuvent pas se connecter aux ports privilégiés (inférieurs à 1024), n'ont pas accès à la plupart des systèmes de fichiers /proc et /sys, et ne peuvent pas effectuer d'opérations nécessitant des capacités du noyau. Cela crée des limites naturelles qui permettent de contenir les éventuelles failles de sécurité.
Les environnements d'exécution modernes intègrent eBPF (extended Berkeley Packet Filter) pour l'application en temps réel de politiques de sécurité qui vont au-delà des contrôles d'accès traditionnels. Les programmes eBPF s'exécutent dans l'espace noyau et peuvent surveiller, filtrer ou modifier les appels système au fur et à mesure qu'ils se produisent, offrant ainsi une visibilité et un contrôle sans précédent sur le comportement des conteneurs.
Les profils Seccomp (Secure Computing) utilisent BPF pour filtrer les appels système au niveau du noyau. Au lieu d'autoriser aux conteneurs l'accès à l'ensemble des plus de 300 appels système Linux, les profils seccomp définissent précisément les appels autorisés. Le profil seccomp par défaut de Docker bloque les appels système potentiellement dangereux, tandis que les profils personnalisés peuvent être encore plus restrictifs en fonction des exigences de l'application.
L'intégration avancée de l'eBPF permet une surveillance comportementale en temps réel. Des outils tels que Falco utilisent des programmes eBPF pour détecter les comportements anormaux des conteneurs, tels que des connexions réseau inhabituelles, des modèles d'accès aux fichiers inattendus ou des tentatives d'utilisation d'appels système bloqués. Ces détections se produisent en temps réel avec une surcharge minimale en termes de performances, car la surveillance s'effectue dans l'espace noyau.
L'application des politiques réseau via eBPF permet un contrôle granulaire du trafic au niveau des paquets. Cilium, un CNI Kubernetes très apprécié, utilise eBPF pour mettre en œuvre des politiques réseau capables de filtrer le trafic en fonction des protocoles de la couche application, et pas seulement des adresses IP et des ports. Cela signifie que vous pouvez créer des politiques telles que « autoriser les requêtes HTTP GET vers /api/v1/users mais bloquer les requêtes POST » directement dans le noyau.
La sécurité basée sur eBPF permet également une surveillance tenant compte des conteneurs, qui comprend la relation entre les processus, les conteneurs et les pods Kubernetes. Les outils de surveillance traditionnels examinent les processus individuels, tandis que les programmes eBPF peuvent établir une corrélation entre les appels système et les métadonnées des conteneurs afin de fournir des informations de sécurité contextuelles.
Ces fonctionnalités transforment la sécurité, qui passe d'une approche réactive de correction à une approche proactive d'application des politiques, où les comportements suspects sont automatiquement bloqués avant qu'ils ne puissent causer des dommages.
Les performances des conteneurs sont particulièrement importantes lorsque vous exécutez des centaines, voire des milliers de conteneurs sur votre infrastructure. Explorons les stratégies qui minimisent la surcharge des ressources et la latence au démarrage.
Le temps de démarrage à froid, c'est-à-dire le délai entre la demande d'un conteneur et sa disponibilité pour traiter le trafic, a un impact direct sur l'expérience utilisateur et l'efficacité des ressources. Des techniques ont été développées afin de minimiser ces délais dans différentes architectures d'exécution.
Les images pré-extraites éliminent le temps de téléchargement en conservant les images de conteneurs fréquemment utilisées en cache sur les nœuds. Les DaemonSets Kubernetes peuvent pré-télécharger des images critiques, tandis que les registres tels que Harbor prennent en charge la réplication d'images vers des emplacements périphériques. Cette technique permet de réduire le temps de démarrage à froid de quelques secondes à quelques millisecondes pour les images mises en cache.
L'optimisation des couches d'image réduit la quantité de données à transférer et à extraire. Les constructions en plusieurs étapes permettent d'obtenir des images finales plus petites, tandis que des outils tels que dive permettent d'identifier les couches inutiles. Les images Distroless de Google éliminent les gestionnaires de paquets et les shells, ce qui réduit souvent considérablement la taille des images.
Le chargement différé avec des projets tels que Stargz permet aux conteneurs d' s de démarrer avant que l'image entière ne soit téléchargée. Le runtime ne récupère que les fichiers nécessaires au démarrage initial, téléchargeant les couches supplémentaires à la demande. Cela peut réduire le temps de démarrage à froid de plusieurs secondes à moins d'une seconde pour les images de grande taille.
L'optimisation de l'exécution varie selon l'implémentation. L'implémentation Rust de Youki présente des performances de démarrage améliorées par rapport à runC grâce à une meilleure gestion de la mémoire. Crun, écrit en C, permet d'obtenir des améliorations similaires en éliminant la surcharge liée au ramasse-miettes de Go lors de la création de conteneurs.
Le partage de snapshots dans containerd permet à plusieurs conteneurs de partager des snapshots de systèmes de fichiers en lecture seule, réduisant ainsi la charge de stockage et de mémoire. Lorsque vous démarrez plusieurs conteneurs à partir de la même image, seules les couches inscriptibles nécessitent une allocation distincte.
L'optimisation du processus d'initialisation peut réduire le temps de démarrage en utilisant des systèmes d'initialisation légers tels que tini ou en concevant soigneusement les séquences de démarrage des applications afin de minimiser le travail d'initialisation.
La surcharge mémoire varie selon les environnements d'exécution des conteneurs, et ces différences deviennent critiques dans les environnements aux ressources limitées ou les déploiements à haute densité.
La surcharge de base d'exécution diffère considérablement :
La déduplication des couches d'image permet d'économiser de la mémoire lors de l'exécution de plusieurs conteneurs à partir d'images associées. Les environnements d'exécution de conteneurs utilisent des systèmes de fichiers de type « copy-on-write » (copie à l'écriture) dans lesquels les couches partagées ne consomment de la mémoire qu'une seule fois pour l'ensemble des conteneurs. Un cluster exécutant de nombreux conteneurs à partir d'images de base similaires peut réaliser d'importantes économies de mémoire grâce à la déduplication.
L'optimisation du mappage mémoire dans les environnements d'exécution modernes réduit l'utilisation de la mémoire résidente. Des outils tels que crun exécutent les fichiers directement à partir du stockage plutôt que de les charger en mémoire, ce qui réduit l'empreinte mémoire des conteneurs contenant des binaires volumineux.
La comptabilité mémoire Cgroup permet un contrôle précis des limites de mémoire des conteneurs, mais les différents environnements d'exécution gèrent différemment la pression mémoire. Certains environnements d'exécution optimisent la récupération de mémoire en cas de forte sollicitation, tandis que d'autres fournissent des rapports plus précis sur l'utilisation de la mémoire pour faciliter les décisions d'autoscaling.
L', qui ne nécessite pas de mémoire, privilégie la sécurité au détriment de l'efficacité. Les conteneurs sans racine nécessitent des processus supplémentaires pour la gestion de l'espace de noms utilisateur et la mise en réseau, ce qui ajoute généralement une surcharge par rapport au fonctionnement avec racine.
Le choix entre les environnements d'exécution se résume souvent à trouver un équilibre entre l'efficacité de la mémoire et les exigences en matière de fonctionnalités. CRI-O offre une faible surcharge pour les charges de travail Kubernetes, tandis que Podman sacrifie une partie de son efficacité au profit de la sécurité et de la compatibilité.
Le meilleur environnement d'exécution de conteneurs n'a aucune valeur s'il ne correspond pas à votre flux de travail de développement. Les alternatives à Docker ont mis en place des outils qui surpassent souvent l'expérience développeur offerte par Docker dans des scénarios spécifiques.
Le développement local de Kubernetes a évolué au-delà de l'approche de machine virtuelle de minikube vers des solutions plus efficaces qui s'intègrent directement aux environnements d'exécution de conteneurs. Le choix de l'environnement local a un impact significatif sur la vitesse de développement et la consommation des ressources.
Kind (Kubernetes dans Docker) permet de créer des clusters Kubernetes en utilisant des nœuds de conteneurs plutôt que des machines virtuelles. Le temps d'installation est généralement de 1 à 2 minutes, avec une charge mémoire modérée par nœud. Kind est compatible avec tous les environnements d'exécution compatibles avec Docker, vous pouvez donc l'utiliser avec Podman (kind create cluster --runtime podman) pour le développement Kubernetes sans root.
K3s offre une option légère, exécutant une distribution Kubernetes complète avec une utilisation minimale de la mémoire. Il démarre rapidement et comprend un stockage intégré, une mise en réseau et des contrôleurs d'entrée. K3s fonctionne efficacement avec containerd et peut être exécuté sur des machines de développement aux ressources limitées.
L' MicroK8s de Canonical offre un compromis avec une utilisation modérée de la mémoire et des modules complémentaires modulaires. Il s'intègre parfaitement à containerd et offre des fonctionnalités similaires à celles utilisées en production, sans la surcharge liée aux machines virtuelles. Le temps de démarrage est raisonnable pour un cluster complet.
Rancher Desktop combine K3s avec les backends containerd ou Dockerd, offrant une alternative à Docker Desktop qui utilise moins de ressources. Il comprend une fonctionnalité intégrée de numérisation d'images et une intégration au tableau de bord Kubernetes.
Les pods Podman offrent une alternative unique : vous pouvez développer des applications multi-conteneurs en utilisant le concept de pod de Podman, qui reflète le comportement des pods Kubernetes. Générez directement du code YAML Kubernetes à partir de pods en cours d'exécution à l'aide d'podman generate kube, créant ainsi un cheminement fluide entre le développement local et le déploiement en cluster.
Les pipelines CI/CD traditionnels basés sur Docker rencontrent des limitations dans les environnements conteneurisés où l'exécution de Docker-in-Docker pose des défis en matière de sécurité et de performances. Les alternatives modernes offrent de meilleures solutions pour créer et déployer des images de conteneurs dans les systèmes d'intégration continue.
Buildah excelle dans les environnements CI car il ne nécessite ni démon ni privilèges root. Vous pouvez créer des images conformes à l'OCI à l'aide de scripts shell qui sont plus faciles à auditer que les fichiers Dockerfile. L'approche de script de Buildah permet la construction dynamique d'images basée sur des variables CI, ce qui la rend idéale pour les processus de construction complexes nécessitant une logique conditionnelle.

Image 7 - Page d'accueil de Buildah
À titre de comparaison, les fichiers Dockerfile traditionnels utilisent des instructions déclaratives :
FROM alpine:latest
RUN apk add --no-cache nodejs npm
COPY package.json /app/
WORKDIR /appBuildah utilise des commandes shell impératives pouvant inclure des variables et une logique conditionnelle :
# Buildah scripting approach with CI integration
buildah from alpine:latest
buildah run $container apk add --no-cache nodejs npm
buildah copy $container package.json /app/
buildah config --workingdir /app $container
buildah commit $container myapp:${CI_COMMIT_SHA}Cette flexibilité de script vous permet de sélectionner dynamiquement des images de base, d'installer des paquets de manière conditionnelle en fonction des noms de branche ou de modifier les étapes de compilation en fonction des variables d'environnement CI, des capacités qui nécessitent des solutions de contournement complexes dans les fichiers Dockerfile traditionnels.
Kaniko résout le problème de l'e et du Docker-in-Docker en créant des images entièrement dans l'espace utilisateur au sein d'un conteneur. Il fonctionne dans des pods Kubernetes sans nécessiter d'accès privilégié ni de démon Docker. Kaniko est efficace dans les pipelines GitLab CI et Jenkins X où les politiques de sécurité empêchent les conteneurs privilégiés.
Cet outil extrait les images de base, applique les instructions Dockerfile de manière isolée et transfère les résultats directement vers les registres. Les temps de compilation sont comparables à ceux de Docker, mais avec une sécurité nettement améliorée dans les environnements orchestrés.
Nerdctl assure la compatibilité de l'interface CLI Docker d' s pour containerd, ce qui en fait un excellent substitut à Docker dans les systèmes CI. Il prend en charge les mêmes commandes build, push et pull que Docker, mais utilise containerd comme backend. Cela élimine le démon Docker tout en conservant les flux de travail habituels.
Nerdctl comprend des fonctionnalités avancées telles que le « lazy pulling » et les images cryptées qui peuvent améliorer les performances de l'intégration continue. Pour les équipes utilisant containerd en production, nerdctl assure la cohérence entre les environnements CI et d'exécution.
Comparaison des performances dans les pipelines CI :
Le choix dépend de vos exigences en matière de sécurité, de l'infrastructure existante et des besoins en termes de performances. Kaniko est particulièrement efficace dans les environnements Kubernetes axés sur la sécurité, tandis que Buildah est recommandé lorsque vous avez besoin d'une logique de compilation complexe difficile à exprimer dans les fichiers Dockerfiles.
Le déploiement de conteneurs en entreprise nécessite plus que le simple choix du bon environnement d'exécution. Il est nécessaire de disposer de plateformes capables de gérer la conformité, la gouvernance et les opérations multi-clusters à grande échelle. Les solutions de conteneurs que vous sélectionnez doivent s'intégrer aux outils de gestion d'entreprise et respecter les exigences réglementaires.
La gestion des conteneurs sur plusieurs clusters, clouds et emplacements périphériques nécessite des plateformes d'orchestration sophistiquées qui vont au-delà des fonctionnalités de base de Kubernetes. Les solutions d'entreprise offrent une gestion centralisée, l'application des politiques et une cohérence opérationnelle dans divers environnements.
Red Hat OpenShift développe l' e sur Kubernetes avec des choix de runtime de conteneurs axés sur l'entreprise. OpenShift utilise par défaut CRI-O pour une sécurité et une efficacité des ressources accrues par rapport aux déploiements basés sur Docker. La plateforme intègre des fonctionnalités de scan d'images, d'application des politiques et de workflows de développement qui fonctionnent de manière cohérente, que vous utilisiez AWS, Azure ou une infrastructure sur site.

Image 8 - Page d'accueil de Red Hat OpenShift
La gestion multi-clusters d'OpenShift assure la standardisation de l'environnement d'exécution dans tous les environnements. Vous pouvez exiger que tous les clusters utilisent CRI-O avec des politiques de sécurité spécifiques, garantissant ainsi un comportement cohérent, que les conteneurs soient exécutés dans des environnements de développement, de test ou de production.
Rancher fournit, une interface unifiée pour la gestion des clusters Kubernetes, quel que soit leur environnement d'exécution de conteneurs sous-jacent. Rancher prend en charge les clusters exécutant Docker, containerd ou CRI-O, ce qui vous permet de migrer progressivement les environnements d'exécution sans perturber les opérations. La plateforme comprend une surveillance centralisée, une sauvegarde et une analyse de sécurité sur tous les clusters gérés.
Image 9 - Page d'accueil de Rancher
L'approche de Rancher est particulièrement utile lorsque vous disposez d'environnements mixtes : certains clusters peuvent utiliser containerd pour des raisons de performances, tandis que d'autres utilisent CRI-O pour des raisons de conformité en matière de sécurité. La couche de gestion résume ces différences tout en fournissant des outils opérationnels cohérents.
Mirantis Kubernetes Engine se concentre sur les environnements Docker d'entreprise, mais prend en charge la migration vers des déploiements basés sur containerd. La plateforme offre un soutien aux entreprises, un renforcement de la sécurité et des outils de conformité qui fonctionnent sur différents environnements d'exécution de conteneurs.
Image 10 - Page d'accueil de Mirantis
Ces plateformes simplifient la complexité opérationnelle liée à l'exécution de différents environnements d'exécution de conteneurs au sein de votre infrastructure, tout en maintenant une gouvernance centralisée et des politiques de sécurité.
Les environnements d'entreprise exigent souvent la conformité à des réglementations telles que FIPS 140-2, SOC 2 ou RGPD, qui ont un impact direct sur le choix et la configuration du runtime des conteneurs. La conformité ne concerne pas uniquement le runtime lui-même, elle s'étend également aux registres d'images, aux analyses de sécurité et à la journalisation des audits.
La validation FIPS (Federal Information Processing Standards) exige des modules cryptographiques conformes aux normes de sécurité gouvernementales. Tous les environnements d'exécution de conteneurs ne prennent pas en charge les bibliothèques cryptographiques validées par la norme FIPS. Red Hat Enterprise Linux fournit des versions conformes à la norme FIPS de CRI-O et Podman, tandis que les installations Docker standard nécessitent souvent une configuration supplémentaire pour être conformes à la norme FIPS.
La conformité FIPS concerne la signature d'images, les communications TLS et le stockage crypté. Les plateformes de conteneurs doivent utiliser des bibliothèques cryptographiques validées par la norme FIPS pour toutes les opérations de sécurité, du téléchargement d'images à l'établissement de connexions réseau entre les conteneurs.
La conformité au RGPD a un impact sur la manière dont les plateformes de conteneurs traitent les données personnelles dans les journaux, les métriques et les métadonnées d'images. Les registres de conteneurs d'entreprise tels que Harbor, Quay et AWS ECR offrent des fonctionnalités telles que le contrôle de la résidence des données, la journalisation des audits et les politiques automatisées de conservation des données.
Les environnements d'exécution des conteneurs doivent prendre en charge des fonctionnalités de conformité telles que :
La conformité SOC 2 exige des contrôles de sécurité démontrables en matière de gestion des accès, de surveillance des systèmes et de protection des données. Les plateformes de conteneurs doivent s'intégrer aux fournisseurs d'identité d'entreprise, fournir des pistes d'audit détaillées et prendre en charge l'application automatisée des politiques de sécurité.
Les environnements d'exécution de conteneurs modernes tels que CRI-O et containerd offrent une meilleure base de conformité que Docker, car ils proposent des contrôles de sécurité plus granulaires, une meilleure journalisation des audits et une séparation plus claire entre les composants d'exécution et les interfaces de gestion.
La conformité s'étend également à la sécurité de la chaîne d'approvisionnement, garantissant que les images de conteneurs proviennent de sources fiables et n'ont pas été altérées. Des outils tels que Sigstore et in-toto permettent de vérifier de manière cryptographique la provenance des images de conteneurs, tandis que les contrôleurs d'admission peuvent garantir que seules les images signées et analysées sont exécutées dans les clusters de production.
Le paysage de la conteneurisation continue d'évoluer au-delà des conteneurs Linux traditionnels vers de nouveaux modèles d'exécution et de nouveaux paradigmes d'observabilité. Ces technologies émergentes promettent de remédier aux limitations fondamentales des architectures de conteneurs actuelles.
WebAssembly (WASM) s'impose progressivement comme une alternative convaincante aux conteneurs OCI traditionnels pour des charges de travail spécifiques. Contrairement aux conteneurs qui encapsulent l'intégralité de l'espace utilisateur d'un système d'exploitation, WebAssembly fournit un environnement d'exécution léger et sandboxé qui fonctionne à des vitesses proches de celles d'un système natif sur différentes architectures.
Les modules WASM démarrent beaucoup plus rapidement que les conteneurs traditionnels, ce qui les rend idéaux pour les fonctions sans serveur et l'informatique de pointe, où le temps de démarrage à froid a un impact direct sur l'expérience utilisateur. Un module WebAssembly peut traiter un nombre de requêtes nettement supérieur à celui d'un conteneur dont les temps d'initialisation sont plus lents.
Le modèle de sécurité diffère fondamentalement de celui des conteneurs. WebAssembly offre une sécurité basée sur les capacités, dans laquelle les modules ne peuvent accéder qu'aux ressources qui leur ont été explicitement accordées. Il n'y a pas de surface de noyau partagée comme dans les conteneurs traditionnels : les modules WASM s'exécutent dans un environnement sandboxé qui empêche de nombreuses catégories de vulnérabilités de sécurité.
Les environnements d'exécution de conteneurs commencent à prendre en charge directement les charges de travail WebAssembly. Wasmtime intègre avec containerd en tant que shim d'exécution, ce qui vous permet de déployer des modules WASM à l'aide du format YAML standard de Kubernetes. Cela signifie que vous pouvez combiner des conteneurs traditionnels et des charges de travail WebAssembly dans le même cluster en fonction des exigences de performance et de sécurité.
Le compromis réside dans la maturité de l'écosystème. WebAssembly offre une prise en charge linguistique limitée par rapport aux conteneurs : Rust, C/C++ et AssemblyScript fonctionnent bien, tandis que des langages tels que Python et Java nécessitent des couches d'exécution supplémentaires qui réduisent les avantages en termes de performances.
WASM est particulièrement performant pour les charges de travail informatiques, les fonctions sans serveur et l'informatique de pointe, mais n'est pas encore en mesure de remplacer les conteneurs pour les applications complexes qui nécessitent une intégration approfondie du système d'exploitation.
eBPF (extended Berkeley Packet Filter) transforme l'observabilité des conteneurs en fournissant des informations au niveau du noyau sans nécessiter de modifications des applications ou de conteneurs sidecar. Contrairement à la surveillance traditionnelle qui s'appuie sur des métriques exportées par les applications, les programmes eBPF observent les appels système, le trafic réseau et les événements du noyau en temps réel.
La surveillance sensible aux conteneurs via eBPF établit une corrélation entre les événements système de bas niveau et les métadonnées de haut niveau des conteneurs et de Kubernetes. Des outils d'els que Pixie et Cilium Hubble peuventvous indiquer précisément quelles requêtes HTTP circulent entre des pods spécifiques, y compris la latence des requêtes, l'inspection des charges utiles et les taux d'erreur, le tout sans modifier vos applications.
Cette approche offre une visibilité sans précédent sur les modèles de communication des microservices. Vous pouvez générer automatiquement des cartes de service en observant les flux réseau réels plutôt qu'en vous basant sur une configuration statique. Lorsqu'un service commence à communiquer avec une nouvelle dépendance, les outils basés sur eBPF le détectent immédiatement et mettent à jour la topologie du service en temps réel.
L', qui analyse les performances à l'aide de l'eBPF, identifie les goulots d'étranglement au niveau des conteneurs. Au lieu de vous demander pourquoi un pod est lent, vous pouvez voir précisément quelles appels système prennent du temps, quels fichiers sont consultés et comment la latence du réseau affecte les performances des applications. Ces données sont collectées en continu avec une charge minimale, généralement inférieure à 1 % de l'utilisation du processeur.
L' s de surveillance de la sécurité bénéficie de la capacité de l'eBPF à détecter les comportements anormaux. Au lieu d'analyser les journaux après un incident, les programmes eBPF peuvent détecter les appels système suspects, les connexions réseau inattendues ou les modèles d'accès aux fichiers dès qu'ils se produisent. Cela permet une détection des menaces en temps réel qui tient compte du contexte des limites des conteneurs et de l'identité des charges de travail Kubernetes.
L'intégration entre eBPF et les environnements d'exécution de conteneurs continue de s'intensifier. Cilium fournit une mise en réseau basée sur eBPF pour Kubernetes qui est à la fois plus rapide et plus observable que les plugins CNI traditionnels. Falco utilise eBPF pour la surveillance de la sécurité à l'exécution qui comprend nativement le contexte des conteneurs.
Cette tendance vers l'observabilité au niveau du noyau représente un changement fondamental, passant d'une surveillance de type « boîte noire » à une transparence totale du système, rendant les environnements de conteneurs plus faciles à déboguer et plus sécurisés par défaut.
Choisir la bonne alternative à Docker ne consiste pas à trouver un seul remplacement, mais plutôt à adapter les outils à des cas d'utilisation spécifiques dans vos environnements de développement et de production. L'écosystème de la conteneurisation a évolué pour devenir un ensemble de solutions performantes dans différents scénarios.
En ce qui concerne l'expérience développeur, Podman offre la migration la plus fluide grâce à sa compatibilité avec l'interface CLI Docker, tout en garantissant une sécurité supérieure grâce à son fonctionnement sans root. Si vous utilisez beaucoup les workflows Docker Desktop, Rancher Desktop avec containerd offre des fonctionnalités similaires avec une meilleure efficacité des ressources. Les équipes qui développent des pipelines CI/CD complexes bénéficient de la flexibilité des scripts de Buildah ou de l'approche sécurisée et sans démon de Kaniko.
À l'échelle de la production,, containerd et CRI-O offrent de meilleures performances et une meilleure efficacité des ressources que Docker Engine. Containerd est particulièrement adapté aux environnements d'entreprise qui requièrent stabilité et fonctionnalités étendues, tandis que CRI-O constitue l'option la plus efficace pour les déploiements axés sur Kubernetes. Pour l'informatique en périphérie ou les systèmes embarqués, les environnements d'exécution légers tels que runC ou Youki offrent la surcharge minimale requise pour les environnements aux ressources limitées.
Les organisations soucieuses de la sécurité devraient privilégier les environnements d'exécution sans root tels que Podman ou containerd sans root. La combinaison de l'isolation de l'espace utilisateur, de la surveillance basée sur eBPF et de la réduction de la surface d'attaque offre une défense en profondeur que les déploiements Docker traditionnels ne peuvent égaler. Pour les secteurs réglementés, veuillez vous assurer que le runtime que vous avez sélectionné est conforme à la norme FIPS et s'intègre aux systèmes de journalisation d'audit de l'entreprise.
Une approche hybride s'avère souvent la plus efficace dans la pratique.. Veuillez utiliser Podman pour le développement local afin de bénéficier d'une sécurité sans root et de la compatibilité Docker. Déployez vos charges de travail de production sur containerd ou CRI-O pour une intégration et des performances Kubernetes optimales. Utilisez des outils spécialisés tels que Buildah pour les pipelines CI/CD où la sécurité et la flexibilité sont plus importantes que la compatibilité.
Vous recherchez des idées de projets liés à Docker et à la conteneurisation ? Ces 10 éléments vous aideront à démarrer.
À l'avenir, WebAssembly et eBPF représentent la prochaine évolution dans le domaine de la conteneurisation. Les temps de démarrage rapides et les garanties de sécurité élevées de WebAssembly devraient dominer les charges de travail sans serveur et de l'edge computing. L'observabilité au niveau du noyau d'eBPF transforme déjà la manière dont nous surveillons et sécurisons les applications conteneurisées. Ces technologies ne remplaceront pas entièrement les conteneurs traditionnels, mais elles créeront de nouvelles catégories de charges de travail auxquelles les limitations actuelles des conteneurs ne s'appliquent pas.
Il est essentiel de rester flexible à mesure que ces technologies évoluent et de comprendre que la meilleure stratégie de conteneurisation consiste à combiner plusieurs outils plutôt que de dépendre d'une seule solution.
Si vous souhaitez en savoir plus sur Docker, la conteneurisation, la virtualisation et Kubernetes, ces cours constituent une excellente étape suivante :
Veuillez approfondir vos connaissances sur Docker grâce à ces cours.
Cursus
Cours
Cours