
programa
Desarrollar grandes modelos lingüísticos
16 h
Si tuviera que describir la nueva era de la IA en una palabra, sería escala. Desde que OpenAI publicó la interfaz basada en web para GPT-3, conocida como ChatGPT, en noviembre de 2022, la popularidad de los Modelos de Grandes Lenguajes ha crecido significativamente debido a su uso generalizado por el público en general.
El término escala se aplica no sólo a la popularidad de estos modelos, sino también a la gran cantidad de datos con los que se entrenan, su elevado número de parámetros y la diversidad de tareas que pueden realizar.
Desde mi punto de vista, el auge de este tipo de modelos puso inicialmente Grandes Modelos Lingüísticos (LLM) en el centro. Dos años después, debido a los avances en este campo, creo que el término popular ha pasado a ser modelos fundacionales.
Pero, ¿qué son los modelos fundacionales? Y ¿qué hace que un modelo sea fundacional?
Al contrario que los LLM, los modelos fundacionales existen en la comunidad desde hace siglos. En este artículo, exploraremos el concepto de modelos fundacionales, centrándonos en sus características clave, aplicaciones y futuro en la era de la IA.
Tomemos una arquitectura de IA, como un transformadory entrénala con grandes cantidades de datos diversos: texto de Common Crawl y libros, imágenes, vídeos de YouTube y mucho más.
Como estos datos son amplios, generales y multimodales, el modelo resultante se convierte en un gran sistema de propósito general con amplios conocimientos. Se trata de unmodelo fundacional : un modelo versátil y de uso general que sirve de "base" para construir aplicaciones de IA especializadas.
Estos modelos básicos pueden adaptarse a tareas específicas mediante el ajuste fino, el estímulo u otras técnicas de aprendizaje por transferencia. La idea es que, una vez especializado en un dominio concreto, el modelo conserve las fuertes propiedades de generalización y las capacidades emergentes del modelo base.
Los primeros sistemas de IA se basaban principalmente en reglas y eran muy específicos de cada dominio, por lo que requerían una programación específica para cada tarea. Los primeros años de la década de 2000 estuvieron marcados por la aparición del aprendizaje automático como un cambio hacia los enfoques basados en datos, aunque todavía se limitaba a tareas específicas.
El gran avance del aprendizaje profundo se produjo en torno a 2012, permitiendo un reconocimiento de patrones más complejo y modelos generativos avanzados, con dos grandes hitos: las redes generativas adversariales en 2014 y transformadores en 2017.
El crecimiento de la IA se ha visto muy favorecido por los avances en potencia computacional (p. ej, GPUs, TPUs) y la disponibilidad de conjuntos de datos masivos, que han permitido el entrenamiento de modelos cada vez mayores, lo que ha llevado a la aparición de modelos fundacionales.
La diferencia entre los sistemas tradicionales de IA y los modelos fundacionales también viene definida por su escala. Un ejemplo de ello es el paso del entrenamiento con conjuntos de datos curados en los sistemas tradicionales de IA, al uso de datos masivos, diversos y a menudo no estructurados en los modelos fundacionales. Además, los modelos fundacionales muestran una gran capacidad de generalización, lo que les permite abordar tareas más complejas y diversas, mientras que los sistemas tradicionales de IA suelen requerir un reentrenamiento o amplias modificaciones para nuevas tareas.
Hay algunas características especiales que hacen que los Modelos Fundacionales sean únicos:
La generalización se refiere a la capacidad de un modelo para rendir bien en tareas no vistas o, concretamente, en datos más allá de su conjunto de entrenamiento. Los modelos fundacionales son especialmente valiosos por esta propiedad. En estrecha relación con esto, estos modelos también pueden mostrar habilidades inesperadas, no planificadas en el entrenamiento, que surgen a escala, lo que se conoce como comportamiento emergente.
Mientras que la generalización es un resultado esperado del entrenamiento de modelos, las capacidades emergentes suelen ser impredecibles, ya que los modelos no se entrenan explícitamente para esos fines.
Además, estos modelos son escalables, lo que significa que su rendimiento puede mejorarse aumentando el tamaño del modelo (junto con los datos y los recursos informáticos). Aunque los modelos más grandes tienden a generalizar mejor,el tamaño del modelo por sí solo no garantiza una mejor generalización. Sin embargo, los comportamientos emergentes están fuertemente correlacionados con el tamaño del modelo.
La multimodalidad se refiere a la capacidad de un modelo de IA para procesar e integrar múltiples tipos de datos, como texto, imágenes, vídeo, etc. Aunque los Modelos Fundacionales pueden ser multimodales, no es un requisito.
Uno de los aspectos clave de la multimodalidad es la comprensión intermodal, en la que el modelo puede comprender y conectar información entre distintos tipos de datos. Por ejemplo, combinar texto e imágenes para generar pies de foto o responder a preguntas sobre contenido visual. La multimodalidad permite interacciones más ricas y abre la puerta a aplicaciones en las que texto, visión y audio deben trabajar juntos, como en robótica o sistemas sanitarios.
Para una explicación más detallada de la Multimodalidad, considera la posibilidad de leer nuestro artículo, ¿Qué es la IA Multimodal?
Por último, otro aspecto clave de los modelos fundacionales es que pueden servir de base para modelos específicos de dominio. Por tanto, podemos adaptarlos a tareas o dominios específicos ajustando sus ponderaciones basándonos en un conjunto de datos más pequeño y específico del dominio, al tiempo que nos beneficiamos de su multimodalidad, capacidad de generalización y otras propiedades. Este proceso se conoce como ajuste, sobre el que puedes obtener más información en nuestra guía para afinar los LLM.
Algunas técnicas de ajuste son
Los grandes modelos lingüísticos son un tipo especializado de modelo fundacional entrenado exclusiva o predominantemente en datos de texto. Un LLM puede afinarse aún más para tareas específicas, como la traducción de idiomas o el resumen.
La siguiente tabla puede ayudar a resaltar las diferencias y similitudes entre ambas categorías de modelos:
|
Aspecto |
Modelo Fundacional |
Modelo de lengua grande |
|
Alcance |
Modelos de uso general que suelen entrenarse con datos multimodales. |
Subconjunto de Modelos Fundacionales entrenados exclusivamente con datos de prueba, y a veces afinados para una tarea específica. |
|
Datos de entrenamiento |
Conjuntos de datos diversos (y generalmente multimodales). |
Principalmente corpus de texto. |
|
Arquitectura |
Múltiples arquitecturas: Transformadores, Redes Neuronales Convolucionales (CNN), o arquitecturas híbridas según el tipo de datos. |
Arquitectura típicamente basada en transformadores. |
|
Casos prácticos |
Tareas generales multimodales. |
Centrado en tareas lingüísticas: traducción, resumen, chatbot, generación de código, etc. Popular en toda la sociedad actual. Encuentra los modelos de código abierto más populares en nuestra guía. |
* En la próxima sección profundizaremos un poco más en las arquitecturas de los Modelos Fundacionales.
Si pensamos en un ejemplo más práctico, el primer modelo GPT utilizado en la interfaz web ChatGPT fue el GPT-3. Era un modelo de gran lenguaje puramente textual, y los usuarios sólo podían interactuar con él mediante instrucciones. Dado que los LLM son un subconjunto dentro de los modelos fundacionales, el GPT-3 también era un modelo fundacional.
Hoy en día, cuando entramos en la interfaz de ChatGPT, vemos que podemos adjuntar imágenes junto al aviso. Esto se debe a que ahora GPT-4 es el modelo que hay detrás de la interfaz. La GPT-4 es, en cambio, un modelo fundacional multimodal.
Captura de pantalla de la interfaz multimodal de ChatGPT.
Dado que nuestra primera interacción con esos grandes modelos fue a través de los LLM, la gente tiende a pensar que la arquitectura Transformer es la única que está detrás de los modelos fundacionales.
Sin embargo, redes neuronales recurrentes (RNN) eran la arquitectura a la que se recurría para los Modelos Fundacionales basados en texto antes de que los Transformadores ganaran popularidad.
En el ámbito de la generación de imágenes, los modelos de difusión son ahora la columna vertebral de estos sistemas de última generación. Algunos modelos conocidos son la Difusión Estable y DALL-E, pero Redes Neuronales Convolucionales (CNN) ¡se utilizaron antes que ellas!
Los modelos de difusión se consideran fundamentales para la generación de imágenes por las mismas razones antes expuestas: pueden generar imágenes diversas y de alta calidad, y ajustarse con precisión para tareas específicas, como la edición o el repintado de imágenes.
Los Modelos Fundacionales se utilizan en diversos ámbitos debido a su versatilidad y adaptabilidad, algunos de ellos son:
Como ya se ha dicho, los Modelos Fundacionales han aportado notables mejoras al Procesamiento del Lenguaje Natural. Las capacidades similares a las humanas de modelos como ChatGPT han hecho que esos modelos sean indispensables enlas aplicaciones de atención al cliente de , por ejemplo. Ahora es probable que todos los agentes conversacionales en línea se basen en LLM, que pueden entablar conversaciones más naturales y coherentes en comparación con los anteriores chatbots que se basaban en sistemas basados en reglas.
Estos modelos también impulsan aplicaciones de traducción de idiomas como Google Translate y DeepL. Si utilizas ahora estas herramientas, te darás cuenta de que se han vuelto más precisas y conscientes del contexto que hace diez años.
Si te interesan las aplicaciones del lenguaje natural, el curso "Desarrollo de aplicaciones de IA"¡te dará un empujón!
Modelos como CLIP y DALL-Epor ejemplo, combinan la comprensión de textos e imágenes, lo que permite aplicaciones como el subtitulado de imágenes y generación de texto a imagenque no eran viables con las arquitecturas anteriores.
Entre las herramientas, Adobe Photoshop ha incorporado modelos de difusión en sus herramientas de edición, como en Relleno basado en el contenido y otras funciones basadas en IA para completar y repintar imágenes automáticamente.
Por último, también existen aplicaciones multimodales que pueden procesar e integrar datos de múltiples dominios simultáneamente. Por ejemplo, enlos sistemas autónomos de , Tesla y Waymo -el proyecto de vehículo autónomo de Google- utilizan sistemas multimodales que combinan datos visuales de cámaras, señales de radar y sensores LiDAR, con información textual y contextual para navegar y comprender el entorno.
Estas aplicaciones multidominio están transformando las industrias, permitiendo sistemas más dinámicos, adaptables e inteligentes que antes estaban limitados por modelos más estrechos.
Después de ver esas aplicaciones, podemos clasificar visualmente los modelos como en la imagen siguiente:
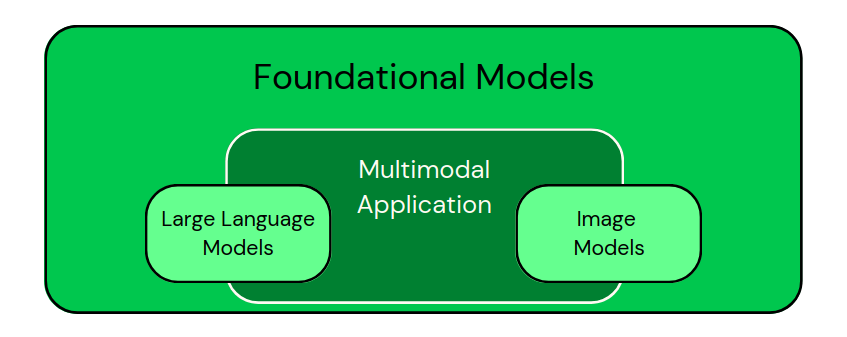
Clasificación de los modelos específicos de dominio como subconjuntos de los Modelos Fundacionales. Las aplicaciones multimodales combinan distintos tipos de datos. - Imagen del autor
Si estás pensando en construir aplicaciones impulsadas por estos modelos, el artículo "5 proyectos que puedes construir con modelos generativos de IA" te dará algunas ideas estupendas.
Como hemos visto, los modelos fundacionales tienen mayores capacidades, pero también debemos ser conscientes de que conllevan varios retos y consideraciones éticas:
El entrenamiento de estos modelos requiere muchos recursos en términos de tiempo y energía. Una vez entrenados, estos modelos siguen exigiendo recursos sustanciales para la inferencia, sobre todo en aplicaciones en tiempo real, lo que hace que sean caros de operar a escala. A medida que los modelos se hacen más grandes y complejos, también aumenta la carga computacional.
El coste es algo especialmente difícil para las instituciones de investigación y empresas más pequeñas, que pueden carecer de medios económicos para entrenar grandes modelos desde cero, lo que permite a las grandes empresas dominar la investigación en este campo. En mi opinión, la disponibilidad de modelos de código abierto preentrenados ayudará en ambos sentidos.
Estrechamente relacionado con el coste, el impacto medioambiental de este tipo de modelos es una preocupación creciente. Entrenar grandes modelos de IA consume una cantidad sustancial de energía, lo que contribuye a una elevada huella de carbono.
El uso creciente de la IA y el preentrenamiento de modelos cada vez mayores intensifica la preocupación por la sostenibilidad. Se están haciendo esfuerzos para reducir el consumo de energía mediante algoritmos y hardware más eficientes, así como mediante la adopción de fuentes de energía renovables en los centros de datos, pero la cuestión sigue siendo crítica.
Los modelos fundacionales no están exentos del riesgo de sesgo. Como ocurre con muchos algoritmos de aprendizaje profundo, este riesgo surge de la gran cantidad de datos del mundo real con los que se entrenan. Los modelos heredan inevitablemente sesgos presentes en los datos, que pueden dar lugar a resultados injustos o a discriminación en aplicaciones sensibles.
Mitigar los sesgos es esencial y puede lograrse mediante estrategias como la aplicación de algoritmos justos, la diversificación de los conjuntos de datos de entrenamiento y la auditoría periódica de los modelos para garantizar que no perpetúan sesgos perjudiciales.
Por último, la preocupación normativa en torno al uso de modelos fundacionales es cada vez mayor. A medida que estos modelos se hacen más potentes y se despliegan en diversas industrias, los gobiernos y los organismos internacionales trabajan para establecer marcos de seguridad y responsabilidad de la IA.
Garantizar el cumplimiento de las normas mundiales, como la Ley de IA de la UE, será crucial para gestionar los riesgos asociados al despliegue de la IA, incluidos los problemas de privacidad y la desinformación. Puedes ponerte al día sobre esta normativa con el curso de DataCamp Fundamentos de la Ley de IA de la UE.
Una de las tendencias más destacadas en los modelos fundacionales es la evolución de las capacidades multimodales. Estos modelos se diseñan cada vez más para procesar e integrar diversos tipos de datos en un marco unificado.
Este enfoque multimodal permite a los sistemas de IA comprender mejor el mundo e interactuar con él, y algunos afirman que incluso lo hacen de un modo que refleja la cognición humana. A medida que estas capacidades maduren, estoy seguro de que permitirán aplicaciones más completas.
Otra tendencia interesante es la perspectiva de la adaptabilidad en tiempo real. Los modelos fundacionales actuales requieren un amplio preentrenamiento y un ajuste fino para adaptarse a tareas específicas. Sin embargo, se espera que los modelos futuros sean más dinámicos, capaces de aprender y adaptarse en tiempo real a medida que encuentren nuevos datos o entornos.
Esta posibilidad permitirá a los sistemas de IA responder más eficazmente a las condiciones cambiantes, como la evolución de las preferencias de los usuarios o las tendencias emergentes en los datos.
Por último, las innovaciones para hacer que los modelos sean más ligeros y accesibles es también un requisito tanto para disminuir el consumo de energía y el coste como para democratizar el uso de las tecnologías fundacionales de la IA.
La investigación en curso pretende reducir el tamaño y la demanda de recursos de estos modelos sin comprometer su rendimiento. Se están explorando técnicas como la destilación de modelos, la cuantización y el diseño de arquitecturas eficientes para crear modelos más pequeños, más rápidos y más eficientes energéticamente.
Además, los modelos ligeros permitirán el despliegue en dispositivos periféricos, como smartphones y dispositivos IoT, acercando las capacidades de IA a los usuarios finales en aplicaciones del mundo real.
Me gustaría asegurarme de que, llegados a este punto, podemos abordar la cuestión planteada en la introducción: "¿Qué hace que un modelo fundacional sea fundacional?".
Un modelo es fundacional cuando es de propósito general, capaz de generalizarse a través de diversas tareas y puede especializarse para diferentes tareas más limitadas. Los modelos fundacionales permiten desarrollar modelos específicos para cada tarea, que sirven de base para el ajuste fino en diversos dominios. Sin embargo, su poder conlleva retos, como la parcialidad y los problemas éticos, y algunas nuevas tendencias futuras que explorar.
Si estás interesado en más contenido como este, considera echar un vistazo a DataCamp's Fundamentos de la IA que cubre muchos de los aspectos esenciales necesarios para trabajar con modelos de IA.
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
11 min
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Moez Ali


