
Cursus
Développer des LLM
16 h
Si je devais décrire la nouvelle ère de l'IA en un mot, ce serait échelle. Depuis qu'OpenAI a publié l'interface web pour le GPT-3, connue sous le nom de ChatGPT, en novembre 2022, la popularité des grands modèles de langage a considérablement augmenté en raison de leur utilisation généralisée par le grand public.
Le terme échelle s'applique non seulement à la popularité de ces modèles, mais aussi à à la grande quantité de données sur lesquelles ils sont entraînés, au nombre élevé de paramètres et à la diversité des tâches qu'ils peuvent accomplir. qu'ils peuvent accomplir.
De mon point de vue, l'essor de ces types de modèles a d'abord mis l'accent sur l'importance de l'utilisation de la langue. grands modèles linguistiques (LLM) au centre. Deux ans plus tard, en raison des progrès réalisés dans ce domaine, je pense que le terme populaire a été remplacé par modèles fondamentaux.
Mais qu'est-ce qu'un modèle fondamental ? Et Qu'est-ce qui fait qu'un modèle est fondateur ?
Contrairement aux LLM, les modèles fondateurs existent depuis longtemps dans la communauté. Dans cet article, nous allons explorer le concept de modèles fondamentaux, en nous concentrant sur leurs caractéristiques clés, leurs applications et leur avenir à l'ère de l'IA.
Prenez une architecture IA, telle qu'un transformateuret entraînez-la sur de grandes quantités de données diverses : textes issus de Common Crawl et de livres, images, vidéos YouTube, etc.
Comme ces données sont vastes, générales et multimodales, le modèle qui en résulte devient un grand système polyvalent doté de connaissances étendues. Il s'agit d'unmodèle fondamental ( ): un modèle polyvalent, à usage général, qui sert de "base" à la création d'applications spécialisées dans l'IA.
Ces modèles de base peuvent être adaptés à des tâches spécifiques par le biais d'un réglage fin, d'invites ou d'autres techniques d'apprentissage par transfert. L'idée est qu'une fois spécialisé dans un domaine spécifique, le modèle conservera les fortes propriétés de généralisation et les capacités émergentes du modèle de base.
Les premiers systèmes d'IA étaient principalement basés sur des règles et très spécifiques à un domaine, ce qui nécessitait une programmation spécifique à une tâche. Le début des années 2000 a été marqué par l'émergence de l'apprentissage automatique en tant qu'évolution vers des approches basées sur les données, bien qu'il soit encore limité à des tâches spécifiques.
La percée de l'apprentissage profond a eu lieu vers 2012, permettant une reconnaissance des formes plus complexe et des modèles génératifs avancés, avec deux étapes majeures : les réseaux adversaires génératifs en 2014 et les transformateurs en 2017.
Le développement de l'IA a été largement soutenu par les progrès de la puissance de calcul (par ex, GPU, TPU) et la disponibilité d'énormes ensembles de données, qui ont permis l'entraînement de modèles de plus en plus grands, conduisant à l'émergence de modèles fondamentaux.
La différence entre les systèmes d'IA traditionnels et les modèles fondateurs est également définie par leur échelle. Le passage de la formation sur des ensembles de données conservés dans les systèmes d'IA traditionnels à l'utilisation de données massives, diverses et souvent non structurées dans les modèles de base en est un exemple. En outre, les modèles fondamentaux présentent de fortes capacités de généralisation, ce qui leur permet de s'attaquer à des tâches plus complexes et plus diversifiées, alors que les systèmes d'IA traditionnels nécessitent généralement un réentraînement ou des modifications importantes pour les nouvelles tâches.
Les modèles de base présentent certaines caractéristiques particulières qui les rendent uniques :
La généralisation fait référence à la capacité d'un modèle à donner de bons résultats sur des tâches inédites ou, concrètement, sur des données au-delà de son ensemble d'apprentissage. Les modèles fondateurs sont particulièrement précieux en raison de cette propriété. Dans le même ordre d'idées, ces modèles peuvent également présenter des capacités inattendues, non planifiées lors de la formation, qui émergent à l'échelle, ce que l'on appelle lecomportement émergent .
Alors que la généralisation est un résultat attendu de la formation des modèles, les capacités émergentes sont souvent imprévisibles, car les modèles ne sont pas explicitement formés à ces fins.
En outre, ces modèles sont évolutifs, ce qui signifie que leurs performances peuvent être améliorées en augmentant la taille du modèle (ainsi que les données et les ressources informatiques). Bien que les modèles de grande taille tendent à mieux se généraliser, la taille du modèle ne garantit pas à elle seule une meilleure généralisation. Cependant, les comportements émergents sont fortement corrélés à la taille du modèle.
La multimodalité désigne la capacité d'un modèle d'IA à traiter et à intégrer plusieurs types de données, telles que du texte, des images, des vidéos, etc. Les modèles fondateurs peuvent être multimodaux, mais ce n'est pas une obligation.
L'un des aspects clés de la multimodalité est la compréhension multimodale, qui permet au modèle de comprendre et de relier des informations provenant de différents types de données. Par exemple, combiner du texte et des images pour générer des légendes d'images ou répondre à des questions sur un contenu visuel. La multimodalité permet des interactions plus riches et ouvre la voie à des applications où le texte, la vision et l'audio doivent fonctionner ensemble, comme dans la robotique ou les systèmes de soins de santé.
Pour une explication plus approfondie de la multimodalité, lisez notre article, Qu'est-ce que l'IA multimodale ?
Enfin, un autre aspect essentiel des modèles fondamentaux est , car ils peuvent servir de base à des modèles spécifiques à un domaine. Par conséquent, nous pouvons les adapter à des tâches ou domaines spécifiques en ajustant leurs poids sur la base d'un ensemble de données plus petit et spécifique à un domaine, tout en bénéficiant de leur multimodalité, de leurs capacités de généralisation et d'autres propriétés. Ce processus est connu sous le nom de "fine-tuning", que vous pouvez découvrir dans notre guide sur le réglage fin des LLM.
Voici quelques techniques de mise au point :
Les grands modèles de langage sont un type spécialisé de modèle fondamental formé exclusivement ou principalement sur des données textuelles. Un LLM peut être affiné pour des tâches spécifiques, telles que la traduction ou le résumé.
Le tableau suivant peut aider à mettre en évidence les différences et les similitudes entre les deux catégories de modèles :
|
Aspect |
Modèle de base |
Grand modèle linguistique |
|
Champ d'application |
Modèles à usage général qui sont généralement formés sur des données multimodales. |
Sous-ensemble de modèles fondamentaux formés exclusivement sur des données de test et parfois affinés pour une tâche spécifique. |
|
Données de formation |
Des ensembles de données diversifiés (et généralement multimodaux). |
Principalement des corpus de textes. |
|
Architecture* |
Architectures multiples : Transformateurs, réseaux neuronaux convolutifs (CNN) ou architectures hybrides en fonction du type de données. |
Architecture typiquement basée sur un transformateur. |
|
Cas d'utilisation |
Tâches générales multimodales. |
Axé sur les tâches linguistiques : traduction, résumé, chatbot, génération de code, etc. Cette pratique est aujourd'hui très répandue dans la société. Découvrez les modèles open-source les plus populaires dans notre guide. |
* Nous reviendrons plus en détail sur les architectures des modèles fondamentaux dans la section suivante.
Si nous pensons à un exemple plus pratique, le premier modèle GPT utilisé dans l'interface web de ChatGPT était le GPT-3. Il s'agissait d'un modèle de grand langage purement textuel, et les utilisateurs ne pouvaient interagir avec lui que par le biais d'invites. Étant donné que les LLM sont un sous-ensemble à l'intérieur des modèles fondateurs, le GPT-3 est également un modèle fondateur.
Aujourd'hui, lorsque nous entrons dans l'interface du ChatGPT, nous pouvons voir que nous pouvons joindre des images à côté de l'invite. En effet, le GPT-4 est le modèle qui se cache derrière l'interface. Le GPT-4 est au contraire un modèle fondamental multimodal.
Capture d'écran de l'interface multimodale du ChatGPT.
Étant donné que notre première interaction avec ces grands modèles s'est faite par le biais des LLM, les gens ont tendance à penser que l'architecture Transformer est la seule à être à l'origine des modèles fondateurs.
Cependant, réseaux neuronaux récurrents (RNN) étaient l'architecture privilégiée pour les modèles de base basés sur le texte avant que les transformateurs ne gagnent en popularité.
Dans le domaine de la génération d'images, les modèles de diffusion constituent désormais l'épine dorsale de ces systèmes de pointe. Parmi les modèles les plus connus, citons Stable Diffusion et DALL-E. réseaux neuronaux convolutifs (CNN) ont été utilisés avant eux !
Les modèles de diffusion sont considérés comme fondamentaux pour la génération d'images pour les mêmes raisons que celles évoquées précédemment : ils peuvent générer des images diversifiées de haute qualité et être affinés pour des tâches spécifiques telles que l'édition d'images ou l'inpainting.
Les modèles fondamentaux sont utilisés dans divers domaines en raison de leur polyvalence et de leur adaptabilité :
Comme nous l'avons vu précédemment, les modèles fondateurs ont apporté des améliorations remarquables au traitement du langage naturel. Les capacités semblables à celles des humains de modèles tels que ChatGPT ont rendu ces modèles indispensables dans lesapplications de service à la clientèle , par exemple. Tout agent conversationnel en ligne est désormais probablement basé sur le LLM, ce qui permet d'engager des conversations plus naturelles et cohérentes par rapport aux premiers chatbots qui s'appuyaient sur des systèmes basés sur des règles.
Ces modèles alimentent également des applications de traduction telles que Google Translate et DeepL. Si vous utilisez aujourd'hui ces outils, vous vous rendrez compte qu'ils sont devenus plus précis et mieux adaptés au contexte qu'il y a dix ans.
Si vous êtes intéressé par les applications en langage naturel, le cours "Développer des applications d'IA"vous donnera un coup de pouce !
Des modèles tels que CLIP et DALL-Epar exemple, combinent la compréhension du texte et de l'image, ce qui permet des applications telles que le le sous-titrage d'images et la la génération de texte à partir d'imagesqui n'étaient pas réalisables avec les architectures précédentes.
Parmi les outils, Adobe Photoshop a intégré des modèles de diffusion dans ses outils d'édition, comme dans l'outil Remplissage en fonction du contenu et d'autres fonctions pilotées par l'IA pour compléter et repeindre automatiquement les images.
Enfin, il existe également des applications multimodales qui peuvent traiter et intégrer simultanément des données provenant de plusieurs domaines. Par exemple, dans lessystèmes autonomes , Tesla et Waymo - le projet de véhicule autonome de Google - utilisent des systèmes multimodaux qui combinent des données visuelles provenant de caméras, de signaux radar et de capteurs LiDAR, avec des informations textuelles et contextuelles pour naviguer et comprendre l'environnement.
Ces applications inter-domaines transforment les industries, permettant des systèmes plus dynamiques, adaptables et intelligents qui étaient auparavant limités par des modèles plus étroits.
Après avoir vu ces applications, nous pouvons classer visuellement les modèles comme dans l'image ci-dessous :
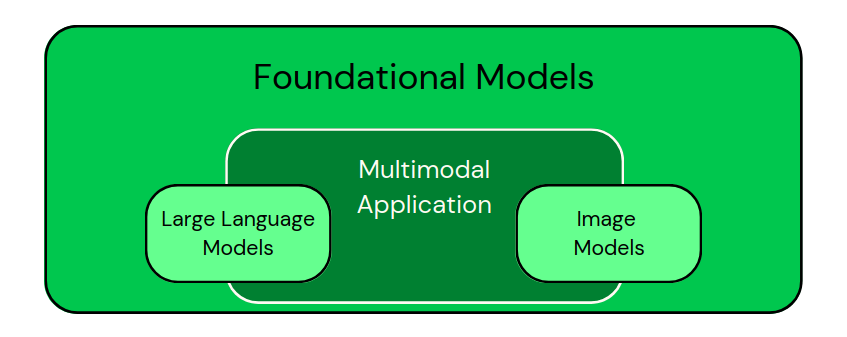
Classification des modèles spécifiques à un domaine en tant que sous-ensembles des modèles fondamentaux. Les applications multimodales combinent différents types de données. - Image par l'auteur
Si vous envisagez de créer des applications basées sur ces modèles, l'article "5 projets que vous pouvez réaliser avec des modèles d'IA générative" vous donnera d'excellentes idées.
Comme nous l'avons vu, les modèles fondateurs ont de plus grandes capacités, mais nous devons également être conscients qu'ils s'accompagnent de plusieurs défis et considérations éthiques :
La formation de ces modèles est très gourmande en ressources en termes de temps et d'énergie. Une fois formés, ces modèles nécessitent encore des ressources substantielles pour l'inférence, en particulier dans les applications en temps réel, ce qui les rend coûteux à exploiter à grande échelle. Au fur et à mesure que les modèles deviennent plus grands et plus complexes, la charge de calcul augmente également.
Le coût est un problème particulièrement difficile à résoudre pour les petits instituts de recherche et les petites entreprises, qui n'ont pas toujours les moyens financiers de former de grands modèles à partir de zéro, ce qui permet aux grandes entreprises de dominer la recherche dans ce domaine. À mon avis, la disponibilité de modèles libres pré-entraînés sera bénéfique pour les deux parties.
Étroitement lié au coût, l'impact sur l'environnement l'impact environnemental de ces types de modèles est une préoccupation croissante. La formation de grands modèles d'IA consomme une quantité substantielle d'énergie, contribuant ainsi à une empreinte carbone élevée.
L'utilisation croissante de l'IA et le pré-entraînement de modèles de plus en plus grands renforcent les préoccupations en matière de durabilité. Des efforts sont faits pour réduire la consommation d'énergie grâce à des algorithmes et du matériel plus efficaces, ainsi qu'à l'adoption de sources d'énergie renouvelables dans les centres de données, mais le problème reste critique.
Les modèles fondateurs ne sont pas exempts de risques de biais. Comme pour de nombreux algorithmes d'apprentissage profond, ce risque découle des vastes quantités de données du monde réel sur lesquelles ils sont entraînés. Les modèles héritent inévitablement des biais présents dans les données, ce qui peut conduire à des résultats injustes ou à des discriminations dans des applications sensibles..
L'atténuation des préjugés est essentielle et peut être réalisée grâce à des stratégies telles que la mise en œuvre d'algorithmes d'équité, la diversification des ensembles de données d'entraînement et l'audit régulier des modèles pour s'assurer qu'ils ne perpétuent pas de préjugés nuisibles.
Enfin, les préoccupations réglementaires concernant l'utilisation des modèles de base sont de plus en plus prononcées. À mesure que ces modèles deviennent plus puissants et sont déployés dans diverses industries, les gouvernements et les organismes internationaux s'efforcent d'établir des cadres pour la sécurité et la responsabilité de l'IA.
Le respect des normes mondiales, telles que la loi sur l'IA de l'UE, sera essentiel pour gérer les risques associés au déploiement de l'IA, y compris les problèmes de protection de la vie privée et de désinformation. Vous pouvez vous mettre au diapason de ces réglementations grâce au parcours de compétences de DataCamp. Le cursus des fondamentaux de la loi sur l'IA de l'UE.
L'une des tendances les plus marquées dans les modèles fondamentaux est l'évolution des capacités multimodales. Ces modèles sont de plus en plus conçus pour traiter et intégrer divers types de données dans un cadre unifié.
Cette approche multimodale permet aux systèmes d'IA de mieux comprendre le monde et d'interagir avec lui, certains affirmant même qu'ils le font d'une manière qui reflète la cognition humaine. Au fur et à mesure que ces capacités se développeront, je suis sûr qu'elles permettront de créer des applications plus complètes.
Une autre tendance intéressante est la perspective d'une adaptabilité en temps réel. Les modèles fondamentaux actuels nécessitent une formation préalable approfondie et un réglage fin pour s'adapter à des tâches spécifiques. Toutefois, les modèles futurs devraient devenir plus dynamiques, capables d'apprendre et de s'adapter en temps réel à mesure qu'ils rencontrent de nouvelles données ou de nouveaux environnements.
Cette possibilité permettra aux systèmes d'IA de répondre plus efficacement aux conditions changeantes, telles que l'évolution des préférences des utilisateurs ou les tendances émergentes dans les données.
Enfin, les innovations visant à rendre les modèles plus légers et plus accessibles sont également nécessaires pour réduire la consommation d'énergie et les coûts, et pour démocratiser l'utilisation des technologies fondamentales de l'IA.
Les recherches en cours visent à réduire la taille et les besoins en ressources de ces modèles sans compromettre leurs performances. Des techniques telles que la distillation de modèles, la quantification et la conception d'architectures efficaces sont explorées pour créer des modèles plus petits, plus rapides et plus économes en énergie.
En outre, les modèles légers permettront un déploiement sur des appareils périphériques, tels que les smartphones et les appareils IoT, ce qui rapprochera les capacités d'IA des utilisateurs finaux dans les applications du monde réel.
Je voudrais m'assurer qu'à ce stade, nous pouvons aborder la question posée dans l'introduction : "Qu'est-ce qui rend un modèle fondamental fondamental?
Un modèle est fondamental lorsqu'il est polyvalent, capable de se généraliser à diverses tâches et qu'il peut être spécialisé pour différentes tâches plus restreintes. Les modèles fondamentaux permettent de développer des modèles spécifiques à une tâche et servent de base à l'affinement dans différents domaines. Cependant, leur pouvoir s'accompagne de défis, notamment de préjugés et de problèmes éthiques, et de nouvelles tendances à explorer.
Si vous êtes intéressé par d'autres contenus de ce type, pensez à consulter le site de DataCamp. Fondamentaux de l'IA de DataCamp, qui couvre la plupart des éléments essentiels nécessaires pour travailler avec des modèles d'IA.
Les meilleurs cours de DataCamp
Cursus
Cours
Cours