
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
Se eu tivesse que descrever a nova era da IA em uma palavra, ela seria escala. Desde que a OpenAI lançou a interface baseada na Web para o GPT-3, conhecida como ChatGPT, em novembro de 2022, a popularidade dos modelos de linguagem grande cresceu significativamente devido ao seu uso generalizado pelo público em geral.
O termo escala aplica-se não apenas à popularidade desses modelos, mas também ao fato de que você pode usar o termo à grande quantidade de dados em que são treinados, ao alto número de parâmetros e à variedade de tarefas que que eles podem executar.
Do meu ponto de vista, o boom desses tipos de modelos inicialmente colocou a Modelos de idiomas grandes (LLMs) no centro. Dois anos depois, devido aos avanços nesse campo, acredito que o termo popular tenha mudado para modelos fundamentais.
Mas o que são modelos fundamentais? E O que torna um modelo fundamental?
Ao contrário dos LLMs, os modelos fundamentais estão presentes na comunidade há muito tempo. Neste artigo, exploraremos o conceito dosmodelos fundamentais do , com foco em suas principais características, aplicações e futuro na era da IA.
Considere uma arquitetura de IA, como um transformadore treine-a com grandes quantidades de dados diversos: texto do Common Crawl e de livros, imagens, vídeos do YouTube e muito mais.
Como esses dados são amplos, gerais e multimodais, o modelo resultante se torna um sistema grande e de uso geral com amplo conhecimento. Este é ummodelo básico do : um modelo versátil e de uso geral que serve como "base" para a criação de aplicativos de IA especializados.
Esses modelos básicos podem ser adaptados a tarefas específicas por meio de ajustes finos, estímulos ou outras técnicas de aprendizagem por transferência. A ideia é que, uma vez especializado em um domínio específico, o modelo manterá as fortes propriedades de generalização e os recursos emergentes do modelo de base.
Os primeiros sistemas de IA eram, em sua maioria, baseados em regras e muito específicos de um domínio, exigindo, portanto, uma programação específica para cada tarefa. O início dos anos 2000 foi marcado pelo surgimento do aprendizado de máquina como uma mudança em direção a abordagens orientadas por dados, embora ainda estivesse limitado a tarefas específicas.
O avanço da aprendizagem profunda ocorreu por volta de 2012, permitindo o reconhecimento de padrões mais complexos e modelos generativos avançados, com dois marcos importantes: redes adversárias generativas em 2014 e transformadores em 2017.
O crescimento da IA tem sido muito apoiado pelos avanços na capacidade de computação (por exemplo, GPUs, TPUs, etc.), GPUs, TPUs) e a disponibilidade de conjuntos de dados maciços, que permitiram o treinamento de modelos cada vez maiores, levando ao surgimento de modelos fundamentais.
A diferença entre os sistemas de IA tradicionais e os modelos fundamentais também é definida por sua escala. A mudança do treinamento em conjuntos de dados selecionados em sistemas de IA tradicionais para o uso de dados maciços, diversificados e, muitas vezes, não estruturados em modelos básicos é um exemplo. Além disso, os modelos básicos apresentam recursos sólidos de generalização, o que lhes permite lidar com tarefas mais complexas e diversificadas, enquanto os sistemas tradicionais de IA geralmente exigem retreinamento ou modificações extensas para novas tarefas.
Há algumas características especiais que tornam os Modelos Fundamentais únicos:
A generalização refere-se à capacidade de um modelo de apresentar bom desempenho em tarefas não vistas ou, concretamente, em dados além do conjunto de treinamento. Os modelos básicos são particularmente valiosos devido a essa propriedade. Intimamente relacionado a isso, esses modelos também podem apresentar habilidades inesperadas, não planejadas no treinamento, que surgem em escala, conhecidas como comportamento emergente.
Embora a generalização seja um resultado esperado do treinamento de modelos, os recursos emergentes geralmente são imprevisíveis, pois os modelos não são treinados explicitamente para esses fins.
Além disso, esses modelos são escalonáveis, o que significa que seu desempenho pode ser aprimorado com o aumento do tamanho do modelo (juntamente com os dados e os recursos computacionais). Embora modelos maiores tendam a generalizar melhor,o tamanho do modelo por si só não garante uma generalização aprimorada. No entanto, os comportamentos emergentes estão fortemente correlacionados com o tamanho do modelo.
A multimodalidade refere-se à capacidade de um modelo de IA de processar e integrar vários tipos de dados, como texto, imagens, vídeo e outros. Embora os modelos básicos possam ser multimodais, isso não é um requisito.
Um dos principais aspectos da multimodalidade é a compreensão multimodal, em que o modelo pode compreender e conectar informações em diferentes tipos de dados. Por exemplo, combinando texto e imagens para gerar legendas para fotos ou responder a perguntas sobre conteúdo visual. A multimodalidade permite interações mais ricas e abre as portas para aplicativos em que texto, visão e áudio precisam trabalhar juntos, como em sistemas de robótica ou de saúde.
Para obter uma explicação mais detalhada sobre multimodalidade, considere ler nosso artigo, O que é IA multimodal?
Por fim, outro aspecto importante dos modelos fundamentais é que eles podem servir de base para modelos específicos de domínio. Portanto, podemos adaptá-los a tarefas ou domínios específicos ajustando seus pesos com base em um conjunto de dados menor e específico do domínio e, ao mesmo tempo, nos beneficiando de sua multimodalidade, recursos de generalização e outras propriedades. Esse processo é conhecido como ajuste fino, sobre o qual você pode saber mais em nosso guia para ajuste fino de LLMs.
Algumas técnicas de ajuste fino incluem:
Os modelos de linguagem grande são um tipo especializado de modelo básico treinado exclusiva ou predominantemente em dados de texto. Um LLM pode ser ajustado ainda mais para tarefas específicas, como tradução ou resumo de idiomas.
A tabela a seguir pode ajudar a destacar as diferenças e semelhanças entre as duas categorias de modelos:
|
Aspecto |
Modelo básico |
Modelo de idioma grande |
|
Escopo |
Modelos de uso geral que geralmente são treinados em dados multimodais. |
Subconjunto de modelos básicos treinados exclusivamente em dados de teste e, às vezes, ajustados para uma tarefa específica. |
|
Dados de treinamento |
Conjuntos de dados diversos (e geralmente multimodais). |
Principalmente corpora de texto. |
|
Arquitetura* |
Várias arquiteturas: Transformadores, redes neurais convolucionais (CNNs) ou arquiteturas híbridas, dependendo do tipo de dados. |
Normalmente, a arquitetura é baseada em transformadores. |
|
Casos de uso |
Tarefas gerais multimodais. |
Focado em tarefas linguísticas: tradução, resumo, chatbot, geração de código, etc. Popular em toda a sociedade atualmente. Encontre os modelos de código aberto mais populares em nosso guia. |
* Na próxima seção, falaremos um pouco mais sobre as arquiteturas dos modelos básicos.
Se você pensar em um exemplo mais prático, o primeiro modelo de GPT usado na interface da Web do ChatGPT foi o GPT-3. Tratava-se de um modelo de linguagem grande puramente textual, e os usuários só podiam interagir com ele por meio de avisos. Como os LLMs são um subconjunto dos modelos básicos, o GPT-3 também foi um modelo básico.
Atualmente, quando entramos na interface do ChatGPT, podemos ver que podemos anexar imagens ao lado do prompt. Isso ocorre porque o GPT-4 é o modelo por trás da interface agora. Em vez disso, o GPT-4 é um modelo de base multimodal.
Captura de tela da interface multimodal do ChatGPT.
Como nossa primeira interação com esses modelos grandes foi por meio de LLMs, as pessoas tendem a pensar que a arquitetura do Transformer é a única por trás dos modelos fundamentais.
No entanto, Redes Neurais Recorrentes (RNNs) eram a arquitetura de referência para modelos básicos baseados em texto antes de os Transformers ganharem popularidade.
No domínio da geração de imagens, os modelos de difusão são agora a espinha dorsal desses sistemas de última geração. Alguns modelos conhecidos incluem o Stable Diffusion e o DALL-E, mas Redes Neurais Convolucionais (CNNs) foram usadas antes deles!
Os modelos de difusão são considerados fundamentais para a geração de imagens pelos mesmos motivos discutidos anteriormente: eles podem gerar imagens diversas e de alta qualidade e ser ajustados para tarefas específicas, como edição ou pintura de imagens.
Os modelos fundamentais são usados em vários domínios devido à sua versatilidade e adaptabilidade, alguns deles incluem:
Conforme discutido anteriormente, os modelos fundamentais proporcionaram melhorias notáveis no processamento de linguagem natural. Os recursos semelhantes aos humanos de modelos como o ChatGPT tornaram esses modelos indispensáveis nosaplicativos de atendimento ao cliente do site , por exemplo,. Qualquer agente de conversação on-line agora provavelmente é todo baseado em LLM, que pode se envolver em conversas mais naturais e coerentes em comparação com os chatbots anteriores que dependiam de sistemas baseados em regras.
Esses modelos também alimentam aplicativos de tradução de idiomas , como o Google Translate e oDeepL. Se você usar essas ferramentas agora, perceberá que elas se tornaram mais precisas e contextualmente conscientes do que há dez anos.
Se você estiver interessado em aplicativos de linguagem natural, o curso "Desenvolvimento de aplicativos de IA" dará a você um impulso!
Modelos como CLIP e DALL-Epor exemplo, combinam a compreensão de texto e imagem, permitindo aplicativos como legendagem de imagens e geração de texto para imagemque não eram viáveis com arquiteturas anteriores.
Entre as ferramentas, o Adobe Photoshop incorporou modelos de difusão em suas ferramentas de edição, como no Preenchimento sensível ao conteúdo e outros recursos orientados por IA para preenchimento automático de imagens e pintura.
Por fim, há também aplicativos multimodais que podem processar e integrar dados de vários domínios simultaneamente. Por exemplo, em sistemas autônomos, o Tesla eo Waymo - o projeto de veículo autônomo do Google - usam sistemas multimodais que combinam dados visuais de câmeras, sinais de radar e sensores LiDAR com informações textuais e contextuais para navegar e entender o ambiente.
Esses aplicativos entre domínios estão transformando os setores, permitindo sistemas mais dinâmicos, adaptáveis e inteligentes que antes eram limitados por modelos mais restritos.
Depois de ver esses aplicativos, podemos classificar visualmente os modelos como na imagem abaixo:
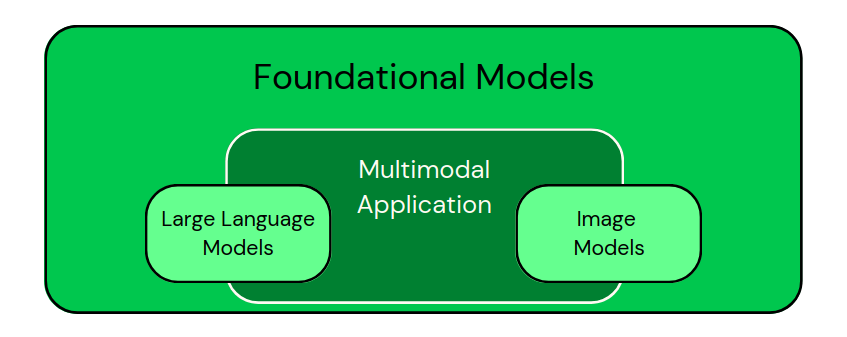
Classificação de modelos específicos de domínio como subconjuntos de modelos fundamentais. Os aplicativos multimodais combinam diferentes tipos de dados. - Imagem do autor
Se você está pensando em criar aplicativos alimentados por esses modelos, o artigo "5 projetos que você pode criar com modelos de IA generativa" dará a você algumas ótimas ideias.
Como vimos, os modelos básicos têm mais recursos, mas também devemos estar cientes de que eles apresentam vários desafios e considerações éticas:
O treinamento desses modelos consome muitos recursos em termos de tempo e energia. Depois de treinados, esses modelos ainda exigem recursos substanciais para a inferência, principalmente em aplicativos em tempo real, o que os torna caros para operar em escala. À medida que os modelos ficam maiores e mais complexos, a carga computacional também aumenta.
O custo é algo particularmente desafiador para instituições de pesquisa e empresas menores, que podem não ter os meios financeiros para treinar grandes modelos do zero, permitindo que as grandes empresas dominem a pesquisa nesse campo. Na minha opinião, a disponibilidade de modelos de código aberto pré-treinados ajudará nos dois sentidos.
Intimamente relacionado ao custo, o impacto ambiental desses tipos de modelos é uma preocupação crescente. O treinamento de grandes modelos de IA consome uma quantidade substancial de energia, contribuindo para uma alta pegada de carbono.
O uso crescente da IA e o pré-treinamento de modelos cada vez maiores intensificam as preocupações com a sustentabilidade. Estão sendo feitos esforços para reduzir o consumo de energia por meio de algoritmos e hardware mais eficientes, bem como a adoção de fontes de energia renováveis nos data centers, mas a questão continua crítica.
Os modelos básicos não estão isentos do risco de viés. Como acontece com muitos algoritmos de aprendizagem profunda, esse risco decorre das grandes quantidades de dados do mundo real em que eles são treinados. Os modelos inevitavelmente herdam vieses presentes nos dados, o que pode levar a resultados injustos ou discriminação em aplicativos sensíveis.
A atenuação de vieses é essencial e pode ser obtida por meio de estratégias como a implementação de algoritmos justos, a diversificação de conjuntos de dados de treinamento e a auditoria regular de modelos para garantir que eles não perpetuem vieses prejudiciais.
Por fim, as preocupações regulatórias relacionadas ao uso de modelos básicos estão se tornando mais pronunciadas. À medida que esses modelos se tornam mais poderosos e são implantados em vários setores, os governos e os órgãos internacionais estão trabalhando para estabelecer estruturas para a segurança e a responsabilidade da IA.
Garantir a conformidade com padrões globais, como a Lei de IA da UE, será fundamental para gerenciar os riscos associados à implantação da IA, incluindo problemas de privacidade e desinformação. Você pode se atualizar sobre essas regulamentações com o curso de habilidades do DataCamp Fundamentos da Lei de IA da UE.
Uma das tendências mais proeminentes nos modelos básicos é a evolução dos recursos multimodais. Esses modelos estão sendo cada vez mais projetados para processar e integrar diversos tipos de dados em uma estrutura unificada.
Essa abordagem multimodal permite que os sistemas de IA compreendam e interajam melhor com o mundo, e alguns afirmam que eles até mesmo fazem isso de uma forma que espelha a cognição humana. À medida que esses recursos forem amadurecendo, tenho certeza de que eles permitirão aplicativos mais completos.
Outra tendência interessante é a perspectiva de adaptabilidade em tempo real. Os modelos básicos atuais exigem um extenso pré-treinamento e um ajuste fino para se adaptarem a tarefas específicas. No entanto, espera-se que os modelos futuros se tornem mais dinâmicos, capazes de aprender e se adaptar em tempo real à medida que encontrarem novos dados ou ambientes.
Essa possibilidade permitirá que os sistemas de IA respondam com mais eficiência às condições variáveis, como a evolução das preferências do usuário ou as tendências emergentes nos dados.
Finalmente, inovações para tornar os modelos mais leves e acessíveis também é um requisito para diminuir o consumo de energia e o custo e para democratizar o uso de tecnologias fundamentais de IA.
A pesquisa em andamento visa reduzir o tamanho e a demanda de recursos desses modelos sem comprometer seu desempenho. Técnicas como destilação de modelos, quantização e design de arquitetura eficiente estão sendo exploradas para criar modelos menores, mais rápidos e mais eficientes em termos de energia.
Além disso, os modelos leves permitirão a implantação em dispositivos de ponta, como smartphones e dispositivos de IoT, aproximando os recursos de IA dos usuários finais em aplicativos do mundo real.
Gostaria de me certificar de que, neste ponto, podemos abordar a pergunta feita na introdução: "O que torna um modelo fundamental fundamental?".
Um modelo é fundamental quando é de uso geral, capaz de generalizar em diversas tarefas e pode ser especializado para diferentes tarefas mais restritas. Os modelos básicos permitem o desenvolvimento de modelos específicos de tarefas que servem como base para o ajuste fino em vários domínios. No entanto, seu poder vem acompanhado de desafios, incluindo preconceitos e preocupações éticas, e algumas novas tendências futuras a serem exploradas.
Se você estiver interessado em mais conteúdo como este, considere conferir o curso do DataCamp Fundamentos de IA do DataCamp, que abrange muitos dos fundamentos necessários para você trabalhar com modelos de IA.
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Javier Canales Luna
9 min
blog
Yuliya Melnik
15 min
blog
Matt Crabtree
15 min
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer

