
Track
Developing Large Language Models
16 hr
If I had to describe the new AI era in one word, it would be scale. Since OpenAI released the web-based interface for GPT-3, known as ChatGPT, in November 2022, the popularity of Large Language Models has grown significantly due to their widespread use by the general public.
The term scale applies not only to the popularity of these models but also to the vast amounts of data they are trained on, their high number of parameters, and the diverse range of tasks they can perform.
From my perspective, the boom of these types of models initially put Large Language Models (LLMs) at the center. Two years later, due to advancements in this field, I believe the popular term has shifted to foundational models instead.
But what are foundational models? And what makes a model foundational?
Contrary to LLMs, foundational models have been around in the community for ages. In this article, we will explore the concept of foundational models, focusing on their key characteristics, applications, and future in the AI era.
Take an AI architecture, such as a transformer, and train it on vast amounts of diverse data: text from Common Crawl and books, images, YouTube videos, and more.
Since this data is broad, general, and multimodal, the resulting model becomes a large, general-purpose system with extensive knowledge. This is a foundational model: a versatile, general-purpose model that serves as a “foundation” for building specialized AI applications.
These foundation models can be adapted to specific tasks through fine-tuning, prompting, or other transfer learning techniques. The idea is that once specialized in a specific domain, the model will retain the strong generalization properties and emergent capabilities of the base model.
Early AI systems were mostly rule-based and very domain-specific, thus requiring task-specific programming. The early 2000s were marked by the emergence of machine learning as a shift toward data-driven approaches, though it was still limited to specific tasks.
The breakthrough of deep learning came around 2012, enabling more complex pattern recognition and advanced generative models, with two major milestones: generative adversarial networks in 2014 and transformers in 2017.
AI growth has been greatly supported by advances in computational power (e.g., GPUs, TPUs) and the availability of massive datasets, which have enabled the training of increasingly larger models, leading to the emergence of foundational models.
The difference between traditional AI systems and foundational models is also defined by their scale. The shift from training on curated datasets in traditional AI systems, to using massive, diverse, and often unstructured data in foundational models is an example. Additionally, foundational models exhibit strong generalization capabilities, enabling them to tackle more complex and diverse tasks, whereas traditional AI systems typically require retraining or extensive modifications for new tasks.
There are some special characteristics that make Foundational Models unique:
Generalization refers to a model’s ability to perform well on unseen tasks or, concretely, on data beyond its training set. Foundational models are particularly valuable because of this property. Closely related to this, these models can also exhibit unexpected abilities, not planned at training, that emerge at scale, known as emergent behavior.
While generalization is an expected outcome of model training, emergent capabilities are often unpredictable, as models are not explicitly trained for those purposes.
Additionally, these models are scalable, meaning their performance can be improved by increasing model size (along with data and computational resources). While larger models tend to generalize better, model size alone does not guarantee improved generalization. However, emergent behaviours are strongly correlated with model size.
Multimodality refers to the ability of an AI model to process and integrate multiple types of data, such as text, images, video, and more. While Foundational Models can be multimodal, this is not a requirement.
One of the key aspects of multimodality is cross-modal understanding, where the model can comprehend and connect information across different types of data. For example, combining text and images to generate captions for pictures or answer questions about visual content. Multimodality enables richer interactions and opens the door to applications where text, vision, and audio must work together, such as in robotics or healthcare systems.
For a more in-depth explanation of Multimodality, consider reading our article, What is Multimodal AI?
Finally, another key aspect of foundational models is that they can serve as the base for domain-specific models. Therefore, we can adapt them to specific tasks or domains by adjusting their weights based on a smaller, domain-specific dataset, while benefiting from their multimodality, generalization capabilities, and other properties. This process is known as fine-tuning, which you can learn more about in our guide to fine-tuning LLMs.
Some fine-tuning techniques include:
Large language models are a specialized type of foundational model trained exclusively or predominantly on text data. An LLM can be further fine-tuned for specific tasks, such as language translation or summarization.
The following table might help highlight the differences and similarities between both model categories:
|
Aspect |
Foundational Model |
Large Language Model |
|
Scope |
General-purpose models that are generally trained on multimodal data. |
Subset of Foundational Models trained exclusively on test data, and sometimes fine-tuned for a specific task. |
|
Training Data |
Diverse (and generally multimodal) datasets. |
Primarily text corpora. |
|
Architecture* |
Multiple architectures: Transformers, Convolutional Neural Networks (CNNs), or hybrid architectures depending on the data type. |
Typically Transformer-based architecture. |
|
Use-cases |
Multimodal general tasks. |
Focused on language tasks: translation, summarization, chatbot, code generation, etc. Popular across society nowadays. Find the most popular open-source models in our guide. |
* We will elaborate a bit more on the architectures for Foundational Models in the next section.
If we think of a more practical example, the first GPT model used in the ChatGPT web interface was GPT-3. It was a purely textual large language model, and users could only interact with it via prompting. Since LLMs are a subset inside foundational models, GPT-3 was also a foundational model.
Nowadays, when we enter the ChatGPT interface, we can see that we can attach images alongside the prompt. This is because GPT-4 is the model behind the interface now. GPT-4 is instead a multimodal foundational model.
Screenshot of the multimodal interface of ChatGPT.
Since our first interaction with those large models was through LLMs, people tend to think that the Transformer architecture is the only one behind foundational models.
However, Recurrent Neural Networks (RNNs) were the go-to architecture for text-based Foundational Models before Transformers gained popularity.
In the domain of image generation, diffusion models are now the backbone of these state-of-the-art systems. Some well-known models include Stable Diffusion and DALL-E, but Convolutional Neural Networks (CNNs) were used before them!
Diffusion models are considered foundational for image generation for the same reasons discussed earlier: they can generate high-quality, diverse images and be fine-tuned for specific tasks such as image editing or inpainting.
Foundational Models are used in various domains due to their versatility and adaptability, some of them include:
As discussed before, Foundational Models have made remarkable improvements in Natural Language Processing. The human-like capabilities of models like ChatGPT have made those models indispensable in customer service applications, for example. Any online conversational agent is now likely all LLM-based, which can engage in more natural, coherent conversations compared to earlier chatbots that relied on rule-based systems.
These models also power applications in language translation such as Google Translate and DeepL. If you now use these tools you will realize that they have become more accurate and contextually aware than ten years ago.
If you are interested in natural language applications, the course “Developing AI Applications” will give you a boost!
Models such as CLIP and DALL-E, for example, combine text and image understanding, enabling applications like image captioning and text-to-image generation, which were not feasible with previous architectures.
Among the tools, Adobe Photoshop has incorporated diffusion models into its editing tools, such as in Content-Aware Fill and other AI-driven features for automatic image completion and inpainting.
Finally, there are also multimodal applications that can process and integrate data from multiple domains simultaneously. For example, in autonomous systems, Tesla and Waymo - Google’s autonomous vehicle project - use multimodal systems that combine visual data from cameras, radar signals, and LiDAR sensors, with textual and contextual information to navigate and understand the environment.
These cross-domain applications are transforming industries, enabling more dynamic, adaptable, and intelligent systems that were previously limited by narrower models.
After seeing those applications, we can visually classify the models as in the image below:
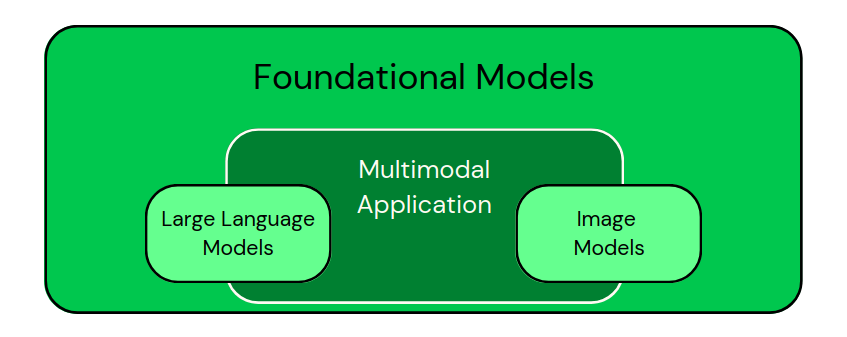
Classification of domain-specific models as subsets of Foundational Models. Multimodal applications combine different types of data. - Image by Author
If you are considering building applications powered by these models, the article “5 Projects You Can Build with Generative AI Models” will give you some great ideas.
As we have seen, foundational models have greater capabilities, but we should also be aware that they come with several challenges and ethical considerations:
Training these models is highly resource-intensive in terms of time and energy. Once trained, these models still demand substantial resources for inference, particularly in real-time applications, making them expensive to operate at scale. As the models grow larger and more complex, the computational burden also increases.
The cost is something particularly challenging for smaller research institutions and companies, which may lack the financial means to train large models from scratch, allowing big companies to dominate research in this field. In my opinion, the availability of pre-trained open-source models will help both ways.
Closely related to the cost, the environmental impact of these types of models is a growing concern. Training large AI models consumes a substantial amount of energy, contributing to a high carbon footprint.
The increasing use of AI and the pre-training of bigger and bigger models intensifies concerns about sustainability. Efforts are being made to reduce energy consumption through more efficient algorithms and hardware, as well as the adoption of renewable energy sources in data centers, but the issue remains critical.
Foundational models are not exempt from the risk of bias. As with many deep learning algorithms, this risk arises from the vast amounts of real-world data they are trained on. Models inevitably inherit biases present in the data, which can lead to unfair outcomes or discrimination in sensitive applications.
Mitigating bias is essential and can be achieved through strategies such as implementing fairness algorithms, diversifying training datasets, and regularly auditing models to ensure they do not perpetuate harmful biases.
Finally, regulatory concerns surrounding the use of foundational models are becoming more pronounced. As these models grow more powerful and are deployed across various industries, governments, and international bodies are working to establish frameworks for AI safety and accountability.
Ensuring compliance with global standards, such as the EU’s AI Act, will be crucial for managing risks associated with AI deployment, including privacy issues and misinformation. You can get up to speed with such regulations with DataCamp’s EU AI Act Fundamentals skill track.
One of the most prominent trends in foundational models is the evolution of multimodal capabilities. These models are increasingly being designed to process and integrate diverse types of data into a unified framework.
This multimodal approach allows AI systems to better understand and interact with the world, some claiming that they even do it in a way that mirrors human cognition. As these capabilities mature, I am sure they will enable more complete applications.
Another exciting trend is the prospect of real-time adaptability. Current foundational models require extensive pre-training and fine-tuning to adapt to specific tasks. However, future models are expected to become more dynamic, capable of learning and adapting in real-time as they encounter new data or environments.
This possibility will enable AI systems to respond more effectively to changing conditions, such as evolving user preferences or emerging trends in data.
Finally, innovations in making models more lightweight and accessible is also a requirement to both diminish energy consumption, cost, and to democratize the use of foundational AI technologies.
Ongoing research aims to reduce the size and resource demands of these models without compromising their performance. Techniques such as model distillation, quantization, and efficient architecture design are being explored to create smaller, faster, and more energy-efficient models.
Additionally, lightweight models will enable deployment on edge devices, such as smartphones and IoT devices, bringing AI capabilities closer to end-users in real-world applications.
I would like to make sure that, at this point, we can tackle the question posed in the introduction: “What makes a foundational model foundational?”.
A model is foundational when it is general-purpose, capable of generalizing across diverse tasks and can be specialized for different narrower tasks. Foundational models enable the development of task-specific models serving as a base for fine-tuning in various domains. However, their power comes with challenges, including bias and ethical concerns, and some new future trends to explore.
If you are interested in more content like this, consider checking out DataCamp’s AI Fundamentals skill track, which covers many of the essentials needed to work with AI models.
Top DataCamp Courses
Track
Course
Course
blog
Javier Canales Luna
9 min
blog
Javier Canales Luna
12 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Abid Ali Awan
8 min
blog
Bhavishya Pandit
8 min
code-along
Richie Cotton


