
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
Wenn ich die neue KI-Ära mit einem Wort beschreiben müsste, wäre es scale. Seit OpenAI im November 2022 die webbasierte Schnittstelle für GPT-3, bekannt als ChatGPT, veröffentlicht hat, ist die Popularität von Large Language Models aufgrund ihrer weit verbreiteten Nutzung durch die Allgemeinheit deutlich gestiegen.
Der Begriff Maßstab bezieht sich nicht nur auf die Popularität dieser Modelle, sondern auch auf die riesigen Datenmengen, auf denen sie trainiert werden, ihre hohe Anzahl an Parametern und die vielfältigen Aufgaben die sie ausführen können.
Aus meiner Sicht hat der Boom dieser Art von Modellen zunächst Große Sprachmodelle (LLMs) in den Mittelpunkt. Zwei Jahre später, aufgrund der Fortschritte in diesem Bereich, hat sich der populäre Begriff meiner Meinung nach zu Gründungsmodelle verlagert.
Aber was sind Grundmodelle? Und Was macht ein Modell grundlegend?
Im Gegensatz zu den LLMs gibt es die Gründungsmodelle schon seit Ewigkeiten in der Gemeinschaft. In diesem Artikel erkunden wir das Konzept von grundlegenden Modellen und konzentrieren uns dabei auf ihre wichtigsten Merkmale, Anwendungen und ihre Zukunft in der KI-Ära.
Nehmen wir eine KI-Architektur, wie zum Beispiel einen Transformerund trainiere sie mit riesigen Mengen unterschiedlicher Daten: Texte aus Common Crawl und Büchern, Bilder, YouTube-Videos und mehr.
Da diese Daten breit gefächert, allgemein und multimodal sind, wird das daraus resultierende Modell zu einem großen, universellen System mit umfangreichem Wissen. Dies ist ein Basismodell: ein vielseitiges, universell einsetzbares Modell, das als "Grundlage" für den Aufbau spezialisierter KI-Anwendungen dient.
Diese Basismodelle können durch Feinabstimmung, Prompting oder andere Transfer-Lerntechniken an bestimmte Aufgaben angepasst werden. Die Idee ist, dass das Modell, sobald es auf einen bestimmten Bereich spezialisiert ist, die starken Verallgemeinerungseigenschaften und emergenten Fähigkeiten des Basismodells beibehält.
Frühe KI-Systeme waren meist regelbasiert und sehr domänenspezifisch, sodass eine aufgabenspezifische Programmierung erforderlich war. Die frühen 2000er Jahre waren geprägt vom Aufkommen des maschinellen Lernens als eine Entwicklung hin zu datengesteuerten Ansätzen, die allerdings noch auf bestimmte Aufgaben beschränkt war.
Der Durchbruch des Deep Learning kam um 2012 und ermöglichte eine komplexere Mustererkennung und fortschrittliche generative Modelle, mit zwei wichtigen Meilensteinen: Generative adversarische Netzwerke im Jahr 2014 und Transformatoren im Jahr 2017.
Das Wachstum der KI wurde durch Fortschritte bei der Rechenleistung (z. B. GPUs, TPUs) stark gefördert, GPUs, TPUs) und die Verfügbarkeit riesiger Datensätze, die das Training immer größerer Modelle ermöglicht haben, was zur Entstehung von grundlegenden Modellen.
Der Unterschied zwischen traditionellen KI-Systemen und Gründungsmodellen wird auch durch ihren Maßstabdefiniert. Ein Beispiel dafür ist der Wechsel vom Training auf kuratierten Datensätzen in traditionellen KI-Systemen zur Verwendung großer, vielfältiger und oft unstrukturierter Daten in grundlegenden Modellen. Darüber hinaus weisen grundlegende Modelle starke Generalisierungsfähigkeiten auf, die es ihnen ermöglichen, komplexere und vielfältigere Aufgaben zu bewältigen, während herkömmliche KI-Systeme für neue Aufgaben in der Regel neu trainiert oder umfangreich modifiziert werden müssen.
Es gibt einige besondere Merkmale, die das Gründungsmodell einzigartig machen:
Die Generalisierung bezieht sich auf die Fähigkeit eines Modells, auch bei unbekannten Aufgaben oder konkret bei Daten, die über die Trainingsmenge hinausgehen, gute Ergebnisse zu erzielen. Grundlegende Modelle sind aufgrund dieser Eigenschaft besonders wertvoll. In engem Zusammenhang damit können diese Modelle auch unerwartete Fähigkeiten zeigen, die bei der Ausbildung nicht geplant waren und sich erst im Laufe der Zeit herauskristallisieren, was als emergentes Verhalten bezeichnet wird.
Während die Verallgemeinerung ein erwartetes Ergebnis des Modelltrainings ist, sind neu entstehende Fähigkeiten oft unvorhersehbar, da die Modelle nicht explizit für diese Zwecke trainiert werden.
Außerdem sind diese Modelle skalierbar, d.h. ihre Leistung kann durch eine Erhöhung der Modellgröße (zusammen mit den Daten und Rechenressourcen) verbessert werden. Auch wenn größere Modelle in der Regel besser verallgemeinern,garantiert die Modellgröße allein noch keine bessere Verallgemeinerung. Das entstehende Verhalten ist jedoch stark von der Modellgröße abhängig.
Multimodalität bezieht sich auf die Fähigkeit eines KI-Modells, verschiedene Arten von Daten zu verarbeiten und zu integrieren, z. B. Text, Bilder, Videos und mehr. Grundlegende Modelle können zwar multimodal sein, aber das ist keine Voraussetzung.
Einer der Schlüsselaspekte der Multimodalität ist das cross-modale Verständnis, bei dem das Modell Informationen über verschiedene Datentypen hinweg verstehen und verbinden kann. Kombiniere zum Beispiel Text und Bilder, um Bildunterschriften zu erstellen oder Fragen zu visuellen Inhalten zu beantworten. Multimodalität ermöglicht reichhaltigere Interaktionen und öffnet die Tür zu Anwendungen, bei denen Text, Bild und Ton zusammenarbeiten müssen, z. B. in der Robotik oder in Gesundheitssystemen.
Für eine ausführlichere Erklärung von Multimodalität solltest du unseren Artikel lesen, Was ist multimodale KI?
Ein weiterer wichtiger Aspekt von Basismodellen ist dass sie als Grundlage für domänenspezifische Modelle dienen können. Daher können wir sie an bestimmte Aufgaben oder Domänen anpassen, indem wir ihre Gewichtung auf der Grundlage eines kleineren, domänenspezifischen Datensatzes anpassen und gleichzeitig von ihrer Multimodalität, ihren Generalisierungsfähigkeiten und anderen Eigenschaften profitieren. Dieser Prozess wird als Feinabstimmung bezeichnet. Mehr darüber erfährst du in unserem Leitfaden zur Feinabstimmung von LLMs.
Einige Techniken zur Feinabstimmung sind:
Große Sprachmodelle sind eine spezielle Art von Basismodellen , die ausschließlich oder überwiegend auf Textdaten trainiert werden. Ein LLM kann für bestimmte Aufgaben, wie z.B. Sprachübersetzung oder Zusammenfassungen, weiter verfeinert werden.
Die folgende Tabelle kann helfen, die Unterschiede und Gemeinsamkeiten zwischen den beiden Modellkategorien aufzuzeigen:
|
Aspekt |
Grundlegendes Modell |
Großes Sprachmodell |
|
Umfang |
Allzweckmodelle, die in der Regel auf multimodalen Daten trainiert werden. |
Eine Untergruppe von Grundmodellen, die ausschließlich auf Testdaten trainiert und manchmal für eine bestimmte Aufgabe feinabgestimmt werden. |
|
Trainingsdaten |
Vielfältige (und in der Regel multimodale) Datensätze. |
Vor allem Textkorpora. |
|
Architektur* |
Mehrere Architekturen: Transformatoren, Convolutional Neural Networks (CNNs) oder hybride Architekturen, je nach Datentyp. |
Typischerweise Transformator-basierte Architektur. |
|
Anwendungsfälle |
Multimodale allgemeine Aufgaben. |
Fokussiert auf sprachliche Aufgaben: Übersetzung, Zusammenfassung, Chatbot, Codegenerierung, etc. Heutzutage in der ganzen Gesellschaft beliebt. In unserem Leitfaden findest du die beliebtesten Open-Source-Modelle. |
* Im nächsten Abschnitt werden wir etwas ausführlicher auf die Architekturen der Grundmodelle eingehen.
Ein praktischeres Beispiel: Das erste GPT-Modell, das in der ChatGPT-Weboberfläche verwendet wurde, war GPT-3. Es handelte sich um ein rein textuelles Großsprachenmodell, mit dem die Nutzer nur über Eingabeaufforderungen interagieren konnten. Da LLMs eine Teilmenge innerhalb von Gründungsmodellen sind, war auch GPT-3 ein Gründungsmodell.
Wenn wir heute die ChatGPT-Oberfläche aufrufen, sehen wir, dass wir neben der Eingabeaufforderung auch Bilder anhängen können. Das liegt daran, dass GPT-4 jetzt das Modell hinter der Schnittstelle ist. GPT-4 ist stattdessen ein multimodales Gründungsmodell.
Screenshot der multimodalen Schnittstelle von ChatGPT.
Da wir zum ersten Mal durch LLMs mit diesen großen Modellen in Berührung gekommen sind, neigen die Leute dazu zu denken, dass die Transformer-Architektur die einzige ist, die hinter den Gründungsmodellen steht.
Wie auch immer, Recurrent Neural Networks (RNNs) waren die bevorzugte Architektur für textbasierte Basismodelle, bevor Transformers populär wurden.
Im Bereich der Bilderzeugung sind die Diffusionsmodelle heute das Rückgrat dieser modernen Systeme. Einige bekannte Modelle sind Stable Diffusion und DALL-E, aber Convolutional Neural Networks (CNNs) wurden schon vor ihnen verwendet!
Diffusionsmodelle gelten aus denselben Gründen als grundlegend für die Bilderzeugung wie oben beschrieben: Sie können qualitativ hochwertige, vielfältige Bilder erzeugen und für bestimmte Aufgaben wie Bildbearbeitung oder Inpainting fein abgestimmt werden.
Grundlegende Modelle werden aufgrund ihrer Vielseitigkeit und Anpassungsfähigkeit in verschiedenen Bereichen eingesetzt, einige davon sind:
Wie bereits erwähnt, haben die grundlegenden Modelle bemerkenswerte Verbesserungen in der natürlichen Sprachverarbeitung bewirkt. Die menschenähnlichen Fähigkeiten von Modellen wie ChatGPT haben diese Modelle in Kundenservice-Anwendungen, zum Beispiel, unverzichtbar gemacht. Jeder Online-Konversationsagent ist jetzt wahrscheinlich LLM-basiert und kann im Vergleich zu früheren Chatbots, die auf regelbasierten Systemen basierten, natürlichere, kohärentere Gespräche führen.
Diese Modelle unterstützen auch Anwendungen im Bereich der Sprachübersetzung wie Google Translate und DeepL. Wenn du diese Tools jetzt benutzt, wirst du feststellen, dass sie genauer und kontextbezogener geworden sind als noch vor zehn Jahren.
Wenn du dich für natürlichsprachliche Anwendungen interessierst, ist der Kurs "Entwickeln von KI-Anwendungen" wird dir einen Schub geben!
Modelle wie CLIP und DALL-Ekombinieren beispielsweise Text- und Bildverständnis und ermöglichen Anwendungen wie Bildbeschriftung und Text-zu-Bild-Generierungmöglich, die mit früheren Architekturen nicht machbar waren.
Unter den Werkzeugen hat Adobe Photoshop Diffusionsmodelle in seine Bearbeitungswerkzeuge integriert, wie zum Beispiel in Inhaltsbasiertes Füllen und andere KI-gesteuerte Funktionen zur automatischen Bildvervollständigung und -übermalung.
Schließlich gibt es auch multimodale Anwendungen , die Daten aus mehreren Bereichen gleichzeitig verarbeiten und integrieren können. In autonomen Systemen verwenden beispielsweiseTesla und Waymo - Googles autonomes Fahrzeugprojekt - multimodale Systeme, die visuelle Daten von Kameras, Radarsignalen und LiDAR-Sensoren mit Text- und Kontextinformationen kombinieren, um zu navigieren und die Umgebung zu verstehen.
Diese bereichsübergreifenden Anwendungen verändern die Industrie und ermöglichen dynamischere, anpassungsfähigere und intelligentere Systeme, die bisher durch engere Modelle begrenzt waren.
Nachdem wir diese Anwendungen gesehen haben, können wir die Modelle visuell klassifizieren, wie in der Abbildung unten:
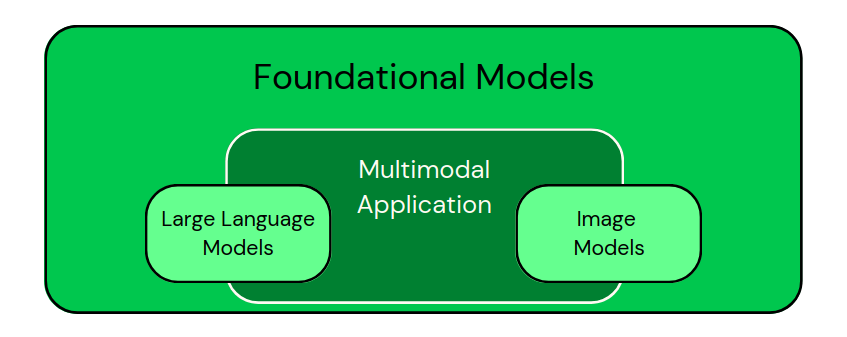
Klassifizierung von domänenspezifischen Modellen als Teilmengen von grundlegenden Modellen. Multimodale Anwendungen kombinieren verschiedene Arten von Daten. - Bild vom Autor
Wenn du darüber nachdenkst, Anwendungen zu entwickeln, die auf diesen Modellen basieren, solltest du den Artikel "5 Projekte, die du mit generativen KI-Modellen bauen kannst" gibt dir einige tolle Ideen.
Wie wir gesehen haben, haben Gründungsmodelle mehr Möglichkeiten, aber wir sollten uns auch bewusst sein, dass sie mit einigen Herausforderungen und ethischen Überlegungen verbunden sind:
Die Ausbildung dieser Modelle ist sehr ressourcenintensiv in Bezug auf Zeit und Energie. Wenn diese Modelle einmal trainiert sind, benötigen sie immer noch beträchtliche Ressourcen für die Inferenz, vor allem bei Echtzeitanwendungen, was ihren Betrieb im großen Maßstab teuer macht. Je größer und komplexer die Modelle werden, desto höher ist auch der Rechenaufwand.
Die Kosten stellen vor allem für kleinere Forschungseinrichtungen und Unternehmen eine Herausforderung dar, da sie möglicherweise nicht über die finanziellen Mittel verfügen, um große Modelle von Grund auf zu trainieren, so dass große Unternehmen die Forschung in diesem Bereich dominieren können. Meiner Meinung nach wird die Verfügbarkeit von vortrainierten Open-Source-Modellen beiden Seiten helfen.
Eng verbunden mit den Kosten sind die Auswirkungen auf die Umwelt dieser Modelle ein wachsendes Problem dar. Das Trainieren großer KI-Modelle verbraucht eine beträchtliche Menge an Energie und trägt damit zu einem hohen CO2-Fußabdruck bei.
Der zunehmende Einsatz von KI und das Vortraining immer größerer Modelle verstärkt die Sorge um die Nachhaltigkeit. Es werden zwar Anstrengungen unternommen, um den Energieverbrauch durch effizientere Algorithmen und Hardware sowie durch den Einsatz erneuerbarer Energiequellen in Rechenzentren zu senken, aber das Problem bleibt kritisch.
Grundlegende Modelle sind nicht frei von dem Risiko der Verzerrung. Wie bei vielen Deep-Learning-Algorithmen ergibt sich dieses Risiko aus den riesigen Mengen an realen Daten, auf denen sie trainiert werden. Modelle erben unweigerlich die in den Daten vorhandenen Verzerrungen, was zu ungerechten Ergebnissen oder Diskriminierung bei sensiblen Anwendungen führen kann.
Der Abbau von Verzerrungen ist von entscheidender Bedeutung und kann durch Strategien wie die Implementierung fairer Algorithmen, die Diversifizierung von Trainingsdaten und die regelmäßige Überprüfung von Modellen erreicht werden, um sicherzustellen, dass sie keine schädlichen Verzerrungen aufrechterhalten.
Und schließlich werden die regulatorischen Bedenken hinsichtlich der Verwendung von Gründungsmodellen immer deutlicher. Da diese Modelle immer leistungsfähiger werden und in verschiedenen Branchen zum Einsatz kommen, arbeiten Regierungen und internationale Gremien daran, Rahmenbedingungen für die Sicherheit und Verantwortlichkeit von KI zu schaffen.
Die Einhaltung globaler Standards wie des KI-Gesetzes der EU ist entscheidend für die Bewältigung der Risiken, die mit dem Einsatz von KI verbunden sind, einschließlich Datenschutzfragen und Fehlinformationen. Mit dem DataCamp-Kurs "Grundlagen des EU-KI-Gesetzes" kannst du dich mit diesen Vorschriften vertraut machen. EU AI Act Fundamentals Lernpfad.
Einer der wichtigsten Trends bei den Gründungsmodellen ist die Entwicklung von multimodalen Fähigkeiten. Diese Modelle werden zunehmend entwickelt, um verschiedene Arten von Daten zu verarbeiten und in einen einheitlichen Rahmen zu integrieren.
Dieser multimodale Ansatz ermöglicht es KI-Systemen, die Welt besser zu verstehen und mit ihr zu interagieren. Manche behaupten sogar, dass sie dies auf eine Art und Weise tun, die der menschlichen Kognition ähnelt. Ich bin mir sicher, dass diese Fähigkeiten mit zunehmender Reife immer umfassendere Anwendungen ermöglichen werden.
Ein weiterer spannender Trend ist die Aussicht auf die Anpassungsfähigkeit in Echtzeit. Aktuelle Grundmodelle erfordern ein umfangreiches Vortraining und eine Feinabstimmung, um sich an bestimmte Aufgaben anzupassen. Es wird jedoch erwartet, dass zukünftige Modelle dynamischer werden und in der Lage sind, in Echtzeit zu lernen und sich anzupassen, wenn sie auf neue Daten oder Umgebungen treffen.
Dadurch können KI-Systeme effektiver auf sich ändernde Bedingungen reagieren, z. B. auf sich verändernde Nutzerpräferenzen oder aufkommende Trends in Daten.
Endlich! Innovationen, die Modelle leichter und zugänglicher machen um den Energieverbrauch und die Kosten zu senken und die Nutzung der grundlegenden KI-Technologien zu demokratisieren.
Die laufende Forschung zielt darauf ab, die Größe und den Ressourcenbedarf dieser Modelle zu reduzieren, ohne ihre Leistung zu beeinträchtigen. Techniken wie Modelldestillation, Quantisierung und effizientes Architekturdesign werden erforscht, um kleinere, schnellere und energieeffizientere Modelle zu erstellen.
Darüber hinaus ermöglichen leichtgewichtige Modelle den Einsatz auf Edge-Geräten wie Smartphones und IoT-Geräten und bringen KI-Fähigkeiten näher an die Endnutzer in realen Anwendungen.
Ich möchte sicherstellen, dass wir an dieser Stelle die in der Einleitung gestellte Frage angehen können: "Was macht ein Gründungsmodell grundlegend?".
Ein Modell ist grundlegend, wenn es universell einsetzbar ist und für verschiedene Aufgaben verallgemeinert und für verschiedene, engere Aufgaben spezialisiert werden kann. Grundlegende Modelle ermöglichen die Entwicklung von aufgabenspezifischen Modellen, die als Basis für die Feinabstimmung in verschiedenen Bereichen dienen. Ihre Macht bringt jedoch auch Herausforderungen mit sich, z. B. Voreingenommenheit und ethische Bedenken, sowie einige neue Zukunftstrends, die es zu erforschen gilt.
Wenn du an weiteren Inhalten dieser Art interessiert bist, solltest du dir die DataCamp KI-Grundlagen Lernpfad des DataCamps an, der viele der Grundlagen für die Arbeit mit KI-Modellen abdeckt.
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
