
Cours
Implémentation IA en entreprise
2 h
51.7K
Le coût informatique de la formation de grands modèles linguistiques (LLM) devient de plus en plus incontrôlable. Par exemple, la formation de GPT-4 a coûté à OpenAI environ 100 millions de dollars. Le coût provient principalement des opérations de multiplication des matrices (MatMul en abrégé), et il est naturel que les chercheurs et les développeurs aient essayé de l'éliminer complètement ou de le rendre plus efficace.
L'article intitulé "Scalable MatMul-free Language Modeling" présente une approche novatrice qui aborde ce problème de front. En éliminant complètement MatMul des LLM, les auteurs ont développé un modèle qui maintient des performances compétitives tout en réduisant de manière significative les exigences en matière de calcul et de mémoire.
Source : Rui-Jie Zhu et. al
Tous les modèles de l'article sont disponibles sur HuggingFace - vouspouvez les essayer en ligne ou localement en utilisant les bibliothèques de HuggingFace. Les chercheurs ont également mis leur code à disposition sur GitHub, ce qui permet à d'autres de former leurs modèles.
Si vous souhaitez mieux comprendre la complexité temporelle cubique de la multiplication matricielle, je vous recommande cette introduction à la notation Big-O et à la complexité temporelle, qui comporte une section spéciale sur la complexité temporelle des LLM de MatMul.
J'ai également effectué une comparaison entre les LLM sans MatMul et les LLM avec MatMul - vous pouvez la trouver dans cet article : Matmul-Free vs MatMul LLMs : Vitesse et consommation de mémoire.
Les LLM modernes basés sur des transformateurs s'appuient fortement sur des opérations de multiplication de matrices, qui sont au cœur de leurs composants principaux, tels que les mécanismes d'attention et les couches d'anticipation. Les coûts de calcul et de mémoire associés aux opérations MatMul sont considérables et ont un impact sur les phases d'apprentissage et d'inférence. Au fur et à mesure que la taille des LLM augmente, le nombre de paramètres et la complexité des calculs augmentent, ce qui fait de MatMul un goulot d'étranglement majeur.
Un exemple courant de ce problème est lorsque la VRAM d'un GPU est insuffisante pour gérer la taille du modèle, ce qui oblige les utilisateurs à former ou à exécuter l'inférence sur des CPU à la place. Les CPU ne sont pas optimisés pour les opérations MatMul parallélisées comme les GPU, ce qui entraîne des calculs beaucoup plus lents. Cela crée une boucle frustrante dans laquelle le matériel disponible ne peut être pleinement utilisé en raison de contraintes de mémoire, même si la puissance de calcul est adéquate.
Au fil des ans, les chercheurs ont exploré diverses stratégies pour réduire la charge de calcul de MatMul. La quantification, qui consiste à réduire la précision des poids et des activations, est une approche très répandue. En représentant les nombres avec moins de bits, la quantification peut réduire le coût de calcul et l'empreinte mémoire des opérations MatMul.
Toutefois, cette méthode sacrifie souvent la précision du modèle et n'élimine pas complètement MatMul. Des efforts notables, tels que BitNet de Microsoft, ont montré qu'il était possible de mettre à l'échelle les LLM avec une quantification binaire ou ternaire, mais ces modèles reposent toujours sur des opérations MatMul pour certaines parties, telles que le mécanisme d'auto-attention.
D'autres architectures ont également été proposées pour remédier aux insuffisances de MatMul. Des approches telles que AdderNet remplacent les multiplications par des additions dans certains composants du réseau, et les réseaux neuronaux binaires/ternaires utilisent des opérations arithmétiques simplifiées.
Bien que ces méthodes offrent certaines améliorations, elles ne parviennent généralement pas à supprimer complètement MatMul et ne ciblent que des parties spécifiques du modèle. Par conséquent, le coût de calcul global reste élevé, ce qui limite l'évolutivité et l'efficacité des LLM.
Pour comprendre le fonctionnement des LM sans MatMul, examinons l'architecture sous-jacente et les composants clés.
Dans les réseaux neuronaux traditionnels, les couches denses (qui connectent tous les neurones entre deux couches consécutives) s'appuient sur MatMul pour transformer les données d'entrée. Les auteurs les remplacent par des couches BitLinear, qui utilisent des poids ternaires. Au lieu d'avoir des poids qui peuvent être n'importe quel nombre réel, ils sont contraints à seulement trois valeurs : -1, 0 ou 1.
Les poids sont initialement formés comme des valeurs de pleine précision, puis, au cours de la formation, ils sont quantifiés en valeurs ternaires à l'aide d'un processus appelé "quantification de la moyenne absente". Ce processus met à l'échelle la matrice des poids en fonction de sa valeur absolue moyenne, puis arrondit chaque élément à l'entier ternaire le plus proche (-1, 0 ou 1).
Cette simplification leur permet de remplacer les multiplications dans MatMul par des additions et des soustractions. Par exemple, multiplier un nombre par -1 revient à l'annuler, multiplier par 0 donne 0 et multiplier par 1 laisse le nombre inchangé.
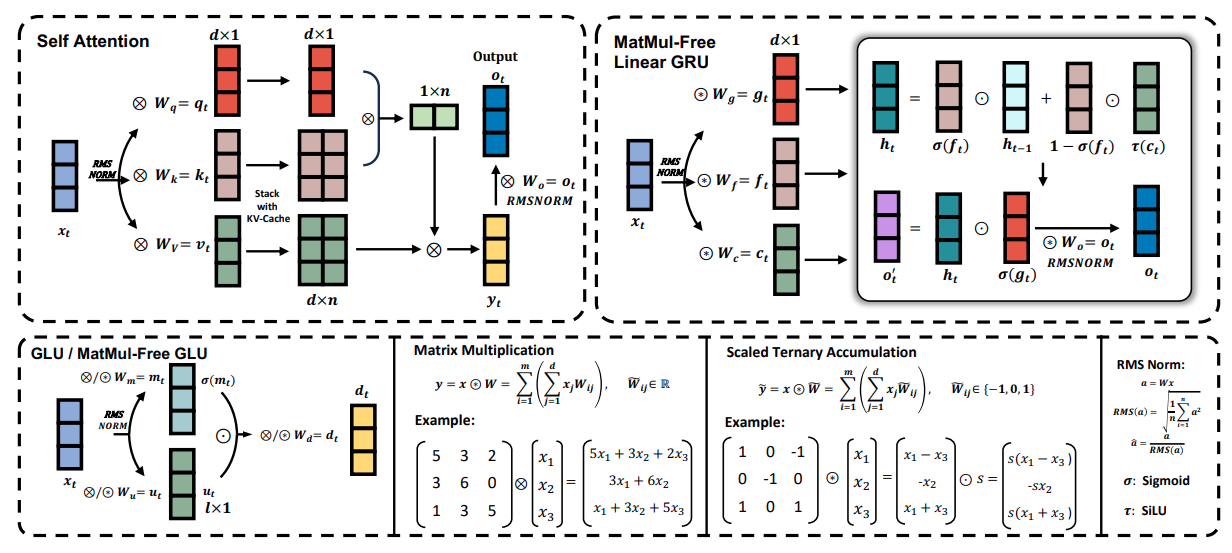
La figure ci-dessous donne un aperçu des composants clés du modèle de langage MatMul-Free, y compris l'unité récurrente linéaire à grille MatMul-Free (MLGRU) et l'unité linéaire à grille MatMul-Free (GLU) :
Source : Rui-Jie Zhu et. al
La figure est divisée en plusieurs sections (du haut à gauche au bas à droite) :
Le MLGRU traite la séquence d'entrée un jeton à la fois. À chaque étape, il prend en compte l'intégration du jeton actuel et l'état caché précédent. L'état caché agit comme une mémoire, stockant les informations des jetons précédents. Le MLGRU met ensuite à jour cet état caché à l'aide d'une série d'opérations par éléments et de mécanismes de contrôle. Ces portes, essentiellement des vecteurs de nombres entre 0 et 1, contrôlent le flux d'informations en déterminant quelles parties de l'état caché précédent et de l'intégration du jeton actuel sont les plus pertinentes pour l'étape suivante. Ce processus se poursuit jusqu'à ce que la séquence entière ait été traitée.
L'unité linéaire à portes sans MatMul (GLU) est un autre élément clé du modèle de langage sans MatMul. Il mélange des informations sur les différentes dimensions de la représentation interne des mots du modèle (embeddings). En termes plus simples, il aide le modèle à comprendre les différents aspects ou caractéristiques de chaque mot.
L'UGL y parvient en utilisant un mécanisme de blocage pour contrôler le flux d'informations entre les différents canaux d'intégration. Ce mécanisme de contrôle est similaire aux portes du MLGRU, mais il opère sur la dimension du canal au lieu de la dimension du jeton.
L'UGL sans MatMul est une version modifiée de l'UGL standard, adaptée pour éliminer les multiplications de matrices en utilisant des couches BitLinear, qui sont des couches denses utilisant des poids ternaires (poids qui ne peuvent prendre que les valeurs -1, 0 ou 1). Dans l'UGL sans MatMul, l'entrée est d'abord transformée à l'aide de deux couches BitLinear distinctes. La sortie d'une couche passe par la fonction d'activation SiLU, puis est multipliée par élément avec la sortie de l'autre couche. Cette sortie est ensuite passée par une autre couche BitLinear pour produire la sortie finale.
Il ne s'agit que d'une explication de haut niveau des composantes MLGRU et GLU. Je vous encourage à vous référer au document de recherche original pour une compréhension plus détaillée de leur fonctionnement interne et de leurs formulations mathématiques.
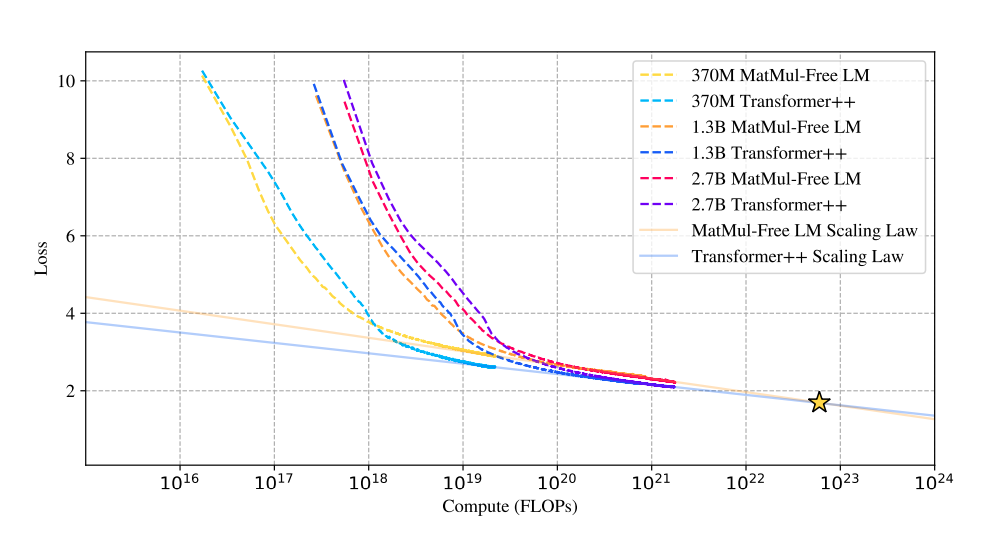
La recherche étudie les lois de mise à l'échelle des modèles sans MatMul, en comparant leurs performances aux architectures Transformer traditionnelles au fur et à mesure que la taille du modèle augmente.
De manière surprenante, les résultats révèlent que l'écart de performance entre ces deux approches se réduit au fur et à mesure que la taille du modèle augmente. Cette observation est importante car elle suggère que les modèles sans MatMul deviennent de plus en plus compétitifs par rapport aux transformateurs traditionnels au fur et à mesure qu'ils augmentent d'échelle, et qu'ils peuvent même les surpasser à très grande échelle.
Source : Rui-Jie Zhu et. al
Ce graphique sur la comparaison des lois d'échelle montre que les courbes de perte des LM sans MatMul et des transformateurs traditionnels convergent à mesure que le nombre d'opérations en virgule flottante (FLOP) augmente.
Au départ, les LM sans MatMul présentent une perte plus importante en raison des contraintes liées aux poids ternaires. Toutefois, cet écart diminue à mesure que la taille du modèle augmente et, à un certain point (étoile), les courbes de perte se croisent, ce qui indique des performances comparables. Cela suggère une loi d'échelle plus raide pour les modèles sans MatMul, ce qui signifie que leurs performances s'améliorent plus rapidement avec l'augmentation de la taille par rapport aux transformateurs traditionnels.
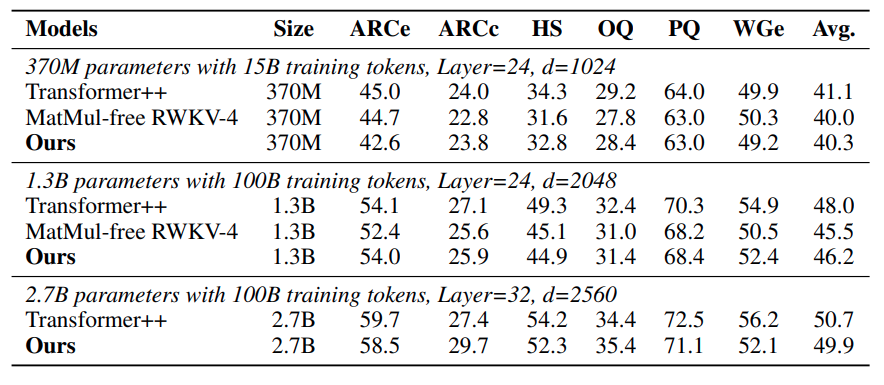
Les performances compétitives des LM sans MatMul sont encore renforcées par leurs excellents résultats sur divers benchmarks d'apprentissage sans essai. Dans des tâches telles que ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, PIQA et OpenbookQA, ces modèles obtiennent souvent des résultats équivalents ou supérieurs à ceux des transformateurs traditionnels, malgré leur complexité de calcul considérablement réduite. Cela témoigne de l'efficacité des opérations alternatives et des choix architecturaux employés dans les LM sans MatMul.
Source : Rui-Jie Zhu et. al
Le tableau sur la précision de l'essai à zéro montre que les LM sans MatMul ont des performances compétitives pour différentes tâches. Par exemple, dans l'ARC-Challenge, un benchmark particulièrement difficile, le LM sans MatMul à 2,7 milliards de paramètres atteint une précision supérieure à celle d'un modèle de transformateur traditionnel.
De même, pour les tâches Winogrande et OpenbookQA, les LM sans MatMul affichent des performances solides, ce qui indique que l'élimination de MatMul ne compromet pas la capacité du modèle à comprendre et à générer du langage.
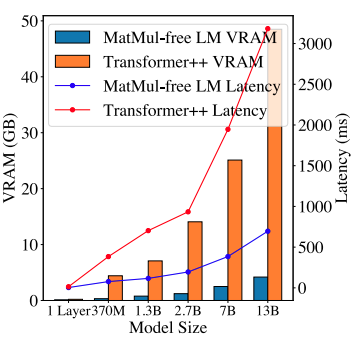
L'un des avantages les plus frappants des LM sans MatMul est leur efficacité exceptionnelle en termes de mémoire. En remplaçant les opérations lourdes de multiplication par des additions et des soustractions plus simples permises par les poids ternaires, ces modèles permettent de réduire considérablement l'utilisation de la mémoire.
Lors de l'apprentissage, une implémentation GPU optimisée peut réduire la consommation de mémoire jusqu'à 61% par rapport aux modèles non optimisés. En ce qui concerne l'inférence, les économies de mémoire sont encore plus spectaculaires, avec des réductions de plus de dix fois. Cela rend les LM sans MatMul particulièrement intéressants pour le déploiement sur des appareils à ressources limitées comme les smartphones, où la mémoire est souvent un facteur limitant.
Source : Rui-Jie Zhu et. al
Ce graphique de comparaison de la mémoire et de la latence des GPU illustre les gains d'efficacité des LM sans MatMul. La consommation de mémoire d'inférence d'un LM sans MatMul de 2,7 milliards de paramètres est nettement inférieure à celle d'un transformateur traditionnel comparable. Cette empreinte mémoire réduite permet non seulement de déployer des modèles plus importants sur un matériel limité, mais aussi de réduire la latence, ce qui rend ces modèles plus adaptés aux applications en temps réel où la réactivité est cruciale.
L'une des principales avancées présentées dans ce document est la mise en œuvre optimisée par le GPU des LM sans MatMul. Les auteurs ont obtenu une augmentation de 25,6 % de la vitesse d'apprentissage et une réduction de 61 % de l'utilisation de la mémoire en utilisant des noyaux fusionnés dans leur propre implémentation GPU. Ces noyaux combinent plusieurs opérations en un seul processus plus efficace, réduisant ainsi les frais généraux liés à l'accès à la mémoire et au déplacement des données.
Pour exploiter davantage les opérations légères des LM sans MatMul, les auteurs ont développé un accélérateur FPGA personnalisé en SystemVerilog. Les FPGA (Field-Programmable Gate Arrays) offrent une plate-forme matérielle flexible et efficace pour la mise en œuvre de tâches informatiques spécialisées.
L'accélérateur personnalisé a été conçu pour tirer parti de la simplicité des opérations ternaires et des produits élémentaires, ce qui permet d'obtenir des gains d'efficacité substantiels. L'implémentation RTL (Register Transfer Level) est essentielle dans le processus de conception du FPGA. Il s'agit de spécifier le comportement du matériel à un niveau élevé, qui est ensuite synthétisé dans la configuration réelle du FPGA. La conception RTL personnalisée pour les LM sans MatMul garantit que le FPGA peut traiter efficacement les opérations légères, en réduisant la consommation d'énergie et en augmentant le débit.
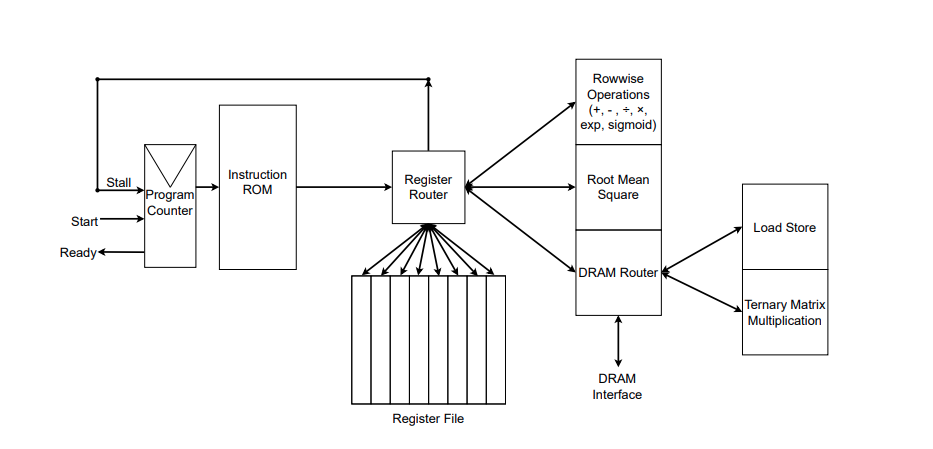
Source : Rui-Jie Zhu et. al
La figure illustre la mise en œuvre RTL de l'accélérateur FPGA personnalisé. Vous pouvez voir les fonctions qu'il met en œuvre à droite du routeur de registre. Les auteurs ont également développé leur propre assembleur pour convertir les fichiers d'assemblage contenant des instructions personnalisées en une ROM d'instructions, que vous pouvez voir à droite de la figure. Les instructions sont transmises au routeur de registres qui gère la mémoire (fichier de registres) et exécute les instructions.
De plus, les auteurs ont mentionné dans un commentaire sur GitHub que les spécifications complètes de leur implémentation FPGA sont encore en cours d'optimisation, et que le code SystemVerilog sera rendu public plus tard.
Le tableau ci-dessous montre l'utilisation des ressources et les mesures de performance pour l'implémentation FPGA de la génération de jetons sans MatMul.
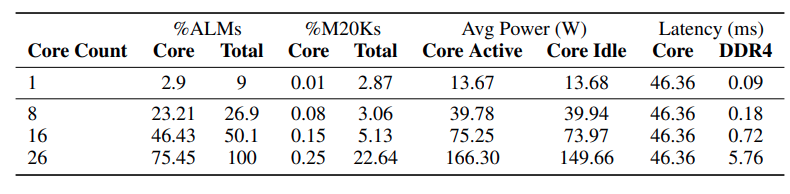
Source : Rui-Jie Zhu et. al
Les données montrent qu'à mesure que le nombre de cœurs (unités de traitement) dans le FPGA augmente, la latence globale reste relativement stable dans un premier temps. Cependant, la latence augmente de manière significative de 16 à 26 cœurs, ce qui suggère que l'interface DDR4, qui est responsable du transfert de données, devient un goulot d'étranglement à mesure que la demande de transfert de données augmente avec le nombre de cœurs.
Alors que l'opération de multiplication de la matrice ternaire domine actuellement la latence globale, les auteurs prévoient que l'optimisation de cette unité dans les futures implémentations déplacera le goulot d'étranglement vers l'interface DDR4.
L'une des affirmations les plus intrigantes de l'article est que son approche sans MatMul rapproche les LLM d'une efficacité comparable à celle du cerveau en termes de calcul et de consommation d'énergie. Les auteurs affirment que leurs modèles imitent l'efficacité des réseaux neuronaux biologiques et atteignent une vitesse de lecture comparable à celle de l'homme.
Cependant, la comparaison directe de l'efficacité de ces modèles avec le fonctionnement complexe des réseaux neuronaux biologiques est une question complexe qui nécessite des recherches plus approfondies. Les mécanismes de calcul du cerveau sont très différents et beaucoup plus complexes que les opérations simplifiées utilisées dans les LM sans MatMul.
L'article intitulé "Scalable MatMul-free Language Modeling" remet en question une hypothèse fondamentale du traitement du langage naturel : la multiplication matricielle (MatMul) est essentielle à la construction de LLM performants.
En démontrant la viabilité des architectures sans MatMul, cette recherche ouvre une nouvelle frontière dans la conception des LLM, encourageant l'exploration d'opérations et de paradigmes de calcul alternatifs. Cela pourrait entraîner une vague d'innovation, les chercheurs développant de nouvelles architectures de modèles.
Cette évolution vers des modèles sans MatMul ne concerne pas seulement les logiciels, mais aussi le matériel. Les puces traditionnelles comme les GPU sont excellentes pour la multiplication matricielle, mais ne sont pas nécessairement les mieux adaptées à ces nouveaux modèles légers.
L'accélérateur FPGA personnalisé construit par les chercheurs est un aperçu de l'avenir du matériel d'IA - des puces spécialisées conçues pour tirer le maximum de performances de ces modèles efficaces. Cela pourrait déboucher sur une toute nouvelle génération d'appareils alimentés par l'IA, plus rapides, plus économes en énergie et accessibles à un public plus large.
En tant que personne soucieuse de l'environnement, je suis particulièrement enthousiaste à l'idée que les modèles sans MatMul puissent réduire l'empreinte carbone de l'IA. La consommation massive d'énergie des grands modèles linguistiques actuels est un réel problème. En réduisant considérablement les besoins de calcul, cette recherche pourrait ouvrir la voie à des technologies d'IA plus économes en énergie et à l'empreinte environnementale plus faible.
Si l'article "Scalable MatMul-free Language Modeling" représente une avancée significative, il ouvre également plusieurs pistes de recherche : explorer différentes architectures sans MatMul, évaluer leurs performances sur un plus large éventail de tâches et comprendre mathématiquement les limites théoriques de cette approche ne sont que quelques-unes des directions de recherche passionnantes.
En outre, l'élaboration de critères de référence normalisés et de mesures d'évaluation spécifiques pour les modèles sans MatMul faciliterait des comparaisons équitables et accélérerait les progrès dans ce domaine. Le voyage vers une IA réellement efficace et accessible ne fait que commencer, et les possibilités sont illimitées. Par ailleurs, je suis personnellement très enthousiaste à l'idée d'essayer les futurs chatbots assistants sans MatMul !
L'article "Scalable MatMul-free Language Modeling" apporte une contribution significative au domaine des LLM en introduisant une nouvelle approche qui élimine les opérations de multiplication matricielle (MatMul).
Cette avancée permet d'éliminer les goulets d'étranglement en matière de calcul et de mémoire associés aux LLM traditionnels, ouvrant ainsi la voie à des modèles plus efficaces et plus évolutifs. En tirant parti des opérations additives et des poids ternaires, les auteurs démontrent qu'il est possible de maintenir des performances compétitives tout en réduisant considérablement les besoins en ressources.
L'impact potentiel de cette recherche sur l'avenir du développement et du déploiement du LLM est considérable. Les modèles sans MatMul offrent une alternative viable aux architectures conventionnelles, permettant la création de modèles légers et efficaces qui sont bien adaptés aux environnements à ressources limitées tels que les appareils périphériques et les plates-formes mobiles.
Si vous souhaitez en savoir plus sur l'intelligence artificielle, consultez ces cours sur l'IA.
Apprenez l'IA avec ces cours !
Cours
Cours
Cours