
Course
Implementing AI Solutions in Business
2 hr
51.7K
The computational cost of training large language models (LLMs) is increasingly getting out of hand. For example, the training of GPT-4 cost OpenAI approximately 100 million dollars. The cost mainly comes from matrix multiplication operations (MatMul for short), and it’s natural that researchers and developers alike have tried to eliminate it completely or make it more efficient.
The "Scalable MatMul-free Language Modeling" paper introduces a groundbreaking approach that addresses this issue head-on. By completely eliminating MatMul from LLMs, the authors have developed a model that maintains competitive performance while significantly reducing computational and memory requirements.
Source: Rui-Jie Zhu et. al
All the models from the paper are available on HuggingFace—you can either try them out online or locally using HuggingFace’s libraries. Also, the researchers have provided their code on GitHub, allowing others to train their models.
If you want to better understand the cubic time complexity of matrix multiplication, I recommend this introduction to Big-O Notation and Time Complexity, which has a special section on the time complexity of MatMul LLMs.
I also did a comparison between MatMul-free and MatMul LLMs—you can find it in this article: Matmul-Free vs MatMul LLMs: Speed and Memory Consumption.
Modern transformer-based LLMs rely heavily on matrix multiplication operations, which are central to their core components, such as attention mechanisms and feedforward layers. The computational and memory costs associated with MatMul operations are substantial, impacting both the training and inference phases. As the size of LLMs increases, the number of parameters and the complexity of the computations grow, making MatMul a major bottleneck.
A common example of this issue is when the VRAM of a GPU is insufficient to handle the model size, forcing users to train or run inference on CPUs instead. CPUs are not optimized for parallelized MatMul operations like GPUs, leading to significantly slower computations. This creates a frustrating loop where the available hardware cannot be fully utilized due to memory constraints, even if the computational power is adequate.
Over the years, researchers have explored various strategies to reduce the computational burden of MatMul. Quantization, which involves reducing the precision of the weights and activations, has been a popular approach. By representing numbers with fewer bits, quantization can lower the computational cost and memory footprint of MatMul operations.
However, this method often sacrifices model accuracy and does not completely eliminate MatMul. Notable efforts like BitNet by Microsoft have shown that it's possible to scale LLMs with binary or ternary quantization, but these models still rely on MatMul operations for certain parts, such as the self-attention mechanism.
Alternative architectures have also been proposed to address MatMul's inefficiencies. Approaches like AdderNet replace multiplications with additions in certain network components, and binary/ternary neural networks utilize simplified arithmetic operations
While these methods offer some improvements, they typically fail to fully remove MatMul and only target specific parts of the model. As a result, the overall computational cost remains high, limiting the scalability and efficiency of LLMs.
To understand how MatMul-free LMs work, let's examine the underlying architecture and key components.
In traditional neural networks, dense layers (which connect all neurons between two consecutive layers) rely on MatMul to transform input data. The authors replace these with BitLinear layers, which use ternary weights. Instead of having weights that can be any real number, they are constrained to only three values: -1, 0, or 1.
The weights are initially trained as full-precision values, and then during training, they are quantized to ternary values using a process called "absmean quantization." This process scales the weight matrix by its average absolute value and then rounds each element to the nearest ternary integer (-1, 0, or 1).
This simplification allows them to replace the multiplications in MatMul with additions and subtractions. For example, multiplying a number by -1 is the same as negating it, multiplying by 0 results in 0, and multiplying by 1 leaves the number unchanged.
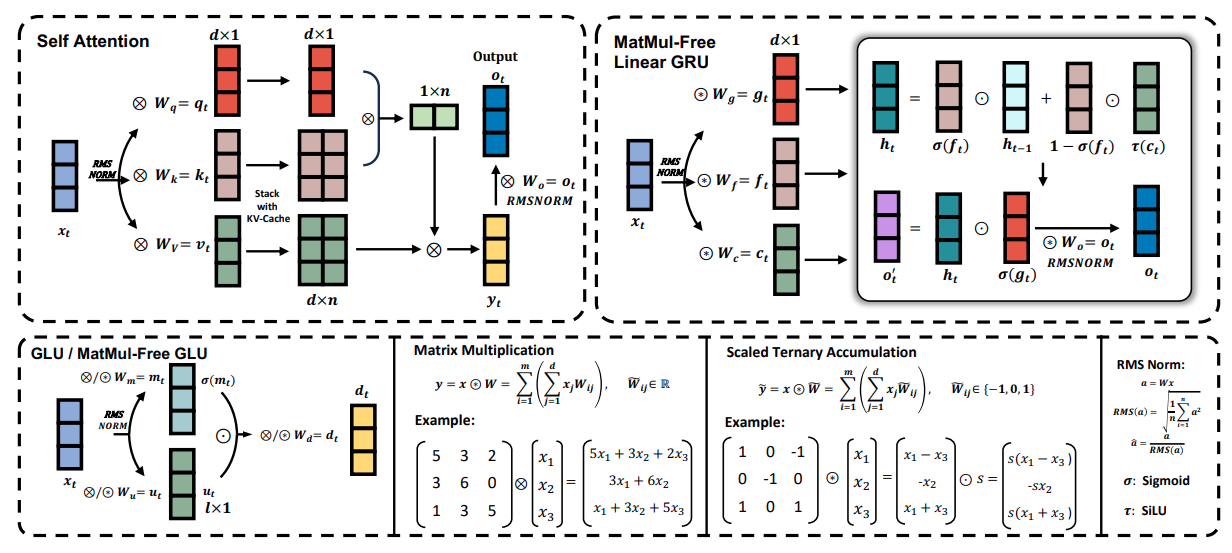
The figure below provides an overview of the key components of the MatMul-Free Language Model, including the MatMul-Free Linear Gated Recurrent Unit (MLGRU) and the MatMul-Free Gated Linear Unit (GLU):
Source: Rui-Jie Zhu et. al
The figure is divided into several sections (from top left to bottom right):
The MLGRU operates by processing the input sequence one token at a time. At each step, it takes the current token's embedding and the previous hidden state as input. The hidden state acts as a memory, storing information from previous tokens. The MLGRU then updates this hidden state using a series of element-wise operations and gating mechanisms. These gates, essentially vectors of numbers between 0 and 1, control the flow of information by determining which parts of the previous hidden state and the current token's embedding are most relevant for the next step. This process continues until the entire sequence has been processed.
The MatMul-free gated linear unit (GLU) is another key component of the MatMul-free language model. It mixes information across the different dimensions of the model's internal representation of words (embeddings). In simpler terms, it helps the model understand the different aspects or features of each word.
The GLU achieves this by using a gating mechanism to control the flow of information between different embedding channels. This gating mechanism is similar to the gates in the MLGRU, but it operates on the channel dimension instead of the token dimension.
The MatMul-free GLU is a modified version of the standard GLU, adapted to eliminate matrix multiplications by using BitLinear layers, which are dense layers that employ ternary weights (weights that can only take on the values -1, 0, or 1). In the MatMul-free GLU, the input is first transformed using two separate BitLinear layers. The output of one layer is passed through the SiLU activation function and then multiplied element-wise with the output of the other layer. This gated output is then passed through another BitLinear layer to produce the final output.
This is just a high-level explanation of the MLGRU and GLU components. I encourage you to refer to the original research paper for a more detailed understanding of their inner workings and mathematical formulations.
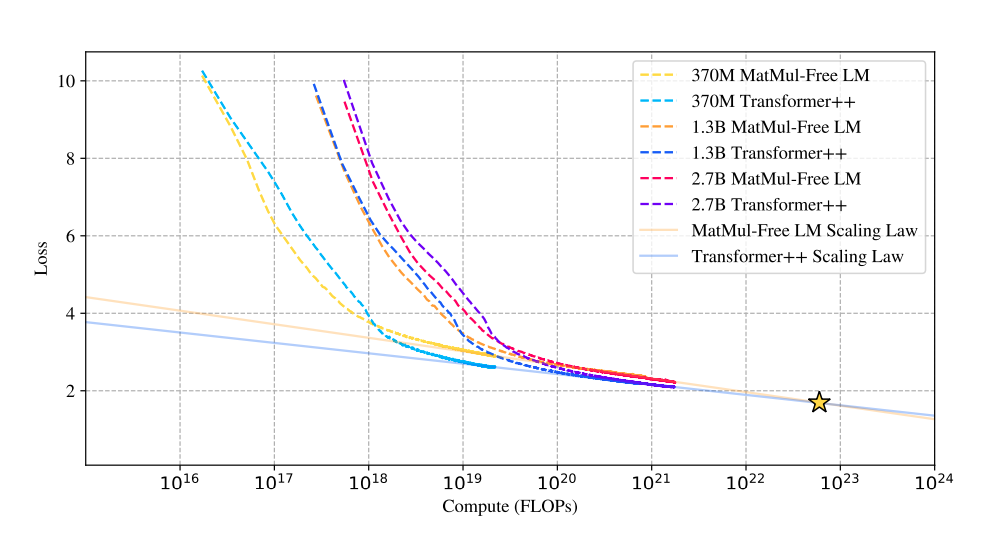
The research investigates the scaling laws of MatMul-free models, comparing their performance to traditional Transformer architectures as the model size increases.
Surprisingly, the findings reveal that the performance gap between these two approaches narrows as the model size grows. This is a significant observation because it suggests that MatMul-free models become increasingly competitive with traditional Transformers as they scale up, potentially outperforming them at very large scales.
Source: Rui-Jie Zhu et. al
This graph on scaling law comparison shows that the loss curves of MatMul-free LMs and traditional transformers converge as the number of floating-point operations (FLOPs) increases.
Initially, MatMul-free LMs exhibit higher loss due to the constraints of ternary weights. However, this gap diminishes as the model size increases, and at a certain point (star), the loss curves intersect, indicating comparable performance. This suggests a steeper scaling law for MatMul-free models, meaning their performance improves more rapidly with increasing size compared to traditional Transformers.
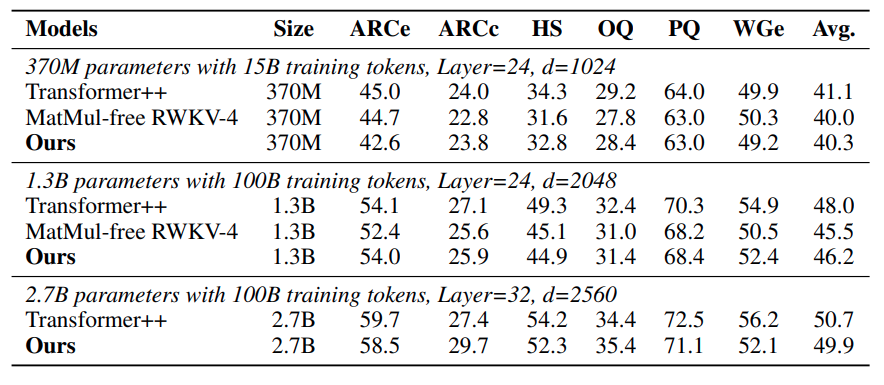
The competitive performance of MatMul-free LMs is further reinforced by their strong showing on various zero-shot learning benchmarks. In tasks like ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, PIQA, and OpenbookQA, these models often perform on par with or surpass traditional Transformers, despite their significantly reduced computational complexity. This is a testament to the effectiveness of the alternative operations and architectural choices employed in MatMul-free LMs.
Source: Rui-Jie Zhu et. al
The table on zero-shot accuracy shows that MatMul-free LMs perform competitively across various tasks. For instance, in the ARC-Challenge, a particularly difficult benchmark, the 2.7B parameter MatMul-free LM achieves an accuracy higher than that of a traditional transformer model.
Similarly, on the Winogrande and OpenbookQA tasks, the MatMul-free LMs show robust performance, indicating that eliminating MatMul does not compromise the model's ability to understand and generate language.
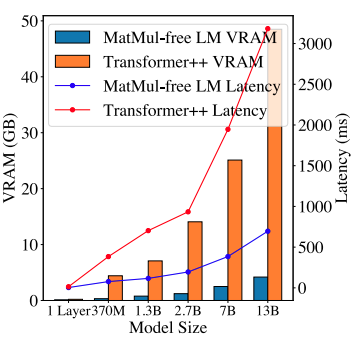
One of the most striking advantages of MatMul-free LMs is their exceptional memory efficiency. By replacing multiplication-heavy operations with simpler additions and subtractions enabled by ternary weights, these models achieve substantial reductions in memory usage.
During training, an optimized GPU implementation can reduce memory consumption by up to 61% compared to unoptimized models. In inference, the memory savings are even more dramatic, with reductions of over tenfold. This makes MatMul-free LMs particularly appealing for deployment on resource-constrained devices like smartphones, where memory is often a limiting factor.
Source: Rui-Jie Zhu et. al
This graph on GPU memory and latency comparison illustrates the efficiency gains of MatMul-free LMs. The inference memory consumption of a 2.7B parameter MatMul-free LM is significantly lower than that of a comparable traditional Transformer. This reduced memory footprint not only allows for the deployment of larger models on limited hardware but also translates to lower latency, making these models more suitable for real-time applications where responsiveness is crucial.
One of the key advancements presented in the paper is the optimized GPU implementation of MatMul-free LMs. The authors achieved a 25.6% increase in training speed and up to 61.0% reduction in memory usage by using fused kernels in their own GPU implementation. These kernels combine multiple operations into a single, more efficient process, reducing the overhead associated with memory access and data movement.
To further exploit the lightweight operations of MatMul-free LMs, the authors developed a custom FPGA accelerator in SystemVerilog. FPGAs (Field-Programmable Gate Arrays) offer a flexible and efficient hardware platform for implementing specialized computational tasks.
The custom accelerator was designed to leverage the simplicity of ternary operations and element-wise products, achieving substantial efficiency gains. The RTL (Register Transfer Level) implementation is critical in the FPGA design process. It involves specifying the hardware behavior at a high level, which is then synthesized into the actual FPGA configuration. The custom RTL design for the MatMul-free LMs ensures that the FPGA can efficiently handle the lightweight operations, reducing power consumption and increasing throughput.
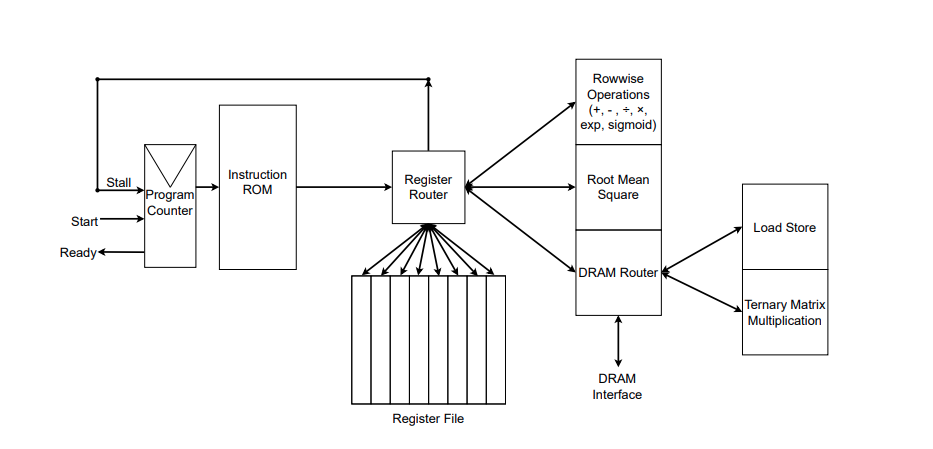
Source: Rui-Jie Zhu et. al
The figure illustrates the RTL implementation of the custom FPGA accelerator. You can see the functions it implements to the right of the Register Router. The authors also developed their own assembler to convert assembly files with custom instructions into an instruction ROM, which you can see at the right of the figure. The instructions are given to the Register Router which manages memory (Register File) and performs instruction.
Furthermore, the authors mentioned in a comment to GitHub issue that the complete specifications of their FPGA implementation are still being optimized, and the SystemVerilog code will be made public later.
The table below shows the resource utilization and performance metrics for the FPGA implementation of MatMul-free token generation.
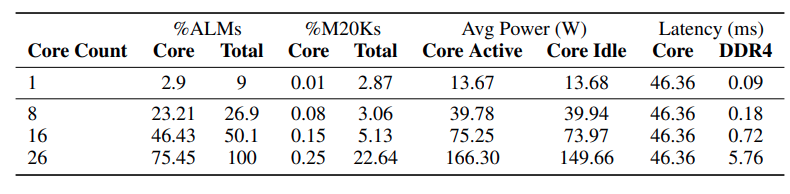
Source: Rui-Jie Zhu et. al
The data demonstrates that as the number of cores (processing units) within the FPGA increases, the overall latency initially remains relatively stable. However, the latency increases significantly from 16 to 26 cores, suggesting that the DDR4 interface, which is responsible for data transfer, is becoming a bottleneck as the demand for data transfer grows with the number of cores.
While the ternary matrix multiplication operation currently dominates the overall latency, the authors anticipate that optimizing this unit in future implementations will shift the bottleneck to the DDR4 interface.
One of the paper's most intriguing claims is that its MatMul-free approach moves LLMs closer to brain-like efficiency in terms of computation and energy consumption. The authors argue that their models mimic the efficiency of biological neural networks and achieve human-like reading speed.
However, directly comparing the efficiency of these models to the intricate workings of biological neural networks is a complex issue that requires further investigation. The brain's computational mechanisms are vastly different and far more complex than the simplified operations used in MatMul-free LMs.
The "Scalable MatMul-free Language Modeling" paper challenges a fundamental assumption in natural language processing: that matrix multiplication (MatMul) is essential for building high-performing LLMs.
By demonstrating the viability of MatMul-free architectures, this research opens up a new frontier in LLM design, encouraging the exploration of alternative operations and computational paradigms. This could lead to a wave of innovation, with researchers developing novel model architectures.
This shift towards MatMul-free models isn't just about software—it's about hardware too. Traditional chips like GPUs are great at matrix multiplication but are not necessarily the best fit for these new, lightweight models.
The custom FPGA accelerator built by the researchers is a glimpse into the future of AI hardware—specialized chips designed to squeeze every ounce of performance out of these efficient models. This could lead to a whole new generation of AI-powered devices that are faster, more energy-efficient, and accessible to a wider audience.
As someone who cares about the environment, I'm particularly excited about the potential of MatMul-free models to reduce AI's carbon footprint. The massive energy consumption of today's large language models is a real concern. By significantly reducing computational demands, this research could pave the way for more energy-efficient AI technologies with a smaller environmental footprint.
While the "Scalable MatMul-free Language Modeling" paper presents a significant leap forward, it also opens up several avenues for further research—exploring different MatMul-free architectures, evaluating their performance on a wider range of tasks, and mathematically understanding the theoretical limits of this approach are just a few of the exciting research directions.
Additionally, developing standardized benchmarks and evaluation metrics specifically for MatMul-free models would facilitate fair comparisons and accelerate progress in this field. The journey towards truly efficient and accessible AI has just begun, and the possibilities are boundless. Also, I am personally very excited to try out future MatMul-free assistant chatbots!
The "Scalable MatMul-free Language Modeling" paper makes a significant contribution to the field of LLMs by introducing a novel approach that eliminates matrix multiplication (MatMul) operations.
This breakthrough addresses the computational and memory bottlenecks associated with traditional LLMs, paving the way for more efficient and scalable models. By leveraging additive operations and ternary weights, the authors demonstrate that it’s possible to maintain competitive performance while significantly reducing resource demands.
The potential impact of this research on the future of LLM development and deployment is profound. MatMul-free models offer a viable alternative to conventional architectures, enabling the creation of lightweight, efficient models that are well-suited for resource-constrained environments such as edge devices and mobile platforms.
If you want to learn more about artificial intelligence, check out these AI courses.
Learn AI with these courses!
Course
Course
Course
blog
Javier Canales Luna
12 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Dimitri Didmanidze
Tutorial
Andrea Valenzuela
Tutorial
Avinash Navlani
