

Curso
Comprender la inteligencia artificial
2 h
401.5K
Es posible que muchas cargas de trabajo empresariales no necesiten modelos a escala fronteriza, y que lo que realmente necesiten sea una inferencia rápida y rentable en tareas específicas. Estoy pensando en la distribución de la atención al cliente, la clasificación de documentos y la finalización de códigos.
Esta es la apuesta de Mistral AI: modelos compactos y de peso abierto, que pueden ajustarse con precisión a los datos del dominio y que pueden funcionar de manera eficiente a gran escala.
Con ese fin, esta misma semana Mistral ha lanzado Mistral 3, y creo que contribuye en gran medida a alcanzar ese objetivo. En primer lugar, los modelos en sí mismos son prometedores: Mistral Large 3, el buque insignia, supera a sus competidores de código abierto Kimi-K2 y Deepseek-3.1 en importantes pruebas de rendimiento. En segundo lugar, Mistral está aclarando su oferta de productos. Verás, esta es la primera vez que Mistral AI lanza una familia completa de modelos. (Cuando Medium 3 salió a la venta a principios de este año, no resultaba evidente (solo por el nombre) que se suponía que debía superar a Large 2, que se lanzó el año pasado).
Mistral 3 es la de última generación de Mistral AI, creados sobre una arquitectura y un conjunto de características compartidas. En lugar de lanzar variantes únicas, Mistral ha pasado a una familia unificada en la que todos los modelos admiten indicaciones multilingües, entradas multimodales y las mismas capacidades básicas. La idea es ofrecer a los programadores una base de referencia coherente, independientemente del tamaño que elijan.
Esta generación también se centra en mejorar el razonamiento, la eficiencia y la usabilidad práctica en todos los ámbitos. Tanto si realizas pruebas en la nube como si creas aplicaciones que requieren una inferencia más rápida, Mistral 3 ofrece una base más clara y predecible sobre la que construir.
Mencioné que Mistral 3 es realmente una familia de modelos. Hay cuatro en total, y todas ellas se centran en diferentes limitaciones: profundidad de razonamiento, límites de hardware, latencia y entornos de implementación. Dicho esto, hay un modelo que destaca por encima del resto: Large 3 está diseñado para una clase de cargas de trabajo muy diferente a la de los niveles más pequeños, que se han diseñado teniendo en cuenta la practicidad y la flexibilidad de implementación.
Mistral Large 3 es el modelo insignia de la generación. Utiliza una arquitectura MoE dispersa con 675 000 millones de parámetros, de los cuales aproximadamente 41 000 millones están activos durante la inferencia, lo que naturalmente conlleva mayores requisitos de hardware. El modelo está diseñado para cargas de trabajo que dependen de un razonamiento sólido, un procesamiento de contexto largo y una calidad de salida constante. Obtiene buenos resultados en evaluaciones de código abierto, incluyendo los mejores resultados en la clasificación sin razonamiento de LMArena. La eficiencia del token es buena, aunque el coste computacional refleja su tamaño.
Este es el modelo denso más resistente de la familia. Es una buena opción cuando se busca una capacidad real sin entrar en el terreno de los clústeres con múltiples GPU. Funciona cómodamente con una única configuración de GPU de gama alta (cuatro GPU si deseas margen de maniobra) y obtiene excelentes puntuaciones en tareas como AIME '25. El equilibrio entre la calidad de los resultados y la eficiencia de los tokens lo convierte en una solución intermedia práctica para los equipos que desean un razonamiento inteligente sin necesidad de hardware a escala MoE.
Considero que el 8B es el caballo de batalla. Se mantiene rápido, predecible y económico, al tiempo que cubre una amplia gama de escenarios de producción: sistemas de chat, herramientas internas, flujos de automatización y aplicaciones RAG. No igualará al Large 3 ni al 14B en cuanto a razonamiento profundo, pero la relación coste-rendimiento es la más sólida de la familia. El uso de tokens sigue siendo bajo y los resultados siguen siendo coherentes.
Este es el modelo más pequeño y está diseñado para funcionar prácticamente en cualquier lugar. Es denso, ligero y cómodo en CPU, dispositivos móviles o hardware IoT. No lo utilizarás cuando necesites un razonamiento complejo, pero es ideal para aplicaciones sin conexión, tareas de enrutamiento, clasificadores ligeros y asistentes que necesitan respuestas inmediatas. La eficiencia de los tokens es excelente.

En los cuatro, obtienes la licencia Apache 2.0, compatibilidad multimodal con imágenes y texto, y una amplia cobertura multilingüe. Dado que los modelos se comportan de manera coherente, puedes ampliar o reducir sin necesidad de volver a aprender peculiaridades.
Aquí tienes una comparación rápida entre los modelos:
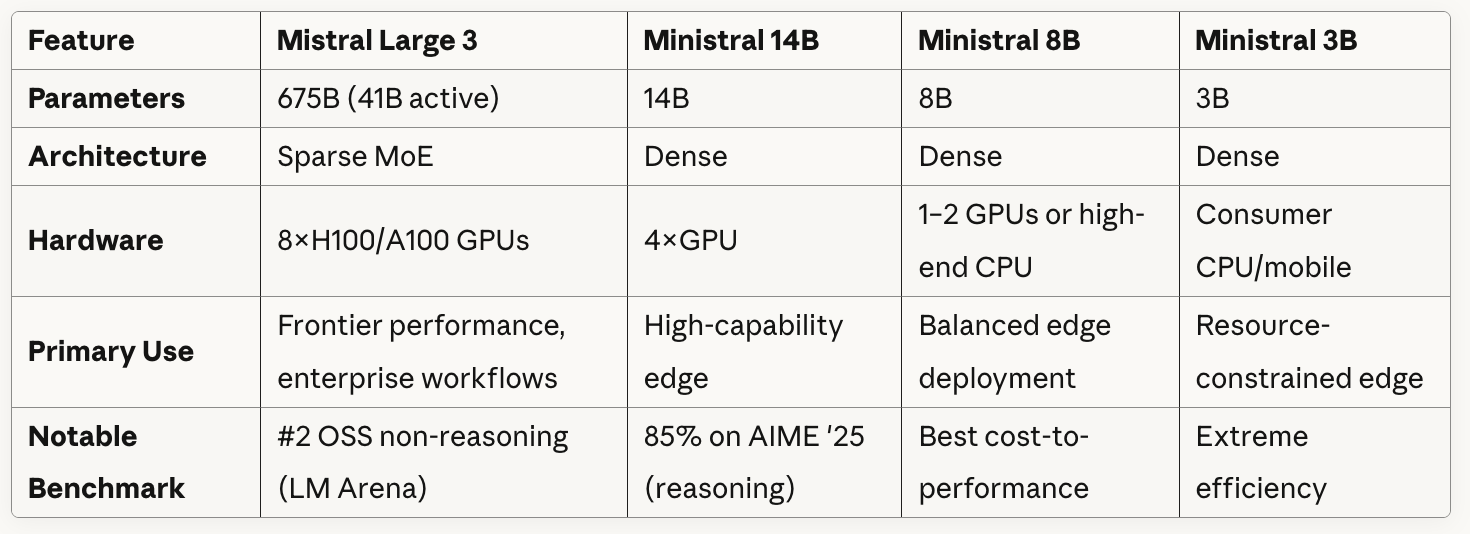
Como puedes ver en la tabla, Mistral Large 3 utiliza una arquitectura Sparse MoE con 41 000 millones de parámetros activos de un total de 675 000 millones. Básicamente, el modelo contiene múltiples redes «expertas» especializadas y, para cada token o tarea, se enruta selectivamente solo a través de un subconjunto de estos expertos en lugar de utilizar todos los parámetros.
Todos los modelos Ministral utilizan arquitecturas densas, lo que significa que todos los parámetros están activos para cada inferencia.
Si observas detenidamente lo que muestra la tabla sobre los requisitos de hardware, podrás ver una clara relación entre el tamaño de los modelos y la flexibilidad de implementación: Mistral Large 3 requiere ocho GPU de gama alta, pero Ministral 3B puede ejecutarse en CPU/móviles de consumo.
Centré mis pruebas en Large 3. Dado que Large 3 es el modelo insignia, es tanto el más capaz como el que más gente utilizará.
Para mi primera prueba, le proporcioné a Mistral 3 Large una captura de pantalla en árabe con la siguiente indicación.
En este escenario, un cliente describe un problema con su antena parabólica. Dicen que lo han reinstalado o reposicionado, pero no funciona correctamente y no tienen conexión a Internet.

A customer sent the attached error message screenshot showing an error in Arabic.
Please:
1. Read and translate the error message from the screenshot
2. Write a troubleshooting guide in English for our support team (3-4 steps)
3. Translate that solution back to Levantine Arabic in a natural, conversational way the customer would understandPrimero, Large 3 tradujo el mensaje y me preocupó que pudiéramos estar yendo en la dirección equivocada. No hace falta ser hablante nativo de árabe para darse cuenta de que la versión en inglés no es correcta.

Large 3 continuó y me dio instrucciones en árabe que yo podía dar como respuesta.
A pesar de que la traducción de Mistral de la pregunta era incorrecta, las instrucciones que me dio y que yo podía transmitir al cliente (que es la parte más útil) tenían sentido. Los puntos 1 a 3 se leen bien en árabe (lo sé porque solicité ayuda para traducirlos), pero Mistral cometió un error en el cuarto punto al referirse a «soporte artístico» en lugar de «soporte técnico».

Como nota final, descubrí que Mistral era fiel al dialecto árabe que se te había solicitado. La conversación fue notablemente levantina.
A continuación, te pedí que realizases una tarea de programación pequeña pero realista:
Write a Python function that takes a list of timestops (ISO format) and returns time gaps between each consecutive time gap in minutes. Make the function safe against invalid entries.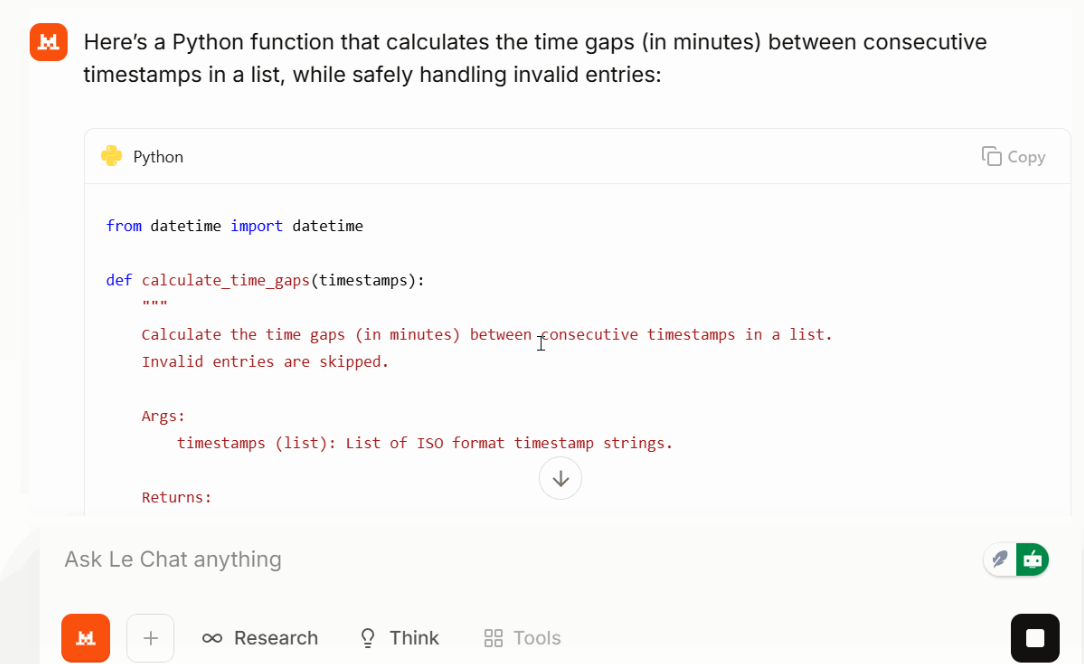
Large 3 devolvía una función corta y legible con un manejo de errores sensato y entradas ordenadas. En mi prueba, la solución fue compacta y el resultado se mantuvo enfocado. Dependiendo de la indicación y la tarea, esto podría ayudar a mantener el uso de tokens por debajo de lo esperado.
Para comprobar el razonamiento en varios pasos sin cambiar a un modo específico, utilicé un rompecabezas clásico:
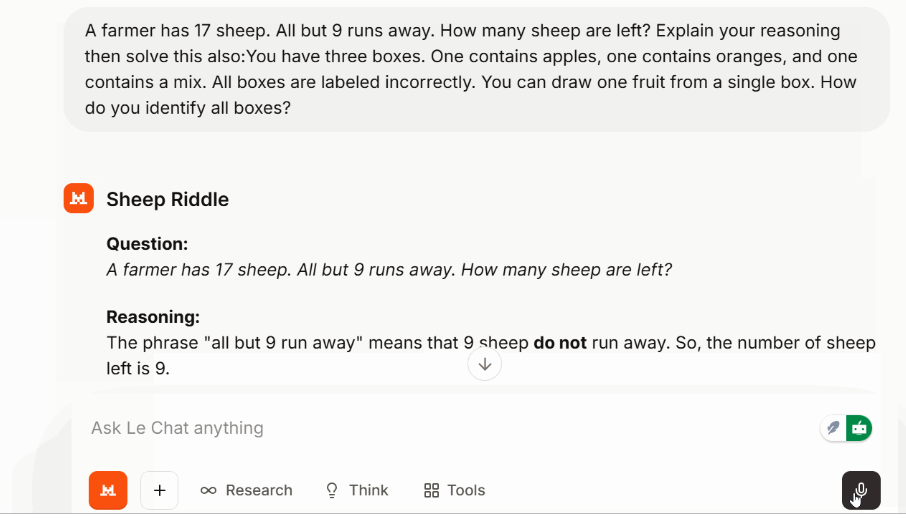
También se resolvió limpiamente y sin titubeos un rompecabezas lógico posterior sobre cajas de fruta mal etiquetadas.
Los puntos de referencia no lo son todo, pero ayudan a situar el modelo en su contexto. Mistral compara Large 3 principalmente con otros productos de código abierto similares, como DeepSeek-3.1 y Kimi-K2, lo cual tiene sentido dada la licencia Apache 2.0.
Large 3 obtiene buenos resultados en las evaluaciones de razonamiento, GSM8K, AIME y codificación. De hecho, es el modelo de codificación de código abierto que actualmente ocupa el primer puesto en la clasificación de LMArena. Los primeros resultados de SWE-Bench muestran que resuelve tareas de ingeniería de software a un nivel comparable al de otros sistemas densos y MoE de alta capacidad. Los modelos Ministral también ocupan posiciones sólidas en relación con su tamaño.
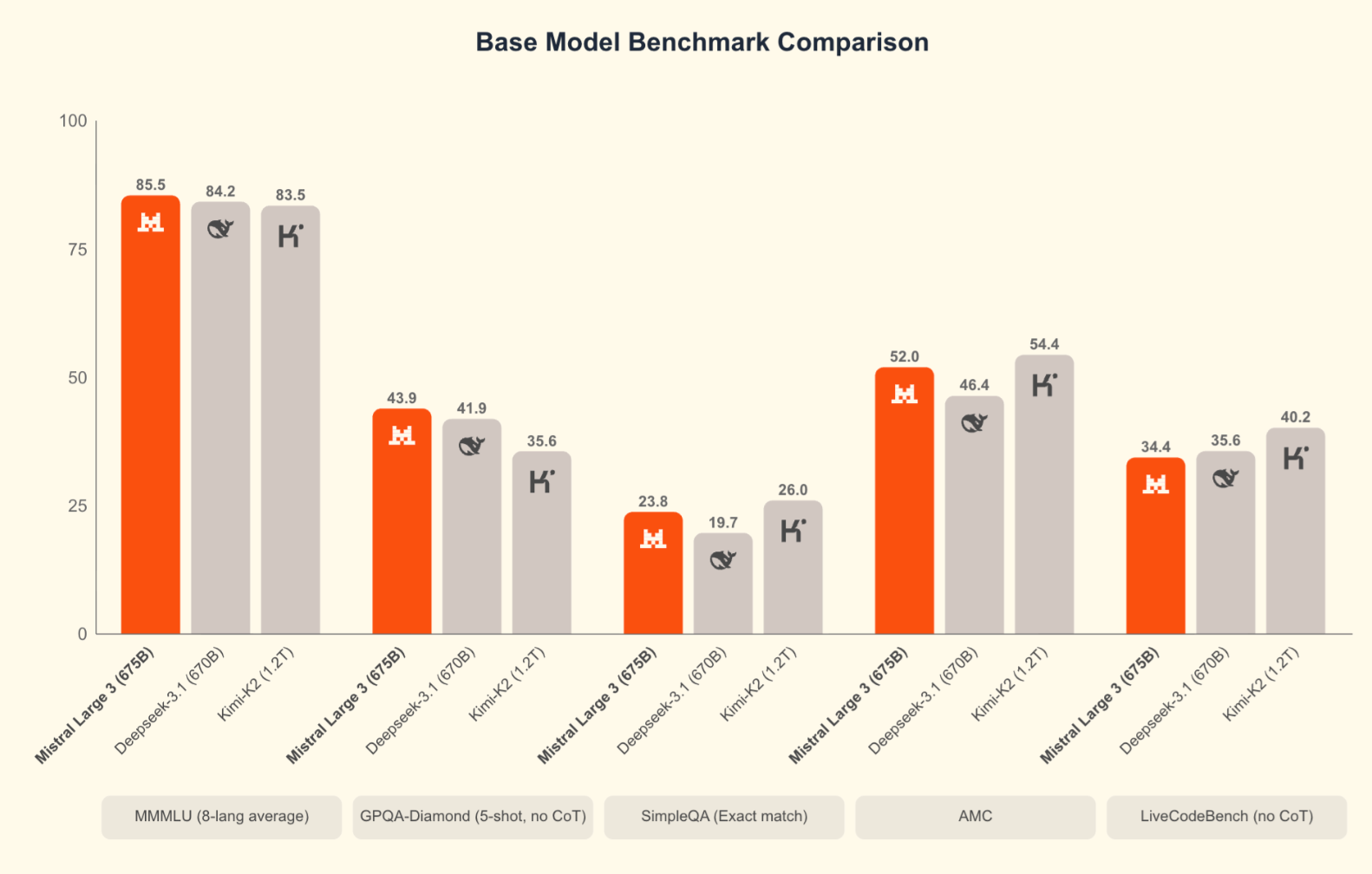
Cabe destacar que en las comparaciones de Mistral no aparecen los modelos Frontier lanzados a finales de noviembre: Gemini 3 Pro (que obtiene una puntuación del 91,9 % en GPQA Diamond y 1501 Elo en LMArena), GPT-5.1y Claude Opus 4.5 (que lidera SWE-bench Verified con más del 80 %). Cuando se compara Large 3 con estos modelos, los sistemas patentados siguen teniendo ventaja en las pruebas de razonamiento más difíciles y en las tareas agenticas complejas. Eso es cierto. Sin embargo, para muchas cargas de trabajo prácticas, especialmente si se tiene en cuenta la capacidad de autohospedar, ajustar y desplegar sin dependencia de un proveedor, Large 3 ofrece un rendimiento competitivo.
|
Característica |
Mistral Grande 3 |
Gemini 3 Pro |
GPT-5.1 |
Claude Opus 4.5 |
|
Tipo |
MoE disperso, pesos abiertos |
Multimodal patentado |
Multimodal patentado |
Centrado en el razonamiento propio |
|
Licencias |
Apache 2.0 |
Cerrado |
Cerrado |
Cerrado |
|
Implementación |
API, autoalojamiento completo |
Solo alojado |
Solo alojado |
Solo alojado |
|
Puntos fuertes |
Razonamiento, apertura, multilingüismo/multimodalidad |
Multimodalidad profunda, vídeo |
Codificación, uso de herramientas, tareas generales. |
Razonamiento detallado y cuidadoso |
|
Capacidad de razonamiento |
Alto |
Alto |
Muy alto |
Muy alto |
|
Capacidad de codificación |
Fuerte |
Sólido |
Muy fuerte |
Fuerte pero más lento |
|
Multimodal |
Imagen + texto |
Imagen, audio, vídeo |
Imagen + texto |
Imagen + texto |
|
Longitud del contexto |
Largo |
Extremadamente largo |
Muy largo |
Muy largo |
|
Eficiencia de los tokens |
Resultados ajustados |
Más detallado |
Conciso |
A menudo detallado/más largo |
|
Autoalojamiento |
Sí |
No |
No |
No |
|
Mejor ajuste |
Equipos que necesitan rendimiento + control |
Flujos de trabajo de vídeo/multimodales |
Agentes de producción |
Tareas analíticas profundas |
Mistral 3 es una versión potente para el ecosistema abierto. La combinación de eficiencia de tokens, profundidad multilingüe y manejo de contextos largos lo hace significativo. Es una combinación de capacidad y apertura a una escala que nunca antes habíamos visto. Large 3 se acerca a los mejores sistemas propietarios, pero sigue siendo algo que puedes descargar, examinar e implementar como quieras.
Si hay algo que te permite mantener tus expectativas estables, es una planificación muy minuciosa. Large 3 funciona bien, pero modelos como Opus y GPT manejan el razonamiento de cadena larga con mayor consistencia. Sin embargo, en la mayoría de las aplicaciones reales, la diferencia es pequeña.
Hay varias formas de empezar, dependiendo de cómo pienses utilizar los modelos.
Si solo quieres probarlos, la API alojada es la opción más sencilla. Los cuatro niveles (Large 3, 14B, 8B y 3B) están disponibles con una clave API estándar. La facturación se basa en tokens y es la forma más rápida de probar el razonamiento, las indicaciones multimodales o las tareas multilingües.
Si prefieres tener un control total, puedes descargar las plantillas abiertas. Cuando Mistral los denomina «los mejores modelos permisivos de peso abierto», se refieren a:
El Large 3 requiere un hardware potente, pero los modelos Ministral se adaptan sin problemas. También puedes utilizar plataformas asociadas si deseas probar diferentes backends sin necesidad de ejecutar tus propias máquinas.
En este artículo he mencionado un par de casos de uso, pero ahora quiero dedicar más tiempo a escribir sobre cómo veo que los equipos utilizan cada nivel en la práctica. El equipo directivo de Mistral apuesta firmemente por que la mayoría de las empresas pueden trabajar con modelos pequeños y abiertos que se pueden ajustar con precisión.
Me imagino cómo un analista de fondos de cobertura de podría subir 50 transcripciones de conferencias sobre resultados y pedir a Mistral Large 3 que señale qué equipos directivos están cubriendo sus previsiones o cambiando de tono de un trimestre a otro. La ventana de contexto de 256k podría manejar transcripciones completas más los formularios 10-K (documentos financieros anuales) sin necesidad de fragmentarlos. O si formás parte de una empresa de inversión europea, Mistral seguramente funcionaría en francés, alemán, italiano (o árabe, como probamos).
Si esto te parece descabellado, quizá no debería, porque HSBC anunció un acuerdo con Mistral esta misma semana.
Mistral 3 finalmente le da a Mistral una estructura coherente y modelos que se adaptan de forma natural a diferentes restricciones. Large 3 compite con los principales sistemas propietarios, mientras que la gama Ministral facilita la elección del nivel que mejor se adapta a tus necesidades de hardware y latencia.
Si tienes pensado experimentar, la API alojada es la forma más rápida de empezar. Y si deseas crear localmente o autohospedar, descargar los pesos te da un control total.
Si tienes curiosidad por saber cómo funcionan modelos como Mistral, nuestro curso Conceptos de modelos de lenguaje grandes te resultará muy útil, y si estás integrando Mistral en una aplicación, el cursoFundamentos de API en Python te ayudará con la parte práctica.
Aprende con DataCamp
Curso
Curso
Curso
blog
Ryan Ong
8 min
blog
Stanislav Karzhev
9 min
blog
Natassha Selvaraj
15 min
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Dimitri Didmanidze

