

Course
Understanding Artificial Intelligence
2 hr
401.5K
It’s possible that many enterprise workloads don't need frontier-scale models, and what they really need is fast, cost-effective inference on specific tasks. I’m thinking about customer support routing, document classification, code completion.
This is the story that Mistral AI is betting on: compact, open-weight models, which can be fine-tuned on domain data, and that can run efficiently at scale.
To that end, just this week Mistral has released Mistral 3, and I think it goes a long way towards accomplishing that goal. First, the models themselves have promise: Mistral Large 3, the flagship, outperforms its open-source competitors, Kimi-K2 and Deepseek-3.1, on important benchmark tests. Secondly, Mistral is making their product offering more clear. You see, this is the first time Mistral AI has released a full family of models. (When Medium 3 dropped earlier this year, it wasn’t immediately obvious (from the name alone) that it was supposed to outperform Large 2, which was released last year.)
Mistral 3 is Mistral AI’s newest generation of models built on a shared architecture and feature set. Instead of releasing one-off variants, Mistral has moved to a unified family where every model supports multilingual prompts, multimodal inputs, and the same core capabilities. The idea is to give developers a consistent baseline no matter which size they choose.
This generation also focuses on improving reasoning, efficiency, and practical usability across the board. Whether you're running tests in the cloud or building applications that need faster inference, Mistral 3 introduces a clearer and more predictable foundation to build on.
I mentioned that Mistral 3 is really a family of models. There are four in all, and they all target different constraints, reasoning depth, hardware limits, latency, and deployment environments. That said, one model stands apart: Large 3 is built for a very different class of workloads than the smaller tiers, which are designed with practicality and deployment flexibility in mind.
Mistral Large 3 is the flagship model in the generation. It uses a sparse MoE architecture with 675B parameters, of which roughly 41B are active during inference, and this naturally comes with higher hardware requirements. The model is designed for workloads that rely on strong reasoning, long-context processing, and consistent output quality. It performs well in open-source evaluations, including top results on LMArena’s non-reasoning leaderboard. Token efficiency is good, though the computational cost reflects its size.
This is the strongest dense model in the family. It’s a good option when you want real capability without stepping into multi-GPU cluster territory. It runs comfortably on a single high-end GPU setup (four GPUs if you want headroom) and pulls strong scores on tasks like AIME ’25. The balance of output quality and token efficiency makes it a practical middle ground for teams that want smart reasoning without MoE-scale hardware. You can read our separate tutorial on fine-tuning Ministral 3.
I think of 8B as the workhorse. It stays fast, predictable, and inexpensive while covering a wide range of production scenarios: chat systems, internal tools, automation flows, and RAG applications. It won’t match Large 3 or 14B on deep reasoning, but the cost-to-performance ratio is the strongest in the family. Token usage stays low, and outputs remain coherent.
This is the smallest model and is designed to run almost anywhere. It’s dense, lightweight, and comfortable on CPUs, mobile devices, or IoT hardware. You won’t reach for it when you need complex reasoning, but it’s ideal for offline apps, routing tasks, lightweight classifiers, and assistants that need immediate responses. Token efficiency is excellent.

Across all four, you get Apache 2.0 licensing, multimodal image+text support, and broad multilingual coverage. Because the models behave consistently, you can scale up or down without relearning quirks.
Here’s how the models compare at a glance:
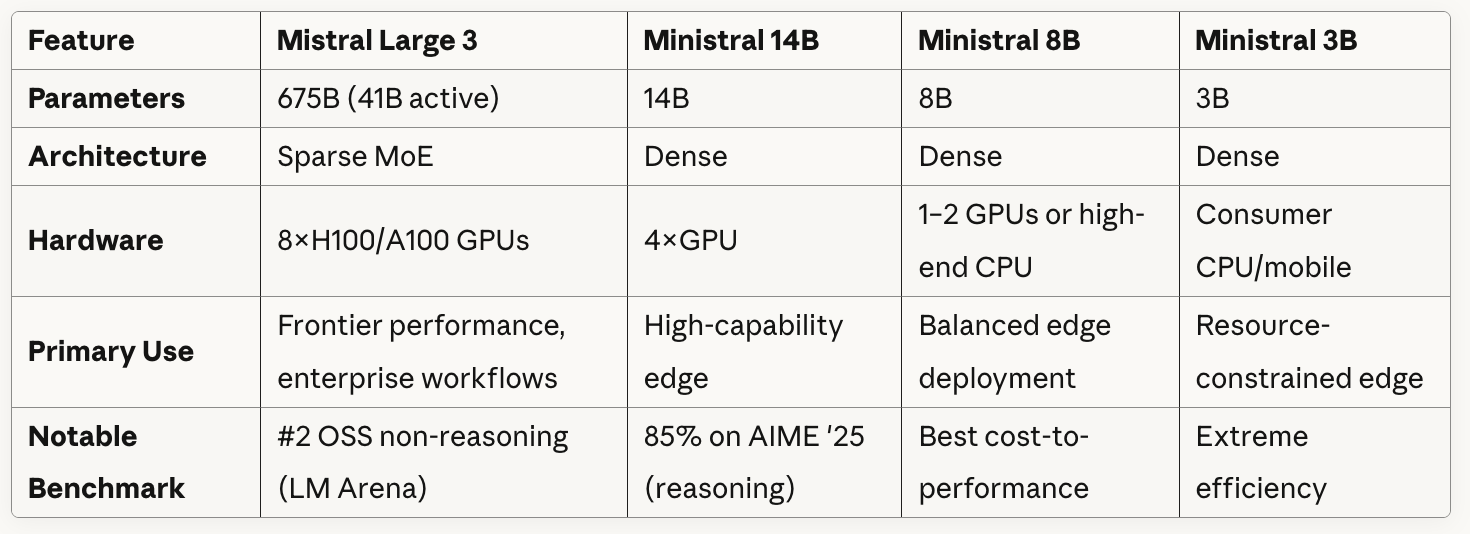
As you can see in the table, Mistral Large 3 uses a Sparse MoE architecture with 41 billion active parameters out of 675 billion total. Basically, the model contains multiple specialized "expert" networks, and for each token or task, it selectively routes through only a subset of these experts rather than using all parameters.
The Ministral models all use dense architectures, meaning all parameters are active for every inference.
If you look closely at what the table shows about hardware requirements, you can see a clear tradeoff between the model sizes and the deployment flexibility: Mistral Large 3 requires eight high-end GPUs but Ministral 3B can run on consumer CPU/mobile.
I focused my testing on Large 3. Since Large 3 is the flagship, it's both the most capable model and also the one most people will use.
For my first test, I gave Mistral 3 Large a screenshot in Arabic with the following prompt.
In this scenario, a customer is describing a problem with their satellite dish. They're saying they reinstalled or repositioned it, but it's not working properly, and their internet connection is down.

A customer sent the attached error message screenshot showing an error in Arabic.
Please:
1. Read and translate the error message from the screenshot
2. Write a troubleshooting guide in English for our support team (3-4 steps)
3. Translate that solution back to Levantine Arabic in a natural, conversational way the customer would understandFirst, Large 3 translated the message, and I worried we might be heading in the wrong direction. You don’t have to be a native Arabic speaker to understand that the English version is off.

Despite the fact that Mistral’s mistranslated parts of the question, its directions to the customer (which is the more useful part) made sense. Numbers 1-3 read well in Arabic (I know this because I solicited some human translation help), but Mistral did create an error in the 4th point when it referenced “art support” instead of “tech support.”

I was impressed that Mistral was true to the dialect of Arabic I asked for. The conversation was notably Levantine.
Next, I asked it for a small but realistic coding task:
Write a Python function that takes a list of timestops (ISO format) and returns time gaps between each consecutive time gap in minutes. Make the function safe against invalid entries.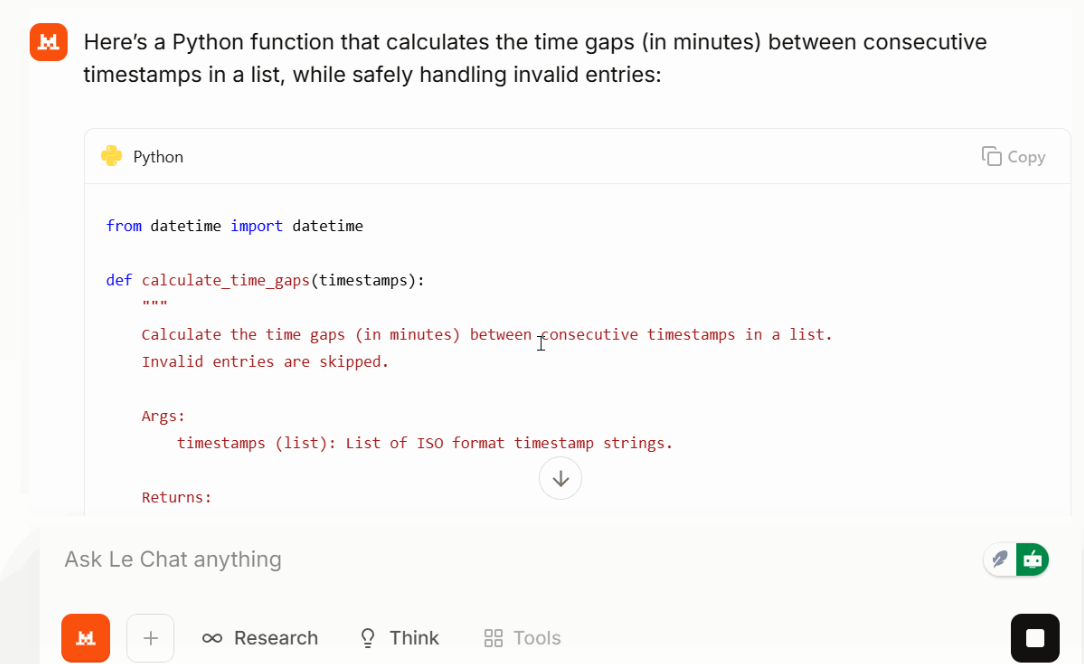
Large 3 returned a short, readable function with sensible error handling and sorted inputs. In my test, the solution was compact, and the output stayed focused. Depending on the prompt and task, this could help keep token usage lower than expected.
To check multi-step reasoning without switching into a dedicated mode, I used a classic puzzle:
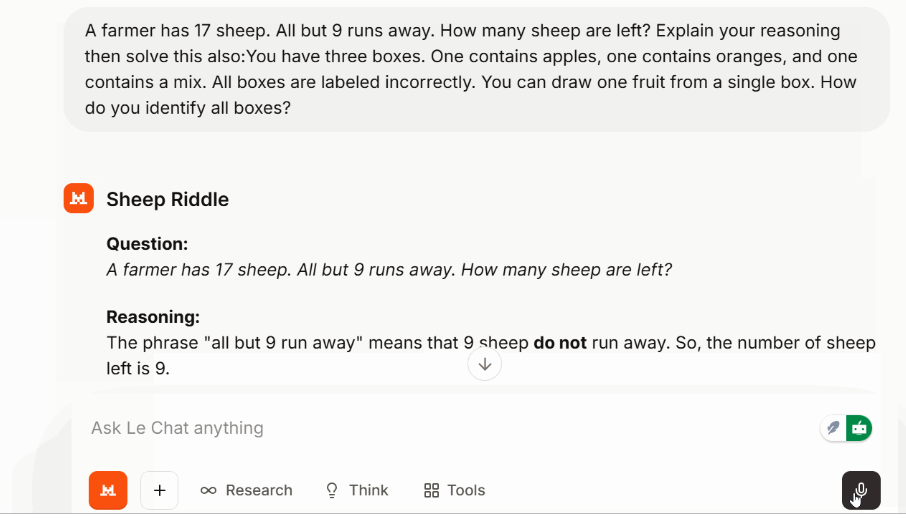
A follow-up logic puzzle about mislabeled fruit boxes was also solved cleanly without wandering.
Benchmarks aren’t everything, but they help place the model in context. Mistral compares Large 3 primarily against open-source peers like DeepSeek-3.1 and Kimi-K2, which makes sense given the Apache 2.0 license.
Large 3 performs well across reasoning, GSM8K, AIME, and coding evaluations. It’s actually the current top open source coding model on the LMArena leaderboard. Early SWE-Bench results show it solving software engineering tasks at a level comparable to other high-capacity dense and MoE systems. The Ministral models also hold strong positions relative to their size.
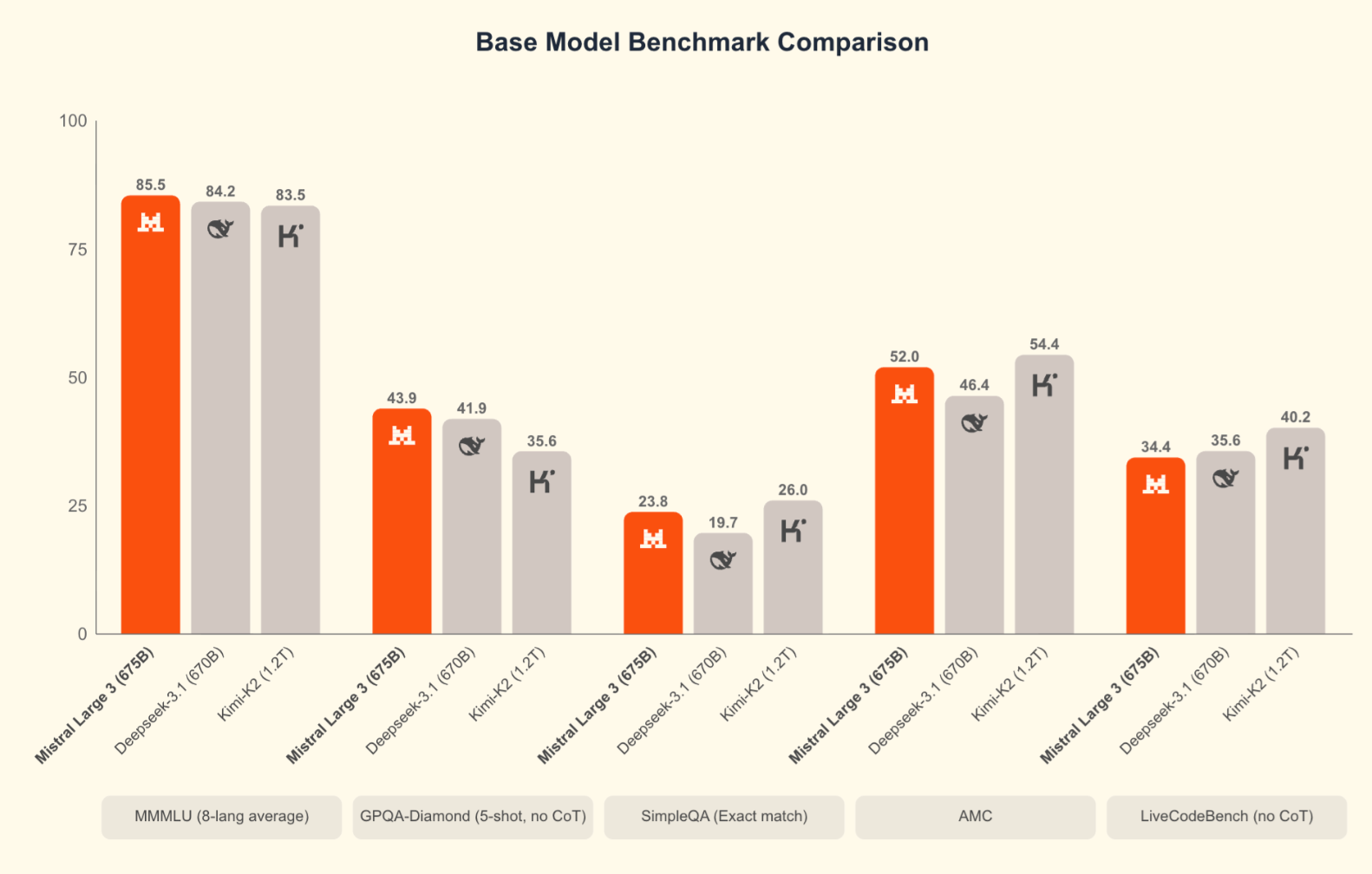
Notably absent from Mistral's comparisons are the frontier models released in late November: Gemini 3 Pro (which scores 91.9% on GPQA Diamond and 1501 Elo on LMArena), GPT-5.1, and Claude Opus 4.5 (which leads on SWE-bench Verified at over 80%). When you put Large 3 alongside these models, the proprietary systems still hold an edge on the hardest reasoning benchmarks and complex agentic tasks. That is true. But for many practical workloads, especially when you factor in the ability to self-host, fine-tune, and deploy without vendor lock-in, Large 3 delivers competitive performance.
| Feature | Mistral Large 3 | Gemini 3 Pro | GPT-5.1 | Claude Opus 4.5 |
|---|---|---|---|---|
| Licensing | Apache 2.0 (open-weight) | Closed | Closed | Closed |
| Context Window | 256K | 1M | 272K | 200K |
| Multimodal | Text + images | Text, images, video, audio, code | Text, images, audio | Text + images |
| Top Benchmark | #2 OSS (LMArena) | 1501 Elo (LMArena #1) | Improved AIME/Codeforces | 80.9% SWE-bench Verified |
| Coding | Strong multilingual | 76.2% SWE-bench, 1487 WebDev Elo | Adaptive reasoning | 80.9% SWE-bench (best) |
| Best For | Open deployment, edge to enterprise | Multimodal tasks, long context | Conversational AI, general use | Software engineering, agents |
| API Pricing | ~80% cheaper than GPT-4o | $2/$12 per M tokens | Not specified | $5/$25 per M tokens |
Mistral 3 is a strong release for the open ecosystem. The combination of token efficiency, multilingual depth, and long-context handling makes it significant. It is a combination of capability and openness at a scale we haven’t seen before. Large 3 comes close to the top proprietary systems while still being something you can download, inspect, and deploy however you want.
If there’s one place to keep expectations steady, it’s on the more complex reasoning tasks and agentic capabilities. Large 3 does well, but models like Opus 4.5 and GPT 5.1 do handle long-chain reasoning with more consistency.
There are a few ways to get started, depending on how you plan to use the models.
If you just want to try them, the hosted API is the simplest route. All four tiers—Large 3, 14B, 8B, and 3B are available with a standard API key. Billing is token-based, and it’s the fastest way to test reasoning, multimodal prompts, or multilingual tasks.
If you prefer full control, the open weights are available to download. When Mistral calls these the “best permissive open-weight models,” they mean:
Large 3 requires serious hardware, but the Ministral models scale down smoothly. You can also use partner platforms if you want to experiment with different backends without running your own machines.
I surfaced a couple of use cases in this article, but I want to spend more time now writing about how I could see teams actually using each tier in practice. The leadership team at Mistral is really betting that most enterprises can do things with small, open-weight models that you can fine-tune.
I'm imagining how a hedge fund analyst might upload 50 earnings call transcripts and ask Mistral Large 3 to flag which management teams are hedging on guidance or shifting tone quarter-over-quarter. The 256k context window would handle entire transcripts plus 10-Ks (annual finance docs) without chunking. Or if you’re part of a European investment firm, Mistral would surely work across French, German, Italian, (or Arabic, as we tried).
If this sounds far-fetched, maybe it shouldn’t, because HSBC announced a deal with Mistral just this week.
Mistral 3 finally gives Mistral a consistent structure and models that scale naturally across different constraints. Large 3 holds its own against the major proprietary systems, while the Ministral lineup makes it easy to choose a tier that fits your hardware and latency needs.
If you're planning to experiment, the hosted API is the quickest way to start. And if you want to build locally or self-host, downloading the weights gives you full control.
If you are curious about how models like Mistral work under the hood, you will get a lot out of our Large Language Models Concepts course, and if you're wiring Mistral into an application, API Fundamentals in Python helps with the practical side.
Learn with DataCamp
Course
Course
Course
blog
Ryan Ong
8 min
Tutorial
Josep Ferrer
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Bex Tuychiev
Tutorial
Hesam Sheikh Hassani
