

Curso
Entendendo a inteligência artificial
2 h
401.5K
É possível que muitas cargas de trabalho empresariais não precisem de modelos de ponta, e o que elas realmente precisam é de uma inferência rápida e econômica em tarefas específicas. Estou pensando em roteamento de suporte ao cliente, classificação de documentos, autocompletar código.
Essa é a história em que a Mistral AI está apostando: modelos compactos e de peso aberto, que podem ser ajustados com base em dados do domínio e que podem funcionar de forma eficiente em grande escala.
Para isso, ainda esta semana a Mistral lançou o Mistral 3, e acho que ele vai ajudar bastante a alcançar esse objetivo. Primeiro, os próprios modelos são promissores: O Mistral Large 3, o carro-chefe, supera seus concorrentes de código aberto Kimi-K2 e Deepseek-3.1 em testes de benchmark importantes. Em segundo lugar, a Mistral está deixando sua oferta de produtos mais clara. Olha só, essa é a primeira vez que a Mistral AI lança uma família completa de modelos. (Quando o Medium 3 foi lançado no começo deste ano, não ficou claro logo de cara (só pelo nome) que ele deveria superar o Large 2, que saiu no ano passado.)
O Mistral 3 é a baseada em uma arquitetura e um conjunto de recursos compartilhados. Em vez de lançar variantes únicas, a Mistral mudou para uma família unificada, onde todos os modelos suportam prompts multilíngues, entradas multimodais e os mesmos recursos básicos. A ideia é dar aos desenvolvedores uma base consistente, não importa o tamanho que escolherem.
Essa geração também se concentra em melhorar o raciocínio, a eficiência e a usabilidade prática em todos os aspectos. Se você está fazendo testes na nuvem ou criando aplicativos que precisam de inferência mais rápida, o Mistral 3 traz uma base mais clara e previsível para você trabalhar.
Eu falei que o Mistral 3 é, na verdade, uma família de modelos. São quatro no total, e todos eles focam em diferentes restrições, profundidade de raciocínio, limites de hardware, latência e ambientes de implantação. Dito isso, um modelo se destaca: O Large 3 foi feito pra um tipo de carga de trabalho bem diferente das camadas menores, que foram pensadas pra serem práticas e fáceis de implementar.
O Mistral Large 3 é o modelo principal dessa geração. Ele usa uma arquitetura MoE esparsa com 675 bilhões de parâmetros, dos quais aproximadamente 41 bilhões estão ativos durante a inferência, e isso naturalmente vem com requisitos de hardware mais elevados. O modelo foi feito pra lidar com cargas de trabalho que dependem de raciocínio forte, processamento de contexto longo e qualidade de saída consistente. Tem um bom desempenho em avaliações de código aberto, incluindo os melhores resultados no ranking sem raciocínio da LMArena. A eficiência do token é boa, embora o custo computacional reflita seu tamanho.
Esse é o modelo denso mais forte da família. É uma boa opção quando você quer capacidade real sem entrar no território dos clusters com várias GPUs. Ele roda bem em uma única configuração de GPU de ponta (quatro GPUs se você quiser mais espaço) e tem ótimas pontuações em tarefas como o AIME '25. O equilíbrio entre a qualidade da produção e a eficiência dos tokens torna-o um meio-termo prático para equipes que querem raciocínio inteligente sem hardware em escala MoE.
Eu vejo o 8B como o cavalo de batalha. Ele continua rápido, previsível e barato, cobrindo uma ampla gama de cenários de produção: sistemas de chat, ferramentas internas, fluxos de automação e aplicativos RAG. Não vai chegar ao nível do Large 3 ou do 14B em termos de raciocínio profundo, mas a relação custo-desempenho é a melhor da família. O uso de tokens continua baixo e os resultados continuam coerentes.
Esse é o modelo menor e foi feito pra funcionar em quase qualquer lugar. É compacto, leve e confortável em CPUs, dispositivos móveis ou hardware IoT. Você não vai recorrer a ele quando precisar de raciocínio complexo, mas ele é ideal para aplicativos offline, tarefas de roteamento, classificadores leves e assistentes que precisam de respostas imediatas. A eficiência do token é excelente.

Em todos os quatro, você tem licença Apache 2.0, suporte multimodal para imagens e texto e ampla cobertura multilíngue. Como os modelos funcionam de forma consistente, você pode aumentar ou diminuir a escala sem precisar reaprender peculiaridades.
Veja aqui uma comparação rápida entre os modelos:
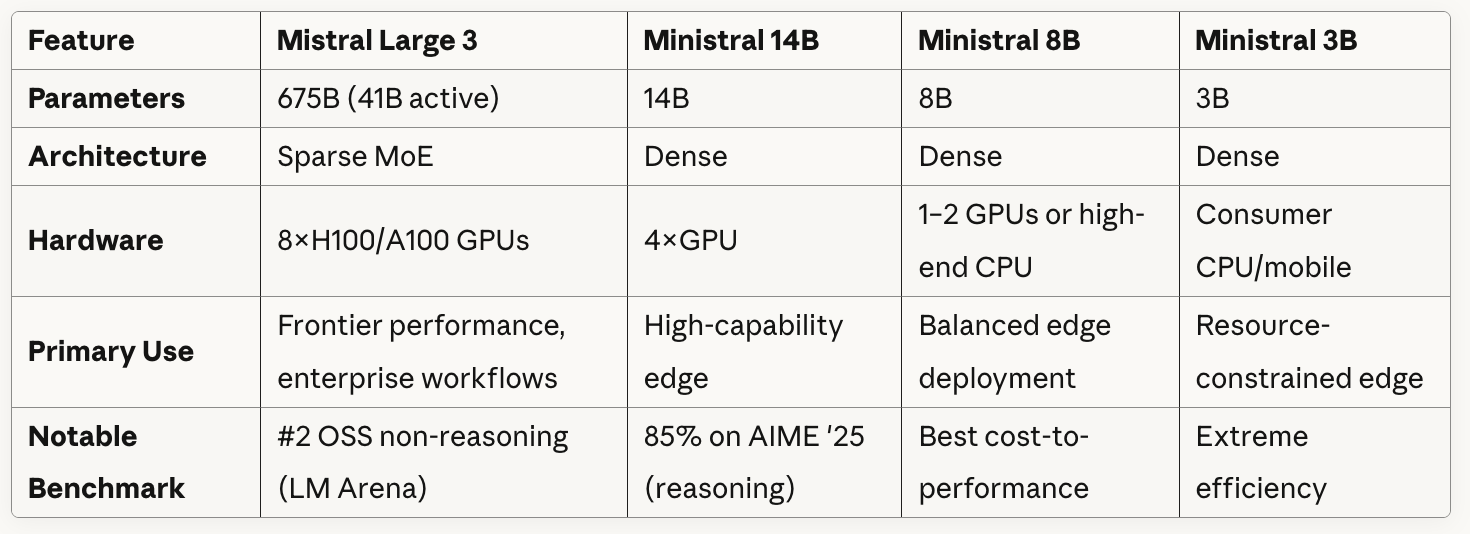
Como você pode ver na tabela, o Mistral Large 3 usa uma arquitetura Sparse MoE com 41 bilhões de parâmetros ativos de um total de 675 bilhões. Basicamente, o modelo tem várias redes “especializadas” e, para cada token ou tarefa, ele escolhe apenas um subconjunto dessas redes em vez de usar todos os parâmetros.
Todos os modelos Ministral usam arquiteturas densas, o que significa que todos os parâmetros estão ativos para cada inferência.
Se você olhar com atenção o que a tabela mostra sobre os requisitos de hardware, vai ver uma troca clara entre os tamanhos dos modelos e a flexibilidade de implantação: O Mistral Large 3 precisa de oito GPUs de última geração, mas o Ministral 3B pode rodar em CPUs/dispositivos móveis comuns.
Concentrei meus testes no Large 3. Como o Large 3 é o carro-chefe, ele é o modelo mais potente e também o que a maioria das pessoas vai usar.
No meu primeiro teste, enviei ao Mistral 3 Large uma captura de tela em árabe com a seguinte solicitação.
Nesse cenário, um cliente está contando um problema com sua antena parabólica. Eles dizem que reinstalaram ou reposicionaram, mas não está funcionando direito e a conexão com a internet deles está fora do ar.

A customer sent the attached error message screenshot showing an error in Arabic.
Please:
1. Read and translate the error message from the screenshot
2. Write a troubleshooting guide in English for our support team (3-4 steps)
3. Translate that solution back to Levantine Arabic in a natural, conversational way the customer would understandPrimeiro, o Large 3 traduziu a mensagem, e eu fiquei preocupado que a gente pudesse estar indo na direção errada. Você não precisa ser um falante nativo de árabe para perceber que a versão em inglês está errada.

Grande 3 continuou e me deu instruções em árabe que eu poderia usar como resposta.
Mesmo que a tradução da pergunta feita pelo Mistral estivesse errada, as instruções que ele me deu e que eu pude passar pro cliente (que é a parte mais útil) faziam sentido. Os números 1 a 3 ficaram bem em árabe (sei disso porque pedi ajuda com a tradução), mas o Mistral errou no quarto ponto, quando falou em “suporte artístico” em vez de “suporte técnico”.

Como nota final, descobri que o Mistral era fiel ao dialeto árabe que eu pedi. A conversa foi bem levantina.
Depois, pedi pra ele fazer uma tarefa de programação pequena, mas realista:
Write a Python function that takes a list of timestops (ISO format) and returns time gaps between each consecutive time gap in minutes. Make the function safe against invalid entries.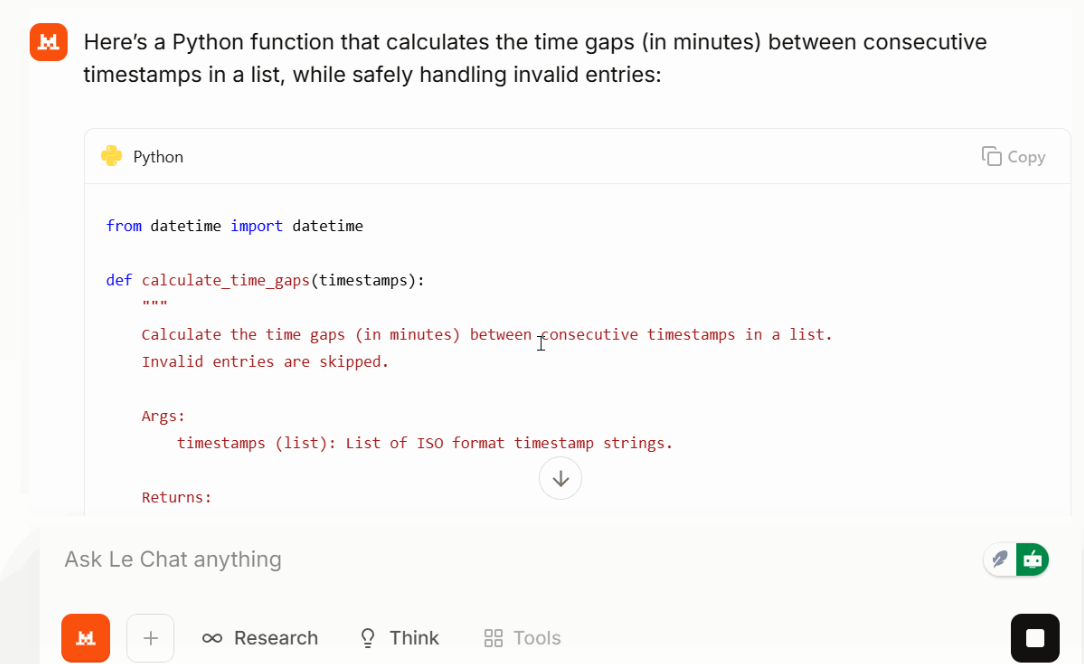
Large 3 retornou uma função curta e legível, com tratamento de erros sensato e entradas classificadas. No meu teste, a solução foi compacta e o resultado ficou bem focado. Dependendo do prompt e da tarefa, isso pode ajudar a manter o uso de tokens mais baixo do que o esperado.
Pra conferir o raciocínio em várias etapas sem mudar pra um modo específico, usei um quebra-cabeça clássico:
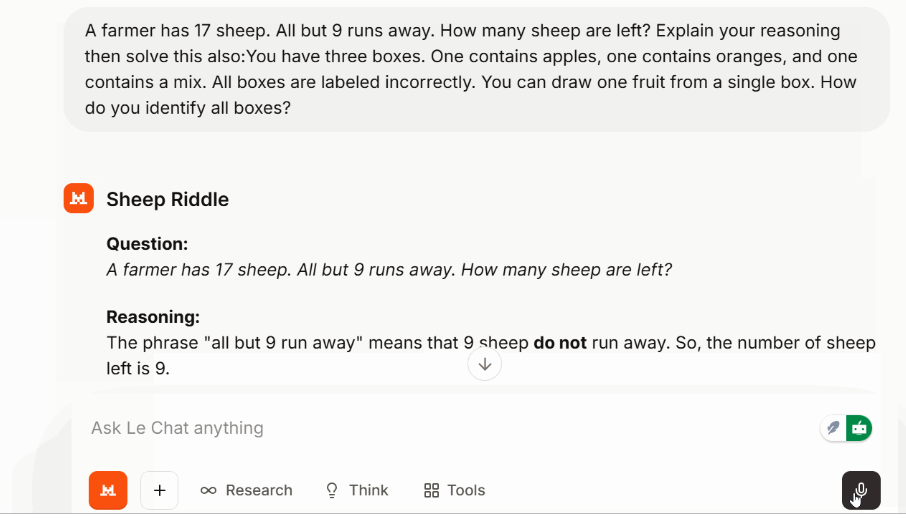
Um quebra-cabeça lógico sobre caixas de frutas com etiquetas erradas também foi resolvido sem complicações.
Os benchmarks não são tudo, mas ajudam a colocar o modelo em contexto. A Mistral compara o Large 3 principalmente com outros programas de código aberto, como o DeepSeek-3.1 e Kimi-K2, o que faz sentido, dada a licença Apache 2.0.
O Large 3 tem um bom desempenho nas avaliações de raciocínio, GSM8K, AIME e codificação. Na verdade, é o modelo de codificação de código aberto mais popular no ranking da LMArena. Os primeiros resultados do SWE-Bench mostram que ele resolve tarefas de engenharia de software em um nível comparável a outros sistemas densos e MoE de alta capacidade. Os modelos Ministral também têm uma posição forte em relação ao seu tamanho.
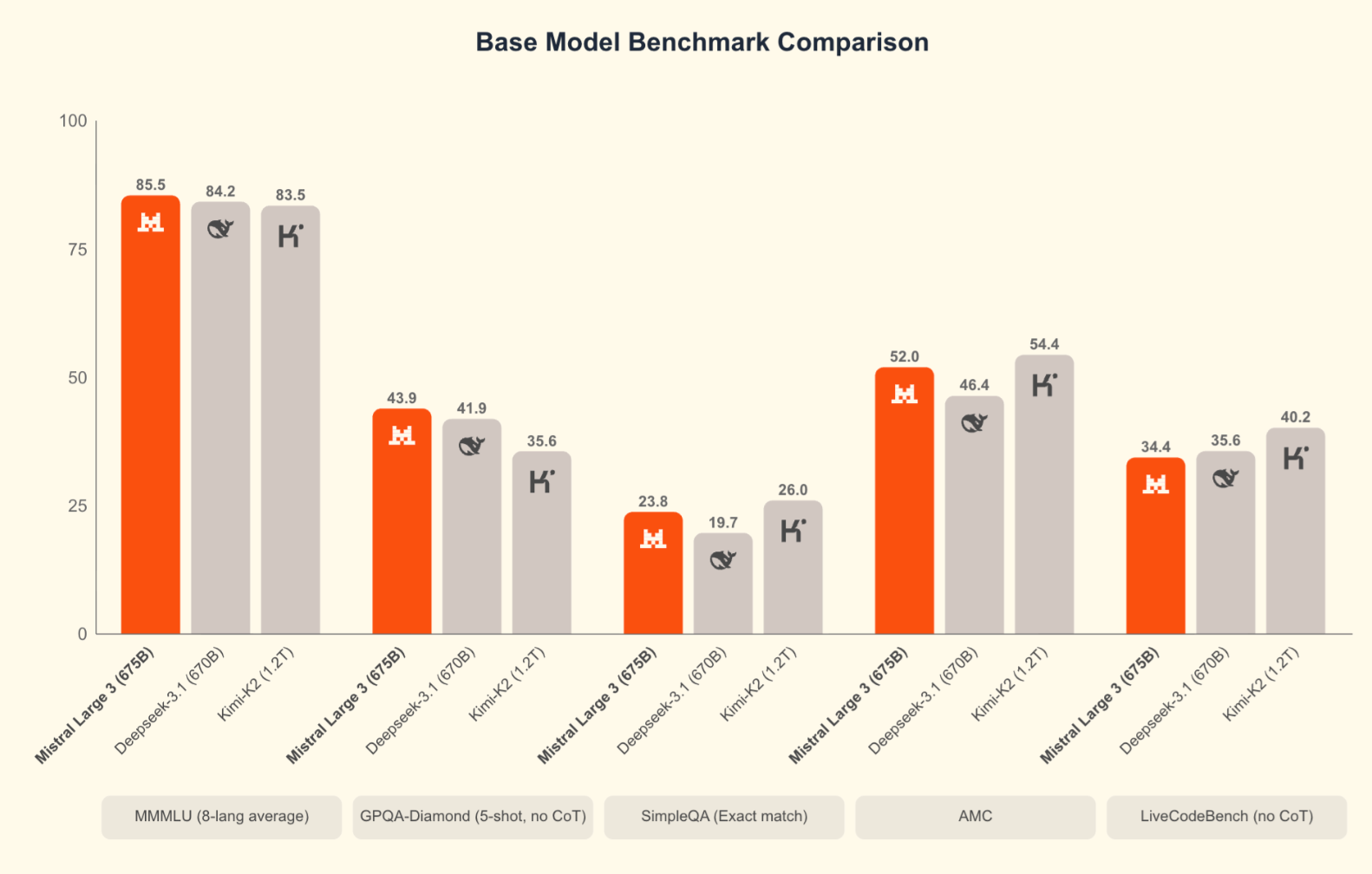
Notavelmente ausentes das comparações da Mistral estão os modelos de ponta lançados no final de novembro: Gemini 3 Pro (que tem uma pontuação de 91,9% no GPQA Diamond e 1501 Elo no LMArena), GPT-5.1e Claude Opus 4.5 (que lidera no SWE-bench Verified com mais de 80%). Quando você coloca o Large 3 junto com esses modelos, os sistemas proprietários ainda têm uma vantagem nos benchmarks de raciocínio mais difíceis e nas tarefas agentivas complexas. Isso é verdade. Mas, para muitas cargas de trabalho práticas, especialmente quando você leva em consideração a capacidade de hospedar, ajustar e implantar sem dependência de fornecedores, o Large 3 oferece um desempenho competitivo.
|
Recurso |
Mistral Grande 3 |
Gemini 3 Pro |
GPT-5.1 |
Claude Opus 4.5 |
|
Tipo |
MoE esparso, pesos abertos |
Multimodal proprietário |
Multimodal proprietário |
Foco no raciocínio proprietário |
|
Licenciamento |
Apache 2.0 |
Fechado |
Fechado |
Fechado |
|
Implantação |
API, hospedagem totalmente independente |
Apenas hospedado |
Apenas hospedado |
Apenas hospedado |
|
Pontos fortes |
Raciocínio, abertura, multilíngue/multimodal |
Multimodalidade profunda, vídeo |
Codificação, uso de ferramentas, tarefas gerais |
Raciocínio cuidadoso e detalhado |
|
Capacidade de raciocínio |
Alto |
Alto |
Muito alto |
Muito alto |
|
Habilidade de codificação |
Forte |
Sólido |
Muito forte |
Forte, mas mais lento |
|
Multimodal |
Imagem + texto |
Imagem, áudio, vídeo |
Imagem + texto |
Imagem + texto |
|
Comprimento do contexto |
Long |
Muito longo |
Muito longo |
Muito longo |
|
Eficiência do token |
Resultados enxutos |
Mais detalhado |
Conciso |
Muitas vezes detalhado/mais longo |
|
Hospedagem própria |
Sim |
Não |
Não |
Não |
|
Melhor ajuste |
Equipes que precisam de desempenho + controle |
Fluxos de trabalho de vídeo/multimodais |
Agentes de produção |
Tarefas analíticas complexas |
O Mistral 3 é um lançamento importante para o ecossistema aberto. A combinação de eficiência de tokens, profundidade multilíngue e tratamento de contexto longo torna-o significativo. É uma combinação de capacidade e abertura em uma escala que nunca vimos antes. O Large 3 chega perto dos principais sistemas proprietários, mas ainda é algo que você pode baixar, conferir e usar como quiser.
Se tem um jeito de manter as expectativas sob controle, é com um planejamento super detalhado. O Large 3 funciona bem, mas modelos como o Opus e o GPT lidam com raciocínios de cadeia longa com mais consistência. Mas, pra maioria dos aplicativos reais, a diferença é pequena.
Tem várias maneiras de começar, dependendo de como você quer usar os modelos.
Se você só quer experimentá-los, a API hospedada é a opção mais simples. Todos os quatro níveis — Large 3, 14B, 8B e 3B — estão disponíveis com uma chave API padrão. A cobrança é baseada em tokens e é a maneira mais rápida de testar raciocínio, prompts multimodais ou tarefas multilíngues.
Se você prefere ter controle total, os pesos abertos estão disponíveis para download. Quando a Mistral chama esses modelos de “os melhores modelos permissivos de peso aberto”, eles querem dizer:
O Large 3 precisa de um hardware potente, mas os modelos Ministral funcionam bem em versões menores. Você também pode usar plataformas de parceiros se quiser experimentar diferentes backends sem precisar operar suas próprias máquinas.
Apresentei alguns casos de uso neste artigo, mas agora quero dedicar mais tempo a escrever sobre como vejo as equipes usando cada camada na prática. A equipe de liderança da Mistral está realmente apostando que a maioria das empresas pode fazer coisas com modelos pequenos e de peso aberto que você pode ajustar.
Estou imaginando como um analista de fundos de hedge poderia fazer o upload de 50 transcrições de teleconferências sobre resultados financeiros e pedir ao Mistral Large 3 para sinalizar quais equipes de gestão estão fazendo hedge nas orientações ou mudando o tom trimestre a trimestre. A janela de contexto de 256k daria conta de transcrições inteiras mais 10-Ks (documentos financeiros anuais) sem precisar dividir em partes. Ou se você faz parte de uma empresa de investimentos europeia, a Mistral com certeza funcionaria em francês, alemão, italiano (ou árabe, como a gente tentou).
Se isso parece improvável, talvez não deva, porque o HSBC anunciou um acordo com a Mistral justamente esta semana.
O Mistral 3 finalmente dá ao Mistral uma estrutura consistente e modelos que se adaptam naturalmente a diferentes restrições. O Large 3 não fica atrás dos principais sistemas proprietários, enquanto a linha Ministral facilita a escolha de um nível que se adapte às suas necessidades de hardware e latência.
Se você está pensando em fazer uns testes, a API hospedada é a maneira mais rápida de começar. E se você quiser fazer a compilação localmente ou hospedar por conta própria, baixar os pesos te dá controle total.
Se você está curioso para saber como modelos como o Mistral funcionam nos bastidores, você vai aprender muito com nosso curso Conceitos de Modelos de Linguagem de Grande Porte, e se você estiver conectando o Mistral a um aplicativo, o cursoFundamentos de API em Python ajuda com a parte prática.
Aprenda com o DataCamp
Curso
Curso
Curso
blog
Ryan Ong
8 min
blog
Richie Cotton
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan


