
Curso
Desarrollo de aplicaciones LLM con LangChain
3 h
46.3K
En este tutorial, aprenderemos a afinar el modelo Gemma 2 en el conjunto de datos de conversaciones entre paciente y médico. También convertiremos el modelo en formato GGUF para que pueda utilizarse localmente en el portátil sin conexión.
Conoceremos Gemma 2 y sus mejoras con respecto a las generaciones anteriores, antes de afinar el modelo Gemma 2 en el conjunto de datos de conversión paciente-médico. A continuación, fusionaremos el adaptador guardado con el modelo base, empujaremos el modelo completo al Hub de Caras Abrazadas y utilizaremos un Espacio de Caras Abrazadas para convertir y cuantizar el modelo. Por último, descargaremos el modelo cuantizado y lo utilizaremos localmente con la aplicación Jan.

Imagen del autor
Gemma 2 es la última versión de la familia Gemma de modelos abiertos de grandes lenguas (LLM) de Google. Está disponible para investigadores y desarrolladores en dos tamaños, 9.000 millones (9B) y 27.000 millones (27B) de parámetros, bajo una licencia comercial. Esto significa que puedes afinarlo en tu conjunto de datos privado e implantar el modelo afinado en producción sin ninguna restricción.
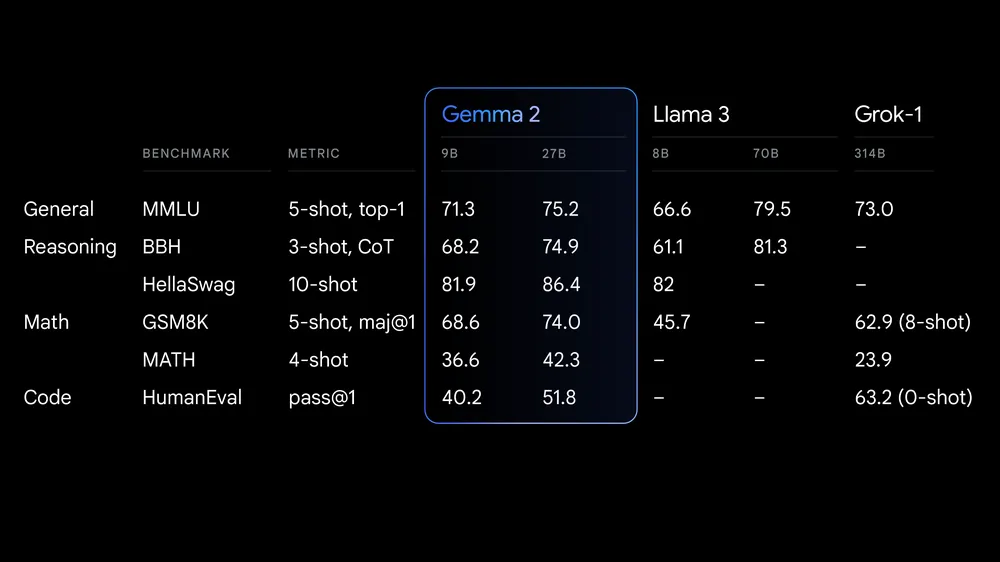
Fuente: Google launches Gemma 2
Gemma 2 ofrece avances significativos en rendimiento y eficacia de inferencia. La arquitectura rediseñada garantiza una inferencia ultrarrápida en distintas configuraciones de hardware y una integración perfecta con los principales marcos de IA, como Transformadores de Caras AbrazadasJAX, PyTorch y TensorFlow.
Gemma 2 también incluye sólidas medidas de seguridad y herramientas para el despliegue ético de la IA. Supera a Llama 3 y Groq-1 en varias pruebas comparativas y viene con una integración mejorada de Keras 3 para un ajuste fino y una inferencia del modelo sin fisuras.
Si quieres aprender sobre la primera generación de modelos Gemma, un gran recurso es nuestro tutorial, Ajuste fino Google Gemma: Mejorar los LLM con instrucciones personalizadas. Este recurso proporciona una orientación completa sobre cómo afinar los modelos Gemma, como el Gemma 7b-it, en conjuntos de datos y tareas específicas.
En esta sección, descargaremos el modelo, lo cargaremos en cuantización de 4 bits y, a continuación, ejecutaremos la inferencia en una GPU.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Nota: El modelo Gemma 2 9B-It es grande, e incluso con 16 GB de memoria GPU, no podemos cargar el modelo completo. Por eso cargamos el modelo en 4 bits cuantificación.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, AutoConfig
modelName = "google/gemma-2-9b-it"
bnbConfig = BitsAndBytesConfig(
load_in_4bit = True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(modelName)
model = AutoModelForCausalLM.from_pretrained(
modelName,
device_map = "auto",
quantization_config=bnbConfig
)from IPython.display import Markdown, display
system = "You are a skilled software architect who consistently creates system designs for various applications."
user = "Design a system with the ASCII diagram for the customer support application."
prompt = f"System: {system} \n User: {user} \n AI: "
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_length=500, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
Markdown(text.split("AI:")[1])Como vemos, el modelo Gemma 2 ha hecho un gran trabajo.
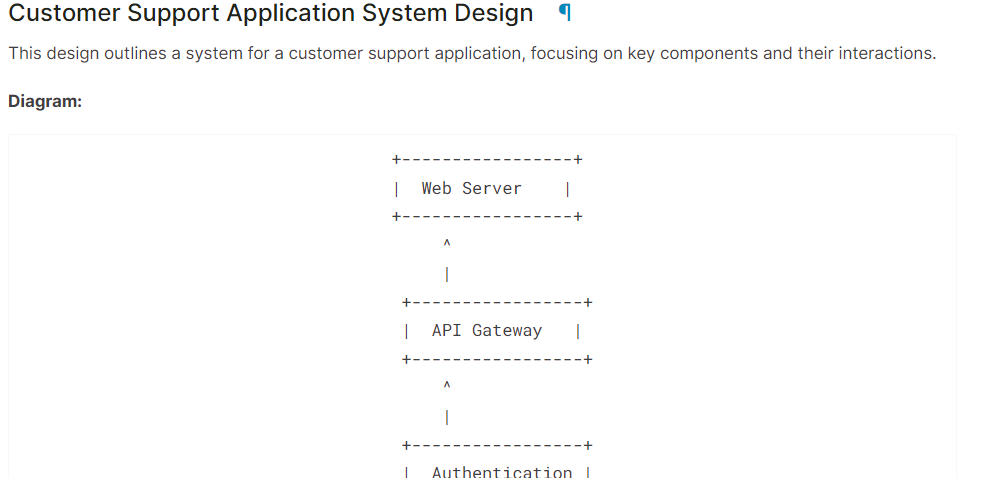
Si tienes problemas para ejecutar el código anterior, consulta el Cuaderno Kaggle: Gemma 2 Inferencia simple en la GPU.
En esta sección, afinaremos el modelo Gemma 2 9B-It sobre el conjunto de datos sanitariosque consiste en conversaciones entre pacientes y médicos. Cargaremos el modelo y el tokenizador, cargaremos el conjunto de datos, convertiremos el conjunto de datos, configuraremos el modelo utilizando argumentos de entrenamiento y seguiremos el rendimiento del modelo utilizando la API de Pesos y Sesgos.
Si te interesa comprender cómo funciona la teoría del ajuste fino, lee nuestra guía, Guía introductoria a los LLM de ajuste fino.
Instala los paquetes Python necesarios para cargar, ajustar y evaluar el modelo en el conjunto de datos médicos.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandbCarga los paquetes Python necesarios y las funciones.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_formatInicia sesión en Hugging Face CLI utilizando la clave API que hemos guardado utilizando los Secretos de Kaggle.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
Carga la clave API de Pesos y Sesgos de los secretos de Kaggle para iniciar el proyecto de seguimiento del rendimiento del modelo.
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Gemma-2-9b-it on HealthCare Dataset',
job_type="training",
anonymous="allow"
)Establecer el ID del modelo y del conjunto de datos para que podamos cargarlos desde el Hub Cara Abrazada. Además, tenemos que establecer el nombre del modelo afinado para crear un repositorio de modelos en Cara Abrazada y empujar el modelo afinado.
base_model = "google/gemma-2-9b-it"
dataset_name = "lavita/ChatDoctor-HealthCareMagic-100k"
new_model = "Gemma-2-9b-it-chat-doctor"Establecer el tipo de datos y la implementación de la atención basada en la GPU.
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
torch_dtype = torch.bfloat16
attn_implementation = "flash_attention_2"
else:
torch_dtype = torch.float16
attn_implementation = "eager"Debemos crear la configuración QLoRA para poder cargar el modelo con una precisión de 4 bits, reduciendo el uso de memoria y acelerando el proceso de ajuste fino.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
Utilizando la URL del modelo, la configuración de LoRA y la implementación de la atención, carga el modelo Gemma 2 9B-It y el tokenizador.
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)Crea la función Python que utilizará el modelo y extraerá los nombres de todos los módulos lineales.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)Afinar el modelo completo llevará mucho tiempo, así que para acelerar el proceso de entrenamiento, crearemos y adjuntaremos la capa adaptadora, lo que dará lugar a un proceso más rápido y eficiente en memoria.
La capa de adopción se crea utilizando los módulos de destino y el tipo de tarea. A continuación, configuramos el formato de chat para el modelo y el tokenizador. Por último, unimos el modelo base al adaptador para crear un modelo de ajuste fino eficiente de parámetros (PEFT).
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = get_peft_model(model, peft_config)Ahora cargaremos el lavita/ChatDoctor-CuidadoMágico-100k del centro Cara Abrazada. El conjunto de datos consta de tres columnas:
Después de cargar el conjunto de datos, lo barajaremos y seleccionaremos 1000 muestras para reducir aún más el tiempo de entrenamiento. Al final, crearemos el formato de chat utilizando la plantilla de chat por defecto y la utilizaremos para crear la columna "texto".
#Importing the dataset
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
def format_chat_template(row):
row_json = [{"role": "system", "content": row["instruction"]},
{"role": "user", "content": row["input"]},
{"role": "assistant", "content": row["output"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= 4,
)
datasetSalida:
Dataset({
features: ['instruction', 'input', 'output', 'text'],
num_rows: 1000
})Revisemos la columna "texto" de la fila 3.
dataset['text'][3]La columna "texto" contiene las instrucciones, la consulta del paciente y la respuesta del médico en el estilo OpenAI.

Para evaluar el modelo, dividiremos el conjunto de datos en entrenamiento y prueba.
dataset = dataset.train_test_split(test_size=0.1)Ahora estableceremos el argumento de entrenamiento y los parámetros STF y, a continuación, iniciaremos el proceso de entrenamiento.
Puedes cambiar los distintos hiperparámetros en función de tu entorno, cálculo y memoria. Los hiperparámetros que aparecen a continuación están optimizados para el Cuaderno Kaggle. Así que, si quieres hacer lo mismo en Google Colab, considera la posibilidad de experimentar con algoritmos de entrenamiento.
# Setting Hyperparamter
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
eval_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)
# Setting sft parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
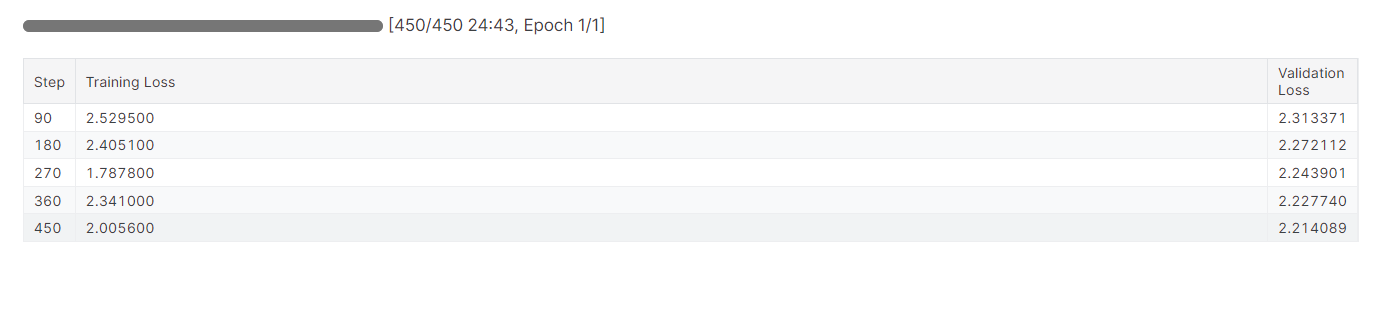
model.config.use_cache = False
trainer.train()Tardamos casi 25 minutos en afinar el modelo, y como podemos ver, la pérdida de entrenamiento y validación se ha reducido gradualmente. Para mejorar el rendimiento, intenta ajustar el modelo en el conjunto de datos completo durante al menos tres épocas.
 El ajuste puede ser un poco técnico para principiantes y personas sin conocimientos técnicos. Si buscas una solución más sencilla, deberías consultar la página Ajuste fino GPT-4 de OpenAI: Guía paso a paso tutorial. Cubre una forma sencilla de afinar un modelo de vanguardia utilizando la API OpenAI.
El ajuste puede ser un poco técnico para principiantes y personas sin conocimientos técnicos. Si buscas una solución más sencilla, deberías consultar la página Ajuste fino GPT-4 de OpenAI: Guía paso a paso tutorial. Cubre una forma sencilla de afinar un modelo de vanguardia utilizando la API OpenAI.
Terminaremos el experimento "Pesos y sesgos", que generará un informe de evaluación.
wandb.finish()
model.config.use_cache = True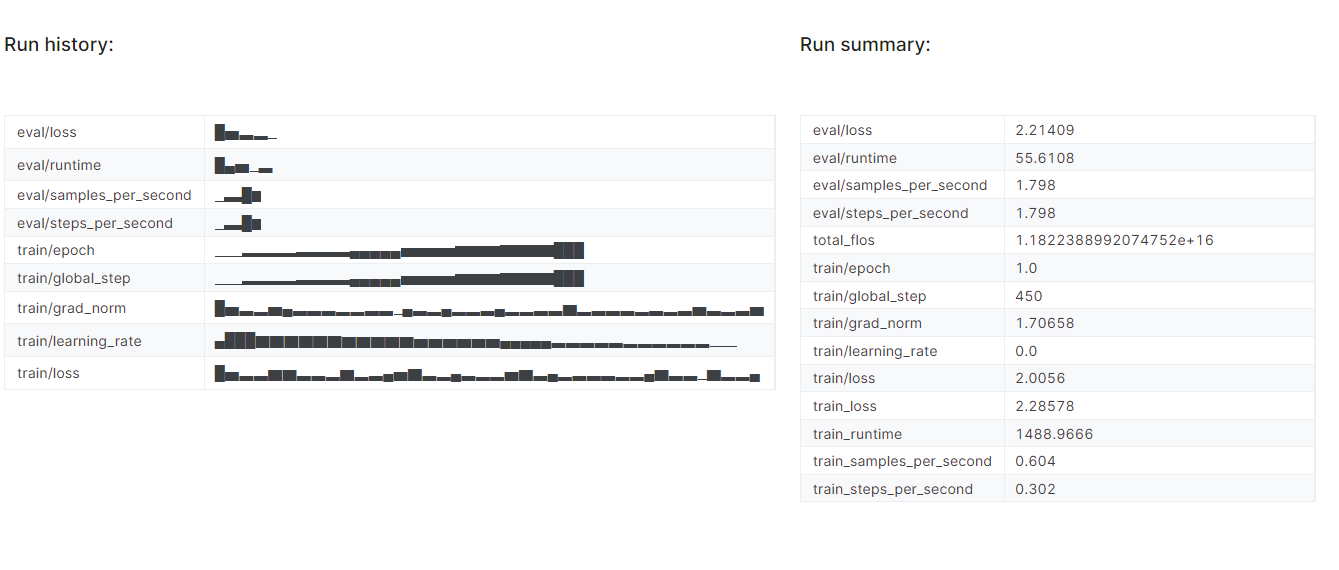
Para ver el informe detallado, ve a tu cuenta de Pesos y Sesgos y haz clic en "Afinar Gemma-2-9b-it en el conjunto de datos de sanidad" nombre del proyecto.
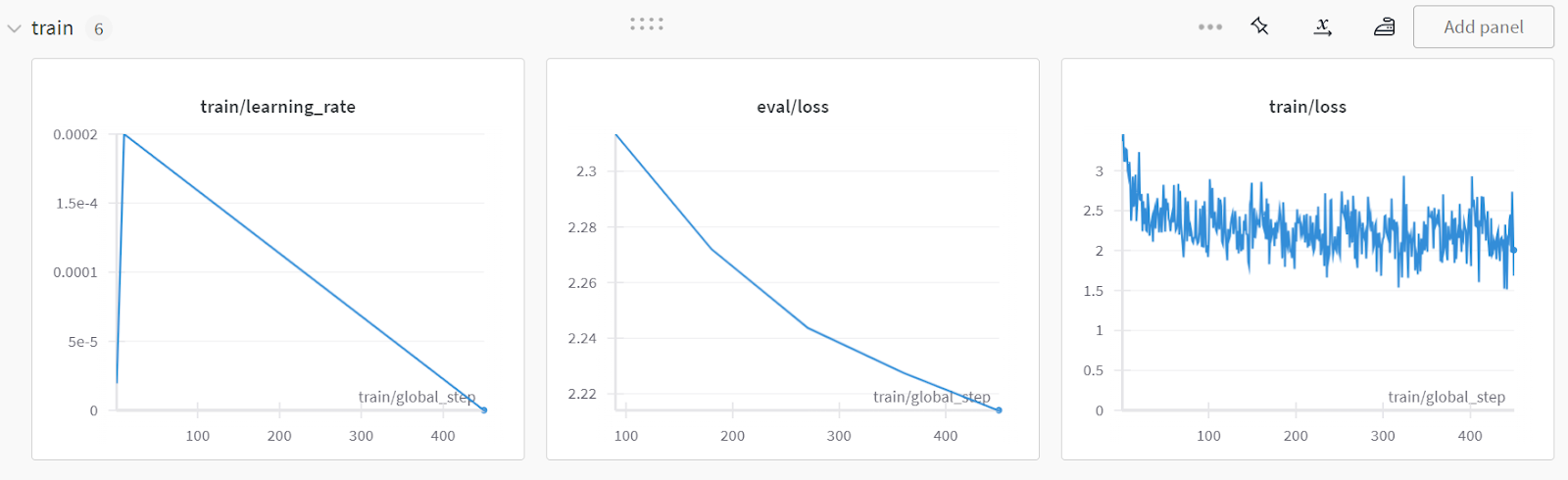
La captura de pantalla es de wandb.ai
Ahora guardaremos el adoptador ajustado localmente y también lo enviaremos al hub Cara Abrazada.
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)Para utilizar el adoptador guardado en otro cuaderno Kaggle, tenemos que guardar el cuaderno. Podemos hacerlo pulsando "Guardar versión" en la parte superior derecha. Después, selecciona "Guardado rápido" y "Guardar siempre la salida al crear un Guardado rápido", y pulsa el botón "Guardar".
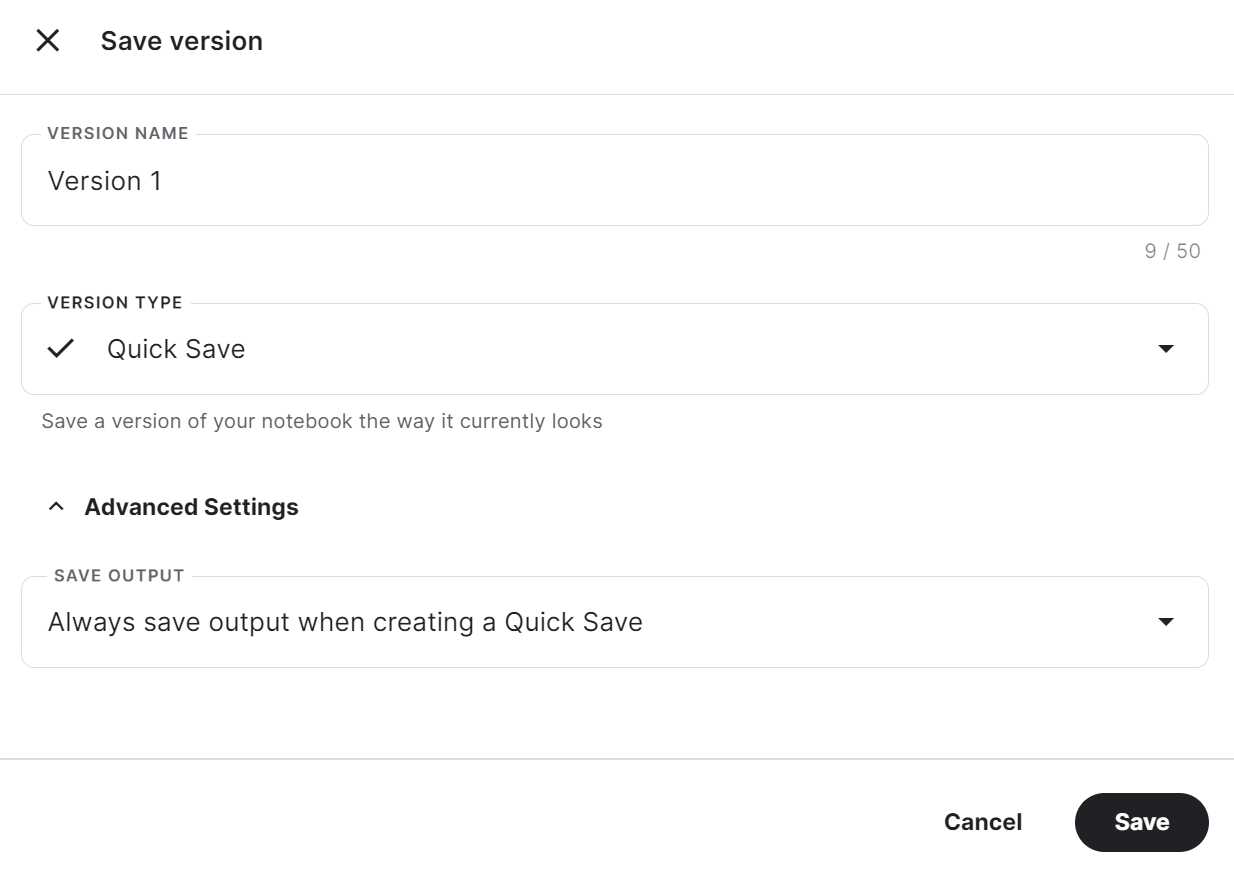
Si tienes problemas para ejecutar el código, por favor clona el Cuaderno Kaggle y ejecútalo. Debes configurar la clave API de Cara Abrazada y Pesos y Sesgos utilizando los Secretos de Kaggle.
Para determinar si el ajuste fino o la Generación Mejorada por Recuperación (RAG) son más adecuados para tu caso de uso específico, te recomiendo encarecidamente que leas el documento RAG vs Ajuste fino blog.
Ahora, fusionaremos el adaptador con el modelo base y empujaremos el modelo completo al hub Cara Abrazada.
Crea un nuevo cuaderno Kaggle con una CPU como acelerador e instala los paquetes Python necesarios.
¿Por qué utilizamos la CPU como acelerador? ¿No será lento? Sí, pero la máquina GPU de Kaggle sólo nos proporciona 16 GB de memoria GPU, que es suficiente para un modelo de 7.000 millones de parámetros, pero no para un modelo de 9.000 millones de parámetros. Mientras tanto, la máquina con CPU proporciona 30 GB, que son suficientes para cargar tanto el modelo base como el adaptador.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlConsigue la clave API de los Secretos de Kaggle e inicia sesión en la CLI de Cara Abrazada.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Para acceder al modelo guardado, tienes que importar el cuaderno Kaggle guardado. Para ello, haz clic en el botón "Añadir entrada" de la parte superior derecha y selecciona la pestaña "Tu trabajo". A continuación, haz clic en el botón más de la libreta guardada para acceder a todos los archivos que contiene.
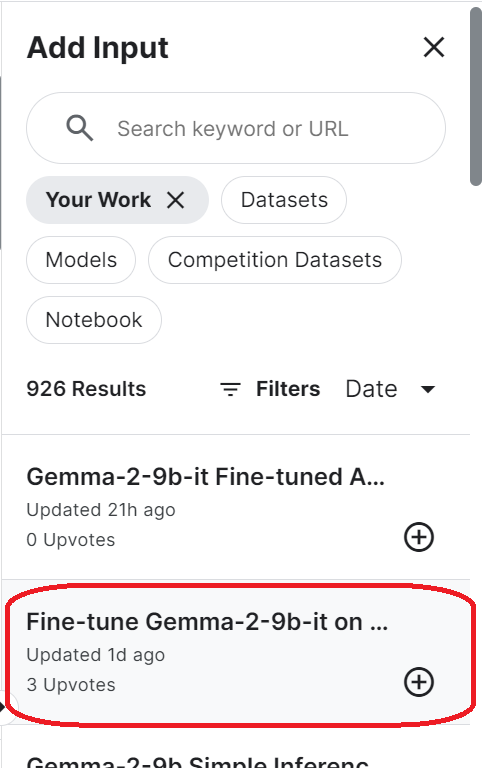
Configura la URL del modelo base proporcionando el nombre del repositorio Cara de Abrazo. Además, configura la URL del adaptador especificando el directorio local donde se guarda el adaptador.
base_model_url = "google/gemma-2-9b-it"
new_model_url = "/kaggle/input/fine-tune-gemma-2-9b-it-on-healthcare-dataset/Gemma-2-9b-it-chat-doctor/"Carga el tokenizador y el modelo completo utilizando la URL del modelo base. Asegúrate de establecer el dispositivo "cpu" y el dtype "float16".
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model_url)
base_model_reload= AutoModelForCausalLM.from_pretrained(
base_model_url,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="cpu",
)Ajusta el formato de chat al modelo base recién cargado y combínalo con el adoptador. Al final, cargaremos y fusionaremos el adoptador con el modelo base.
La función merge_and_unload() nos ayudará a fusionar los pesos del adaptador con el modelo base y a utilizarlo como modelo independiente.
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
model = PeftModel.from_pretrained(base_model_reload, new_model_url)
model = model.merge_and_unload()Guarda localmente el modelo completo y el tokenizador.
model.save_pretrained("Gemma-2-9b-it-chat-doctor")
tokenizer.save_pretrained("Gemma-2-9b-it-chat-doctor")Además, envía todos los archivos del modelo y el tokenizador al hub Cara Abrazada.
model.push_to_hub("Gemma-2-9b-it-chat-doctor", use_temp_dir=False)
tokenizer.push_to_hub("Gemma-2-9b-it-chat-doctor", use_temp_dir=False)Puedes ir a tu repositorio de modelos de Cara Abrazada y ver todos los archivos.
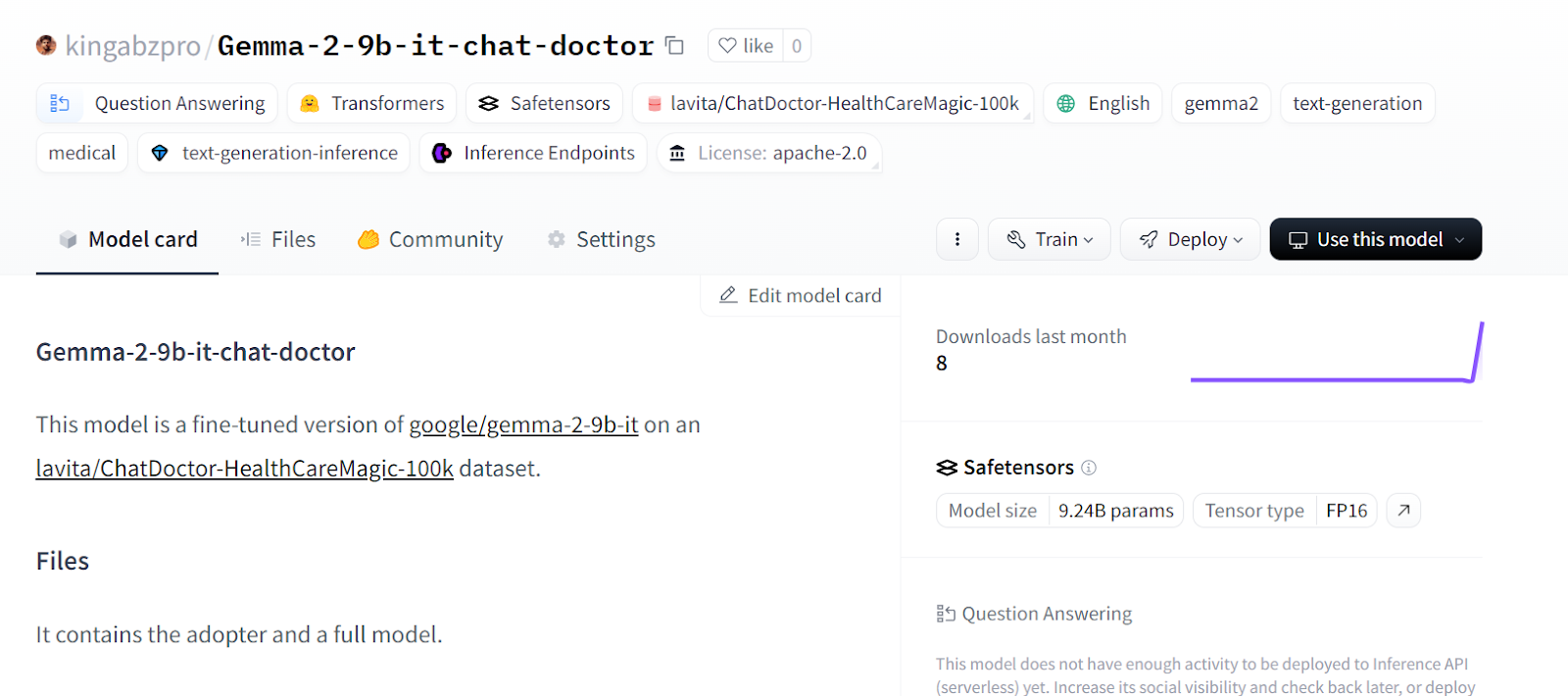
Fuente: kingabzpro/Gemma-2-9b-it-chat-doctor - Cara de abrazo
Si tienes problemas para fusionar modelos utilizando la CPU, consulta el Cuaderno Kaggle.
Con el GGUF Mi Repo Hugging Face Space, la conversión de modelos y la cuantización se han vuelto fáciles y rápidas. Lo único que tienes que hacer es conectarte y proporcionar el identificador del modelo.
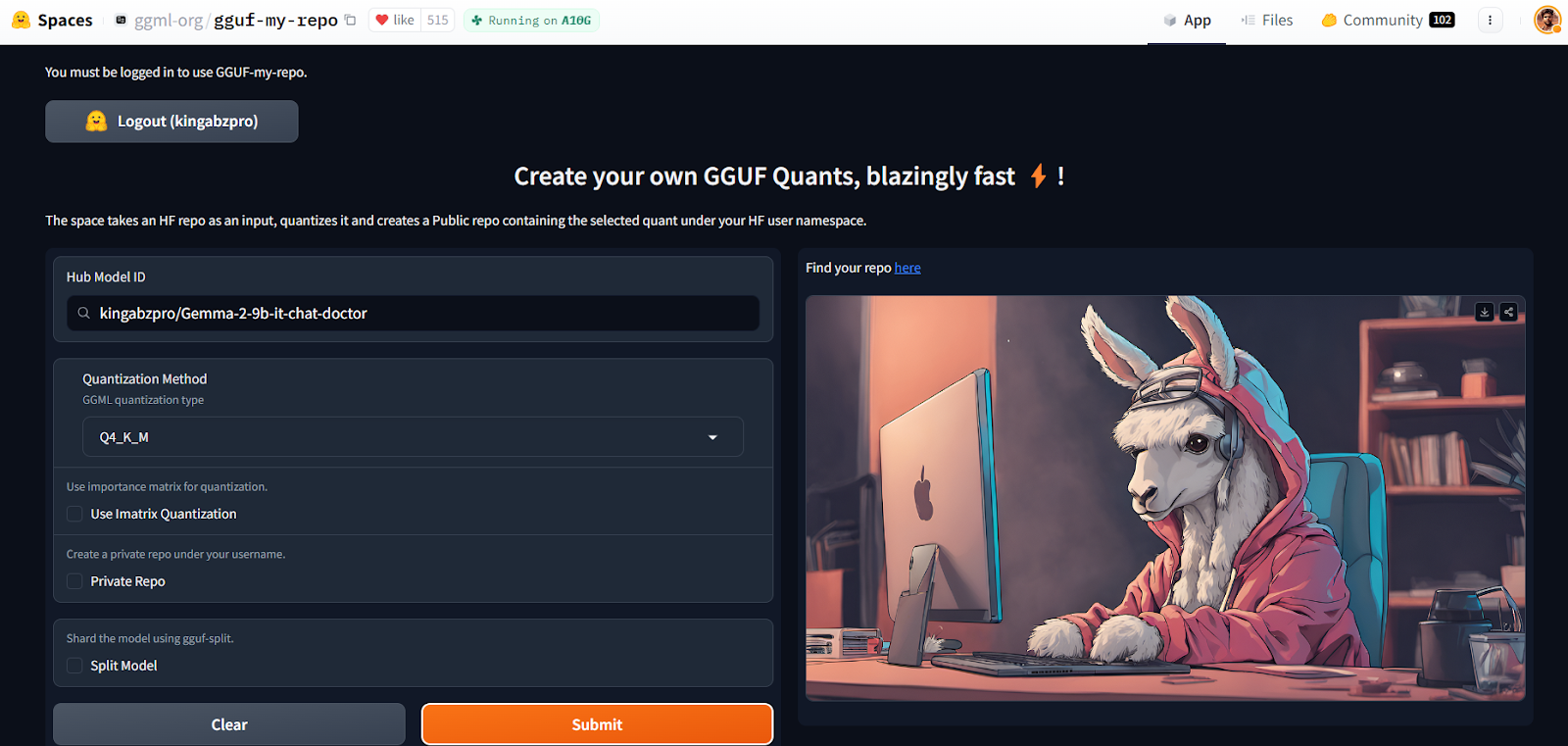
Fuente: GGUF My Repo - un espacio de caras abrazadas by ggml-org
Te creará un nuevo repositorio de modelos con un archivo de modelo cuantizado que podrás descargar más tarde para utilizarlo localmente. Es así de sencillo.
Puedes aprender la teoría que hay detrás de la cuantización leyendo nuestro artículo sobre Cuantización para grandes modelos lingüísticos (LLM): Reducir eficazmente el tamaño de los modelos de IA.
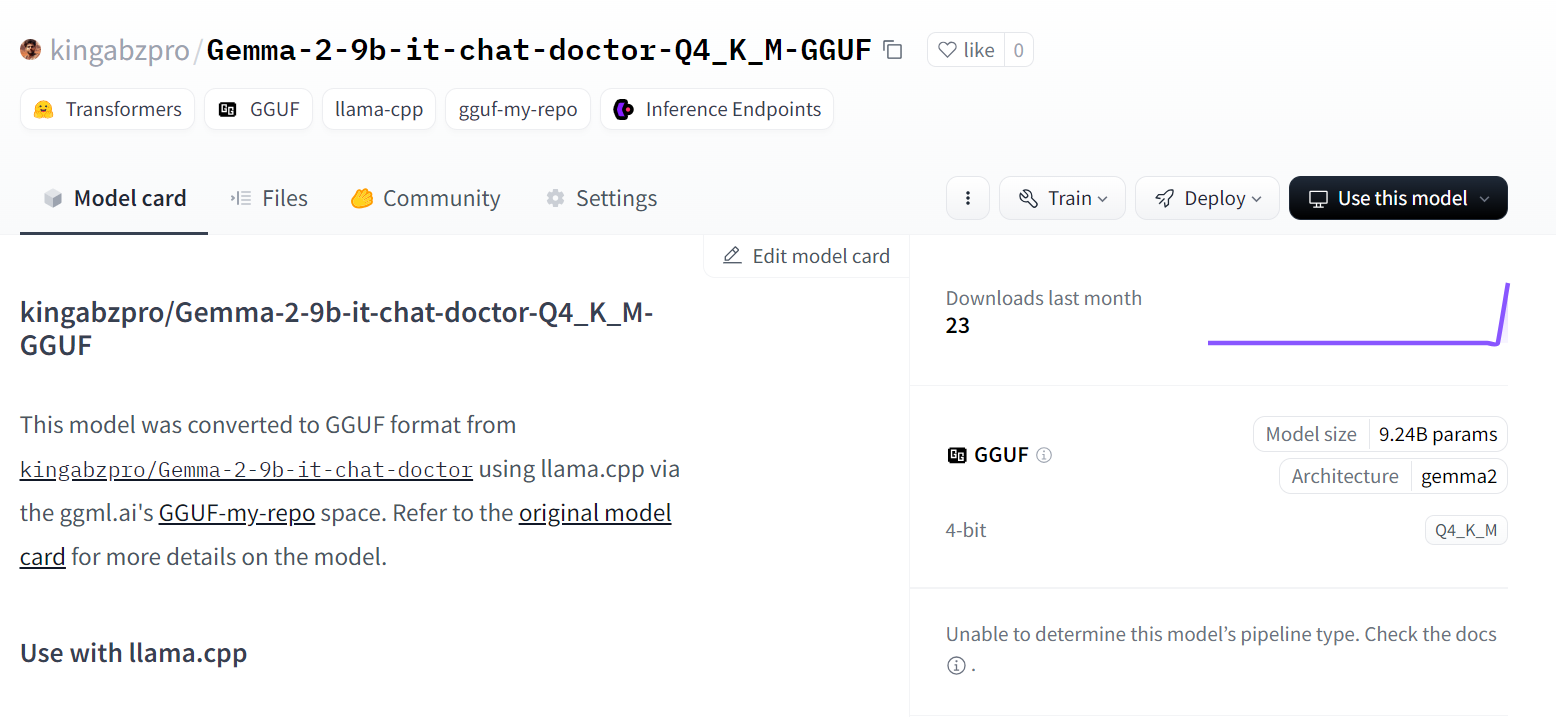
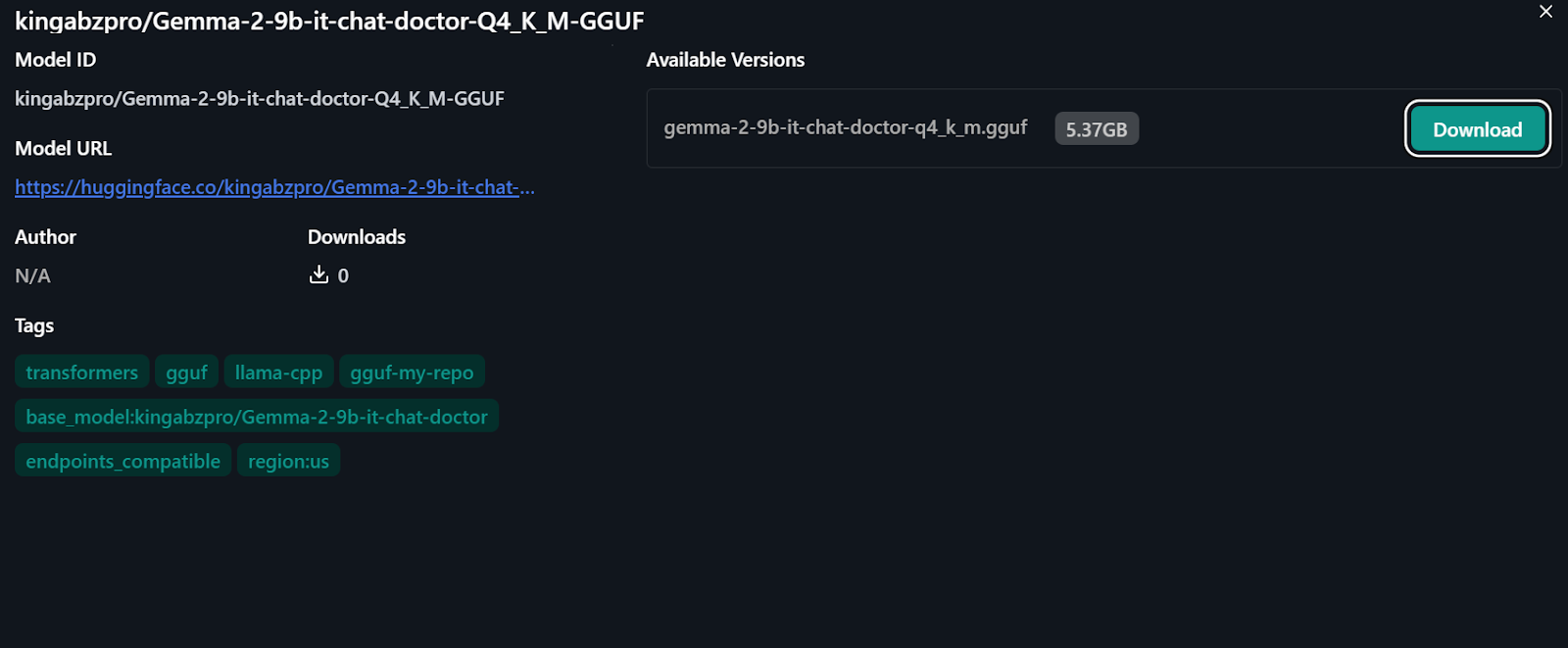
Fuente: kingabzpro/Gemma-2-9b-it-chat-doctor-Q4_K_M-GGUF - Cara de abrazo
Pero si quieres ensuciarte las manos y ejecutar scripts llama.cpp por tu cuenta, entonces deberías consultar el documento Ajuste fino de Llama 3 y uso local tutorial.
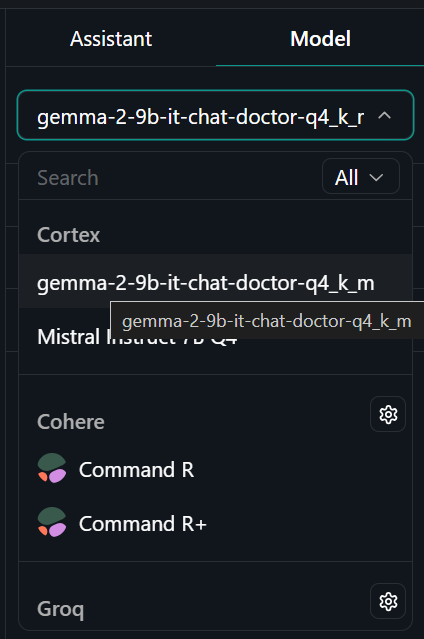
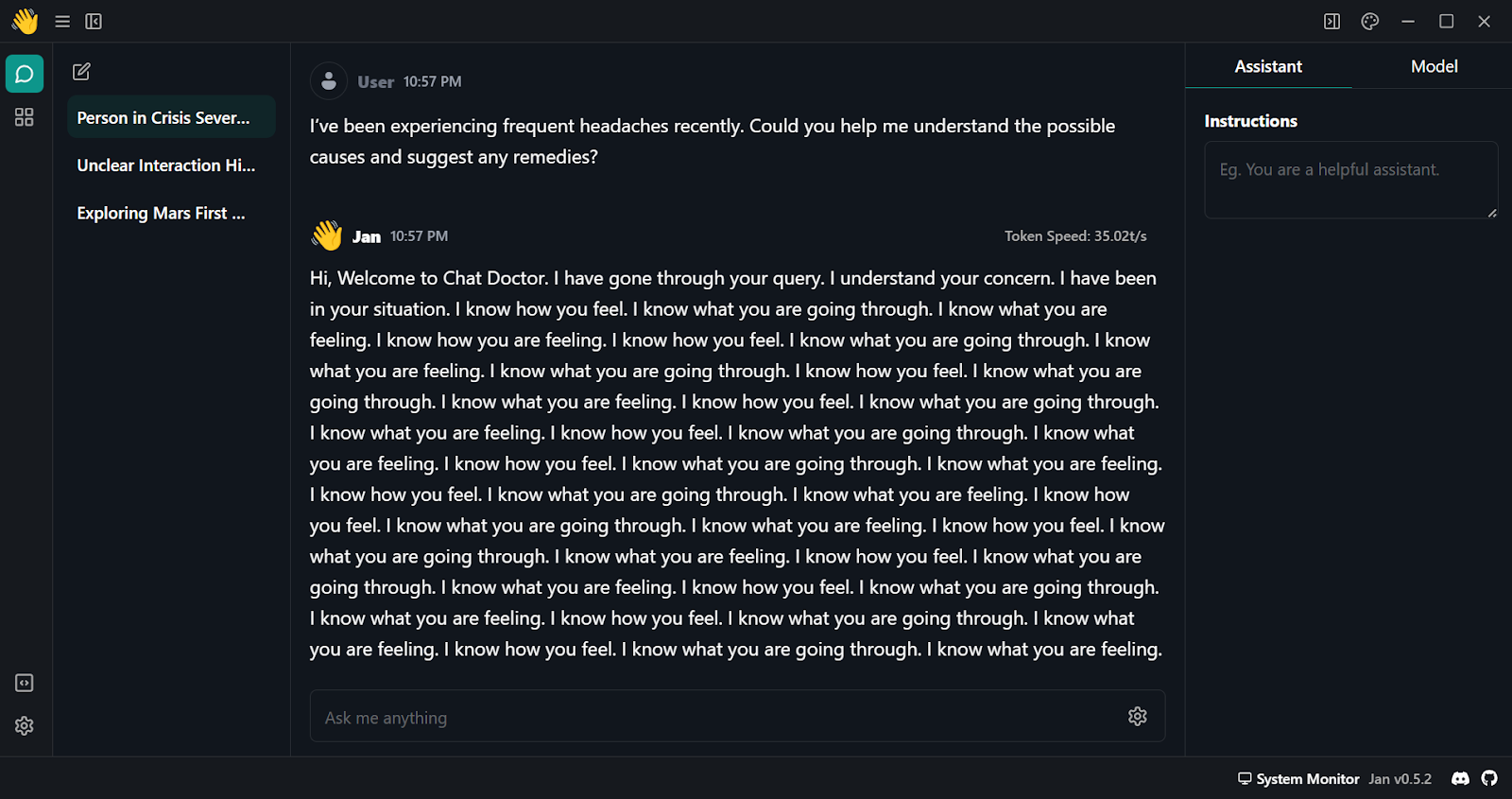
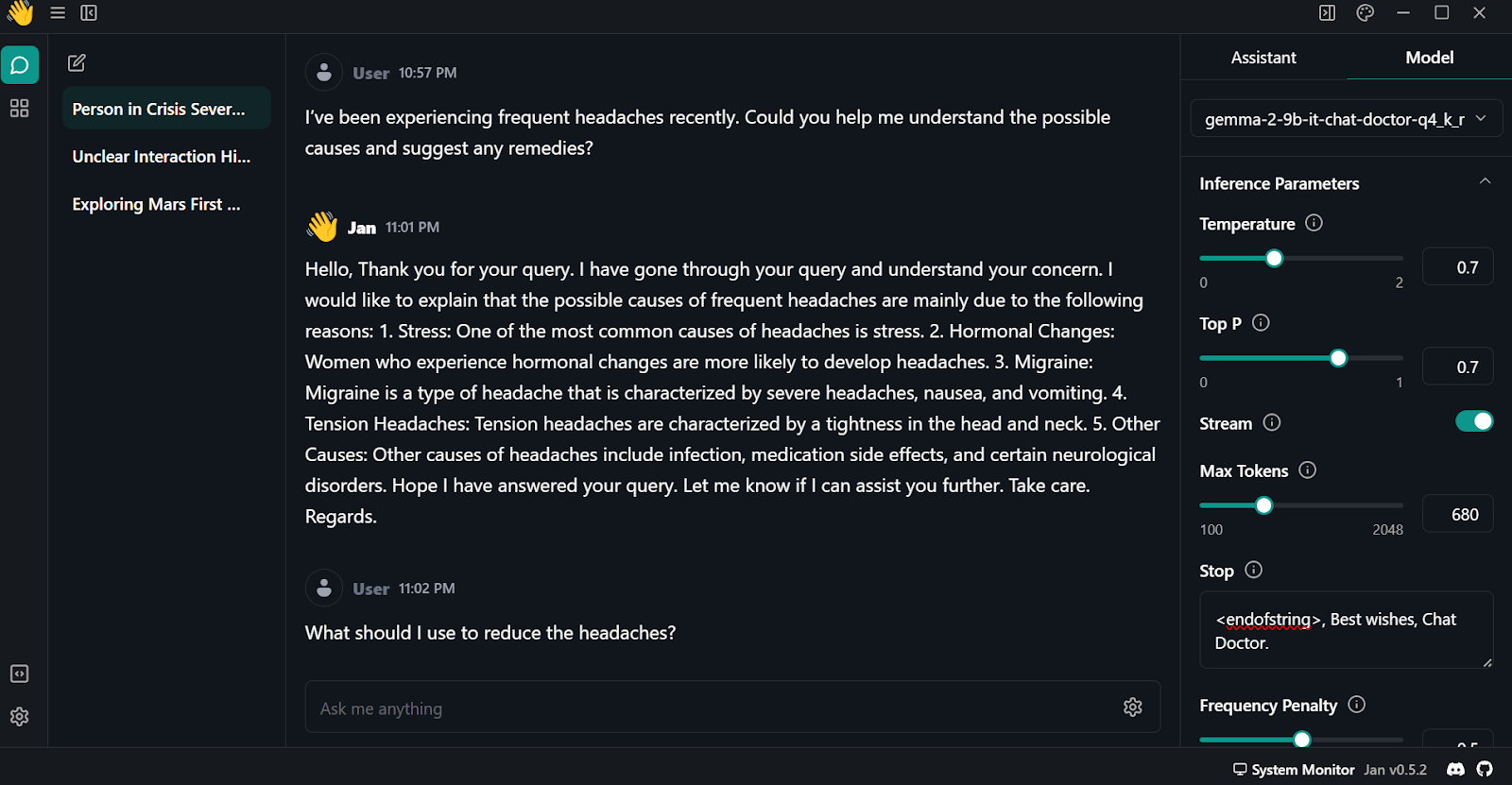
Para utilizar localmente el modelo cuantizado:
Gemma 2 es un gran modelo, y puede ser aún mejor si utilizas el marco Keras 3 para el ajuste fino distribuido y la inferencia del modelo. Conseguirás un tiempo de entrenamiento e inferencia más rápido que si utilizas el marco Transformers.
Puedes aprender a afinar el modelo Gemma y ejecutar la inferencia del modelo utilizando Keras 3 de la siguiente manera Ajuste fino y ejecución de la inferencia en el modelo Gemma de Google con TPU de Google.
En este tutorial, hemos aprendido sobre los modelos Gemma 2 y cómo acceder a ellos utilizando la biblioteca Transformer. También hemos aprendido a afinar el modelo en las conversaciones paciente-médico, a fusionar lo adoptado con el modelo base, a enviar el modelo completo al Hugging Face hub, a convertir y cuantizar el modelo utilizando el Hugging Face Space, a descargar y ejecutar el modelo localmente en el portátil utilizando la aplicación Jan.
Es un proyecto divertido que los entusiastas de la IA deberían probar. Esto mejorará su capacidad para resolver los problemas que surjan durante el ajuste fino de grandes modelos lingüísticos. Los principales retos suelen ser las limitaciones de memoria y cálculo, así como minimizar las pérdidas.
También puedes aprender a desarrollar tus propios LLM con PyTorch y Hugging Face en el apartado Desarrollo de grandes modelos lingüísticos en DataCamp.
Los mejores cursos LLM
Curso
Curso
Curso