
programa
Desarrollo de aplicaciones de IA
21 h
Los enfoques tradicionales, como el preentrenamiento en un gran conjunto de datos y el posterior ajuste en un conjunto de datos de una tarea específica, son fundamentales, pero a veces insuficientes. Han surgido métodos más avanzados para abordar los matices de los cambios de dominio, la escasez de datos y el aprendizaje multitarea.
Los métodos avanzados introducen capas adicionales de complejidad y flexibilidad. Estas técnicas pretenden mejorar el rendimiento del modelo en situaciones en las que los enfoques tradicionales pueden no ser adecuados.
Las técnicas de adaptación de dominio están diseñadas para manejar las discrepancias entre los dominios de origen (preentrenamiento) y de destino (ajuste fino). El ajuste fino tradicional a menudo produce resultados subóptimos cuando los modelos preentrenados se encuentran con datos que divergen significativamente de sus datos de entrenamiento. Las técnicas de adaptación al dominio reducen este desajuste alineando las distribuciones de datos, lo que garantiza que el modelo pueda generalizar mejor en entornos novedosos.
La MTL permite que un modelo aprenda simultáneamente en varias tareas relacionadas. Al compartir conocimientos entre tareas, el modelo puede utilizar los puntos en común y mejorar el rendimiento en todas las tareas. Esta estrategia es especialmente eficaz cuando las tareas son complementarias, como el aprendizaje conjunto de la clasificación de textos y el análisis de sentimientos en el procesamiento del lenguaje natural. El MTL mejora la generalización y reduce el riesgo de sobreajuste al guiar al modelo para que se centre en los patrones compartidos.
Otra técnica clave es aprendizaje de pocos datosdiseñado para entrenar modelos con un mínimo de datos etiquetados. Mientras que los enfoques tradicionales requieren grandes cantidades de datos etiquetados, las técnicas de pocos datos permiten a los modelos transferir conocimientos utilizando sólo unos pocos ejemplos. Métodos como el metaaprendizaje y las redes prototípicas pueden conducir a una rápida adaptación a nuevas tareas, lo que los hace inestimables en campos como las recomendaciones personalizadas o las clasificaciones de imágenes de nicho.
La SSL utiliza datos no etiquetados para entrenar modelos, lo que la consolida como una potente herramienta cuando los datos etiquetados son escasos o no están disponibles. Esta técnica construye señales de supervisión a partir de los propios datos, resolviendo tareas de pretexto como predecir las partes que faltan en una imagen o reconstruir un texto revuelto. Los modelos preentrenados mediante SSL han demostrado una gran transferibilidad a toda una serie de aplicaciones.
El aprendizaje cero va un paso más allá al permitir que los modelos manejen tareas completamente nuevas sin ningún dato etiquetado. Esto se consigue mediante información auxiliar, como relaciones semánticas o descripciones de tareas, que permiten al modelo generalizar incluso ante categorías novedosas. Esta capacidad es muy relevante en campos dinámicos en los que surgen con frecuencia nuevas categorías, como en las aplicaciones de PNL que manejan términos recién acuñados o argot.
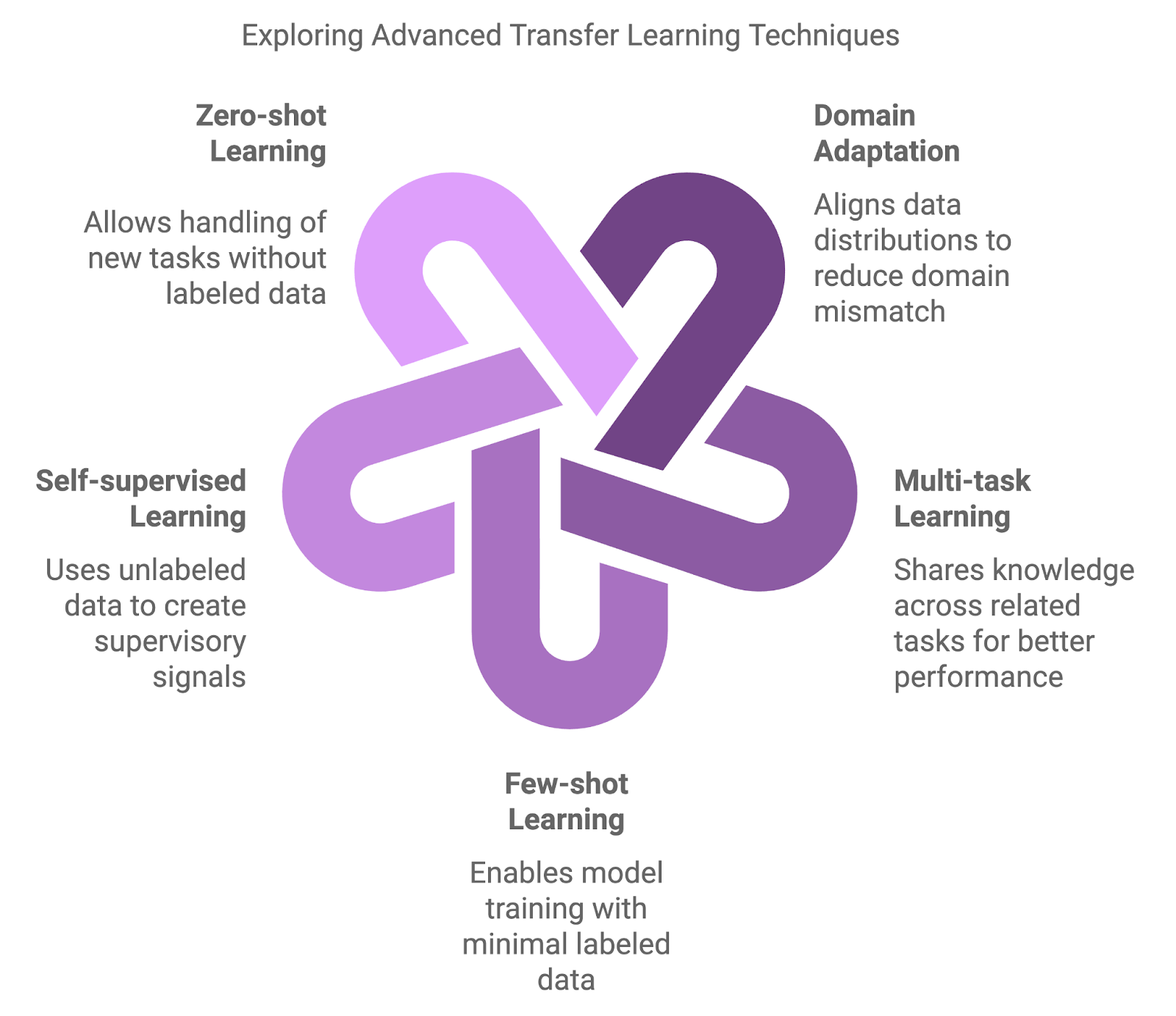
Diagrama generado con napkin.ai
Como ya se ha comentado brevemente, la adaptación de dominio es un subcampo del aprendizaje por transferencia centrado en el manejo de situaciones en las que existe una diferencia significativa, o "cambio de dominio", entre los datos utilizados para entrenar un modelo y los datos en los que se despliega el modelo.
En el aprendizaje por transferencia típico, se supone que los dominios de origen y destino comparten características similares, pero en muchos escenarios del mundo real, estos dominios difieren sustancialmente. En última instancia, esto puede degradar el rendimiento, ya que los modelos entrenados en un conjunto de datos tienen dificultades para generalizarse a nuevas condiciones.
Las técnicas de adaptación de dominio están diseñadas para salvar esta distancia, permitiendo que un modelo entrenado en un dominio funcione eficazmente en otro minimizando la discrepancia entre las distribuciones de datos de origen y de destino. Como resultado, la adaptación al dominio es aún más valiosa en situaciones en las que los datos etiquetados son abundantes en un dominio, pero escasos o no disponibles en otro.
Se han desarrollado varias técnicas para abordar el reto de la adaptación al dominio: dos de los enfoques más comunes son los métodos adversariales y el aprendizaje de características invariantes del dominio.
Una técnica muy utilizada para la adaptación al dominio es el aprendizaje adversarial. En este contexto, se entrena un modelo para que aprenda características útiles para la tarea de destino, asegurando al mismo tiempo que esas características no se distinguen entre los dominios de origen y de destino.
Podemos conseguirlo utilizando un discriminador, es decir, una red neuronal encargada de distinguir entre los datos del dominio de origen y los del dominio de destino. El modelo se entrena de forma adversarial para que aprenda a "engañar" al discriminador, haciendo que las representaciones de rasgos sean invariantes del dominio. Si esto te resulta familiar, es porque esta técnica se inspira en Redes Generativas Adversariales (GAN)que utilizan una configuración similar para generar datos sintéticos realistas.
Otro enfoque se centra en el aprendizaje de representaciones que no se ven afectadas por las variaciones específicas del dominio. Esto transforma los datos de entrada de ambos dominios en un espacio de características compartido en el que los dominios de origen y destino se alinean más estrechamente. Técnicas como la Máxima Discrepancia Media (MMD) y la CORAL (Correlation Alignment) ayudan a minimizar las diferencias estadísticas en este espacio, garantizando que el modelo pueda generalizarse más eficazmente cuando se aplique al dominio objetivo.
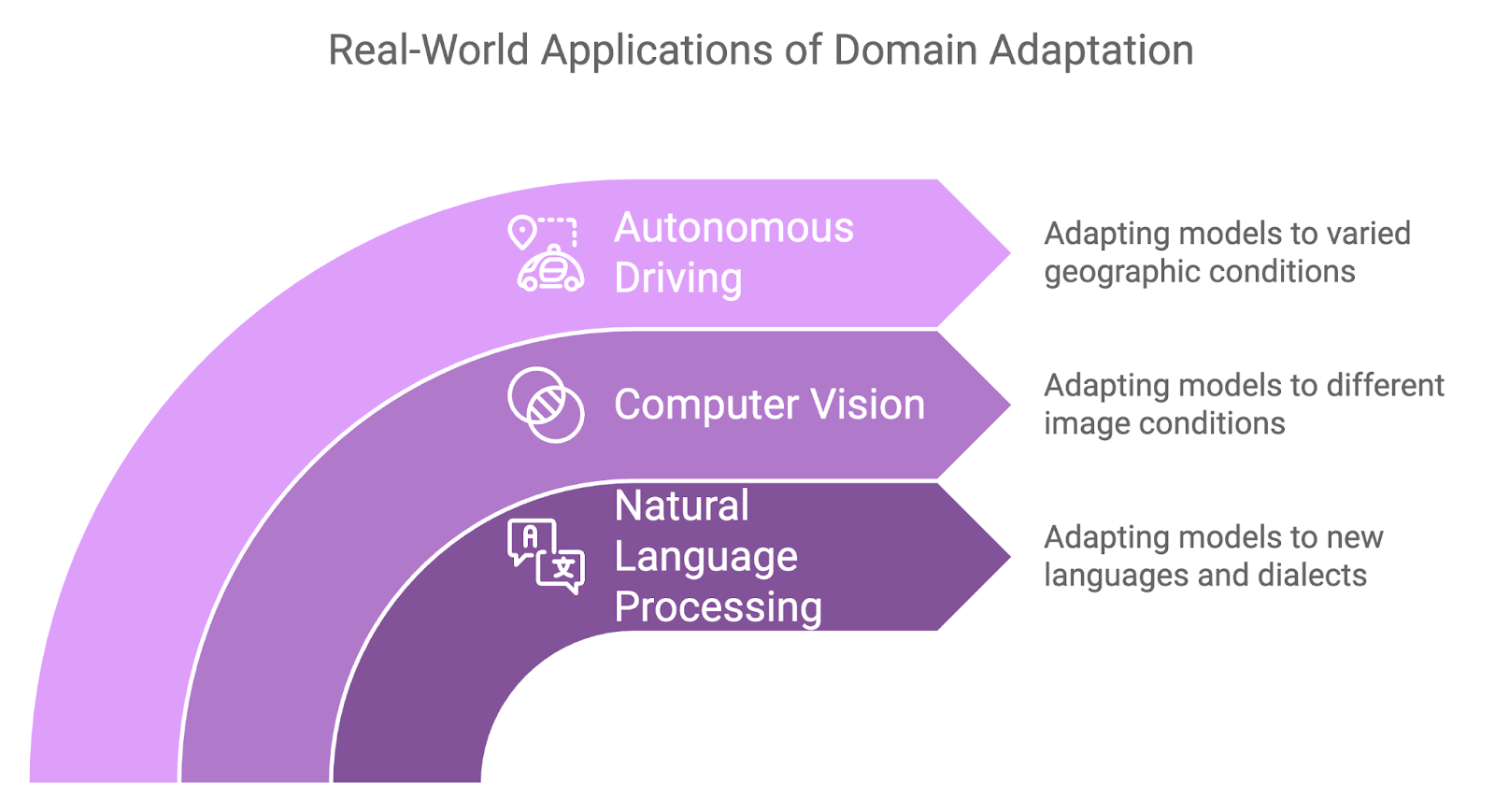
La adaptación al dominio ha demostrado su utilidad en diversas aplicaciones del mundo real en las que los cambios de dominio son inevitables:
A medida que las tareas de aprendizaje automático aumentan en complejidad, la capacidad de abordar simultáneamente múltiples problemas relacionados puede mejorar significativamente el rendimiento y la eficacia de un modelo. La MTL aborda este problema entrenando a los modelos para que realicen varias tareas a la vez, en lugar de centrarse en una única tarea de forma aislada.
La fuerza del MTL reside en su capacidad para capitalizar las relaciones y estructuras compartidas entre tareas, lo que permite a los modelos aprender representaciones de rasgos más ricas. Los conocimientos adquiridos en una tarea mejoran el rendimiento del modelo en otra, lo que conduce a una mayor eficacia general del aprendizaje.
En la MTL, se suelen utilizar dos estrategias principales:
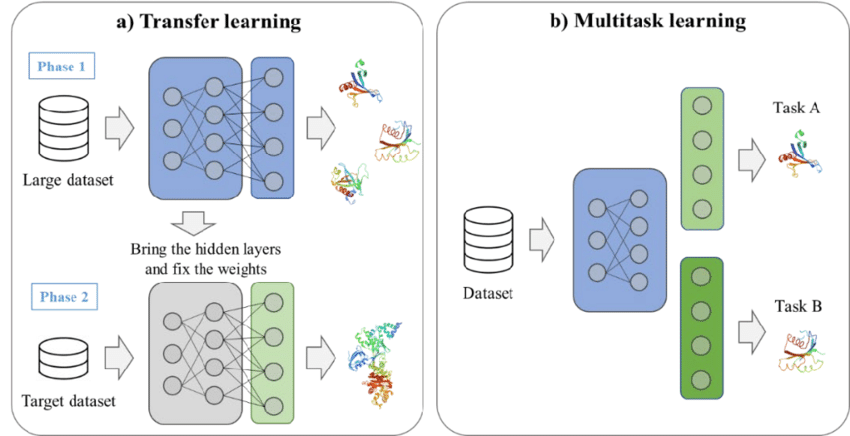
Un ejemplo de aprendizaje por transferencia y aprendizaje multitarea. Fuente: Kim et al., 2021
La MTL ofrece varias ventajas que la convierten en un enfoque valioso para escenarios complejos de aprendizaje automático.
Al aprender en múltiples tareas, el modelo se expone a una gama más amplia de datos y aprende representaciones más generales. Esto a menudo conduce a un mejor rendimiento en cada tarea, especialmente cuando esas tareas están relacionadas.
Con la MTL, los modelos aprovechan mejor los datos disponibles, sobre todo en situaciones en las que los datos etiquetados son escasos. Como el modelo aprende de múltiples tareas, puede utilizar la información de tareas relacionadas para mejorar el rendimiento. Este aprendizaje entre tareas acelera el proceso de aprendizaje y reduce la dependencia de grandes conjuntos de datos para cada tarea.
En lugar de entrenar modelos separados para cada tarea, el MTL consolida el aprendizaje en un único modelo. Esto reduce el coste computacional y la huella de memoria, haciéndolo más eficiente para su despliegue en entornos con recursos limitados.
La MTL se ha aplicado con éxito en varios ámbitos, con casos de uso notables en la PNL y la visión por ordenador.
En el procesamiento del lenguaje natural, la MTL se utiliza habitualmente para entrenar modelos en múltiples tareas relacionadas. Por ejemplo, un modelo lingüístico puede entrenarse para realizar simultáneamente la traducción automática y la clasificación de textos. Al compartir las representaciones aprendidas en estas tareas, el modelo puede mejorar su comprensión de la estructura y el contexto del lenguaje, lo que beneficia a ambas tareas.
En visión por ordenador, la MTL puede aplicarse a tareas como la detección de objetos y la segmentación de imágenes. Podemos entrenar un modelo para identificar objetos dentro de una imagen y, al mismo tiempo, aprender también a clasificar esos objetos. Este proceso de aprendizaje compartido permite al modelo reconocer tanto la ubicación como la categoría de los objetos, lo que lo hace más versátil y eficaz.
En escenarios en los que los datos etiquetados son escasos o no están disponibles, el aprendizaje de pocos datos y la SSL han surgido como poderosas técnicas para abordar las limitaciones de los métodos supervisados tradicionales.
Estos enfoques ofrecen formas innovadoras de adaptar modelos a nuevas tareas con un mínimo de datos etiquetados o utilizando grandes cantidades de datos sin etiquetar, lo que los convierte en herramientas esenciales en el ámbito del aprendizaje por transferencia avanzado.
Como ya sabemos, el aprendizaje de pocos disparos está diseñado para permitir que los modelos se adapten rápidamente a nuevas tareas con sólo unos pocos ejemplos etiquetados.
Sin embargo, recopilar grandes conjuntos de datos es poco práctico en muchas aplicaciones, como el diagnóstico de enfermedades raras o la identificación de productos nicho. El aprendizaje de pocos datos resuelve esto transfiriendo conocimientos de tareas relacionadas y afinando los modelos para que funcionen bien con un mínimo de datos nuevos.
A continuación, analizamos dos estrategias clave en el aprendizaje de pocos disparos.
También conocido como "aprender a aprender", el metaaprendizaje consiste en entrenar un modelo para que se adapte rápidamente a nuevas tareas con un mínimo de datos. La idea es entrenar el modelo a través de una variedad de tareas para que pueda generalizar su aprendizaje y ajustarse rápidamente a tareas no vistas.
Los marcos de metaaprendizaje como el Metaaprendizaje Diagnóstico de Modelos (MAML) permiten que el modelo aprenda un conjunto óptimo de parámetros que pueden ajustarse a nuevas tareas con sólo unos pocos ejemplos.
Otro enfoque habitual son las redes prototípicas, diseñadas para clasificar puntos de datos calculando distancias entre ellos en un espacio de características aprendido. En esta configuración, cada clase está representada por un prototipo (la media de los ejemplos de esa clase en el espacio de características).
A continuación, los nuevos puntos de datos se clasifican en función de su proximidad a estos prototipos. Las redes prototípicas pueden ser eficaces en el aprendizaje de pocos ejemplos, ya que sólo necesitan un número mínimo de ejemplos por clase para generar prototipos significativos para la clasificación.
SSL permite a los modelos extraer representaciones significativas de grandes cantidades de datos sin etiquetar mediante la generación de señales de supervisión, obviando la necesidad de etiquetas manuales. Una vez que el modelo ha aprendido de los datos no etiquetados, se puede afinar en un conjunto de datos etiquetados más pequeño, consiguiendo un gran rendimiento en las tareas posteriores.
Una de las técnicas SSL más impactantes es el aprendizaje contrastivo, que entrena modelos comparando pares positivos y negativos de puntos de datos. El objetivo es acercar los puntos de datos similares (pares positivos) en el espacio de características y alejar los disímiles (pares negativos).
En el procesamiento del lenguaje natural, un método SSL popular es el modelado del lenguaje enmascarado, utilizado en modelos como el BERT. Aquí, se enmascaran partes de la entrada y se entrena al modelo para predecir los elementos que faltan utilizando el contexto circundante. Esta estrategia de preentrenamiento ayuda al modelo a aprender representaciones robustas y de uso general que pueden ajustarse para diversas tareas de PNL.
El aprendizaje de pocos datos y el aprendizaje autosupervisado se utilizan mucho en campos en los que las limitaciones de datos son un obstáculo importante. He aquí algunas aplicaciones clave de cada uno.
El aprendizaje de pocos intentos resulta valioso en la detección de objetos personalizados, donde la identificación de objetos raros o especializados puede requerir que los modelos aprendan de sólo un puñado de ejemplos etiquetados.
En entornos industriales, la detección de defectos en un proceso de fabricación puede implicar muy pocos casos del defecto. Aprovechando el aprendizaje de pocos disparos, un modelo preentrenado en tareas generales de detección de objetos puede adaptarse rápidamente para detectar estos objetos específicos con un mínimo de datos de entrenamiento adicionales.
El aprendizaje autosupervisado ha revolucionado el procesamiento del lenguaje natural mediante modelos como GPT y BERT. Estos modelos aprenden representaciones lingüísticas de uso general que pueden ajustarse para tareas específicas con conjuntos de datos etiquetados relativamente pequeños. Por ejemplo, un modelo lingüístico preentrenado mediante SSL puede ajustarse para realizar tareas como el análisis de sentimientos, la clasificación de textos o el resumen, consiguiendo a menudo resultados de vanguardia.
Las bibliotecas y marcos de aprendizaje automático pueden simplificar considerablemente la aplicación de métodos avanzados de aprendizaje por transferencia. Herramientas como PyTorch, TensorFlowy Transformadores de Caras Abrazadas proporcionan la flexibilidad necesaria y componentes preconstruidos para acelerar el proceso de desarrollo.
Para los profesionales que deseen aplicar técnicas avanzadas de aprendizaje por transferencia, varias bibliotecas y marcos de trabajo ofrecen un amplio apoyo:
Aplicar técnicas avanzadas de aprendizaje por transferencia es un reto, y hay algunos factores críticos que debemos tener en cuenta.
El perfeccionamiento en tareas nuevas puede hacer que los modelos "olviden" lo que han aprendido en tareas anteriores. Técnicas como Consolidación del Peso Elástico (EWC) pueden ayudar a preservar los pesos del modelo preentrenado, lo que es crucial para el conocimiento previo.
Técnicas como la adaptación al dominio y el aprendizaje multitarea pueden aumentar significativamente los requisitos computacionales. Entrenar modelos de adaptación al dominio adversario o arquitecturas multitarea puede requerir más recursos debido a la complejidad adicional. Tenemos que optimizar nuestro modelo y utilizar herramientas como el entrenamiento de precisión mixta para manejar modelos grandes con eficacia.
Los modelos de aprendizaje por transferencia preentrenados en datos sesgados pueden propagar o incluso amplificar estos sesgos en nuevas tareas, lo que conduce a predicciones sesgadas. Este riesgo es crítico en ámbitos sensibles como la sanidad y las finanzas. Para garantizar la imparcialidad, deberíamos evaluar periódicamente los resultados del modelo en busca de sesgos y aplicar técnicas de mitigación, como la reponderación, la desprejuiciación adversarial o el aprendizaje de representación justa.
Los métodos avanzados de aprendizaje por transferencia se están aplicando en diversos sectores, aportando soluciones innovadoras a complejos retos del mundo real. A continuación se presentan algunas aplicaciones clave y ejemplos de la industria que ponen de relieve cómo estas técnicas están impulsando los avances de la IA.
El modelo modelo GPT-4o de OpenAIun ejemplo destacado de aprendizaje con pocos ejemplos en acción, ha demostrado la capacidad de adaptarse a nuevas tareas con sólo unos pocos ejemplos. GPT-4o, preentrenado en cantidades masivas de datos de texto, puede realizar varias tareas, como traducción, resumen y respuesta a preguntas, sin necesidad de un ajuste fino específico de la tarea.
En su lugar, los usuarios proporcionan algunos ejemplos de la tarea deseada, y el modelo generaliza a partir de ahí. Esta capacidad de aprendizaje en pocos pasos ha ampliado la gama de aplicaciones de los grandes modelos lingüísticos, desde la escritura creativa hasta los agentes conversacionales.
DeepMind, líder en investigación de IA, ha utilizado el aprendizaje multitarea para desarrollar modelos sanitarios que pueden ayudar a diagnosticar múltiples afecciones a partir de imágenes médicas. Por ejemplo, su sistema de IA para detectar enfermedades oculares a partir de exploraciones de la retina es capaz de diagnosticar una serie de afecciones, como la retinopatía diabética y la degeneración macular asociada a la edad, utilizando un único modelo.
Este enfoque MTL reduce la necesidad de modelos separados para cada afección, lo que permite a los profesionales sanitarios agilizar sus procesos de diagnóstico y proporcionar una atención al paciente más rápida y precisa.
Waymo (el proyecto de coche autoconducido de Google) utiliza técnicas de adaptación de dominio para mejorar la generalización de sus modelos de vehículo autónomo en diversos entornos de conducción. La empresa entrena sus modelos en entornos simulados y luego los adapta para su despliegue en el mundo real, en diferentes ciudades y condiciones meteorológicas.
Este proceso garantiza que los coches autoconducidos puedan adaptarse a los matices de los distintos paisajes urbanos, desde las congestionadas calles de San Francisco hasta las amplias autopistas de Arizona, sin necesidad de un reentrenamiento exhaustivo para cada lugar.
Los investigadores están ampliando constantemente los límites, esforzándose por hacer modelos más adaptables, justos y capaces de manejar tareas complejas del mundo real, reduciendo al mismo tiempo la cantidad de datos y el tiempo de entrenamiento necesarios.
El aprendizaje continuo o aprendizaje a lo largo de toda la vida se centra en el desarrollo de modelos que puedan aprender continuamente a partir de nuevos datos, al tiempo que retienen los conocimientos de las tareas aprendidas anteriormente. A diferencia del aprendizaje por transferencia tradicional, en el que los modelos son estáticos una vez ajustados, el aprendizaje continuo permite una adaptación continua a la nueva información.
Esto es vital para entornos dinámicos, como la robótica y los sistemas autónomos, en los que surgen nuevos escenarios con regularidad. En este contexto, las estrategias basadas en la memoria ayudan a equilibrar la necesidad de conservar los conocimientos pasados al tiempo que se incorporan nuevas habilidades. Los desarrollos futuros pretenden ampliar el aprendizaje continuo a dominios más complejos, garantizando que los modelos puedan actualizarse eficazmente sin comprometer el rendimiento anterior.
A medida que el aprendizaje por transferencia se hace más frecuente en sectores como la sanidad, las finanzas y la aplicación de la ley, es imposible ignorar la necesidad de abordar la imparcialidad y la parcialidad.
Los modelos preentrenados en conjuntos de datos grandes y diversos suelen llevar sesgos inherentes, que pueden dar lugar a resultados sesgados en nuevas aplicaciones. Para contrarrestarlo, los investigadores están explorando técnicas como la eliminación de sesgos adversariales, la reponderación y el aprendizaje de representación justa para detectar y mitigar estos sesgos.
Garantizar la imparcialidad seguirá siendo un punto central en la investigación del aprendizaje por transferencia, especialmente en dominios sensibles en los que las predicciones sesgadas pueden tener implicaciones en el mundo real.
Aprende IA con estos cursos
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
