
Programa
Desenvolvimento de aplicativos de IA
21 h
As abordagens tradicionais, como o pré-treinamento em um grande conjunto de dados e, em seguida, o ajuste fino em um conjunto de dados específico da tarefa, são fundamentais, mas às vezes insuficientes. Surgiram métodos mais avançados para lidar com as nuances das mudanças de domínio, escassez de dados e aprendizado multitarefa.
Os métodos avançados introduzem camadas adicionais de complexidade e flexibilidade. Essas técnicas visam melhorar o desempenho do modelo em cenários em que as abordagens tradicionais podem não ser adequadas.
As técnicas de adaptação de domínio são projetadas para lidar com discrepâncias entre os domínios de origem (pré-treinamento) e de destino (ajuste fino). O ajuste fino tradicional geralmente produz resultados abaixo do ideal quando os modelos pré-treinados encontram dados que divergem significativamente dos dados de treinamento. As técnicas de adaptação de domínio reduzem essa incompatibilidade alinhando as distribuições de dados, garantindo que o modelo possa se generalizar melhor em novas configurações.
O MTL permite que um modelo aprenda simultaneamente em várias tarefas relacionadas. Ao compartilhar o conhecimento entre as tarefas, o modelo pode usar pontos em comum e melhorar o desempenho em todas as tarefas. Essa estratégia é especialmente eficaz quando as tarefas são complementares, como o aprendizado conjunto de classificação de texto e análise de sentimentos no processamento de linguagem natural. O MTL aprimora a generalização e reduz o risco de ajuste excessivo, orientando o modelo a se concentrar em padrões compartilhados.
Outra técnica importante é a aprendizado de poucos disparosprojetada para treinar modelos com o mínimo de dados rotulados. Embora as abordagens tradicionais exijam grandes quantidades de dados rotulados, as técnicas de poucos disparos permitem que os modelos transfiram conhecimento usando apenas alguns exemplos. Métodos como meta-aprendizagem e redes prototípicas podem levar a uma rápida adaptação a novas tarefas, tornando-os inestimáveis em campos como recomendações personalizadas ou classificações de imagens de nicho.
O SSL usa dados não rotulados para treinar modelos, consolidando-o como uma ferramenta poderosa quando os dados rotulados são escassos ou não estão disponíveis. Essa técnica constrói sinais de supervisão a partir dos próprios dados, solucionando tarefas de pretexto, como a previsão de partes ausentes de uma imagem ou a reconstrução de texto embaralhado. Os modelos pré-treinados usando SSL demonstraram alta capacidade de transferência em uma variedade de aplicações.
A aprendizagem zero-shot vai um passo além, permitindo que os modelos lidem com tarefas completamente novas sem nenhum dado rotulado. Isso é obtido por meio de informações auxiliares, como relações semânticas ou descrições de tarefas, permitindo que o modelo generalize mesmo quando confrontado com novas categorias. Esse recurso é altamente relevante em campos dinâmicos em que novas categorias surgem com frequência, como em aplicativos de PNL que lidam com termos ou gírias recém-criados.
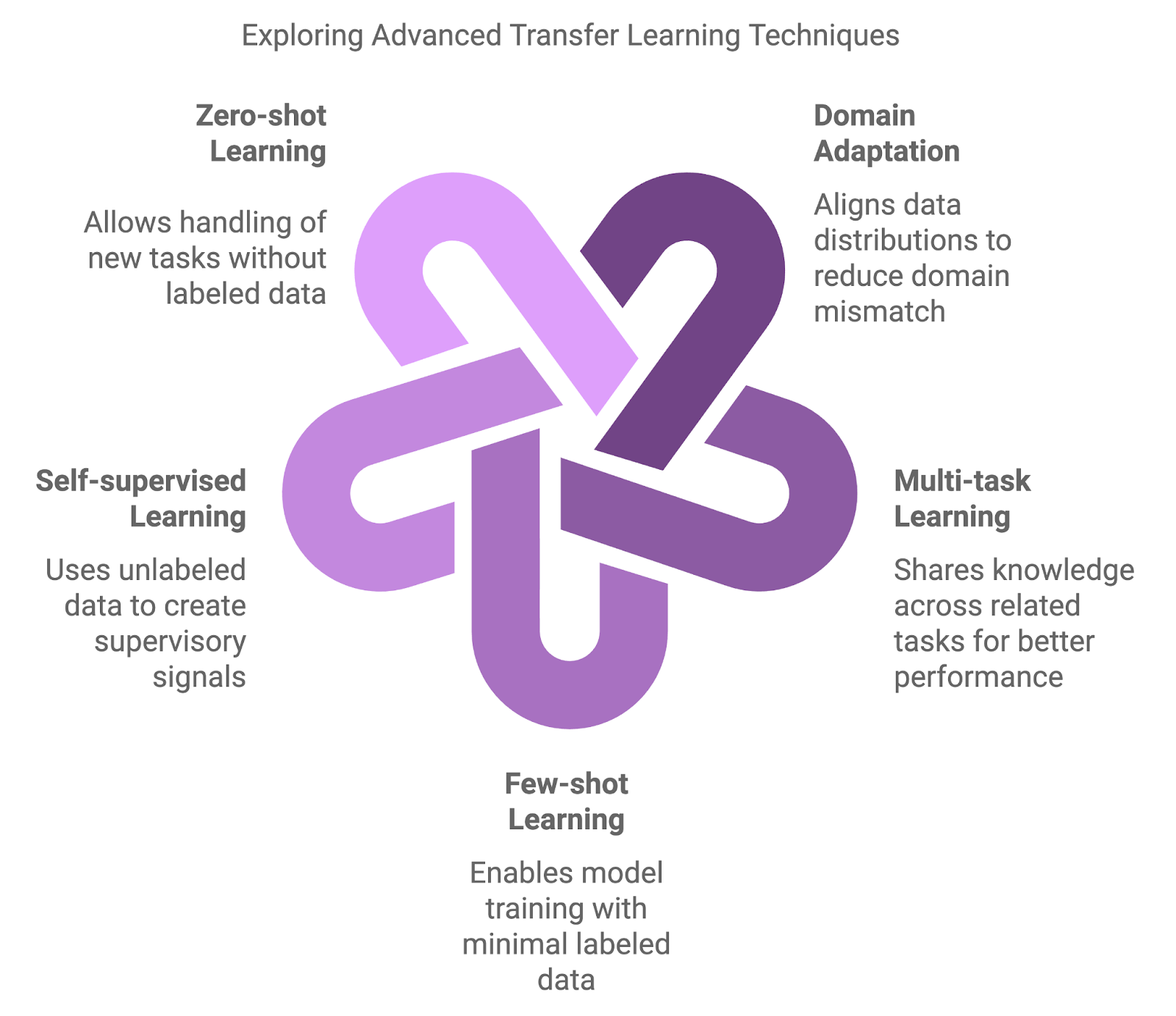
Diagrama gerado com o napkin.ai
Conforme discutido brevemente anteriormente, a adaptação de domínio é um subcampo da aprendizagem por transferência que se concentra em lidar com situações em que há uma diferença significativa, ou "mudança de domínio", entre os dados usados para treinar um modelo e os dados em que o modelo é implantado.
Na aprendizagem por transferência típica, supõe-se que os domínios de origem e de destino compartilhem características semelhantes, mas em muitos cenários do mundo real, esses domínios diferem substancialmente. Em última análise, isso pode prejudicar o desempenho, pois os modelos treinados em um conjunto de dados têm dificuldade para generalizar para novas condições.
As técnicas de adaptação de domínio são projetadas para preencher essa lacuna, permitindo que um modelo treinado em um domínio tenha um desempenho eficaz em outro, minimizando a discrepância entre as distribuições de dados de origem e de destino. Como resultado, a adaptação do domínio é ainda mais valiosa em situações em que os dados rotulados são abundantes em um domínio, mas escassos ou indisponíveis em outro.
Várias técnicas foram desenvolvidas para enfrentar o desafio da adaptação de domínio - duas das abordagens mais comuns são os métodos adversários e o aprendizado de recursos invariantes de domínio.
Uma técnica amplamente usada para a adaptação do domínio envolve o aprendizado contraditório. Nesse contexto, um modelo é treinado para aprender recursos que são úteis para a tarefa de destino e, ao mesmo tempo, garantir que esses recursos sejam indistinguíveis entre os domínios de origem e de destino.
Podemos fazer isso usando um discriminador, ou seja, uma rede neural encarregada de distinguir entre os dados de domínio de origem e de destino. O modelo é treinado de forma contraditória para que aprenda a "enganar" o discriminador, tornando as representações de recursos independentes do domínio. Se isso soa familiar, é porque essa técnica é inspirada em Redes Adversariais Generativas (GANs)que usam uma configuração semelhante para gerar dados sintéticos realistas.
Outra abordagem se concentra em aprender representações que não são afetadas por variações específicas do domínio. Isso transforma os dados de entrada de ambos os domínios em um espaço de recursos compartilhado em que os domínios de origem e de destino se alinham mais estreitamente. Técnicas como MMD (Maximum Mean Discrepancy, discrepância média máxima) e CORAL (Correlation Alignment, alinhamento de correlação) ajudam a minimizar as diferenças estatísticas nesse espaço, garantindo que o modelo possa ser generalizado com mais eficiência quando aplicado ao domínio de destino.
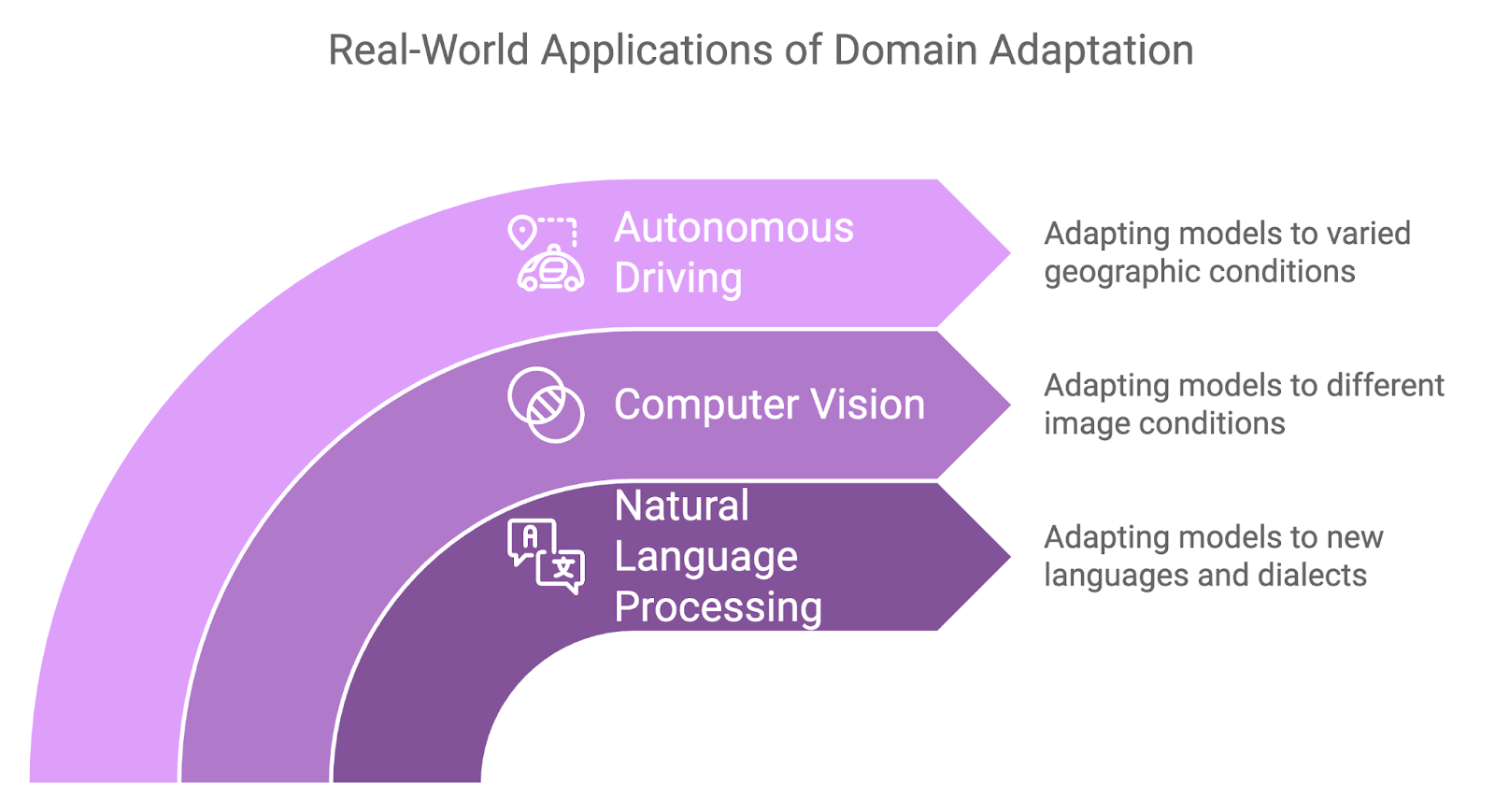
A adaptação de domínio provou ser útil em uma variedade de aplicativos do mundo real em que as mudanças de domínio são inevitáveis:
À medida que as tarefas de aprendizado de máquina aumentam em complexidade, a capacidade de lidar com vários problemas relacionados simultaneamente pode melhorar significativamente o desempenho e a eficiência de um modelo. O MTL aborda isso treinando modelos para executar várias tarefas ao mesmo tempo, em vez de se concentrar em uma única tarefa isoladamente.
A força da MTL está em sua capacidade de capitalizar relacionamentos e estruturas compartilhadas entre tarefas, permitindo que os modelos aprendam representações de recursos mais ricas. Os insights obtidos em uma tarefa melhoram o desempenho do modelo em outra, levando a uma maior eficiência geral de aprendizado.
Na MTL, duas estratégias principais são comumente usadas:
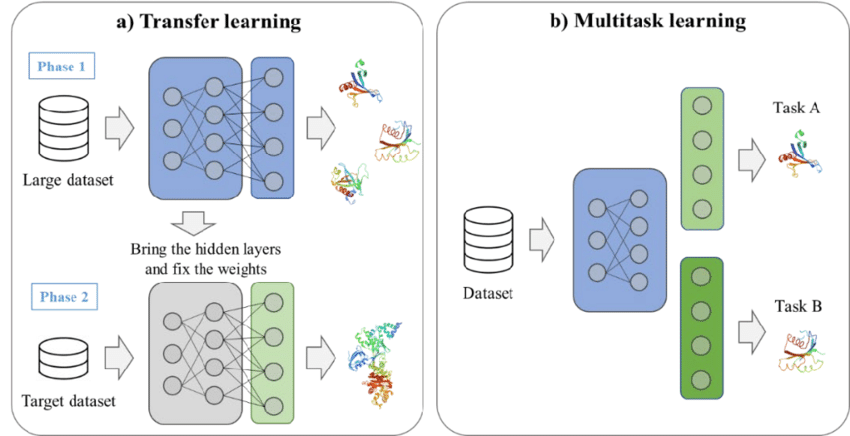
Um exemplo de aprendizagem por transferência e aprendizagem multitarefa. Fonte: Kim et al., 2021
O MTL oferece várias vantagens que o tornam uma abordagem valiosa para cenários complexos de aprendizado de máquina.
Ao aprender em várias tarefas, o modelo é exposto a uma gama mais ampla de dados e aprende representações mais gerais. Isso geralmente leva a um melhor desempenho em cada tarefa, especialmente quando essas tarefas estão relacionadas.
Com o MTL, os modelos fazem melhor uso dos dados disponíveis, especialmente em situações em que os dados rotulados são escassos. Como o modelo aprende com várias tarefas, ele pode usar insights de tarefas relacionadas para melhorar o desempenho. Esse aprendizado entre tarefas acelera o processo de aprendizado e reduz a dependência de grandes conjuntos de dados para cada tarefa.
Em vez de treinar modelos separados para cada tarefa, o MTL consolida o aprendizado em um único modelo. Isso reduz o custo computacional e o espaço de memória, tornando-o mais eficiente para a implantação em ambientes com recursos limitados.
A MTL tem sido aplicada com sucesso em vários domínios, com casos de uso notáveis em PNL e visão computacional.
No processamento de linguagem natural, o MTL é comumente usado para treinar modelos em várias tarefas relacionadas. Por exemplo, um modelo de linguagem pode ser treinado para realizar simultaneamente a tradução automática e a classificação de texto. Ao compartilhar representações aprendidas nessas tarefas, o modelo pode melhorar sua compreensão da estrutura e do contexto da linguagem, beneficiando ambas as tarefas.
Na visão computacional, a MTL pode ser aplicada a tarefas como detecção de objetos e segmentação de imagens. Podemos treinar um modelo para identificar objetos em uma imagem e, ao mesmo tempo, aprender a classificar esses objetos. Esse processo de aprendizado compartilhado permite que o modelo reconheça tanto a localização quanto a categoria dos objetos, tornando-o mais versátil e eficiente.
Em cenários em que os dados rotulados são escassos ou não estão disponíveis, o aprendizado de poucos disparos e a SSL surgiram como técnicas poderosas para lidar com as limitações dos métodos supervisionados tradicionais.
Essas abordagens oferecem maneiras inovadoras de adaptar modelos a novas tarefas com o mínimo de dados rotulados ou usando grandes quantidades de dados não rotulados, o que as torna ferramentas essenciais no campo da aprendizagem por transferência avançada.
Como já sabemos, a aprendizagem de poucos disparos foi projetada para permitir que os modelos se adaptem rapidamente a novas tarefas com apenas alguns exemplos rotulados.
No entanto, a coleta de grandes conjuntos de dados é impraticável em muitas aplicações, como o diagnóstico de doenças raras ou a identificação de produtos de nicho. O aprendizado de poucos disparos resolve isso transferindo o conhecimento de tarefas relacionadas e ajustando os modelos para que tenham um bom desempenho com o mínimo de novos dados.
A seguir, discutiremos duas estratégias importantes no aprendizado de poucos disparos.
Também conhecido como "aprender a aprender", o meta-aprendizado envolve o treinamento de um modelo para se adaptar rapidamente a novas tarefas com o mínimo de dados. A ideia é treinar o modelo em uma variedade de tarefas para que ele possa generalizar seu aprendizado e se ajustar rapidamente a tarefas inéditas.
As estruturas de meta-aprendizagem, como a MAML (Model-Agnostic Meta-Learning), permitem que o modelo aprenda um conjunto ideal de parâmetros que podem ser ajustados para novas tarefas com apenas alguns exemplos.
Outra abordagem comum são as redes prototípicas, que são projetadas para classificar pontos de dados calculando as distâncias entre eles em um espaço de recursos aprendido. Nessa configuração, cada classe é representada por um protótipo (a média dos exemplos dessa classe no espaço de recursos).
Novos pontos de dados são então classificados com base em sua proximidade com esses protótipos. As redes prototípicas podem ser eficazes no aprendizado de poucas tentativas, pois exigem apenas um número mínimo de exemplos por classe para gerar protótipos significativos para a classificação.
O SSL permite que os modelos extraiam representações significativas de grandes quantidades de dados não rotulados, gerando sinais de supervisão, ignorando a necessidade de rótulos manuais. Depois que o modelo tiver aprendido com os dados não rotulados, ele poderá ser ajustado em um conjunto de dados rotulados menor, obtendo um bom desempenho em tarefas posteriores.
Uma das técnicas de SSL mais impactantes é a aprendizagem contrastiva, que treina modelos comparando pares positivos e negativos de pontos de dados. O objetivo é aproximar os pontos de dados semelhantes (pares positivos) no espaço de recursos e afastar os pontos diferentes (pares negativos).
No processamento de linguagem natural, um método popular de SSL é a modelagem de linguagem mascarada, usada em modelos como o BERT. Aqui, partes da entrada são mascaradas, e o modelo é treinado para prever os elementos ausentes usando o contexto ao redor. Essa estratégia de pré-treinamento ajuda o modelo a aprender representações robustas e de uso geral que podem ser ajustadas para várias tarefas de PLN.
O aprendizado com poucos disparos e autossupervisionado é amplamente usado em campos em que as limitações de dados são uma barreira significativa. Aqui estão algumas das principais aplicações de cada uma delas.
O aprendizado de poucos disparos se mostra valioso na detecção de objetos personalizados, em que a identificação de objetos raros ou especializados pode exigir que os modelos aprendam com apenas alguns exemplos rotulados.
Em ambientes industriais, a detecção de defeitos em um processo de fabricação pode envolver muito poucas instâncias do defeito. Ao aproveitar o aprendizado de poucos disparos, um modelo pré-treinado em tarefas gerais de detecção de objetos pode ser rapidamente adaptado para detectar esses objetos específicos com o mínimo de dados de treinamento adicionais.
O aprendizado autossupervisionado revolucionou o processamento de linguagem natural por meio de modelos como GPT e BERT. Esses modelos aprendem representações de linguagem de uso geral que podem ser ajustadas para tarefas específicas com conjuntos de dados rotulados relativamente pequenos. Por exemplo, um modelo de linguagem pré-treinado usando SSL pode ser ajustado para executar tarefas como análise de sentimentos, classificação de texto ou sumarização, geralmente obtendo resultados de última geração.
As bibliotecas e estruturas de aprendizagem automática podem simplificar significativamente a implementação de métodos avançados de aprendizagem por transferência. Ferramentas como PyTorch, TensorFlowe Transformadores Hugging Face fornecem a flexibilidade necessária e componentes pré-construídos para acelerar o processo de desenvolvimento.
Para os profissionais que desejam implementar técnicas avançadas de aprendizagem por transferência, várias bibliotecas e estruturas oferecem amplo suporte:
A implementação de técnicas avançadas de aprendizagem por transferência é um desafio, e há alguns fatores críticos que precisamos ter em mente.
O ajuste fino em novas tarefas pode fazer com que os modelos "esqueçam" o que aprenderam em tarefas anteriores. Técnicas como Consolidação de peso elástico (EWC) podem ajudar a preservar os pesos do modelo pré-treinado, o que é fundamental para o conhecimento prévio.
Técnicas como adaptação de domínio e aprendizado multitarefa podem aumentar significativamente os requisitos computacionais. O treinamento de modelos de adaptação de domínio adversários ou arquiteturas multitarefa pode exigir mais recursos devido à complexidade adicional. Precisamos otimizar nosso modelo e usar ferramentas como treinamento de precisão mista para lidar com modelos grandes de forma eficiente.
Os modelos de aprendizagem por transferência pré-treinados em dados tendenciosos podem propagar ou até mesmo ampliar essas tendências em novas tarefas, levando a previsões distorcidas. Esse risco é crítico em áreas sensíveis, como saúde e finanças. Para garantir a imparcialidade, devemos avaliar regularmente os resultados do modelo quanto à parcialidade e aplicar técnicas de atenuação, como reponderação, desvios adversários ou aprendizado de representação justa.
Métodos avançados de aprendizagem por transferência estão sendo aplicados em vários setores, fornecendo soluções inovadoras para desafios complexos do mundo real. Veja abaixo alguns aplicativos importantes e exemplos do setor que destacam como essas técnicas estão impulsionando os avanços da IA.
O modelo GPT-4o da OpenAIda OpenAI, um dos principais exemplos de aprendizado de poucos disparos em ação, demonstrou a capacidade de se adaptar a novas tarefas com apenas alguns exemplos. O GPT-4o, pré-treinado em grandes quantidades de dados de texto, pode executar várias tarefas, como tradução, resumo e resposta a perguntas, sem a necessidade de ajuste fino específico da tarefa.
Em vez disso, os usuários fornecem alguns exemplos da tarefa desejada, e o modelo generaliza a partir daí. Esse recurso de aprendizado de poucos disparos ampliou a gama de aplicações para modelos de linguagem grandes, desde a escrita criativa até agentes de conversação.
A DeepMind, líder em pesquisa de IA, utilizou o aprendizado multitarefa para desenvolver modelos de saúde que podem auxiliar no diagnóstico de várias condições a partir de imagens médicas. Por exemplo, seu sistema de IA para detectar doenças oculares a partir de exames de retina é capaz de diagnosticar uma série de condições, incluindo retinopatia diabética e degeneração macular relacionada à idade, usando um único modelo.
Essa abordagem MTL reduz a necessidade de modelos separados para cada condição, permitindo que os prestadores de serviços de saúde otimizem seus processos de diagnóstico e ofereçam um atendimento mais rápido e preciso aos pacientes.
O Waymo (projeto de carro autônomo do Google) usa técnicas de adaptação de domínio para melhorar a generalização de seus modelos de veículos autônomos em vários ambientes de direção. A empresa treina seus modelos em ambientes simulados e depois os adapta para implantação no mundo real em diferentes cidades e condições climáticas.
Esse processo garante que os carros autônomos possam lidar com as nuances de diferentes paisagens urbanas, desde as ruas congestionadas de São Francisco até as rodovias abertas do Arizona, sem a necessidade de um treinamento extensivo para cada local.
Os pesquisadores estão constantemente ampliando os limites, esforçando-se para tornar os modelos mais adaptáveis, justos e capazes de lidar com tarefas complexas do mundo real e, ao mesmo tempo, reduzir a quantidade de dados e o tempo de treinamento necessários.
A aprendizagem contínua ou aprendizagem ao longo da vida concentra-se no desenvolvimento de modelos que podem aprender continuamente com novos dados e, ao mesmo tempo, reter o conhecimento de tarefas aprendidas anteriormente. Em contraste com a aprendizagem por transferência tradicional, em que os modelos são estáticos após o ajuste fino, a aprendizagem contínua permite a adaptação contínua a novas informações.
Isso é vital para ambientes dinâmicos, como robótica e sistemas autônomos, em que novos cenários surgem regularmente. Nesse contexto, as estratégias baseadas na memória ajudam a equilibrar a necessidade de preservar o conhecimento anterior e, ao mesmo tempo, incorporar novas habilidades. Os desenvolvimentos futuros visam estender a aprendizagem contínua a domínios mais complexos, garantindo que os modelos possam ser atualizados com eficiência sem comprometer o desempenho anterior.
À medida que a aprendizagem por transferência se torna mais predominante em setores como saúde, finanças e aplicação da lei, é impossível ignorar a necessidade de abordar a justiça e o preconceito.
Os modelos pré-treinados em conjuntos de dados grandes e diversificados geralmente apresentam vieses inerentes, o que pode levar a resultados distorcidos em novos aplicativos. Para neutralizar isso, os pesquisadores estão explorando técnicas como a eliminação de vieses adversários, a reponderação e o aprendizado de representação justa para detectar e atenuar esses vieses.
Garantir a imparcialidade continuará sendo o foco central da pesquisa sobre aprendizagem por transferência, especialmente em domínios sensíveis em que as previsões tendenciosas podem ter implicações no mundo real.
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita

