
Track
Developing AI Applications
21 hr
Traditional approaches, such as pre-training on a large dataset and then fine-tuning on a task-specific dataset, are foundational but sometimes insufficient. More advanced methods have emerged to tackle the nuances of domain shifts, data scarcity, and multi-task learning.
Advanced methods introduce additional layers of complexity and flexibility. These techniques aim to improve model performance in scenarios where traditional approaches may not be adequate.
Domain adaptation techniques are designed to handle discrepancies between the source (pre-training) and target (fine-tuning) domains. Traditional fine-tuning often yields suboptimal results when pre-trained models encounter data that diverges significantly from their training data. Domain adaptation techniques reduce this mismatch by aligning data distributions, ensuring the model can generalize better in novel settings.
MTL allows a model to learn across multiple related tasks simultaneously. By sharing knowledge between tasks, the model can use commonalities and improve performance across all tasks. This strategy is especially effective when tasks are complementary, such as joint learning of text classification and sentiment analysis in natural language processing. MTL enhances generalization and reduces the risk of overfitting by guiding the model to focus on shared patterns.
Another key technique is few-shot learning, designed to train models with minimal labeled data. While traditional approaches require vast amounts of labeled data, few-shot techniques allow models to transfer knowledge using only a few examples. Methods like meta-learning and prototypical networks can lead to quick adaptation to new tasks, making them invaluable in fields like personalized recommendations or niche image classifications.
SSL uses unlabeled data to train models, cementing it as a powerful tool when labeled data is scarce or unavailable. This technique constructs supervisory signals from the data itself, solving pretext tasks such as predicting missing parts of an image or reconstructing scrambled text. Models pre-trained using SSL have demonstrated high transferability across a range of applications.
Zero-shot learning goes a step further by allowing models to handle completely new tasks without any labeled data. This is achieved through auxiliary information like semantic relationships or task descriptions, enabling the model to generalize even when faced with novel categories. This capability is highly relevant in dynamic fields where new categories frequently emerge, such as in NLP applications handling newly coined terms or slang.
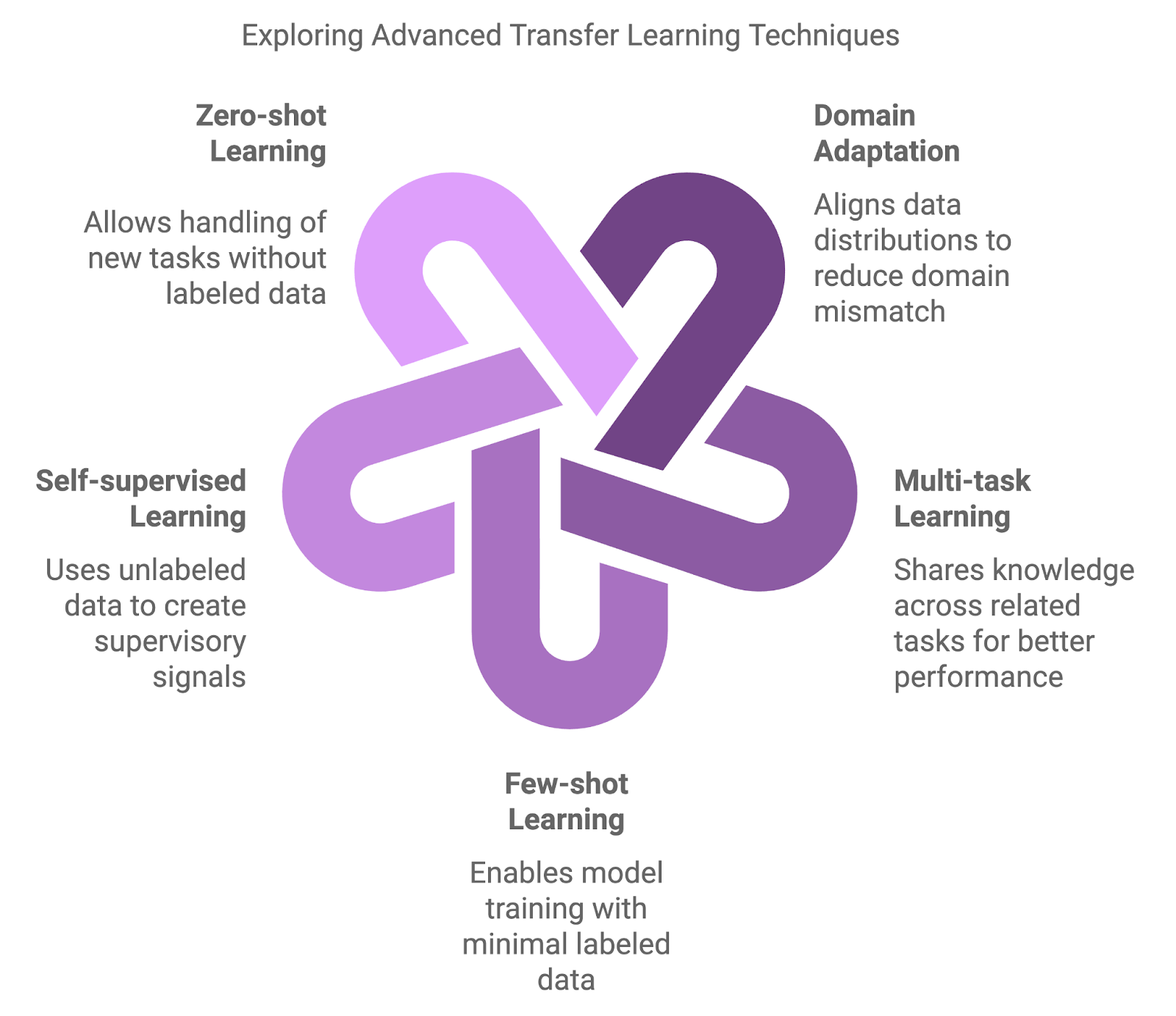
Diagram generated with napkin.ai
As briefly discussed earlier, domain adaptation is a subfield of transfer learning focused on handling situations where there is a significant difference, or "domain shift," between the data used to train a model and the data where the model is deployed.
In typical transfer learning, it's assumed that the source and target domains share similar characteristics, but in many real-world scenarios, these domains differ substantially. Ultimately, this can degrade performance, as models trained on one set of data struggle to generalize to new conditions.
Domain adaptation techniques are designed to bridge this gap, enabling a model trained in one domain to perform effectively in another by minimizing the discrepancy between the source and target data distributions. As a result, domain adaptation is even more valuable in situations where labeled data is abundant in one domain but scarce or unavailable in another.
Several techniques have been developed to tackle the challenge of domain adaptation—two of the most common approaches are adversarial methods and domain-invariant feature learning.
One widely used technique for domain adaptation involves adversarial learning. In this context, a model is trained to learn features that are useful for the target task while simultaneously ensuring that these features are indistinguishable between the source and target domains.
We can accomplish this using a discriminator, i.e. a neural network tasked with distinguishing between source and target domain data. The model is trained in an adversarial manner so that it learns to "fool" the discriminator, making the feature representations domain-invariant. If this sounds familiar, it’s because this technique is inspired by Generative Adversarial Networks (GANs), which use a similar setup to generate realistic synthetic data.
Another approach focuses on learning representations that are unaffected by domain-specific variations. This transforms input data from both domains into a shared feature space where the source and target domains align more closely. Techniques such as Maximum Mean Discrepancy (MMD) and CORAL (Correlation Alignment) help minimize statistical differences in this space, ensuring the model can generalize more effectively when applied to the target domain.
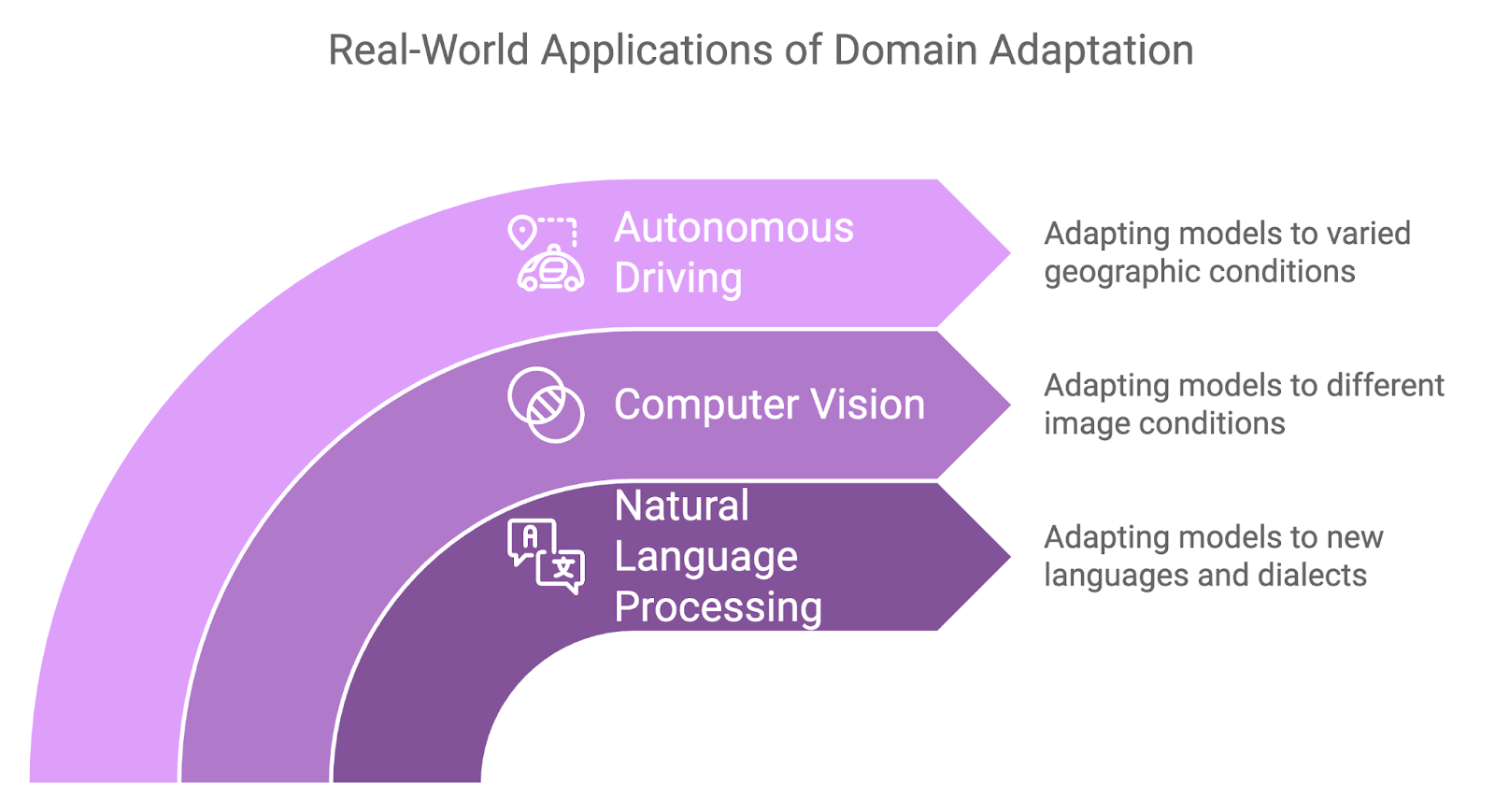
Domain adaptation has proven to be useful in a variety of real-world applications where domain shifts are inevitable:
As machine learning tasks grow in complexity, the ability to tackle multiple related problems simultaneously can significantly enhance a model’s performance and efficiency. MTL addresses this by training models to perform multiple tasks at once, rather than focusing on a single task in isolation.
The strength of MTL lies in its ability to capitalize on relationships and shared structures between tasks, enabling models to learn richer feature representations. Insights gained from one task improve the model's performance on another, leading to greater overall learning efficiency.
In MTL, two main strategies are commonly used:
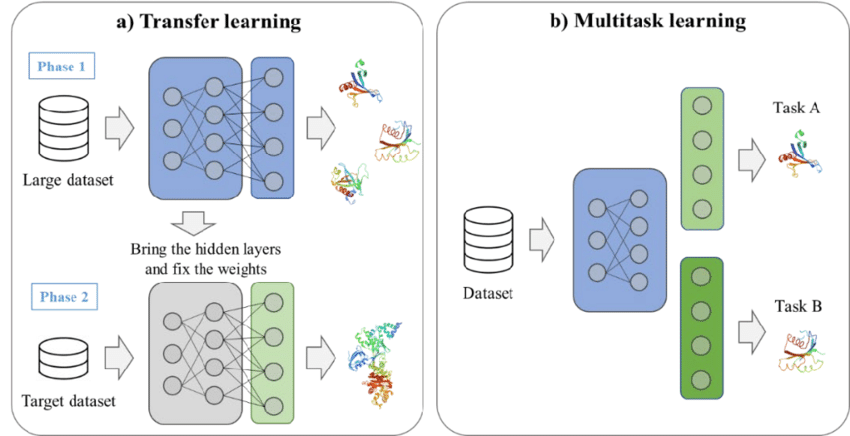
An example of transfer learning and multitask learning. Source: Kim et al., 2021
MTL offers several advantages that make it a valuable approach for complex machine-learning scenarios.
By learning across multiple tasks, the model is exposed to a broader range of data and learns more general representations. This often leads to better performance on each task, especially when those tasks are related.
With MTL, models make better use of available data, particularly in situations where labeled data is scarce. Since the model learns from multiple tasks, it can use insights from related tasks to improve performance. This cross-task learning accelerates the learning process and reduces the reliance on large datasets for each task.
Instead of training separate models for each task, MTL consolidates learning into a single model. This reduces the computational cost and memory footprint, making it more efficient for deployment in environments with limited resources.
MTL has been successfully applied across various domains, with notable use cases in NLP and computer vision.
In natural language processing, MTL is commonly used to train models on multiple related tasks. For instance, a language model can be trained to perform both machine translation and text classification simultaneously. By sharing learned representations across these tasks, the model can improve its understanding of language structure and context, benefiting both tasks.
In computer vision, MTL can be applied to tasks like object detection and image segmentation. We can train a model to identify objects within an image while simultaneously also learning to classify those objects. This shared learning process allows the model to recognize both the location and category of objects, making it more versatile and efficient.
In scenarios where labeled data is scarce or unavailable, few-shot learning and SSL have emerged as powerful techniques to address the limitations of traditional supervised methods.
These approaches offer innovative ways to adapt models to new tasks with minimal labeled data or by using large amounts of unlabeled data, making them essential tools in the realm of advanced transfer learning.
As we now know, few-shot learning is designed to enable models to quickly adapt to new tasks with only a few labeled examples.
However, collecting large datasets is impractical in many applications, such as rare disease diagnosis or niche product identification. Few-shot learning solves this by transferring knowledge from related tasks and fine-tuning models to perform well with minimal new data.
Below, we discuss two key strategies in few-shot learning.
Also known as "learning to learn," meta-learning involves training a model to adapt quickly to new tasks with minimal data. The idea is to train the model across a variety of tasks so that it can generalize its learning and rapidly adjust to unseen tasks.
Meta-learning frameworks like Model-Agnostic Meta-Learning (MAML) enable the model to learn an optimal set of parameters that can be fine-tuned to new tasks with only a few examples.
Another common approach is prototypical networks, which are designed to classify data points by computing distances between them in a learned feature space. In this setup, each class is represented by a prototype (the mean of the examples from that class in the feature space).
New data points are then classified based on their proximity to these prototypes. Prototypical networks can be effective in few-shot learning as they require only a minimal number of examples per class to generate meaningful prototypes for classification.
SSL allows models to extract meaningful representations from vast amounts of unlabeled data by generating supervisory signals, bypassing the need for manual labels. Once the model has learned from the unlabeled data, it can then be fine-tuned on a smaller labeled dataset, achieving strong performance on downstream tasks.
One of the most impactful SSL techniques is contrastive learning, which trains models by comparing positive and negative pairs of data points. The objective is to pull similar data points (positive pairs) closer together in the feature space while pushing dissimilar ones (negative pairs) farther apart.
In natural language processing, a popular SSL method is masked language modeling, used in models like BERT. Here, parts of the input are masked, and the model is trained to predict the missing elements using the surrounding context. This pre-training strategy helps the model learn robust, general-purpose representations that can be fine-tuned for various NLP tasks.
Few-shot and self-supervised learning are widely used in fields where data limitations are a significant barrier. Here are a few key applications of each.
Few-shot learning proves valuable in custom object detection, where identifying rare or specialized objects may require models to learn from only a handful of labeled examples.
In industrial settings, detecting defects in a manufacturing process might involve very few instances of the defect. By leveraging few-shot learning, a model pre-trained on general object detection tasks can be quickly adapted to detect these specific objects with minimal additional training data.
Self-supervised learning has revolutionized natural language processing through models like GPT and BERT. These models learn general-purpose language representations that can be fine-tuned for specific tasks with relatively small labeled datasets. For example, a language model pre-trained using SSL can be fine-tuned to perform tasks like sentiment analysis, text classification, or summarization, often achieving state-of-the-art results.
Machine learning libraries and frameworks can significantly simplify the implementation of advanced transfer learning methods. Tools like PyTorch, TensorFlow, and Hugging Face Transformers provide the necessary flexibility and pre-built components to accelerate the development process.
For practitioners looking to implement advanced transfer learning techniques, several libraries and frameworks provide extensive support:
Implementing advanced transfer learning techniques is challenging, and there are some critical factors we need to keep in mind.
Fine-tuning on new tasks can cause models to "forget" what they’ve learned from earlier tasks. Techniques like Elastic Weight Consolidation (EWC) can help preserve the weights of the pre-trained model, which is crucial for prior knowledge.
Techniques like domain adaptation and multi-task learning can significantly increase computational requirements. Training adversarial domain adaptation models or multi-task architectures may require more resources due to the additional complexity. We need to optimize our model and use tools like mixed precision training to handle large models efficiently.
Transfer learning models pre-trained on biased data may propagate or even amplify these biases in new tasks, leading to skewed predictions. This risk is critical in sensitive fields like healthcare and finance. To ensure fairness, we should regularly evaluate model outputs for bias and apply mitigation techniques such as reweighting, adversarial de-biasing, or fair representation learning.
Advanced transfer learning methods are being applied across various industries, providing innovative solutions to complex real-world challenges. Below are some key applications and industry examples that highlight how these techniques are driving AI advancements.
OpenAI’s GPT-4o model, a leading example of few-shot learning in action, has demonstrated the ability to adapt to new tasks with only a few examples. GPT-4o, pre-trained on massive amounts of text data, can perform various tasks such as translation, summarization, and question-answering without the need for task-specific fine-tuning.
Instead, users provide a few examples of the desired task, and the model generalizes from there. This few-shot learning capability has broadened the range of applications for large language models, from creative writing to conversational agents.
DeepMind, a leader in AI research, has utilized multi-task learning to develop healthcare models that can assist in diagnosing multiple conditions from medical imaging. For instance, their AI system for detecting eye diseases from retinal scans is capable of diagnosing a range of conditions, including diabetic retinopathy and age-related macular degeneration, using a single model.
This MTL approach reduces the need for separate models for each condition, allowing healthcare providers to streamline their diagnostic processes and provide faster, more accurate patient care.
Waymo (Google’s self-driving car project) uses domain adaptation techniques to improve the generalization of its autonomous vehicle models across various driving environments. The company trains its models in simulated environments and then adapts them for real-world deployment in different cities and weather conditions.
This process ensures that self-driving cars can handle the nuances of different urban landscapes, from congested streets in San Francisco to wide-open highways in Arizona, without requiring extensive retraining for each location.
Researchers are constantly pushing the boundaries, striving to make models more adaptable, fair, and capable of handling complex real-world tasks while reducing the amount of data and training time required.
Continual learning or lifelong learning focuses on developing models that can continuously learn from new data while retaining knowledge from previously learned tasks. In contrast to traditional transfer learning, where models are static once fine-tuned, continual learning allows for ongoing adaptation to new information.
This is vital for dynamic environments, such as robotics and autonomous systems, where new scenarios are bound to emerge regularly. In this context, memory-based strategies help balance the need to preserve past knowledge while incorporating new skills. Future developments aim to extend continual learning to more complex domains, ensuring models can update efficiently without compromising earlier performance.
As transfer learning becomes more prevalent in industries like healthcare, finance, and law enforcement, the need to address fairness and bias is impossible to ignore.
Models pre-trained on large, diverse datasets often carry inherent biases, which can lead to skewed outcomes in new applications. To counteract this, researchers are exploring techniques such as adversarial de-biasing, reweighting, and fair representation learning to detect and mitigate these biases.
Ensuring fairness will remain a central focus in transfer learning research, especially in sensitive domains where biased predictions can have real-world implications.
Learn AI with these courses!
Track
Course
Course
blog
Javier Canales Luna
7 min
blog
Stanislav Karzhev
12 min
blog
Vinod Chugani
10 min
Tutorial
Lars Hulstaert
Tutorial
Moez Ali
Tutorial
Matt Crabtree

