
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Herkömmliche Ansätze, wie das Vortraining auf einem großen Datensatz und das anschließende Feintuning auf einem aufgabenspezifischen Datensatz, sind zwar grundlegend, aber manchmal nicht ausreichend. Es wurden fortschrittlichere Methoden entwickelt, um die Feinheiten von Domänenverschiebungen, Datenknappheit und Multi-Task-Lernen zu bewältigen.
Fortgeschrittene Methoden bringen zusätzliche Ebenen der Komplexität und Flexibilität mit sich. Diese Techniken zielen darauf ab, die Modellleistung in Szenarien zu verbessern, in denen herkömmliche Ansätze möglicherweise nicht ausreichend sind.
Techniken zur Domänenanpassung wurden entwickelt, um Diskrepanzen zwischen der Quell- (Pre-Training) und der Zieldomäne (Fine-Tuning) zu bewältigen. Die herkömmliche Feinabstimmung führt oft zu suboptimalen Ergebnissen, wenn vortrainierte Modelle auf Daten treffen, die erheblich von ihren Trainingsdaten abweichen. Techniken zur Bereichsanpassung verringern diese Diskrepanz, indem sie die Datenverteilungen angleichen und so sicherstellen, dass das Modell in neuen Situationen besser verallgemeinert werden kann.
MTL ermöglicht es einem Modell, über mehrere zusammenhängende Aufgaben gleichzeitig zu lernen. Durch den Austausch von Wissen zwischen den Aufgaben kann das Modell Gemeinsamkeiten nutzen und die Leistung bei allen Aufgaben verbessern. Diese Strategie ist besonders effektiv, wenn sich die Aufgaben ergänzen, wie z.B. beim gemeinsamen Lernen von Textklassifikation und Sentimentanalyse in der natürlichen Sprachverarbeitung. MTL verbessert die Generalisierung und verringert das Risiko einer Überanpassung, indem es das Modell dazu anleitet, sich auf gemeinsame Muster zu konzentrieren.
Eine weitere wichtige Technik ist few-shot learningdas darauf abzielt, Modelle mit minimalen gelabelten Daten zu trainieren. Während herkömmliche Ansätze riesige Mengen an gekennzeichneten Daten benötigen, können Modelle mit Hilfe von wenigen Beispielen Wissen übertragen. Methoden wie Meta-Lernen und prototypische Netzwerke können zu einer schnellen Anpassung an neue Aufgaben führen, was sie in Bereichen wie personalisierten Empfehlungen oder Nischenbildklassifizierungen von unschätzbarem Wert macht.
SSL nutzt unbeschriftete Daten, um Modelle zu trainieren. Das macht es zu einem leistungsstarken Werkzeug, wenn beschriftete Daten knapp sind oder nicht zur Verfügung stehen. Diese Technik konstruiert Überwachungssignale aus den Daten selbst und löst so Aufgaben wie die Vorhersage fehlender Teile eines Bildes oder die Rekonstruktion von verschlüsseltem Text. Modelle, die mit SSL trainiert wurden, haben eine hohe Übertragbarkeit auf eine Reihe von Anwendungen gezeigt.
Das Zero-Shot-Lernen geht noch einen Schritt weiter, indem es den Modellen ermöglicht, völlig neue Aufgaben ohne gelabelte Daten zu bewältigen. Dies wird durch Zusatzinformationen wie semantische Beziehungen oder Aufgabenbeschreibungen erreicht, die es dem Modell ermöglichen, auch bei neuen Kategorien zu generalisieren. Diese Fähigkeit ist in dynamischen Bereichen, in denen häufig neue Kategorien auftauchen, von großer Bedeutung, z. B. in NLP-Anwendungen, die mit neu geprägten Begriffen oder Slang arbeiten.
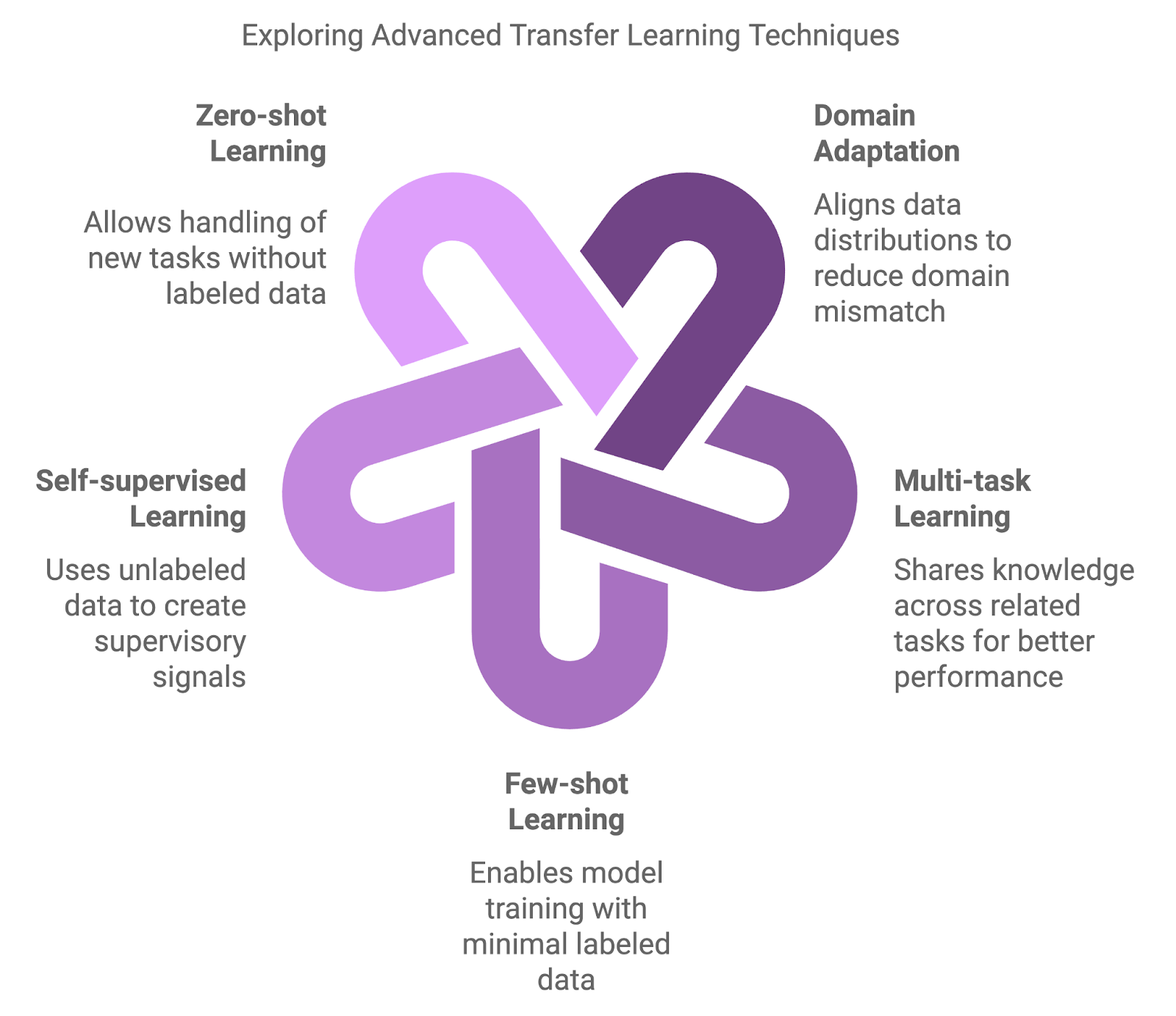
Mit napkin.ai erstelltes Diagramm
Wie bereits kurz erläutert, ist die Domänenanpassung ein Teilbereich des Transferlernens, der sich mit Situationen befasst, in denen ein signifikanter Unterschied oder "Domänenwechsel" zwischen den Daten, die zum Trainieren eines Modells verwendet wurden, und den Daten, in denen das Modell eingesetzt wird, besteht.
Beim typischen Transferlernen wird davon ausgegangen, dass die Quell- und die Zieldomäne ähnliche Merkmale aufweisen, aber in vielen realen Szenarien unterscheiden sich diese Domänen erheblich. Letztlich kann dies die Leistung beeinträchtigen, da Modelle, die auf einem Datensatz trainiert wurden, nur schwer auf neue Bedingungen verallgemeinert werden können.
Techniken zur Domänenanpassung sollen diese Kluft überbrücken, indem sie ein in einer Domäne trainiertes Modell in die Lage versetzen, in einer anderen Domäne effektiv zu arbeiten, indem sie die Diskrepanz zwischen den Verteilungen der Ausgangs- und Zieldaten minimieren. Daher ist die Domänenanpassung umso wertvoller, wenn in einer Domäne viele beschriftete Daten vorhanden sind, in einer anderen aber nur wenige oder gar keine.
Es wurden verschiedene Techniken entwickelt, um die Herausforderung der Domänenanpassung zu meistern - zwei der gängigsten Ansätze sind adversarische Methoden und domäneninvariantes Merkmalslernen.
Eine weit verbreitete Technik für die Domänenanpassung ist das kontradiktorische Lernen. In diesem Zusammenhang wird ein Modell so trainiert, dass es Merkmale lernt, die für die Zielaufgabe nützlich sind, während gleichzeitig sichergestellt wird, dass diese Merkmale zwischen der Ausgangs- und der Zieldomäne nicht unterscheidbar sind.
Wir können dies mit einem Diskriminator erreichen, d.h. einem neuronales Netz das die Aufgabe hat, zwischen Quell- und Zieldaten zu unterscheiden. Das Modell wird so trainiert, dass es lernt, den Diskriminator zu "täuschen", indem es die Merkmalsrepräsentationen domäneninvariant macht. Wenn dir das bekannt vorkommt, dann liegt das daran, dass diese Technik von Generative Adversarial Networks (GANs)inspiriert, die einen ähnlichen Aufbau verwenden, um realistische synthetische Daten zu erzeugen.
Ein anderer Ansatz konzentriert sich auf das Erlernen von Repräsentationen, die von domänenspezifischen Variationen unbeeinflusst sind. Dadurch werden die Eingabedaten aus beiden Bereichen in einen gemeinsamen Merkmalsraum umgewandelt, in dem sich die Quell- und die Zieldomäne stärker annähern. Techniken wie Maximum Mean Discrepancy (MMD) und CORAL (Correlation Alignment) helfen dabei, statistische Unterschiede in diesem Raum zu minimieren, damit das Modell bei der Anwendung auf den Zielbereich besser verallgemeinert werden kann.
Die Domänenanpassung hat sich in einer Reihe von realen Anwendungen als nützlich erwiesen, bei denen Domänenverschiebungen unvermeidlich sind:
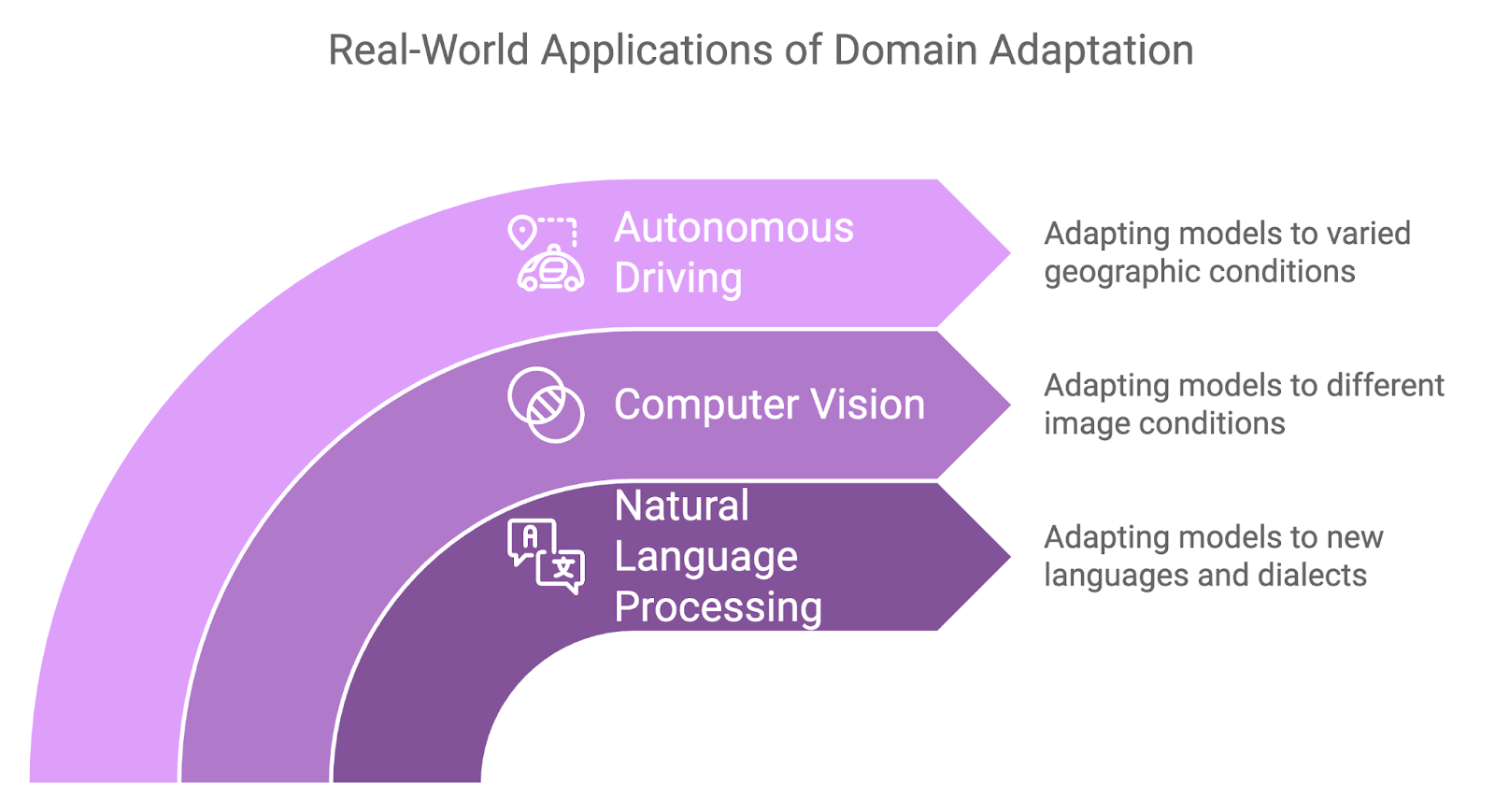
Da die Aufgaben des maschinellen Lernens immer komplexer werden, kann die Fähigkeit, mehrere zusammenhängende Probleme gleichzeitig zu lösen, die Leistung und Effizienz eines Modells erheblich steigern. MTL geht dieses Problem an, indem es Modelle trainiert, die mehrere Aufgaben gleichzeitig ausführen, anstatt sich auf eine einzelne Aufgabe zu konzentrieren.
Die Stärke der MTL liegt in ihrer Fähigkeit, Beziehungen und gemeinsame Strukturen zwischen Aufgaben zu nutzen, so dass die Modelle umfangreichere Merkmalsrepräsentationen lernen können. Die aus einer Aufgabe gewonnenen Erkenntnisse verbessern die Leistung des Modells bei einer anderen Aufgabe, was zu einer größeren Lerneffizienz führt.
Bei MTL werden in der Regel zwei Strategien angewendet:
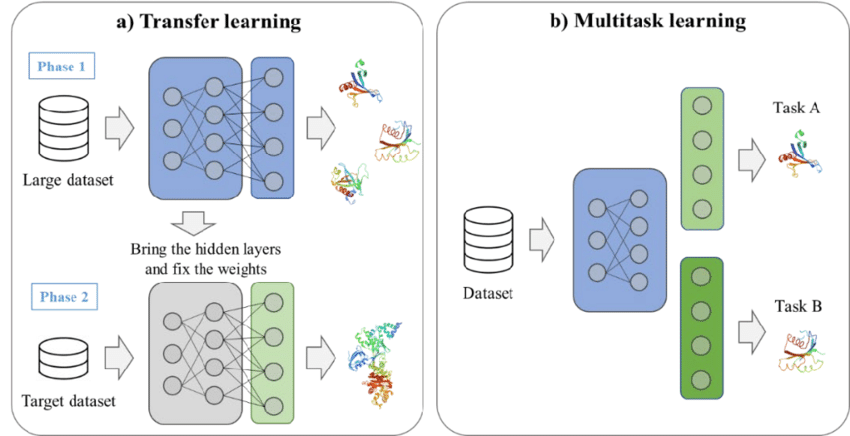
Ein Beispiel für Transferlernen und Multitasking. Quelle: Kim et al., 2021
MTL bietet mehrere Vorteile, die sie zu einem wertvollen Ansatz für komplexe Machine-Learning-Szenarien machen.
Durch das Lernen über mehrere Aufgaben hinweg wird das Modell einer breiteren Palette von Daten ausgesetzt und lernt allgemeinere Repräsentationen. Das führt oft zu einer besseren Leistung bei den einzelnen Aufgaben, vor allem wenn diese Aufgaben miteinander verbunden sind.
Mit MTL nutzen die Modelle die verfügbaren Daten besser, vor allem in Situationen, in denen es nur wenige beschriftete Daten gibt. Da das Modell aus mehreren Aufgaben lernt, kann es Erkenntnisse aus verwandten Aufgaben nutzen, um die Leistung zu verbessern. Dieses aufgabenübergreifende Lernen beschleunigt den Lernprozess und reduziert die Abhängigkeit von großen Datensätzen für jede Aufgabe.
Anstatt für jede Aufgabe separate Modelle zu trainieren, fasst MTL das Lernen in einem einzigen Modell zusammen. Dadurch werden die Rechenkosten und der Speicherbedarf reduziert, was den Einsatz in Umgebungen mit begrenzten Ressourcen effizienter macht.
MTL wurde bereits in verschiedenen Bereichen erfolgreich eingesetzt, insbesondere in den Bereichen NLP und Computer Vision.
In der Verarbeitung natürlicher Sprache wird die MTL häufig verwendet, um Modelle für mehrere verwandte Aufgaben zu trainieren. Ein Sprachmodell kann zum Beispiel so trainiert werden, dass es gleichzeitig eine maschinelle Übersetzung und eine Textklassifizierung durchführt. Durch die gemeinsame Nutzung gelernter Repräsentationen in diesen Aufgaben kann das Modell sein Verständnis von Sprachstruktur und Kontext verbessern, was beiden Aufgaben zugute kommt.
In der Computer Vision kann MTL für Aufgaben wie Objekterkennung und Bildsegmentierung eingesetzt werden. Wir können ein Modell trainieren, um Objekte in einem Bild zu identifizieren und gleichzeitig zu lernen, diese Objekte zu klassifizieren. Dieser gemeinsame Lernprozess ermöglicht es dem Modell, sowohl den Ort als auch die Kategorie von Objekten zu erkennen, was es vielseitiger und effizienter macht.
In Szenarien, in denen nur wenige oder keine gelabelten Daten zur Verfügung stehen, haben sich "few-shot learning" und SSL als leistungsstarke Techniken herauskristallisiert, um die Grenzen traditioneller überwachter Methoden zu überwinden.
Diese Ansätze bieten innovative Möglichkeiten, Modelle an neue Aufgaben mit minimalen gelabelten Daten oder mit großen Mengen an nicht gelabelten Daten anzupassen, was sie zu wichtigen Werkzeugen im Bereich des fortgeschrittenen Transferlernens macht.
Wie wir jetzt wissen, soll das "few-shot learning" Modelle in die Lage versetzen, sich mit nur wenigen gelabelten Beispielen schnell an neue Aufgaben anzupassen.
Das Sammeln großer Datensätze ist jedoch für viele Anwendungen unpraktisch, z. B. für die Diagnose seltener Krankheiten oder die Identifizierung von Nischenprodukten. Das Few-Shot-Lernen löst dieses Problem, indem es Wissen aus verwandten Aufgaben überträgt und die Modelle so fein abstimmt, dass sie auch mit wenigen neuen Daten gut funktionieren.
Im Folgenden besprechen wir zwei wichtige Strategien beim Lernen mit wenigen Schüssen.
Beim Meta-Lernen geht es darum, ein Modell so zu trainieren, dass es sich mit wenigen Daten schnell an neue Aufgaben anpassen kann. Die Idee ist, das Modell für eine Vielzahl von Aufgaben zu trainieren, damit es sein Lernen verallgemeinern und sich schnell an unbekannte Aufgaben anpassen kann.
Meta-Learning-Frameworks wie Model-Agnostic Meta-Learning (MAML) ermöglichen es dem Modell, einen optimalen Satz von Parametern zu lernen, der mit nur wenigen Beispielen auf neue Aufgaben abgestimmt werden kann.
Ein weiterer gängiger Ansatz sind prototypische Netze, die Datenpunkte klassifizieren, indem sie die Abstände zwischen ihnen in einem gelernten Merkmalsraum berechnen. Dabei wird jede Klasse durch einen Prototyp (den Mittelwert der Beispiele aus dieser Klasse im Merkmalsraum) repräsentiert.
Neue Datenpunkte werden dann anhand ihrer Nähe zu diesen Prototypen klassifiziert. Prototypische Netze können beim Lernen mit wenigen Beispielen effektiv sein, da sie nur eine minimale Anzahl von Beispielen pro Klasse benötigen, um aussagekräftige Prototypen für die Klassifizierung zu erzeugen.
SSL ermöglicht es den Modellen, sinnvolle Darstellungen aus riesigen Mengen unbeschrifteter Daten zu extrahieren, indem sie Überwachungssignale erzeugen und so die Notwendigkeit manueller Beschriftungen umgehen. Sobald das Modell aus den unmarkierten Daten gelernt hat, kann es auf einem kleineren markierten Datensatz feinabgestimmt werden, um bei den nachfolgenden Aufgaben eine gute Leistung zu erzielen.
Eine der wirkungsvollsten SSL-Techniken ist das kontrastive Lernen, bei dem Modelle durch den Vergleich positiver und negativer Datenpunktpaare trainiert werden. Das Ziel ist es, ähnliche Datenpunkte (positive Paare) im Merkmalsraum näher zusammenzubringen und unähnliche (negative Paare) weiter auseinander zu schieben.
In der natürlichen Sprachverarbeitung ist eine beliebte SSL-Methode die maskierte Sprachmodellierung, die in Modellen wie BERT verwendet wird. Hier werden Teile des Inputs ausgeblendet und das Modell wird darauf trainiert, die fehlenden Elemente anhand des umgebenden Kontexts vorherzusagen. Diese Pre-Training-Strategie hilft dem Modell, robuste, universell einsetzbare Repräsentationen zu lernen, die für verschiedene NLP-Aufgaben fein abgestimmt werden können.
Few-Shot und selbstüberwachtes Lernen werden häufig in Bereichen eingesetzt, in denen Datenbeschränkungen ein großes Hindernis darstellen. Hier sind ein paar wichtige Anwendungen.
Few-Shot-Lernen erweist sich als wertvoll bei der Erkennung von Objekten, bei denen die Identifizierung von seltenen oder speziellen Objekten erfordert, dass die Modelle aus nur einer Handvoll markierter Beispiele lernen.
In der Industrie kann es vorkommen, dass bei der Erkennung von Defekten in einem Fertigungsprozess nur sehr wenige Fälle des Fehlers auftreten. Durch den Einsatz von "few-shot learning" kann ein Modell, das für allgemeine Objekterkennungsaufgaben trainiert wurde, schnell angepasst werden, um diese speziellen Objekte mit minimalen zusätzlichen Trainingsdaten zu erkennen.
Selbstüberwachtes Lernen hat die Verarbeitung natürlicher Sprache durch Modelle wie GPT und BERT revolutioniert. Diese Modelle lernen universelle Sprachrepräsentationen, die für bestimmte Aufgaben mit relativ kleinen Datensätzen fein abgestimmt werden können. Ein Sprachmodell, das mit SSL trainiert wurde, kann zum Beispiel für Aufgaben wie Stimmungsanalyse, Textklassifizierung oder Zusammenfassungen fein abgestimmt werden und erzielt dabei oft die besten Ergebnisse.
Bibliotheken und Frameworks für maschinelles Lernen können die Umsetzung fortgeschrittener Transfer-Learning-Methoden erheblich vereinfachen. Tools wie PyTorch, TensorFlowund Hugging Face Transformers bieten die nötige Flexibilität und vorgefertigte Komponenten, um den Entwicklungsprozess zu beschleunigen.
Für Praktiker, die fortgeschrittene Transfer-Learning-Techniken einsetzen wollen, bieten mehrere Bibliotheken und Frameworks umfangreiche Unterstützung:
Die Umsetzung fortschrittlicher Transfer-Learning-Techniken ist eine Herausforderung, und es gibt einige wichtige Faktoren, die wir beachten müssen.
Die Feinabstimmung bei neuen Aufgaben kann dazu führen, dass die Modelle "vergessen", was sie bei früheren Aufgaben gelernt haben. Techniken wie Elastische Gewichtskonsolidierung (EWC) können dabei helfen, die Gewichte des trainierten Modells zu erhalten, was für das Vorwissen entscheidend ist.
Techniken wie Domänenanpassung und Multi-Task-Lernen können den Rechenaufwand erheblich erhöhen. Das Trainieren von Modellen zur Anpassung an gegnerische Domänen oder Multitasking-Architekturen kann aufgrund der zusätzlichen Komplexität mehr Ressourcen erfordern. Wir müssen unser Modell optimieren und Tools wie das Mixed Precision Training nutzen, um große Modelle effizient zu bearbeiten.
Transfer-Learning-Modelle, die mit verzerrten Daten trainiert wurden, können diese Verzerrungen in neuen Aufgaben weitergeben oder sogar verstärken, was zu verzerrten Vorhersagen führt. Dieses Risiko ist in sensiblen Bereichen wie dem Gesundheits- und Finanzwesen kritisch. Um Fairness zu gewährleisten, sollten wir die Ergebnisse der Modelle regelmäßig auf Verzerrungen überprüfen und Techniken zur Abschwächung der Verzerrungen anwenden, wie z. B. Neugewichtung, De-Biasing oder faires Repräsentationslernen.
Fortgeschrittene Transfer-Learning-Methoden werden in verschiedenen Branchen angewandt und bieten innovative Lösungen für komplexe Herausforderungen der realen Welt. Im Folgenden findest du einige wichtige Anwendungen und Beispiele aus der Industrie, die zeigen, wie diese Techniken den Fortschritt der KI vorantreiben.
OpenAIs GPT-4o Modell, ein führendes Beispiel für das Lernen mit wenigen Beispielen, hat die Fähigkeit bewiesen, sich mit nur wenigen Beispielen an neue Aufgaben anzupassen. GPT-4o, das mit großen Mengen an Textdaten trainiert wurde, kann verschiedene Aufgaben wie Übersetzung, Zusammenfassung und Fragenbeantwortung durchführen, ohne dass eine aufgabenspezifische Feinabstimmung erforderlich ist.
Stattdessen geben die Nutzer ein paar Beispiele für die gewünschte Aufgabe an, und das Modell verallgemeinert von dort aus. Diese Fähigkeit zum Lernen in wenigen Schritten hat das Anwendungsspektrum für große Sprachmodelle erweitert, vom kreativen Schreiben bis hin zu Konversationsagenten.
DeepMind, ein führendes Unternehmen in der KI-Forschung, hat Multitasking-Lernverfahren eingesetzt, um Gesundheitsmodelle zu entwickeln, die bei der Diagnose verschiedener Krankheiten anhand medizinischer Bilder helfen können. Ihr KI-System zur Erkennung von Augenkrankheiten anhand von Netzhautscans ist zum Beispiel in der Lage, eine Reihe von Krankheiten wie diabetische Retinopathie und altersbedingte Makuladegeneration mit einem einzigen Modell zu diagnostizieren.
Dieser MTL-Ansatz reduziert den Bedarf an separaten Modellen für jede Erkrankung und ermöglicht es den Gesundheitsdienstleistern, ihre Diagnoseprozesse zu rationalisieren und eine schnellere und genauere Patientenversorgung zu gewährleisten.
Waymo (Googles Projekt für selbstfahrende Autos) nutzt Techniken der Domänenanpassung, um die Generalisierung seiner autonomen Fahrzeugmodelle in verschiedenen Fahrumgebungen zu verbessern. Das Unternehmen trainiert seine Modelle in simulierten Umgebungen und passt sie dann für den realen Einsatz in verschiedenen Städten und Wetterbedingungen an.
Dieser Prozess stellt sicher, dass selbstfahrende Autos mit den Feinheiten verschiedener Stadtlandschaften umgehen können, von verstopften Straßen in San Francisco bis hin zu weiten Autobahnen in Arizona, ohne dass sie für jeden Ort neu trainiert werden müssen.
Forscherinnen und Forscher arbeiten ständig daran, Modelle anpassungsfähiger und fairer zu machen, damit sie komplexe Aufgaben in der realen Welt bewältigen können und gleichzeitig die Datenmenge und die benötigte Trainingszeit reduzieren.
Kontinuierliches Lernen oder lebenslanges Lernen konzentriert sich auf die Entwicklung von Modellen, die kontinuierlich aus neuen Daten lernen und gleichzeitig das Wissen aus früher gelernten Aufgaben behalten können. Im Gegensatz zum traditionellen Transferlernen, bei dem die Modelle nach der Feinabstimmung statisch sind, ermöglicht das kontinuierliche Lernen eine ständige Anpassung an neue Informationen.
Dies ist besonders wichtig für dynamische Umgebungen wie Robotik und autonome Systeme, in denen regelmäßig neue Szenarien entstehen. In diesem Zusammenhang helfen gedächtnisbasierte Strategien dabei, die Notwendigkeit, vergangenes Wissen zu bewahren und gleichzeitig neue Fähigkeiten einzubauen, auszugleichen. Zukünftige Entwicklungen zielen darauf ab, das kontinuierliche Lernen auf komplexere Bereiche auszuweiten und sicherzustellen, dass die Modelle effizient aktualisiert werden können, ohne die frühere Leistung zu beeinträchtigen.
Da sich Transfer Learning in Branchen wie dem Gesundheitswesen, dem Finanzwesen und der Strafverfolgung immer mehr durchsetzt, ist die Notwendigkeit, sich mit Fairness und Voreingenommenheit auseinanderzusetzen, nicht zu übersehen.
Modelle, die mit großen, unterschiedlichen Datensätzen trainiert wurden, sind oft mit Verzerrungen behaftet, die bei neuen Anwendungen zu verzerrten Ergebnissen führen können. Um dem entgegenzuwirken, erforschen Forscherinnen und Forscher Techniken wie "adversarial de-biasing", "reweighting" und "fair representation learning", um diese Verzerrungen zu erkennen und abzumildern.
Die Gewährleistung von Fairness wird auch in Zukunft ein zentrales Thema in der Transfer-Learning-Forschung sein, vor allem in sensiblen Bereichen, in denen voreingenommene Vorhersagen Auswirkungen auf die reale Welt haben können.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.