
Cursus
Développer des applications d'IA
21 h
Les approches traditionnelles, telles que le pré-entraînement sur un grand ensemble de données, puis le réglage fin sur un ensemble de données spécifique à une tâche, sont fondamentales mais parfois insuffisantes. Des méthodes plus avancées sont apparues pour traiter les nuances des changements de domaine, la rareté des données et l'apprentissage multitâche.
Les méthodes avancées introduisent des niveaux supplémentaires de complexité et de flexibilité. Ces techniques visent à améliorer les performances des modèles dans des scénarios où les approches traditionnelles peuvent ne pas être adéquates.
Les techniques d'adaptation au domaine sont conçues pour gérer les divergences entre le domaine source (pré-entraînement) et le domaine cible (réglage fin). Le réglage fin traditionnel donne souvent des résultats sous-optimaux lorsque les modèles pré-entraînés sont confrontés à des données qui divergent considérablement de leurs données d'entraînement. Les techniques d'adaptation au domaine réduisent cette inadéquation en alignant les distributions de données, ce qui permet au modèle de mieux se généraliser dans de nouveaux contextes.
La MTL permet à un modèle d'apprendre simultanément sur plusieurs tâches connexes. En partageant les connaissances entre les tâches, le modèle peut utiliser les points communs et améliorer les performances dans toutes les tâches. Cette stratégie est particulièrement efficace lorsque les tâches sont complémentaires, comme l'apprentissage conjoint de la classification des textes et de l'analyse des sentiments dans le traitement du langage naturel. MTL améliore la généralisation et réduit le risque de surajustement en guidant le modèle pour qu'il se concentre sur les modèles partagés.
Une autre technique clé est l'apprentissage à quelques coupsconçue pour former des modèles avec un minimum de données étiquetées. Alors que les approches traditionnelles nécessitent de grandes quantités de données étiquetées, les techniques "few-shot" permettent aux modèles de transférer des connaissances en utilisant seulement quelques exemples. Des méthodes telles que le méta-apprentissage et les réseaux prototypiques peuvent conduire à une adaptation rapide à de nouvelles tâches, ce qui les rend inestimables dans des domaines tels que les recommandations personnalisées ou les classifications d'images de niche.
SSL utilise des données non étiquetées pour former des modèles, ce qui en fait un outil puissant lorsque les données étiquetées sont rares ou indisponibles. Cette technique permet de construire des signaux de supervision à partir des données elles-mêmes, ce qui permet de résoudre des tâches préalables telles que la prédiction des parties manquantes d'une image ou la reconstruction d'un texte brouillé. Les modèles pré-entraînés à l'aide de SSL ont fait preuve d'une grande transférabilité dans toute une série d'applications.
L'apprentissage à partir de zéro va encore plus loin en permettant aux modèles de traiter des tâches totalement nouvelles sans aucune donnée étiquetée. Pour ce faire, des informations auxiliaires telles que des relations sémantiques ou des descriptions de tâches permettent au modèle de se généraliser, même lorsqu'il est confronté à de nouvelles catégories. Cette capacité est très utile dans les domaines dynamiques où de nouvelles catégories apparaissent fréquemment, comme dans les applications NLP qui traitent des termes nouvellement inventés ou de l'argot.
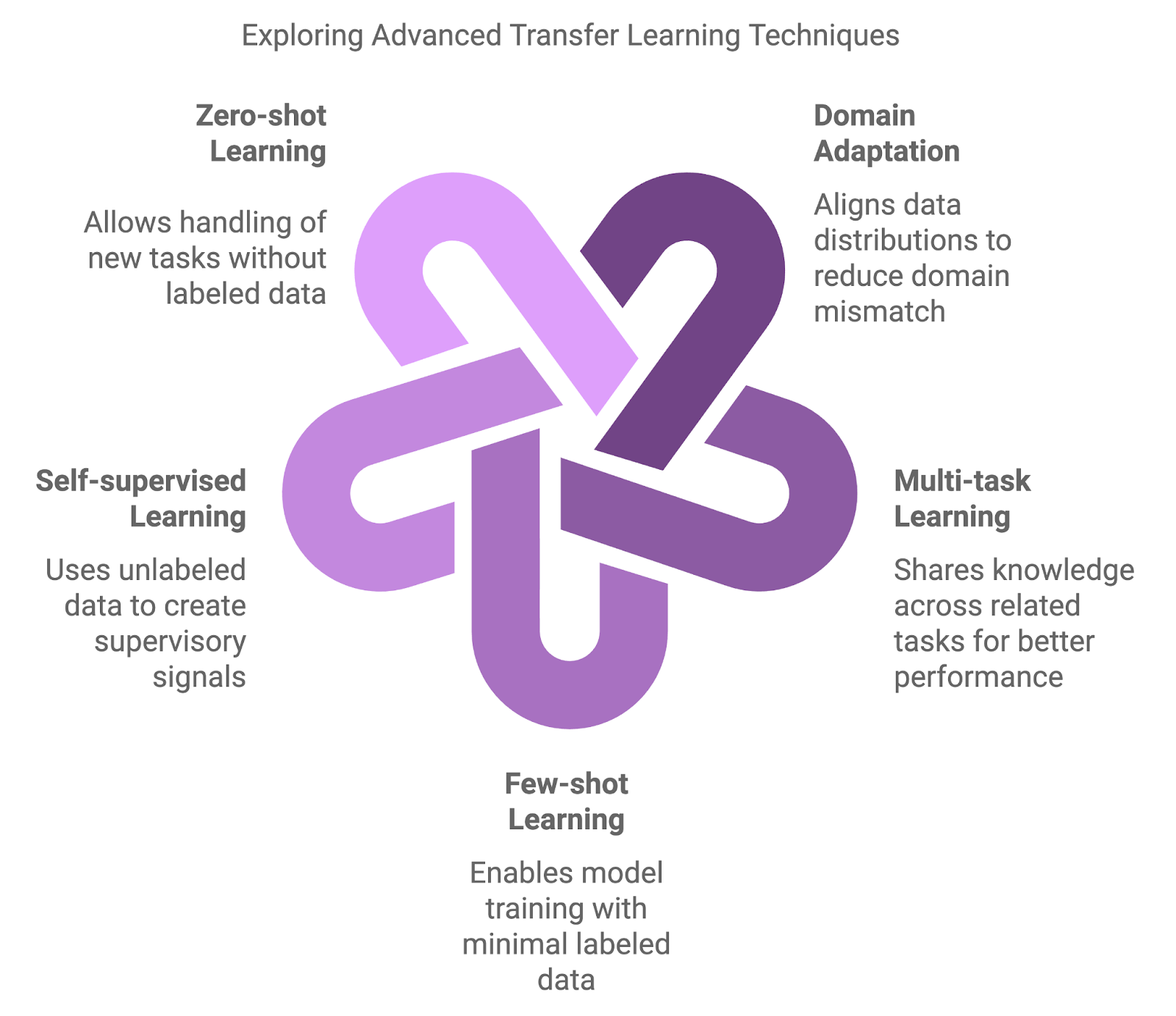
Diagramme généré avec napkin.ai
Comme nous l'avons brièvement évoqué précédemment, l'adaptation au domaine est un sous-domaine de l'apprentissage par transfert axé sur la gestion des situations dans lesquelles il existe une différence significative, ou "changement de domaine", entre les données utilisées pour former un modèle et les données dans lesquelles le modèle est déployé.
Dans l'apprentissage par transfert classique, on suppose que les domaines source et cible présentent des caractéristiques similaires, mais dans de nombreux scénarios réels, ces domaines diffèrent considérablement. En fin de compte, cela peut nuire aux performances, car les modèles formés sur un ensemble de données ont du mal à s'adapter à de nouvelles conditions.
Les techniques d'adaptation au domaine sont conçues pour combler ce fossé, permettant à un modèle formé dans un domaine de fonctionner efficacement dans un autre en minimisant l'écart entre les distributions de données source et cible. Par conséquent, l'adaptation au domaine est encore plus précieuse dans les situations où les données étiquetées sont abondantes dans un domaine, mais rares ou indisponibles dans un autre.
Plusieurs techniques ont été développées pour relever le défi de l'adaptation au domaine - deux des approches les plus courantes sont les méthodes antagonistes et l'apprentissage de caractéristiques invariantes par rapport au domaine.
Une technique largement utilisée pour l'adaptation au domaine implique l'apprentissage contradictoire. Dans ce contexte, un modèle est formé pour apprendre les caractéristiques utiles à la tâche cible tout en veillant à ce que ces caractéristiques ne puissent pas être distinguées entre les domaines source et cible.
Pour ce faire, nous pouvons utiliser un discriminateur, c'est-à-dire un réseau neuronal chargé de faire la distinction entre les données du domaine source et celles du domaine cible. Le modèle est entraîné de manière contradictoire afin d'apprendre à "tromper" le discriminateur, ce qui rend les représentations des caractéristiques invariantes par rapport au domaine. Si cela vous semble familier, c'est parce que cette technique s'inspire des réseaux adverbiaux génératifs (GAN). réseaux adversoriels génératifs (GAN)qui utilisent une configuration similaire pour générer des données synthétiques réalistes.
Une autre approche se concentre sur l'apprentissage de représentations qui ne sont pas affectées par les variations spécifiques au domaine. Les données d'entrée des deux domaines sont ainsi transformées en un espace de caractéristiques partagé où les domaines source et cible s'alignent plus étroitement. Des techniques telles que Maximum Mean Discrepancy (MMD) et CORAL (Correlation Alignment) permettent de minimiser les différences statistiques dans cet espace, ce qui garantit que le modèle peut être généralisé plus efficacement lorsqu'il est appliqué au domaine cible.
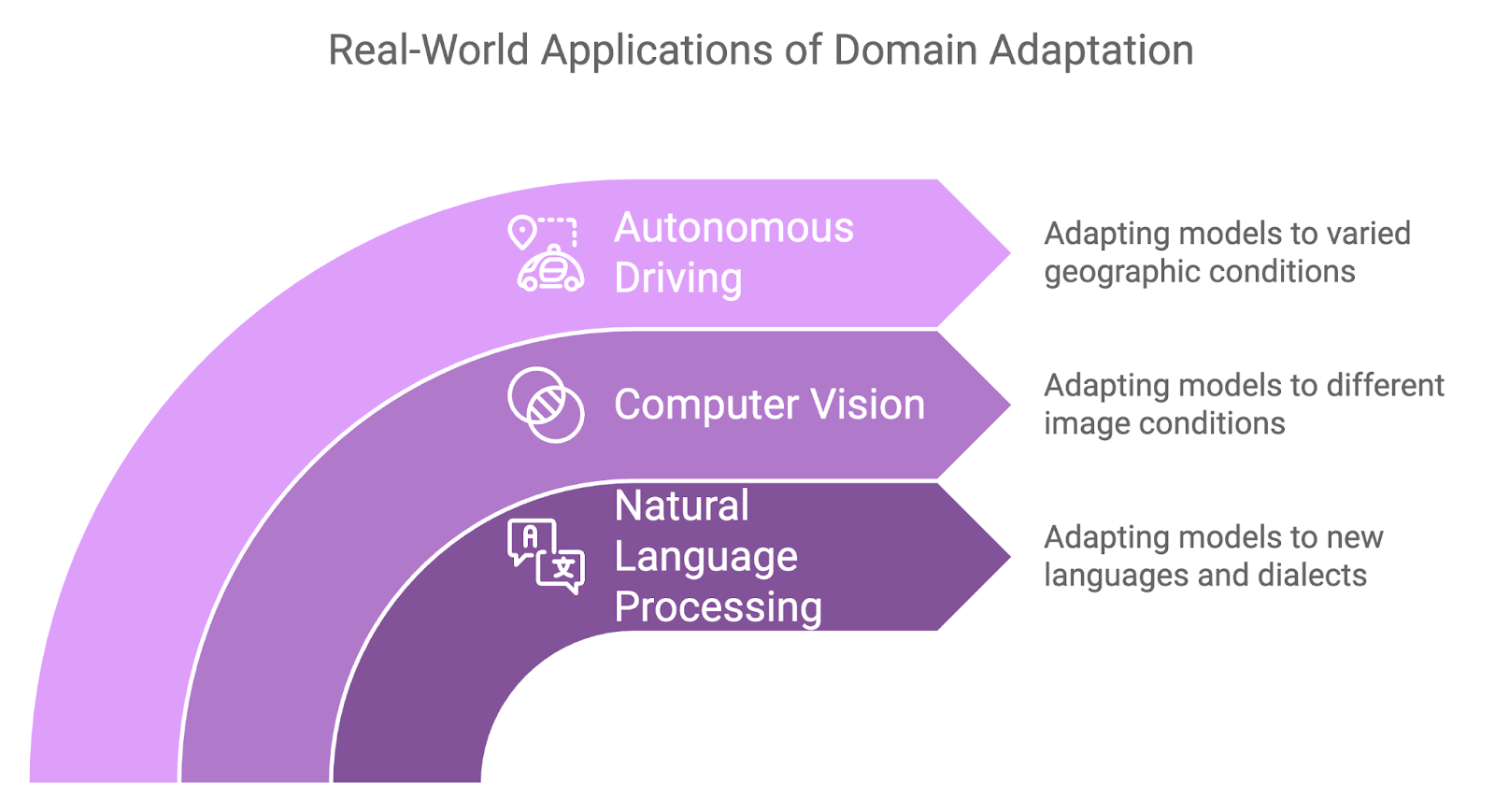
L'adaptation au domaine s'est avérée utile dans une variété d'applications du monde réel où les changements de domaine sont inévitables :
Les tâches d'apprentissage automatique devenant de plus en plus complexes, la possibilité de s'attaquer simultanément à plusieurs problèmes connexes peut améliorer considérablement les performances et l'efficacité d'un modèle. La MTL s'attaque à ce problème en formant les modèles à effectuer plusieurs tâches à la fois, plutôt que de se concentrer sur une seule tâche isolée.
La force de la MTL réside dans sa capacité à exploiter les relations et les structures partagées entre les tâches, ce qui permet aux modèles d'apprendre des représentations de caractéristiques plus riches. Les enseignements tirés d'une tâche améliorent les performances du modèle dans une autre tâche, ce qui permet d'améliorer l'efficacité globale de l'apprentissage.
En matière de MTL, deux stratégies principales sont couramment utilisées :
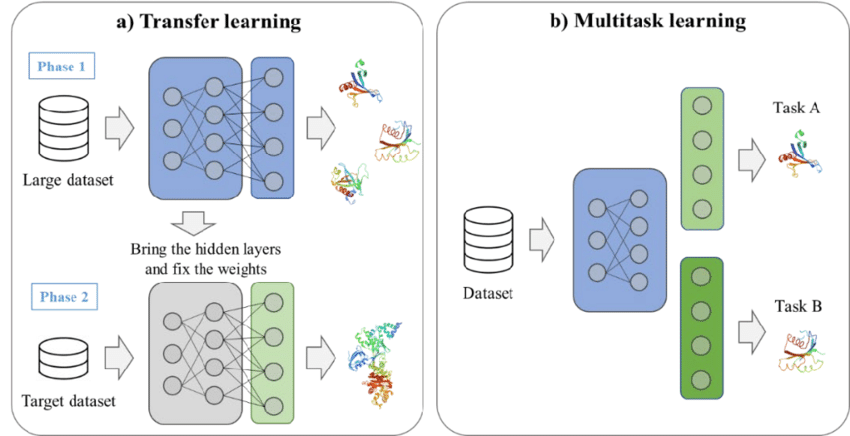
Un exemple d'apprentissage par transfert et d'apprentissage multitâche. Source : Kim et al, 2021
La MTL offre plusieurs avantages qui en font une approche précieuse pour les scénarios complexes d'apprentissage automatique.
En apprenant à travers plusieurs tâches, le modèle est exposé à un plus large éventail de données et apprend des représentations plus générales. Cela permet souvent d'améliorer les performances pour chaque tâche, en particulier lorsque ces tâches sont liées.
Avec la MTL, les modèles utilisent mieux les données disponibles, en particulier dans les situations où les données étiquetées sont rares. Étant donné que le modèle apprend à partir de plusieurs tâches, il peut utiliser les connaissances acquises lors de tâches connexes pour améliorer ses performances. Cet apprentissage inter-tâches accélère le processus d'apprentissage et réduit la dépendance à l'égard de grands ensembles de données pour chaque tâche.
Au lieu de former des modèles distincts pour chaque tâche, MTL consolide l'apprentissage dans un modèle unique. Le coût de calcul et l'empreinte mémoire sont ainsi réduits, ce qui permet un déploiement plus efficace dans des environnements aux ressources limitées.
La MTL a été appliquée avec succès dans divers domaines, avec des cas d'utilisation notables en NLP et en vision par ordinateur.
Dans le domaine du traitement du langage naturel, la MTL est couramment utilisée pour former des modèles sur plusieurs tâches connexes. Par exemple, un modèle linguistique peut être formé pour effectuer simultanément la traduction automatique et la classification des textes. En partageant les représentations apprises entre ces tâches, le modèle peut améliorer sa compréhension de la structure et du contexte de la langue, ce qui profite aux deux tâches.
Dans le domaine de la vision artificielle, la MTL peut être appliquée à des tâches telles que la détection d'objets et la segmentation d'images. Nous pouvons entraîner un modèle à identifier des objets dans une image tout en apprenant simultanément à classer ces objets. Ce processus d'apprentissage partagé permet au modèle de reconnaître à la fois l'emplacement et la catégorie des objets, ce qui le rend plus polyvalent et plus efficace.
Dans les scénarios où les données étiquetées sont rares ou indisponibles, l'apprentissage à quelques coups et le SSL se sont imposés comme des techniques puissantes pour remédier aux limites des méthodes supervisées traditionnelles.
Ces approches offrent des moyens innovants d'adapter les modèles à de nouvelles tâches avec un minimum de données étiquetées ou en utilisant de grandes quantités de données non étiquetées, ce qui en fait des outils essentiels dans le domaine de l'apprentissage par transfert avancé.
Comme nous le savons maintenant, l'apprentissage à court terme est conçu pour permettre aux modèles de s'adapter rapidement à de nouvelles tâches avec seulement quelques exemples étiquetés.
Toutefois, la collecte de vastes ensembles de données n'est pas pratique dans de nombreuses applications, telles que le diagnostic de maladies rares ou l'identification de produits de niche. L'apprentissage en quelques étapes résout ce problème en transférant les connaissances acquises lors de tâches connexes et en affinant les modèles pour qu'ils fonctionnent bien avec un minimum de nouvelles données.
Nous examinons ci-dessous deux stratégies clés de l'apprentissage à court terme.
Également appelé "apprendre à apprendre", le méta-apprentissage consiste à former un modèle pour qu'il s'adapte rapidement à de nouvelles tâches avec un minimum de données. L'idée est d'entraîner le modèle à travers une variété de tâches afin qu'il puisse généraliser son apprentissage et s'adapter rapidement à des tâches inédites.
Les cadres de méta-apprentissage tels que le méta-apprentissage agnostique de modèle (MAML) permettent au modèle d'apprendre un ensemble optimal de paramètres qui peuvent être affinés pour de nouvelles tâches avec seulement quelques exemples.
Une autre approche courante est celle des réseaux prototypiques, qui sont conçus pour classer les points de données en calculant les distances entre eux dans un espace de caractéristiques appris. Dans cette configuration, chaque classe est représentée par un prototype (la moyenne des exemples de cette classe dans l'espace des caractéristiques).
Les nouveaux points de données sont ensuite classés en fonction de leur proximité avec ces prototypes. Les réseaux prototypiques peuvent être efficaces dans le cadre de l'apprentissage en quelques étapes, car ils ne nécessitent qu'un nombre minimal d'exemples par classe pour générer des prototypes significatifs en vue de la classification.
SSL permet aux modèles d'extraire des représentations significatives à partir de grandes quantités de données non étiquetées en générant des signaux de supervision, sans qu'il soit nécessaire de procéder à des étiquetages manuels. Une fois que le modèle a appris à partir des données non étiquetées, il peut être affiné sur un plus petit ensemble de données étiquetées, ce qui permet d'obtenir de bonnes performances sur les tâches en aval.
L'une des techniques SSL les plus efficaces est l'apprentissage contrastif, qui permet de former des modèles en comparant des paires de données positives et négatives. L'objectif est de rapprocher les points de données similaires (paires positives) dans l'espace des caractéristiques et d'éloigner les points dissemblables (paires négatives).
Dans le traitement du langage naturel, une méthode SSL populaire est la modélisation du langage masqué, utilisée dans des modèles tels que BERT. Dans ce cas, certaines parties de l'entrée sont masquées et le modèle est entraîné à prédire les éléments manquants à l'aide du contexte environnant. Cette stratégie de pré-entraînement permet au modèle d'apprendre des représentations robustes et polyvalentes qui peuvent être affinées pour diverses tâches de NLP.
L'apprentissage à petite échelle et l'apprentissage auto-supervisé sont largement utilisés dans les domaines où les limites des données constituent un obstacle important. Voici quelques applications clés de chacune d'entre elles.
L'apprentissage à partir de quelques exemples s'avère précieux dans la détection d'objets personnalisés, où l'identification d'objets rares ou spécialisés peut nécessiter que les modèles apprennent à partir d'une poignée d'exemples étiquetés.
Dans l'industrie, la détection des défauts dans un processus de fabrication peut impliquer très peu de cas de défauts. En tirant parti de l'apprentissage en quelques étapes, un modèle pré-entraîné pour des tâches générales de détection d'objets peut être rapidement adapté pour détecter ces objets spécifiques avec un minimum de données d'entraînement supplémentaires.
L'apprentissage auto-supervisé a révolutionné le traitement du langage naturel grâce à des modèles tels que GPT et BERT. Ces modèles apprennent des représentations linguistiques générales qui peuvent être affinées pour des tâches spécifiques à l'aide d'ensembles de données étiquetées relativement restreints. Par exemple, un modèle de langage pré-entraîné à l'aide de SSL peut être affiné pour effectuer des tâches telles que l'analyse de sentiments, la classification de textes ou le résumé, ce qui permet souvent d'obtenir des résultats à la pointe de la technologie.
Les bibliothèques et les cadres d'apprentissage automatique peuvent simplifier considérablement la mise en œuvre de méthodes avancées d'apprentissage par transfert. Des outils comme PyTorch, TensorFlowet Hugging Face Transformers offrent la flexibilité nécessaire et des composants pré-construits pour accélérer le processus de développement.
Pour les praticiens qui cherchent à mettre en œuvre des techniques avancées d'apprentissage par transfert, plusieurs bibliothèques et frameworks offrent un soutien important :
La mise en œuvre de techniques avancées d'apprentissage par transfert est un défi, et nous devons garder à l'esprit certains facteurs critiques.
La mise au point de nouvelles tâches peut amener les modèles à "oublier" ce qu'ils ont appris lors des tâches précédentes. Des techniques telles que Consolidation élastique des poids (EWC) peuvent aider à préserver les poids du modèle pré-entraîné, ce qui est crucial pour la connaissance préalable.
Des techniques telles que l'adaptation au domaine et l'apprentissage multi-tâches peuvent augmenter de manière significative les besoins de calcul. La formation de modèles d'adaptation à des domaines antagonistes ou d'architectures multitâches peut nécessiter davantage de ressources en raison de la complexité supplémentaire. Nous devons optimiser notre modèle et utiliser des outils tels que l'apprentissage à précision mixte pour traiter efficacement les modèles de grande taille.
Les modèles d'apprentissage par transfert pré-entraînés sur des données biaisées peuvent propager ou même amplifier ces biais dans de nouvelles tâches, ce qui conduit à des prédictions biaisées. Ce risque est critique dans des domaines sensibles comme les soins de santé et la finance. Pour garantir l'équité, nous devrions évaluer régulièrement les résultats des modèles pour détecter les biais et appliquer des techniques d'atténuation telles que la repondération, le dé-biaisage contradictoire ou l'apprentissage d'une représentation équitable.
Les méthodes avancées d'apprentissage par transfert sont appliquées dans divers secteurs, apportant des solutions innovantes à des défis complexes du monde réel. Vous trouverez ci-dessous quelques applications clés et des exemples industriels qui illustrent la manière dont ces techniques font progresser l'IA.
Le modèle modèle GPT-4oun exemple phare de l'apprentissage en quelques secondes, a démontré sa capacité à s'adapter à de nouvelles tâches avec seulement quelques exemples. GPT-4o, pré-entraîné sur des quantités massives de données textuelles, peut effectuer diverses tâches telles que la traduction, le résumé et la réponse à des questions sans qu'il soit nécessaire de procéder à un réglage fin spécifique à la tâche.
Au lieu de cela, les utilisateurs fournissent quelques exemples de la tâche souhaitée et le modèle se généralise à partir de là. Cette capacité d'apprentissage en quelques coups a élargi l'éventail des applications des grands modèles linguistiques, de l'écriture créative aux agents conversationnels.
DeepMind, leader de la recherche en IA, a utilisé l'apprentissage multitâche pour développer des modèles de soins de santé qui peuvent aider à diagnostiquer de multiples conditions à partir de l'imagerie médicale. Par exemple, leur système d'IA pour la détection des maladies oculaires à partir de scanners rétiniens est capable de diagnostiquer une série d'affections, dont la rétinopathie diabétique et la dégénérescence maculaire liée à l'âge, à l'aide d'un seul modèle.
Cette approche MTL réduit la nécessité d'utiliser des modèles distincts pour chaque pathologie, ce qui permet aux prestataires de soins de santé de rationaliser leurs processus de diagnostic et de fournir des soins plus rapides et plus précis aux patients.
Waymo (le projet de voiture autonome de Google) utilise des techniques d'adaptation au domaine pour améliorer la généralisation de ses modèles de véhicules autonomes dans divers environnements de conduite. L'entreprise forme ses modèles dans des environnements simulés et les adapte ensuite à un déploiement réel dans différentes villes et conditions météorologiques.
Ce processus garantit que les voitures autonomes peuvent gérer les nuances des différents paysages urbains, des rues encombrées de San Francisco aux autoroutes dégagées de l'Arizona, sans nécessiter un recyclage approfondi pour chaque lieu.
Les chercheurs repoussent constamment les limites, s'efforçant de rendre les modèles plus adaptables, plus justes et capables de traiter des tâches complexes dans le monde réel tout en réduisant la quantité de données et le temps de formation nécessaires.
L'apprentissage continu ou l'apprentissage tout au long de la vie se concentre sur le développement de modèles capables d'apprendre en permanence à partir de nouvelles données tout en conservant les connaissances acquises lors des tâches précédentes. Contrairement à l'apprentissage par transfert traditionnel, où les modèles sont statiques une fois affinés, l'apprentissage continu permet une adaptation permanente aux nouvelles informations.
C'est essentiel pour les environnements dynamiques, tels que la robotique et les systèmes autonomes, où de nouveaux scénarios émergent régulièrement. Dans ce contexte, les stratégies basées sur la mémoire permettent de trouver un équilibre entre la nécessité de préserver les connaissances antérieures et celle d'intégrer de nouvelles compétences. Les développements futurs visent à étendre l'apprentissage continu à des domaines plus complexes, en veillant à ce que les modèles puissent être mis à jour efficacement sans compromettre les performances antérieures.
L'apprentissage par transfert devenant de plus en plus répandu dans des secteurs tels que les soins de santé, la finance et l'application de la loi, il est impossible d'ignorer la nécessité d'aborder la question de l'équité et des préjugés.
Les modèles pré-entraînés sur des ensembles de données vastes et diversifiés comportent souvent des biais inhérents, qui peuvent conduire à des résultats faussés dans les nouvelles applications. Pour y remédier, les chercheurs explorent des techniques telles que le débiaisage, la repondération et l'apprentissage de la représentation équitable, afin de détecter et d'atténuer ces biais.
La garantie de l'équité restera au cœur de la recherche sur l'apprentissage par transfert, en particulier dans les domaines sensibles où les prédictions biaisées peuvent avoir des implications dans le monde réel.
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours