Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
100.8K
A medida que el procesamiento del lenguaje natural (PLN) sigue creciendo rápidamente, los grandes modelos lingüísticos (LLM) se han convertido en herramientas muy potentes, capaces de manejar un número cada vez mayor de tareas. Sin embargo, un reto constante ha sido adaptar estos modelos generales a ámbitos muy especializados, como la literatura médica o la documentación de software.
Aquí es donde entra en juego el Retrieval-Augmented Fine-Tuning (RAFT), una nueva técnica que podría transformar la PNL de dominio específico. RAFT combina los puntos fuertes de la Generación Mejorada por Recuperación (RAG), un método que combina los LLM con fuentes de datos externas, y el ajuste fino, que permite a los modelos no sólo aprender conocimientos específicos del dominio, sino también aprender a recuperar y comprender con precisión el contexto externo para realizar las tareas.
En este artículo, exploraremos el funcionamiento interno de RAFT, analizaremos sus ventajas y veremos cómo esta técnica de vanguardia podría revolucionar la forma en que abordamos las tareas de PNL en dominios específicos. Para empezar, consulta algunos recursos sobre el GAR, como nuestra introducción al GAR y las aplicaciones prácticas del GAR.
El Ajuste Fino Aumentado por Recuperación (RAFT) es un enfoque innovador de los modelos lingüísticos que combina las ventajas de la RAG y el ajuste fino. Esta técnica adapta los modelos lingüísticos a dominios específicos mejorando la capacidad de los modelos para comprender y utilizar el conocimiento específico del dominio, al tiempo que garantiza la solidez frente a recuperaciones inexactas.
RAFT está diseñado específicamente para abordar los retos de adaptar los LLM a dominios especializados. En estos contextos, el razonamiento de conocimiento general se vuelve menos crítico, y el enfoque principal se desplaza hacia la maximización de la precisión con respecto a un conjunto predefinido de documentos específicos del dominio.
La Generación Mejorada por Recuperación (RAG) es una técnica que mejora los modelos lingüísticos integrando un módulo de recuperación que obtiene información relevante de bases de conocimiento externas.
Este módulo de recuperación obtiene los documentos relevantes basándose en la consulta introducida. A continuación, el modelo lingüístico utiliza este contexto adicional para generar el resultado final.
La RAG, que funciona según el paradigma de "recuperar y leer", ha demostrado ser muy eficaz en varias tareas de PNL, como el modelado del lenguaje y la respuesta a preguntas de dominio abierto.
Sin embargo, estos modelos lingüísticos no se han entrenado para recuperar documentos precisos específicos del dominio, sino que sólo tienen conocimientos generales del dominio a partir del preentrenamiento.
Como se señala en el artículo original, los métodos existentes de recuperación en contexto equivalen a hacer un examen a libro abierto sin saber qué documentos son los más relevantes para responder a la pregunta.
Para saber más sobre RAG, consulta cómo se puede utilizar RAG con GPT y Milvus para realizar Respuestas a Preguntas.
El ajuste fino es un enfoque ampliamente adoptado para adaptar los LLM preentrenados a las tareas posteriores. Este proceso implica un entrenamiento adicional del modelo con datos específicos de la tarea, lo que le permite aprender patrones y alinearse con el formato de salida deseado.
El ajuste fino ha demostrado su eficacia en diversas aplicaciones de la PNL, como la síntesis, la respuesta a preguntas y la generación de diálogos. Sin embargo, los métodos tradicionales de ajuste fino pueden tener dificultades para aprovechar el conocimiento externo específico del dominio o manejar las recuperaciones imperfectas durante la inferencia.
Utilizando una analogía similar a la anterior, afinar es como memorizar documentos y responder a las preguntas sin hacer referencia a ellos durante el examen. El problema de este enfoque es que el ajuste fino puede ser costoso, y los conocimientos ajustados pueden quedar obsoletos. Además, estos métodos de ajuste fino no son tan sensibles como los métodos basados en la GAR.
Para saber más sobre el ajuste fino, aquí tienes una guía introductoria a los LLM de ajuste fino.
La RAFT reconoce las limitaciones de los enfoques existentes y pretende combinar los puntos fuertes de la GAR y el ajuste fino. Al incorporar documentos específicos del dominio durante el proceso de ajuste, RAFT permite que el modelo aprenda patrones específicos del dominio objetivo, al tiempo que mejora su capacidad para comprender y utilizar el contexto externo de forma eficaz.
A un alto nivel, en RAFT, los datos de entrenamiento consisten en preguntas, documentos (tanto relevantes como irrelevantes) y las correspondientes respuestas tipo cadena de pensamiento generadas a partir de los documentos relevantes. El modelo se entrena para responder a las preguntas basándose en estos documentos proporcionados, incluidos los documentos distractores que no contienen información relevante. Este enfoque enseña al modelo a identificar y priorizar la información relevante mientras descarta el contenido irrelevante.
Profundicemos en la mecánica del funcionamiento del Ajuste fino mejorado por recuperación. RAFT propone un método novedoso para preparar datos de ajuste fino para entrenar modelos de respuesta RAG en el dominio. En RAFT, cada punto de datos del conjunto de datos de entrenamiento consta de:
En el conjunto de datos de entrenamiento de perfeccionamiento RAFT, cada pregunta se empareja con un conjunto de documentos, algunos de los cuales contienen las respuestas y otros no, junto con una respuesta de estilo cadena de pensamiento. Esta estructura es especialmente útil para entrenar al modelo a distinguir entre información útil e irrelevante a la hora de obtener respuestas.
Para mejorar aún más el aprendizaje del modelo, el conjunto de datos de entrenamiento RAFT incluye una mezcla de tipos de preguntas:
Por último, las respuestas de estilo cadena de pensamiento incorporan segmentos de los documentos del oráculo y un proceso de razonamiento detallado. Este enfoque mejora la precisión del modelo a la hora de responder preguntas, enseñándole a formar una cadena de razonamiento utilizando segmentos relevantes del contexto original.

Fuente de la imagen: RAFT: Adaptar el modelo lingüístico al GAR específico del dominio
Una vez preparados los datos de entrenamiento, el proceso de ajuste consiste en
Durante la fase de inferencia, a nuestro modelo afinado se le presentarán una pregunta y los documentos top-K recuperados por la canalización RAG. Ten en cuenta que el módulo recuperador funciona independientemente de RAFT.
Para demostrar que RAFT destaca en la extracción de información relevante de documentos del dominio y en la respuesta a preguntas, el artículo original comparaba el enfoque RAFT con un modelo de propósito general con RAG y con modelos afinados específicos del dominio. Concretamente, afinaron Llama-2 utilizando el método RAFT para crear el modelo RAFT 7B, y lo compararon con los siguientes:
Estos modelos se evaluaron en tres tipos de conjuntos de datos para valorar el rendimiento de RAFT en una serie de dominios:
En general, los resultados muestran que RAFT superó sistemáticamente al método de ajuste fino supervisado, tanto con RAG como sin ella, en PubMed, HotpotQA y los demás conjuntos de datos API.
En comparación con el ajuste fino específico de dominio (DSF), RAFT superó significativamente al DSF. Curiosamente, la DSF con RAG no condujo a un mejor rendimiento y, de hecho, obtuvo peores resultados.
Esto indica que DSF carece de capacidad para extraer eficazmente la información relevante de los documentos proporcionados. Utilizando RAFT, entrenamos el modelo tanto para procesar los documentos con precisión como para proporcionar un estilo de respuesta adecuado.
El enfoque RAFT superó incluso a GPT-3.5 con RAG, que es un modelo lingüístico mucho mayor, lo que demuestra la eficacia de RAFT.
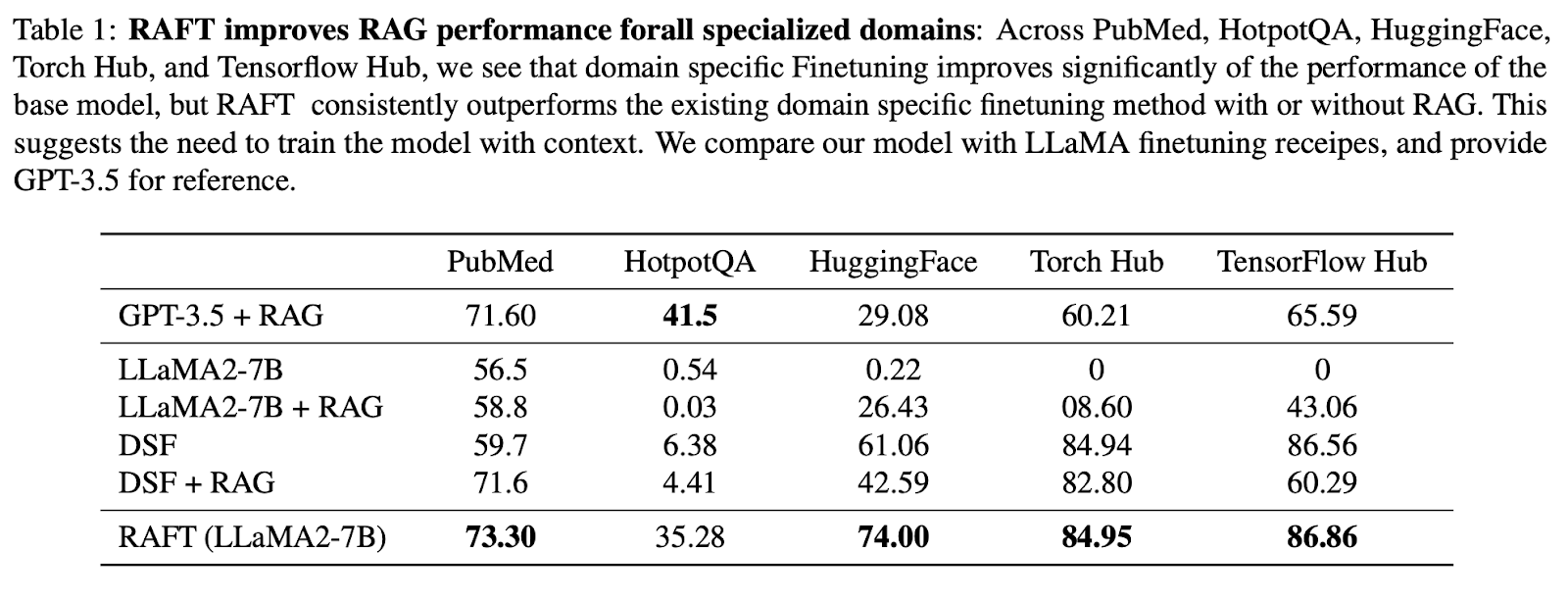
Fuente de la imagen: RAFT: Adaptar el modelo lingüístico al GAR específico del dominio
Estudios de ablación
Además de los experimentos principales, en el artículo original también se realizaron varios estudios de ablación para comprender el impacto de diversos componentes en el rendimiento del RAFT:
Para poner en práctica el RAFT, los investigadores y los profesionales pueden seguir los pasos descritos en el documento. Esto incluye generar respuestas tipo cadena de pensamiento a partir de documentos relevantes, incorporar documentos distractores durante el entrenamiento y afinar el modelo mediante técnicas de aprendizaje supervisado. Los autores también han abierto el código y han proporcionado una demostración para facilitar una mayor experimentación y adopción de RAFT.
RAFT representa un avance significativo en el campo del modelado lingüístico de dominios específicos, ya que ofrece una potente solución para adaptar los LLM a dominios especializados. Al combinar los puntos fuertes de la RAG y el ajuste fino, la RAFT dota a los modelos lingüísticos de la capacidad de aprovechar eficazmente el conocimiento específico del dominio, manteniendo al mismo tiempo la solidez frente a las imprecisiones de la recuperación.
A quienes estén interesados en profundizar en el mundo de la GAR y el ajuste fino, les recomendamos que exploren los siguientes recursos:
A medida que siga creciendo la demanda de modelos lingüísticos específicos para cada dominio, técnicas como RAFT desempeñarán un papel crucial a la hora de permitir aplicaciones de PLN más precisas y fiables en diversos sectores y dominios.
¡Continúa hoy tu viaje de aprendizaje de la IA!
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Josep Ferrer
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita

