
Cours
Concepts des grands modèles de langage (LLM)
2 h
100.8K
Le traitement du langage naturel (NLP) continuant à se développer rapidement, les grands modèles de langage (LLM) sont devenus des outils très puissants, capables de traiter un nombre croissant de tâches. Cependant, l'adaptation de ces modèles généraux à des domaines hautement spécialisés, tels que la littérature médicale ou la documentation des logiciels, constitue un défi permanent.
C'est là qu'intervient le Retrieval-Augmented Fine-Tuning (RAFT), une nouvelle technique qui pourrait transformer le NLP spécifique à un domaine. RAFT combine les forces de la génération améliorée par la recherche (RAG), une méthode qui associe les LLM à des sources de données externes, et le réglage fin, ce qui permet aux modèles d'apprendre non seulement des connaissances spécifiques au domaine, mais aussi d'apprendre à récupérer et à comprendre avec précision le contexte externe pour effectuer des tâches.
Dans cet article, nous allons explorer les rouages de la RAFT, examiner ses avantages et voir comment cette technique de pointe pourrait révolutionner la façon dont nous abordons les tâches de TAL spécifiques à un domaine. Pour commencer, consultez quelques ressources sur les GCR, telles que notre introduction aux GCR et les applications pratiques des GCR.
Retrieval Augmented Fine-Tuning (RAFT) est une approche révolutionnaire des modèles de langage qui combine les avantages de RAG et du réglage fin. Cette technique permet d'adapter les modèles de langage à des domaines spécifiques en améliorant la capacité des modèles à comprendre et à utiliser des connaissances spécifiques à un domaine tout en garantissant la robustesse contre les recherches inexactes.
RAFT est spécialement conçu pour relever les défis que pose l'adaptation des LLM à des domaines spécialisés. Dans ces contextes, le raisonnement sur les connaissances générales devient moins critique et l'objectif principal est de maximiser la précision par rapport à un ensemble prédéfini de documents spécifiques à un domaine.
La génération améliorée par récupération (RAG) est une technique qui améliore les modèles de langage en intégrant un module de récupération qui trouve des informations pertinentes dans des bases de connaissances externes.
Ce module de recherche permet d'extraire les documents pertinents en fonction de la requête d'entrée. Le modèle linguistique utilise ensuite ce contexte supplémentaire pour générer le résultat final.
Fonctionnant selon le paradigme "récupérer et lire", RAG s'est avéré très efficace dans diverses tâches NLP, y compris la modélisation du langage et la réponse à des questions dans un domaine ouvert.
Toutefois, ces modèles linguistiques n'ont pas été entraînés à extraire des documents spécifiques à un domaine précis et ne disposent au contraire que de connaissances générales sur le domaine, acquises lors d'un entraînement préalable.
Comme indiqué dans l'article original, les méthodes de recherche en contexte existantes reviennent à passer un examen à livre ouvert sans savoir quels sont les documents les plus pertinents pour répondre à la question.
Pour en savoir plus sur RAG, voyez comment RAG peut être utilisé avec GPT et Milvus pour répondre à des questions.
Le réglage fin est une approche largement adoptée pour adapter les LLM pré-entraînés aux tâches en aval. Ce processus implique un entraînement supplémentaire du modèle sur des données spécifiques à la tâche, ce qui lui permet d'apprendre des modèles et de s'aligner sur le format de sortie souhaité.
Le réglage fin a fait ses preuves dans diverses applications NLP, telles que le résumé, la réponse aux questions et la génération de dialogues. Cependant, les méthodes traditionnelles de réglage fin peuvent avoir du mal à exploiter les connaissances externes spécifiques au domaine ou à gérer les récupérations imparfaites au cours de l'inférence.
En utilisant une analogie similaire à la précédente, la mise au point revient à mémoriser des documents et à répondre à des questions sans s'y référer pendant l'examen. Le problème de cette approche est que la mise au point peut être coûteuse et que les connaissances mises au point peuvent devenir obsolètes. En outre, ces méthodes de réglage fin ne sont pas aussi réactives que les méthodes basées sur le RAG.
Pour en savoir plus sur le réglage fin, voici un guide d'introduction aux LLM de réglage fin.
RAFT reconnaît les limites des approches existantes et vise à combiner les points forts de RAG et du réglage fin. En incorporant des documents spécifiques au domaine pendant le processus d'ajustement, RAFT permet au modèle d'apprendre des modèles spécifiques au domaine cible tout en améliorant sa capacité à comprendre et à utiliser efficacement le contexte externe.
À un niveau élevé, dans RAFT, les données de formation sont constituées de questions, de documents (pertinents et non pertinents) et de réponses correspondantes de type chaîne de pensée générées à partir des documents pertinents. Le modèle est entraîné à répondre aux questions sur la base des documents fournis, y compris les documents distracteurs qui ne contiennent pas d'informations pertinentes. Cette approche apprend au modèle à identifier et à hiérarchiser les informations pertinentes tout en ignorant le contenu non pertinent.
Voyons plus en détail comment fonctionne le "Retrieval-Augmented Fine-Tuning". RAFT propose une nouvelle méthode pour préparer des données de réglage fin afin de former des modèles de réponse RAG dans le domaine. Dans RAFT, chaque point de données dans l'ensemble de données d'apprentissage se compose de
Dans l'ensemble de données de formation RAFT, chaque question est associée à un ensemble de documents, dont certains contiennent les réponses et d'autres non, ainsi qu'à une réponse de type chaîne de pensée. Cette structure est particulièrement utile pour apprendre au modèle à distinguer les informations utiles de celles qui ne le sont pas lorsqu'il s'agit de trouver des réponses.
Pour améliorer encore l'apprentissage du modèle, l'ensemble de données de formation RAFT comprend un mélange de types de questions :
Enfin, les réponses de type "chaîne de pensée" intègrent des segments des documents de l'oracle et un processus de raisonnement détaillé. Cette approche améliore la précision des réponses du modèle en lui apprenant à former une chaîne de raisonnement à l'aide de segments pertinents du contexte d'origine.

Source de l'image : RAFT : Adaptation du modèle linguistique à un domaine spécifique
Une fois les données d'apprentissage préparées, le processus de réglage fin implique :
Au cours de la phase d'inférence, notre modèle affiné sera présenté avec une question et les K premiers documents récupérés par le pipeline RAG. Notez que le module de récupération fonctionne indépendamment de RAFT.
Pour démontrer que RAFT excelle dans l'extraction d'informations pertinentes à partir de documents du domaine et dans la réponse aux questions, l'article original a comparé l'approche RAFT à un modèle général avec RAG et à des modèles affinés spécifiques à un domaine. Plus précisément, ils ont affiné Llama-2 en utilisant la méthode RAFT pour créer le modèle RAFT 7B, et l'ont comparé aux modèles suivants :
Ces modèles ont été évalués sur trois types d'ensembles de données afin d'évaluer les performances de RAFT dans une série de domaines :
Dans l'ensemble, les résultats montrent que RAFT est toujours plus performant que la méthode de réglage fin supervisée, avec et sans RAG, dans PubMed, HotpotQA et les autres ensembles de données API.
Comparé au réglage fin spécifique à un domaine (DSF), RAFT est nettement plus performant que le DSF. Il est intéressant de noter que le CVD avec RAG n'a pas permis d'améliorer les performances et qu'il les a même détériorées.
Cela indique que le FSN n'est pas en mesure d'extraire efficacement les informations pertinentes des documents fournis. En utilisant RAFT, nous entraînons le modèle à traiter les documents avec précision et à fournir un style de réponse approprié.
L'approche RAFT a même surpassé GPT-3.5 avec RAG, qui est un modèle linguistique beaucoup plus grand, ce qui démontre l'efficacité de RAFT.
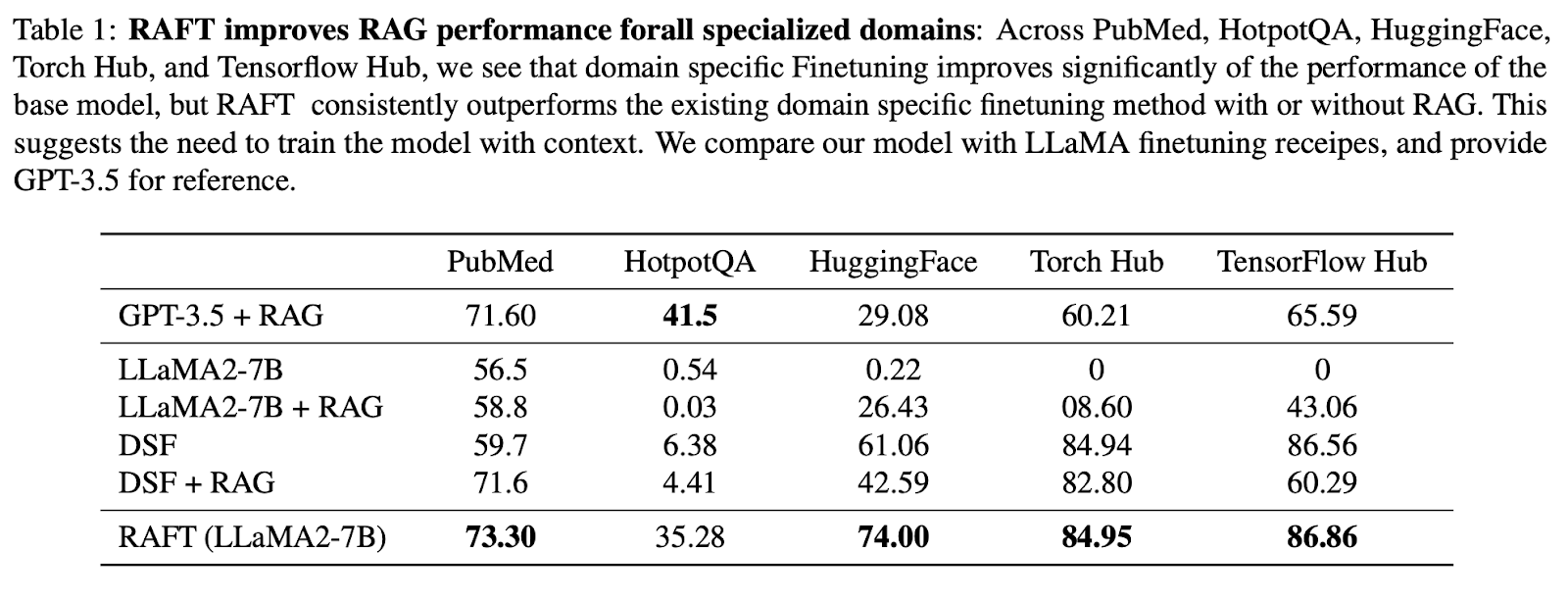
Source de l'image : RAFT : Adaptation du modèle linguistique à un domaine spécifique
Études d'ablation
Outre les expériences principales, l'article original a également mené plusieurs études d'ablation pour comprendre l'impact des différents composants sur les performances de la RAFT :
Pour mettre en œuvre RAFT, les chercheurs et les praticiens peuvent suivre les étapes décrites dans le document. Il s'agit notamment de générer des réponses de type chaîne de pensée à partir des documents pertinents, d'incorporer des documents distracteurs pendant la formation et d'affiner le modèle à l'aide de techniques d'apprentissage supervisé. Les auteurs ont également ouvert le code et fourni une démo pour faciliter l'expérimentation et l'adoption de RAFT.
RAFT représente une avancée significative dans le domaine de la modélisation linguistique spécifique à un domaine, offrant une solution puissante pour adapter les LLM à des domaines spécialisés. En combinant les forces de RAG et du réglage fin, RAFT dote les modèles linguistiques de la capacité d'exploiter efficacement les connaissances spécifiques au domaine tout en maintenant la robustesse face aux inexactitudes de la recherche.
Pour ceux qui souhaitent se plonger plus profondément dans le monde des RAG et du réglage fin, nous vous recommandons d'explorer les ressources suivantes :
Alors que la demande de modèles linguistiques spécifiques à un domaine continue de croître, des techniques telles que RAFT joueront un rôle crucial dans la mise en place d'applications NLP plus précises et plus fiables dans divers secteurs et domaines.
Poursuivez votre voyage d'apprentissage de l'IA dès aujourd'hui !
Cours
Cours
Cours