Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
100.8K
Como o processamento de linguagem natural (PLN) continua crescendo rapidamente, os modelos de linguagem grandes (LLMs) se tornaram ferramentas muito poderosas, capazes de lidar com um número cada vez maior de tarefas. No entanto, um desafio constante tem sido a adaptação desses modelos gerais a áreas altamente especializadas, como literatura médica ou documentação de software.
É aí que entra o Retrieval-Augmented Fine-Tuning (RAFT), uma nova técnica que pode transformar a PNL específica do domínio. O RAFT combina os pontos fortes do Retrieval-Augmented Generation (RAG), um método que combina LLMs com fontes de dados externas, e o ajuste fino, permitindo que os modelos não apenas aprendam conhecimentos específicos do domínio, mas também aprendam a recuperar e entender com precisão o contexto externo para executar tarefas.
Neste artigo, exploraremos o funcionamento interno da RAFT, analisaremos suas vantagens e veremos como essa técnica de ponta pode revolucionar a forma como abordamos as tarefas de PNL específicas de um domínio. Para começar, confira alguns recursos sobre o RAG, como nossa introdução ao RAG e aplicações práticas do RAG.
O Retrieval Augmented Fine-Tuning (RAFT) é uma abordagem inovadora para modelos de linguagem que combina os benefícios do RAG e do ajuste fino. Essa técnica adapta os modelos de linguagem a domínios específicos, aprimorando a capacidade dos modelos de compreender e utilizar o conhecimento específico do domínio e, ao mesmo tempo, garantindo a robustez contra recuperações imprecisas.
O RAFT foi projetado especificamente para enfrentar os desafios da adaptação de LLMs a domínios especializados. Nesses contextos, o raciocínio de conhecimento geral torna-se menos crítico, e o foco principal passa a ser a maximização da precisão em relação a um conjunto predefinido de documentos específicos do domínio.
O Retrieval-Augmented Generation (RAG) é uma técnica que aprimora os modelos de linguagem integrando um módulo de recuperação que obtém informações relevantes de bases de conhecimento externas.
Esse módulo de recuperação busca documentos relevantes com base na consulta de entrada. O modelo de linguagem usa esse contexto adicional para gerar o resultado final.
Operando sob o paradigma de "recuperar e ler", o RAG provou ser altamente eficaz em várias tarefas de PLN, incluindo modelagem de linguagem e resposta a perguntas de domínio aberto.
No entanto, esses modelos de linguagem não foram treinados para recuperar documentos precisos específicos do domínio e, em vez disso, só têm conhecimento geral do domínio a partir do pré-treinamento.
Conforme observado no artigo original, os métodos existentes de recuperação no contexto são equivalentes a fazer um exame com consulta sem saber quais documentos são mais relevantes para responder à pergunta.
Para saber mais sobre o RAG, veja como o RAG pode ser usado com o GPT e o Milvus para realizar a resposta a perguntas.
O ajuste fino é uma abordagem amplamente adotada para adaptar LLMs pré-treinados a tarefas posteriores. Esse processo envolve o treinamento adicional do modelo em dados específicos da tarefa, permitindo que ele aprenda padrões e se alinhe com o formato de saída desejado.
O ajuste fino foi comprovadamente bem-sucedido em vários aplicativos de PNL, como resumo, resposta a perguntas e geração de diálogos. No entanto, os métodos tradicionais de ajuste fino podem ter dificuldades para aproveitar o conhecimento externo específico do domínio ou lidar com recuperações imperfeitas durante a inferência.
Usando uma analogia semelhante à anterior, o ajuste fino é como memorizar documentos e responder a perguntas sem consultá-los durante o exame. O problema dessa abordagem é que o ajuste fino pode ser caro, e o conhecimento ajustado pode ficar desatualizado. Além disso, esses métodos de ajuste fino não são tão responsivos quanto os métodos baseados em RAG.
Para saber mais sobre o ajuste fino, aqui está um guia introdutório para o ajuste fino de LLMs.
O RAFT reconhece as limitações das abordagens existentes e tem como objetivo combinar os pontos fortes do RAG e do ajuste fino. Ao incorporar documentos específicos do domínio durante o processo de ajuste fino, o RAFT permite que o modelo aprenda padrões específicos do domínio de destino e, ao mesmo tempo, aprimora sua capacidade de entender e utilizar o contexto externo de forma eficaz.
Em um alto nível, no RAFT, os dados de treinamento consistem em perguntas, documentos (relevantes e irrelevantes) e respostas correspondentes no estilo cadeia de raciocínio geradas a partir dos documentos relevantes. O modelo é treinado para responder a perguntas com base nesses documentos fornecidos, incluindo documentos de distração que não contêm informações relevantes. Essa abordagem ensina o modelo a identificar e priorizar informações relevantes e a desconsiderar conteúdo irrelevante.
Vamos nos aprofundar na mecânica de como o ajuste fino aumentado por recuperação funciona. O RAFT propõe um novo método para preparar dados de ajuste fino para treinar modelos de resposta RAG no domínio. No RAFT, cada ponto de dados no conjunto de dados de treinamento consiste em:
No conjunto de dados de treinamento de ajuste fino RAFT, cada pergunta é combinada com um conjunto de documentos, alguns contendo as respostas e outros não, juntamente com uma resposta no estilo cadeia de raciocínio. Essa estrutura é particularmente útil para treinar o modelo para distinguir entre informações úteis e irrelevantes ao derivar respostas.
Para aprimorar ainda mais o aprendizado do modelo, o conjunto de dados de treinamento RAFT inclui uma combinação de tipos de perguntas:
Por fim, as respostas no estilo cadeia de raciocínio incorporam segmentos dos documentos do oráculo e um processo de raciocínio detalhado. Essa abordagem aumenta a precisão do modelo nas respostas às perguntas, ensinando-o a formar uma cadeia de raciocínio usando segmentos relevantes do contexto original.

Fonte da imagem: RAFT: Adaptação do modelo de linguagem ao RAG específico do domínio
Depois que os dados de treinamento são preparados, o processo de ajuste fino envolve:
Durante o estágio de inferência, nosso modelo ajustado será apresentado com uma pergunta e os principais K documentos recuperados pelo pipeline RAG. Observe que o módulo retriever opera independentemente do RAFT.
Para demonstrar que a RAFT é excelente na extração de informações relevantes de documentos do domínio e na resposta a perguntas, o artigo original comparou a abordagem da RAFT com um modelo de uso geral com RAG e com modelos ajustados específicos do domínio. Especificamente, eles ajustaram o Llama-2 usando o método RAFT para criar o modelo RAFT 7B e o compararam com o seguinte:
Esses modelos foram avaliados em três tipos de conjuntos de dados para avaliar o desempenho do RAFT em uma variedade de domínios:
Em geral, os resultados mostram que o RAFT superou consistentemente o método de ajuste fino supervisionado, com e sem RAG, no PubMed, HotpotQA e outros conjuntos de dados de API.
Quando comparado ao ajuste fino específico do domínio (DSF), o RAFT superou significativamente o DSF. É interessante notar que o DSF com RAG não levou a um melhor desempenho e, na verdade, teve um desempenho pior.
Isso indica que o DSF não tem a capacidade de extrair informações relevantes dos documentos fornecidos de forma eficaz. Ao utilizar o RAFT, treinamos o modelo para processar documentos com precisão e fornecer um estilo de resposta adequado.
A abordagem RAFT superou até mesmo o GPT-3.5 com o RAG, que é um modelo de linguagem muito maior, demonstrando a eficácia do RAFT.
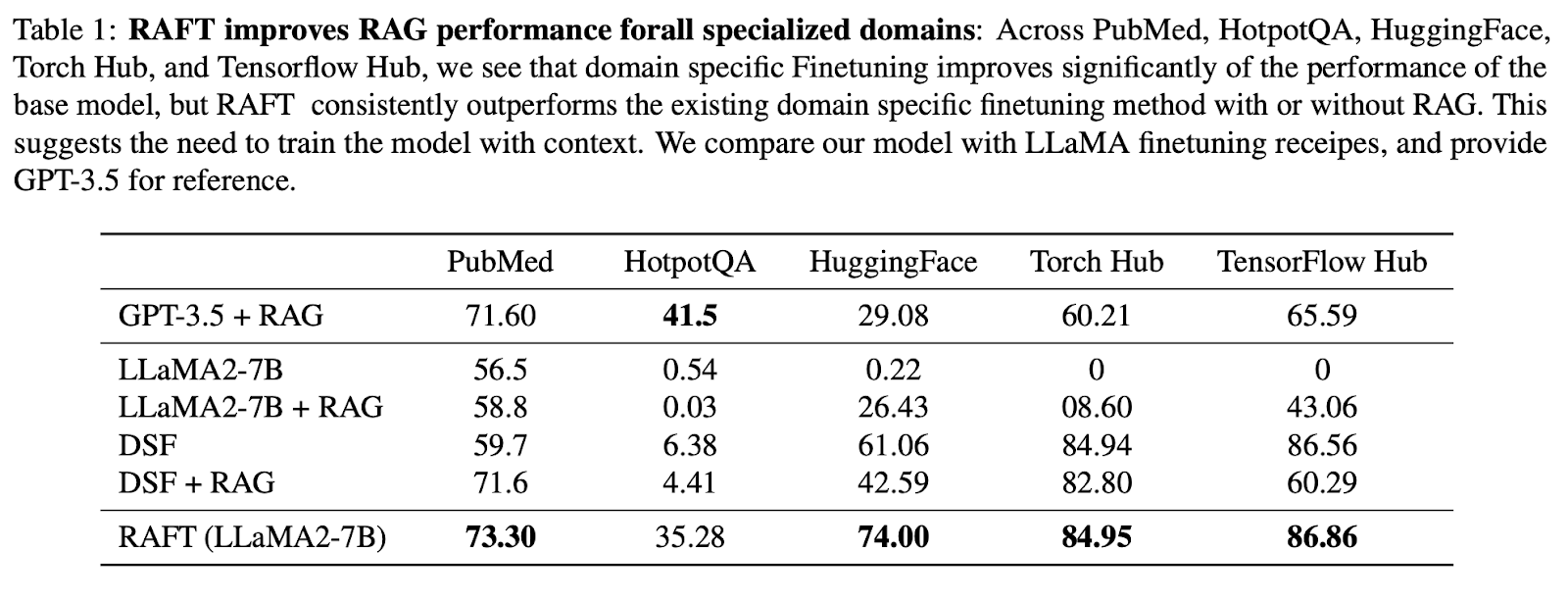
Fonte da imagem: RAFT: Adaptação do modelo de linguagem ao RAG específico do domínio
Estudos de ablação
Além dos experimentos principais, o artigo original também realizou vários estudos de ablação para entender o impacto de vários componentes no desempenho da RAFT:
Para implementar o RAFT, os pesquisadores e profissionais podem seguir as etapas descritas no documento. Isso inclui a geração de respostas no estilo cadeia de pensamento a partir de documentos relevantes, a incorporação de documentos de distração durante o treinamento e o ajuste fino do modelo usando técnicas de aprendizado supervisionado. Os autores também abriram o código e forneceram uma demonstração para facilitar a experimentação e a adoção do RAFT.
O RAFT representa um avanço significativo no campo da modelagem de linguagem específica de domínio, oferecendo uma solução poderosa para adaptar LLMs a domínios especializados. Ao combinar os pontos fortes do RAG e do ajuste fino, o RAFT equipa os modelos de linguagem com a capacidade de aproveitar efetivamente o conhecimento específico do domínio e, ao mesmo tempo, manter a robustez contra imprecisões de recuperação.
Para os interessados em se aprofundar no mundo do RAG e do ajuste fino, recomendamos que você explore os seguintes recursos:
Como a demanda por modelos de linguagem específicos de domínio continua a crescer, técnicas como a RAFT desempenharão um papel fundamental na viabilização de aplicativos de PNL mais precisos e confiáveis em vários setores e domínios.
Continue sua jornada de aprendizado de IA hoje mesmo!
Curso
Curso
Curso
blog
Nisha Arya Ahmed
12 min
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
