
Course
Large Language Models (LLMs) Concepts
2 hr
100.8K
As natural language processing (NLP) continues growing rapidly, large language models (LLMs) have become very powerful tools, able to handle an increasing number of tasks. However, one ongoing challenge has been adapting these general models to highly specialized areas, such as medical literature or software documentation.
This is where Retrieval-Augmented Fine-Tuning (RAFT) comes in, a new technique that could transform domain-specific NLP. RAFT combines the strengths of Retrieval-Augmented Generation (RAG), a method that combines LLMs with external data sources, and fine-tuning, enabling models to not only learn domain-specific knowledge but also learn how to accurately retrieve and understand external context to perform tasks.
In this article, we'll explore the inner workings of RAFT, look at its advantages, and see how this cutting-edge technique could revolutionize how we approach domain-specific NLP tasks. To get started, check out some resources on RAG, such as our introduction to RAG and practical applications of RAG.
Retrieval Augmented Fine-Tuning (RAFT) is a groundbreaking approach to language models that combines the benefits of RAG and fine-tuning. This technique tailors language models to specific domains by enhancing the models' ability to comprehend and utilize domain-specific knowledge while ensuring robustness against inaccurate retrievals.
RAFT is specifically designed to address the challenges of adapting LLMs to specialized domains. In these contexts, general knowledge reasoning becomes less critical, and the primary focus shifts towards maximizing accuracy with respect to a predefined set of domain-specific documents.
Retrieval-Augmented Generation (RAG) is a technique that enhances language models by integrating a retrieval module that sources relevant information from external knowledge bases.
This retrieval module fetches relevant documents based on the input query. The language model then uses this additional context to generate the final output.
Operating under a 'retrieve-and-read' paradigm, RAG has proven highly effective in various NLP tasks, including language modeling and open-domain question answering.
However, these language models haven’t been trained to retrieve accurate domain-specific documents and instead only has general domain knowledge from pre-training.
As noted in the original paper, existing in-context retrieval methods are equivalent to taking an open-book exam without knowing which documents are most relevant for answering the question.
To learn more about RAG, check out how RAG can be used with GPT and Milvus to perform Questions Answering.
Fine-tuning is a widely adopted approach for adapting pre-trained LLMs to downstream tasks. This process involves further training the model on task-specific data, enabling it to learn patterns and align with the desired output format.
Fine-tuning has proven successful in various NLP applications, such as summarization, questions answering, and dialogue generation. However, traditional fine-tuning methods may struggle to leverage external domain-specific knowledge or handle imperfect retrievals during inference.
Using a similar analogy as before, fine-tuning is like memorizing documents and answering questions without referencing them during the exam. The problem with this approach is that fine-tuning can be costly, and the fine-tuned knowledge may become outdated. Additionally, these fine-tuning methods are not as responsive as RAG-based methods.
To learn more about fine-tuning, here’s an introductory guide to fine-tuning LLMs.
RAFT recognizes the limitations of existing approaches and aims to combine the strengths of RAG and fine-tuning. By incorporating domain-specific documents during the fine-tuning process, RAFT enables the model to learn patterns specific to the target domain while also enhancing its ability to understand and utilize external context effectively.
At a high level, in RAFT, the training data consists of questions, documents (both relevant and irrelevant), and corresponding chain-of-thought-style answers generated from the relevant documents. The model is trained to answer questions based on these provided documents, including distractor documents that do not contain relevant information. This approach teaches the model to identify and prioritize relevant information while disregarding irrelevant content.
Let's dive deeper into the mechanics of how Retrieval-Augmented Fine-Tuning works. RAFT proposes a novel method to prepare fine-tuning data to train in-domain RAG answering models. In RAFT, each data point in the training dataset consists of:
In the RAFT fine-tuning training dataset, each question is paired with a set of documents, some containing the answers and some not, along with a chain-of-thought style answer. This structure is particularly useful for training the model to distinguish between useful and irrelevant information when deriving answers.
To further enhance the model's learning, the RAFT training dataset includes a mix of question types:
Finally, the chain-of-thought style answers incorporate segments from the oracle documents and a detailed reasoning process. This approach enhances the model’s accuracy in answering questions by teaching it to form a reasoning chain using relevant segments from the original context.

Image Source: RAFT: Adapting Language Model to Domain Specific RAG
Once the training data is prepared, the fine-tuning process involves:
During the inference stage, our fine-tuned model will be presented with a question and the top-K documents retrieved by the RAG pipeline. Note that the retriever module operates independently of RAFT.
To demonstrate that RAFT excels at extracting relevant information from in-domain documents and answering questions, the original paper compared the RAFT approach to a general-purpose model with RAG and to domain-specific fine-tuned models. Specifically, they fine-tuned Llama-2 using the RAFT method to create the RAFT 7B model, and compared it to the following:
These models were evaluated on three types of datasets to assess the performance of RAFT across a range of domains:
Overall, the results show that RAFT consistently outperformed the supervised fine-tuning method, both with and without RAG, across PubMed, HotpotQA, and the other API datasets.
When compared to domain-specific fine-tuning (DSF), RAFT significantly outperformed DSF. Interestingly, DSF with RAG did not lead to better performance and, in fact, performed worse.
This indicates that DSF lacks the capability to extract relevant information from provided documents effectively. By utilizing RAFT, we train the model to both process documents accurately and provide an appropriate answering style.
The RAFT approach even outperformed GPT-3.5 with RAG, which is a much larger language model, demonstrating the effectiveness of RAFT.
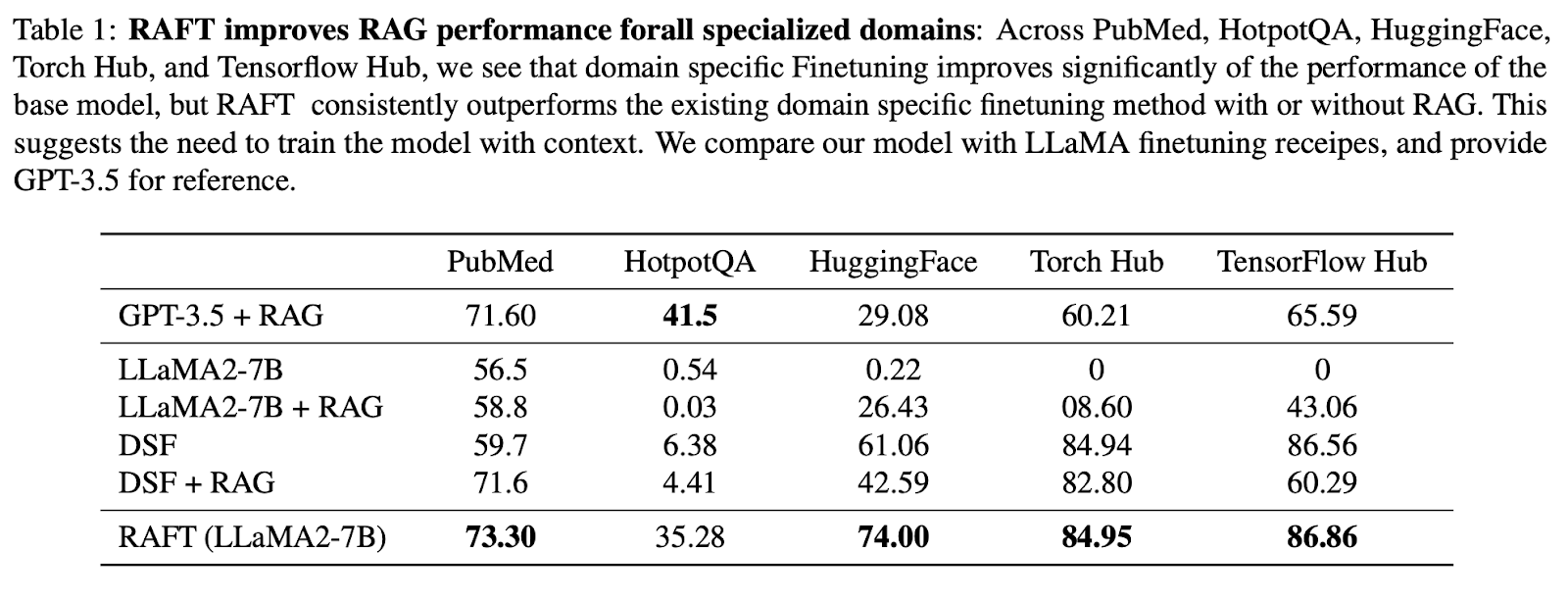
Image source: RAFT: Adapting Language Model to Domain Specific RAG
Ablation studies
In addition to the main experiments, the original paper also conducted several ablation studies to understand the impact of various components on the performance of RAFT:
To implement RAFT, researchers and practitioners can follow the steps outlined in the paper. This includes generating chain-of-thought-style answers from relevant documents, incorporating distractor documents during training, and fine-tuning the model using supervised learning techniques. The authors have also open-sourced the code and provided a demo to facilitate further experimentation and adoption of RAFT.
RAFT represents a significant advancement in the field of domain-specific language modeling, offering a powerful solution for adapting LLMs to specialized domains. By combining the strengths of RAG and fine-tuning, RAFT equips language models with the ability to effectively leverage domain-specific knowledge while maintaining robustness against retrieval inaccuracies.
For those interested in diving deeper into the world of RAG and fine-tuning, we recommend exploring the following resources:
As the demand for domain-specific language models continues to grow, techniques like RAFT will play a crucial role in enabling more accurate and reliable NLP applications across various industries and domains.
Continue Your AI Learning Journey Today!
Course
Course
Course
blog
Natassha Selvaraj
10 min
blog
Stanislav Karzhev
12 min
Tutorial
Abid Ali Awan
Tutorial
Iván Palomares Carrascosa
Tutorial
Josep Ferrer
Tutorial
Bhavishya Pandit
