
programa
Fundamentos de la IA
10 h
Imagina un sistema capaz de identificar y neutralizar amenazas con las que nunca se ha topado, al tiempo que recuerda invasores pasados para rechazarlos con mayor eficacia. Tu sistema inmunitario lo hace todos los días.
Ahora, imagina aplicar este mismo nivel de inteligencia a la resolución de problemas informáticos complejos. Conlos sistemas inmunitarios artificiales (SIA) de , podemos hacer precisamente eso.
Los sistemas inmunitarios artificiales son potentes modelos computacionales inspirados en la capacidad del sistema inmunitario humano para proteger al cuerpo de cualquier daño.
El sistema inmunitario es el mecanismo de defensa de nuestro cuerpo, diseñado para reconocer y neutralizar amenazas como bacterias, virus y hongos. Lo hace a través de unos pocos actores clave: anticuerpos, células b y células t.
Anticuerpos actúan como unidades de identificación del sistema inmunitario. Estas proteínas especializadas reconocen y se adhieren a sustancias extrañas específicas, denominadasantígenos , marcándolas como amenazas. Cada anticuerpo es único, diseñado para coincidir con un antígeno concreto, como una cerradura y una llave.
Células B son las fábricas que producen anticuerpos. También participan en la creación de células de memoria. Ayudan al organismo a responder más rápidamente a antígenos encontrados previamente, recordando qué anticuerpos fueron útiles la última vez.
Las células T son las ejecutoras del sistema inmunitario. Detectan y destruyen las células marcadas por los anticuerpos como infectadas o peligrosas, garantizando que la amenaza se neutralice rápidamente.
Una de las características más notables del sistema inmunitario es su capacidad para evolucionar y mejorar nuevos anticuerpos a lo largo del tiempo. Ante un nuevo agente patógeno, el sistema inmunitario no responde una sola vez. Perfecciona continuamente su enfoque, creando anticuerpos más fuertes y eficaces para hacer frente a la amenaza.
Los sistemas inmunitarios artificiales (SIA) son la implementación de estos principios biológicos en algoritmos. El AIS imita las funciones del sistema inmunitario en la resolución de problemas.
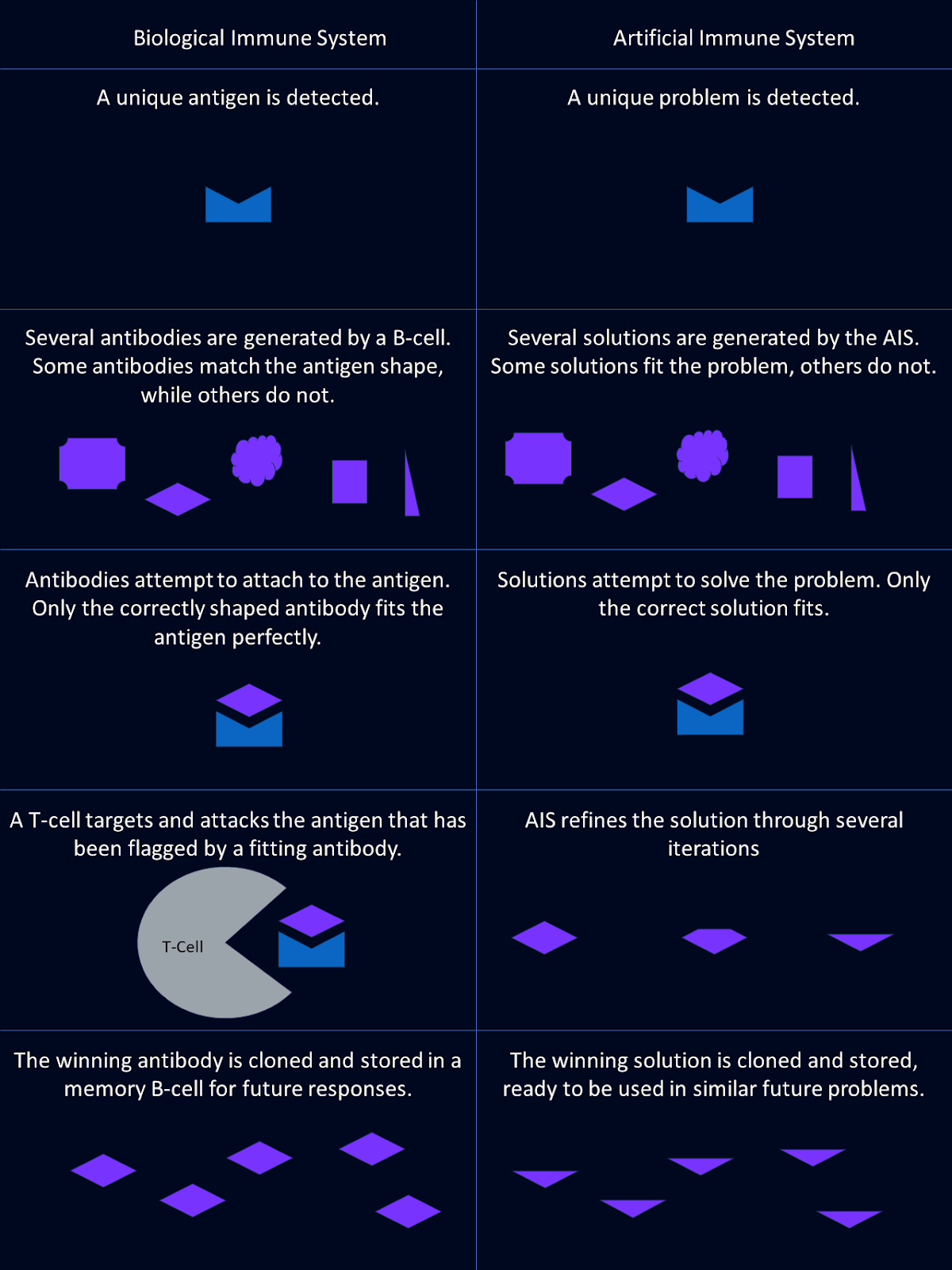
En los AIS, los antígenos representan los problemas o retos que hay que abordar. Pueden ser desde la detección de anomalías en los datos hasta la optimización de una solución.
Los anticuerpos en la AIS son soluciones candidatas a estos problemas. Al igual que los anticuerpos biológicos reconocen antígenos específicos, la AIS desarrolla soluciones potenciales adaptadas a retos concretos.
El proceso de las células B en la AIS refleja cómo los sistemas biológicos generan diversidad y memoria. Los algoritmos AIS utilizan diversas soluciones candidatas y las van refinando con el tiempo. Aprenden de problemas anteriores para mejorar su rendimiento futuro.
Los sistemas inmunitarios artificiales no tienen un análogo directo de las células T, pero incorporan mecanismos de evaluación que cumplen una función similar. Estos procesos eliminan las soluciones ineficaces y afinan las que funcionan mejor.
Los AIS utilizan principios evolutivos, como la mutación y la selección, para mejorar continuamente la calidad de las soluciones.
Los sistemas inmunitarios artificiales incorporan conceptos clave como la interacción anticuerpo-antígeno, la selección clonal, la selección negativa y la teoría de redes inmunitarias.
Parte integrante de los sistemas inmunitarios artificiales es el concepto de interacción anticuerpo-antígeno. Este proceso se inspira directamente en cómo responde nuestro sistema inmunitario a las amenazas. Piensa en los anticuerpos como soluciones potenciales a un problema y en los antígenos como los propios problemas o retos.
En el mundo biológico, los anticuerpos son proteínas que se adhieren a los antígenos y los neutralizan. En AIS, un anticuerpo representa una solución candidata a un problema computacional, mientras que el antígeno representa el problema que hay que resolver.
El algoritmo AIS hace evolucionar una población de estos anticuerpos para que reconozcan y neutralicen eficazmente los antígenos correspondientes. Con el tiempo, el algoritmo afina estos anticuerpos, perfeccionando las soluciones más eficaces.
El algoritmo de selección clonal (CSA) se inspira en otro proceso crítico de nuestro sistema inmunitario. Cuando el organismo detecta un antígeno, no despliega cualquier célula inmunitaria al azar, sino que selecciona las que pueden reconocer específicamente al invasor. A continuación, estas células seleccionadas se clonan en grandes cantidades para montar una defensa eficaz.
Estos clones sufren mutaciones, introduciendo ligeras variaciones que aumentan la diversidad de la respuesta inmunitaria. Esto garantiza que, aunque el patógeno evolucione, el sistema inmunitario pueda adaptarse y responder eficazmente.
Del mismo modo, el algoritmo de selección clonal selecciona las soluciones más prometedoras y crea múltiples copias o "clones" de ellas.
A continuación, estos clones se someten a mutaciones, generando un conjunto diverso de soluciones potenciales. Los clones con mejores resultados se conservan, y el proceso se repite, mejorando gradualmente la calidad de las soluciones. Este algoritmo es especialmente potente en tareas de optimización, en las que el objetivo es encontrar la solución más eficiente entre muchas posibilidades.
La CSA se utiliza con frecuencia para resolver problemas de optimización. Por ejemplo, en el sector aeroespacial, puede ayudar a diseñar estructuras eficientes, como las alas de los aviones, mejorando las propiedades aerodinámicas a lo largo de múltiples iteraciones.
En imagen médica, la CSA puede mejorar la claridad de la imagen o detectar patrones irregulares en entornos ruidosos, lo que la hace útil para las resonancias magnéticas o la detección de tumores.
El sistema inmunitario humano debe distinguir entre las células del organismo y los invasores extraños. Aquí es donde entra en juego el algoritmo de selección negativa (NSA). Se eliminan las células inmunitarias que reaccionan con demasiada fuerza a las células del propio organismo. Esto ayuda a garantizar que el sistema inmunitario no se ataque a sí mismo por error (causando una enfermedad autoinmunitaria).
La NSA imita este proceso para identificar anomalías o valores atípicos en los datos. El algoritmo genera un conjunto de modelos, llamados detectores, diseñados para reconocer patrones normales en los datos. Se eliminan los detectores que coinciden con los datos normales, dejando sólo los que no coinciden con los patrones típicos. Estos detectores restantes se utilizan para controlar los nuevos datos.
Si estos detectores atípicos marcan un nuevo punto de datos, lo indica como una anomalía. Esto es similar a cómo el sistema inmunitario detecta a los invasores extraños. Este método es muy eficaz en campos como ciberseguridaddonde la detección de patrones inusuales es clave para identificar posibles amenazas.
La NSA es muy adecuada para los sistemas de detección de intrusos que controlan el tráfico de la red, identificando la actividad maliciosa mediante la comparación de patrones normales con los de amenazas potenciales.
La NSA también puede aplicarse para detectar fallos mecánicos o de funcionamiento en sistemas complejos, como las centrales eléctricas.
La teoría de redes inmunitarias (TRI) amplía el concepto de AIS modelando no sólo la interacción entre anticuerpos y antígenos, sino también las interacciones entre los propios anticuerpos.
En el sistema inmunitario biológico, los anticuerpos no actúan aisladamente. Se comunican e influyen entre sí, creando una red dinámica de respuestas más sólida y adaptable. Esta interacción en red ayuda al sistema inmunitario a mantener un equilibrio, garantizando que pueda responder eficazmente a una amplia gama de amenazas sin reaccionar de forma exagerada ante ninguna de ellas.
INT se utiliza para modelar interacciones y dependencias complejas entre distintas soluciones. Esto permite al algoritmo considerar una gama más amplia de posibles respuestas, lo que conduce a estrategias de resolución de problemas más sofisticadas.
Al simular cómo se influyen mutuamente los anticuerpos, el AIS puede explorar simultáneamente múltiples vías hacia una solución, mejorando su capacidad para encontrar soluciones óptimas en entornos complejos y dinámicos. Esta teoría sustenta algunos de los algoritmos AIS más avanzados, lo que la convierte en una poderosa herramienta para abordar intrincados retos computacionales.
La teoría de las redes inmunes puede aplicarse al control de enjambres robóticos. Las interacciones entre robots imitan las de los anticuerpos, lo que permite un comportamiento coordinado y la resolución de problemas en tareas como las misiones de búsqueda y rescate.
En finanzas, los modelos de redes inmunes pueden utilizarse para estudiar las interacciones entre diversos indicadores económicos, lo que permite predecir las tendencias del mercado o detectar anomalías financieras.
Python suele ser el lenguaje elegido para crear sistemas inmunitarios artificiales, debido a sus amplias bibliotecas y a su facilidad de uso.
El algoritmo de selección clonal se inspira en el proceso biológico por el que las células inmunitarias que reconocen con éxito una amenaza se clonan y luego mutan para mejorar la respuesta inmunitaria. En AIS, estas "células inmunitarias" son soluciones candidatas a un problema, y el objetivo es hacer evolucionar estas soluciones para encontrar la mejor.
A continuación te explicamos cómo puedes implementar una versión sencilla de CSA en Python:
Vamos a resolver un problema de optimización de funciones utilizando CSA. Optimizaremos una conocida función de referencia, la función Rastrigin. Esta función puede utilizarse para probar algoritmos de optimización debido a sus numerosos mínimos locales.
En el código siguiente, utilizamos una CSA para encontrar los mínimos globales de la función:
import numpy as np
import matplotlib.pyplot as plt
# Define the Rastrigin function
def rastrigin(X):
n = len(X)
return 10 * n + np.sum(X**2 - 10 * np.cos(2 * np.pi * X))
# Generate the initial population of potential solutions
def generate_initial_population(pop_size, solution_size):
return np.random.uniform(-5.12, 5.12, size=(pop_size, solution_size)) # Initialize within the search space of Rastrigin
# Evaluate the fitness of each individual in the population (lower is better)
def evaluate_population(population):
return np.array([rastrigin(individual) for individual in population])
# Select the best candidates from the population based on their fitness
def select_best_candidates(population, fitness, num_candidates):
indices = np.argsort(fitness)
return population[indices[:num_candidates]], fitness[indices[:num_candidates]]
# Clone the best candidates multiple times
def clone_candidates(candidates, num_clones):
return np.repeat(candidates, num_clones, axis=0)
# Introduce random mutations to the cloned candidates to explore new solutions
def mutate_clones(clones, mutation_rate):
mutations = np.random.rand(*clones.shape) < mutation_rate
clones[mutations] += np.random.uniform(-1, 1, np.sum(mutations)) # Mutate by adding a random value
return clones
# Main function implementing the Clonal Selection Algorithm
def clonal_selection_algorithm(solution_size=2, pop_size=100, num_candidates=10, num_clones=10, mutation_rate=0.05, generations=100):
population = generate_initial_population(pop_size, solution_size)
best_fitness_per_generation = [] # Track the best fitness in each generation
for generation in range(generations):
fitness = evaluate_population(population)
candidates, candidate_fitness = select_best_candidates(population, fitness, num_candidates)
clones = clone_candidates(candidates, num_clones)
mutated_clones = mutate_clones(clones, mutation_rate)
clone_fitness = evaluate_population(mutated_clones)
# Replace the worst individuals in the population with the new mutated clones
population[:len(mutated_clones)] = mutated_clones
fitness[:len(clone_fitness)] = clone_fitness
# Track the best fitness of this generation
best_fitness = np.min(fitness)
best_fitness_per_generation.append(best_fitness)
# Stop early if we've found a solution close to the global minimum
if best_fitness < 1e-6:
print(f"Optimal solution found in {generation + 1} generations.")
break
# Plot the fitness improvement over generations
plt.figure(figsize=(10, 6))
plt.plot(best_fitness_per_generation, marker='o', color='blue', label='Best Fitness per Generation')
plt.xlabel('Generations')
plt.ylabel('Fitness (Rastrigin Function Value)')
plt.title('Fitness Improvement Over Generations')
plt.grid(True)
plt.show()
# Return the best solution found (the one with the lowest fitness score)
best_solution = population[np.argmin(fitness)]
return best_solution
# Example Usage
best_solution = clonal_selection_algorithm(solution_size=2) # Using 2D Rastrigin function
print("Best solution found:", best_solution)
print("Rastrigin function value at best solution:", rastrigin(best_solution))
# Plot the surface of the Rastrigin function with the best solution found
x = np.linspace(-5.12, 5.12, 200)
y = np.linspace(-5.12, 5.12, 200)
X, Y = np.meshgrid(x, y)
Z = 10 * 2 + (X**2 - 10 * np.cos(2 * np.pi * X)) + (Y**2 - 10 * np.cos(2 * np.pi * Y))
plt.figure(figsize=(8, 6))
plt.contourf(X, Y, Z, levels=50, cmap='viridis')
plt.colorbar(label='Function Value')
plt.scatter(best_solution[0], best_solution[1], c='red', s=100, label='Best Solution')
plt.title('Rastrigin Function Optimization with CSA')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()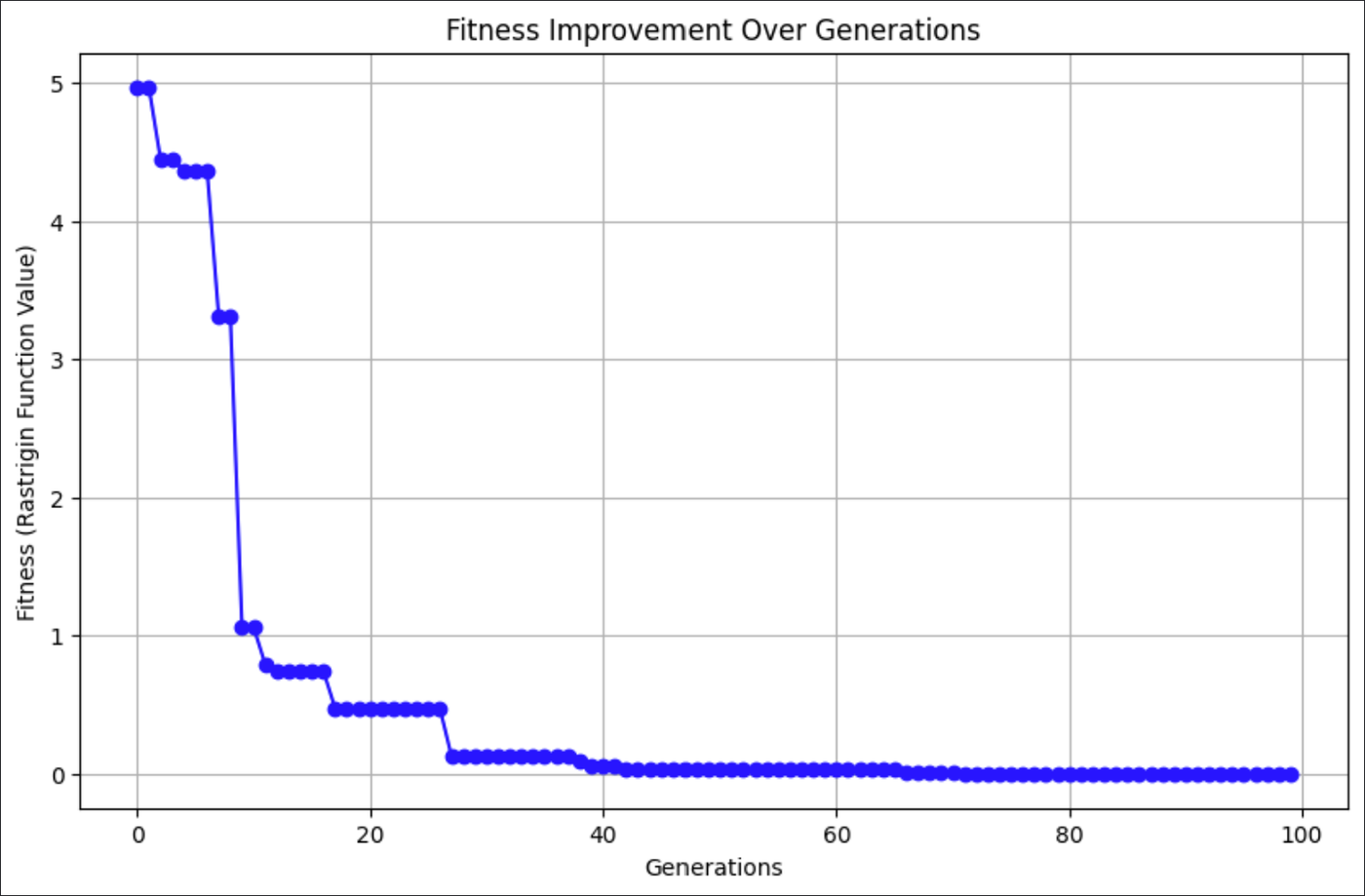
El gráfico anterior muestra cómo el CSA encontró mejores soluciones a la función Rastrigin con cada generación.
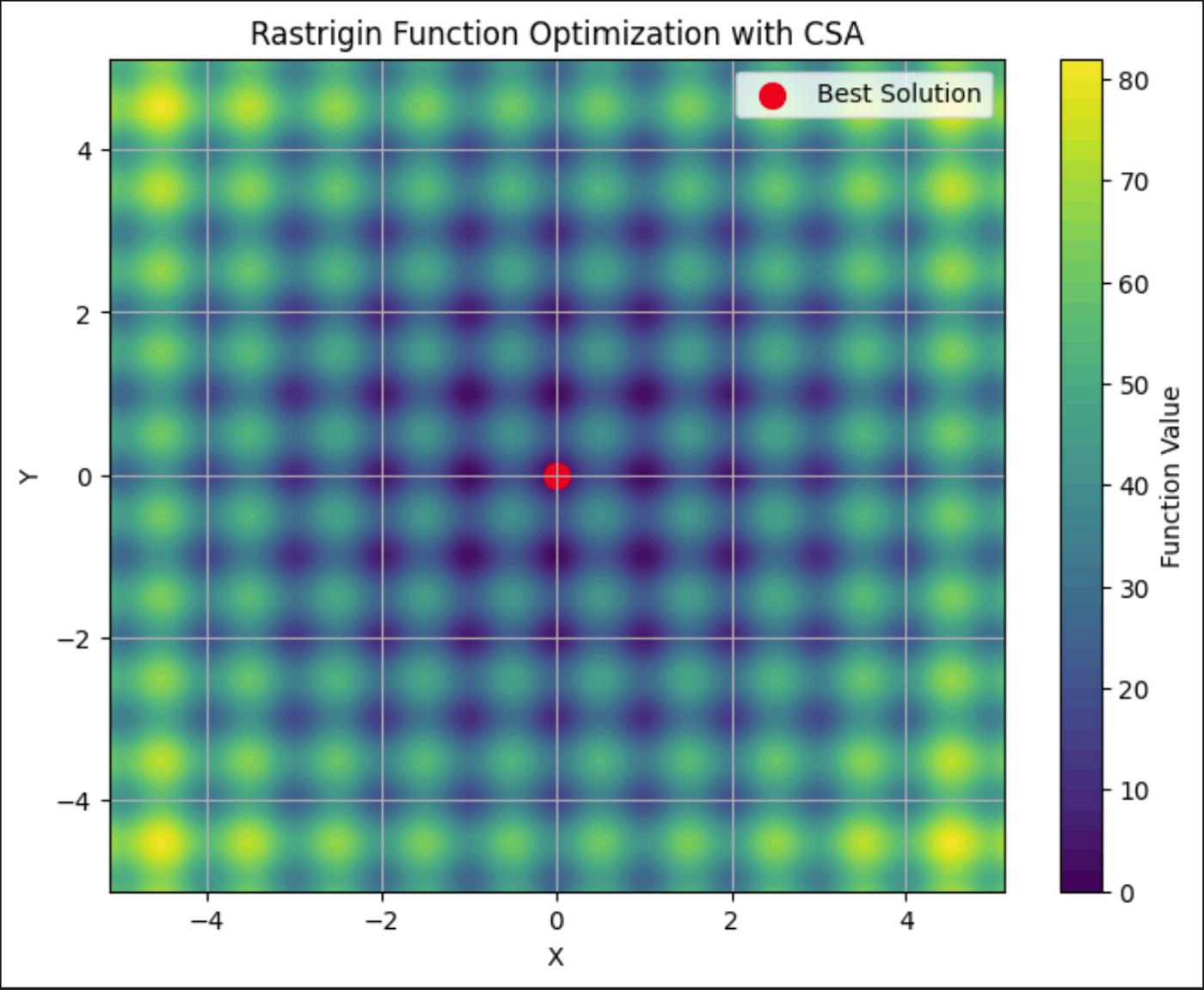
Este gráfico muestra el Rastrigin trazado, demostrando sus numerosos mínimos locales. La mejor solución, el punto rojo del centro, es la solución final encontrada por la CSA.
La NSA es especialmente útil para tareas de detección de anomalías. Este algoritmo simula cómo el sistema inmunitario distingue entre las células del propio cuerpo y los invasores extraños. En una NSA, generas un conjunto de detectores que no coinciden con los patrones de datos normales. Estos detectores se utilizan para controlar los nuevos datos, señalando cualquier cosa que parezca anómala.
Aquí tienes un resumen de cómo crear una ANS:
Veamos cómo funciona utilizando un conjunto ficticio de transacciones. En este ejemplo, generamos transacciones normales centradas en torno a dos clusters y transacciones fraudulentas dispersas aleatoriamente. Emplearemos un algoritmo de selección negativa, en el que los detectores de fraude se dispersan por el espacio de características para identificar las anomalías en función de su proximidad a estos detectores.
import numpy as np
import matplotlib.pyplot as plt
# Generate a synthetic dataset
np.random.seed()
# Parameters for bimodal distribution
num_normal_points = 80 # total number of normal transactions
num_points_per_cluster = num_normal_points // 2 # number of points in each cluster
# Generate normal transactions for two clusters
cluster1_center = [2, 2]
cluster2_center = [8, 8]
# Generate points around the first cluster center
normal_cluster1 = np.random.normal(loc=cluster1_center, scale=0.5, size=(num_points_per_cluster, 2))
# Generate points around the second cluster center
normal_cluster2 = np.random.normal(loc=cluster2_center, scale=0.5, size=(num_points_per_cluster, 2))
# Combine clusters into one dataset
normal_transactions = np.vstack([normal_cluster1, normal_cluster2])
# Define random distribution for fraudulent transactions
num_fraud_points = 5 # number of fraudulent transactions
fraudulent_transactions = np.random.uniform(low=0, high=10, size=(num_fraud_points, 2))
# Combine into one dataset
data = np.vstack([normal_transactions, fraudulent_transactions])
labels = np.array([0] * len(normal_transactions) + [1] * len(fraudulent_transactions))
# Function to generate detectors (random points) that don't match any of the normal data
def generate_detectors(normal_data, num_detectors, detector_size):
detectors = []
while len(detectors) < num_detectors:
detector = np.random.rand(detector_size) * 10 # Scale to cover the data range
if not any(np.allclose(detector, pattern, atol=0.5) for pattern in normal_data):
detectors.append(detector)
return np.array(detectors)
# Function to detect anomalies (points in the data that are close to any detector)
def detect_anomalies(detectors, data, threshold=0.5):
anomalies = []
for point in data:
if any(np.linalg.norm(detector - point) < threshold for detector in detectors):
anomalies.append(point)
return anomalies
# Generate detectors that do not match the normal data
detectors = generate_detectors(normal_transactions, num_detectors=300, detector_size=2)
# Detect anomalies within the entire dataset using the detectors
anomalies = detect_anomalies(detectors, data)
print("Number of anomalies detected:", len(anomalies))
# Convert anomalies to a numpy array for visualization
anomalies = np.array(anomalies) if anomalies else np.array([])
# Define axis limits
x_min, x_max = 0, 10
y_min, y_max = -1, 11
# Visualize the dataset, detectors, and anomalies
plt.figure(figsize=(14, 6))
# Plot the normal transactions and fraudulent transactions
plt.subplot(1, 2, 1)
plt.scatter(normal_transactions[:, 0], normal_transactions[:, 1], color='red', marker='x', label='Normal Transactions')
plt.scatter(fraudulent_transactions[:, 0], fraudulent_transactions[:, 1], color='green', marker='o', label='Fraudulent Transactions')
plt.scatter(detectors[:, 0], detectors[:, 1], color='blue', marker='o', alpha=0.5, label='Detectors')
if len(anomalies) > 0:
plt.scatter(anomalies[:, 0], anomalies[:, 1], color='yellow', marker='*', s=100, label='Detected Anomalies')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Fraud Detection Using Negative Selection Algorithm (NSA)')
plt.legend(loc='lower right')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.grid(False)
# Create a grid of points to classify
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100))
grid_points = np.c_[xx.ravel(), yy.ravel()]
# Classify grid points
decision = np.array([any(np.linalg.norm(detector - point) < 0.5 for detector in detectors) for point in grid_points])
decision = decision.reshape(xx.shape)
# Plot the decision boundary
plt.subplot(1, 2, 2)
plt.contourf(xx, yy, decision, cmap='coolwarm', alpha=0.3)
plt.scatter(normal_transactions[:, 0], normal_transactions[:, 1], color='red', marker='x', label='Normal Transactions')
plt.scatter(fraudulent_transactions[:, 0], fraudulent_transactions[:, 1], color='green', marker='o', label='Fraudulent Transactions')
plt.scatter(detectors[:, 0], detectors[:, 1], color='blue', marker='o', alpha=0.5, label='Detectors')
if len(anomalies) > 0:
plt.scatter(anomalies[:, 0], anomalies[:, 1], color='yellow', marker='*', s=100, label='Detected Anomalies')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Decision Boundary Visualization')
plt.legend(loc='lower right')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.grid(False)
# Show the plot
plt.show()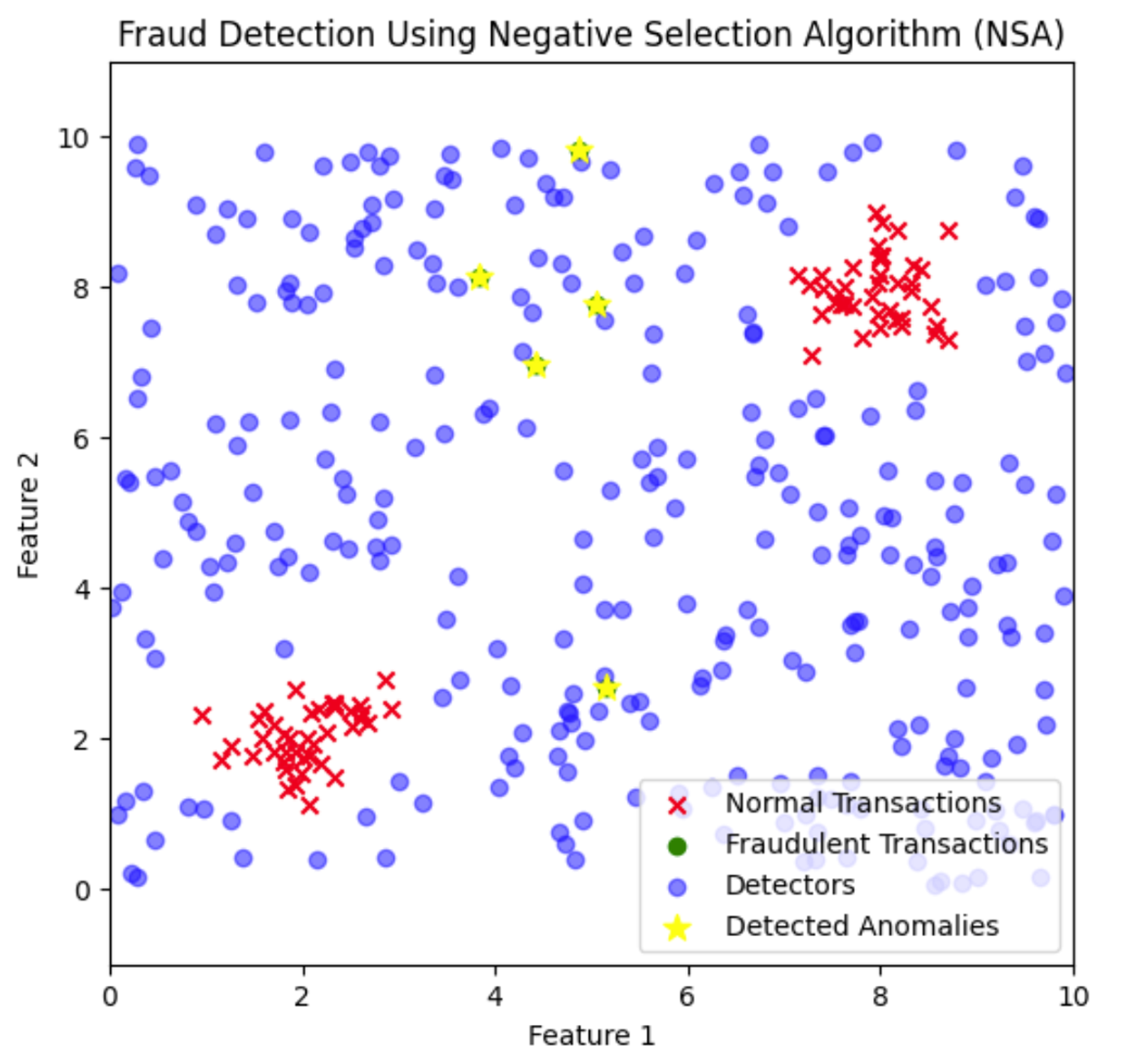
Aquí, los detectores de fraude se distribuyen por el espacio de características para cubrir las zonas en las que no aparecen transacciones normales. Las transacciones fraudulentas que se acercan a estos detectores se identifican y se marcan como anomalías.
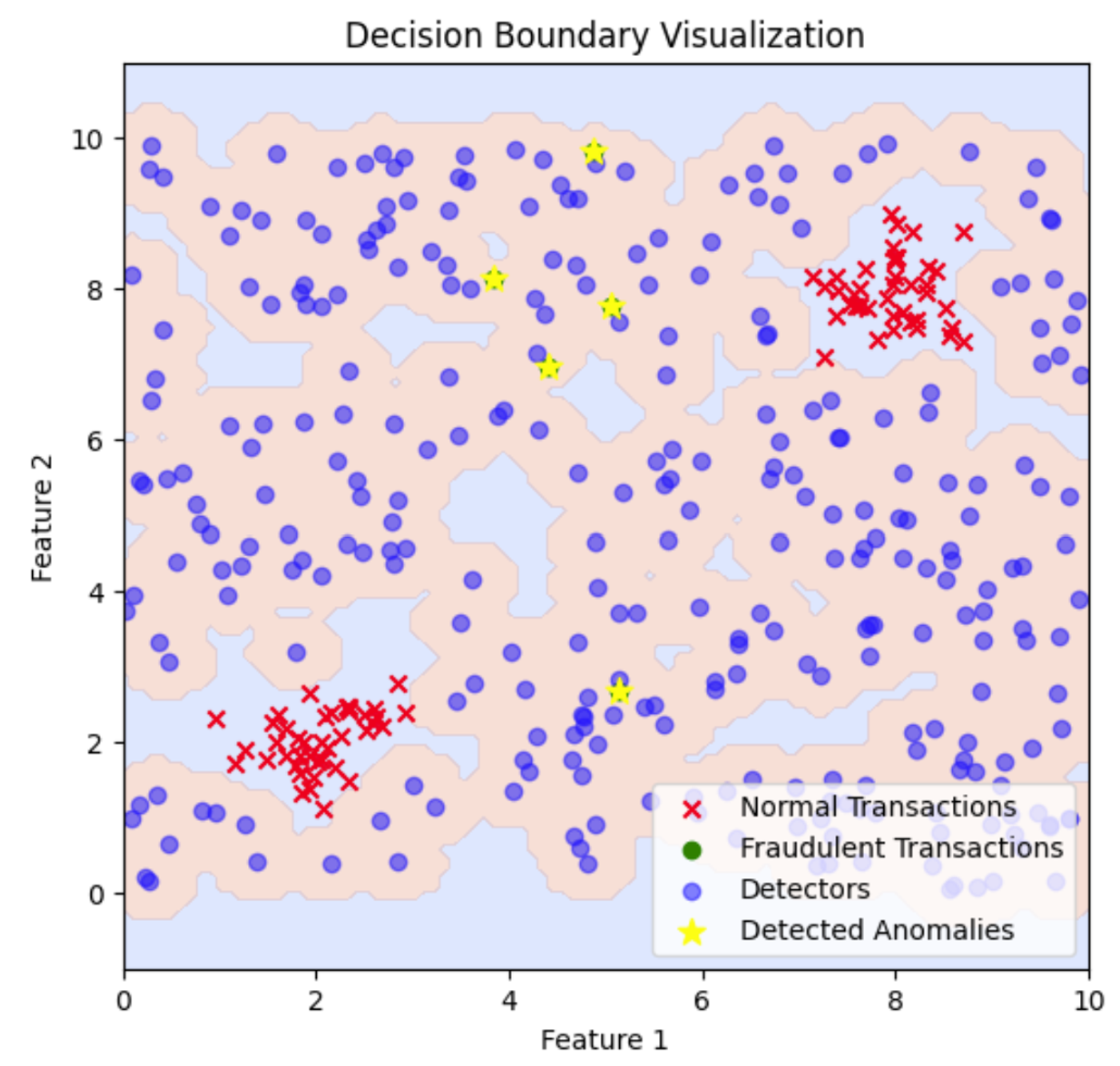
Este gráfico ilustra el límite de decisión creado por los detectores de fraude. Las regiones sombreadas representan zonas clasificadas como anómalas en función de la proximidad a los detectores, destacando dónde se detectan transacciones fraudulentas en relación con las transacciones normales. Para ajustar el límite de decisión y abarcar más o menos superficie, puedes modificar el umbral de distancia utilizado para detectar anomalías, lo que ampliará o contraerá las regiones clasificadas como anómalas.
La INT se inspira en la idea de que las respuestas inmunitarias no sólo se basan en anticuerpos individuales, sino también en su comunicación. Este enfoque modela el sistema inmunitario como una red en la que los anticuerpos se comunican para mejorar la respuesta inmunitaria global. En este contexto, cada anticuerpo (solución) puede interactuar con otros para influir y refinar la búsqueda de soluciones óptimas.
He aquí cómo puedes implementar una versión básica de INT en Python:
Utilicemos la INT para predecir las tendencias bursátiles basándonos en un conjunto de indicadores económicos. Utilizaremos un conjunto de datos ficticio en el que cada solución representa una combinación de indicadores para predecir los precios de las acciones.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Generate synthetic data for illustration
np.random.seed(42)
n_samples = 100
n_features = 5
X = np.random.rand(n_samples, n_features) # Random economic indicators
true_weights = np.array([0.5, -0.2, 0.3, 0.1, -0.1])
y = X @ true_weights + np.random.normal(0, 0.1, n_samples) # Stock prices with noise
# Define the fitness function
def fitness_function(solution, X, y):
model = LinearRegression()
model.coef_ = solution
predictions = X @ model.coef_
return mean_squared_error(y, predictions)
# Generate the initial population of potential solutions
def generate_initial_population(pop_size, solution_size):
return np.random.uniform(-1, 1, size=(pop_size, solution_size))
# Create the immune network
def create_immune_network(population, fitness, num_neighbors):
network = []
for i, individual in enumerate(population):
distances = np.linalg.norm(population - individual, axis=1)
neighbors = np.argsort(distances)[1:num_neighbors+1] # Exclude self
network.append(neighbors)
return network
# Update the immune network
def update_network(network, population, fitness, mutation_rate):
new_population = np.copy(population)
for i, neighbors in enumerate(network):
if np.random.rand() < mutation_rate:
# Apply mutation with a smaller range
mutation = np.random.uniform(-0.05, 0.05, population.shape[1])
new_population[i] += mutation
return new_population
# Main function implementing Immune Network Theory
def immune_network_theory(solution_size=n_features, pop_size=50, num_neighbors=5, mutation_rate=0.1, generations=50):
population = generate_initial_population(pop_size, solution_size)
best_fitness_per_generation = [] # Track the best fitness in each generation
for generation in range(generations):
fitness = np.array([fitness_function(ind, X, y) for ind in population])
network = create_immune_network(population, fitness, num_neighbors)
new_population = update_network(network, population, fitness, mutation_rate)
# Evaluate the fitness of the new population
fitness_new = np.array([fitness_function(ind, X, y) for ind in new_population])
# Combine the old and new populations
combined_population = np.vstack((population, new_population))
combined_fitness = np.hstack((fitness, fitness_new))
# Select the best individuals
best_indices = np.argsort(combined_fitness)[:pop_size]
population = combined_population[best_indices]
fitness = combined_fitness[best_indices]
# Track the best fitness of this generation
best_fitness = np.min(fitness)
best_fitness_per_generation.append(best_fitness)
# Stop early if the fitness is good enough
if best_fitness < 0.01:
print(f"Optimal solution found in {generation + 1} generations.")
break
# Plot the fitness improvement over generations
plt.figure(figsize=(10, 6))
plt.plot(best_fitness_per_generation, marker='o', color='blue', label='Best Fitness per Generation')
plt.xlabel('Generations')
plt.ylabel('Mean Squared Error')
plt.title('Fitness Improvement Over Generations')
plt.grid(True)
plt.show()
# Return the best solution found
best_solution = population[np.argmin(fitness)]
return best_solution
# Example Usage
best_solution = immune_network_theory()
print("Best solution found (economic indicators weights):", best_solution)
print("Mean Squared Error at best solution:", fitness_function(best_solution, X, y))
# Plot the predicted vs. actual values using the best solution
model = LinearRegression()
model.coef_ = best_solution
predictions = X @ model.coef_
plt.figure(figsize=(8, 6))
plt.scatter(y, predictions, c='blue', label='Predicted vs Actual')
plt.plot([min(y), max(y)], [min(y), max(y)], 'r--', label='Ideal Fit')
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Stock Price Prediction with INT')
plt.legend()
plt.grid(True)
plt.show()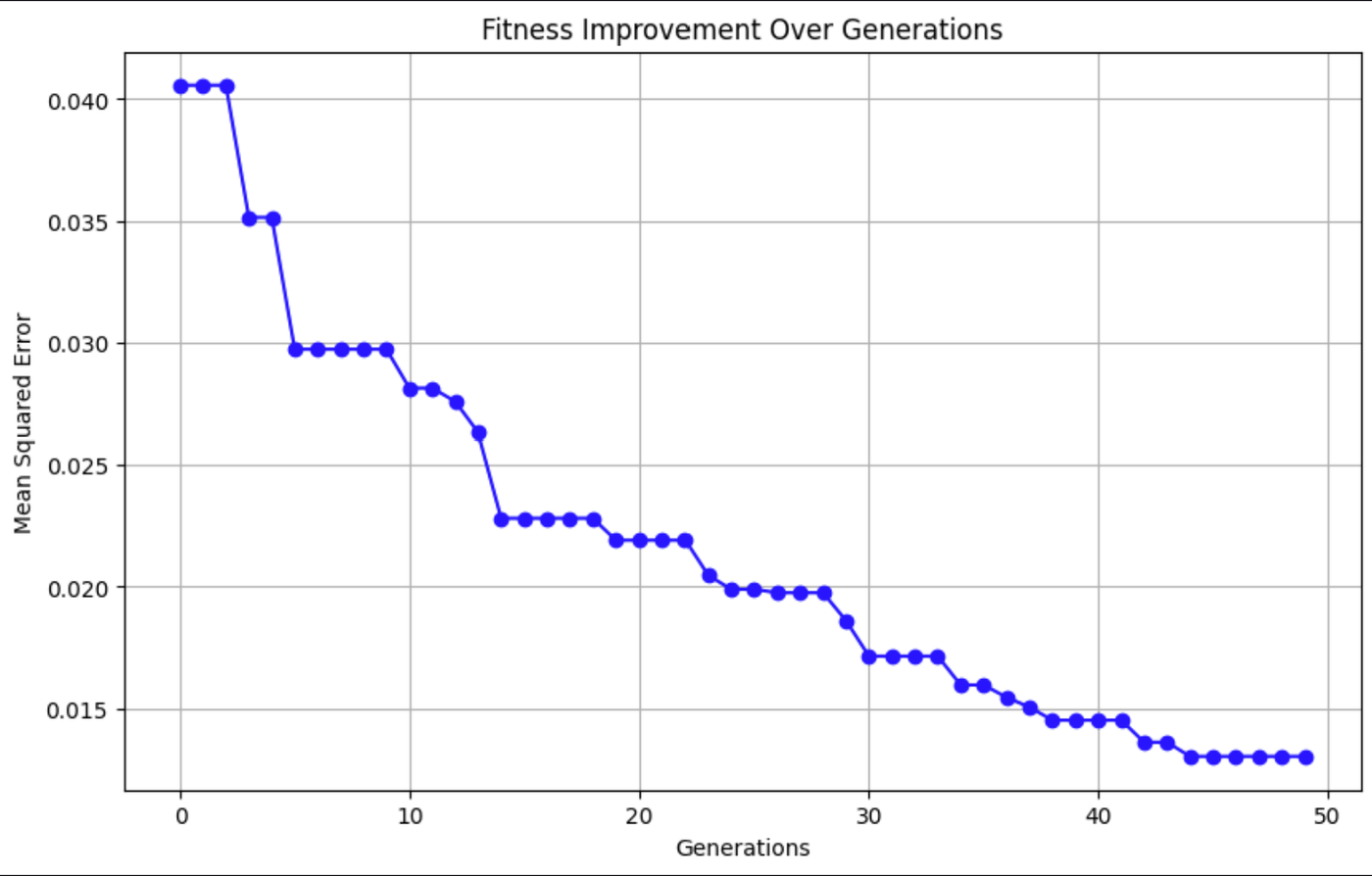
Este gráfico muestra que el Error Cuadrático Medio (ECM) disminuye con el tiempo, lo que indica que las predicciones del modelo son cada vez más precisas.
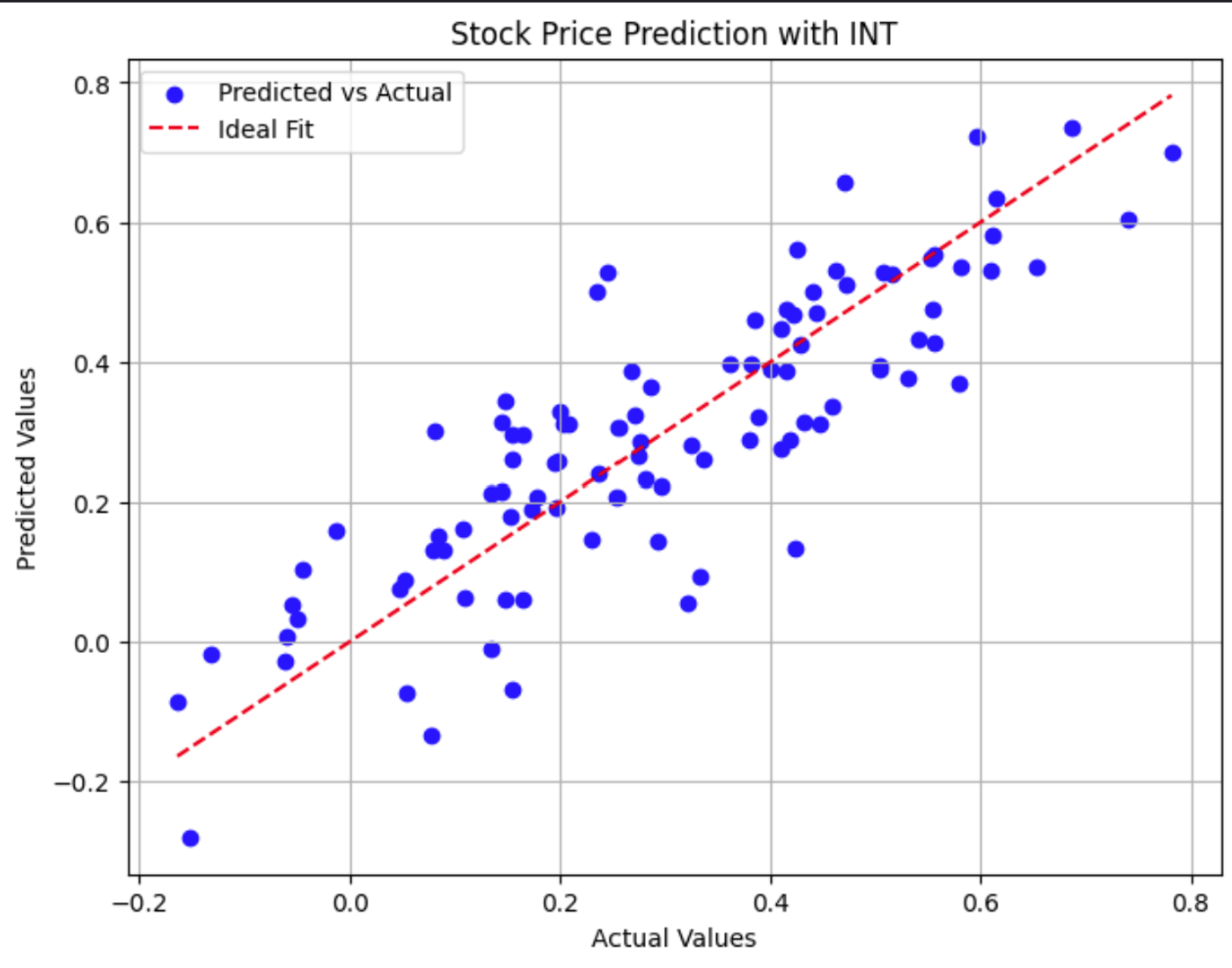
Este gráfico de dispersión compara los precios reales de las acciones con las predicciones del modelo. Los puntos más cercanos a la línea discontinua roja muestran predicciones más precisas.
El AIS es una de las muchas técnicas de aprendizaje automático que se inspiran en la biología.
Las redes neuronales están inspiradas en el cerebro humano y destacan en el aprendizaje a partir de grandes conjuntos de datos. Se utilizan para tareas como el reconocimiento de imágenes y el procesamiento del lenguaje natural. Se basan en un amplio entrenamiento con grandes cantidades de datos para ajustar los pesos de las neuronas interconectadas.
En cambio, los sistemas inmunitarios artificiales se centran en la adaptabilidad y la resolución descentralizada de problemas, sin necesitar grandes conjuntos de datos. Los SIA imitan la capacidad del sistema inmunitario para reconocer y responder a nuevos retos en tiempo real, lo que los hace adecuados para entornos dinámicos en los que la adaptación rápida es crucial.
Los algoritmos genéticos, inspirados en la evolución natural, son eficaces para optimizar problemas complejos haciendo evolucionar una población de soluciones mediante selección, cruce y mutación. Este proceso es similar al CSA.
Sin embargo, mientras que los algoritmos genéticos se basan en operadores genéticos para explorar el espacio de soluciones, la CSA adapta las soluciones imitando las respuestas inmunitarias, lo que ofrece flexibilidad para enfrentarse a retos nuevos e inesperados. Los SIA, incluidos los CSA, son especialmente eficaces en entornos dinámicos en los que la adaptación rápida y el aprendizaje continuo son cruciales.
Puedes leer más sobre algoritmos genéticos en Algoritmo genético: Guía completa con implementación en Python.
Los algoritmos de inteligencia de enjambre se inspiran en el comportamiento colectivo de organismos sociales como las hormigas y las abejas. Utilizan sistemas descentralizados e interacciones sencillas entre agentes para lograr una optimización global compleja.
Esto es similar, en espíritu, a INT. Ambos enfoques se centran en mantener la diversidad y la adaptabilidad dentro de un sistema para abordar los problemas de optimización. Mientras que la inteligencia de enjambre hace hincapié en las interacciones basadas en agentes, la INT aprovecha mecanismos similares a las respuestas inmunitarias, ofreciendo métodos complementarios para la resolución dinámica de problemas.
Puedes leer más sobre los algoritmos de inteligencia de enjambre en Algoritmos de inteligencia de enjambre: Tres implementaciones de Python.
Los sistemas inmunitarios artificiales son prometedores para resolver problemas complejos en diversos ámbitos. Los investigadores trabajan para mejorar estos sistemas y hacerlos aún más útiles.
Un área que están explorando los investigadores es cómo crear modelos híbridos que combinen los SIA con otras técnicas de inteligencia computacional. La esperanza es que estos modelos híbridos sean más robustos y versátiles.
Estos enfoques híbridos pretenden utilizar los puntos fuertes de cada método, como la capacidad de adaptación de los SIA y los potentes mecanismos de aprendizaje de las redes neuronales. Para más información, consulta Sistemas inmunitarios artificiales.
Otra área de investigación activa consiste en aplicar los SIA a nuevos dominios. Aunque tradicionalmente se ha utilizado en ciberseguridad y optimización, el AIS se está explorando ahora en campos como la robótica, la bioinformática e incluso la modelización financiera. La adaptabilidad y la naturaleza descentralizada del SIA lo convierten en un candidato prometedor para resolver problemas en estos entornos dinámicos y a menudo impredecibles. Para más información, te animo a que leas Informática inspirada en la naturaleza: Alcance y Aplicaciones de los Sistemas Inmunes Artificiales al Análisis y Diagnóstico de Problemas Complejos.
Los modelos AIS no sólo ofrecen técnicas computacionales mejoradas, sino que también pueden contribuir a nuestra comprensión de los sistemas inmunitarios reales. Hacen avanzar las estrategias de inmunoterapia para enfermedades como el cáncer y los trastornos autoinmunitarios. Echa un vistazo a esta colaboración entre la Clínica Cleveland e IBM para saber más.
Los sistemas inmunitarios artificiales ofrecen un enfoque único para resolver problemas complejos inspirándose en el sistema inmunitario humano. Al emular procesos biológicos como el reconocimiento de patrones, la adaptación y la memoria, los SIA proporcionan soluciones versátiles en campos que van desde la ciberseguridad a la optimización.
Aprende a trabajar con LLMs en Python directamente en tu navegador

Aprende IA con estos cursos
programa
programa
Curso
blog
Natasha Al-Khatib
14 min
blog
Abid Ali Awan
7 min
Tutorial
Bex Tuychiev
Tutorial
Natassha Selvaraj
Tutorial
Arunn Thevapalan


