
Cursus
Principes fondamentaux de l'IA
10 h
Imaginez un système capable d'identifier et de neutraliser des menaces qu'il n'a jamais rencontrées auparavant, tout en se souvenant des envahisseurs passés pour les repousser plus efficacement. C'est ce que fait votre système immunitaire tous les jours.
Imaginez maintenant que vous appliquiez ce même niveau d'intelligence à la résolution de problèmes informatiques complexes. Lessystèmes immunitaires artificiels (SIA) de nous permettent d'atteindre cet objectif.
Les systèmes immunitaires artificiels sont de puissants modèles informatiques inspirés de la capacité du système immunitaire humain à protéger l'organisme contre les agressions.
Le système immunitaire est le mécanisme de défense de notre organisme, conçu pour reconnaître et neutraliser les menaces telles que les bactéries, les virus et les champignons. Il le fait par l'intermédiaire de quelques acteurs clés : les anticorps, les cellules b et les cellules t.
Les anticorps sont les unités d'identification du système immunitaire. Ces protéines spécialisées reconnaissent et s'attachent à des substances étrangères spécifiques, appelées antigènes, les étiquetant comme des menaces. Chaque anticorps est unique, conçu pour correspondre à un antigène particulier, comme une serrure et une clé.
Les cellules B sont les usines qui produisent les anticorps. Elles sont également impliquées dans la création des cellules de la mémoire. Ils aident l'organisme à réagir plus rapidement à des antigènes déjà rencontrés en se souvenant des anticorps qui ont été utiles la dernière fois.
Les lymphocytes T sont les garants du système immunitaire. Ils détectent et détruisent les cellules signalées par les anticorps comme étant infectées ou dangereuses, ce qui permet de neutraliser rapidement la menace.
L'une des caractéristiques les plus remarquables du système immunitaire est sa capacité à évoluer et à améliorer de nouveaux anticorps au fil du temps. Lorsqu'il est confronté à un nouvel agent pathogène, le système immunitaire ne réagit pas qu'une seule fois. Il affine en permanence son approche, créant des anticorps plus puissants et plus efficaces pour faire face à la menace.
Les systèmes immunitaires artificiels (SIA) sont la mise en œuvre de ces principes biologiques dans des algorithmes. L'AIS imite les fonctions du système immunitaire dans la résolution de problèmes.
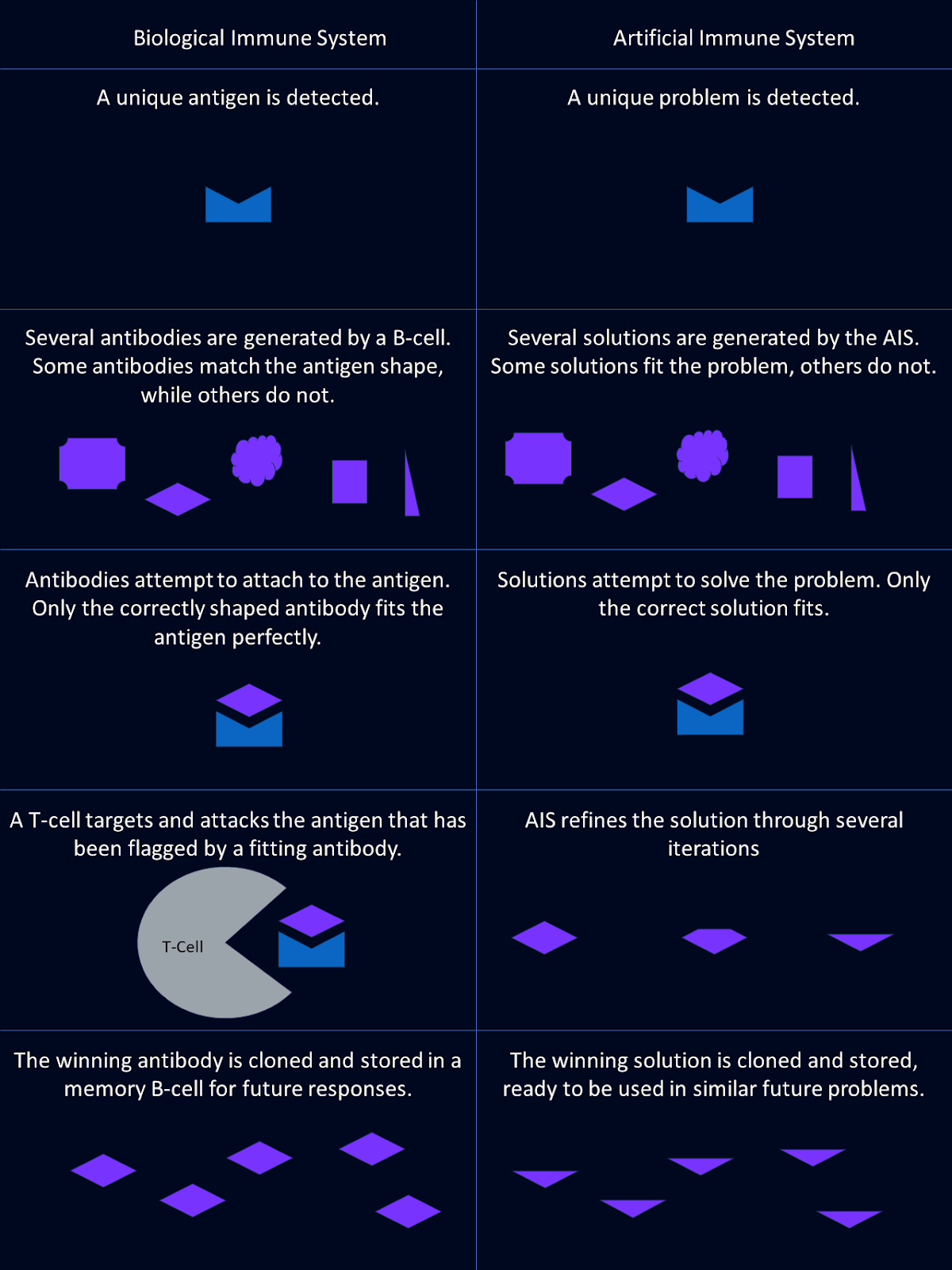
Dans l'AIS, les antigènes représentent les problèmes ou les défis à relever. Cela peut aller de la détection d'anomalies dans les données à l'optimisation d'une solution.
Les anticorps dans l'AIS sont des solutions potentielles à ces problèmes. Tout comme les anticorps biologiques qui reconnaissent des antigènes spécifiques, l'AIS développe des solutions potentielles adaptées à des défis spécifiques.
Le processus des cellules B dans l'AIS reflète la façon dont les systèmes biologiques génèrent la diversité et la mémoire. Les algorithmes AIS utilisent diverses solutions candidates et les affinent au fil du temps. Ils tirent des enseignements des problèmes rencontrés précédemment pour améliorer leurs performances futures.
Les systèmes immunitaires artificiels n'ont pas d'analogue direct aux cellules T, mais ils intègrent des mécanismes d'évaluation qui jouent un rôle similaire. Ces processus permettent d'éliminer les solutions inefficaces et d'affiner celles qui sont plus performantes.
Les EAE utilisent des principes évolutifs, tels que la mutation et la sélection, pour améliorer en permanence la qualité des solutions.
Les systèmes immunitaires artificiels intègrent des concepts clés tels que l'interaction anticorps-antigène, la sélection clonale, la sélection négative et la théorie des réseaux immunitaires.
Le concept d'interaction anticorps-antigène fait partie intégrante des systèmes immunitaires artificiels. Ce processus s'inspire directement de la manière dont notre système immunitaire réagit aux menaces. Considérez les anticorps comme des solutions potentielles à un problème et les antigènes comme les problèmes ou les défis eux-mêmes.
Dans le monde biologique, les anticorps sont des protéines qui s'accrochent aux antigènes et les neutralisent. Dans l'AIS, un anticorps représente une solution candidate à un problème informatique, tandis que l'antigène représente le problème à résoudre.
L'algorithme AIS fait évoluer une population de ces anticorps pour qu'ils reconnaissent et neutralisent efficacement les antigènes correspondants. Au fil du temps, l'algorithme affine ces anticorps, en se concentrant sur les solutions les plus efficaces.
L'algorithme de sélection clonale (CSA) s'inspire d'un autre processus essentiel de notre système immunitaire. Lorsque l'organisme détecte un antigène, il ne déploie pas n'importe quelles cellules immunitaires au hasard ; il sélectionne celles qui peuvent reconnaître spécifiquement l'envahisseur. Ces cellules sélectionnées sont ensuite clonées en grand nombre pour constituer une défense efficace.
Ces clones subissent des mutations, introduisant de légères variations qui augmentent la diversité de la réponse immunitaire. Ainsi, même si l'agent pathogène évolue, le système immunitaire peut s'adapter et réagir efficacement.
De même, l'algorithme de sélection clonale sélectionne les solutions les plus prometteuses et en crée plusieurs copies ou "clones".
Ces clones sont ensuite soumis à des mutations, ce qui génère un ensemble varié de solutions potentielles. Les clones les plus performants sont conservés et le processus se répète, améliorant progressivement la qualité des solutions. Cet algorithme est particulièrement puissant dans les tâches d'optimisation, où l'objectif est de trouver la solution la plus efficace parmi de nombreuses possibilités.
La CSA est fréquemment utilisée pour résoudre des problèmes d'optimisation. Par exemple, dans l'aérospatiale, elle peut aider à concevoir des structures efficaces comme les ailes d'avion en améliorant les propriétés aérodynamiques sur plusieurs itérations.
Dans le domaine de l'imagerie médicale, la CSA peut améliorer la clarté des images ou détecter des motifs irréguliers dans des environnements bruyants, ce qui la rend utile pour les examens IRM ou la détection des tumeurs.
Le système immunitaire humain doit faire la distinction entre les cellules de l'organisme et les envahisseurs étrangers. C'est là que l'algorithme de sélection négative (NSA) entre en jeu. Les cellules immunitaires qui réagissent trop fortement aux cellules de l'organisme sont éliminées. Cela permet d'éviter que le système immunitaire ne s'attaque par erreur à lui-même (provoquant une maladie auto-immune).
La NSA imite ce processus pour identifier les anomalies ou les valeurs aberrantes dans les données. L'algorithme génère un ensemble de modèles, appelés détecteurs, conçus pour reconnaître les modèles normaux dans les données. Tous les détecteurs qui correspondent étroitement aux données normales sont éliminés, ne laissant que ceux qui ne correspondent pas aux modèles typiques. Les détecteurs restants sont ensuite utilisés pour contrôler les nouvelles données.
Si ces détecteurs atypiques repèrent un nouveau point de données, ils l'indiquent comme une anomalie. Ce phénomène est similaire à la manière dont le système immunitaire détecte les envahisseurs étrangers. Cette méthode est très efficace dans des domaines comme la cybersécuritéoù la détection de modèles inhabituels est essentielle pour identifier les menaces potentielles.
La NSA est bien adaptée aux systèmes de détection d'intrusion qui surveillent le trafic réseau et identifient les activités malveillantes en comparant les schémas normaux avec ceux des menaces potentielles.
Les ASN peuvent également être utilisées pour détecter des défauts mécaniques ou opérationnels dans des systèmes complexes tels que les centrales électriques.
La théorie du réseau immunitaire (INT) étend le concept de l'AIS en modélisant non seulement l'interaction entre les anticorps et les antigènes, mais aussi les interactions entre les anticorps eux-mêmes.
Dans le système immunitaire biologique, les anticorps ne fonctionnent pas de manière isolée. Ils communiquent et s'influencent mutuellement, créant un réseau dynamique de réponses plus robustes et plus adaptables. Cette interaction en réseau aide le système immunitaire à maintenir un équilibre, ce qui lui permet de répondre efficacement à un large éventail de menaces sans réagir de manière excessive à une seule d'entre elles.
INT est utilisé pour modéliser des interactions et des dépendances complexes entre différentes solutions. Cela permet à l'algorithme de prendre en compte un éventail plus large de réponses possibles, ce qui conduit à des stratégies de résolution de problèmes plus sophistiquées.
En simulant la manière dont les anticorps s'influencent mutuellement, l'AIS peut explorer simultanément plusieurs voies menant à une solution, améliorant ainsi sa capacité à trouver des solutions optimales dans des environnements complexes et dynamiques. Cette théorie est à la base de certains des algorithmes AIS les plus avancés, ce qui en fait un outil puissant pour relever des défis informatiques complexes.
La théorie des réseaux immunitaires peut être appliquée au contrôle des essaims robotiques. Les interactions entre les robots imitent les interactions entre les anticorps, ce qui permet un comportement coordonné et la résolution de problèmes dans des tâches telles que les missions de recherche et de sauvetage.
En finance, les modèles de réseaux immunitaires peuvent être utilisés pour étudier les interactions entre divers indicateurs économiques, ce qui permet de prédire les tendances du marché ou de détecter des anomalies financières.
Python est souvent le langage de choix lors de la création de systèmes immunitaires artificiels en raison de ses bibliothèques étendues et de sa facilité d'utilisation.
L'algorithme de sélection clonale s'inspire du processus biologique selon lequel les cellules immunitaires qui reconnaissent avec succès une menace sont clonées puis mutées pour améliorer la réponse immunitaire. Dans l'AIS, ces "cellules immunitaires" sont des solutions candidates à un problème, et l'objectif est de faire évoluer ces solutions pour trouver la meilleure.
Voici comment vous pouvez mettre en œuvre une version simple de l'ASC en Python :
Résolvons un problème d'optimisation de fonction à l'aide de CSA. Nous allons optimiser une fonction de référence bien connue, la fonction de Rastrigin. Cette fonction peut être utilisée pour tester les algorithmes d'optimisation en raison de ses nombreux minima locaux.
Dans le code ci-dessous, nous utilisons un CSA pour trouver les minima globaux de la fonction :
import numpy as np
import matplotlib.pyplot as plt
# Define the Rastrigin function
def rastrigin(X):
n = len(X)
return 10 * n + np.sum(X**2 - 10 * np.cos(2 * np.pi * X))
# Generate the initial population of potential solutions
def generate_initial_population(pop_size, solution_size):
return np.random.uniform(-5.12, 5.12, size=(pop_size, solution_size)) # Initialize within the search space of Rastrigin
# Evaluate the fitness of each individual in the population (lower is better)
def evaluate_population(population):
return np.array([rastrigin(individual) for individual in population])
# Select the best candidates from the population based on their fitness
def select_best_candidates(population, fitness, num_candidates):
indices = np.argsort(fitness)
return population[indices[:num_candidates]], fitness[indices[:num_candidates]]
# Clone the best candidates multiple times
def clone_candidates(candidates, num_clones):
return np.repeat(candidates, num_clones, axis=0)
# Introduce random mutations to the cloned candidates to explore new solutions
def mutate_clones(clones, mutation_rate):
mutations = np.random.rand(*clones.shape) < mutation_rate
clones[mutations] += np.random.uniform(-1, 1, np.sum(mutations)) # Mutate by adding a random value
return clones
# Main function implementing the Clonal Selection Algorithm
def clonal_selection_algorithm(solution_size=2, pop_size=100, num_candidates=10, num_clones=10, mutation_rate=0.05, generations=100):
population = generate_initial_population(pop_size, solution_size)
best_fitness_per_generation = [] # Track the best fitness in each generation
for generation in range(generations):
fitness = evaluate_population(population)
candidates, candidate_fitness = select_best_candidates(population, fitness, num_candidates)
clones = clone_candidates(candidates, num_clones)
mutated_clones = mutate_clones(clones, mutation_rate)
clone_fitness = evaluate_population(mutated_clones)
# Replace the worst individuals in the population with the new mutated clones
population[:len(mutated_clones)] = mutated_clones
fitness[:len(clone_fitness)] = clone_fitness
# Track the best fitness of this generation
best_fitness = np.min(fitness)
best_fitness_per_generation.append(best_fitness)
# Stop early if we've found a solution close to the global minimum
if best_fitness < 1e-6:
print(f"Optimal solution found in {generation + 1} generations.")
break
# Plot the fitness improvement over generations
plt.figure(figsize=(10, 6))
plt.plot(best_fitness_per_generation, marker='o', color='blue', label='Best Fitness per Generation')
plt.xlabel('Generations')
plt.ylabel('Fitness (Rastrigin Function Value)')
plt.title('Fitness Improvement Over Generations')
plt.grid(True)
plt.show()
# Return the best solution found (the one with the lowest fitness score)
best_solution = population[np.argmin(fitness)]
return best_solution
# Example Usage
best_solution = clonal_selection_algorithm(solution_size=2) # Using 2D Rastrigin function
print("Best solution found:", best_solution)
print("Rastrigin function value at best solution:", rastrigin(best_solution))
# Plot the surface of the Rastrigin function with the best solution found
x = np.linspace(-5.12, 5.12, 200)
y = np.linspace(-5.12, 5.12, 200)
X, Y = np.meshgrid(x, y)
Z = 10 * 2 + (X**2 - 10 * np.cos(2 * np.pi * X)) + (Y**2 - 10 * np.cos(2 * np.pi * Y))
plt.figure(figsize=(8, 6))
plt.contourf(X, Y, Z, levels=50, cmap='viridis')
plt.colorbar(label='Function Value')
plt.scatter(best_solution[0], best_solution[1], c='red', s=100, label='Best Solution')
plt.title('Rastrigin Function Optimization with CSA')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()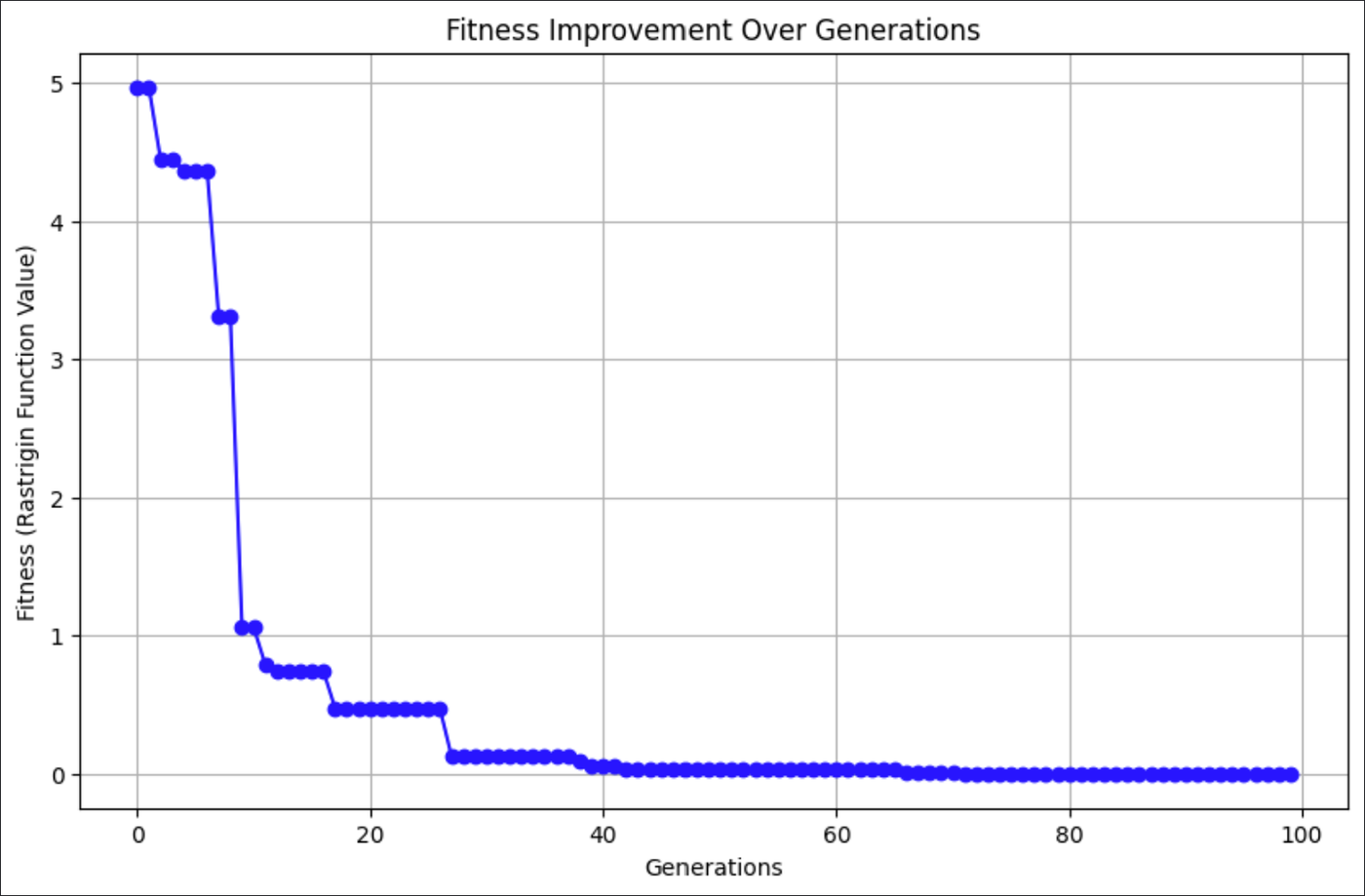
Le graphique ci-dessus montre comment l'ASC a trouvé de meilleures solutions à la fonction Rastrigin à chaque génération.
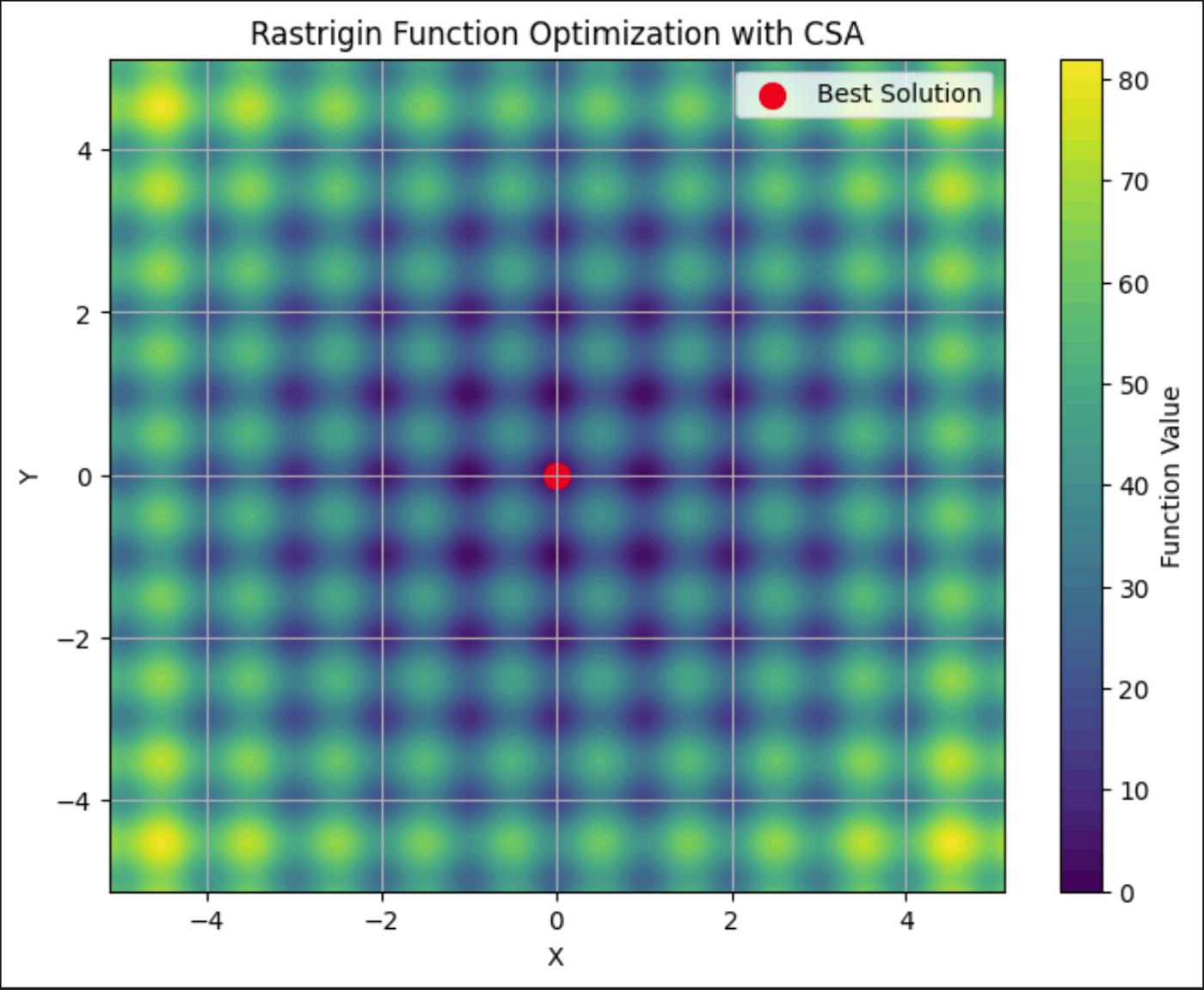
Ce graphique montre le tracé de Rastrigin, mettant en évidence ses nombreux minima locaux. La meilleure solution, le point rouge au milieu, est la solution finale trouvée par l'ASC.
La NSA est particulièrement utile pour les tâches de détection d'anomalies. Cet algorithme simule la manière dont le système immunitaire fait la distinction entre les cellules propres à l'organisme et les envahisseurs étrangers. Dans une ANS, vous générez un ensemble de détecteurs qui ne correspondent pas aux modèles de données normaux. Ces détecteurs sont ensuite utilisés pour surveiller les nouvelles données, en signalant tout ce qui semble anormal.
Voici un aperçu de la manière de créer une ASN :
Voyons comment cela fonctionne à l'aide d'un ensemble fictif de transactions. Dans cet exemple, nous générons des transactions normales centrées autour de deux groupes et des transactions frauduleuses dispersées de manière aléatoire. Nous utiliserons un algorithme de sélection négative, dans lequel les détecteurs de fraude sont dispersés dans l'espace des caractéristiques afin d'identifier les anomalies en fonction de leur proximité avec ces détecteurs.
import numpy as np
import matplotlib.pyplot as plt
# Generate a synthetic dataset
np.random.seed()
# Parameters for bimodal distribution
num_normal_points = 80 # total number of normal transactions
num_points_per_cluster = num_normal_points // 2 # number of points in each cluster
# Generate normal transactions for two clusters
cluster1_center = [2, 2]
cluster2_center = [8, 8]
# Generate points around the first cluster center
normal_cluster1 = np.random.normal(loc=cluster1_center, scale=0.5, size=(num_points_per_cluster, 2))
# Generate points around the second cluster center
normal_cluster2 = np.random.normal(loc=cluster2_center, scale=0.5, size=(num_points_per_cluster, 2))
# Combine clusters into one dataset
normal_transactions = np.vstack([normal_cluster1, normal_cluster2])
# Define random distribution for fraudulent transactions
num_fraud_points = 5 # number of fraudulent transactions
fraudulent_transactions = np.random.uniform(low=0, high=10, size=(num_fraud_points, 2))
# Combine into one dataset
data = np.vstack([normal_transactions, fraudulent_transactions])
labels = np.array([0] * len(normal_transactions) + [1] * len(fraudulent_transactions))
# Function to generate detectors (random points) that don't match any of the normal data
def generate_detectors(normal_data, num_detectors, detector_size):
detectors = []
while len(detectors) < num_detectors:
detector = np.random.rand(detector_size) * 10 # Scale to cover the data range
if not any(np.allclose(detector, pattern, atol=0.5) for pattern in normal_data):
detectors.append(detector)
return np.array(detectors)
# Function to detect anomalies (points in the data that are close to any detector)
def detect_anomalies(detectors, data, threshold=0.5):
anomalies = []
for point in data:
if any(np.linalg.norm(detector - point) < threshold for detector in detectors):
anomalies.append(point)
return anomalies
# Generate detectors that do not match the normal data
detectors = generate_detectors(normal_transactions, num_detectors=300, detector_size=2)
# Detect anomalies within the entire dataset using the detectors
anomalies = detect_anomalies(detectors, data)
print("Number of anomalies detected:", len(anomalies))
# Convert anomalies to a numpy array for visualization
anomalies = np.array(anomalies) if anomalies else np.array([])
# Define axis limits
x_min, x_max = 0, 10
y_min, y_max = -1, 11
# Visualize the dataset, detectors, and anomalies
plt.figure(figsize=(14, 6))
# Plot the normal transactions and fraudulent transactions
plt.subplot(1, 2, 1)
plt.scatter(normal_transactions[:, 0], normal_transactions[:, 1], color='red', marker='x', label='Normal Transactions')
plt.scatter(fraudulent_transactions[:, 0], fraudulent_transactions[:, 1], color='green', marker='o', label='Fraudulent Transactions')
plt.scatter(detectors[:, 0], detectors[:, 1], color='blue', marker='o', alpha=0.5, label='Detectors')
if len(anomalies) > 0:
plt.scatter(anomalies[:, 0], anomalies[:, 1], color='yellow', marker='*', s=100, label='Detected Anomalies')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Fraud Detection Using Negative Selection Algorithm (NSA)')
plt.legend(loc='lower right')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.grid(False)
# Create a grid of points to classify
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100))
grid_points = np.c_[xx.ravel(), yy.ravel()]
# Classify grid points
decision = np.array([any(np.linalg.norm(detector - point) < 0.5 for detector in detectors) for point in grid_points])
decision = decision.reshape(xx.shape)
# Plot the decision boundary
plt.subplot(1, 2, 2)
plt.contourf(xx, yy, decision, cmap='coolwarm', alpha=0.3)
plt.scatter(normal_transactions[:, 0], normal_transactions[:, 1], color='red', marker='x', label='Normal Transactions')
plt.scatter(fraudulent_transactions[:, 0], fraudulent_transactions[:, 1], color='green', marker='o', label='Fraudulent Transactions')
plt.scatter(detectors[:, 0], detectors[:, 1], color='blue', marker='o', alpha=0.5, label='Detectors')
if len(anomalies) > 0:
plt.scatter(anomalies[:, 0], anomalies[:, 1], color='yellow', marker='*', s=100, label='Detected Anomalies')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Decision Boundary Visualization')
plt.legend(loc='lower right')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.grid(False)
# Show the plot
plt.show()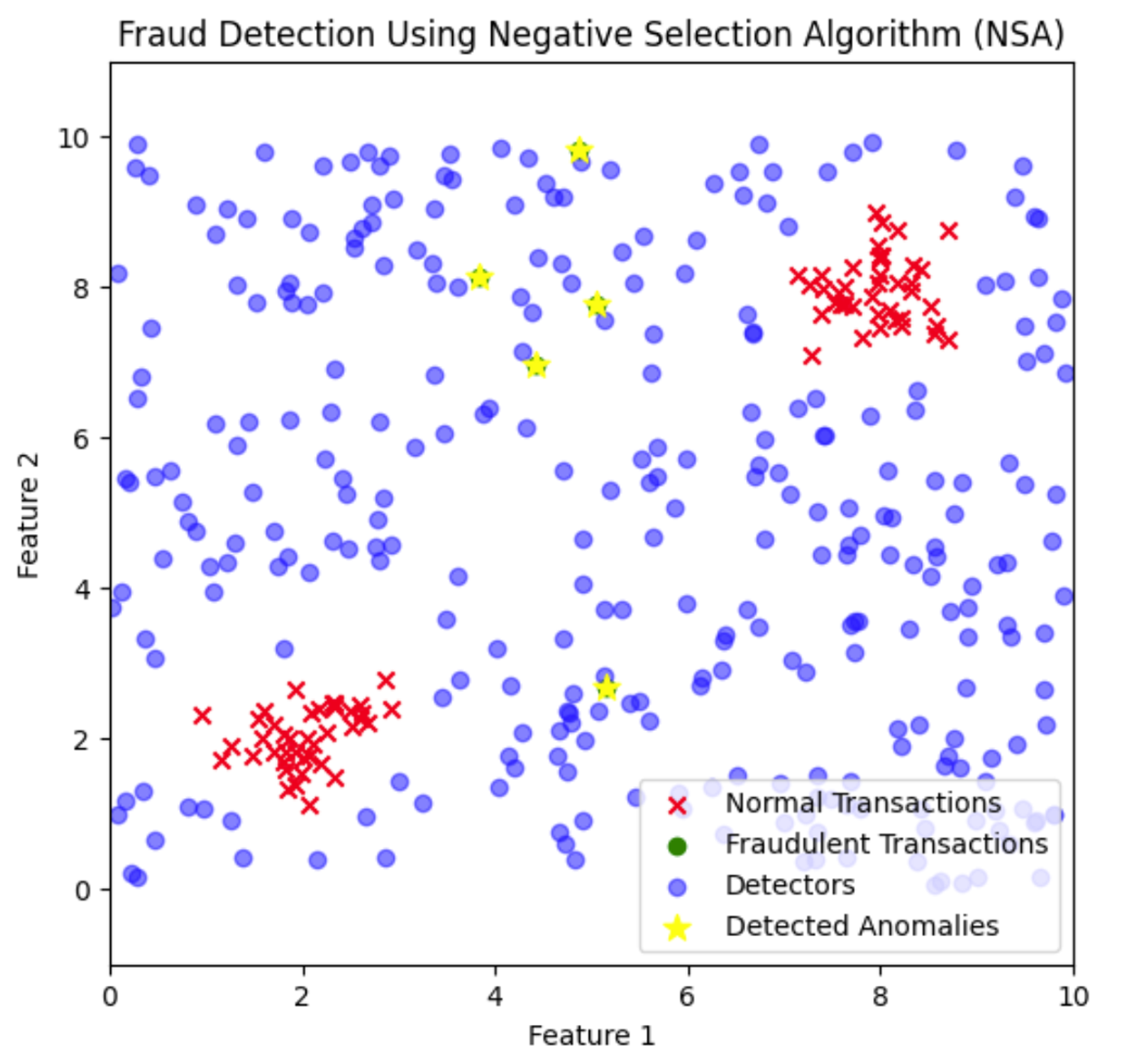
Dans ce cas, les détecteurs de fraude sont répartis dans l'espace des caractéristiques afin de couvrir les zones où les transactions normales n'apparaissent pas. Les transactions frauduleuses qui se rapprochent de ces détecteurs sont identifiées et signalées comme des anomalies.
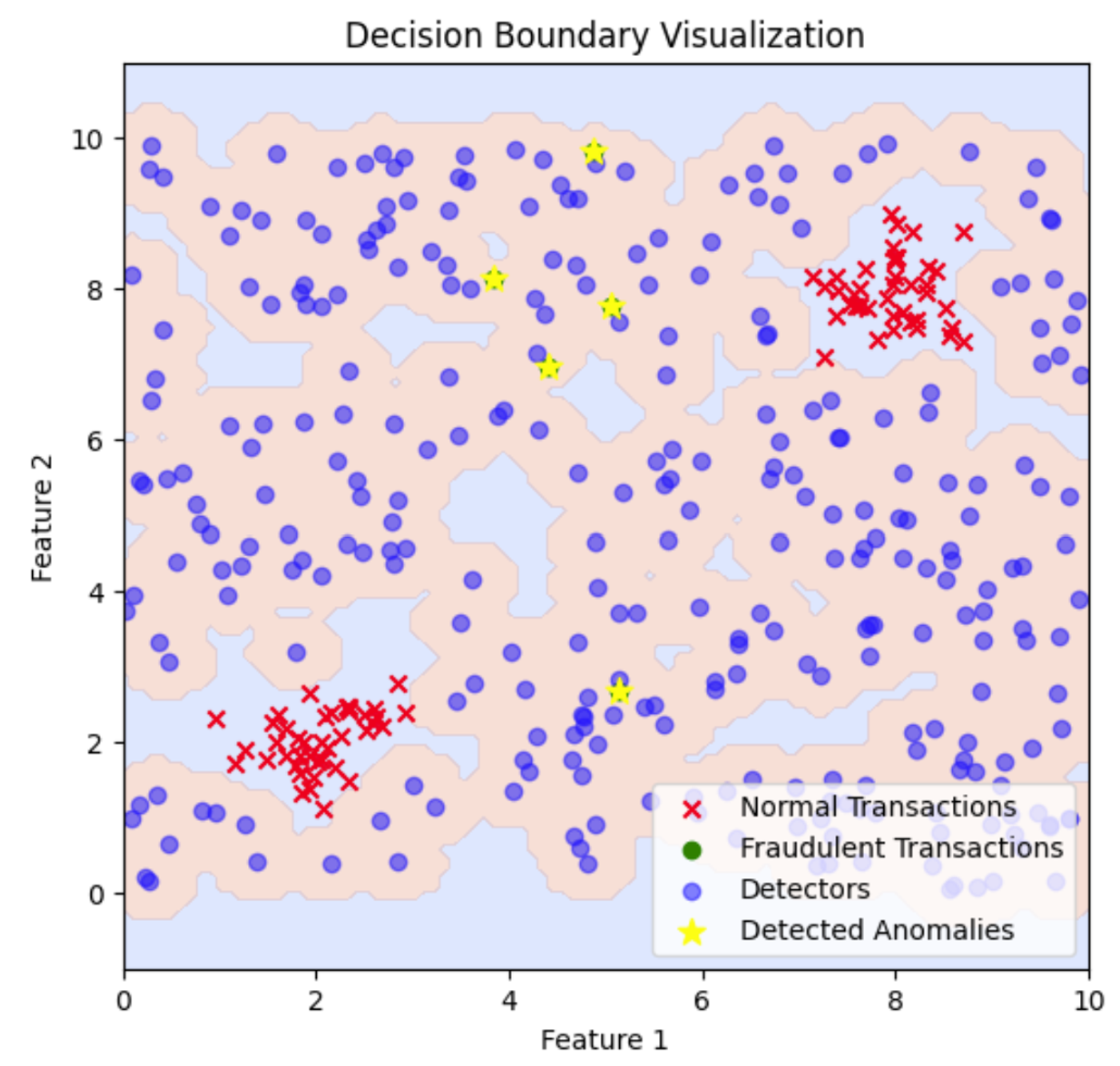
Ce graphique illustre la limite de décision créée par les détecteurs de fraude. Les régions ombrées représentent les zones classées comme anormales sur la base de la proximité des détecteurs, mettant en évidence les transactions frauduleuses détectées par rapport aux transactions normales. Pour ajuster la limite de décision et couvrir une zone plus ou moins étendue, vous pouvez modifier le seuil de distance utilisé pour la détection des anomalies, ce qui aura pour effet d'étendre ou de réduire les régions classées comme anormales.
INT s'inspire de l'idée que les réponses immunitaires ne sont pas seulement basées sur des anticorps individuels, mais aussi sur leur communication. Cette approche modélise le système immunitaire comme un réseau où les anticorps communiquent pour améliorer la réponse immunitaire globale. Dans ce contexte, chaque anticorps (solution) peut interagir avec d'autres pour influencer et affiner la recherche de solutions optimales.
Voici comment vous pouvez mettre en œuvre une version basique de INT en Python :
Utilisons INT pour prédire les tendances du marché boursier sur la base d'une série d'indicateurs économiques. Nous utiliserons un ensemble de données fictif dans lequel chaque solution représente une combinaison d'indicateurs permettant de prévoir les cours des actions.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Generate synthetic data for illustration
np.random.seed(42)
n_samples = 100
n_features = 5
X = np.random.rand(n_samples, n_features) # Random economic indicators
true_weights = np.array([0.5, -0.2, 0.3, 0.1, -0.1])
y = X @ true_weights + np.random.normal(0, 0.1, n_samples) # Stock prices with noise
# Define the fitness function
def fitness_function(solution, X, y):
model = LinearRegression()
model.coef_ = solution
predictions = X @ model.coef_
return mean_squared_error(y, predictions)
# Generate the initial population of potential solutions
def generate_initial_population(pop_size, solution_size):
return np.random.uniform(-1, 1, size=(pop_size, solution_size))
# Create the immune network
def create_immune_network(population, fitness, num_neighbors):
network = []
for i, individual in enumerate(population):
distances = np.linalg.norm(population - individual, axis=1)
neighbors = np.argsort(distances)[1:num_neighbors+1] # Exclude self
network.append(neighbors)
return network
# Update the immune network
def update_network(network, population, fitness, mutation_rate):
new_population = np.copy(population)
for i, neighbors in enumerate(network):
if np.random.rand() < mutation_rate:
# Apply mutation with a smaller range
mutation = np.random.uniform(-0.05, 0.05, population.shape[1])
new_population[i] += mutation
return new_population
# Main function implementing Immune Network Theory
def immune_network_theory(solution_size=n_features, pop_size=50, num_neighbors=5, mutation_rate=0.1, generations=50):
population = generate_initial_population(pop_size, solution_size)
best_fitness_per_generation = [] # Track the best fitness in each generation
for generation in range(generations):
fitness = np.array([fitness_function(ind, X, y) for ind in population])
network = create_immune_network(population, fitness, num_neighbors)
new_population = update_network(network, population, fitness, mutation_rate)
# Evaluate the fitness of the new population
fitness_new = np.array([fitness_function(ind, X, y) for ind in new_population])
# Combine the old and new populations
combined_population = np.vstack((population, new_population))
combined_fitness = np.hstack((fitness, fitness_new))
# Select the best individuals
best_indices = np.argsort(combined_fitness)[:pop_size]
population = combined_population[best_indices]
fitness = combined_fitness[best_indices]
# Track the best fitness of this generation
best_fitness = np.min(fitness)
best_fitness_per_generation.append(best_fitness)
# Stop early if the fitness is good enough
if best_fitness < 0.01:
print(f"Optimal solution found in {generation + 1} generations.")
break
# Plot the fitness improvement over generations
plt.figure(figsize=(10, 6))
plt.plot(best_fitness_per_generation, marker='o', color='blue', label='Best Fitness per Generation')
plt.xlabel('Generations')
plt.ylabel('Mean Squared Error')
plt.title('Fitness Improvement Over Generations')
plt.grid(True)
plt.show()
# Return the best solution found
best_solution = population[np.argmin(fitness)]
return best_solution
# Example Usage
best_solution = immune_network_theory()
print("Best solution found (economic indicators weights):", best_solution)
print("Mean Squared Error at best solution:", fitness_function(best_solution, X, y))
# Plot the predicted vs. actual values using the best solution
model = LinearRegression()
model.coef_ = best_solution
predictions = X @ model.coef_
plt.figure(figsize=(8, 6))
plt.scatter(y, predictions, c='blue', label='Predicted vs Actual')
plt.plot([min(y), max(y)], [min(y), max(y)], 'r--', label='Ideal Fit')
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Stock Price Prediction with INT')
plt.legend()
plt.grid(True)
plt.show()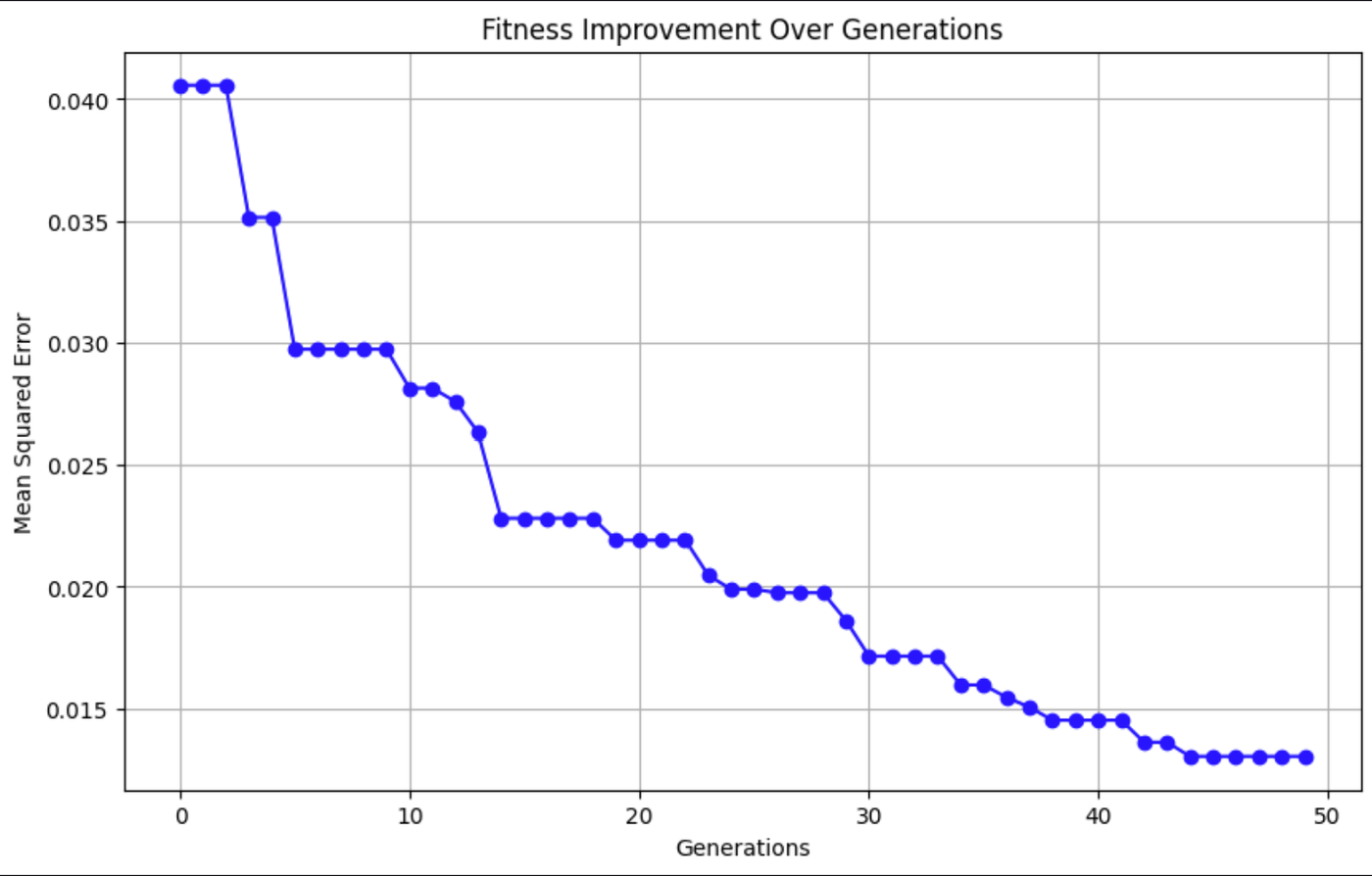
Ce graphique montre que l'erreur quadratique moyenne (EQM) diminue avec le temps, ce qui indique que les prédictions du modèle deviennent plus précises.
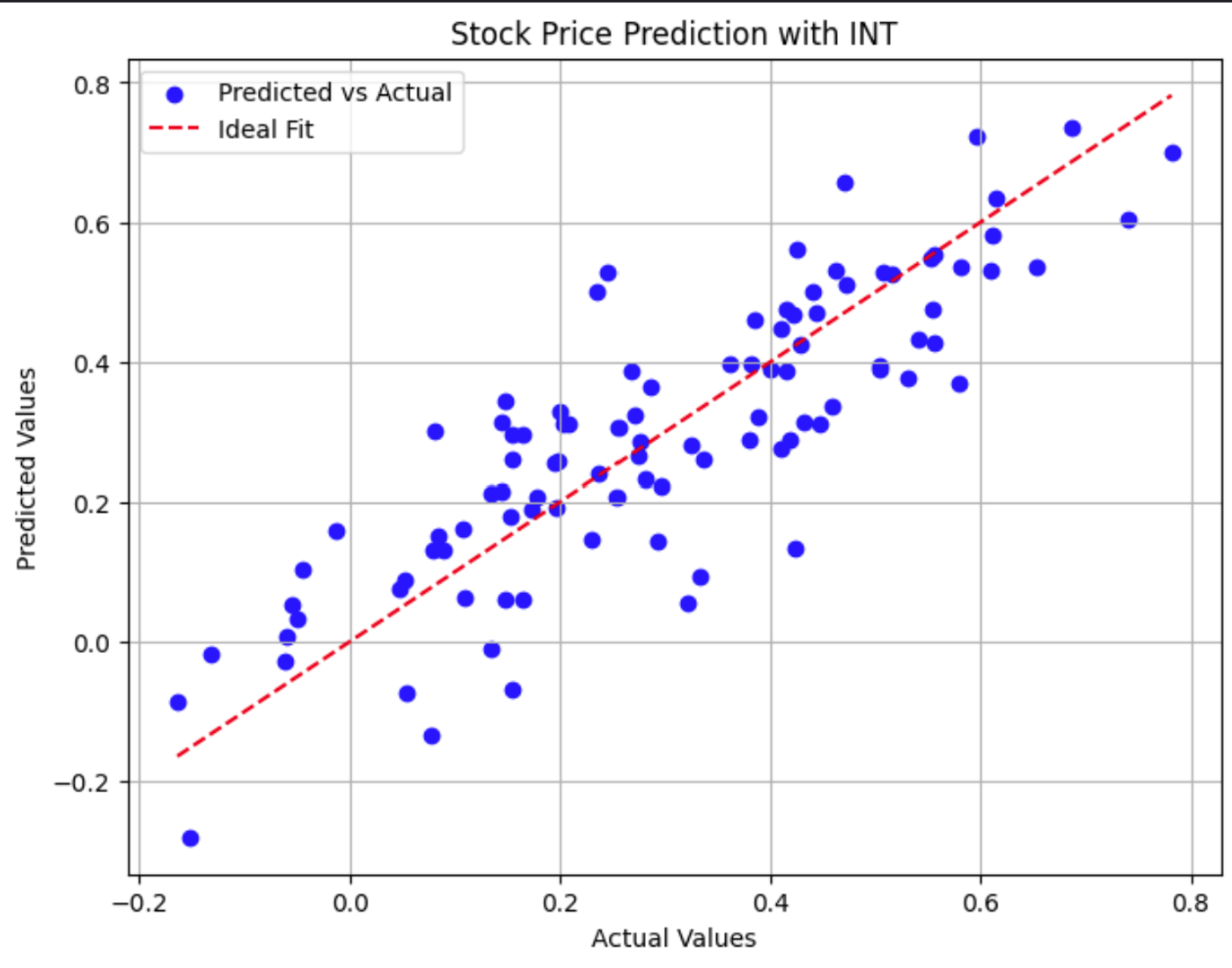
Ce diagramme de dispersion compare les cours réels des actions aux prévisions du modèle. Les points les plus proches de la ligne pointillée rouge indiquent des prévisions plus précises.
L'AIS est l'une des nombreuses techniques d'apprentissage automatique qui s'inspirent de la biologie.
Les réseaux neuronaux sont inspirés du cerveau humain et excellent dans l'apprentissage à partir de grands ensembles de données. Ils sont utilisés pour des tâches telles que la reconnaissance d'images et le traitement du langage naturel. Ils s'appuient sur un entraînement intensif avec de grandes quantités de données pour ajuster les poids des neurones interconnectés.
En revanche, les systèmes immunitaires artificiels se concentrent sur l'adaptabilité et la résolution décentralisée des problèmes sans nécessiter de grands ensembles de données. Les SIA imitent la capacité du système immunitaire à reconnaître et à répondre à de nouveaux défis en temps réel, ce qui les rend adaptés aux environnements dynamiques où l'adaptation rapide est cruciale.
Les algorithmes génétiques, inspirés de l'évolution naturelle, sont efficaces pour optimiser des problèmes complexes en faisant évoluer une population de solutions par sélection, croisement et mutation. Ce processus est similaire à celui de l'ASC.
Cependant, alors que les algorithmes génétiques s'appuient sur des opérateurs génétiques pour explorer l'espace des solutions, la CSA adapte les solutions en imitant les réponses immunitaires, ce qui offre une certaine souplesse pour faire face à des défis nouveaux et inattendus. Les EAE, y compris la CSA, sont particulièrement efficaces dans des environnements dynamiques où l'adaptation rapide et l'apprentissage continu sont essentiels.
Pour en savoir plus sur les algorithmes génétiques, consultez le site Genetic Algorithm : Guide complet avec implémentation Python.
Les algorithmes d'intelligence en essaim s'inspirent du comportement collectif d'organismes sociaux tels que les fourmis et les abeilles. Ils utilisent des systèmes décentralisés et des interactions simples entre agents pour parvenir à une optimisation globale complexe.
L'esprit est similaire à celui de l'INT. Les deux approches se concentrent sur le maintien de la diversité et de l'adaptabilité au sein d'un système afin de résoudre les problèmes d'optimisation. Alors que l'intelligence en essaim met l'accent sur les interactions basées sur les agents, l'INT exploite des mécanismes proches des réponses immunitaires, offrant des méthodes complémentaires pour la résolution dynamique des problèmes.
Pour en savoir plus sur les algorithmes d'intelligence en essaim, consultez le siteSwarm Intelligence Algorithms : Trois implémentations Python.
Les systèmes immunitaires artificiels sont prometteurs pour la résolution de problèmes complexes dans divers domaines. Les chercheurs s'efforcent d'améliorer ces systèmes pour les rendre encore plus utiles.
L'un des domaines explorés par les chercheurs est la création de modèles hybrides combinant l'AIS et d'autres techniques d'intelligence informatique. On espère que ces modèles hybrides seront plus robustes et plus polyvalents.
Ces approches hybrides visent à utiliser les points forts de chaque méthode, tels que les capacités d'adaptation de l'AIS et les puissants mécanismes d'apprentissage des réseaux neuronaux. Pour plus d'informations, consultez Systèmes immunitaires artificiels.
Un autre domaine de recherche actif consiste à appliquer l'AIS à de nouveaux domaines. Traditionnellement utilisés dans les domaines de la cybersécurité et de l'optimisation, les SIA sont désormais explorés dans des domaines tels que la robotique, la bio-informatique et même la modélisation financière. L'adaptabilité et la nature décentralisée de l'AIS en font un candidat prometteur pour résoudre les problèmes dans ces environnements dynamiques et souvent imprévisibles. Pour plus d'informations, je vous encourage à lire Nature-Inspired Computing : Portée et applications des systèmes immunitaires artificiels pour l'analyse et le diagnostic de problèmes complexes.
Les modèles AIS offrent non seulement des techniques de calcul améliorées, mais peuvent également contribuer à notre compréhension des systèmes immunitaires réels. Ils font progresser les stratégies d'immunothérapie pour des maladies telles que le cancer et les troubles auto-immuns. Jetez un coup d'œil à cette collaboration entre la Cleveland Clinic et IBM pour en savoir plus.
Les systèmes immunitaires artificiels offrent une approche unique pour résoudre des problèmes complexes en s'inspirant du système immunitaire humain. En émulant des processus biologiques tels que la reconnaissance des formes, l'adaptation et la mémoire, les SIA offrent des solutions polyvalentes dans des domaines allant de la cybersécurité à l'optimisation.
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours