
Lernpfad
Grundlagen der KI
10 Std.
Stell dir ein System vor, das Bedrohungen erkennen und neutralisieren kann, denen es noch nie begegnet ist, und sich gleichzeitig an frühere Angreifer erinnert, um sie effizienter abzuwehren. Dein Immunsystem macht das jeden Tag.
Stell dir nun vor, du wendest dieselbe Intelligenz an, um komplexe Computerprobleme zu lösen. Mit künstlichen Immunsystemen (AIS) können wir genau das tun.
Künstliche Immunsysteme sind leistungsstarke Computermodelle, die sich an der Fähigkeit des menschlichen Immunsystems orientieren, den Körper vor Schäden zu schützen.
Das Immunsystem ist der Abwehrmechanismus unseres Körpers, der Bedrohungen wie Bakterien, Viren und Pilze erkennen und neutralisieren soll. Dies geschieht durch ein paar wichtige Akteure: Antikörper, B-Zellen und T-Zellen.
Antikörper fungieren als Erkennungseinheiten des Immunsystems. Diese spezialisierten Proteine erkennen und heften sich an bestimmte fremde Substanzen, die Antigene genannt werden, und markieren sie als Bedrohung. Jeder Antikörper ist einzigartig und auf ein bestimmtes Antigen abgestimmt, wie ein Schloss und ein Schlüssel.
B-Zellen sind die Fabriken, die Antikörper produzieren. Sie sind auch an der Bildung von Gedächtniszellen beteiligt. Sie helfen dem Körper, schneller auf frühere Antigene zu reagieren, indem sie sich daran erinnern, welche Antikörper beim letzten Mal hilfreich waren.
T-Zellen sind die Vollstrecker des Immunsystems. Sie erkennen und zerstören Zellen, die von Antikörpern als infiziert oder gefährlich eingestuft werden, und sorgen dafür, dass die Bedrohung schnell neutralisiert wird.
Eine der bemerkenswertesten Eigenschaften des Immunsystems ist seine Fähigkeit, mit der Zeit neue Antikörper zu entwickeln und zu verbessern. Wenn es mit einem neuen Krankheitserreger konfrontiert wird, reagiert das Immunsystem nicht nur einmal. Sie verfeinert ihren Ansatz ständig und entwickelt stärkere und effektivere Antikörper, um die Bedrohung zu bekämpfen.
Künstliche Immunsysteme (AIS) sind die Umsetzung dieser biologischen Prinzipien in Algorithmen. AIS ahmt die Funktionen des Immunsystems bei der Problemlösung nach.
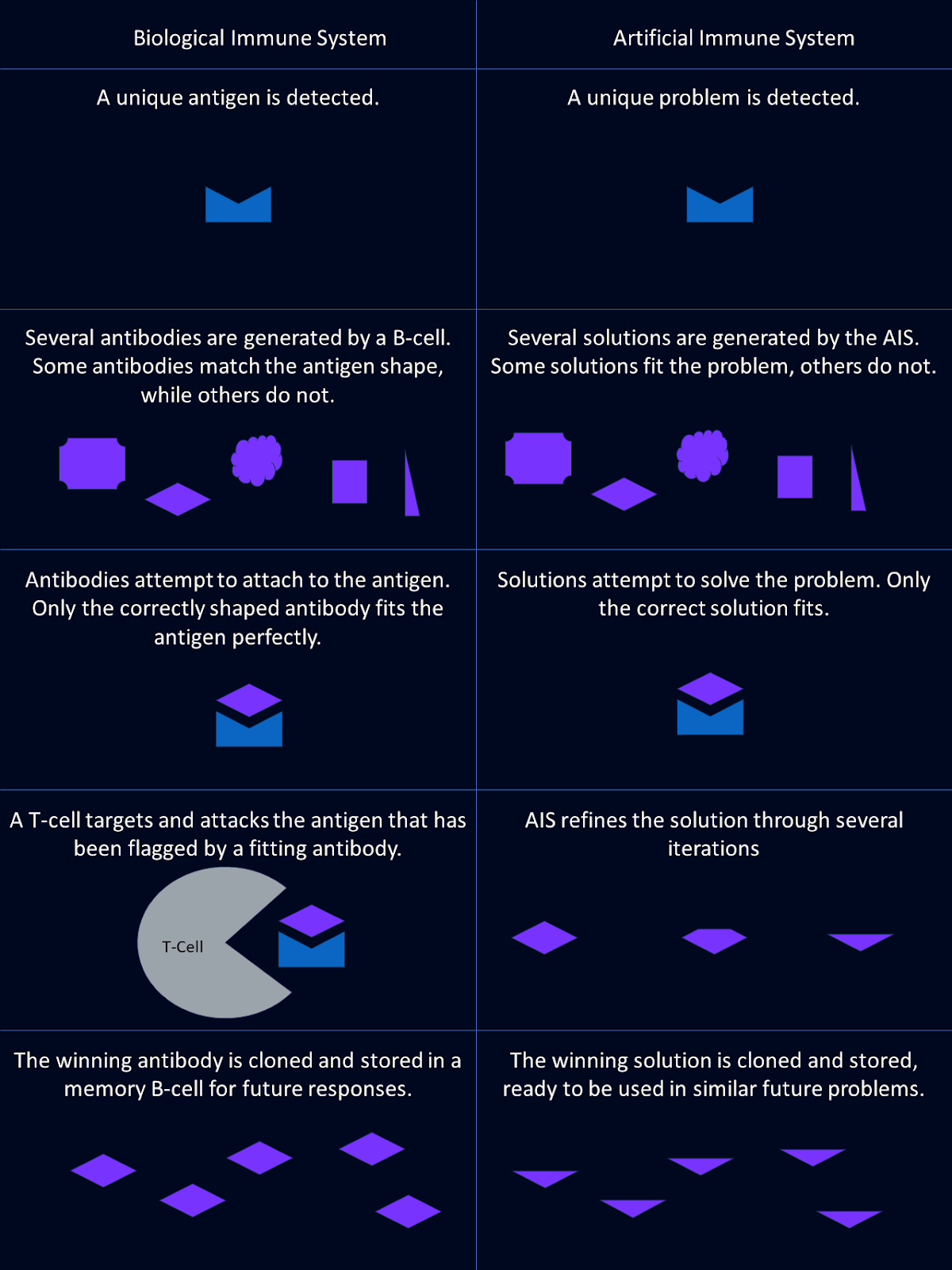
Bei AIS stellen die Antigene die Probleme oder Herausforderungen dar, die es zu bewältigen gilt. Das kann von der Erkennung von Anomalien in Daten bis hin zur Optimierung einer Lösung alles sein.
Antikörper in AIS sind Kandidaten für die Lösung dieser Probleme. Genauso wie biologische Antikörper bestimmte Antigene erkennen, entwickelt AIS potenzielle Lösungen, die auf bestimmte Herausforderungen zugeschnitten sind.
Der Prozess der B-Zellen im AIS spiegelt wider, wie biologische Systeme Vielfalt und Gedächtnis erzeugen. AIS-Algorithmen verwenden verschiedene Lösungsvorschläge und verfeinern sie mit der Zeit. Sie lernen aus früheren Problemlösungen, um ihre Leistung in Zukunft zu verbessern.
Künstliche Immunsysteme haben kein direktes Analogon zu T-Zellen, aber sie enthalten Bewertungsmechanismen, die eine ähnliche Funktion haben. Mit diesen Prozessen werden ineffektive Lösungen eliminiert und diejenigen, die besser funktionieren, feinjustiert.
AIS nutzen evolutionäre Prinzipien, wie Mutation und Selektion, um die Qualität der Lösungen kontinuierlich zu verbessern.
Künstliche Immunsysteme beinhalten Schlüsselkonzepte wie Antikörper-Antigen-Interaktion, klonale Selektion, negative Selektion und die Theorie des Immunitätsnetzwerks.
Ein wesentlicher Bestandteil von künstlichen Immunsystemen ist das Konzept der Antikörper-Antigen-Interaktion. Dieser Prozess ist direkt davon inspiriert, wie unser Immunsystem auf Bedrohungen reagiert. Betrachte Antikörper als potenzielle Lösungen für ein Problem und Antigene als die Probleme oder Herausforderungen selbst.
In der biologischen Welt sind Antikörper Proteine, die sich an Antigene heften und sie neutralisieren. Bei AIS stellt ein Antikörper einen Lösungsvorschlag für ein Rechenproblem dar, während das Antigen das Problem repräsentiert, das gelöst werden muss.
Der AIS-Algorithmus entwickelt eine Population dieser Antikörper, um die entsprechenden Antigene effektiv zu erkennen und zu neutralisieren. Mit der Zeit stimmt der Algorithmus diese Antikörper ab und findet so die effektivsten Lösungen.
Der klonale Selektionsalgorithmus (CSA) ist von einem anderen wichtigen Prozess in unserem Immunsystem inspiriert. Wenn der Körper ein Antigen entdeckt, setzt er nicht einfach irgendwelche Immunzellen ein, sondern wählt diejenigen aus, die den Eindringling spezifisch erkennen können. Diese ausgewählten Zellen werden dann in großer Zahl geklont, um eine effektive Verteidigung aufzubauen.
Diese Klone unterliegen Mutationen, die leichte Variationen einführen, die die Vielfalt der Immunantwort erhöhen. So wird sichergestellt, dass sich das Immunsystem anpassen und wirksam reagieren kann, auch wenn sich der Erreger weiterentwickelt.
In ähnlicher Weise wählt der Algorithmus der klonalen Auswahl die vielversprechendsten Lösungen aus und erstellt mehrere Kopien oder "Klone" von ihnen.
Diese Klone werden dann Mutationen unterzogen, wodurch ein vielfältiger Pool an möglichen Lösungen entsteht. Die leistungsstärksten Klone werden behalten, und der Prozess wird wiederholt, um die Qualität der Lösungen schrittweise zu verbessern. Dieser Algorithmus ist besonders leistungsfähig bei Optimierungsaufgaben, bei denen es darum geht, die effizienteste Lösung unter vielen Möglichkeiten zu finden.
CSA wird häufig zur Lösung von Optimierungsproblemen eingesetzt. In der Luft- und Raumfahrt kann sie zum Beispiel helfen, effiziente Strukturen wie Flugzeugflügel zu entwerfen, indem sie die aerodynamischen Eigenschaften über mehrere Iterationen verbessert.
In der medizinischen Bildgebung kann CSA die Bildschärfe verbessern oder unregelmäßige Muster in verrauschten Umgebungen erkennen, was sie für MRT-Scans oder die Tumorerkennung nützlich macht.
Das menschliche Immunsystem muss zwischen körpereigenen Zellen und fremden Eindringlingen unterscheiden. Hier kommt der negative Selektionsalgorithmus (NSA) ins Spiel. Immunzellen, die zu stark auf körpereigene Zellen reagieren, werden eliminiert. So wird sichergestellt, dass das Immunsystem nicht fälschlicherweise sich selbst angreift (und eine Autoimmunerkrankung verursacht).
Die NSA ahmt diesen Prozess nach, um Anomalien oder Ausreißer in Daten zu identifizieren. Der Algorithmus erstellt eine Reihe von Modellen, sogenannte Detektoren, die normale Muster in den Daten erkennen sollen. Alle Detektoren, die mit den normalen Daten übereinstimmen, werden eliminiert, so dass nur diejenigen übrig bleiben, die nicht den typischen Mustern entsprechen. Diese verbleibenden Detektoren werden dann zur Überwachung neuer Daten verwendet.
Wenn diese atypischen Detektoren einen neuen Datenpunkt erkennen, wird er als Anomalie. Das ist ähnlich wie die Art und Weise, wie das Immunsystem fremde Eindringlinge erkennt. Diese Methode ist sehr effektiv in Bereichen wie Cybersicherheitwo die Erkennung ungewöhnlicher Muster der Schlüssel zur Identifizierung potenzieller Bedrohungen ist.
Die NSA eignet sich gut für Intrusion Detection Systeme, die den Netzwerkverkehr überwachen und bösartige Aktivitäten durch den Vergleich normaler Muster mit denen potenzieller Bedrohungen erkennen.
NSA kann auch eingesetzt werden, um mechanische oder betriebliche Fehler in komplexen Systemen wie Kraftwerken zu erkennen.
Die Immun-Netzwerk-Theorie (INT) erweitert das Konzept der AIS, indem sie nicht nur die Interaktion zwischen Antikörpern und Antigenen, sondern auch die Interaktionen zwischen den Antikörpern selbst modelliert.
Im biologischen Immunsystem arbeiten die Antikörper nicht isoliert. Sie kommunizieren und beeinflussen sich gegenseitig und schaffen so ein dynamisches Netzwerk von Reaktionen, das robuster und anpassungsfähiger ist. Dieses vernetzte Zusammenspiel hilft dem Immunsystem, ein Gleichgewicht zu halten, das sicherstellt, dass es effektiv auf eine Vielzahl von Bedrohungen reagieren kann, ohne auf eine einzelne zu überreagieren.
INT wird verwendet, um komplexe Wechselwirkungen und Abhängigkeiten zwischen verschiedenen Lösungen zu modellieren. Dadurch kann der Algorithmus eine breitere Palette möglicher Antworten in Betracht ziehen, was zu anspruchsvolleren Problemlösungsstrategien führt.
Durch die Simulation der gegenseitigen Beeinflussung von Antikörpern kann AIS mehrere Wege zu einer Lösung gleichzeitig erkunden und so die Fähigkeit verbessern, optimale Lösungen in komplexen und dynamischen Umgebungen zu finden. Diese Theorie bildet die Grundlage für einige der fortschrittlichsten AIS-Algorithmen und macht sie zu einem leistungsstarken Werkzeug, um komplizierte Berechnungen durchzuführen.
Die Theorie der Immunitätsnetzwerke kann auf die Steuerung von Roboterschwärmen angewendet werden. Die Interaktionen zwischen den Robotern ahmen die Interaktionen von Antikörpern nach und ermöglichen koordiniertes Verhalten und Problemlösungen bei Aufgaben wie Such- und Rettungseinsätzen.
In der Finanzwelt können Immunnetzwerkmodelle verwendet werden, um die Wechselwirkungen zwischen verschiedenen Wirtschaftsindikatoren zu untersuchen und so Markttrends vorherzusagen oder finanzielle Anomalien zu erkennen.
Python ist aufgrund seiner umfangreichen Bibliotheken und seiner Benutzerfreundlichkeit oft die Sprache der Wahl, wenn es um die Entwicklung künstlicher Immunsysteme geht.
Der Algorithmus der klonalen Selektion ist von dem biologischen Prozess inspiriert, bei dem Immunzellen, die erfolgreich eine Bedrohung erkennen, geklont und dann mutiert werden, um die Immunantwort zu verbessern. Bei AIS sind diese "Immunzellen" Lösungsvorschläge für ein Problem, und das Ziel ist es, diese Lösungen weiterzuentwickeln, um die beste zu finden.
Hier erfährst du, wie du eine einfache Version von CSA in Python implementieren kannst:
Lass uns ein Funktionsoptimierungsproblem mit CSA lösen. Wir werden eine bekannte Benchmark-Funktion, die Rastrigin-Funktion, optimieren. Diese Funktion kann aufgrund ihrer vielen lokalen Minima zum Testen von Optimierungsalgorithmen verwendet werden.
Im folgenden Code verwenden wir eine CSA, um die globalen Minima für die Funktion zu finden:
import numpy as np
import matplotlib.pyplot as plt
# Define the Rastrigin function
def rastrigin(X):
n = len(X)
return 10 * n + np.sum(X**2 - 10 * np.cos(2 * np.pi * X))
# Generate the initial population of potential solutions
def generate_initial_population(pop_size, solution_size):
return np.random.uniform(-5.12, 5.12, size=(pop_size, solution_size)) # Initialize within the search space of Rastrigin
# Evaluate the fitness of each individual in the population (lower is better)
def evaluate_population(population):
return np.array([rastrigin(individual) for individual in population])
# Select the best candidates from the population based on their fitness
def select_best_candidates(population, fitness, num_candidates):
indices = np.argsort(fitness)
return population[indices[:num_candidates]], fitness[indices[:num_candidates]]
# Clone the best candidates multiple times
def clone_candidates(candidates, num_clones):
return np.repeat(candidates, num_clones, axis=0)
# Introduce random mutations to the cloned candidates to explore new solutions
def mutate_clones(clones, mutation_rate):
mutations = np.random.rand(*clones.shape) < mutation_rate
clones[mutations] += np.random.uniform(-1, 1, np.sum(mutations)) # Mutate by adding a random value
return clones
# Main function implementing the Clonal Selection Algorithm
def clonal_selection_algorithm(solution_size=2, pop_size=100, num_candidates=10, num_clones=10, mutation_rate=0.05, generations=100):
population = generate_initial_population(pop_size, solution_size)
best_fitness_per_generation = [] # Track the best fitness in each generation
for generation in range(generations):
fitness = evaluate_population(population)
candidates, candidate_fitness = select_best_candidates(population, fitness, num_candidates)
clones = clone_candidates(candidates, num_clones)
mutated_clones = mutate_clones(clones, mutation_rate)
clone_fitness = evaluate_population(mutated_clones)
# Replace the worst individuals in the population with the new mutated clones
population[:len(mutated_clones)] = mutated_clones
fitness[:len(clone_fitness)] = clone_fitness
# Track the best fitness of this generation
best_fitness = np.min(fitness)
best_fitness_per_generation.append(best_fitness)
# Stop early if we've found a solution close to the global minimum
if best_fitness < 1e-6:
print(f"Optimal solution found in {generation + 1} generations.")
break
# Plot the fitness improvement over generations
plt.figure(figsize=(10, 6))
plt.plot(best_fitness_per_generation, marker='o', color='blue', label='Best Fitness per Generation')
plt.xlabel('Generations')
plt.ylabel('Fitness (Rastrigin Function Value)')
plt.title('Fitness Improvement Over Generations')
plt.grid(True)
plt.show()
# Return the best solution found (the one with the lowest fitness score)
best_solution = population[np.argmin(fitness)]
return best_solution
# Example Usage
best_solution = clonal_selection_algorithm(solution_size=2) # Using 2D Rastrigin function
print("Best solution found:", best_solution)
print("Rastrigin function value at best solution:", rastrigin(best_solution))
# Plot the surface of the Rastrigin function with the best solution found
x = np.linspace(-5.12, 5.12, 200)
y = np.linspace(-5.12, 5.12, 200)
X, Y = np.meshgrid(x, y)
Z = 10 * 2 + (X**2 - 10 * np.cos(2 * np.pi * X)) + (Y**2 - 10 * np.cos(2 * np.pi * Y))
plt.figure(figsize=(8, 6))
plt.contourf(X, Y, Z, levels=50, cmap='viridis')
plt.colorbar(label='Function Value')
plt.scatter(best_solution[0], best_solution[1], c='red', s=100, label='Best Solution')
plt.title('Rastrigin Function Optimization with CSA')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()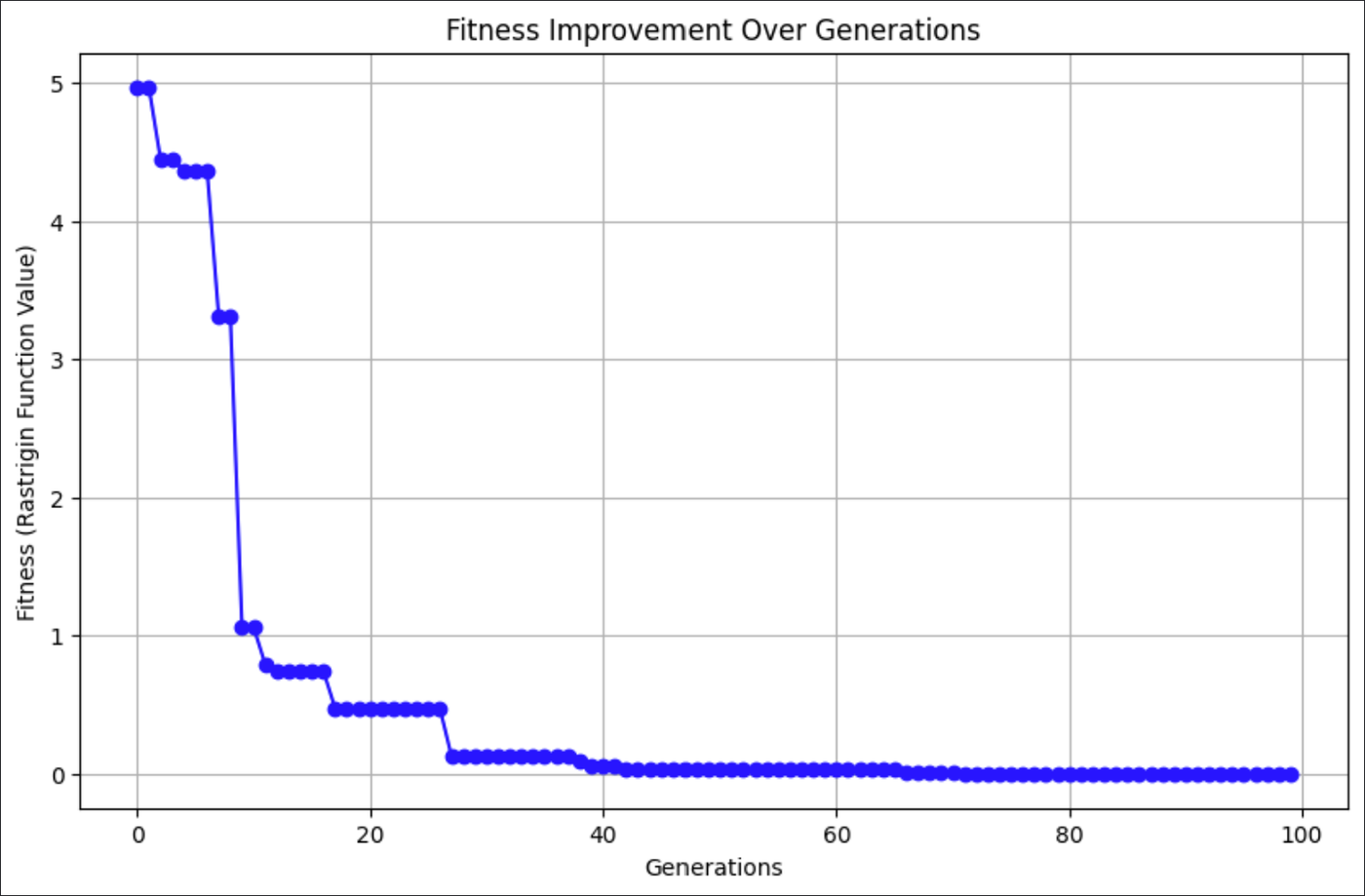
Die Grafik oben zeigt, wie die CSA mit jeder Generation bessere Lösungen für die Rastrigin-Funktion gefunden hat.
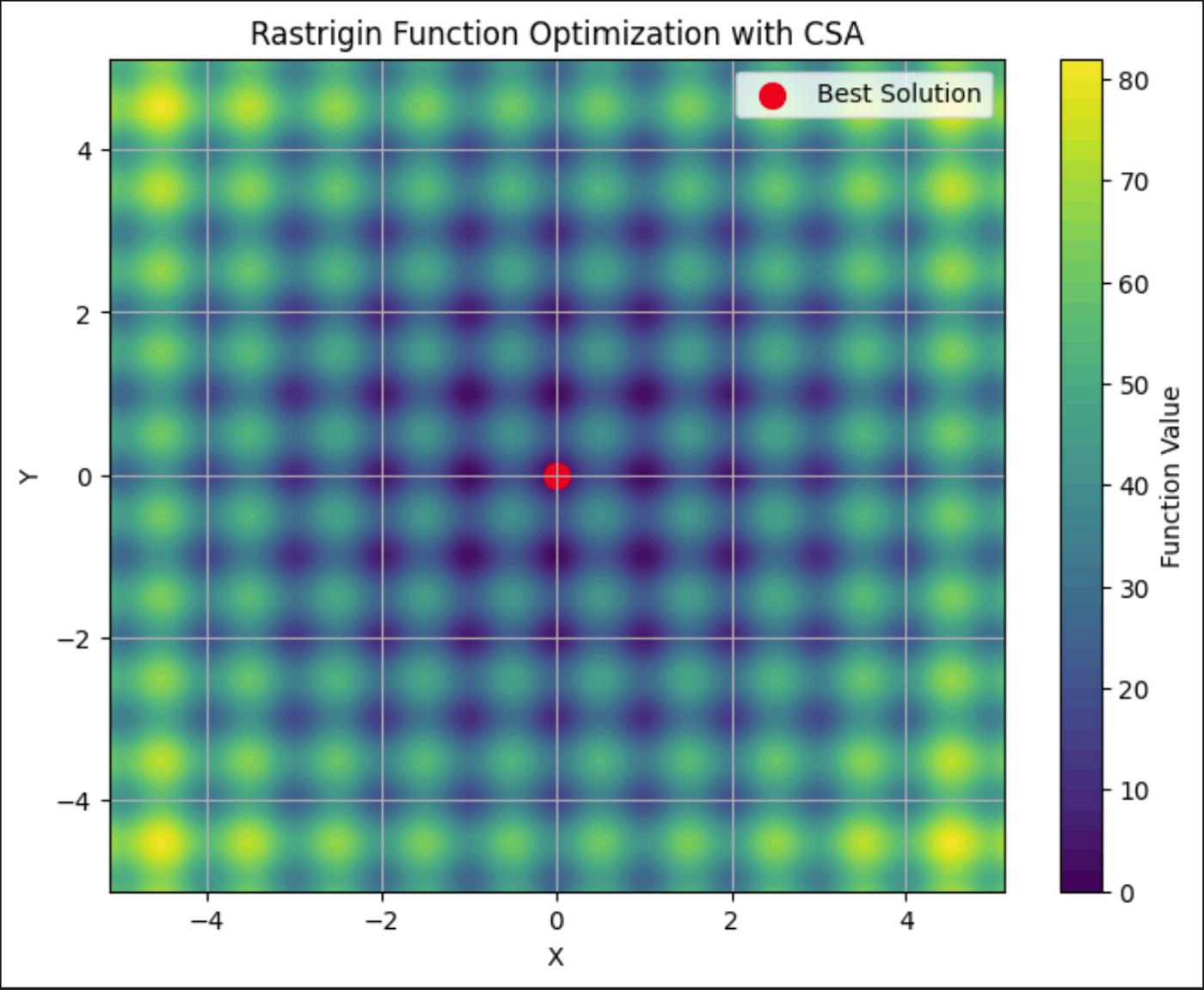
Diese Grafik zeigt den Rastrigin, der viele lokale Minima aufweist. Die beste Lösung, der rote Punkt in der Mitte, ist die endgültige Lösung, die von der CSA gefunden wurde.
Die NSA ist besonders nützlich für die Erkennung von Anomalien. Dieser Algorithmus simuliert, wie das Immunsystem zwischen körpereigenen Zellen und fremden Eindringlingen unterscheidet. Bei einer NSA erzeugst du eine Reihe von Detektoren, die nicht mit den normalen Datenmustern übereinstimmen. Diese Detektoren werden dann verwendet, um neue Daten zu überwachen und alles zu markieren, was anomal erscheint.
Hier ist ein Überblick darüber, wie man eine NSA erstellt:
Schauen wir uns an, wie das mit einer fiktiven Reihe von Transaktionen funktioniert. In diesem Beispiel generieren wir normale Transaktionen, die in zwei Clustern zentriert sind, und betrügerische Transaktionen, die zufällig verstreut sind. Wir verwenden einen negativen Selektionsalgorithmus, bei dem Betrugsdetektoren über den Merkmalsraum verstreut werden, um Anomalien anhand ihrer Nähe zu diesen Detektoren zu identifizieren.
import numpy as np
import matplotlib.pyplot as plt
# Generate a synthetic dataset
np.random.seed()
# Parameters for bimodal distribution
num_normal_points = 80 # total number of normal transactions
num_points_per_cluster = num_normal_points // 2 # number of points in each cluster
# Generate normal transactions for two clusters
cluster1_center = [2, 2]
cluster2_center = [8, 8]
# Generate points around the first cluster center
normal_cluster1 = np.random.normal(loc=cluster1_center, scale=0.5, size=(num_points_per_cluster, 2))
# Generate points around the second cluster center
normal_cluster2 = np.random.normal(loc=cluster2_center, scale=0.5, size=(num_points_per_cluster, 2))
# Combine clusters into one dataset
normal_transactions = np.vstack([normal_cluster1, normal_cluster2])
# Define random distribution for fraudulent transactions
num_fraud_points = 5 # number of fraudulent transactions
fraudulent_transactions = np.random.uniform(low=0, high=10, size=(num_fraud_points, 2))
# Combine into one dataset
data = np.vstack([normal_transactions, fraudulent_transactions])
labels = np.array([0] * len(normal_transactions) + [1] * len(fraudulent_transactions))
# Function to generate detectors (random points) that don't match any of the normal data
def generate_detectors(normal_data, num_detectors, detector_size):
detectors = []
while len(detectors) < num_detectors:
detector = np.random.rand(detector_size) * 10 # Scale to cover the data range
if not any(np.allclose(detector, pattern, atol=0.5) for pattern in normal_data):
detectors.append(detector)
return np.array(detectors)
# Function to detect anomalies (points in the data that are close to any detector)
def detect_anomalies(detectors, data, threshold=0.5):
anomalies = []
for point in data:
if any(np.linalg.norm(detector - point) < threshold for detector in detectors):
anomalies.append(point)
return anomalies
# Generate detectors that do not match the normal data
detectors = generate_detectors(normal_transactions, num_detectors=300, detector_size=2)
# Detect anomalies within the entire dataset using the detectors
anomalies = detect_anomalies(detectors, data)
print("Number of anomalies detected:", len(anomalies))
# Convert anomalies to a numpy array for visualization
anomalies = np.array(anomalies) if anomalies else np.array([])
# Define axis limits
x_min, x_max = 0, 10
y_min, y_max = -1, 11
# Visualize the dataset, detectors, and anomalies
plt.figure(figsize=(14, 6))
# Plot the normal transactions and fraudulent transactions
plt.subplot(1, 2, 1)
plt.scatter(normal_transactions[:, 0], normal_transactions[:, 1], color='red', marker='x', label='Normal Transactions')
plt.scatter(fraudulent_transactions[:, 0], fraudulent_transactions[:, 1], color='green', marker='o', label='Fraudulent Transactions')
plt.scatter(detectors[:, 0], detectors[:, 1], color='blue', marker='o', alpha=0.5, label='Detectors')
if len(anomalies) > 0:
plt.scatter(anomalies[:, 0], anomalies[:, 1], color='yellow', marker='*', s=100, label='Detected Anomalies')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Fraud Detection Using Negative Selection Algorithm (NSA)')
plt.legend(loc='lower right')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.grid(False)
# Create a grid of points to classify
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100))
grid_points = np.c_[xx.ravel(), yy.ravel()]
# Classify grid points
decision = np.array([any(np.linalg.norm(detector - point) < 0.5 for detector in detectors) for point in grid_points])
decision = decision.reshape(xx.shape)
# Plot the decision boundary
plt.subplot(1, 2, 2)
plt.contourf(xx, yy, decision, cmap='coolwarm', alpha=0.3)
plt.scatter(normal_transactions[:, 0], normal_transactions[:, 1], color='red', marker='x', label='Normal Transactions')
plt.scatter(fraudulent_transactions[:, 0], fraudulent_transactions[:, 1], color='green', marker='o', label='Fraudulent Transactions')
plt.scatter(detectors[:, 0], detectors[:, 1], color='blue', marker='o', alpha=0.5, label='Detectors')
if len(anomalies) > 0:
plt.scatter(anomalies[:, 0], anomalies[:, 1], color='yellow', marker='*', s=100, label='Detected Anomalies')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Decision Boundary Visualization')
plt.legend(loc='lower right')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.grid(False)
# Show the plot
plt.show()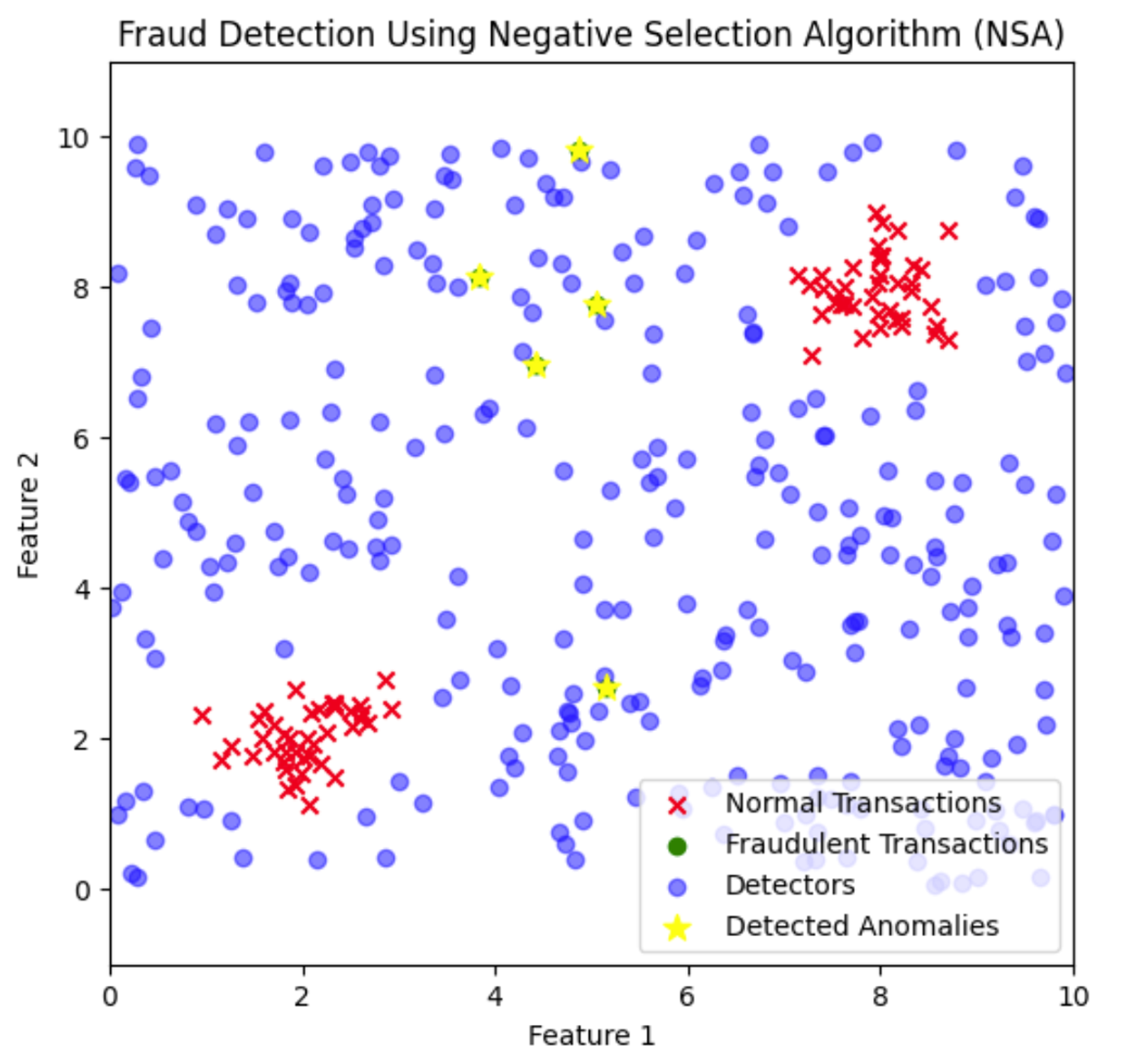
Hier werden die Betrugsdetektoren über den Merkmalsraum verteilt, um Bereiche abzudecken, in denen normale Transaktionen nicht vorkommen. Betrügerische Transaktionen, die in die Nähe dieser Detektoren fallen, werden identifiziert und als Anomalien gekennzeichnet.
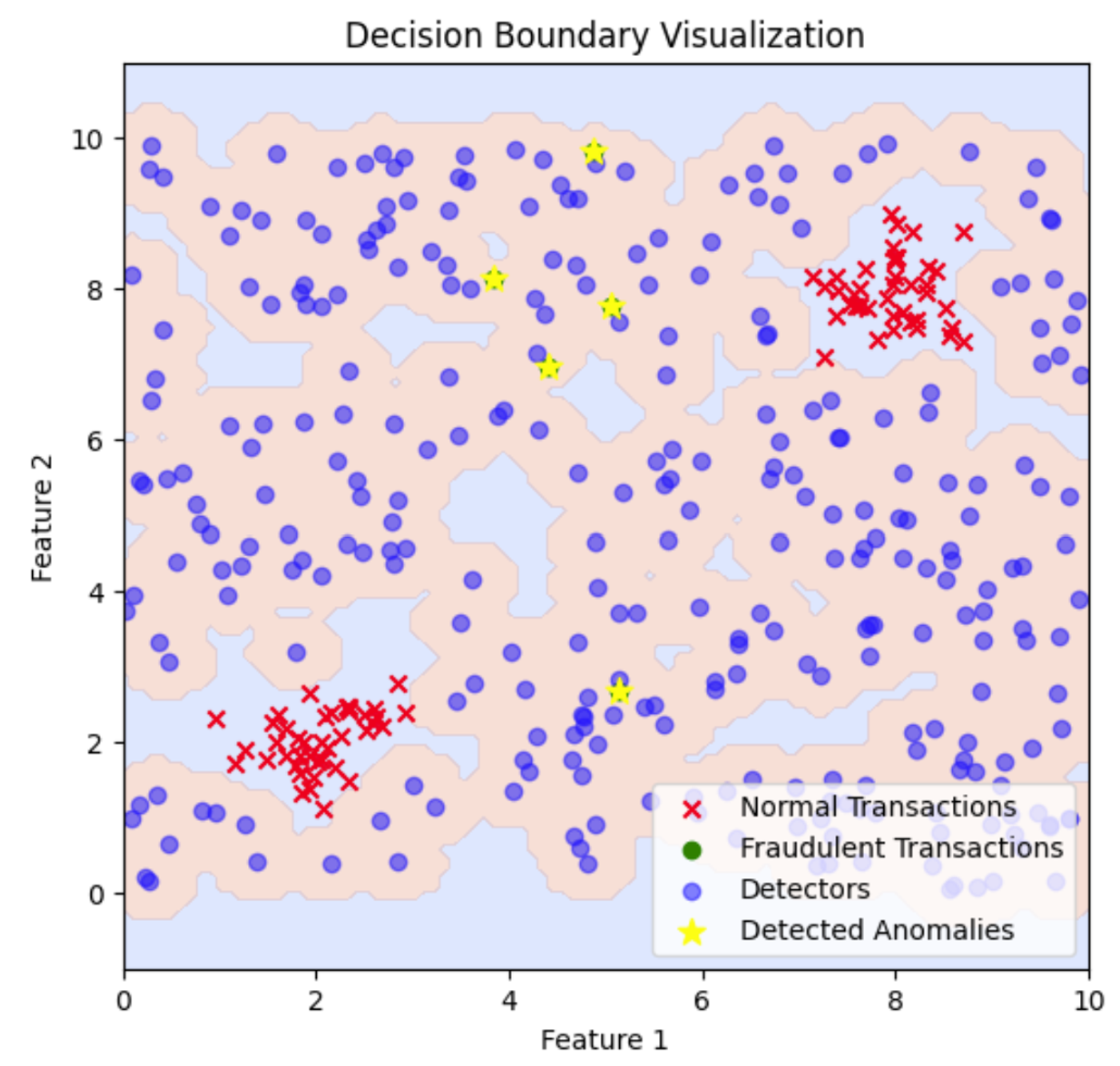
Diese Grafik veranschaulicht die Entscheidungsgrenze, die von den Betrugsdetektoren gezogen wird. Die schattierten Bereiche stellen die Bereiche dar, die aufgrund der Nähe zu den Detektoren als anomal eingestuft werden und zeigen, wo betrügerische Transaktionen im Vergleich zu normalen Transaktionen entdeckt werden. Um die Entscheidungsgrenze anzupassen und mehr oder weniger Fläche abzudecken, kannst du den Abstandsschwellenwert für die Erkennung von Anomalien ändern, wodurch die als anomal eingestuften Regionen erweitert oder verkleinert werden.
INT ist von der Idee inspiriert, dass Immunreaktionen nicht nur auf einzelnen Antikörpern beruhen, sondern auch auf deren Kommunikation. Bei diesem Ansatz wird das Immunsystem als ein Netzwerk modelliert, in dem Antikörper miteinander kommunizieren, um die gesamte Immunantwort zu verbessern. In diesem Zusammenhang kann jeder Antikörper (Lösung) mit anderen interagieren, um die Suche nach optimalen Lösungen zu beeinflussen und zu verfeinern.
Hier siehst du, wie du eine einfache Version von INT in Python implementieren kannst:
Verwenden wir INT, um die Entwicklung des Aktienmarktes auf der Grundlage einer Reihe von Wirtschaftsindikatoren vorherzusagen. Wir verwenden einen fiktiven Datensatz, bei dem jede Lösung eine Kombination von Indikatoren zur Vorhersage von Aktienkursen darstellt.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Generate synthetic data for illustration
np.random.seed(42)
n_samples = 100
n_features = 5
X = np.random.rand(n_samples, n_features) # Random economic indicators
true_weights = np.array([0.5, -0.2, 0.3, 0.1, -0.1])
y = X @ true_weights + np.random.normal(0, 0.1, n_samples) # Stock prices with noise
# Define the fitness function
def fitness_function(solution, X, y):
model = LinearRegression()
model.coef_ = solution
predictions = X @ model.coef_
return mean_squared_error(y, predictions)
# Generate the initial population of potential solutions
def generate_initial_population(pop_size, solution_size):
return np.random.uniform(-1, 1, size=(pop_size, solution_size))
# Create the immune network
def create_immune_network(population, fitness, num_neighbors):
network = []
for i, individual in enumerate(population):
distances = np.linalg.norm(population - individual, axis=1)
neighbors = np.argsort(distances)[1:num_neighbors+1] # Exclude self
network.append(neighbors)
return network
# Update the immune network
def update_network(network, population, fitness, mutation_rate):
new_population = np.copy(population)
for i, neighbors in enumerate(network):
if np.random.rand() < mutation_rate:
# Apply mutation with a smaller range
mutation = np.random.uniform(-0.05, 0.05, population.shape[1])
new_population[i] += mutation
return new_population
# Main function implementing Immune Network Theory
def immune_network_theory(solution_size=n_features, pop_size=50, num_neighbors=5, mutation_rate=0.1, generations=50):
population = generate_initial_population(pop_size, solution_size)
best_fitness_per_generation = [] # Track the best fitness in each generation
for generation in range(generations):
fitness = np.array([fitness_function(ind, X, y) for ind in population])
network = create_immune_network(population, fitness, num_neighbors)
new_population = update_network(network, population, fitness, mutation_rate)
# Evaluate the fitness of the new population
fitness_new = np.array([fitness_function(ind, X, y) for ind in new_population])
# Combine the old and new populations
combined_population = np.vstack((population, new_population))
combined_fitness = np.hstack((fitness, fitness_new))
# Select the best individuals
best_indices = np.argsort(combined_fitness)[:pop_size]
population = combined_population[best_indices]
fitness = combined_fitness[best_indices]
# Track the best fitness of this generation
best_fitness = np.min(fitness)
best_fitness_per_generation.append(best_fitness)
# Stop early if the fitness is good enough
if best_fitness < 0.01:
print(f"Optimal solution found in {generation + 1} generations.")
break
# Plot the fitness improvement over generations
plt.figure(figsize=(10, 6))
plt.plot(best_fitness_per_generation, marker='o', color='blue', label='Best Fitness per Generation')
plt.xlabel('Generations')
plt.ylabel('Mean Squared Error')
plt.title('Fitness Improvement Over Generations')
plt.grid(True)
plt.show()
# Return the best solution found
best_solution = population[np.argmin(fitness)]
return best_solution
# Example Usage
best_solution = immune_network_theory()
print("Best solution found (economic indicators weights):", best_solution)
print("Mean Squared Error at best solution:", fitness_function(best_solution, X, y))
# Plot the predicted vs. actual values using the best solution
model = LinearRegression()
model.coef_ = best_solution
predictions = X @ model.coef_
plt.figure(figsize=(8, 6))
plt.scatter(y, predictions, c='blue', label='Predicted vs Actual')
plt.plot([min(y), max(y)], [min(y), max(y)], 'r--', label='Ideal Fit')
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Stock Price Prediction with INT')
plt.legend()
plt.grid(True)
plt.show()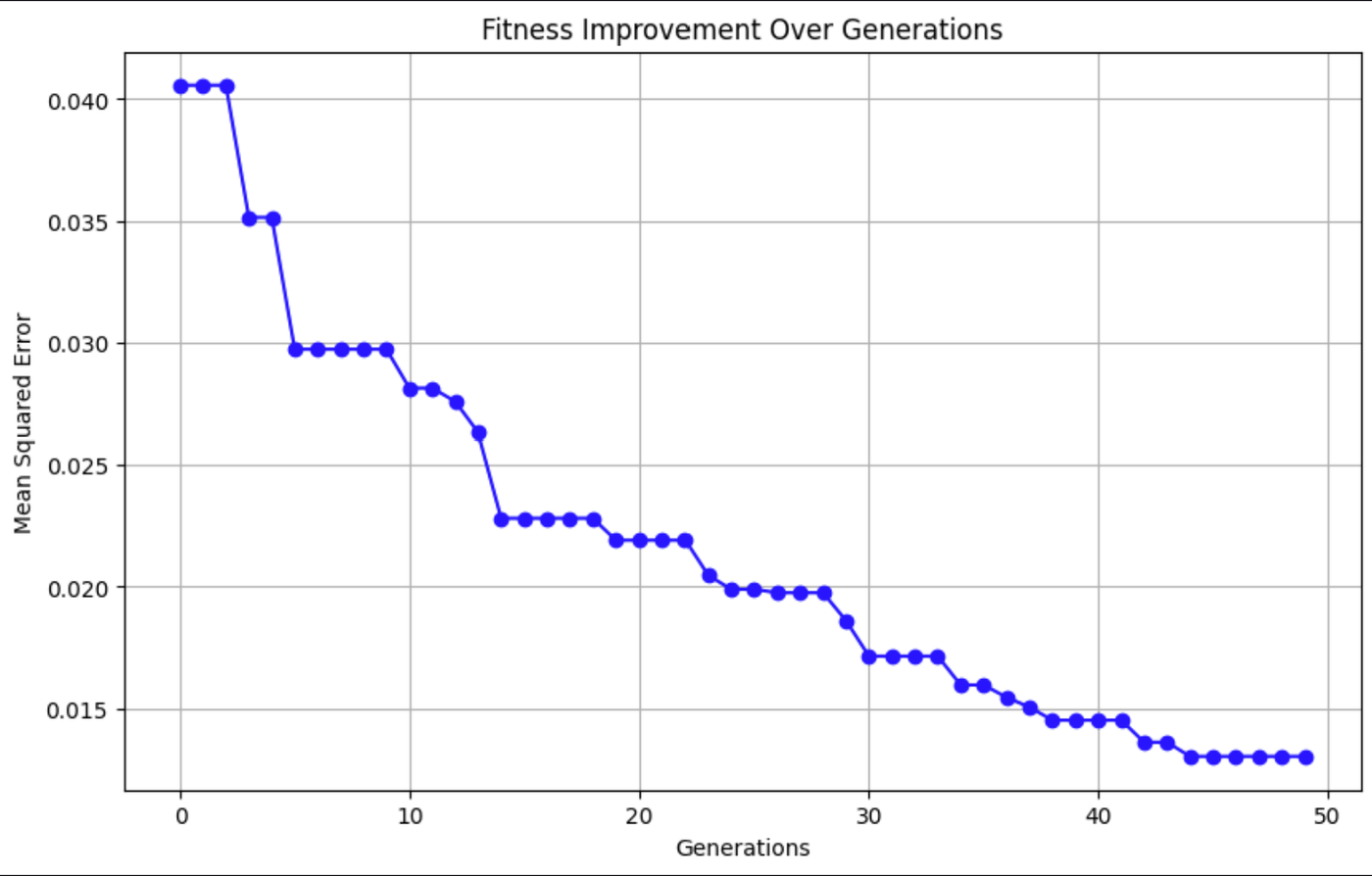
Diese Grafik zeigt, dass der mittlere quadratische Fehler (MSE) im Laufe der Zeit abnimmt, was bedeutet, dass die Vorhersagen des Modells immer genauer werden.
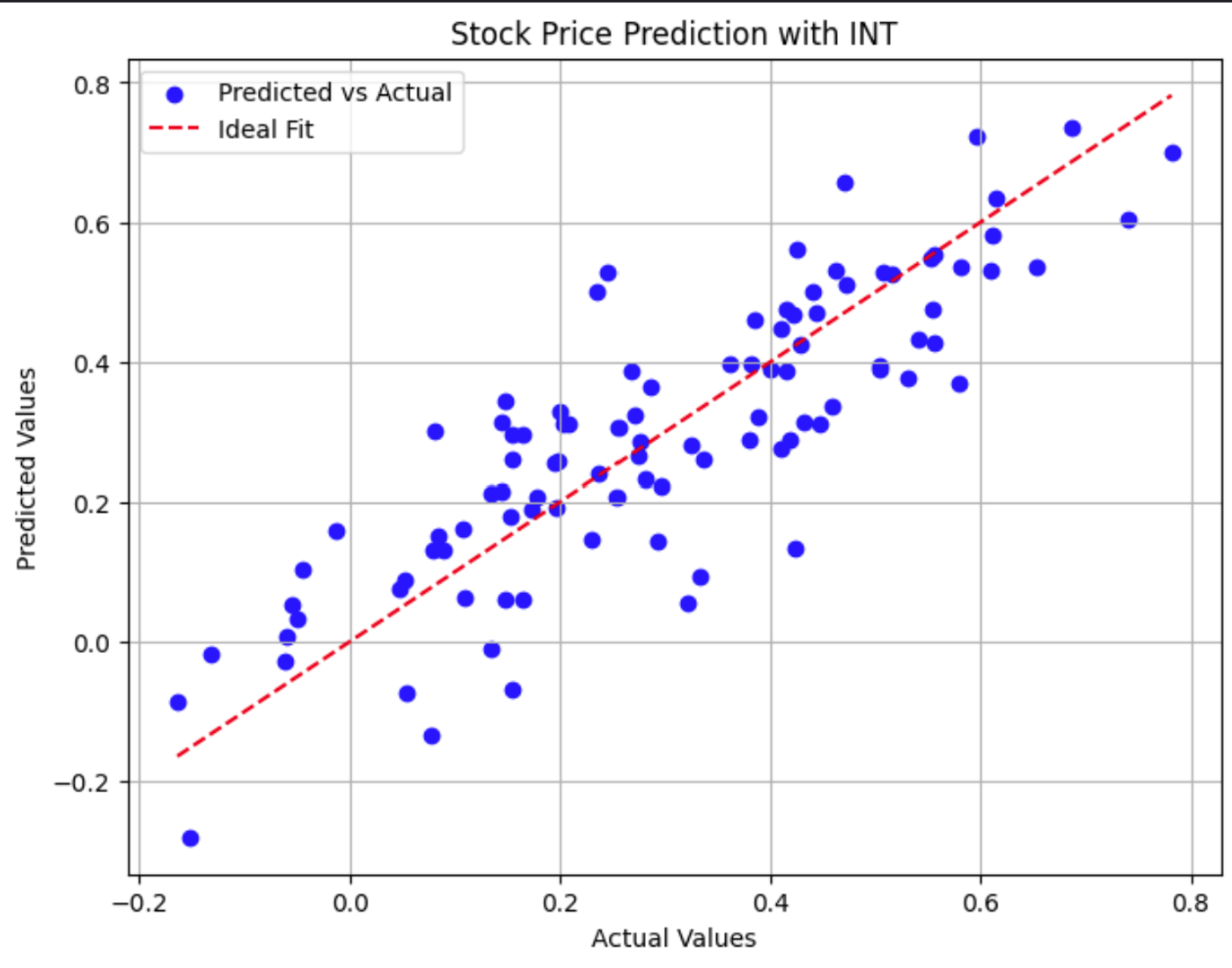
Dieses Streudiagramm vergleicht die tatsächlichen Aktienkurse mit den Modellvorhersagen. Punkte, die näher an der rot gestrichelten Linie liegen, zeigen genauere Vorhersagen.
AIS ist eine von vielen maschinellen Lerntechniken, die von der Biologie inspiriert sind.
Neuronale Netzwerke sind dem menschlichen Gehirn nachempfunden und eignen sich hervorragend zum Lernen aus großen Datensätzen. Sie werden für Aufgaben wie Bilderkennung und natürliche Sprachverarbeitung eingesetzt. Sie sind auf ein umfangreiches Training mit großen Datenmengen angewiesen, um die Gewichte der miteinander verbundenen Neuronen anzupassen.
Im Gegensatz dazu konzentrieren sich künstliche Immunsysteme auf Anpassungsfähigkeit und dezentrale Problemlösung, ohne dass große Datensätze benötigt werden. AIS ahmen die Fähigkeit des Immunsystems nach, neue Herausforderungen in Echtzeit zu erkennen und darauf zu reagieren. Sie eignen sich daher für dynamische Umgebungen, in denen eine schnelle Anpassung entscheidend ist.
Genetische Algorithmen, die von der natürlichen Evolution inspiriert sind, eignen sich für die Optimierung komplexer Probleme, indem sie eine Population von Lösungen durch Selektion, Kreuzung und Mutation entwickeln. Dieser Prozess ist ähnlich wie bei CSA.
Während genetische Algorithmen auf genetische Operatoren angewiesen sind, um den Lösungsraum zu erforschen, passt CSA die Lösungen an, indem es Immunreaktionen nachahmt und so flexibel mit neuen und unerwarteten Herausforderungen umgehen kann. AIS, einschließlich CSA, sind besonders effektiv in dynamischen Umgebungen, in denen schnelle Anpassung und kontinuierliches Lernen entscheidend sind.
Mehr über genetische Algorithmen erfährst du unter Genetischer Algorithmus: Vollständiger Leitfaden mit Python-Implementierung.
Algorithmen der Schwarmintelligenz sind vom kollektiven Verhalten sozialer Organismen wie Ameisen und Bienen inspiriert. Sie nutzen dezentrale Systeme und einfache Agenteninteraktionen, um eine komplexe globale Optimierung zu erreichen.
Dies ist im Grunde genommen ähnlich wie INT. Beide Ansätze konzentrieren sich auf die Erhaltung der Vielfalt und Anpassungsfähigkeit innerhalb eines Systems, um Optimierungsprobleme zu lösen. Während die Schwarmintelligenz den Schwerpunkt auf agentenbasierte Interaktionen legt, nutzt INT Mechanismen, die mit Immunreaktionen vergleichbar sind, und bietet so ergänzende Methoden für dynamische Problemlösungen.
Mehr über Schwarmintelligenz-Algorithmen erfährst du unter Schwarmintelligenz-Algorithmen: Drei Python-Implementierungen.
Künstliche Immunsysteme sind vielversprechend, um komplexe Probleme in verschiedenen Bereichen zu lösen. Forscherinnen und Forscher arbeiten daran, diese Systeme zu verbessern, um sie noch nützlicher zu machen.
Ein Bereich, den die Forscher erforschen, ist die Entwicklung hybrider Modelle, die AIS mit anderen Techniken der Computerintelligenz kombinieren. Die Hoffnung ist, dass diese Hybridmodelle robuster und vielseitiger sein werden.
Diese hybriden Ansätze zielen darauf ab, die Stärken jeder Methode zu nutzen, wie z.B. die adaptiven Fähigkeiten von AIS und die leistungsstarken Lernmechanismen von neuronalen Netzen. Weitere Informationen findest du unter Künstliche Immunsysteme.
Ein weiterer aktiver Forschungsbereich ist die Anwendung von AIS auf neue Bereiche. Während AIS traditionell in den Bereichen Cybersicherheit und Optimierung eingesetzt wird, wird es jetzt auch in Bereichen wie Robotik, Bioinformatik und sogar Finanzmodellierung erforscht. Die Anpassungsfähigkeit und Dezentralität von AIS machen es zu einem vielversprechenden Kandidaten für die Lösung von Problemen in diesen dynamischen und oft unvorhersehbaren Umgebungen. Für weitere Informationen empfehle ich dir, Nature-Inspired Computing zu lesen: Umfang und Anwendungen von künstlichen Immunsystemen für die Analyse und Diagnose komplexer Probleme.
AIS-Modelle bieten nicht nur verbesserte Rechentechniken, sondern können auch zu unserem Verständnis realer Immunsysteme beitragen. Sie bringen Immuntherapiestrategien für Krankheiten wie Krebs und Autoimmunkrankheiten voran. Schau dir diese Zusammenarbeit zwischen der Cleveland Clinic und IBM um mehr zu erfahren.
Künstliche Immunsysteme bieten einen einzigartigen Ansatz, um komplexe Probleme zu lösen, indem sie sich vom menschlichen Immunsystem inspirieren lassen. Durch die Nachahmung biologischer Prozesse wie Mustererkennung, Anpassung und Gedächtnis bieten AIS vielseitige Lösungen in Bereichen wie Cybersicherheit und Optimierung.
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.