
Curso
Diseño de sistemas agénticos con LangChain
3 h
11.3K
DeepSeek-OCR 2 is an end-to-end document reading cum OCR vision-language model designed to handle complex layouts (multi-column pages, forms, tables, formulas) by learning a better reading order instead of flattening image patches in a fixed top-left to bottom-right raster scan.
The core idea is Visual Causal Flow, i.e., the model tries to mimic how humans read documents, progressively and semantically, rather than treating the page like a uniform grid. Architecturally, DeepSeek-OCR 2 keeps the same encoder–decoder framing as DeepSeek-OCR, but upgrades the encoder to DeepEncoder V2, which introduces a causal token reordering mechanism before the decoder generates text.
At a high level, DeepSeek OCR-2 converts a document into text through a vision-language pipeline that learns the reading order instead of relying on fixed coordinate sorting. This includes:
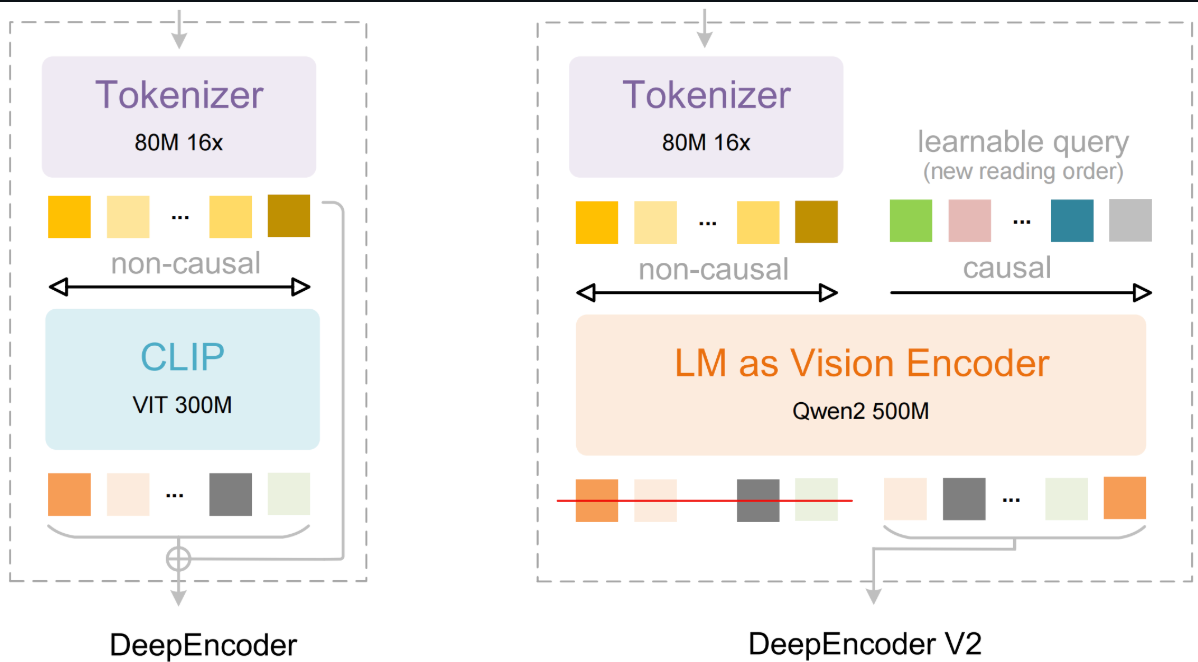
Figure: DeepSeek-OCR 2: Visual Causal Flow
You can refer to the DeepSeek OCR-2 GitHub repository for exploring the code in detail.
In this section, we’ll build a real-time document intelligence application that allows you to upload a PDF, extract its content using DeepSeek OCR-2, and start asking questions while the document is still being processed. Instead of waiting for full OCR to complete, pages become searchable batch by batch, enabling a much faster and more interactive experience.
At a high level, the system performs four core tasks:
The application produces two main outputs:
Note: This tutorial builds on DeepSeek’s official OCR-2 vLLM demo code, including the PDF rendering helper, multimodal input packaging, OCR text cleanup, and the vLLM engine/sampling configuration. On top of that, I add a lightweight RAG layer, mini-batch OCR processing to enable incremental indexing, and a Gradio app.
Before running DeepSeek OCR-2 with vLLM, we need to ensure the runtime environment is ready. In this tutorial, we assume a GPU-enabled environment such as Google Colab with an A100 or a T4, since both vLLM and DeepSeek OCR-2 require CUDA for efficient inference.
In this step, we will:
This ensures the rest of the pipeline can load the model and supporting utilities without path or dependency issues.
import subprocess
gpu = subprocess.run(['nvidia-smi', '--query-gpu=name,memory.total', '--format=csv,noheader'],
capture_output=True, text=True).stdout.strip()
print(f"GPU: {gpu}")
import os, sys
REPO_ROOT = '/content/DeepSeek-OCR-2-main'
VLLM_DIR = f'{REPO_ROOT}/DeepSeek-OCR2-master/DeepSeek-OCR2-vllm'
if not os.path.isdir(VLLM_DIR):
zip_candidates = [
'/content/DeepSeek-OCR-2-main.zip',
]
found_zip = None
for zp in zip_candidates:
if os.path.isfile(zp):
found_zip = zp
break
if found_zip:
!unzip -qo {found_zip} -d /content/
print(f'Extracted {found_zip}')
else:
!git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.git {REPO_ROOT} 2>/dev/null || echo 'Already cloned'
assert os.path.isdir(VLLM_DIR), f'Repo not found at {VLLM_DIR}'
print(f'Repo OK: {VLLM_DIR}')This step verifies that a GPU is available and then prepares the DeepSeek OCR-2 codebase locally. The above script first checks available GPU and memory using nvidia-smi to ensure the environment has sufficient VRAM for vLLM inference.
It then defines the repository paths and checks whether the required vLLM integration directory already exists. If not, it either extracts the repository from a local ZIP or clones the official DeepSeek OCR-2 repository from GitHub.
In the next step, we’ll install the required dependencies and prepare the runtime for vLLM-based inference.
DeepSeek OCR-2 and vLLM are very version-sensitive, so in this step, we pin a working set of packages for CUDA 11.8, install a matching vLLM wheel, and add flash-attn for faster attention kernels.
!pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 \
--index-url https://download.pytorch.org/whl/cu118 2>&1 | tail -3
!pip install https://github.com/vllm-project/vllm/releases/download/v0.8.5/vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl 2>&1 | tail -3
!pip install flash-attn==2.7.3 --no-build-isolation 2>&1 | tail -3
!pip install "pydantic==2.10.6" "gradio==5.23.0" "gradio_client==1.7.2"
!pip install transformers==4.46.3 tokenizers==0.20.3 2>&1 | tail -3
!pip install addict einops tiktoken easydict pymupdf img2pdf pillow 2>&1 | tail -3
!pip install sentence-transformers faiss-cpu gradio 2>&1 | tail -3
os.environ['VLLM_USE_V1'] = '0'
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
if torch.version.cuda == '11.8':
os.environ['TRITON_PTXAS_PATH'] = '/usr/local/cuda-11.8/bin/ptxas'
if VLLM_DIR not in sys.path:
sys.path.insert(0, VLLM_DIR)
import os, sys, re, io, time, threading
import numpy as np
import faiss
import fitz
import gradio as gr
from PIL import Image
from concurrent.futures import ThreadPoolExecutor
from functools import partial
from sentence_transformers import SentenceTransformer
VLLM_DIR = '/content/DeepSeek-OCR-2-main/DeepSeek-OCR2-master/DeepSeek-OCR2-vllm'
if VLLM_DIR not in sys.path:
sys.path.insert(0, VLLM_DIR)
import config
from vllm import LLM, SamplingParams
from vllm.model_executor.models.registry import ModelRegistry
from process.ngram_norepeat import NoRepeatNGramLogitsProcessor
from process.image_process import DeepseekOCR2Processor
from deepseek_ocr2 import DeepseekOCR2ForCausalLM
print('Loading embedding model...')
EMBED_MODEL = SentenceTransformer('all-MiniLM-L6-v2')
EMBED_DIM = EMBED_MODEL.get_sentence_embedding_dimension()
print(f'Embedding model ready (dim={EMBED_DIM})')The above code snippet installs a compatible runtime for DeepSeek OCR-2 with vLLM. It also installs the supporting stack for the application, including Transformers, Gradio for the UI, PyMuPDF and Pillow for PDF/image processing, and SentenceTransformers with FAISS for building the retrieval index.
After installation, environment variables are configured for stable vLLM execution and Triton compatibility. The repository’s vLLM integration is added to sys.path so the custom DeepSeek OCR-2 model and preprocessing modules can be imported, and finally, a lightweight embedding model (all-MiniLM-L6-v2) is loaded to support incremental page-level RAG indexing.
In the next step, we’ll implement preprocessing utilities to convert a PDF into page images, package each page into the multimodal input format expected by DeepSeek OCR-2, and clean the OCR outputs for retrieval.
Before we can run DeepSeek OCR-2, we need a small set of preprocessing utilities that convert a PDF into model-ready inputs and clean the raw OCR output for retrieval.
BATCH_SIZE = 5
def pdf_to_images_high_quality(pdf_path, dpi=144, image_format='PNG'):
images = []
pdf_document = fitz.open(pdf_path)
zoom = dpi / 72.0
matrix = fitz.Matrix(zoom, zoom)
for page_num in range(pdf_document.page_count):
page = pdf_document[page_num]
pixmap = page.get_pixmap(matrix=matrix, alpha=False)
Image.MAX_IMAGE_PIXELS = None
if image_format.upper() == 'PNG':
img_data = pixmap.tobytes('png')
img = Image.open(io.BytesIO(img_data))
else:
img_data = pixmap.tobytes('png')
img = Image.open(io.BytesIO(img_data))
if img.mode in ('RGBA', 'LA'):
background = Image.new('RGB', img.size, (255, 255, 255))
background.paste(img, mask=img.split()[-1] if img.mode == 'RGBA' else None)
img = background
images.append(img)
pdf_document.close()
return images
def process_single_image(image, prompt_str):
return {
'prompt': prompt_str,
'multi_modal_data': {
'image': DeepseekOCR2Processor().tokenize_with_images(
images=[image], bos=True, eos=True, cropping=config.CROP_MODE
)
},
}
def clean_ocr_output(content):
if '<|end▁of▁sentence|>' in content:
content = content.replace('<|end▁of▁sentence|>', '')
else:
if config.SKIP_REPEAT:
return ''
content = re.sub(r'<\|ref\|>image<\|/ref\|><\|det\|>.*?<\|/det\|>', '', content)
content = re.sub(r'<\|ref\|>.*?<\|/ref\|><\|det\|>.*?<\|/det\|>', '', content)
content = content.replace('\\coloneqq', ':=').replace('\\eqqcolon', '=:')
content = content.replace('\n\n\n\n', '\n\n').replace('\n\n\n', '\n\n')
return content.strip()The above utilities define three key components:
We set the BATCH_SIZE = 5 to control how quickly our first results appear versus how efficiently we use the GPU. For a 20-page PDF, progress updates in steps from 0% to 25% to 50% to 75% to 100%, instead of jumping directly from 0% to 100%.
This allows users to start asking questions as soon as the first 5 pages are indexed. Smaller batches improve time-to-first-result, while larger batches improve throughput and GPU utilization.
We used the native pdf_to_images_high_quality() function code from the original implementation using the PyMuPDF library to render each page into a PIL image at 144 DPI(comes from zoom = 144 / 72.0 = 2.0, which doubles the default 72 DPI resolution).
The dpi/72 zoom matrix controls rasterization quality, and alpha=False avoids transparency artifacts. If an image still contains an alpha channel, the function flattens it onto a white background to prevent odd blending that can degrade OCR.
The process_single_image() function (from the original codebase) wraps each page image into the exact dict structure vLLM expects (prompt + multi_modal_data.image), using DeepseekOCR2Processor().tokenize_with_images() which handles the entire image preprocessing pipeline including splitting large images into 2–6 tiles via dynamic_preprocess() based on aspect ratio, creating a padded 1024×1024 global view, applying tensor normalization, and generating the full token sequence with image masks that DeepseekOCR2ForCausalLM consumes.
The repo's config.CROP_MODE controls whether this dynamic tiling is applied, which improves accuracy on dense layouts with small text.
After generation, clean_ocr_output() strips special end-of-sentence tokens, removes detection markup blocks (<|ref|>...<|/ref|><|det|>...<|/det|>), normalizes a few LaTeX-like operators, and collapses excessive newlines, producing cleaner text that chunks better and retrieves more reliably in the downstream RAG index.
Next, we’ll use this cleaned output to build a lightweight page-level RAG index, so pages become searchable immediately after each batch finishes.
Now that we can extract clean text from each page, the next step is to make it searchable immediately. Instead of waiting for the full document to finish processing, we build a lightweight page-level Retrieval-Augmented Generation (RAG) engine that indexes content incrementally.
As each batch of pages is processed, their text is embedded and added to a FAISS index, allowing users to query the document while indexing is still in progress.
class PageRAG:
def __init__(self, chunk_size=1000):
self.chunk_size = chunk_size
self.index = faiss.IndexFlatIP(EMBED_DIM)
self.chunks = []
self.page_count = 0
self._lock = threading.Lock()
def reset(self):
with self._lock:
self.index = faiss.IndexFlatIP(EMBED_DIM)
self.chunks, self.page_count = [], 0
def add_page(self, page_num, text):
if not text or not text.strip():
with self._lock: self.page_count += 1
return
new_chunks = self._split(text, page_num)
texts = [c[1] for c in new_chunks]
embs = EMBED_MODEL.encode(texts, normalize_embeddings=True)
with self._lock:
self.index.add(np.array(embs, dtype=np.float32))
self.chunks.extend(new_chunks)
self.page_count += 1
def query(self, question, top_k=5):
with self._lock:
if self.index.ntotal == 0: return []
q = EMBED_MODEL.encode([question], normalize_embeddings=True)
k = min(top_k, self.index.ntotal)
scores, ids = self.index.search(np.array(q, dtype=np.float32), k)
return [{'page': self.chunks[i][0], 'score': float(s), 'text': self.chunks[i][1]}
for s, i in zip(scores[0], ids[0]) if i >= 0]
def _split(self, text, pn):
if len(text) <= self.chunk_size: return [(pn, text)]
parts, cur = [], ''
for p in re.split(r'\n{2,}', text):
if len(cur) + len(p) > self.chunk_size and cur:
parts.append((pn, cur.strip())); cur = p
else: cur += ('\n\n' + p if cur else p)
if cur.strip(): parts.append((pn, cur.strip()))
return parts or [(pn, text[:self.chunk_size])]
@property
def indexed_pages(self):
with self._lock: return self.page_countThe above class defines four key components:
faiss.IndexFlatIP for fast similarity search over normalized embeddings. As each page is processed, its content is immediately embedded and added to the index, enabling real-time retrieval without rebuilding the index._split() method breaks long page text into ~1000-character chunks based on paragraph boundaries. This improves semantic matching and avoids embedding overly long, noisy context while still preserving page numbers for source attribution.threading.Lock() protects index updates and reads. query() method embeds the user question, retrieves the top-k similar chunks, and returns the matched text along with page numbers and similarity scores. The indexed_pages property tracks progress so the UI can show how many pages are already searchable.In this step, we initialize the DeepSeek OCR-2 inference engine using vLLM. This is the core component that performs multimodal generation by taking the tokenized page images and producing structured OCR text. The configuration follows the official DeepSeek OCR-2 vLLM reference setup, but we wrap it inside a lazy loader load_ocr_engine() so the model loads only when processing starts, reducing startup time and avoiding unnecessary GPU allocation.
ocr_llm = None
ocr_sampling_params = None
def load_ocr_engine():
global ocr_llm, ocr_sampling_params
if ocr_llm is not None:
return
print(f'Loading {config.MODEL_PATH} via vLLM...')
ModelRegistry.register_model('DeepseekOCR2ForCausalLM', DeepseekOCR2ForCausalLM)
ocr_llm = LLM(
model=config.MODEL_PATH,
hf_overrides={'architectures': ['DeepseekOCR2ForCausalLM']},
block_size=256,
enforce_eager=False,
trust_remote_code=True,
max_model_len=8192,
swap_space=0,
max_num_seqs=config.MAX_CONCURRENCY,
tensor_parallel_size=1,
gpu_memory_utilization=0.9,
disable_mm_preprocessor_cache=True,
)
ocr_sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
logits_processors=[
NoRepeatNGramLogitsProcessor(
ngram_size=20, window_size=50,
whitelist_token_ids={128821, 128822},
)
],
skip_special_tokens=False,
include_stop_str_in_output=True,
)
print('vLLM engine loaded')This code snippet defines the following core components:
DeepseekOCR2ForCausalLM class from the repository to vLLM so it can handle image-token inputs produced by DeepseekOCR2Processor.LLM() parameters match the repository’s reference settings, including block_size=256, max_model_len=8192, gpu_memory_utilization=0.9, and disable_mm_preprocessor_cache=True. These settings are tuned for stable high-throughput OCR inference while keeping GPU memory usage predictable.temperature=0.0, large output limits, and a NoRepeatNGramLogitsProcessor to prevent repetitive text patterns, which is a common issue in long-form OCR generation.load_ocr_engine() is first called. Subsequent calls reuse the same instance, which avoids repeated GPU initialization and keeps the UI responsive.Now, let’s connect this engine to a batch processing loop that runs OCR page-by-page and streams the results into the RAG index for real-time querying.
This step is the heart of the app. We implement a background worker that takes an uploaded PDF and turns it into a searchable index progressively, instead of waiting for the entire document to finish OCR.
rag = PageRAG()
total_pages = 0
is_processing = False
processing_error = None
stop_requested = False
def process_pdf_background(pdf_path):
global total_pages, is_processing, processing_error, stop_requested
try:
is_processing = True
processing_error = None
stop_requested = False
load_ocr_engine()
if stop_requested: return
print('PDF loading...')
images = pdf_to_images_high_quality(pdf_path)
total_pages = len(images)
print(f'Rendered {total_pages} pages.')
if stop_requested: return
print('Preprocessing all images with DeepseekOCR2Processor...')
prompt = config.PROMPT
preprocess_fn = partial(process_single_image, prompt_str=prompt)
with ThreadPoolExecutor(max_workers=config.NUM_WORKERS) as executor:
all_inputs = list(executor.map(preprocess_fn, images))
print(f'Preprocessed {len(all_inputs)} pages.')
if stop_requested: return
num_batches = (total_pages + BATCH_SIZE - 1) // BATCH_SIZE
print(f'Running inference in {num_batches} batches of up to {BATCH_SIZE} pages...')
for batch_idx in range(num_batches):
if stop_requested:
print(f'Stopped before batch {batch_idx + 1}.')
return
start = batch_idx * BATCH_SIZE
end = min(start + BATCH_SIZE, total_pages)
batch_inputs = all_inputs[start:end]
print(f' Batch {batch_idx + 1}/{num_batches}: pages {start+1}-{end}...')
outputs_list = ocr_llm.generate(
batch_inputs,
sampling_params=ocr_sampling_params,
)
for i, output in enumerate(outputs_list):
page_num = start + i + 1
cleaned = clean_ocr_output(output.outputs[0].text)
rag.add_page(page_num, cleaned)
print(f' Page {page_num}/{total_pages} ({len(cleaned)} chars)')
print(f' Batch {batch_idx + 1} done. {rag.indexed_pages} pages now searchable.')
except Exception as e:
import traceback
processing_error = f'{e}\n\n{traceback.format_exc()}'
print(f'ERROR: {processing_error}')
finally:
is_processing = False
if stop_requested:
print(f'Stopped. {rag.indexed_pages} pages indexed.')
else:
print('Processing complete.')The flow for our pipeline includes rendering pages, pre-processing inputs, running vLLM inference in mini-batches, then cleaning OCR output, and finally adding each page to the FAISS-backed PageRAG. Here is a detailed analysis of each step:
total_pages, is_processing, processing_error, stop_requested) track progress and failure modes so the UI can show live status, handle stop/reset, and avoid conflicting runs.ThreadPoolExecutor(max_workers=config.NUM_WORKERS) converts page images into model-ready multimodal inputs in parallel. This keeps the GPU busy later by ensuring inputs are prepared ahead of inference.ocr_llm.generate() once over all pages (the official script’s default), the code computes num_batches and processes pages in chunks of BATCH_SIZE. This enables progressive indexing, so the users can start asking questions after the first 5 pages (BATCH_SIZE = 5) are indexed, rather than waiting for the full document.stop_requested is checked before expensive stages and at the start of each batch. That makes the Stop button predictable: it halts between batches, after the current batch finishes, so you don’t end up with a half-written state or partial outputs.At this point, we have an end-to-end pipeline that converts a PDF into a growing search index, so users can query the document while processing continues in the background. Next, we’ll add the UI callbacks that connect this worker to the Gradio application.
At this stage, the OCR and indexing pipeline is running in the background, but the application still needs a control layer that connects user actions to the processing logic.
def start_processing(pdf_file):
global total_pages
if pdf_file is None: return 'Upload a PDF first.'
if is_processing: return 'Already processing.'
rag.reset()
total_pages = 0
threading.Thread(
target=process_pdf_background,
args=(pdf_file.name,),
daemon=True,
).start()
return 'Processing started! Pages become searchable in batches.'
def stop_processing():
global stop_requested
if not is_processing:
return 'Nothing is running.'
stop_requested = True
return 'Stop requested. Will halt after current batch.'
def reset_all():
global total_pages, processing_error, stop_requested
if is_processing:
return 'Cannot reset while processing. Stop first.'
rag.reset()
total_pages = 0
processing_error = None
stop_requested = False
return 'Reset complete. Upload a new PDF.'
def refresh_progress():
idx, tp = rag.indexed_pages, total_pages
if processing_error:
msg, pct, c = f'Error: {processing_error[:200]}', 100, '#ef4444'
elif stop_requested and is_processing:
pct = int(idx / tp * 100) if tp > 0 else 0
msg, c = 'Stopping after current batch...', '#f59e0b'
elif not is_processing and stop_requested:
pct = int(idx / tp * 100) if tp > 0 else 0
msg, c = f'Stopped. {idx} pages indexed -- you can still ask questions.', '#f59e0b'
elif not is_processing and idx == 0:
msg, pct, c = 'Upload a PDF and click Process.', 0, '#6b7280'
elif is_processing and tp == 0:
msg, pct, c = 'Loading vLLM engine & rendering pages...', 0, '#3b82f6'
elif is_processing:
pct = int(idx / tp * 100)
msg, c = f'{idx}/{tp} pages indexed -- ask questions now!', '#3b82f6'
else:
msg, pct, c = f'All {idx} pages indexed.', 100, '#10b981'
bar_min = '32px' if pct > 0 else '0'
pct_text = f'{pct}%' if pct > 5 else ''
return (f'<div style=">'
f'<div style="font-weight:500">{msg}</div>'
f'<div style="background:#1f2937;border-radius:10px;overflow:hidden;height:28px">'
f'<div style="width:{pct}%;background:{c};height:100%;border-radius:10px;'
f'transition:width .6s;display:flex;align-items:center;'
f'justify-content:center;color:white;font-weight:600;'
f'min-width:{bar_min}">{pct_text}</div></div></div>')
def answer_question(question):
if not question.strip(): return ''
idx = rag.indexed_pages
if idx == 0:
if is_processing:
return ('**Processing in progress -- first batch not done yet.**\n\n'
'Pages become searchable in batches of ' + str(BATCH_SIZE) + '.\n'
'Try again shortly!')
return 'Upload a PDF and click **Process** first.'
results = rag.query(question, top_k=5)
if not results: return 'No relevant results found.'
lines = []
if is_processing:
lines.append(f'> *Searched {idx} of {total_pages} pages (still processing).*\n')
lines.append(f'**Source pages: {list(dict.fromkeys(r["page"] for r in results))}**\n')
for i, r in enumerate(results, 1):
lines += ['---', f'**Result {i}** | Page {r["page"]} | score: {r["score"]:.3f}\n',
r['text'][:600]]
if len(r['text']) > 600: lines.append(f'\n*...{len(r["text"]):,} chars total*')
return '\n'.join(lines)This control layer handles five core responsibilities:
start_processing() function validates the input, resets the RAG index, and launches process_pdf_background() in a daemon thread. stop_processing() function sets a stop_requested flag rather than terminating execution immediately. The background worker checks this flag between batches, ensuring the system stops cleanly without corrupting the index.reset_all() function clears the FAISS index, progress counters, and error state. It also prevents accidental resets while processing is still active, which protects against inconsistent application state.refresh_progress() function to read the number of indexed pages from PageRAG and generate a dynamic HTML progress bar. It also communicates system states such as loading, active processing, stopping, completion, or error.In the final step, we’ll connect these callbacks to a Gradio interface to expose the complete workflow through a simple web UI.
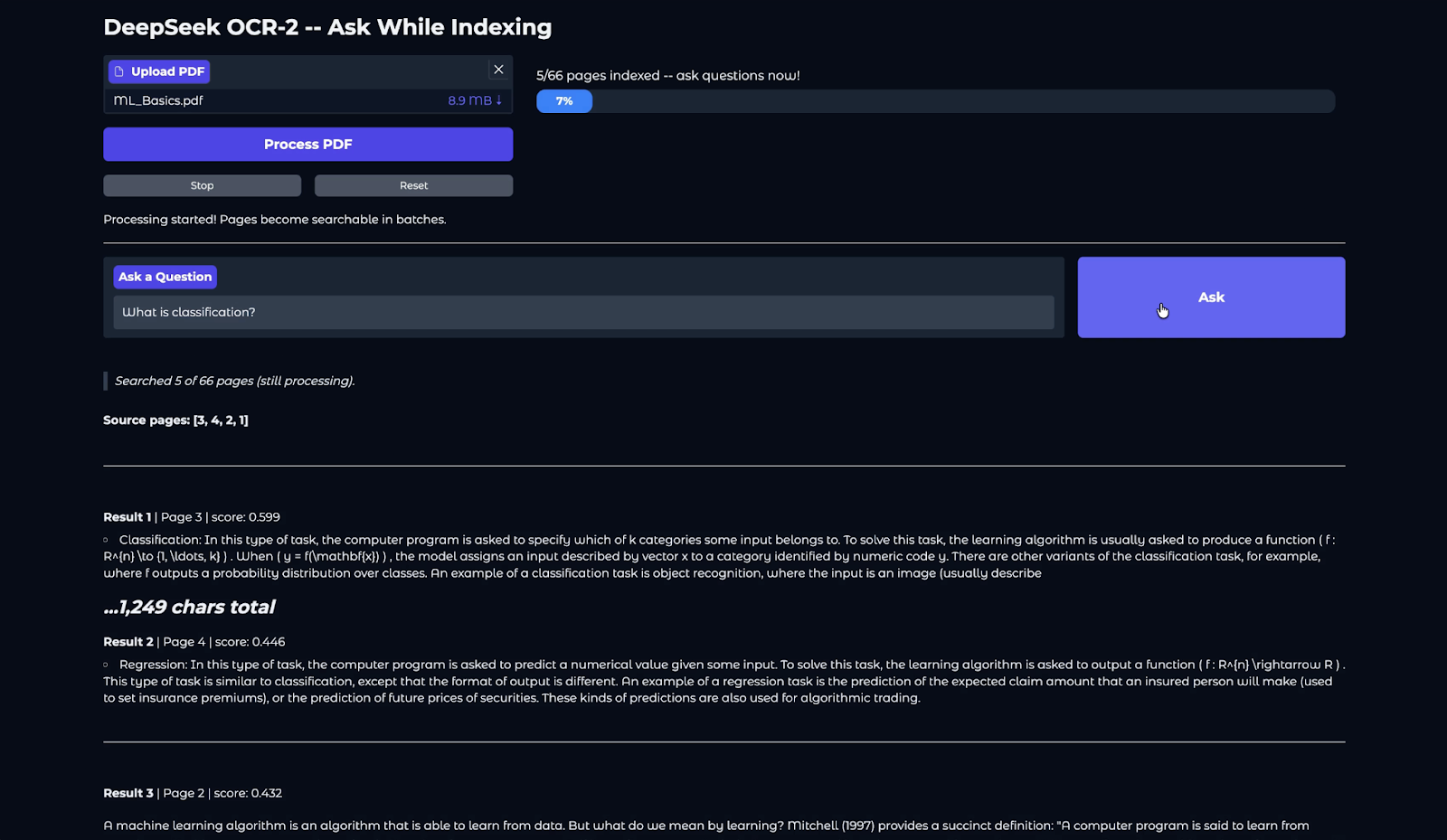
In this final step, we wrap everything into a simple Gradio application. The UI is designed to allow users to upload a PDF, start processing, and begin asking questions before indexing completes.
with gr.Blocks(title='DeepSeek OCR-2', theme=gr.themes.Soft()) as demo:
gr.Markdown('# DeepSeek OCR-2 -- Ask While Indexing\n')
with gr.Row(equal_height=True):
with gr.Column(scale=1, min_width=250):
pdf_input = gr.File(label='Upload PDF', file_types=['.pdf'])
process_btn = gr.Button('Process PDF', variant='primary', size='lg')
with gr.Row():
stop_btn = gr.Button('Stop', variant='stop', size='sm')
reset_btn = gr.Button('Reset', variant='secondary', size='sm')
status_output = gr.Markdown()
with gr.Column(scale=2):
progress_bar = gr.HTML(
value='<div style=">Upload a PDF and click Process.</div>')
gr.Markdown('---')
with gr.Row(equal_height=True):
question_input = gr.Textbox(
label='Ask a Question',
placeholder='What is this document about?',
lines=1, scale=4)
ask_btn = gr.Button('Ask', variant='secondary', scale=1, min_width=100)
answer_output = gr.Markdown()
timer = gr.Timer(2)
timer.tick(fn=refresh_progress, outputs=progress_bar)
process_btn.click(fn=start_processing, inputs=pdf_input, outputs=status_output)
stop_btn.click(fn=stop_processing, outputs=status_output)
reset_btn.click(fn=reset_all, outputs=status_output)
ask_btn.click(fn=answer_question, inputs=question_input, outputs=answer_output)
question_input.submit(fn=answer_question, inputs=question_input, outputs=answer_output)
print('Launching demo...')
demo.queue()
demo.launch(debug=True, share=True)The Gradio application contains two columns. The left column contains the PDF upload widget and the Process/Stop/Reset buttons, while the right column shows a live HTML progress bar. This makes the app feel responsive even when OCR is still running. Here are some key features of our app:
gr.Timer(2) calls refresh_progress() every two seconds and updates the progress bar HTML. Since indexing happens in batches, users see progress move in steps (and the messages change based on states like loading, stopping, error, or completion)..click() handlers connect UI actions directly to your backend functions, such as start_processing() launches the background worker, stop_processing() requests a clean stop, reset_all() clears state, and answer_question() runs retrieval over whatever pages are indexed so far.Finally, demo.launch() launches the app in Colab, provides a shareable link, renders it inline, and enables debug logs to help diagnose issues during development.
In this tutorial, we built a complete vision-first document intelligence pipeline using DeepSeek OCR-2. Starting from a raw PDF, we rendered pages into high-quality images, ran multimodal OCR through vLLM, cleaned and structured the extracted text, and incrementally indexed it into a FAISS-based RAG store.
By processing pages in mini-batches, the application enables a “ask while indexing” experience where users can start querying the document after the first batch instead of waiting for full completion.
However, two noticeable limitations emerged during testing. The formula-heavy regions are not always transcribed accurately, which is a known challenge for vision-language OCR models, even with grounding prompts.
Also, some longer pages exhibit repetitive output patterns. The official pipeline mitigates this with a NoRepeatNGramLogitsProcessor (ngram_size=20), but dense tables and multi-column layouts can still trigger generation loops, in which case the page is silently skipped via the SKIP_REPEAT flag.
To take this further, readers can experiment with adding a lightweight LLM layer (like, calling the Anthropic or OpenAI API) to summarize retrieved chunks instead of returning raw snippets.
Other practical improvements include persisting the FAISS index to disk for reuse across sessions, supporting multiple PDFs in a single index, exposing tunable parameters like BATCH_SIZE and top_k directly in the Gradio UI, or adding structure-aware chunking (headings, tables, and section boundaries) to improve retrieval precision.
Top DataCamp Courses
Curso
Curso
Curso
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Bex Tuychiev