programa
Llama Fundamentals
4 h
DeepSeek-R1 es ideal para los sistemas basados en RAG gracias a su rendimiento optimizado, sus funciones avanzadas de búsqueda vectorial y su flexibilidad en distintos entornos, desde configuraciones locales hasta despliegues escalables. He aquí algunas razones por las que es eficaz:
Nuestro proyecto de demostración se centra en construir un chatbot RAG utilizando DeepSeek-R1 y Gradio.
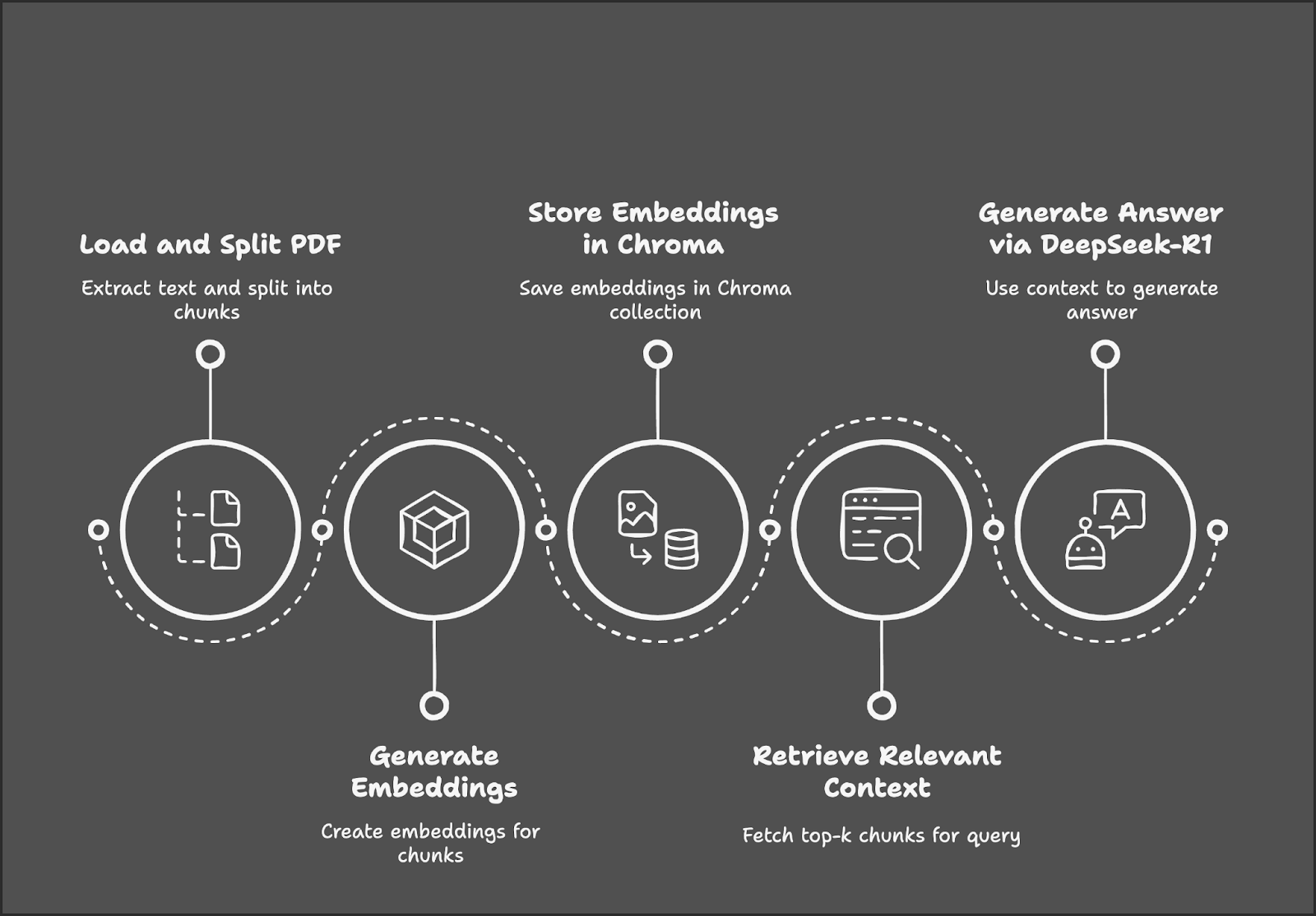
El proceso comienza con la carga y división de un PDF en trozos de texto, seguido de la generación de incrustaciones para esos trozos. Estas incrustaciones se almacenan en una base de datos Chroma para una recuperación eficaz. Cuando un usuario envía una consulta, el sistema recupera los trozos de texto más relevantes y utiliza DeepSeek-R1 para generar una respuesta basada en el contexto recuperado.
Antes de empezar, asegurémonos de que tenemos instaladas las siguientes herramientas y bibliotecas:
Ejecuta los siguientes comandos para instalar las dependencias necesarias:
!pip install langchain chromadb gradio ollama pymypdf
!pip install -U langchain-communityUna vez instaladas las dependencias anteriores, ejecuta los siguientes comandos de importación:
import ollama
import re
import gradio as gr
from concurrent.futures import ThreadPoolExecutor
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.embeddings import OllamaEmbeddings
from chromadb.config import Settings
from chromadb import Client
from langchain.vectorstores import ChromaUtilizaremos PyMuPDFLoader de LangChain para extraer el texto de la versión PDF del libro Fundamentos de los LLM de Tong Xiao y Jingbo Zhu: se trata de un libro con muchas matemáticas, lo que significa que nuestro chatbot debería ser capaz de explicar bien las matemáticas que hay detrás de los LLM. Puedes encontrar el libro en arXiv.
# Load the document using PyMuPDFLoader
loader = PyMuPDFLoader("/path/to/Foundations_of_llms.pdf")
documents = loader.load()Una vez cargado el documento, podemos empezar a dividir el texto en trozos para su posterior procesamiento.
Dividiremos el texto extraído en trozos más pequeños y superpuestos para una mejor recuperación del contexto. Puedes variar el tamaño del trozo y el solapamiento del trozo según tu sistema dentro de la función RecursiveCharacterTextSpilitter().
# Split the document into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)Ahora tenemos los trozos de texto extraídos, listos para convertirlos en incrustaciones.
Utilizaremos Ollama Embeddings basado en DeepSeek-R1 para generar las incrustaciones de documentos. Dependiendo del tamaño del documento, la generación de incrustaciones puede llevar tiempo, por lo que es preferible paralelizarla para un procesamiento más rápido.
Nota: model="deepseek-r1" considera por defecto el modelo de parámetros 7B. Puedes cambiarlo según sea necesario a 8B, 14B, 32B, 70B o 671B. Sustituye la X del nombre del modelo siguiente por el tamaño del modelo: model="deepseek-r1:X"
# Initialize Ollama embeddings using DeepSeek-R1
embedding_function = OllamaEmbeddings(model="deepseek-r1")
# Parallelize embedding generation
def generate_embedding(chunk):
return embedding_function.embed_query(chunk.page_content)
with ThreadPoolExecutor() as executor:
embeddings = list(executor.map(generate_embedding, chunks))La función anterior inicializa DeepSeek-R1 a través de Ollama para generar incrustaciones semánticas de alta dimensión, que luego se utilizarán para la recuperación de documentos basada en similitudes.
La función generate_embedding() toma el texto de un fragmento de documento y genera su incrustación. Por último, ThreadPoolExecutor() aplica generate_embedding() a cada trozo de forma concurrente, recopilando las incrustaciones en una lista para un procesamiento más rápido en comparación con la ejecución secuencial.
Almacenaremos las incrustaciones y los trozos de texto correspondientes en una base de datos vectorial de alto rendimiento, Chroma.
# Initialize Chroma client and create/reset the collection
client = Client(Settings())
client.delete_collection(name="foundations_of_llms") # Delete existing collection (if any)
collection = client.create_collection(name="foundations_of_llms")
# Add documents and embeddings to Chroma
for idx, chunk in enumerate(chunks):
collection.add(
documents=[chunk.page_content],
metadatas=[{'id': idx}],
embeddings=[embeddings[idx]],
ids=[str(idx)] # Ensure IDs are strings
)Empezamos siguiendo estos pasos para almacenar las incrustaciones:
Client(Settings()) inicializa el cliente Chroma para gestionar el almacén de vectores. client.delete_collection() para evitar errores. Por último, utiliza client.create_collection() para crear una nueva colección que almacene los trozos de documentos y sus incrustaciones.collection.add() almacena:chunk.page_content){'id': idx}) para hacer referencia al fragmentoEsta configuración garantiza que cada trozo de documento se indexe correctamente para una recuperación eficaz basada en vectores.
Inicializaremos el recuperador Chroma, asegurándonos de que utiliza las mismas incrustaciones DeepSeek-R1 para las consultas.
# Initialize retriever using Ollama embeddings for queries
retriever = Chroma(collection_name="foundations_of_llms", client=client, embedding_function=embedding_function).as_retriever()El recuperador Chroma se conecta a la colección "foundations_of_llms" y utiliza incrustaciones DeepSeek-R1 a través de Ollama para incrustar las consultas de los usuarios. Recupera los trozos de documentos más relevantes basándose en la similitud vectorial para obtener respuestas conscientes del contexto.
A continuación, recuperaremos los trozos de texto más relevantes y les daremos formato para que DeepSeek-R1 genere respuestas.
def retrieve_context(question):
# Retrieve relevant documents
results = retriever.invoke(question)
# Combine the retrieved content
context = "\n\n".join([doc.page_content for doc in results])
return contextLa función retrieve_context incorpora la consulta del usuario mediante DeepSeek-R1 y recupera los trozos de documentos más relevantes mediante el recuperador Chroma. A continuación, combina el contenido de los trozos recuperados en una única cadena de contexto para su posterior procesamiento.
Ahora, tenemos la pregunta y el contexto recuperado. A continuación, envíalo a DeepSeek-R1 a través de Ollama para obtener nuestra respuesta final.
def query_deepseek(question, context):
# Format the input prompt
formatted_prompt = f"Question: {question}\n\nContext: {context}"
# Query DeepSeek-R1 using Ollama
response = embedding_function.chat(
model="deepseek-r1",
messages=[{'role': 'user', 'content': formatted_prompt}]
)
# Clean and return the response
response_content = response['message']['content']
final_answer = re.sub(r'<think>.*?</think>', '', response_content, flags=re.DOTALL).strip()
return final_answerPara obtener la respuesta final, empezamos combinando la pregunta del usuario y el contexto recuperado en una pregunta estructurada. A continuación, envía esta consulta al modelo DeepSeek-R1 a través de Ollama para recibir una respuesta. Para que el resultado final sea presentable, eliminamos las etiquetas innecesarias y devolvemos la respuesta final.
Ya tenemos en marcha nuestra tubería RAG. Ahora, utilizaremos Gradio para crear una interfaz interactiva para que los usuarios formulen preguntas relacionadas con su base de conocimientos (Fundamentos de los LLM en este caso).
def ask_question(question):
# Retrieve context and generate an answer using RAG
context = retrieve_context(question)
answer = query_deepseek(question, context)
return answer
# Set up the Gradio interface
interface = gr.Interface(
fn=ask_question,
inputs="text",
outputs="text",
title="RAG Chatbot: Foundations of LLMs",
description="Ask any question about the Foundations of LLMs book. Powered by DeepSeek-R1."
)
interface.launch()La función ask_question() recupera el contexto relevante utilizando el recuperador Chroma y genera la respuesta final mediante DeepSeek-R1. La interfaz de Gradio, construida con gr.Interface(), permite a los usuarios hacer preguntas de forma interactiva y recibir respuestas contextualmente precisas y fundamentadas.
¡Enhorabuena! Ahora tienes un chatbot que funciona localmente, listo para hablar de cualquier cosa relacionada con los LLM.
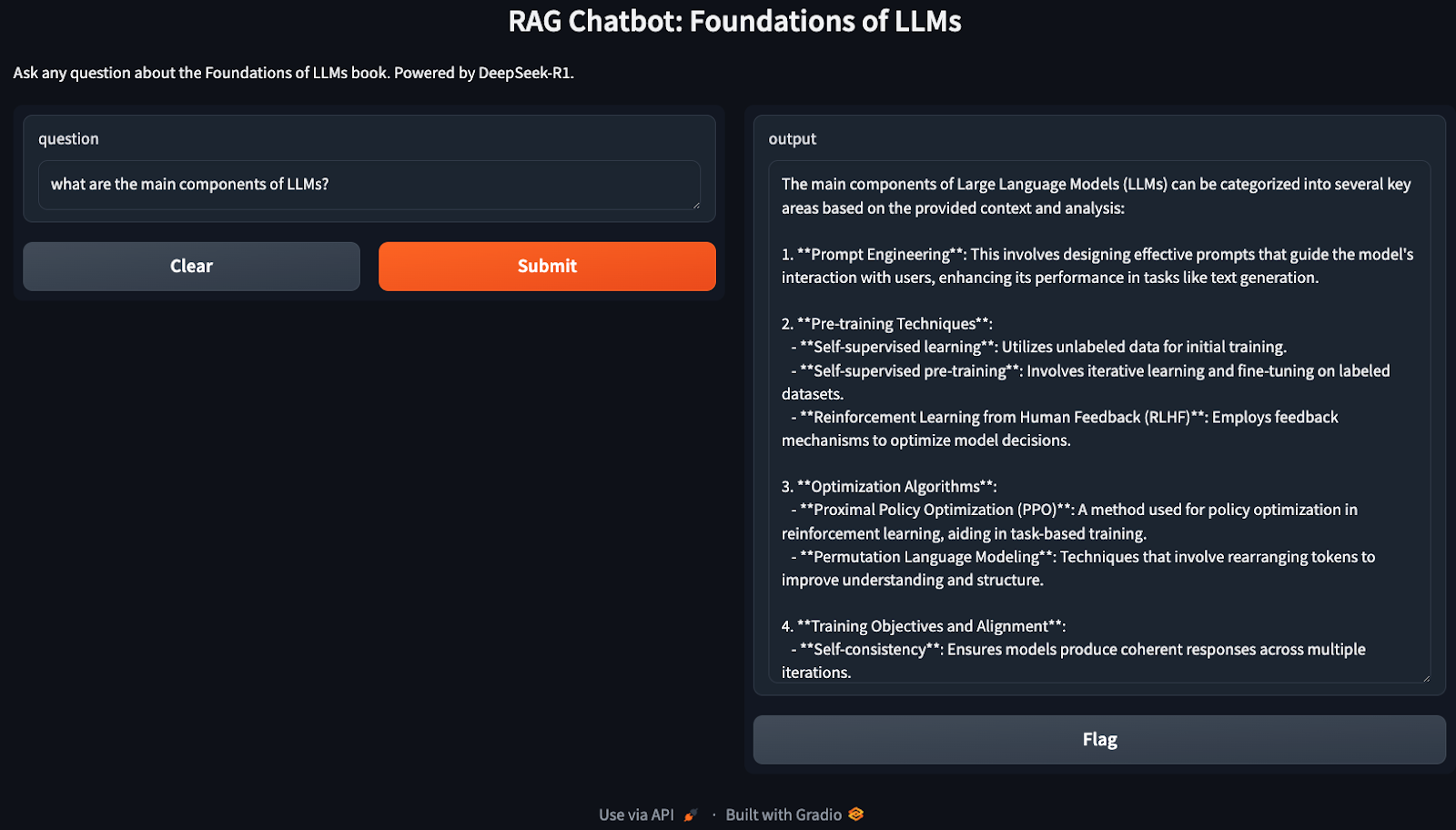
La demostración anterior cubre una implementación muy básica de la GAR, que puede optimizarse aún más para aumentar su eficacia. Aquí tienes algunas cosas que puedes probar:
chunk_size y chunk_overlap para equilibrar el rendimiento y la calidad de la recuperación.En este tutorial, construimos un chatbot local basado en RAG utilizando DeepSeek-R1 y Chroma para la recuperación, lo que garantiza respuestas precisas y ricas en contexto a preguntas basadas en una gran base de conocimientos.
Para saber más sobre DeepSeek, te recomiendo estos blogs:
Aprende IA con estos cursos
programa
Curso
Curso
Tutorial
Ryan Ong
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Adel Nehme
Tutorial
Abid Ali Awan