
Curso
Introducción a los LLMs en Python
3 h
33.6K
DeepSeek ha trastornado el panorama de la IA, desafiando el dominio de OpenAI al lanzar una nueva serie de modelos de razonamiento avanzado. ¿Y lo mejor? Estos modelos son de uso totalmente gratuito y sin restricciones, lo que los hace accesibles a todo el mundo.
En este tutorial, afinaremos el modelo DeepSeek-R1-Distill-Llama-8B en el conjunto de datos Cadena de Pensamiento Médico de Cara Abrazada. Este modelo destilado de DeepSeek-R1 se creó ajustando el modelo Llama 3.1 8B a los datos generados con DeepSeek-R1. Presenta capacidades de razonamiento similares a las del modelo original.
Si eres nuevo en LLMs y el ajuste fino, te recomiendo encarecidamente que tomes el curso Introducción a los LLM en Python en Python.

Imagen del autor
La empresa china de IA DeepSeek AI ha puesto a disposición pública sus modelos de razonamiento de primera generación, DeepSeek-R1 y DeepSeek-R1-Zero, que rivalizan con el o1 de OpenAI en rendimiento en tareas de razonamiento como matemáticas, codificación y lógica. Puedes leer nuestra guía completa de DeepSeek R1 para obtener más información.
DeepSeek-R1-Zero es el primer modelo de código abierto entrenado únicamente con aprendizaje por refuerzo (RL) en lugar del ajuste fino supervisado (SFT) como paso inicial. Este enfoque permite al modelo explorar de forma independiente cadena de pensamiento (CoT), resolver problemas complejos y refinar iterativamente sus resultados. Sin embargo, conlleva retos como pasos de razonamiento repetitivos, mala legibilidad y mezcla de idiomas que pueden afectar a su claridad y usabilidad.
DeepSeek-R1 se introdujo para superar las limitaciones de DeepSeek-R1-Zero incorporando datos de arranque en frío antes del aprendizaje por refuerzo, proporcionando una base sólida para tareas de razonamiento y no razonamiento.
Este entrenamiento en varias fases permite al modelo alcanzar un rendimiento de vanguardia, comparable al de OpenAI-o1, en pruebas de matemáticas, código y razonamiento, al tiempo que mejora la legibilidad y coherencia de sus resultados.
Junto con los grandes modelos lingüísticos que requieren una gran potencia de cálculo y memoria para funcionar, DeepSeek también ha introducido modelos destilados. Estos modelos más pequeños y eficientes han demostrado que aún pueden alcanzar un rendimiento de razonamiento notable.
Con un rango de 1,5B a 70B parámetros, estos modelos conservan una gran capacidad de razonamiento, y DeepSeek-R1-Distill-Qwen-32B supera a OpenAI-o1-mini en múltiples pruebas comparativas.
Los modelos más pequeños heredan los patrones de razonamiento de los modelos más grandes, lo que demuestra la eficacia del proceso de destilación.
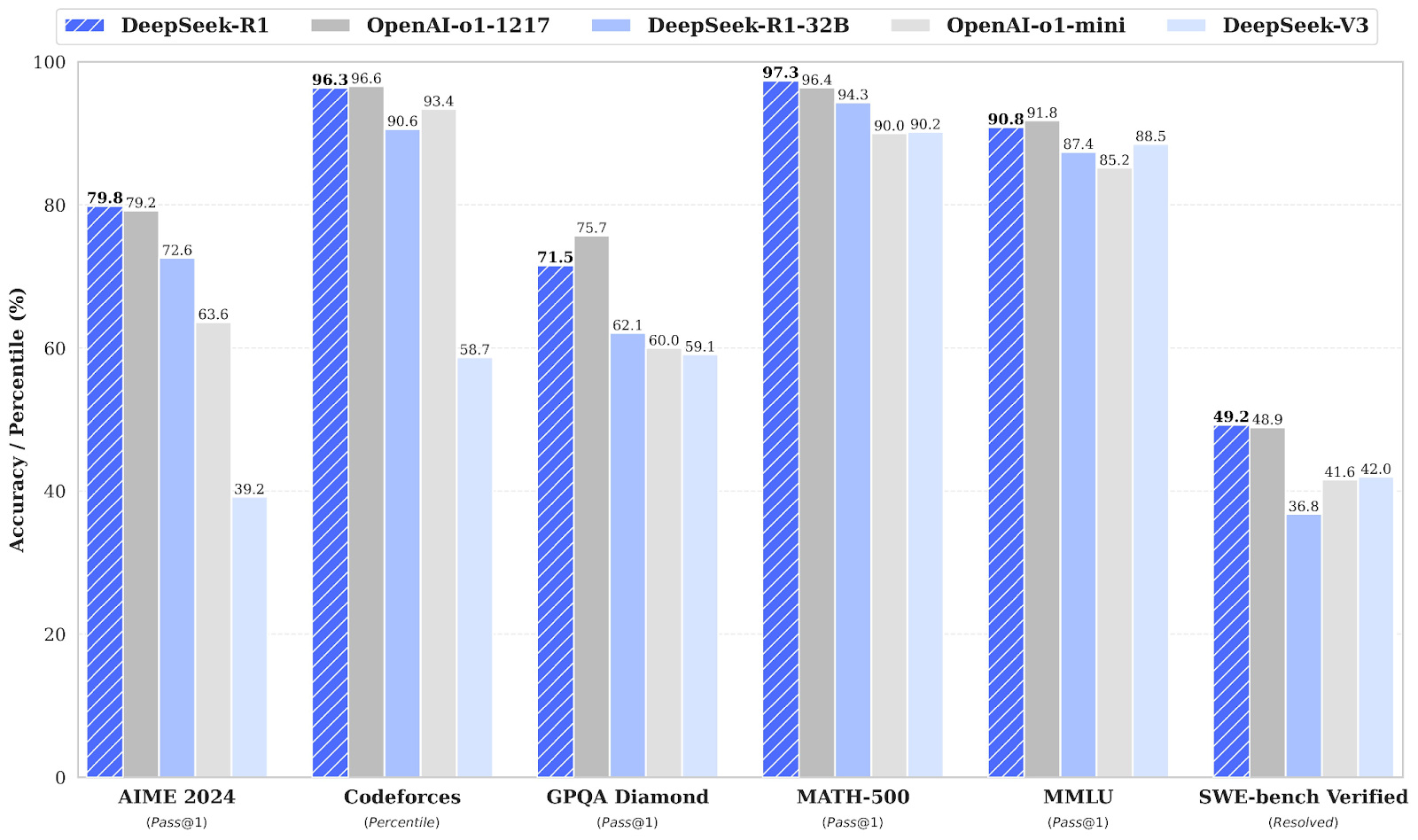
Fuente: deepseek-ai/DeepSeek-R1
Lee la páginaDeepSeek-R1: Características, comparación con o1, modelos destilados y más blog para conocer sus principales características, proceso de desarrollo, modelos destilados, acceso, precio y comparación con OpenAI o1.
Para ajustar el modelo DeepSeek R1, puedes seguir los pasos que se indican a continuación:
Para este proyecto, utilizamos Kaggle como IDE en la nube porque proporciona acceso gratuito a las GPU, que a menudo son más potentes que las disponibles en Google Colab. Para empezar, abre un nuevo cuaderno Kaggle y añade tu ficha Cara de abrazo y tu ficha Pesos y prejuicios como secretos.
Puedes añadir secretos navegando a la pestaña Add-ons de la interfaz del cuaderno Kaggle y seleccionando la opción Secrets.
Después de configurar los secretos, instala el paquete Python unsloth. Unsloth es un marco de trabajo de código abierto diseñado para que el ajuste fino de grandes modelos lingüísticos (LLM) sea 2 veces más rápido y eficiente en memoria.
Lee nuestra Guía de Desenredado: Optimizar y acelerar el ajuste fino LLM para conocer las principales características de Unsloth, sus diversas funciones y cómo optimizar tu flujo de trabajo de ajuste fino .
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.gitInicia sesión en la CLI de Cara Abrazada utilizando la API de Cara Abrazada que hemos extraído de forma segura de Kaggle Secrets.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Entra en Pesos y Sesgos (wandb) utilizando tu clave API y crea un nuevo proyecto para seguir los experimentos y el progreso del ajuste.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)Para este proyecto, estamos cargando la versión Unsloth de DeepSeek-R1-Distil-Llama-8B. Además, cargaremos el modelo en cuantización de 4 bits para optimizar el uso de memoria y el rendimiento.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
token = hf_token,
)Para crear un estilo de pregunta para el modelo, definiremos una pregunta del sistema e incluiremos marcadores de posición para la generación de preguntas y respuestas. La indicación guiará al modelo para que piense paso a paso y dé una respuesta lógica y precisa.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""En este ejemplo, proporcionaremos una pregunta médica a prompt_style, la convertiremos en tokens, y luego pasaremos los tokens al modelo para que genere la respuesta.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])Incluso sin un ajuste fino, nuestro modelo generó con éxito una cadena de pensamiento y proporcionó un razonamiento antes de dar la respuesta final. El proceso de razonamiento se encapsula dentro de las etiquetas <think></think>.
Entonces, ¿por qué seguimos necesitando un ajuste fino? El proceso de razonamiento, aunque detallado, era prolijo y no conciso. Además, la respuesta final se presentó en un formato de viñetas, que se desvía de la estructura y el estilo del conjunto de datos que queremos afinar.
<think>
Okay, so I have this medical question to answer. Let me try to break it down. The patient is a 61-year-old woman with a history of involuntary urine loss during activities like coughing or sneezing, but she doesn't leak at night. She's had a gynecological exam and a Q-tip test. I need to figure out what cystometry would show regarding her residual volume and detrusor contractions.
First, I should recall what I know about urinary incontinence. Involuntary urine loss during activities like coughing or sneezing makes me think of stress urinary incontinence. Stress incontinence typically happens when the urethral sphincter isn't strong enough to resist increased abdominal pressure from activities like coughing, laughing, or sneezing. This usually affects women, especially after childbirth when the pelvic muscles and ligaments are weakened.
The Q-tip test is a common diagnostic tool for stress urinary incontinence. The test involves inserting a Q-tip catheter, which is a small balloon catheter, into the urethra. The catheter is connected to a pressure gauge. The patient is asked to cough, and the pressure reading is taken. If the pressure is above normal (like above 100 mmHg), it suggests that the urethral sphincter isn't closing properly, which is a sign of stress incontinence.
So, based on the history and the Q-tip test, the diagnosis is likely stress urinary incontinence. Now, moving on to what cystometry would show. Cystometry, also known as a filling cystometry, is a diagnostic procedure where a catheter is inserted into the bladder, and the bladder is filled with a liquid to measure how much it can hold (residual volume) and how it responds to being filled (like during a cough or sneeze). This helps in assessing the capacity and compliance of the bladder.
In a patient with stress incontinence, the bladder's capacity might be normal, but the sphincter's function is impaired. So, during the cystometry, the residual volume might be within normal limits because the bladder isn't overfilled. However, when the patient is asked to cough or perform a Valsalva maneuver, the detrusor muscle (the smooth muscle layer of the bladder) might not contract effectively, leading to an increase in intra-abdominal pressure, which might cause leakage.
Wait, but detrusor contractions are usually associated with voiding. In stress incontinence, the issue isn't with the detrusor contractions but with the sphincter's inability to prevent leakage. So, during cystometry, the detrusor contractions would be normal because they are part of the normal voiding process. However, the problem is that the sphincter doesn't close properly, leading to leakage.
So, putting it all together, the residual volume might be normal, but the detrusor contractions would be normal as well. The key finding would be the impaired sphincter function leading to incontinence, which is typically demonstrated during the Q-tip test and clinical history. Therefore, the cystometry would likely show normal residual volume and normal detrusor contractions, but the underlying issue is the sphincter's inability to prevent leakage.
</think>
Based on the provided information, the cystometry findings in this 61-year-old woman with stress urinary incontinence would likely demonstrate the following:
1. **Residual Volume**: The residual volume would be within normal limits. This is because the bladder's capacity is typically normal in cases of stress incontinence, where the primary issue lies with the sphincter function rather than the bladder's capacity.
2. **Detrusor Contractions**: The detrusor contractions would also be normal. These contractions are part of the normal voiding process and are not impaired in stress urinary incontinence. The issue is not with the detrusor muscle but with the sphincter's inability to prevent leakage.
In summary, the key findings of the cystometry would be normal residual volume and normal detrusor contractions, highlighting the sphincteric defect as the underlying cause of the incontinence.<|end▁of▁sentence|>Modificaremos ligeramente el estilo de aviso para procesar el conjunto de datos añadiendo el tercer marcador de posición para la columna de la cadena de pensamiento compleja.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Escribe la función de Python que creará una columna "texto" en el conjunto de datos, que consistirá en el estilo de aviso del tren. Rellena los marcadores de posición con preguntas, cadenas de texto y respuestas.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}Cargaremos las primeras 500 muestras del FreedomIntelligence/medical-o1-razonamiento-SFT que está disponible en el hub Cara Abrazada. Después, mapearemos la columna text utilizando la función formatting_prompts_func.
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT","en", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]Como podemos ver, la columna de texto tiene una indicación del sistema, instrucciones, cadena de pensamiento y la respuesta.
"Below is an instruction that describes a task, paired with an input that provides further context. \nWrite a response that appropriately completes the request. \nBefore answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.\n\n### Instruction:\nYou are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning. \nPlease answer the following medical question. \n\n### Question:\nA 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?\n\n### Response:\n<think>\nOkay, let's think about this step by step. There's a 61-year-old woman here who's been dealing with involuntary urine leakages whenever she's doing something that ups her abdominal pressure like coughing or sneezing. This sounds a lot like stress urinary incontinence to me. Now, it's interesting that she doesn't have any issues at night; she isn't experiencing leakage while sleeping. This likely means her bladder's ability to hold urine is fine when she isn't under physical stress. Hmm, that's a clue that we're dealing with something related to pressure rather than a bladder muscle problem. \n\nThe fact that she underwent a Q-tip test is intriguing too. This test is usually done to assess urethral mobility. In stress incontinence, a Q-tip might move significantly, showing urethral hypermobility. This kind of movement often means there's a weakness in the support structures that should help keep the urethra closed during increases in abdominal pressure. So, that's aligning well with stress incontinence.\n\nNow, let's think about what would happen during cystometry. Since stress incontinence isn't usually about sudden bladder contractions, I wouldn't expect to see involuntary detrusor contractions during this test. Her bladder isn't spasming or anything; it's more about the support structure failing under stress. Plus, she likely empties her bladder completely because stress incontinence doesn't typically involve incomplete emptying. So, her residual volume should be pretty normal. \n\nAll in all, it seems like if they do a cystometry on her, it will likely show a normal residual volume and no involuntary contractions. Yup, I think that makes sense given her symptoms and the typical presentations of stress urinary incontinence.\n</think>\nCystometry in this case of stress urinary incontinence would most likely reveal a normal post-void residual volume, as stress incontinence typically does not involve issues with bladder emptying. Additionally, since stress urinary incontinence is primarily related to physical exertion and not an overactive bladder, you would not expect to see any involuntary detrusor contractions during the test.<|end▁of▁sentence|>"Utilizando los módulos objetivo, configuraremos el modelo añadiendo el adoptante de bajo rango al modelo.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)A continuación, configuraremos los argumentos de entrenamiento y el entrenador proporcionando el modelo, los tokenizadores, el conjunto de datos y otros parámetros de entrenamiento importantes que optimizarán nuestro proceso de ajuste.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)Ejecuta el siguiente comando para iniciar el entrenamiento.
trainer_stats = trainer.train()El proceso de formación duró 44 minutos. La pérdida de entrenamiento se ha reducido gradualmente, lo que es una buena señal de un mejor rendimiento del modelo.
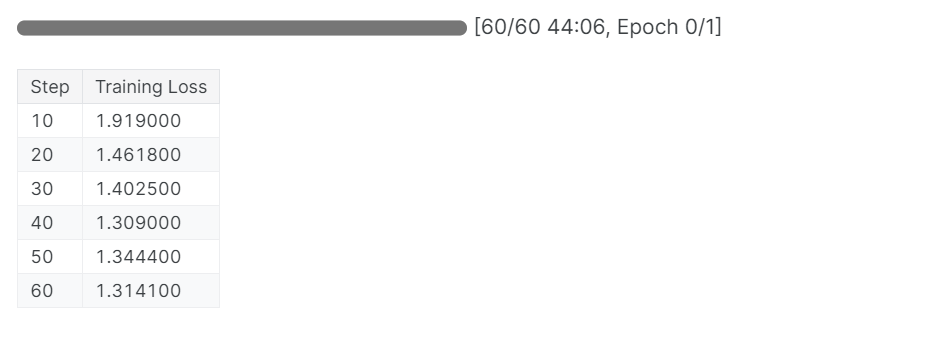
Puedes ver el informe de evaluación del modelo de llenado en el tablero de mandos de Pesos y contrapesos accediendo al sitio web y viendo el proyecto.
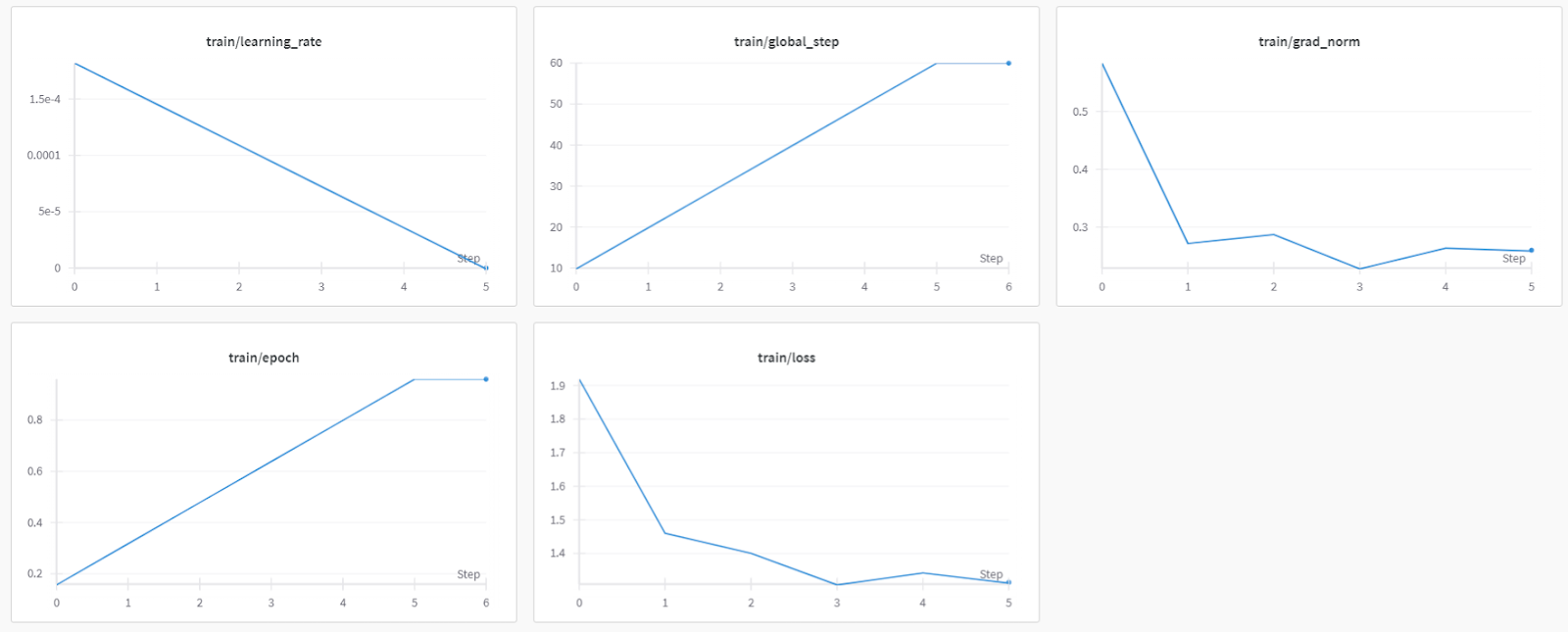
Si tienes problemas para ejecutar el código anterior, consulta la sección Ajuste fino de DeepSeek R1 (Modelo de razonamiento) Cuaderno Kaggle.
Para comparar los resultados, haremos al modelo afinado la misma pregunta que antes para ver qué ha cambiado.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Esto es mucho mejor y más preciso. La cadena de pensamiento era directa, y la respuesta sencilla y en un párrafo. La puesta a punto fue un éxito.
<think>
Okay, so let's think about this. We have a 61-year-old woman who's been dealing with involuntary urine loss during things like coughing or sneezing, but she's not leaking at night. That suggests she might have some kind of problem with her pelvic floor muscles or maybe her bladder.
Now, she's got a gynecological exam and a Q-tip test. Let's break that down. The Q-tip test is usually used to check for urethral obstruction. If it's positive, that means there's something blocking the urethra, like a urethral stricture or something else.
Given that she's had a positive Q-tip test, it's likely there's a urethral obstruction. That would mean her urethra is narrow, maybe due to a stricture or some kind of narrowing. So, her bladder can't empty properly during activities like coughing because the urethral obstruction is making it hard.
Now, let's think about what happens when her bladder can't empty. If there's a urethral obstruction, the bladder is forced to hold more urine, increasing the residual volume. That's because her bladder doesn't empty completely. So, her residual volume is probably increased.
Also, if her bladder can't empty properly, she might have increased detrusor contractions. These contractions are usually stronger to push the urine out. So, we expect her detrusor contractions to be increased.
Putting it all together, if she has a urethral obstruction and a positive Q-tip test, we'd expect her cystometry results to show increased residual volume and increased detrusor contractions. That makes sense because of the obstruction and how her bladder is trying to compensate by contracting more.
</think>
Based on the findings of the gynecological exam and the positive Q-tip test, it is most likely that the cystometry would reveal increased residual volume and increased detrusor contractions. The positive Q-tip test indicates urethral obstruction, which would force the bladder to retain more urine, thereby increasing the residual volume. Additionally, the obstruction can lead to increased detrusor contractions as the bladder tries to compensate by contracting more to expel the urine.<|end▁of▁sentence|>
Ahora, vamos a guardar el adoptador, el modelo completo y el tokenizador localmente para poder utilizarlos en otros proyectos.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)
También enviaremos el adoptador, el tokenizador y el modelo a Hugging Face Hub para que la comunidad de IA pueda aprovechar este modelo integrándolo en sus sistemas.
new_model_online = "kingabzpro/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method = "merged_16bit")
Fuente: kingabzpro/DeepSeek-R1-Medical-COT - Cara de abrazo
El siguiente paso en tu viaje de aprendizaje es servir y desplegar tu modelo en la nube. Puedes seguir la guía Cómo desplegar LLM con BentoML que proporciona un proceso paso a paso para desplegar grandes modelos lingüísticos de forma eficaz y rentable utilizando BentoML y herramientas como vLLM.
Alternativamente, si prefieres utilizar el modelo localmente, puedes convertirlo al formato GGUF y ejecutarlo en tu máquina. Para ello, consulta la página Puesta a punto de Llama 3.2 y uso local que proporciona instrucciones detalladas para el uso local.
Las cosas están cambiando rápidamente en el campo de la IA. La comunidad de código abierto está tomando el relevo, desafiando el dominio de los modelos propietarios que han gobernado el panorama de la IA durante los últimos tres años.
Los grandes modelos lingüísticos (LLM) de código abierto son cada vez mejores, más rápidos y más eficientes, por lo que es más fácil que nunca afinarlos con menos recursos informáticos y de memoria.
En este tutorial, exploramos el modelo de razonamiento DeepSeek R1 y aprendimos a afinar su versión destilada para tareas de preguntas y respuestas médicas. Un modelo de razonamiento afinado no sólo mejora el rendimiento, sino que también permite su aplicación en campos críticos como la medicina, los servicios de urgencias y la asistencia sanitaria.
Para contrarrestar el lanzamiento de DeepSeek R1, OpenAI ha introducido dos potentes herramientas: El o3 de OpenAI, un modelo de razonamiento más avanzado, y el agente de IA Operator de OpenAI, impulsado por el nuevo modelo Computer-Using Agent (CUA), que puede navegar de forma autónoma por sitios web y realizar tareas.
Los mejores cursos de DataCamp
Curso
Curso
Curso
Tutorial
Dimitri Didmanidze
Tutorial
Aashi Dutt
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali

