
programa
Importar y limpiar datos en Python
13 h
Cuando inicias un nuevo proyecto de datos, los datos que adquieres rara vez son perfectos para tu análisis desde el principio. Esto hace que sea esencial que realices el proceso de limpieza de tus datos al inicio de cada nuevo proyecto.
Limpiar tus datos es un proceso de eliminación de errores, valores atípicos e incoherencias, y de garantía de que todos tus datos están en un formato adecuado para tu análisis. Los datos que contienen muchos errores o que no han pasado por este proceso de limpieza de datos se denominan datos sucios.
Este paso puede parecer opcional para muchos profesionales de datos noveles, ¡pero ten por seguro que es crucial! Sin una limpieza de datos adecuada, tu modelo puede llegar a una conclusión errónea, tu gráfico puede mostrar una tendencia falsa y tus estadísticas pueden ser tremendamente inexactas.
Considera un conjunto de datos extremadamente pequeño. Tus amigos y tú vais a repartiros los caramelos a partes iguales, y tienes que determinar cuántos caramelos le toca a cada uno. Introduce tus datos en la tabla siguiente.
|
Person |
Número de caramelos |
|
Peter |
5 |
|
Sandy |
20 |
|
Sandy |
20 |
|
Joseph |
3 |
|
Amed |
12 |
Ahora bien, si tomas la media de la columna Número de caramelos, podrías llegar a la conclusión de que cada persona debería recibir 12 caramelos.
Sin embargo, si intentas dar a cada persona 12 caramelos, se te acabarán antes de que todos reciban su parte porque Sandy se duplicó en tu mesa. ¡Sólo hay 40 caramelos en tu alijo en lugar de 60 (y, de hecho, sólo 4 personas, no 5)!
Si no te tomas el tiempo necesario para limpiar tu conjunto de datos, corres el riesgo de que tu análisis llegue a una conclusión errónea.
En el caso de repartir caramelos entre amigos, la mayor consecuencia puede ser una amistad enfadada. Pero en el mundo empresarial, descuidar la limpieza de tu conjunto de datos podría dar lugar a análisis que sugieran lanzar el producto equivocado, contratar el número de empleados equivocado, invertir en las acciones equivocadas, ¡o incluso cobrar a un cliente el precio equivocado!
La limpieza de datos es aún más importante con análisis más complejos. Con los análisis complejos, puede que no tengas una expectativa tan firme de cuáles deberían ser los resultados, lo que significa que puede que no reconozcas cuándo los resultados son erróneos.
Una limpieza exhaustiva de los datos, junto con pruebas cuidadosas, ayudará a aliviar estas preocupaciones. En este tutorial, cubriremos lo que necesitas saber sobre el proceso de limpieza de datos en Python.
Hay muchos tipos de errores e incoherencias que pueden contribuir a que los datos estén sucios. Repasemos algunos de los tipos más comunes y por qué son problemáticos.
Los conjuntos de datos incompletos son muy frecuentes. Puede que a tu conjunto de datos le falten varios años de datos, que sólo tenga alguna información sobre un cliente, o que no contenga toda la gama de productos de tu empresa.
Los valores perdidos pueden tener múltiples efectos en tu análisis. La falta de grandes porciones de datos cruciales puede causar sesgos en tus resultados. Además, los valores NaN o las celdas que faltan en un DataFrame pueden romper algún código Python, causando mucha frustración mientras construyes tu modelo.
Los valores atípicos son valores que se salen de la norma y no son representativos de los datos. Los valores atípicos pueden deberse a un error tipográfico o a circunstancias excepcionales. Es importante diferenciar los verdaderos valores atípicos de las situaciones extremas informativas. Los valores atípicos pueden sesgar tus resultados, sugiriendo en última instancia una respuesta errónea.
Como hemos visto antes, las entradas de datos duplicadas pueden representar en exceso una entrada en tu análisis, lo que te llevaría a una conclusión errónea. Ten cuidado con los duplicados que aparecen más de una vez y con los que contienen información contradictoria o actualizada.
A veces, los valores de nuestro conjunto de datos son simplemente erróneos. Puedes tener mal escrito el nombre de un cliente, un número de producto incorrecto, información obsoleta o datos mal etiquetados.
A veces puede ser difícil determinar si tus datos son erróneos, ¡por eso es tan importante verificar tu fuente! Recuerda que tu análisis es tan bueno como tus datos.
Las incoherencias se presentan de muchas formas. Puede haber entradas de datos incoherentes, lo que puede indicar una errata o un error. Si ves una edad de cliente atrasada, un ingrediente que cambia de número de identificación o un producto con dos precios simultáneos, merece la pena que eches un vistazo más de cerca para asegurarte de que todo es correcto.
Otro tipo problemático de incoherencia es la incoherencia en el formato de los datos. Los distintos valores pueden comunicarse en unidades diferentes (kilómetros vs. millas vs. pulgadas), en estilos diferentes (Mes Día, Año vs. pulgadas). Día-Mes-Año), en distintos tipos de datos (flotantes frente a enteros), o incluso en distintos tipos de archivo (.jpg frente a .png).
Estas incoherencias harán difícil, si no imposible, que tu código interprete los valores correctamente. Esto puede dar lugar a un análisis incorrecto o a que tu código no se ejecute en absoluto.
Es crucial que comprendas tu conjunto de datos antes de utilizarlo en un análisis complejo. Para desarrollar este tipo de comprensión de tus datos, debes realizar una exploración de los mismos. Puedes considerar este paso como el análisis previo al análisis.
Veamos algunos pasos típicos para realizar una exploración de datos en un conjunto de datos con formato de tabla:
Todo esto puede parecer superfluo para tu análisis previsto, pero hay algunas razones importantes por las que siempre debes seguir estos pasos. En primer lugar, hacer esto te proporcionará una gran comprensión de los límites de tu conjunto de datos, lo cual es esencial si quieres confiar en los resultados de tus análisis finales.
En segundo lugar, la exploración de datos puede indicarte tendencias y análisis importantes que no habías considerado antes. Éstos tienen el potencial de añadirse a tus análisis previstos o de presentar un factor de complicación que debes tener en cuenta.
En tercer lugar, este análisis previo puede ser tu primera pista sobre dónde puedes tener datos sucios. Puede ser la primera vez que veas ese valor atípico, que te des cuenta de que hay el doble de categorías de las que debería haber, o que descubras que el método de recogida de datos era distinto el año pasado que el anterior. Todos estos son datos fundamentales que deberían animarte a sentir curiosidad por tu conjunto de datos.
Para obtener más información sobre la exploración de datos, consulta el curso Exploración de datos en Python de DataCamp o este tutorial para principiantes absolutos.
Entremos en materia con algunas técnicas de limpieza de datos en Python, abordando cómo tratar algunos problemas habituales de datos sucios.
Invariablemente, cuando tienes un gran conjunto de datos, faltarán algunos campos en una o más entradas. Esto no sólo significa que estás perdiendo datos valiosos, sino que las entradas NaN pueden confundir a algunas funciones de Python, haciendo que tu modelo sea inexacto.
Cuando encuentres un valor omitido, tienes la opción de eliminar esa entrada del análisis o intentar imputar un valor razonable para ponerlo en su lugar. Si tu conjunto de datos es razonablemente pequeño, te sugeriría que vieras las filas que contienen valores perdidos para que puedas determinar la mejor forma de actuar.
import pandas as pd # Identify rows with NaN valuesrows_with_nan = df[df.isnull().any(axis=1)] #View the rows with NaN valuesprint(rows_with_nan)Borrar una entrada no suele ser la primera opción, ya que supone eliminar información potencialmente valiosa del análisis.
Sin embargo, a veces borrarla es la mejor opción, por ejemplo, si la entrada no proporciona suficiente información como para justificar su conservación (como si la entrada es sólo una fecha sin información valiosa).
La eliminación también es la forma más fácil de tratar las entradas que contienen valores omitidos. Por tanto, si tienes poco tiempo y el resto de la entrada no es importante para el análisis, eliminar las entradas con NaNs es una opción.
Puedes utilizar el método .dropna() de la biblioteca Pandas para eliminar filas de un DataFrame que contengan NaNs.
import pandas as pd # Assuming df is your DataFramedf.dropna(inplace=True)El método generalmente preferido para tratar los valores que faltan es imputar un valor razonable. Encontrar un valor razonable para imputar puede ser todo un arte, pero hay varios métodos establecidos que pueden ser un buen punto de partida.
El método .fillna() de Pandas imputará los valores perdidos utilizando la media para no cambiar la distribución.
import pandas as pd # Assuming df is your DataFrame# Replace NaN values with the mean of the columndf.fillna(df.mean(), inplace=True)La biblioteca sci-kit learn tiene una sencilla función de imputación que también funciona bien.
from sklearn.impute import SimpleImputerimport pandas as pd # Assuming df is your DataFrameimputer = SimpleImputer(strategy='mean')df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Si necesitas un método de imputación más complejo, puedes plantearte utilizar una imputación KNN o de regresión para encontrar un buen valor. En última instancia, el método que elijas dependerá de tus datos, tus necesidades y tus recursos disponibles.
Los valores atípicos son un poco difíciles de tratar. Algunos datos aparentemente atípicos son en realidad datos importantes, como la respuesta del mercado de valores a crisis como la COVID-19 y la Recesión Mundial. Sin embargo, otras pueden ser erratas o circunstancias irrelevantes y raras, y deben eliminarse.
Conocer la diferencia suele ser cuestión de comprender tus datos en su contexto, para lo que debería haberte ayudado tu anterior exploración de datos, y de tener una idea clara del objetivo de tu análisis.
Muchos valores atípicos son visibles cuando se representan gráficamente los datos, pero también puedes utilizar métodos estadísticos para identificar los valores atípicos.
Un método habitual es calcular una puntuación Z para cada punto de datos y eliminar los valores con una puntuación Z extrema.
import numpy as npimport pandas as pd # Generate some sample datanp.random.seed(0)data = np.random.randint(low=0, high=11, size=1000)# Add some outliersdata[0] = 100data[1] = -100 # Calculate Z-scoresz_scores = (data - np.mean(data)) / np.std(data) # Identify outliers based on Z-score threshold (e.g., 3)threshold = 3outliers = np.where(np.abs(z_scores) > threshold)[0] print("Outliers identified using Z-score method:")print(data[outliers])Otro método consiste en calcular el rango intercuartílico (IQR) de la distribución y clasificar cualquier valor que sea Q1-(1,5 x IQR) o Q3 + (1,5 x IQR) como valores atípicos potenciales.
import numpy as npimport pandas as pd # Generate some sample datanp.random.seed(0)data = np.random.randint(low=0, high=11, size=1000)# Add some outliersdata[0] = 100data[1] = -100 # Calculate quartiles and IQRq1 = np.percentile(data, 25)q3 = np.percentile(data, 75)iqr = q3 - q1 # Identify outliers based on IQRlower_bound = q1 - (1.5 * iqr)upper_bound = q3 + (1.5 * iqr)outliers = np.where((data < lower_bound) | (data > upper_bound))[0] print("Outliers identified using IQR method:")print(data[outliers])Una vez que hayas identificado los valores atípicos y determinado que son problemáticos, existen varios métodos para tratarlos. Si has determinado que el valor atípico se debe a un error, puede ser posible simplemente corregir el error para resolver el valor atípico.
En otros casos, puede ser posible eliminar el valor atípico del conjunto de datos o sustituirlo por un valor menos extremo que conserve la forma general de la distribución.
La limitación es un método en el que estableces un tope, o umbral, en la distribución de tus datos y sustituyes cualquier valor fuera de esos límites por un valor especificado.
import pandas as pdimport numpy as np # Create a sample DataFrame with outliersdata = { 'A': [100, 90, 85, 88, 110, 115, 120, 130, 140], 'B': [1, 2, 3, 4, 5, 6, 7, 8, 9]}df = pd.DataFrame(data) # Define the lower and upper thresholds for capping (Here I used the 5th and 95th percentiles)lower_threshold = df.quantile(0.05)upper_threshold = df.quantile(0.95) # Cap outlierscapped_df = df.clip(lower=lower_threshold, upper=upper_threshold, axis=1) print("Original DataFrame:")print(df)print("\nCapped DataFrame:")print(capped_df)En algunos casos, puedes transformar tus datos de forma que los valores atípicos tengan menos impacto, como una transformación de raíz cuadrada o una transformación logarítmica.
Ten cuidado al transformar tus datos, ya que puedes introducir más problemas a largo plazo si no tienes cuidado. Hay algunas cosas que debes tener en cuenta antes de decidirte a transformar tus datos.
Para aprender más sobre las transformaciones de datos, te recomiendo que sigas un curso de estadística como Introducción a la Estadística en Python o Fundamentos de Estadística con Python, de DataCamp.
Ya hemos visto cómo los duplicados pueden causar estragos en nuestros análisis. Afortunadamente, Python simplifica la identificación y el tratamiento de los duplicados.
Utilizando el método duplicated() de la biblioteca pandas de Python, puedes identificar fácilmente las filas duplicadas en un DataFrame para examinarlas.
import pandas as pd# Assuming 'df' is your DataFrameduplicate_rows = df[df.duplicated()]Esto devolverá un DataFrame que contiene las filas que son duplicadas. Una vez que tengas este DataFrame de filas duplicadas, te animo a que mires los duplicados si no son demasiados.
La mayoría de los duplicados pueden ser copias exactas y pueden eliminarse simplemente utilizando el método drop_duplicates() de Pandas:
# Removing duplicatescleaned_df = df.drop_duplicates()En algunos casos, puede ser más apropiado fusionar registros duplicados, agregando información. Por ejemplo, si los duplicados representan varias entradas para la misma entidad, podemos fusionarlos utilizando funciones de agregación:
# Merging duplicates by aggregating valuesmerged_df = df.groupby(list_of_columns).agg({'column_to_merge': 'sum'})Esto combinará las filas duplicadas en una sola, agregando valores basados en funciones especificadas como suma, media, etc.
import pandas as pd#Sample DataFramedata = { 'customer_id' : [102, 102, 101, 103, 102] 'product_id' : ['A', 'B', 'A', 'C', 'B'] 'quantity_sold : [5, 3, 2, 1, 4]}df = pd.DataFrame(data)df}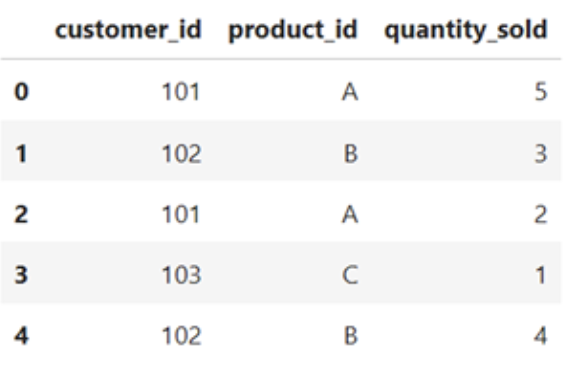
# Merging duplicates by aggregating valuesmerged_df = df.groupby(['cutomer_id', 'product_id']).agg({'quantity_sold': 'sum'}).reset_index()merged_df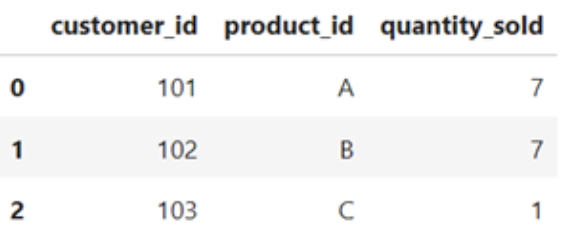
Los distintos tipos de incoherencias requerirán soluciones diferentes. Las incoherencias derivadas de la introducción de datos incorrectos o de erratas pueden tener que ser corregidas por una fuente experta. Otra posibilidad es sustituir los datos incorrectos mediante imputación, como si se tratara de un valor omitido, o eliminarlos por completo del conjunto de datos, según las circunstancias.
Las incoherencias en el formato de los datos pueden corregirse utilizando algunos métodos de normalización. Para eliminar los espacios iniciales y finales de una cadena, puedes utilizar el método .strip(). Los métodos .upper() y .lower() normalizarán las mayúsculas y minúsculas en las cadenas. Y la conversión de fechas a datetimes mediante pd.to_datetime normalizará el formato de las fechas.
También puedes asegurarte de que cada valor de la columna de un Marco de datos es del mismo tipo de datos utilizando el método .astype().
Otras correcciones de incoherencias de formato que puedes necesitar llevar a cabo son:
value_mapping = {'M': 'Male', 'F': 'Female'}standardized_value = value_mapping.get('M', 'Unknown')La transformación de datos y la ingeniería de características son técnicas de preprocesamiento para transformar los datos brutos en un formato más adecuado para los algoritmos de aprendizaje automático y el análisis estadístico. En esta sección, exploraremos brevemente algunas técnicas comunes de transformación de datos e ingeniería de características en Python.
La normalización y la estandarización son dos técnicas utilizadas para llevar las características a una escala similar, lo que es importante para muchos algoritmos de aprendizaje automático.
La normalización escala los datos a un intervalo fijo, normalmente entre 0 y 1. Esto garantiza que todos los rasgos estén a la misma escala y evita que ciertos rasgos dominen a otros debido a su mayor magnitud.
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler()scaled_data = scaler.fit_transform(data)La normalización, en cambio, transforma los datos para que tengan una media de 0 y una desviación típica de 1. Esta técnica es útil cuando los datos tienen diferentes escalas y rangos variables, y garantiza que cada característica tenga un impacto comparable en el modelo.
from sklearn.preprocessing import StandardScaler scaler = StandardScaler()standardized_data = scaler.fit_transform(data)Las características específicas de tus datos y los requisitos de tu modelo previsto dictarán cómo vas a escalar tus datos.
La codificación de variables categóricas es un paso esencial del preprocesamiento en el aprendizaje automático cuando se trata de características que no son numéricas. Las variables categóricas representan datos cualitativos, como tipos, clases o etiquetas. Para utilizar estas variables en algoritmos de aprendizaje automático, es necesario convertirlas a un formato numérico.
Una técnica habitual para codificar variables categóricas es la codificación de un solo punto, que transforma cada categoría en un vector binario. Este método es especialmente útil cuando se trata de variables categóricas nominales, en las que no existe un orden o jerarquía inherente entre las categorías.
import pandas as pdencoded_data = pd.get_dummies(data, columns=['categorical_column'])import pandas as pd#Create a sample DataFrame with categorical column data = { 'ID' : [1, 2, 3, 4, 5]}df = pd.DataFrame(data)#Performe one-hot encoding encoded_data = pd.get_dummies(df, columns==['Color'])print("Original DataFrame")print(df)print("\nEncoded DataFrame:")print(encoded_data)
Otro enfoque es la codificación de etiquetas, que asigna un número entero único a cada categoría. Cada categoría se asigna a un valor numérico, lo que convierte las etiquetas categóricas en números ordinales. Este método es adecuado para variables categóricas ordinales, en las que existe un orden natural o una clasificación entre las categorías.
from sklearn.preprocessing import LabelEncoderencoder = LabelEncoder()encoded_data['categorical_column'] = encoder.fit_transform(data['categorical_column'])from sklearn.preprocessing import LabelEncoderimport pandas as pd#Create a sample DataFrame with categorical column data = { 'ID' : [1, 2, 3, 4, 5] 'Color' : [ 'Red', 'Blue', 'Green', 'Red', 'Green' ]}df = pd.DataFrame(data)#Perform label encodingencoder = LabelEncoder()df ['Color_LabelEncoded'] = encoder.fit_transform(df['Color'])print("Original DataFrame:")print(df[['ID', 'Color']])print("\nDataFrame with Label Encoded Column:")print(df[['ID', 'Color_LabelEncoded']])
Es importante elegir el método de codificación adecuado en función de la naturaleza de la variable categórica y de los requisitos del algoritmo de aprendizaje automático. Por lo general, se prefiere la codificación de un punto para las variables nominales, mientras que la codificación de etiquetas es adecuada para las variables ordinales.
La ingeniería de características es un paso en el desarrollo de modelos de aprendizaje automático que implica la creación de nuevas características o la modificación de las existentes. Este proceso es habitual cuando los datos brutos carecen de características que contribuyan directamente a la tarea de aprendizaje o cuando las características existentes no están en una forma que el algoritmo de aprendizaje pueda utilizar eficazmente.
Considera un escenario en el que trabajas con un conjunto de datos de precios de viviendas, y quieres predecir el precio de venta de las casas basándote en varias características, como el número de habitaciones, los metros cuadrados de la superficie habitable y el estado de la propiedad. Sin embargo, el conjunto de datos no incluye una característica que capte directamente el estado general de la casa.
En este caso, puedes crear una nueva característica combinando características existentes o extrayendo información relevante.
Por ejemplo, podrías crear una característica llamada "Estado general" agregando las valoraciones de estado de componentes individuales de la casa, como el estado de la cocina, la calidad del sótano, la antigüedad de la propiedad, las reformas recientes, etc.
En los casos en que la relación entre los rasgos y la variable objetivo no sea lineal, se pueden generar rasgos polinómicos elevando los rasgos existentes a varias potencias. Este enfoque ayuda a captar relaciones complejas entre variables que pueden no ser linealmente separables.
from sklearn.preprocessing import PolynomialFeaturespoly = PolynomialFeatures(degree=2)polynomial_features = poly.fit_transform(data)En otros casos, puede que te enfrentes a conjuntos de datos de alta dimensión o a multicolinealidad entre características. Pueden emplearse técnicas como el Análisis de Componentes Principales (ACP ) para reducir la dimensionalidad del conjunto de datos conservando la mayor parte de la información relevante.
from sklearn.decomposition import PCApca = PCA(n_components=2)transformed_features = pca.fit_transform(data)La ingeniería de características garantiza que dispones de los datos correctos en el formato adecuado para que los utilice tu modelo. Hay muchas técnicas en la ingeniería de características, y la que utilices dependerá en gran medida de lo que intentes conseguir.
Consulta este curso de ingeniería de funciones para conocer más técnicas que pueden serte útiles.
La limpieza de datos es un paso fundamental en cualquier proyecto de análisis de datos o aprendizaje automático. Aquí tienes algunas prácticas recomendadas que debes tener en cuenta para agilizar tu proceso de limpieza de datos:
¡Conserva siempre el original!
Este es el consejo más importante a la hora de limpiar datos. Guarda una copia de los archivos de datos brutos separada de las versiones limpiadas y procesadas. Esto garantiza que siempre tengas un punto de referencia y que puedas volver fácilmente a los datos originales si es necesario.
Personalmente, siempre hago una copia del archivo de datos brutos antes de realizar ningún cambio y añado el sufijo "-RAW" al nombre del archivo para saber cuál es el original.
Añade comentarios a tu código para explicar la finalidad de cada paso de limpieza y cualquier suposición que se haya hecho.
Querrás asegurarte de que tus esfuerzos de limpieza de datos no modifican significativamente la distribución ni introducen sesgos no intencionados. La exploración repetida de los datos tras tus esfuerzos de limpieza puede ayudarte a asegurarte de que vas por el buen camino.
Si tienes un proceso de limpieza largo o automatizado, quizá quieras mantener un documento aparte donde registres los detalles de cada paso de la limpieza.
Detalles como la fecha, la acción concreta realizada y los problemas encontrados pueden ser útiles más adelante.
Recuerda guardar este documento en algún lugar de fácil acceso, como en la misma carpeta del proyecto que los datos o el código. En el caso de un pipeline automatizado y actualizado periódicamente, considera la posibilidad de que este registro forme parte automática del proceso de limpieza de datos. Esto te permitirá comprobar y asegurarte de que todo funciona correctamente.
Identifica las tareas habituales de limpieza de datos y encapsúlalas en funciones reutilizables. Esto te permite aplicar los mismos pasos de limpieza a varios conjuntos de datos. Esto es especialmente útil si tienes abreviaturas específicas de la empresa que quieres mapear.
Utiliza la Lista de Comprobación de Limpieza de Datos de DataCamp para asegurarte de que no se te escapa nada.
La limpieza de datos no es sólo una tarea mundana; es un paso crucial que constituye la base del éxito de todo proyecto de análisis de datos y aprendizaje automático. Asegurándote de que tus datos son precisos, coherentes y fiables, sientas las bases para tomar decisiones informadas y obtener perspectivas significativas.
Los datos sucios pueden llevar a conclusiones erróneas y análisis defectuosos, que pueden tener consecuencias importantes, tanto si estás repartiendo caramelos entre amigos como si estás tomando decisiones empresariales. Invertir tiempo y esfuerzo en limpiar tus datos merece la pena a largo plazo, ya que garantiza que tus análisis sean fiables y tus resultados procesables.
Para más información y ejercicios interactivos, consulta el curso de limpieza de datos de DataCamp. Para un reto práctico, prueba este código de limpieza de datos.
¡Empieza hoy tu viaje de limpieza de datos!
programa
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Karlijn Willems
Tutorial
Adel Nehme
Tutorial
Moez Ali
Tutorial
Kurtis Pykes


