
Programa
Importação e limpeza de dados Em Python
13 h
Quando você inicia um novo projeto de dados, os dados que você adquire raramente são perfeitos para sua análise logo de cara. Isso faz com que seja essencial que você passe pelo processo de limpeza dos dados no início de cada novo projeto.
A limpeza dos dados é um processo de remoção de erros, discrepâncias e inconsistências e de garantia de que todos os dados estejam em um formato apropriado para a análise. Os dados que contêm muitos erros ou que não passaram por esse processo de limpeza de dados são chamados de dados sujos.
Essa etapa pode parecer opcional para muitos profissionais de dados juniores, mas tenha certeza de que ela é crucial! Sem a limpeza adequada dos dados, seu modelo pode chegar a uma conclusão errada, seu gráfico pode mostrar uma tendência falsa e suas estatísticas podem ser extremamente imprecisas.
Considere um conjunto de dados extremamente pequeno. Você e seus amigos estão dividindo os doces igualmente entre vocês, e você precisa determinar quantos doces cada pessoa receberá. Você insere seus dados na tabela abaixo.
|
Pessoa |
Número de doces |
|
Pedro |
5 |
|
Sandy |
20 |
|
Sandy |
20 |
|
Joseph |
3 |
|
Amed |
12 |
Agora, se você pegar a média da coluna Número de doces, poderá chegar à conclusão de que cada pessoa deve receber 12 doces.
No entanto, se você tentar dar 12 doces para cada pessoa, acabará antes que todos recebam sua parte, pois a Sandy foi duplicada na sua mesa. Você tem apenas 40 doces no seu estoque, em vez de 60 (e, na verdade, apenas 4 pessoas, não 5)!
Se você não dedicar tempo para limpar seu conjunto de dados, corre o risco de sua análise chegar a uma conclusão errada.
No caso da divisão de doces entre amigos, a maior consequência pode ser uma amizade prejudicada. Mas no mundo dos negócios, deixar de limpar seu conjunto de dados pode resultar em análises que sugerem o lançamento do produto errado, a contratação do número errado de funcionários, o investimento em ações erradas ou até mesmo a cobrança de um preço errado de um cliente!
A limpeza de dados é ainda mais importante em análises mais complexas. Com análises complexas, você pode não ter uma expectativa tão firme de quais devem ser os resultados, o que significa que você pode não reconhecer quando os resultados estão errados.
Uma limpeza completa dos dados, juntamente com testes cuidadosos, ajudará a aliviar essas preocupações. Neste tutorial, abordaremos o que você precisa saber sobre o processo de limpeza de dados em Python.
Há muitos tipos de erros e inconsistências que podem contribuir para que os dados fiquem sujos. Vamos examinar alguns dos tipos mais comuns e por que eles são problemáticos.
Conjuntos de dados incompletos são extremamente comuns. Seu conjunto de dados pode estar faltando vários anos de dados, ter apenas algumas informações sobre um cliente ou não conter o conjunto completo de produtos da sua empresa.
Os valores ausentes podem ter vários efeitos na sua análise. A falta de grandes porções de dados cruciais pode causar distorção nos resultados. Além disso, valores NaN ou células ausentes em um DataFrame podem quebrar alguns códigos Python, causando muita frustração durante a criação do modelo.
Outliers são valores que estão muito fora da norma e não são representativos dos dados. Os valores atípicos podem ser o resultado de um erro de digitação ou de circunstâncias excepcionais. É importante diferenciar os verdadeiros outliers das situações extremas informativas. Os valores atípicos podem distorcer seus resultados, sugerindo, em última análise, a resposta errada.
Como vimos acima, entradas de dados duplicadas podem representar demais uma entrada em sua análise, levando a uma conclusão errada. Fique atento às duplicatas que ocorrem mais de uma vez e àquelas que contêm informações conflitantes ou atualizadas.
Às vezes, os valores em nosso conjunto de dados estão simplesmente errados. Você pode ter a grafia errada do nome de um cliente, o número errado do produto, informações desatualizadas ou dados rotulados incorretamente.
Às vezes, pode ser difícil determinar se os dados estão errados, e é por isso que a verificação da fonte é tão importante! Lembre-se de que sua análise é tão boa quanto seus dados.
As inconsistências podem se apresentar de várias formas. Pode haver entradas de dados inconsistentes, o que pode indicar um erro de digitação ou um erro. Se você vir uma idade de cliente atrasada, um ingrediente que muda o número de identificação ou um produto com dois preços simultâneos, vale a pena dar uma olhada mais de perto para ter certeza de que tudo está correto.
Outro tipo problemático de inconsistência é a inconsistência no formato dos dados. Different values may be reported in different units (kilometers vs. miles vs. inches), in different styles (Month Day, Year vs. Dia-Mês-Ano), em diferentes tipos de dados (floats vs. inteiros) ou até mesmo em diferentes tipos de arquivos (.jpg vs. .png).
Essas inconsistências farão com que seja desafiador, se não impossível, que o seu código interprete os valores corretamente. Isso pode resultar em uma análise incorreta ou fazer com que seu código não seja executado.
É fundamental que você entenda seu conjunto de dados antes de usá-lo em uma análise complexa. Para desenvolver esse tipo de entendimento dos seus dados, você deve fazer uma exploração dos dados. Você pode pensar nessa etapa como a análise pré-analítica.
Vejamos algumas etapas típicas para realizar uma exploração de dados em um conjunto de dados em formato de tabela:
Tudo isso pode parecer supérfluo para a análise pretendida, mas há alguns motivos importantes pelos quais você deve sempre seguir essas etapas. Em primeiro lugar, isso lhe dará uma ótima compreensão dos limites do seu conjunto de dados, o que é essencial se você quiser confiar nos resultados das suas análises finais.
Em segundo lugar, a exploração de dados pode indicar tendências e análises importantes que você não havia considerado anteriormente. Eles têm o potencial de acrescentar às suas análises pretendidas ou de apresentar um fator complicador que você precisa levar em consideração.
Em terceiro lugar, essa pré-análise pode ser sua primeira pista sobre onde você pode ter dados sujos. Essa pode ser a primeira vez que você vê uma exceção, percebe que há o dobro de categorias do que deveria haver ou descobre que o método de coleta de dados foi diferente no ano passado e no ano anterior. Todas essas são informações essenciais que devem incentivar você a ter curiosidade sobre seu conjunto de dados.
Para obter mais informações sobre exploração de dados, confira o curso Data Exploration in Python do DataCamp ou este tutorial para iniciantes.
Vamos abordar alguns detalhes com algumas técnicas de limpeza de dados em Python, explicando como lidar com alguns problemas comuns de dados sujos.
Invariavelmente, quando você tem um grande conjunto de dados, alguns campos estarão ausentes em uma ou mais entradas. Isso não significa apenas que você está perdendo dados valiosos, mas as entradas NaN podem atrapalhar algumas funções do Python, tornando seu modelo impreciso.
Ao encontrar um valor ausente, você tem a opção de eliminar essa entrada da análise ou tentar imputar um valor razoável para colocar em seu lugar. Se o seu conjunto de dados for razoavelmente pequeno, sugiro visualizar as linhas que contêm valores ausentes para que você possa determinar o melhor curso de ação.
import pandas as pd # Identify rows with NaN valuesrows_with_nan = df[df.isnull().any(axis=1)] #View the rows with NaN valuesprint(rows_with_nan)Normalmente, a exclusão de uma entrada não é a primeira opção, pois significa retirar informações potencialmente valiosas da análise.
No entanto, às vezes a exclusão é a melhor opção, por exemplo, se a entrada não fornecer informações suficientes para que você a mantenha (por exemplo, se a entrada for apenas uma data sem informações valiosas).
A exclusão também é a maneira mais fácil de lidar com entradas que contêm valores ausentes. Portanto, se você tiver pouco tempo e o restante da entrada não for importante para a análise, excluir entradas com NaNs é uma opção.
Você pode usar o método .dropna() da biblioteca Pandas para eliminar linhas de um DataFrame que contenha NaNs.
import pandas as pd # Assuming df is your DataFramedf.dropna(inplace=True)O método geralmente preferido para lidar com valores ausentes é a imputação de um valor razoável. Encontrar um valor razoável para imputar pode ser uma arte por si só, mas há vários métodos estabelecidos que podem ser um bom ponto de partida.
O método .fillna() do Pandas imputará os valores ausentes usando a média para não alterar a distribuição.
import pandas as pd # Assuming df is your DataFrame# Replace NaN values with the mean of the columndf.fillna(df.mean(), inplace=True)A biblioteca sci-kit learn tem uma função de imputação simples que também funciona bem.
from sklearn.impute import SimpleImputerimport pandas as pd # Assuming df is your DataFrameimputer = SimpleImputer(strategy='mean')df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Se precisar de um método de imputação mais complexo, você pode considerar o uso de uma imputação KNN ou de regressão para encontrar um bom valor. Em última análise, o método que você escolher dependerá dos seus dados, das suas necessidades e dos recursos disponíveis.
É um pouco difícil lidar com outliers. Algumas aparentes exceções são, na verdade, dados importantes, como a forma como o mercado de ações responde a crises como a COVID-19 e a Recessão Global. Entretanto, outros podem ser erros de digitação ou irrelevantes, circunstâncias raras, e devem ser removidos.
Saber a diferença geralmente é uma questão de entender os dados no contexto, o que deve ter ajudado você na exploração de dados anterior, e ter uma ideia clara do objetivo da análise.
Muitos outliers são visíveis quando os dados são plotados, mas você também pode usar métodos estatísticos para identificar outliers.
Um método comum é calcular um escore Z para cada ponto de dados e eliminar os valores com um escore Z extremo.
import numpy as npimport pandas as pd # Generate some sample datanp.random.seed(0)data = np.random.randint(low=0, high=11, size=1000)# Add some outliersdata[0] = 100data[1] = -100 # Calculate Z-scoresz_scores = (data - np.mean(data)) / np.std(data) # Identify outliers based on Z-score threshold (e.g., 3)threshold = 3outliers = np.where(np.abs(z_scores) > threshold)[0] print("Outliers identified using Z-score method:")print(data[outliers])Outro método é calcular o intervalo interquartil (IQR) da distribuição e classificar quaisquer valores que sejam Q1-(1,5 x IQR) ou Q3 + (1,5 x IQR) como possíveis outliers.
import numpy as npimport pandas as pd # Generate some sample datanp.random.seed(0)data = np.random.randint(low=0, high=11, size=1000)# Add some outliersdata[0] = 100data[1] = -100 # Calculate quartiles and IQRq1 = np.percentile(data, 25)q3 = np.percentile(data, 75)iqr = q3 - q1 # Identify outliers based on IQRlower_bound = q1 - (1.5 * iqr)upper_bound = q3 + (1.5 * iqr)outliers = np.where((data < lower_bound) | (data > upper_bound))[0] print("Outliers identified using IQR method:")print(data[outliers])Depois que você identificar os valores discrepantes e determinar que eles são problemáticos, existem vários métodos para lidar com eles. Se você determinou que o valor discrepante é devido a um erro, pode ser possível simplesmente corrigir o erro para resolver o valor discrepante.
Em outros casos, pode ser possível remover o outlier do conjunto de dados ou substituí-lo por um valor menos extremo que mantenha a forma geral da distribuição.
O limite é um método em que você define um limite para a distribuição dos dados e substitui todos os valores fora desses limites por um valor especificado.
import pandas as pdimport numpy as np # Create a sample DataFrame with outliersdata = { 'A': [100, 90, 85, 88, 110, 115, 120, 130, 140], 'B': [1, 2, 3, 4, 5, 6, 7, 8, 9]}df = pd.DataFrame(data) # Define the lower and upper thresholds for capping (Here I used the 5th and 95th percentiles)lower_threshold = df.quantile(0.05)upper_threshold = df.quantile(0.95) # Cap outlierscapped_df = df.clip(lower=lower_threshold, upper=upper_threshold, axis=1) print("Original DataFrame:")print(df)print("\nCapped DataFrame:")print(capped_df)Em alguns casos, você pode transformar seus dados de uma forma que torne os outliers menos impactantes, como uma transformação de raiz quadrada ou uma transformação logarítmica.
Seja cauteloso ao transformar seus dados, pois você pode introduzir mais problemas a longo prazo se não for cuidadoso. Há alguns aspectos que você deve considerar antes de decidir transformar seus dados.
Para saber mais sobre transformações de dados, recomendo que você faça um curso de estatística, como o Introduction to Statistics in Python do DataCamp ou o Statistics Fundamentals with Python.
Já vimos como as duplicatas podem causar estragos em nossas análises. Felizmente, o Python simplifica a identificação e o tratamento de duplicatas.
Usando o método duplicated() da biblioteca pandas do Python, você pode identificar facilmente linhas duplicadas em um DataFrame para examiná-las.
import pandas as pd# Assuming 'df' is your DataFrameduplicate_rows = df[df.duplicated()]Isso retornará um DataFrame contendo linhas que são duplicadas. Depois que você tiver esse DataFrame de linhas duplicadas, recomendo que você examine as duplicatas, se não houver muitas delas.
A maioria das duplicatas podem ser cópias exatas e podem ser simplesmente descartadas usando o método drop_duplicates() no Pandas:
# Removing duplicatescleaned_df = df.drop_duplicates()Em alguns casos, pode ser mais apropriado mesclar registros duplicados, agregando informações. Por exemplo, se as duplicatas representarem várias entradas para a mesma entidade, poderemos mesclá-las usando funções de agregação:
# Merging duplicates by aggregating valuesmerged_df = df.groupby(list_of_columns).agg({'column_to_merge': 'sum'})Isso combinará linhas duplicadas em uma, agregando valores com base em funções especificadas, como soma, média etc.
import pandas as pd#Sample DataFramedata = { 'customer_id' : [102, 102, 101, 103, 102] 'product_id' : ['A', 'B', 'A', 'C', 'B'] 'quantity_sold : [5, 3, 2, 1, 4]}df = pd.DataFrame(data)df}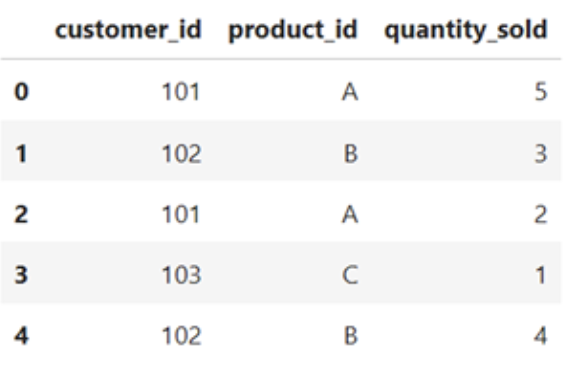
# Merging duplicates by aggregating valuesmerged_df = df.groupby(['cutomer_id', 'product_id']).agg({'quantity_sold': 'sum'}).reset_index()merged_df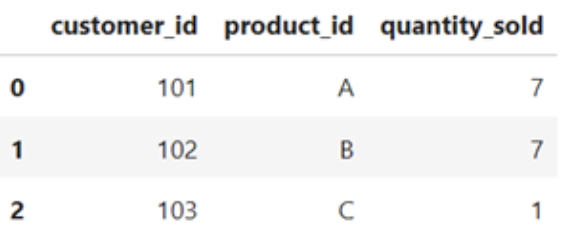
Tipos diferentes de inconsistências exigirão soluções diferentes. As inconsistências resultantes de entradas de dados incorretas ou de erros de digitação podem precisar ser corrigidas por uma fonte experiente. Como alternativa, os dados incorretos podem ser substituídos usando imputação, como se fosse um valor ausente, ou removidos totalmente do conjunto de dados, dependendo das circunstâncias.
As inconsistências na formatação dos dados podem ser corrigidas usando alguns métodos de padronização. Para remover espaços à esquerda e à direita de uma cadeia de caracteres, você pode usar o método .strip(). Os métodos .upper() e .lower() padronizarão o caso em strings. E a conversão de datas em períodos de tempo usando pd.to_datetime padronizará a formatação de datas.
Você também pode garantir que todos os valores da coluna de um DataFrame tenham o mesmo tipo de dados usando o método .astype().
Outras correções de inconsistência de formatação que você pode precisar realizar incluem:
value_mapping = {'M': 'Male', 'F': 'Female'}standardized_value = value_mapping.get('M', 'Unknown')A transformação de dados e a engenharia de recursos são técnicas de pré-processamento para transformar dados brutos em um formato mais adequado para algoritmos de aprendizado de máquina e análise estatística. Nesta seção, exploraremos brevemente algumas técnicas comuns de transformação de dados e engenharia de recursos em Python.
A normalização e a padronização são duas técnicas usadas para colocar os recursos em uma escala semelhante, o que é importante para muitos algoritmos de aprendizado de máquina.
A normalização dimensiona os dados para um intervalo fixo, geralmente entre 0 e 1. Isso garante que todos os recursos estejam na mesma escala e evita que determinados recursos dominem outros devido à sua maior magnitude.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(data)A padronização, por outro lado, transforma os dados para que tenham uma média de 0 e um desvio padrão de 1. Essa técnica é útil quando os dados têm escalas diferentes e intervalos variados, e garante que cada recurso tenha um impacto comparável no modelo.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)As características específicas dos seus dados e os requisitos do modelo pretendido ditarão como você dimensionará seus dados. Saiba mais sobre a diferença entre normalização e padronização com nosso tutorial dedicado, Normalização vs. padronização. Padronização: Como você pode saber a diferença.
A codificação de variáveis categóricas é uma etapa essencial de pré-processamento no aprendizado de máquina ao lidar com recursos que não são numéricos. As variáveis categóricas representam dados qualitativos, como tipos, classes ou rótulos. Para usar essas variáveis em algoritmos de aprendizado de máquina, elas precisam ser convertidas em um formato numérico.
Uma técnica comum para a codificação de variáveis categóricas é a codificação one-hot, que transforma cada categoria em um vetor binário. Esse método é particularmente útil ao lidar com variáveis categóricas nominais, em que não há ordem ou hierarquia inerente entre as categorias.
import pandas as pd
encoded_data = pd.get_dummies(data, columns=['categorical_column'])
import pandas as pd
# Create a sample DataFrame with a categorical column
data = {
'ID': [1, 2, 3, 4, 5],
'Color': ['Red', 'Blue', 'Green', 'Red', 'Blue']
}
df = pd.DataFrame(data)
# Perform one-hot encoding
encoded_data = pd.get_dummies(df, columns=['Color'])
print("Original DataFrame")
print(df)
print("\nEncoded DataFrame:")
print(encoded_data)

Outra abordagem é a codificação de rótulos, que atribui um número inteiro exclusivo a cada categoria. Cada categoria é mapeada para um valor numérico, convertendo efetivamente rótulos categóricos em números ordinais. Esse método é adequado para variáveis categóricas ordinais, em que há uma ordem ou classificação natural entre as categorias.
from sklearn.preprocessing import LabelEncoderencoder = LabelEncoder()encoded_data['categorical_column'] = encoder.fit_transform(data['categorical_column'])from sklearn.preprocessing import LabelEncoderimport pandas as pd#Create a sample DataFrame with categorical column data = { 'ID' : [1, 2, 3, 4, 5] 'Color' : [ 'Red', 'Blue', 'Green', 'Red', 'Green' ]}df = pd.DataFrame(data)#Perform label encodingencoder = LabelEncoder()df ['Color_LabelEncoded'] = encoder.fit_transform(df['Color'])print("Original DataFrame:")print(df[['ID', 'Color']])print("\nDataFrame with Label Encoded Column:")print(df[['ID', 'Color_LabelEncoded']])
É importante escolher o método de codificação adequado com base na natureza da variável categórica e nos requisitos do algoritmo de aprendizado de máquina. A codificação de um ponto é geralmente preferida para variáveis nominais, enquanto a codificação de rótulo é adequada para variáveis ordinais.
A engenharia de recursos é uma etapa do desenvolvimento de modelos de aprendizado de máquina que envolve a criação de novos recursos ou a modificação dos existentes. Esse processo é comum quando os dados brutos não têm recursos que contribuam diretamente para a tarefa de aprendizado ou quando os recursos existentes não estão em uma forma que o algoritmo de aprendizado possa usar com eficiência.
Considere um cenário em que você esteja trabalhando com um conjunto de dados de preços de moradias e queira prever o preço de venda das casas com base em vários recursos, como o número de quartos, a metragem quadrada da área de estar e a condição da propriedade. No entanto, o conjunto de dados não inclui um recurso que capture diretamente a condição geral da casa.
Nesse caso, você pode criar um novo recurso combinando recursos existentes ou extraindo informações relevantes.
Por exemplo, você pode criar um recurso chamado "Condição geral" agregando as classificações de condição de componentes individuais da casa, como a condição da cozinha, a qualidade do porão, a idade da propriedade, reformas recentes etc.
Nos casos em que a relação entre os recursos e a variável-alvo não é linear, os recursos polinomiais podem ser gerados elevando-se os recursos existentes a várias potências. Essa abordagem ajuda a capturar relações complexas entre variáveis que podem não ser linearmente separáveis.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
polynomial_features = poly.fit_transform(data)
Em outros casos, você pode estar lidando com conjuntos de dados de alta dimensão ou com multicolinearidade entre os recursos. Técnicas como a análise de componentes principais (PCA) podem ser empregadas para reduzir a dimensionalidade do conjunto de dados e, ao mesmo tempo, reter a maioria das informações relevantes.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
transformed_features = pca.fit_transform(data)A engenharia de recursos garante que você tenha os dados corretos no formato correto para o seu modelo usar. Há muitas técnicas na engenharia de recursos, e a que você usará dependerá muito do que você está tentando realizar.
Confira este curso de engenharia de recursos para conhecer mais técnicas que podem ser úteis para você.
A limpeza de dados é uma etapa essencial em qualquer projeto de análise de dados ou aprendizado de máquina. Aqui estão algumas práticas recomendadas que você deve ter em mente ao otimizar seu processo de limpeza de dados:
Sempre mantenha o original!
Essa é a dica número um mais importante ao limpar dados. Mantenha uma cópia dos arquivos de dados brutos separada das versões limpas e processadas. Isso garante que você sempre tenha um ponto de referência e possa reverter facilmente para os dados originais, se necessário.
Pessoalmente, sempre faço uma cópia do arquivo de dados brutos antes de fazer qualquer alteração e coloco o sufixo "-RAW" no nome do arquivo para saber qual é o original.
Adicione comentários ao seu código para explicar a finalidade de cada etapa de limpeza e as suposições feitas.
Você deve se certificar de que seus esforços de limpeza de dados não estão alterando significativamente a distribuição ou introduzindo quaisquer vieses não intencionais. A exploração repetida de dados após os esforços de limpeza pode ajudar a garantir que você esteja no caminho certo.
Se você tiver um processo de limpeza longo ou automatizado, talvez queira manter um documento separado no qual registre os detalhes de cada etapa de limpeza.
Detalhes como a data, a ação específica tomada e quaisquer problemas encontrados podem ser úteis no futuro.
Lembre-se de armazenar esse documento em um local de fácil acesso, por exemplo, na mesma pasta do projeto que os dados ou o código. No caso de um pipeline automatizado e atualizado regularmente, considere fazer com que esse registro seja uma parte automática do processo de limpeza de dados. Isso permitirá que você faça o check-in e verifique se tudo está funcionando sem problemas.
Identificar tarefas comuns de limpeza de dados e encapsulá-las em funções reutilizáveis. Isso permite que você aplique as mesmas etapas de limpeza a vários conjuntos de dados. Isso é especialmente útil se você tiver abreviações específicas da empresa que deseja mapear.
Use a lista de verificação de limpeza de dados da DataCamp para garantir que você não perca nada!
A limpeza de dados não é apenas uma tarefa mundana; é uma etapa crucial que forma a base de todo projeto bem-sucedido de análise de dados e aprendizado de máquina. Ao garantir que seus dados sejam precisos, consistentes e confiáveis, você estabelece as bases para tomar decisões informadas e obter insights significativos.
Dados sujos podem levar a conclusões errôneas e análises falhas, que podem ter consequências significativas, quer você esteja dividindo doces entre amigos ou tomando decisões de negócios. Investir tempo e esforço na limpeza de seus dados compensa a longo prazo, garantindo que suas análises sejam confiáveis e que seus resultados sejam acionáveis.
Para obter mais informações e exercícios interativos, confira o curso de limpeza de dados do DataCamp. Para um desafio prático, experimente este code-along de limpeza de dados.
Comece sua jornada de limpeza de dados hoje mesmo!
Programa
Curso
Curso