
Lernpfad
Datenimport/-bereinigung in Python
13 Std.
Wenn du ein neues Datenprojekt beginnst, sind die Daten, die du erhältst, selten auf Anhieb perfekt für deine Analyse. Deshalb ist es wichtig, dass du deine Daten zu Beginn eines jeden neuen Projekts bereinigst.
Beim Bereinigen deiner Daten geht es darum, Fehler, Ausreißer und Inkonsistenzen zu entfernen und sicherzustellen, dass alle Daten in einem für deine Analyse geeigneten Format vorliegen. Daten, die viele Fehler enthalten oder die diesen Datenbereinigungsprozess nicht durchlaufen haben, werden als schmutzige Daten bezeichnet.
Dieser Schritt mag sich für viele junge Datenexperten optional anfühlen, aber sei versichert, dass er entscheidend ist! Ohne eine ordnungsgemäße Datenbereinigung kann dein Modell zu einer falschen Schlussfolgerung kommen, dein Diagramm kann einen falschen Trend anzeigen und deine Statistiken können sehr ungenau sein.
Betrachte einen extrem kleinen Datensatz. Du und deine Freunde teilen die Süßigkeiten gleichmäßig unter euch auf und ihr müsst bestimmen, wie viele Süßigkeiten jede Person bekommt. Du gibst deine Daten in die untenstehende Tabelle ein.
|
Person |
Anzahl der Bonbons |
|
Peter |
5 |
|
Sandy |
20 |
|
Sandy |
20 |
|
Joseph |
3 |
|
Amed |
12 |
Wenn du nun den Mittelwert der Spalte Anzahl der Bonbons nimmst, könntest du zu dem Schluss kommen, dass jede Person 12 Bonbons bekommen sollte.
Wenn du jedoch versuchst, jeder Person 12 Bonbons zu geben, werden dir die Bonbons ausgehen, bevor jeder seinen Anteil bekommt, weil Sandy in deiner Tabelle doppelt vorhanden ist. Du hast nur 40 statt 60 Bonbons in deinem Vorrat (und in Wirklichkeit nur 4 statt 5)!
Wenn du dir nicht die Zeit nimmst, deinen Datensatz zu bereinigen, riskierst du, dass deine Analyse zu einem falschen Ergebnis führt.
Wenn du die Süßigkeiten unter deinen Freunden aufteilst, kann die größte Konsequenz eine verärgerte Freundschaft sein. Aber in der Geschäftswelt könnte die Vernachlässigung der Datenbereinigung zu Analysen führen, die vorschlagen, das falsche Produkt auf den Markt zu bringen, die falsche Anzahl von Mitarbeitern einzustellen, in die falschen Aktien zu investieren oder einem Kunden sogar den falschen Preis zu berechnen!
Die Datenbereinigung ist umso wichtiger, je komplexer die Analysen sind. Bei komplexen Analysen kann es sein, dass du nicht so genau weißt, wie die Ergebnisse aussehen sollten, sodass du nicht erkennst, wenn die Ergebnisse falsch sind.
Eine gründliche Datenbereinigung und sorgfältige Tests helfen, diese Bedenken zu zerstreuen. In diesem Lernprogramm erfährst du, was du über die Datenbereinigung in Python wissen musst.
Es gibt viele Arten von Fehlern und Ungereimtheiten, die dazu beitragen können, dass Daten unsauber sind. Gehen wir ein paar der häufigsten Arten durch und warum sie problematisch sind.
Unvollständige Datensätze sind extrem häufig. Es kann sein, dass in deinem Datensatz Daten aus mehreren Jahren fehlen, dass er nur einige Informationen über einen Kunden enthält oder dass er nicht die gesamte Produktpalette deines Unternehmens abdeckt.
Fehlende Werte können verschiedene Auswirkungen auf deine Analyse haben. Wenn große Teile wichtiger Daten fehlen, kann das zu Verzerrungen in deinen Ergebnissen führen. Außerdem können NaN-Werte oder fehlende Zellen in einem DataFrame einen Python-Code kaputt machen, was beim Aufbau deines Modells zu viel Frustration führen kann.
Ausreißer sind Werte, die weit außerhalb der Norm liegen und nicht repräsentativ für die Daten sind. Ausreißer können das Ergebnis eines Tippfehlers oder außergewöhnlicher Umstände sein. Es ist wichtig, echte Ausreißer von informativen Extremsituationen zu unterscheiden. Ausreißer können deine Ergebnisse verfälschen und letztlich die falsche Antwort nahelegen.
Wie wir oben gesehen haben, können doppelte Dateneinträge einen Eintrag in deiner Analyse überrepräsentieren und zu einer falschen Schlussfolgerung führen. Achte auf Duplikate, die mehr als einmal vorkommen, und auf solche, die widersprüchliche oder aktualisierte Informationen enthalten.
Manchmal sind die Werte in unserem Datensatz einfach falsch. Vielleicht hast du den Namen eines Kunden falsch geschrieben, die falsche Produktnummer, veraltete Informationen oder falsch beschriftete Daten.
Es kann manchmal schwierig sein, festzustellen, ob deine Daten fehlerhaft sind. Deshalb ist die Überprüfung deiner Quelle so wichtig! Denk daran, dass deine Analyse nur so gut ist wie deine Daten.
Ungereimtheiten gibt es in vielen Formen. Es kann zu inkonsistenten Dateneinträgen kommen, die auf einen Tippfehler oder einen Irrtum hindeuten können. Wenn du ein Kundenalter rückwärts siehst, eine Zutat, die ihre ID-Nummer ändert, oder ein Produkt mit zwei gleichzeitigen Preisen, lohnt es sich, genauer hinzuschauen, um sicherzustellen, dass alles korrekt ist.
Eine weitere problematische Art der Inkonsistenz ist die Inkonsistenz im Format der Daten. Unterschiedliche Werte können in verschiedenen Einheiten (Kilometer vs. Meilen vs. Zoll), in verschiedenen Stilen (Monat, Tag, Jahr vs. Jahr) gemeldet werden. Tag-Monat-Jahr), in unterschiedlichen Datentypen (Fließkommazahlen vs. Ganzzahlen) oder sogar in unterschiedlichen Dateitypen (.jpg vs. .png).
Diese Unstimmigkeiten machen es für deinen Code schwierig, wenn nicht sogar unmöglich, die Werte richtig zu interpretieren. Das kann zu einer falschen Analyse führen oder dazu, dass dein Code überhaupt nicht läuft.
Es ist wichtig, dass du deinen Datensatz verstehst, bevor du ihn für eine komplexe Analyse verwendest. Um diese Art von Verständnis für deine Daten zu entwickeln, solltest du eine Datenexploration durchführen. Du kannst dir diesen Schritt als die Analyse vor der Analyse vorstellen.
Schauen wir uns einige typische Schritte an, um eine Datenexploration in einem tabellenformatierten Datensatz durchzuführen:
Das alles mag für deine geplante Analyse überflüssig erscheinen, aber es gibt ein paar wichtige Gründe, warum du diese Schritte immer durchführen solltest. Erstens bekommst du dadurch ein gutes Verständnis für die Grenzen deines Datensatzes, was wichtig ist, wenn du den Ergebnissen deiner endgültigen Analysen vertrauen willst.
Zweitens kann die Datenexploration dich auf wichtige Trends und Analysen hinweisen, die du vorher nicht bedacht hast. Diese haben das Potenzial, deine geplanten Analysen zu ergänzen oder einen komplizierenden Faktor darzustellen, den du berücksichtigen musst.
Drittens kann diese Voranalyse ein erster Anhaltspunkt dafür sein, wo du möglicherweise unsaubere Daten hast. Das kann das erste Mal sein, dass du einen Ausreißer entdeckst, feststellst, dass es doppelt so viele Kategorien wie nötig gibt, oder entdeckst, dass die Methode der Datenerhebung im letzten Jahr anders war als im Jahr davor. Dies sind alles wichtige Informationen, die dich neugierig auf deinen Datensatz machen sollten.
Weitere Informationen zur Datenexploration findest du im DataCamp-Kurs "Datenexploration in Python " oder in diesem Tutorial für absolute Anfänger.
Kommen wir zu den Feinheiten einiger Datenbereinigungstechniken in Python, indem wir uns damit beschäftigen, wie man mit einigen häufigen Problemen mit schmutzigen Daten umgeht.
Wenn du einen großen Datensatz hast, fehlen zwangsläufig einige Felder in einem oder mehreren Einträgen. Das bedeutet nicht nur, dass dir wertvolle Daten fehlen, sondern die NaN-Einträge können auch einige Python-Funktionen durcheinander bringen und dein Modell ungenau machen.
Wenn du einen fehlenden Wert findest, hast du die Wahl, entweder diesen Eintrag aus der Analyse zu streichen oder zu versuchen, einen vernünftigen Wert an dessen Stelle zu setzen. Wenn dein Datensatz relativ klein ist, würde ich vorschlagen, dass du dir die Zeilen mit den fehlenden Werten ansiehst, damit du die beste Vorgehensweise festlegen kannst.
import pandas as pd # Identify rows with NaN valuesrows_with_nan = df[df.isnull().any(axis=1)] #View the rows with NaN valuesprint(rows_with_nan)Das Löschen eines Eintrags ist normalerweise nicht die erste Wahl, da es bedeutet, dass potenziell wertvolle Informationen aus der Analyse herausgenommen werden.
Manchmal ist das Löschen jedoch die beste Option, z. B. wenn der Eintrag nicht genug andere Informationen liefert, um ihn zu behalten (z. B. wenn der Eintrag nur ein Datum ohne wertvolle Informationen ist).
Das Löschen ist auch der einfachste Weg, um mit Einträgen umzugehen, die fehlende Werte enthalten. Wenn du also wenig Zeit hast und der Rest des Eintrags nicht wichtig für die Analyse ist, ist das Löschen von Einträgen mit NaNs eine Option.
Du kannst die Methode .dropna() aus der Pandas-Bibliothek verwenden, um Zeilen aus einem DataFrame zu löschen, die NaNs enthalten.
import pandas as pd # Assuming df is your DataFramedf.dropna(inplace=True)Die allgemein bevorzugte Methode zum Umgang mit fehlenden Werten ist das Imputieren eines angemessenen Wertes. Einen angemessenen Wert für die Anrechnung zu finden, kann eine Kunst für sich sein, aber es gibt einige bewährte Methoden, die ein guter Ausgangspunkt sein können.
Die Methode .fillna() von Pandas setzt fehlende Werte mit dem Mittelwert gleich, um die Verteilung nicht zu verändern.
import pandas as pd # Assuming df is your DataFrame# Replace NaN values with the mean of the columndf.fillna(df.mean(), inplace=True)Die sci-kit learn Bibliothek hat eine einfache Imputationsfunktion, die ebenfalls gut funktioniert.
from sklearn.impute import SimpleImputerimport pandas as pd # Assuming df is your DataFrameimputer = SimpleImputer(strategy='mean')df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Wenn du eine komplexere Imputationsmethode brauchst, kannst du eine KNN- oder Regressions-Imputation verwenden, um einen guten Wert zu finden. Welche Methode du letztendlich wählst, hängt von deinen Daten, deinen Bedürfnissen und deinen verfügbaren Ressourcen ab.
Ausreißer sind ein bisschen schwierig zu handhaben. Einige scheinbare Ausreißer sind in Wirklichkeit wichtige Daten, z. B. wie der Aktienmarkt auf Krisen wie COVID-19 und die globale Rezession reagiert. Bei anderen kann es sich jedoch um Tippfehler oder irrelevante, seltene Umstände handeln, die entfernt werden sollten.
Um den Unterschied zu erkennen, ist es oft wichtig, deine Daten im Kontext zu verstehen, was dir bei deiner vorherigen Datenexploration geholfen haben sollte, und eine klare Vorstellung vom Ziel deiner Analyse zu haben.
Viele Ausreißer sind sichtbar, wenn die Daten aufgezeichnet werden, aber du kannst auch statistische Methoden verwenden, um Ausreißer zu identifizieren.
Eine gängige Methode ist die Berechnung eines Z-Scores für jeden Datenpunkt und die Eliminierung der Werte mit einem extremen Z-Score.
import numpy as npimport pandas as pd # Generate some sample datanp.random.seed(0)data = np.random.randint(low=0, high=11, size=1000)# Add some outliersdata[0] = 100data[1] = -100 # Calculate Z-scoresz_scores = (data - np.mean(data)) / np.std(data) # Identify outliers based on Z-score threshold (e.g., 3)threshold = 3outliers = np.where(np.abs(z_scores) > threshold)[0] print("Outliers identified using Z-score method:")print(data[outliers])Eine andere Methode besteht darin, den Interquartilsbereich (IQR) der Verteilung zu berechnen und alle Werte, die Q1-(1,5 x IQR) oder Q3 + (1,5 x IQR) liegen, als potenzielle Ausreißer einzustufen.
import numpy as npimport pandas as pd # Generate some sample datanp.random.seed(0)data = np.random.randint(low=0, high=11, size=1000)# Add some outliersdata[0] = 100data[1] = -100 # Calculate quartiles and IQRq1 = np.percentile(data, 25)q3 = np.percentile(data, 75)iqr = q3 - q1 # Identify outliers based on IQRlower_bound = q1 - (1.5 * iqr)upper_bound = q3 + (1.5 * iqr)outliers = np.where((data < lower_bound) | (data > upper_bound))[0] print("Outliers identified using IQR method:")print(data[outliers])Wenn du Ausreißer identifiziert hast und feststellst, dass sie problematisch sind, gibt es verschiedene Methoden, um sie zu beseitigen. Wenn du festgestellt hast, dass der Ausreißer auf einen Fehler zurückzuführen ist, kann es möglich sein, den Fehler einfach zu korrigieren, um den Ausreißer zu beheben.
In anderen Fällen kann es möglich sein, den Ausreißer aus dem Datensatz zu entfernen oder ihn durch einen weniger extremen Wert zu ersetzen, der die Gesamtform der Verteilung beibehält.
Bei der Capping-Methode legst du eine Obergrenze oder einen Schwellenwert für die Verteilung deiner Daten fest und ersetzt alle Werte außerhalb dieser Grenzen durch einen bestimmten Wert.
import pandas as pdimport numpy as np # Create a sample DataFrame with outliersdata = { 'A': [100, 90, 85, 88, 110, 115, 120, 130, 140], 'B': [1, 2, 3, 4, 5, 6, 7, 8, 9]}df = pd.DataFrame(data) # Define the lower and upper thresholds for capping (Here I used the 5th and 95th percentiles)lower_threshold = df.quantile(0.05)upper_threshold = df.quantile(0.95) # Cap outlierscapped_df = df.clip(lower=lower_threshold, upper=upper_threshold, axis=1) print("Original DataFrame:")print(df)print("\nCapped DataFrame:")print(capped_df)In manchen Fällen kannst du deine Daten so umwandeln, dass Ausreißer weniger stark ins Gewicht fallen, z. B. durch eine Quadratwurzeltransformation oder eine logarithmische Transformation.
Sei vorsichtig, wenn du deine Daten umwandelst, denn wenn du nicht aufpasst, kannst du auf lange Sicht mehr Probleme verursachen. Bevor du dich für die Umwandlung deiner Daten entscheidest, solltest du einige Dinge beachten.
Um mehr über Datentransformationen zu erfahren, empfehle ich einen Statistikkurs wie DataCamp's Introduction to Statistics in Python oder Statistics Fundamentals with Python.
Wir haben bereits gesehen, wie Duplikate unsere Analysen beeinträchtigen können. Zum Glück ist es mit Python ganz einfach, Duplikate zu erkennen und zu behandeln.
Mit der Methode duplicated() in der Python-Bibliothek pandas kannst du ganz einfach doppelte Zeilen in einem DataFrame identifizieren und untersuchen.
import pandas as pd# Assuming 'df' is your DataFrameduplicate_rows = df[df.duplicated()]Dies gibt einen DataFrame zurück, der Zeilen enthält, die doppelt sind. Sobald du diesen DataFrame mit den doppelten Zeilen hast, solltest du dir die Duplikate ansehen, wenn es nicht zu viele davon gibt.
Die meisten Duplikate sind exakte Kopien und können einfach mit der Methode drop_duplicates() in Pandas gelöscht werden:
# Removing duplicatescleaned_df = df.drop_duplicates()In manchen Fällen kann es sinnvoller sein, doppelte Datensätze zusammenzuführen und Informationen zu aggregieren. Wenn zum Beispiel Duplikate mehrere Einträge für dieselbe Entität darstellen, können wir sie mithilfe von Aggregationsfunktionen zusammenführen:
# Merging duplicates by aggregating valuesmerged_df = df.groupby(list_of_columns).agg({'column_to_merge': 'sum'})Damit werden doppelte Zeilen zu einer einzigen zusammengefasst und die Werte anhand von Funktionen wie Summe, Mittelwert usw. aggregiert.
import pandas as pd#Sample DataFramedata = { 'customer_id' : [102, 102, 101, 103, 102] 'product_id' : ['A', 'B', 'A', 'C', 'B'] 'quantity_sold : [5, 3, 2, 1, 4]}df = pd.DataFrame(data)df}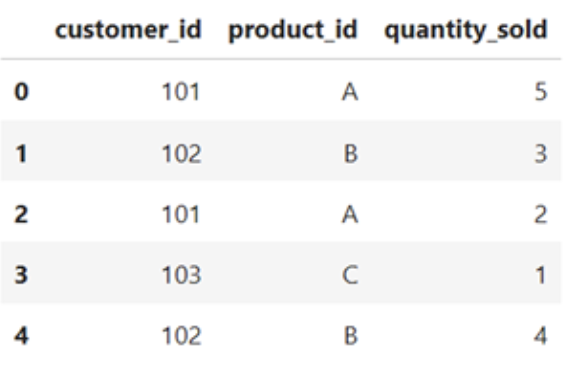
# Merging duplicates by aggregating valuesmerged_df = df.groupby(['cutomer_id', 'product_id']).agg({'quantity_sold': 'sum'}).reset_index()merged_df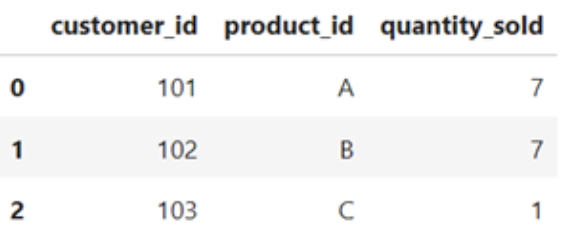
Unterschiedliche Arten von Ungereimtheiten erfordern unterschiedliche Lösungen. Unstimmigkeiten, die durch falsche Dateneingaben oder Tippfehler entstanden sind, müssen möglicherweise von einer sachkundigen Stelle korrigiert werden. Alternativ können die fehlerhaften Daten durch Imputation ersetzt werden, als ob es sich um einen fehlenden Wert handeln würde, oder ganz aus dem Datensatz entfernt werden, je nach den Umständen.
Unstimmigkeiten in der Formatierung der Daten können mit einigen Standardisierungsmethoden korrigiert werden. Um führende und nachgestellte Leerzeichen aus einem String zu entfernen, kannst du die Methode .strip() verwenden. Die Methoden .upper() und .lower() vereinheitlichen die Groß- und Kleinschreibung in Zeichenketten. Und die Konvertierung von Datumsangaben in Datumszeiten mit pd.to_datetime wird die Datumsformatierung standardisieren.
Du kannst auch sicherstellen, dass jeder Wert in der Spalte eines DataFrame denselben Datentyp hat, indem du die Methode .astype() verwendest.
Andere Korrekturen von Formatierungsinkonsistenzen, die du eventuell vornehmen musst, sind:
value_mapping = {'M': 'Male', 'F': 'Female'}standardized_value = value_mapping.get('M', 'Unknown')Datenumwandlung und Feature-Engineering sind Vorverarbeitungstechniken zur Umwandlung von Rohdaten in ein Format, das für maschinelle Lernalgorithmen und statistische Analysen besser geeignet ist. In diesem Abschnitt werden wir kurz einige gängige Datenumwandlungs- und Feature-Engineering-Techniken in Python vorstellen.
Normalisierung und Standardisierung sind zwei Techniken, die verwendet werden, um Merkmale auf einen ähnlichen Maßstab zu bringen, was für viele Algorithmen des maschinellen Lernens wichtig ist.
Bei der Normalisierung werden die Daten auf einen festen Bereich skaliert, normalerweise zwischen 0 und 1. Dadurch wird sichergestellt, dass alle Merkmale auf der gleichen Skala liegen, und verhindert, dass bestimmte Merkmale andere aufgrund ihrer größeren Größe dominieren.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(data)Bei der Standardisierung hingegen werden die Daten so umgewandelt, dass sie einen Mittelwert von 0 und eine Standardabweichung von 1 haben. Diese Technik ist nützlich, wenn die Daten verschiedene Skalen und unterschiedliche Bereiche haben, und sie stellt sicher, dass jedes Merkmal einen vergleichbaren Einfluss auf das Modell hat.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)Die spezifischen Merkmale deiner Daten und die Anforderungen deines geplanten Modells bestimmen, wie du deine Daten skalieren wirst. Erfahre mehr über den Unterschied zwischen Normalisierung und Standardisierung in unserem speziellen Tutorial Normalisierung vs. Standardisierung. Standardisierung: Wie du den Unterschied erkennst.
Die Kodierung kategorialer Variablen ist ein wichtiger Schritt bei der Vorverarbeitung im maschinellen Lernen, wenn es sich um nicht numerische Merkmale handelt. Kategoriale Variablen stellen qualitative Daten dar, z. B. Typen, Klassen oder Etiketten. Um diese Variablen in Algorithmen für maschinelles Lernen zu verwenden, müssen sie in ein numerisches Format umgewandelt werden.
Eine gängige Technik zur Kodierung kategorialer Variablen ist die One-Hot-Kodierung, bei der jede Kategorie in einen binären Vektor umgewandelt wird. Diese Methode ist besonders nützlich, wenn du mit nominalen kategorialen Variablen arbeitest, bei denen es keine inhärente Ordnung oder Hierarchie zwischen den Kategorien gibt.
import pandas as pd
encoded_data = pd.get_dummies(data, columns=['categorical_column'])
import pandas as pd
# Create a sample DataFrame with a categorical column
data = {
'ID': [1, 2, 3, 4, 5],
'Color': ['Red', 'Blue', 'Green', 'Red', 'Blue']
}
df = pd.DataFrame(data)
# Perform one-hot encoding
encoded_data = pd.get_dummies(df, columns=['Color'])
print("Original DataFrame")
print(df)
print("\nEncoded DataFrame:")
print(encoded_data)

Ein anderer Ansatz ist die Label-Kodierung, bei der jeder Kategorie eine eindeutige Ganzzahl zugewiesen wird. Jede Kategorie wird einem numerischen Wert zugeordnet, wodurch kategoriale Bezeichnungen in Ordnungszahlen umgewandelt werden. Diese Methode eignet sich für ordinale kategoriale Variablen, bei denen es eine natürliche Reihenfolge oder Rangfolge zwischen den Kategorien gibt.
from sklearn.preprocessing import LabelEncoderencoder = LabelEncoder()encoded_data['categorical_column'] = encoder.fit_transform(data['categorical_column'])from sklearn.preprocessing import LabelEncoderimport pandas as pd#Create a sample DataFrame with categorical column data = { 'ID' : [1, 2, 3, 4, 5] 'Color' : [ 'Red', 'Blue', 'Green', 'Red', 'Green' ]}df = pd.DataFrame(data)#Perform label encodingencoder = LabelEncoder()df ['Color_LabelEncoded'] = encoder.fit_transform(df['Color'])print("Original DataFrame:")print(df[['ID', 'Color']])print("\nDataFrame with Label Encoded Column:")print(df[['ID', 'Color_LabelEncoded']])
Es ist wichtig, die richtige Kodierungsmethode zu wählen, die sich nach der Art der kategorialen Variablen und den Anforderungen des maschinellen Lernalgorithmus richtet. Die One-Hot-Codierung wird im Allgemeinen für nominale Variablen bevorzugt, während die Label-Codierung für ordinale Variablen geeignet ist.
Feature-Engineering ist ein Schritt in der Entwicklung von Machine-Learning-Modellen, bei dem neue Features erstellt oder bestehende verändert werden. Dieser Prozess ist üblich, wenn die Rohdaten keine Merkmale enthalten, die direkt zur Lernaufgabe beitragen, oder wenn die vorhandenen Merkmale nicht in einer Form vorliegen, die der Lernalgorithmus effektiv nutzen kann.
Stell dir ein Szenario vor, in dem du mit einem Datensatz von Immobilienpreisen arbeitest und den Verkaufspreis von Häusern auf der Grundlage verschiedener Merkmale wie der Anzahl der Zimmer, der Quadratmeterzahl der Wohnfläche und des Zustands der Immobilie vorhersagen möchtest. Der Datensatz enthält jedoch kein Merkmal, das direkt den Gesamtzustand des Hauses erfasst.
In diesem Fall kannst du ein neues Merkmal erstellen, indem du bestehende Merkmale kombinierst oder relevante Informationen extrahierst.
Du könntest z.B. ein Merkmal "Gesamtzustand" erstellen, indem du die Zustandsbewertungen einzelner Komponenten des Hauses zusammenfasst, z.B. den Zustand der Küche, die Qualität des Kellers, das Alter der Immobilie, die letzten Renovierungen usw.
In Fällen, in denen die Beziehung zwischen Merkmalen und der Zielvariablen nicht linear ist, können polynomiale Merkmale erzeugt werden, indem bestehende Merkmale auf verschiedene Potenzen erhöht werden. Dieser Ansatz hilft, komplexe Beziehungen zwischen Variablen zu erfassen, die möglicherweise nicht linear trennbar sind.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
polynomial_features = poly.fit_transform(data)
In anderen Fällen hast du es vielleicht mit hochdimensionalen Datensätzen oder Multikollinearität zwischen den Merkmalen zu tun. Techniken wie die Hauptkomponentenanalyse (PCA) können eingesetzt werden, um die Dimensionalität des Datensatzes zu reduzieren und gleichzeitig die meisten relevanten Informationen zu erhalten.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
transformed_features = pca.fit_transform(data)Das Feature-Engineering stellt sicher, dass du die richtigen Daten im richtigen Format hast, damit dein Modell sie verwenden kann. Es gibt viele Techniken im Feature Engineering, und welche du verwendest, hängt stark davon ab, was du erreichen willst.
In diesem Feature-Engineering-Kurs findest du weitere Techniken, die für dich nützlich sein könnten.
Die Datenbereinigung ist ein wichtiger Schritt bei jeder Datenanalyse und jedem maschinellen Lernprojekt. Im Folgenden findest du einige Best Practices, die du bei der Optimierung deines Datenbereinigungsprozesses beachten solltest:
Behalte immer das Original!
Dies ist der wichtigste Tipp bei der Datenbereinigung. Bewahre eine Kopie der Rohdatendateien getrennt von den bereinigten und verarbeiteten Versionen auf. So ist sichergestellt, dass du immer einen Bezugspunkt hast und bei Bedarf leicht zu den ursprünglichen Daten zurückkehren kannst.
Ich persönlich mache immer eine Kopie der Rohdaten-Datei, bevor ich Änderungen vornehme, und hänge den Zusatz "-RAW" an den Dateinamen, damit ich weiß, welches das Original ist.
Füge Kommentare zu deinem Code hinzu, um den Zweck jedes Reinigungsschritts und alle getroffenen Annahmen zu erklären.
Du solltest sicherstellen, dass deine Datenbereinigung die Verteilung nicht wesentlich verändert oder unbeabsichtigte Verzerrungen verursacht. Eine wiederholte Datenuntersuchung nach deinen Bereinigungsmaßnahmen kann dir helfen, auf dem richtigen Lernpfad zu bleiben.
Wenn du einen langen oder automatisierten Reinigungsprozess hast, solltest du ein separates Dokument führen, in dem du die Details jedes Reinigungsschritts festhältst.
Details wie das Datum, die ergriffenen Maßnahmen und alle aufgetretenen Probleme können später hilfreich sein.
Denke daran, dieses Dokument an einem leicht zugänglichen Ort zu speichern, z. B. im gleichen Projektordner wie die Daten oder der Code. Im Falle einer automatisierten, regelmäßig aktualisierten Pipeline solltest du in Erwägung ziehen, dieses Protokoll automatisch in den Datenbereinigungsprozess einzubinden. So kannst du dich vergewissern, dass alles reibungslos funktioniert.
Identifiziere häufige Datenbereinigungsaufgaben und kapsle sie in wiederverwendbaren Funktionen. So kannst du die gleichen Bereinigungsschritte auf mehrere Datensätze anwenden. Das ist besonders hilfreich, wenn du firmenspezifische Abkürzungen hast, die du abbilden willst.
Nutze die DataCamp Checkliste zur Datenbereinigung, um sicherzustellen, dass du nichts übersiehst!
Die Datenbereinigung ist nicht nur eine banale Aufgabe, sondern ein entscheidender Schritt, der die Grundlage für jede erfolgreiche Datenanalyse und jedes maschinelle Lernprojekt bildet. Indem du sicherstellst, dass deine Daten genau, konsistent und zuverlässig sind, legst du den Grundstein für fundierte Entscheidungen und aussagekräftige Erkenntnisse.
Unsaubere Daten können zu falschen Schlussfolgerungen und fehlerhaften Analysen führen, was erhebliche Folgen haben kann, egal ob du Süßigkeiten unter Freunden aufteilst oder geschäftliche Entscheidungen triffst. Die Zeit und Mühe, die du in die Bereinigung deiner Daten investierst, zahlt sich langfristig aus, denn sie gewährleistet, dass deine Analysen vertrauenswürdig und deine Ergebnisse verwertbar sind.
Weitere Informationen und interaktive Übungen findest du im DataCamp-Kurs zur Datenbereinigung. Wenn du eine praktische Herausforderung suchst, kannst du diesen Code zur Datenbereinigung ausprobieren.
Beginne deine Reise zur Datenbereinigung noch heute!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
