
Cursus
Importation et nettoyage des données en Python
13 h
Lorsque vous démarrez un nouveau projet de données, les données que vous obtenez sont rarement parfaites pour votre analyse dès le départ. Il est donc essentiel que vous procédiez au nettoyage de vos données au début de chaque nouveau projet.
Le nettoyage des données consiste à supprimer les erreurs, les valeurs aberrantes et les incohérences et à s'assurer que toutes les données sont dans un format adapté à l'analyse. Les données qui contiennent de nombreuses erreurs ou qui n'ont pas été soumises à ce processus de nettoyage sont appelées "données sales".
Cette étape peut sembler facultative à de nombreux jeunes professionnels des données, mais sachez qu'elle est cruciale ! Sans un nettoyage adéquat des données, votre modèle peut aboutir à une conclusion erronée, votre graphique peut montrer une tendance erronée et vos statistiques peuvent être totalement inexactes.
Prenons l'exemple d'un ensemble de données extrêmement réduit. Vous et vos amis partagez vos bonbons en parts égales entre chacun d'entre vous, et vous devez déterminer combien de bonbons chaque personne reçoit. Vous inscrivez vos données dans le tableau ci-dessous.
|
Personne |
Nombre de bonbons |
|
Pierre |
5 |
|
Sandy |
20 |
|
Sandy |
20 |
|
Joseph |
3 |
|
Amed |
12 |
Si vous prenez la moyenne de la colonne Nombre de bonbons, vous pouvez conclure que chaque personne devrait recevoir 12 bonbons.
Cependant, si vous essayez de donner 12 bonbons à chaque personne, vous serez à court avant que tout le monde n'ait reçu sa part parce que Sandy a été dupliqué dans votre tableau. Il n'y a que 40 bonbons dans votre réserve au lieu de 60 (et, en fait, seulement 4 personnes, et non 5) !
Si vous ne prenez pas le temps de nettoyer votre ensemble de données, vous risquez que votre analyse aboutisse à une conclusion erronée.
Dans le cas d'un partage de bonbons entre amis, la conséquence la plus importante peut être une amitié contrariée. Mais dans le monde des affaires, négliger de nettoyer votre ensemble de données peut conduire à des analyses qui suggèrent de lancer le mauvais produit, d'embaucher le mauvais nombre d'employés, d'investir dans les mauvaises actions ou même de facturer le mauvais prix à un client !
Le nettoyage des données est d'autant plus important que les analyses sont complexes. Dans le cas d'analyses complexes, il se peut que vous n'ayez pas une idée aussi précise de ce que devraient être les résultats, ce qui signifie que vous risquez de ne pas vous rendre compte que les résultats sont erronés.
Un nettoyage approfondi des données, accompagné de tests minutieux, permettra d'apaiser ces inquiétudes. Dans ce tutoriel, nous allons couvrir ce que vous devez savoir sur le processus de nettoyage des données en Python.
De nombreux types d'erreurs et d'incohérences peuvent contribuer à la saleté des données. Passons en revue quelques-uns des types les plus courants et les raisons pour lesquelles ils posent problème.
Les ensembles de données incomplets sont extrêmement fréquents. Il se peut qu'il manque plusieurs années de données à votre ensemble de données, qu'il ne contienne que quelques informations sur un client ou qu'il ne contienne pas l'ensemble des produits de votre entreprise.
Les valeurs manquantes peuvent avoir de multiples effets sur votre analyse. L'absence d'une grande partie des données essentielles peut fausser vos résultats. En outre, les valeurs NaN ou les cellules manquantes dans un DataFrame peuvent casser certains codes Python, causant ainsi beaucoup de frustration lors de la construction de votre modèle.
Les valeurs aberrantes sont des valeurs très éloignées de la norme et non représentatives des données. Les valeurs aberrantes peuvent résulter d'une faute de frappe ou de circonstances exceptionnelles. Il est important de différencier les vraies valeurs aberrantes des situations extrêmes informatives. Les valeurs aberrantes peuvent fausser vos résultats et suggérer en fin de compte une mauvaise réponse.
Comme nous l'avons vu plus haut, les entrées de données en double peuvent surreprésenter une entrée dans votre analyse, ce qui conduit à une conclusion erronée. Soyez attentif aux doublons qui apparaissent plusieurs fois et à ceux qui contiennent des informations contradictoires ou mises à jour.
Parfois, les valeurs de notre ensemble de données sont tout simplement erronées. Il se peut que le nom d'un client soit mal orthographié, que le numéro de produit soit erroné, que les informations soient obsolètes ou que les données soient mal étiquetées.
Il est parfois difficile de déterminer si vos données sont erronées, c'est pourquoi la vérification de votre source est si importante ! N'oubliez pas que la qualité de votre analyse dépend de celle de vos données.
Les incohérences se présentent sous de nombreuses formes. Il peut y avoir des entrées de données incohérentes, ce qui peut indiquer une faute de frappe ou une erreur. Si vous voyez l'âge d'un client reculer, un ingrédient changer de numéro d'identification ou un produit avoir deux prix simultanés, cela vaut la peine d'y regarder de plus près pour s'assurer que tout est correct.
Un autre type d'incohérence problématique est l'incohérence dans le format des données. Des valeurs différentes peuvent être rapportées dans des unités différentes (kilomètres vs. miles vs. pouces), dans des styles différents (Mois Jour, Année vs. Jour-Mois-Année), dans des types de données différents (flottants ou entiers) ou même dans des types de fichiers différents (.jpg ou .png).
Ces incohérences rendront difficile, voire impossible, l'interprétation correcte des valeurs par votre code. Il peut en résulter une analyse incorrecte ou l'arrêt de l'exécution de votre code.
Il est essentiel que vous compreniez votre ensemble de données avant de l'utiliser dans une analyse complexe. Pour développer ce type de compréhension de vos données, vous devez procéder à une exploration des données. Vous pouvez considérer cette étape comme l'analyse préalable.
Examinons quelques étapes typiques pour effectuer une exploration de données sur un ensemble de données au format tableau :
Tout cela peut sembler superflu par rapport à l'analyse que vous souhaitez faire, mais il y a quelques raisons importantes pour lesquelles vous devriez toujours prendre ces mesures. Tout d'abord, cela vous permettra de bien comprendre les limites de votre ensemble de données, ce qui est essentiel si vous voulez vous fier aux résultats de vos analyses finales.
Deuxièmement, l'exploration des données peut vous orienter vers des tendances et des analyses importantes que vous n'aviez pas envisagées auparavant. Ceux-ci sont susceptibles d'enrichir vos analyses ou de présenter un facteur de complication dont vous devez tenir compte.
Troisièmement, cette pré-analyse peut être le premier indice de l'existence de données sales. C'est peut-être la première fois que vous voyez une valeur aberrante, que vous vous rendez compte qu'il y a deux fois plus de catégories qu'il n'en faudrait ou que vous découvrez que la méthode de collecte des données n'était pas la même l'année dernière que l'année précédente. Il s'agit là d'éléments d'information essentiels qui devraient vous inciter à vous intéresser à votre ensemble de données.
Pour plus d'informations sur l'exploration des données, consultez le cours Data Exploration in Python de DataCamp ou ce tutoriel pour les grands débutants.
Entrons dans le vif du sujet avec quelques techniques de nettoyage de données en Python en abordant la manière de traiter certains problèmes courants de données sales.
Invariablement, lorsque vous disposez d'un grand ensemble de données, certains champs manquent dans une ou plusieurs entrées. Cela signifie non seulement que vous manquez des données précieuses, mais aussi que les entrées NaN peuvent perturber certaines fonctions Python, ce qui rend votre modèle inexact.
Lorsque vous trouvez une valeur manquante, vous avez le choix entre éliminer cette entrée de l'analyse ou essayer d'imputer une valeur raisonnable pour la remplacer. Si votre ensemble de données est raisonnablement petit, je vous suggère de visualiser les lignes qui contiennent des valeurs manquantes afin que vous puissiez déterminer la meilleure marche à suivre.
import pandas as pd # Identify rows with NaN valuesrows_with_nan = df[df.isnull().any(axis=1)] #View the rows with NaN valuesprint(rows_with_nan)La suppression d'une entrée n'est généralement pas le premier choix, car cela revient à retirer de l'analyse des informations potentiellement précieuses.
Cependant, la suppression est parfois la meilleure option, par exemple, si l'entrée ne fournit pas suffisamment d'autres informations pour justifier sa conservation (par exemple, si l'entrée n'est qu'une date sans aucune information utile).
La suppression est également le moyen le plus simple de traiter les entrées qui contiennent des valeurs manquantes. Par conséquent, si vous manquez de temps et que le reste de l'entrée n'est pas important pour l'analyse, il est possible de supprimer les entrées contenant des NaN.
Vous pouvez utiliser la méthode .dropna() de la bibliothèque Pandas pour supprimer les lignes d'un DataFrame qui contiennent des NaN.
import pandas as pd # Assuming df is your DataFramedf.dropna(inplace=True)La méthode généralement préférée pour traiter les valeurs manquantes est l'imputation d'une valeur raisonnable. Trouver une valeur raisonnable à imputer peut être un art en soi, mais il existe plusieurs méthodes établies qui peuvent constituer un bon point de départ.
La méthode .fillna() de Pandas impute les valeurs manquantes en utilisant la moyenne afin de ne pas modifier la distribution.
import pandas as pd # Assuming df is your DataFrame# Replace NaN values with the mean of the columndf.fillna(df.mean(), inplace=True)La bibliothèque sci-kit learn dispose d'une fonction d'imputation simple qui fonctionne également très bien.
from sklearn.impute import SimpleImputerimport pandas as pd # Assuming df is your DataFrameimputer = SimpleImputer(strategy='mean')df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Si vous avez besoin d'une méthode d'imputation plus complexe, vous pouvez envisager d'utiliser une imputation par KNN ou par régression pour trouver une bonne valeur. En fin de compte, la méthode que vous choisirez dépendra de vos données, de vos besoins et des ressources dont vous disposez.
Les valeurs aberrantes sont un peu difficiles à traiter. Certaines données apparemment aberrantes sont en fait importantes, comme la façon dont le marché boursier réagit à des crises telles que COVID-19 et la récession mondiale. Toutefois, d'autres peuvent être des fautes de frappe ou des circonstances rares et non pertinentes, et doivent être supprimées.
Pour faire la différence, il faut souvent comprendre vos données dans leur contexte, ce que votre précédente exploration des données devrait vous avoir aidé à faire, et avoir une idée claire de l'objectif de votre analyse.
De nombreuses valeurs aberrantes sont visibles lorsque les données sont représentées graphiquement, mais vous pouvez également utiliser des méthodes statistiques pour identifier les valeurs aberrantes.
Une méthode courante consiste à calculer un score Z pour chaque point de données et à éliminer les valeurs présentant un score Z extrême.
import numpy as npimport pandas as pd # Generate some sample datanp.random.seed(0)data = np.random.randint(low=0, high=11, size=1000)# Add some outliersdata[0] = 100data[1] = -100 # Calculate Z-scoresz_scores = (data - np.mean(data)) / np.std(data) # Identify outliers based on Z-score threshold (e.g., 3)threshold = 3outliers = np.where(np.abs(z_scores) > threshold)[0] print("Outliers identified using Z-score method:")print(data[outliers])Une autre méthode consiste à calculer l'intervalle interquartile (IQR) de la distribution et à classer toutes les valeurs qui sont Q1-(1,5 x IQR) ou Q3 + (1,5 x IQR) comme des valeurs aberrantes potentielles.
import numpy as npimport pandas as pd # Generate some sample datanp.random.seed(0)data = np.random.randint(low=0, high=11, size=1000)# Add some outliersdata[0] = 100data[1] = -100 # Calculate quartiles and IQRq1 = np.percentile(data, 25)q3 = np.percentile(data, 75)iqr = q3 - q1 # Identify outliers based on IQRlower_bound = q1 - (1.5 * iqr)upper_bound = q3 + (1.5 * iqr)outliers = np.where((data < lower_bound) | (data > upper_bound))[0] print("Outliers identified using IQR method:")print(data[outliers])Une fois que vous avez identifié les valeurs aberrantes et déterminé qu'elles posent problème, il existe plusieurs méthodes pour les traiter. Si vous avez déterminé que la valeur aberrante est due à une erreur, il peut être possible de corriger simplement l'erreur pour résoudre la valeur aberrante.
Dans d'autres cas, il peut être possible de supprimer la valeur aberrante de l'ensemble de données ou de la remplacer par une valeur moins extrême qui conserve la forme générale de la distribution.
Le plafonnement est une méthode qui consiste à fixer un plafond, ou un seuil, à la distribution de vos données et à remplacer toutes les valeurs en dehors de ces limites par une valeur spécifiée.
import pandas as pdimport numpy as np # Create a sample DataFrame with outliersdata = { 'A': [100, 90, 85, 88, 110, 115, 120, 130, 140], 'B': [1, 2, 3, 4, 5, 6, 7, 8, 9]}df = pd.DataFrame(data) # Define the lower and upper thresholds for capping (Here I used the 5th and 95th percentiles)lower_threshold = df.quantile(0.05)upper_threshold = df.quantile(0.95) # Cap outlierscapped_df = df.clip(lower=lower_threshold, upper=upper_threshold, axis=1) print("Original DataFrame:")print(df)print("\nCapped DataFrame:")print(capped_df)Dans certains cas, vous pouvez transformer vos données de manière à ce que les valeurs aberrantes aient moins d'impact, par exemple en les transformant en racine carrée ou en les transformant en logarithme.
Soyez prudent lorsque vous transformez vos données, car vous risquez d'introduire plus de problèmes à long terme si vous ne faites pas attention. Il y a quelques éléments à prendre en compte avant de décider de transformer vos données.
Pour en savoir plus sur les transformations de données, je vous recommande de suivre un cours de statistiques tel que Introduction aux statistiques en Python ou Fondamentaux des statistiques avec Python de DataCamp.
Nous avons déjà vu comment les doublons peuvent nuire à nos analyses. Heureusement, Python simplifie l'identification et la gestion des doublons.
Grâce à la méthode duplicated() de la bibliothèque Python pandas, vous pouvez facilement identifier les lignes dupliquées dans un DataFrame pour les examiner.
import pandas as pd# Assuming 'df' is your DataFrameduplicate_rows = df[df.duplicated()]Cette opération renvoie un DataFrame contenant les lignes qui sont en double. Une fois que vous avez ce DataFrame des lignes dupliquées, je vous encourage à regarder les doublons s'il n'y en a pas trop.
La plupart des doublons peuvent être des copies exactes et peuvent simplement être supprimés à l'aide de la méthode drop_duplicates() de Pandas :
# Removing duplicatescleaned_df = df.drop_duplicates()Dans certains cas, il peut être plus approprié de fusionner les enregistrements en double, en agrégeant les informations. Par exemple, si les doublons représentent plusieurs entrées pour la même entité, nous pouvons les fusionner à l'aide de fonctions d'agrégation :
# Merging duplicates by aggregating valuesmerged_df = df.groupby(list_of_columns).agg({'column_to_merge': 'sum'})Cette fonction permet de combiner les lignes dupliquées en une seule, en agrégeant les valeurs sur la base de fonctions spécifiées telles que la somme, la moyenne, etc.
import pandas as pd#Sample DataFramedata = { 'customer_id' : [102, 102, 101, 103, 102] 'product_id' : ['A', 'B', 'A', 'C', 'B'] 'quantity_sold : [5, 3, 2, 1, 4]}df = pd.DataFrame(data)df}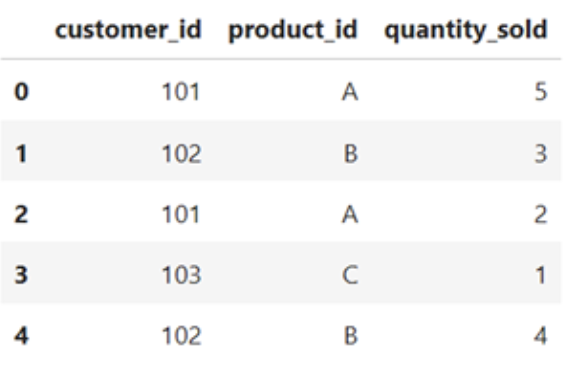
# Merging duplicates by aggregating valuesmerged_df = df.groupby(['cutomer_id', 'product_id']).agg({'quantity_sold': 'sum'}).reset_index()merged_df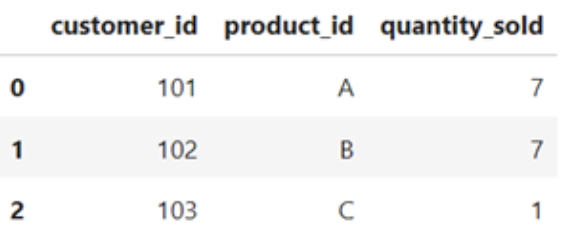
Différents types d'incohérences nécessiteront différentes solutions. Les incohérences résultant de la saisie de données incorrectes ou de fautes de frappe peuvent devoir être corrigées par une source compétente. Les données incorrectes peuvent également être remplacées par imputation, comme s'il s'agissait d'une valeur manquante, ou supprimées entièrement de l'ensemble de données, selon les circonstances.
Les incohérences dans le formatage des données peuvent être corrigées à l'aide de certaines méthodes de normalisation. Pour supprimer les espaces de début et de fin d'une chaîne de caractères, vous pouvez utiliser la méthode .strip(). Les méthodes .upper() et .lower() normalisent la casse des chaînes de caractères. La conversion des dates en dates-horaires à l'aide de pd.to_datetime permettra de normaliser le formatage des dates.
Vous pouvez également vous assurer que chaque valeur de la colonne d'un DataFrame est du même type de données en utilisant la méthode .astype().
D'autres corrections d'incohérences de formatage peuvent s'avérer nécessaires :
value_mapping = {'M': 'Male', 'F': 'Female'}standardized_value = value_mapping.get('M', 'Unknown')La transformation des données et l'ingénierie des caractéristiques sont des techniques de prétraitement permettant de transformer des données brutes en un format plus adapté aux algorithmes d'apprentissage automatique et à l'analyse statistique. Dans cette section, nous allons brièvement explorer certaines techniques courantes de transformation des données et d'ingénierie des fonctionnalités en Python.
La normalisation et la standardisation sont deux techniques utilisées pour ramener les caractéristiques à une échelle similaire, ce qui est important pour de nombreux algorithmes d'apprentissage automatique.
La normalisation permet de ramener les données à un intervalle fixe, généralement compris entre 0 et 1. Cela permet de s'assurer que toutes les caractéristiques sont à la même échelle et d'éviter que certaines caractéristiques ne dominent d'autres caractéristiques en raison de leur plus grande ampleur.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(data)La normalisation, quant à elle, transforme les données pour qu'elles aient une moyenne de 0 et un écart-type de 1. Cette technique est utile lorsque les données ont des échelles différentes et des portées variables, et elle garantit que chaque caractéristique a un impact comparable sur le modèle.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)Les caractéristiques spécifiques de vos données et les exigences du modèle envisagé détermineront la manière dont vous ferez évoluer vos données. Pour en savoir plus sur la différence entre normalisation et standardisation, consultez notre didacticiel dédié, Normalization vs. Normalisation : Comment faire la différence.
Le codage des variables catégorielles est une étape de prétraitement essentielle dans l'apprentissage automatique lorsqu'il s'agit de caractéristiques qui ne sont pas numériques. Les variables catégorielles représentent des données qualitatives, telles que des types, des classes ou des étiquettes. Pour utiliser ces variables dans des algorithmes d'apprentissage automatique, elles doivent être converties en format numérique.
Une technique courante pour coder les variables catégorielles est le codage à une touche, qui transforme chaque catégorie en un vecteur binaire. Cette méthode est particulièrement utile lorsqu'il s'agit de variables catégorielles nominales, où il n'y a pas d'ordre ou de hiérarchie inhérente entre les catégories.
import pandas as pd
encoded_data = pd.get_dummies(data, columns=['categorical_column'])
import pandas as pd
# Create a sample DataFrame with a categorical column
data = {
'ID': [1, 2, 3, 4, 5],
'Color': ['Red', 'Blue', 'Green', 'Red', 'Blue']
}
df = pd.DataFrame(data)
# Perform one-hot encoding
encoded_data = pd.get_dummies(df, columns=['Color'])
print("Original DataFrame")
print(df)
print("\nEncoded DataFrame:")
print(encoded_data)

Une autre approche est le codage des étiquettes, qui attribue un nombre entier unique à chaque catégorie. Chaque catégorie est associée à une valeur numérique, convertissant ainsi les étiquettes catégorielles en nombres ordinaux. Cette méthode convient aux variables catégorielles ordinales, pour lesquelles il existe un ordre naturel ou un classement entre les catégories.
from sklearn.preprocessing import LabelEncoderencoder = LabelEncoder()encoded_data['categorical_column'] = encoder.fit_transform(data['categorical_column'])from sklearn.preprocessing import LabelEncoderimport pandas as pd#Create a sample DataFrame with categorical column data = { 'ID' : [1, 2, 3, 4, 5] 'Color' : [ 'Red', 'Blue', 'Green', 'Red', 'Green' ]}df = pd.DataFrame(data)#Perform label encodingencoder = LabelEncoder()df ['Color_LabelEncoded'] = encoder.fit_transform(df['Color'])print("Original DataFrame:")print(df[['ID', 'Color']])print("\nDataFrame with Label Encoded Column:")print(df[['ID', 'Color_LabelEncoded']])
Il est important de choisir la méthode d'encodage appropriée en fonction de la nature de la variable catégorielle et des exigences de l'algorithme d'apprentissage automatique. Le codage à une chaleur est généralement préféré pour les variables nominales, tandis que le codage par étiquette convient aux variables ordinales.
L'ingénierie des fonctionnalités est une étape du développement de modèles d'apprentissage automatique impliquant la création de nouvelles fonctionnalités ou la modification de fonctionnalités existantes. Ce processus est courant lorsque les données brutes manquent de caractéristiques qui contribuent directement à la tâche d'apprentissage ou lorsque les caractéristiques existantes ne sont pas sous une forme que l'algorithme d'apprentissage peut utiliser efficacement.
Imaginez un scénario dans lequel vous travaillez avec un ensemble de données sur les prix des logements et vous souhaitez prédire le prix de vente des maisons en fonction de diverses caractéristiques telles que le nombre de pièces, la surface habitable et l'état de la propriété. Cependant, l'ensemble des données ne comprend pas de caractéristique permettant de saisir directement l'état général de la maison.
Dans ce cas, vous pouvez créer une nouvelle caractéristique en combinant des caractéristiques existantes ou en extrayant des informations pertinentes.
Par exemple, vous pouvez créer une caractéristique appelée "État général" en regroupant les évaluations de l'état des différents éléments de la maison, tels que l'état de la cuisine, la qualité du sous-sol, l'âge de la propriété, les rénovations récentes, etc.
Dans les cas où la relation entre les caractéristiques et la variable cible n'est pas linéaire, des caractéristiques polynomiales peuvent être générées en élevant les caractéristiques existantes à différentes puissances. Cette approche permet de saisir des relations complexes entre des variables qui peuvent ne pas être linéairement séparables.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
polynomial_features = poly.fit_transform(data)
Dans d'autres cas, vous pouvez avoir affaire à des ensembles de données de haute dimension ou à une multicolinéarité entre les caractéristiques. Des techniques telles que l'analyse en composantes principales (ACP) peuvent être employées pour réduire la dimensionnalité de l'ensemble de données tout en conservant la plupart des informations pertinentes.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
transformed_features = pca.fit_transform(data)L'ingénierie des caractéristiques permet de s'assurer que vous disposez des données correctes dans le bon format pour que votre modèle puisse les utiliser. Il existe de nombreuses techniques d'ingénierie des caractéristiques, et celle que vous utiliserez dépendra fortement de ce que vous essayez d'accomplir.
Consultez ce cours sur l'ingénierie des fonctionnalités pour découvrir d'autres techniques qui pourraient vous être utiles.
Le nettoyage des données est une étape essentielle de tout projet d'analyse de données ou d'apprentissage automatique. Voici quelques bonnes pratiques à garder à l'esprit lorsque vous rationalisez votre processus de nettoyage des données :
Conservez toujours l'original !
Il s'agit du conseil le plus important pour le nettoyage des données. Conservez une copie des fichiers de données brutes séparément des versions nettoyées et traitées. Vous disposez ainsi toujours d'un point de référence et pouvez facilement revenir aux données d'origine si nécessaire.
Personnellement, je fais toujours une copie du fichier de données brutes avant toute modification et j'ajoute le suffixe "-RAW" au nom du fichier afin de savoir lequel est l'original.
Ajoutez des commentaires à votre code pour expliquer l'objectif de chaque étape de nettoyage et les hypothèses formulées.
Vous devez vous assurer que vos efforts de nettoyage des données ne modifient pas de manière significative la distribution ou n'introduisent pas de biais involontaires. Une exploration répétée des données après vos efforts de nettoyage peut vous aider à vous assurer que vous êtes sur le bon cursus.
Si votre processus de nettoyage est long ou automatisé, vous pouvez conserver un document séparé dans lequel vous enregistrez les détails de chaque étape de nettoyage.
Des détails tels que la date, l'action spécifique entreprise et les problèmes rencontrés peuvent s'avérer utiles par la suite.
N'oubliez pas de conserver ce document dans un endroit facilement accessible, par exemple dans le même dossier de projet que les données ou le code. Dans le cas d'un pipeline automatisé et régulièrement mis à jour, envisagez de faire de ce journal un élément automatique du processus de nettoyage des données. Cela vous permettra de vérifier que tout fonctionne correctement.
Identifiez les tâches courantes de nettoyage des données et encapsulez-les dans des fonctions réutilisables. Cela vous permet d'appliquer les mêmes étapes de nettoyage à plusieurs ensembles de données. Cette fonction est particulièrement utile si vous souhaitez cartographier des abréviations propres à votre entreprise.
Utilisez la liste de contrôle du nettoyage des données de DataCamp pour vous assurer de ne rien oublier !
Le nettoyage des données n'est pas une simple tâche banale ; c'est une étape cruciale qui constitue la base de tout projet réussi d'analyse de données et d'apprentissage automatique. En veillant à ce que vos données soient exactes, cohérentes et fiables, vous posez les bases nécessaires à la prise de décisions éclairées et à l'obtention d'informations significatives.
Des données sales peuvent conduire à des conclusions erronées et à des analyses faussées, ce qui peut avoir des conséquences importantes, qu'il s'agisse de partager des bonbons entre amis ou de prendre des décisions commerciales. Investir du temps et des efforts dans le nettoyage de vos données s'avère payant à long terme, car cela garantit que vos analyses sont fiables et que vos résultats sont exploitables.
Pour plus d'informations et des exercices interactifs, consultez le cours de DataCamp sur le nettoyage des données. Pour un défi pratique, essayez ce code-along de nettoyage de données.
Commencez dès aujourd'hui votre voyage de nettoyage de données !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min