
Curso
Diseño de sistemas agénticos con LangChain
3 h
12.1K
Para ejecutar un modelo con un billón de parámetros como Kimi K2.5, normalmente se necesita un clúster masivo con múltiples GPU y un presupuesto de infraestructura acorde, que a menudo supera los 40 dólares por hora. Sin embargo, con las herramientas de optimización adecuadas, puedes ejecutar este modelo de última generación sin arruinarte.
En este tutorial, te mostraré cómo ejecutar Kimi K2.5 localmente utilizando una sola GPU NVIDIA H200 en RunPod. Al aprovechar llama.cpp para una inferencia eficiente y conectarlo a la CLI de Kimi, puedes evitar la compleja infraestructura empresarial y empezar a crear software de alto nivel de inmediato.
Kimi K2.5 es un modelo lingüístico abierto de última generación diseñado para el razonamiento avanzado, la codificación y la generación de texto de alta calidad. Desarrollado por Moonshot AI, es un modelo a escala de un billón de parámetros diseñado para el razonamiento avanzado, la generación de código de alta calidad y tareas de redacción general complejas.
En la práctica, se siente a la par con Claude Opus 4.5 para muchos flujos de trabajo, especialmente programación, razonamiento estructurado y generación de textos largos.
Una de las mayores ventajas de Kimi K2.5 es que es totalmente de código abierto. Esto significa que cualquiera puede descargar los pesos y ejecutar el modelo por su cuenta sin depender de API de pago o plataformas cerradas. La contrapartida, por supuesto, es la escala.
En esta sección se explican los requisitos previos de hardware, memoria y GPU necesarios para ejecutar Kimi K2.5 de forma local, incluido el rendimiento esperado en una sola GPU H200.
Espacio en disco
Memoria (RAM + VRAM)
Requisitos de GPU
Controladores de GPU y CUDA
Ahora configuraremos un pod GPU en RunPod y lo prepararemos para ejecutar Kimi K2.5.
Empieza creando un nuevo pod en RunPod y seleccionando la GPU NVIDIA H200. Para la imagen del contenedor, elige laúltima plantilla PyTorch de , ya que incluye la mayoría de las dependencias de CUDA y aprendizaje profundo que necesitamos. Después de seleccionar la plantilla, haz clicen « » (Editar) para ajustar la configuración predeterminada del pod.
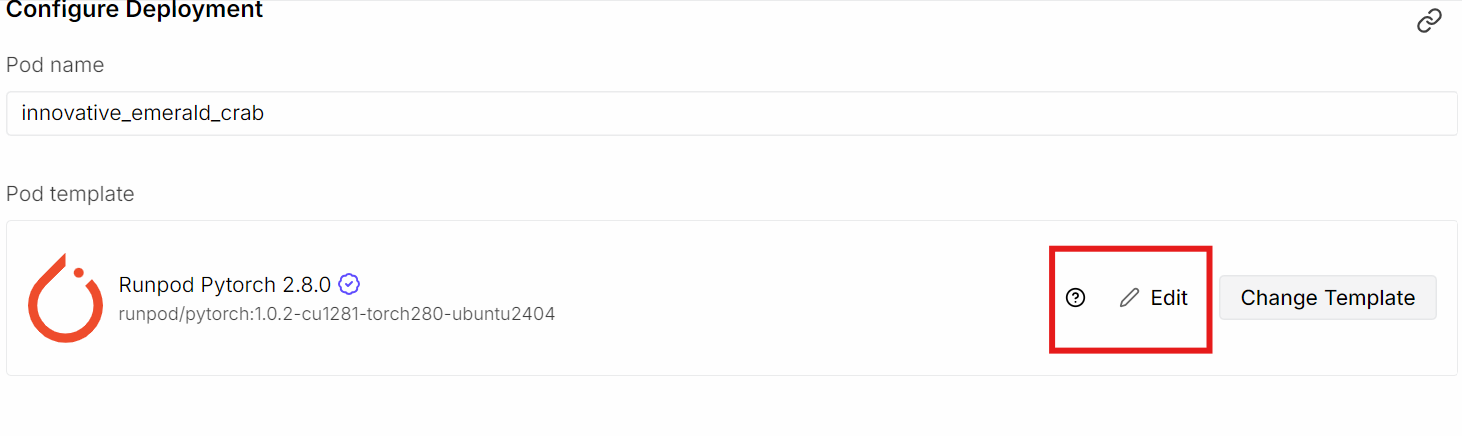
Actualiza la configuración de almacenamiento de la siguiente manera:
A continuación, expón un puerto adicional:
Exponemos el puerto 8080 para poder acceder al servidor llama.cpp y a la interfaz de usuario web directamente desde el navegador, ya sea de forma local o remota, una vez que el servidor esté en funcionamiento.
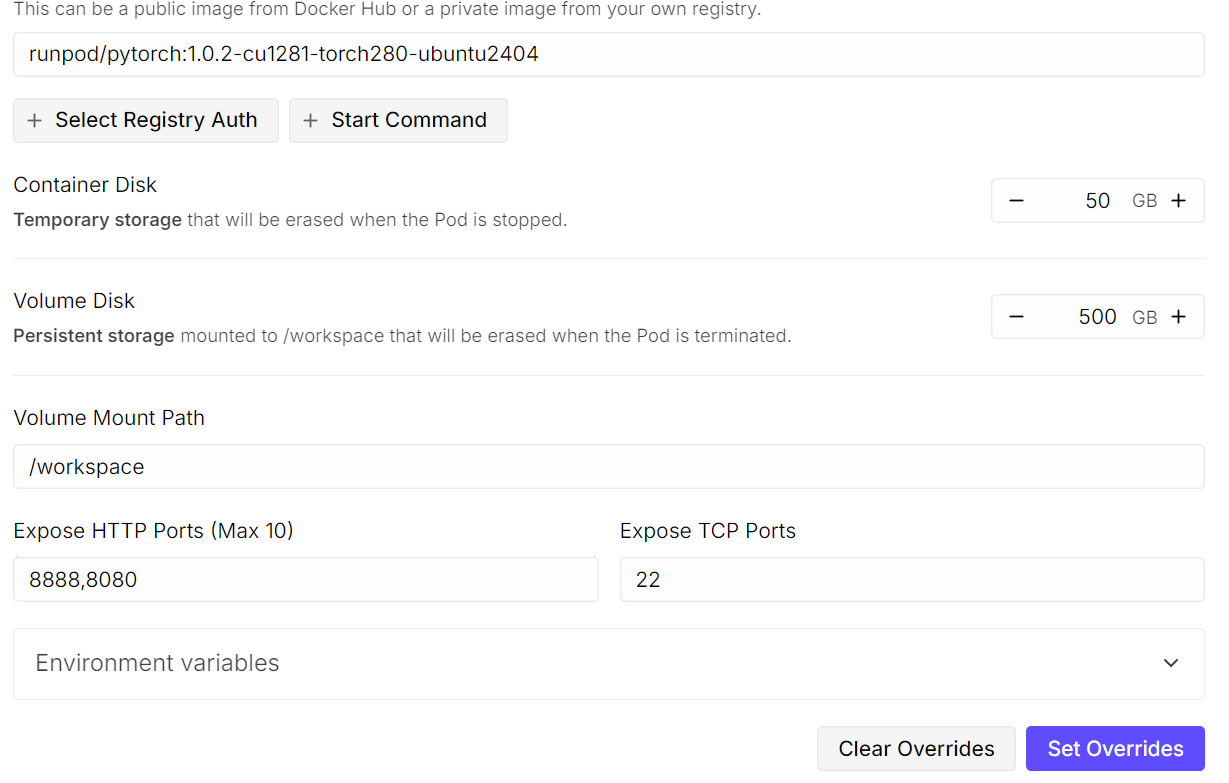
Después de guardar esta configuración, implementa el pod. Incluso con una sola GPU, ejecutar un modelo como Kimi K2.5 resulta caro, pero RunPod ofrece opciones mucho más rentables en comparación con los proveedores de nube tradicionales.
Una vez que el pod esté listo, inicia la interfaz Jupyter Lab. Desde Jupyter Lab, abre una sesión de Terminal.
Usar el terminal dentro de Jupyter es muy práctico, ya que permite abrir varias sesiones de terminal al instante sin tener que gestionar conexiones SSH independientes.
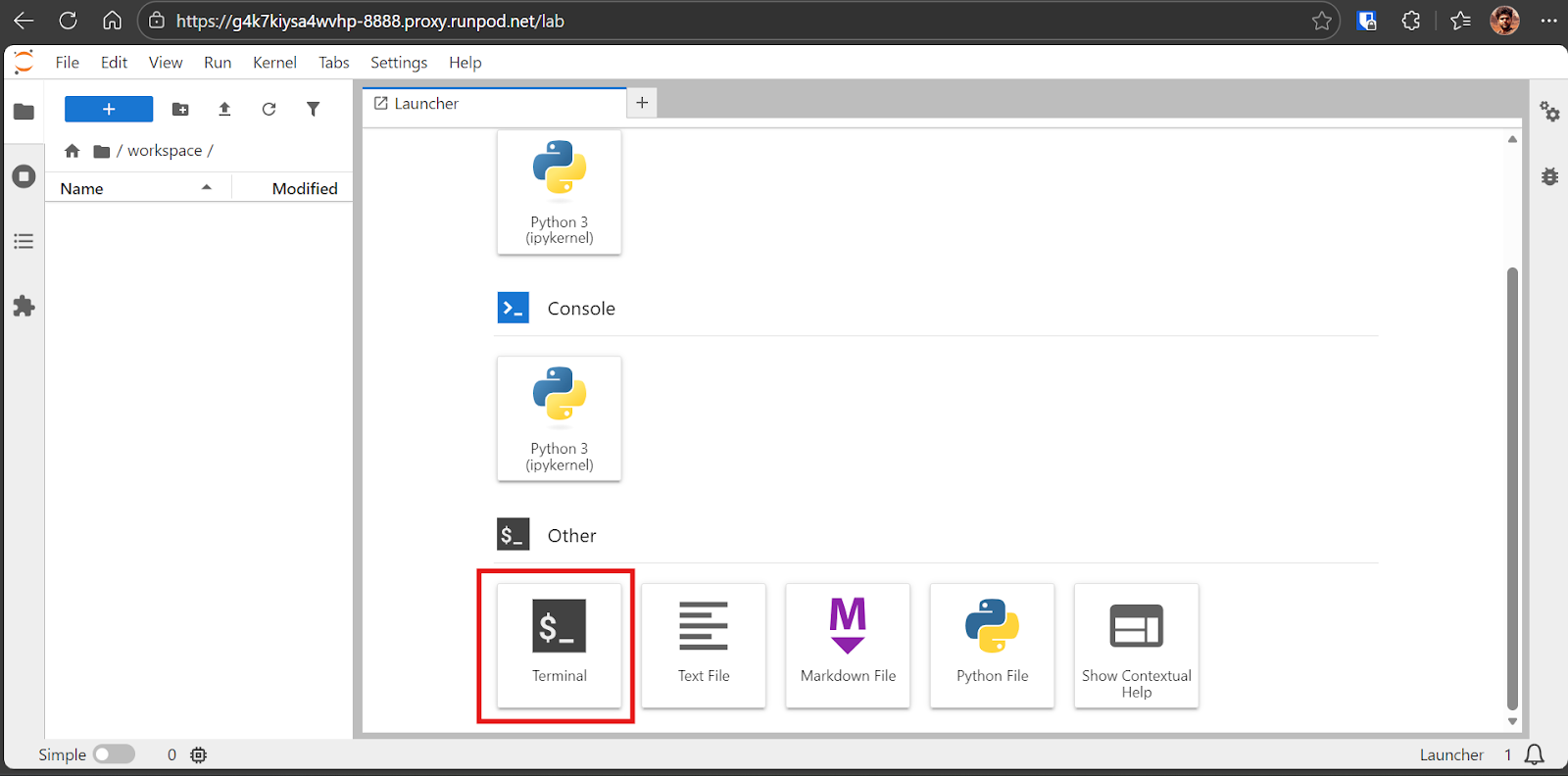
En primer lugar, comprueba que los controladores de la GPU y CUDA estén instalados correctamente ejecutando:
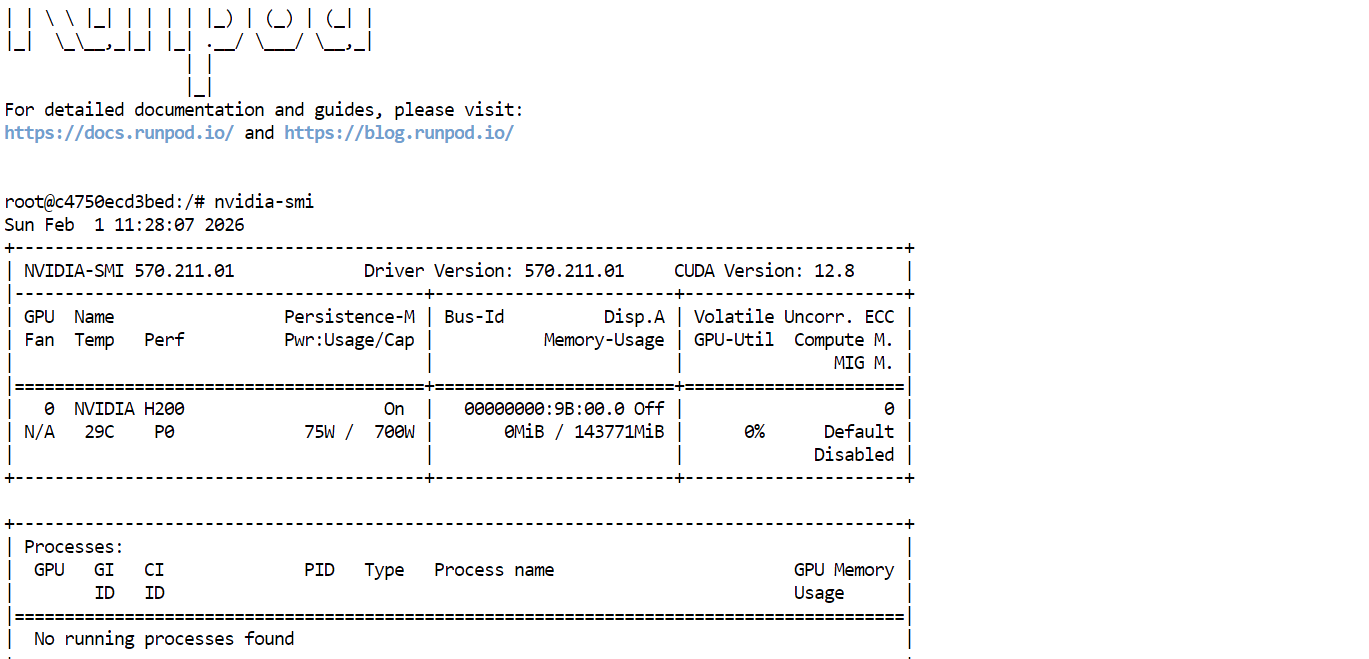
nvidia-smiSi todo está configurado correctamente, deberías ver la GPU H200 con aproximadamente 144 GB de VRAM disponible.
A continuación, instala los paquetes Linux necesarios para compilar llama.cpp desde el código fuente:
sudo apt-get update
sudo apt-get install -y build-essential cmake curl git libcurl4-openssl-devAhora compilaremos llama.cpp desde el código fuente, ya que es rápido, ligero y nos ofrece el mejor rendimiento en la GPU H200.
llama.cpp es un motor de inferencia de código abierto en C y C++ diseñado para ejecutar modelos lingüísticos de gran tamaño. Incluye un servidor HTTP integrado llamado llama-server, que proporciona puntos finales REST y una interfaz de usuario web para interactuar con el modelo desde tu navegador.
También admite kernels CUDA personalizados e inferencia híbrida de CPU y GPU, lo que resulta útil cuando los modelos no caben completamente en la VRAM.
Primero, clona el repositorio oficial llama.cpp:
git clone https://github.com/ggml-org/llama.cppA continuación, configura la compilación con la compatibilidad con CUDA habilitada. Nosotros nos centramos explícitamente en la arquitectura CUDA 90, necesaria para las GPU NVIDIA H200:
cmake /workspace/llama.cpp -B /workspace/llama.cpp/build \
-DGGML_CUDA=ON \
-DBUILD_SHARED_LIBS=OFF \
-DCMAKE_CUDA_ARCHITECTURES=90Ahora compila el binario llama-server. Este servidor se utilizará más adelante para ejecutar Kimi K2.5 y exponer un punto final HTTP y una interfaz de usuario web:
cmake --build /workspace/llama.cpp/build -j --clean-first --target llama-serverUna vez completada la compilación, copia el binario en una ubicación conveniente:
cp /workspace/llama.cpp/build/bin/llama-server /workspace/llama.cpp/llama-serverPor último, comprueba que el binario existe y se ha compilado correctamente:
ls -la /workspace/llama.cpp | sed -n '1,60p'Ahora descargaremos el modelo Kimi K2.5 GGUF de Hugging Face utilizando Xet, que permite descargas mucho más rápidas de archivos de modelos grandes.
En primer lugar, instala las herramientas de transferencia Hugging Face y Xet necesarias:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferHabilita el backend de transferencia de alta velocidad:
export HF_HUB_ENABLE_HF_TRANSFER=1A continuación, descarga el modelo cuantificado de 1,8 bits (UD-TQ1_0) de Hugging Face y guárdalo localmente.
Utilizamos este cuantificador porque ofrece el mejor equilibrio entre la calidad del modelo y la viabilidad del hardware, lo que permite que Kimi K2.5 se ejecute en una sola GPU H200 al descargar parte del modelo a la RAM del sistema, manteniendo al mismo tiempo una velocidad de inferencia utilizable.
hf download unsloth/Kimi-K2.5-GGUF \
--local-dir /workspace/models/Kimi-K2.5-GGUF \
--include "UD-TQ1_0/*"Incluso sin iniciar sesión con un token de acceso de Hugging Face, deberías ver velocidades de descarga de 800 MB por segundo o superior en RunPod.

En nuestro caso, la descarga completa se completó en unos 6 minutos. El tiempo real de descarga puede variar en función del ancho de banda de la red y el rendimiento del disco.

Ahora que el modelo está descargado y llama.cpp está compilado con soporte para CUDA, podemos ejecutar Kimi K2.5 localmente utilizando el servidor HTTP llama.cpp.
Ejecuta el siguiente comando para iniciar llama-server:
/workspace/llama.cpp/llama-server \
--model "/workspace/models/Kimi-K2.5-GGUF/UD-TQ1_0/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf" \
--alias "Kimi-K2.5" \
--host 0.0.0.0 \
--port 8080 \
--threads 32 \
--threads-batch 32 \
--ctx-size 20000\
--temp 0.8 \
--top-p 0.95 \
--min_p 0.01 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024\
--ubatch-size 256Qué hace cada argumento:
--model: Ruta al archivo de modelo GGUF que se va a cargar--alias: Nombre descriptivo utilizado para identificar el modelo en el servidor y la interfaz de usuario.--host: Interfaz de red a la que conectar el servidor (0.0.0.0 permite el acceso externo).--port: Puerto HTTP utilizado para exponer el servidor llama.cpp y la interfaz de usuario web.--threads: Número de subprocesos de CPU utilizados para la inferencia y el preprocesamiento.--threads-batch: Hilos de CPU utilizados para el procesamiento por lotes de mensajes--ctx-size: Máximo tamaño de la ventana de contexto en tokens--temp: Controla la aleatoriedad de los resultados generados.--top-p: Umbral de muestreo del núcleo para la selección de tokens--min_p: Filtra los tokens con muy baja probabilidad.--fit: Equilibra automáticamente los pesos del modelo entre la VRAM y la RAM del sistema.--prio: Establece una prioridad de proceso más alta para las cargas de trabajo de inferencia.--jinja: Habilita las plantillas de mensajes basadas en Jinja.--flash-attn: Activa la atención flash cuando es compatible con la GPU--batch-size: Número de tokens procesados por lote de GPU--ubatch-size: Tamaño de micro lotes para equilibrar el uso de memoria y el rendimientoDurante el inicio, verás que el modelo carga aproximadamente 136 GB en la memoria de la GPU, y el resto de los pesos se descargan en la RAM del sistema.
Nota: Si el servidor llama.cpp no detecta la GPU y se inicia en la CPU, reinicia el pod. Si el problema persiste, elimina la compilación existente y vuelve a compilar llama.cpp con la compatibilidad con CUDA habilitada.
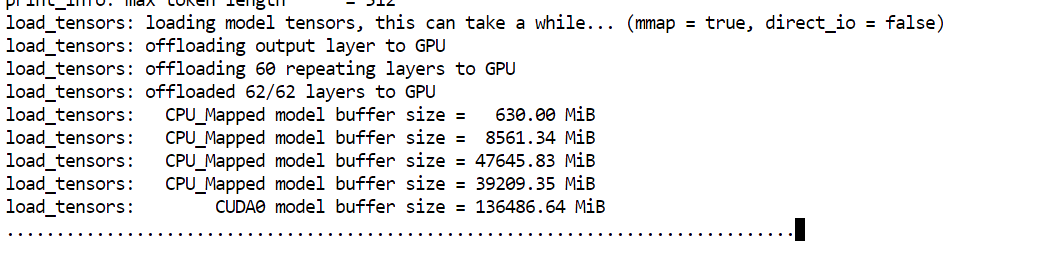
Una vez completada la carga, el servidor imprime una URL de acceso. Abre la interfaz de usuario web en tu navegador en:
Nota: Si ves un error al ejecutar nvidia-smi, es probable que el proceso se haya bloqueado debido a la presión de la memoria. Reinicia el pod. Todos los archivos de modelo permanecen en el disco persistente.
Una vez que el servidor llama.cpp esté en funcionamiento, podrás acceder a él a través de la interfaz de usuario web expuesta en el puerto 8080.
Para abrirlo, ve al panel de control de RunPod, selecciona tu pod en ejecución y haz clic en el enlace que aparece junto al puerto 8080. Esto abre la interfaz de usuario web llama.cpp directamente en tu navegador.
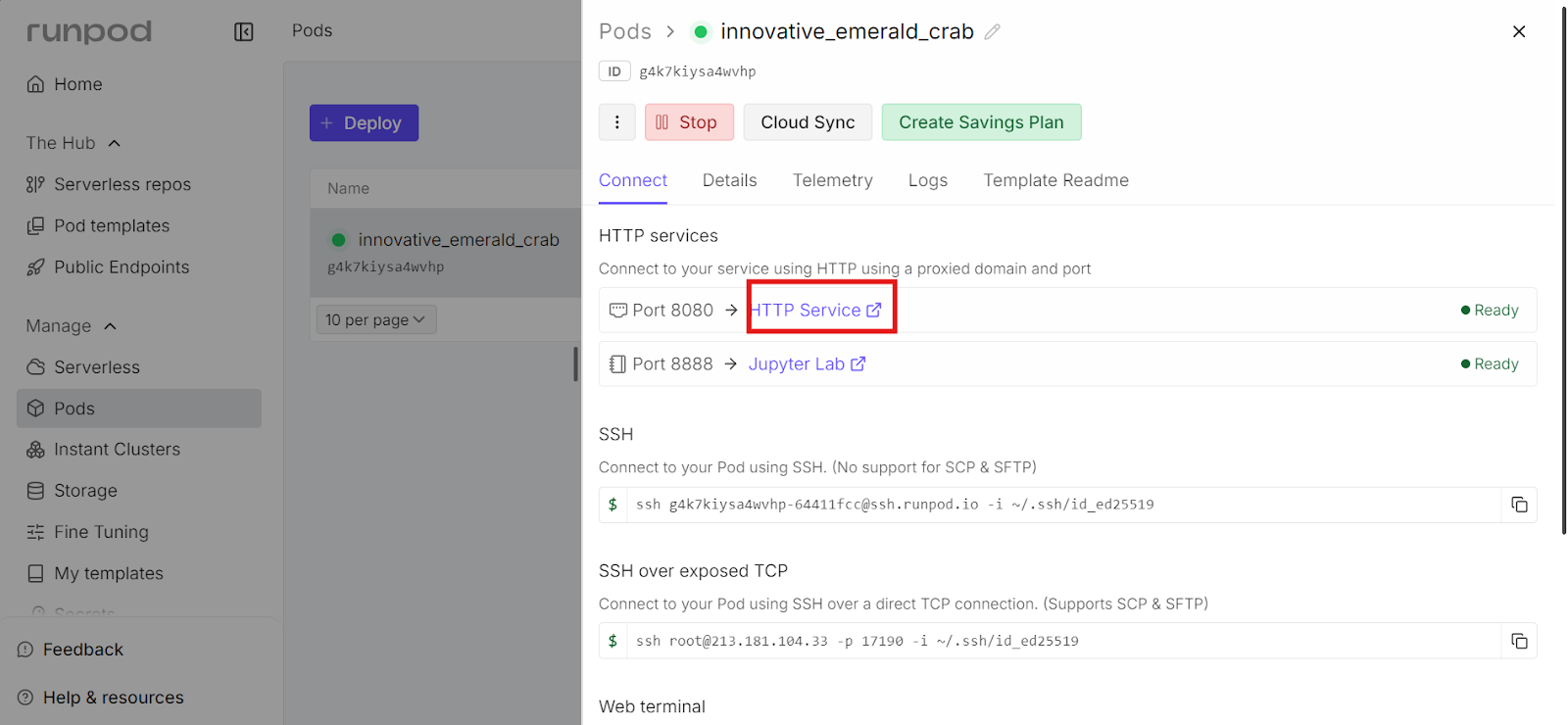
La interfaz de usuario web ofrece una interfaz sencilla similar a la de un chat, parecida a chatGPT, pero que se ejecuta íntegramente en tu propia instancia de RunPod. La URL es de acceso público. Puedes compartir este enlace con tus compañeros de equipo o colaboradores si es necesario.
Comienza enviando un mensaje sencillo al modelo Kimi K2.5 para verificar que todo funciona correctamente. En nuestro caso, el modelo responde a aproximadamente 6 a 7 tokens por segundo, lo que es de esperar para la cuantificación de 1,8 bits que se ejecuta en una sola GPU H200 con descarga parcial de RAM. Esta es una base sólida y confirma que el modelo está utilizando correctamente la GPU.
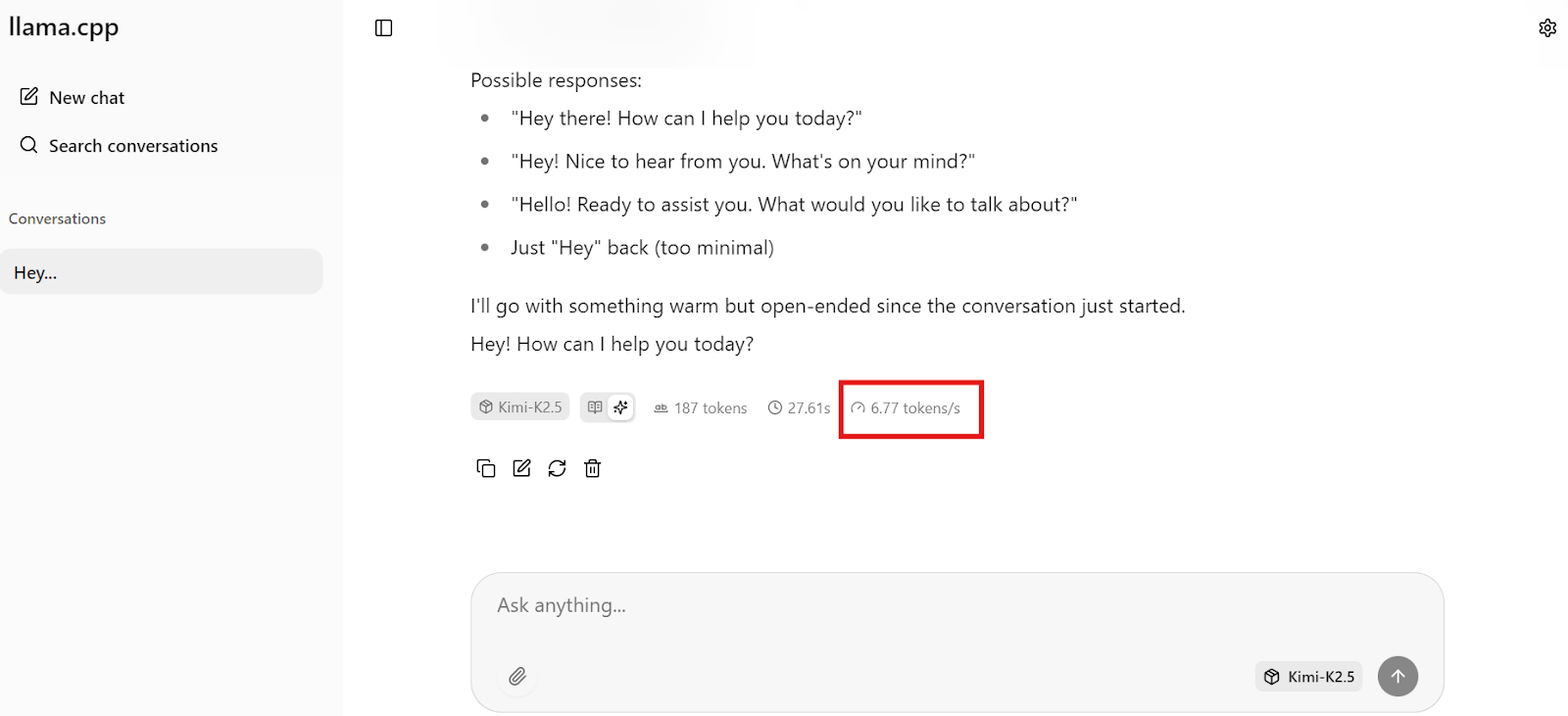
Nota: La interfaz de usuario web llama.cpp no separa claramente el razonamiento del resultado final, por lo que es posible que veas ambos mezclados debido a problemas con las plantillas.
Kimi CLI es un agente de codificación y razonamiento basado en terminal desarrollado por Moonshot AI. Está diseñado para ayudar con tareas de codificación, flujos de trabajo de terminal y cambios a nivel de proyecto directamente desde tu línea de comandos. A diferencia de una simple interfaz de chat, Kimi CLI puede funcionar dentro de tu directorio de trabajo, lo que lo hace muy adecuado para flujos de trabajo de desarrollo reales.
Para la inferencia local, la ventaja clave de Kimi CLI es que admite API compatibles con OpenAI. Esto nos permite apuntarlo directamente a nuestro llama-server que se ejecuta localmente, lo que permite que Kimi K2.5 se ejecute completamente en nuestro propio hardware sin depender de ningún servicio API alojado o de pago.
Comienza ejecutando el script de instalación oficial:
curl -LsSf https://code.kimi.com/install.sh | bashA continuación, añade el binario a tu PATH para que el kimi esté disponible en tu terminal:
export PATH="/root/.local/bin:$PATH"Confirma que la instalación se ha realizado correctamente:
kimi --versionDeberías ver un resultado similar a kimi, version 1.5.
Crea el directorio de configuración utilizado por Kimi CLI:
mkdir -p ~/.kimiAhora, crea el archivo de configuración. Esto le indica a Kimi CLI que trate tuservidor local llama.cpp como un proveedor compatible con OpenAI que se ejecuta en http://127.0.0.1:8080/v1. También registra una entrada de modelo local que coincide con el alias que especificaste al iniciar llama-server.
cat << 'EOF' > ~/.kimi/config.toml
[providers.local_llama]
type = "openai_legacy"
base_url = "http://127.0.0.1:8080/v1"
api_key = "sk-no-key-required"
[models.kimi_k25_local]
provider = "local_llama"
model = "Kimi-K2.5"
max_context_size = 20000
EOFAsegúrate de que el valor de « model » coincida exactamente con el valor de « --alias » utilizado al iniciar « llama-server ». El campo « api_key » (Punto de referencia de la red) es un marcador de posición y no es necesario para la inferencia local.
En esta sección, utilizaremos Kimi CLI conectado a nuestro servidor local Kimi K2.5 para crear de una sola vez un juego Snake totalmente jugable utilizando la codificación vibe.
Primero, crea un nuevo directorio para el proyecto y entra en él:
mkdir -p /workspace/snake-game
cd /workspace/snake-gameA continuación, inicia la CLI de Kimi:
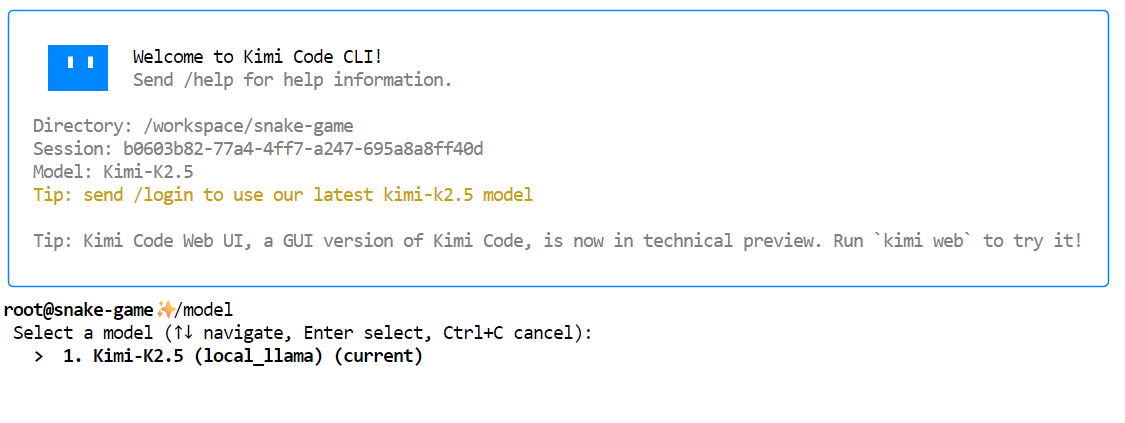
kimiUna vez que se inicie Kimi CLI, escribe /model y selecciona el modelo local Kimi K2.5 que hemos configurado anteriormente. Deberías verel modelo Kimi-K2.5 de como modelo disponible.
 Ahora, solicita a Kimi que genere el juego. Utiliza una instrucción sencilla y directa como la siguiente:
Ahora, solicita a Kimi que genere el juego. Utiliza una instrucción sencilla y directa como la siguiente:
"Create a simple Snake game as a single self-contained file named index.html."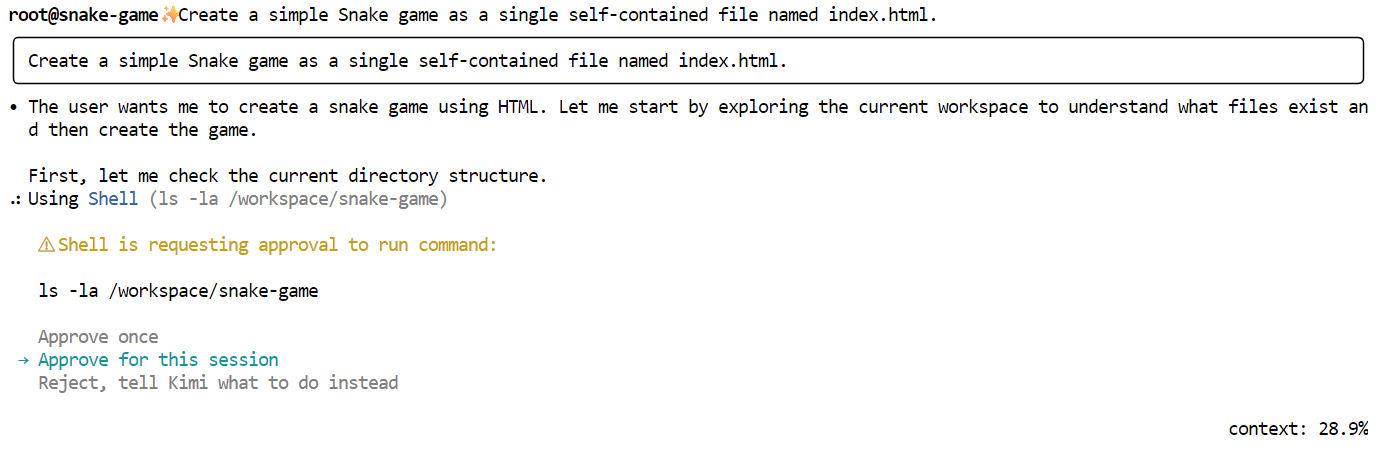
Kimi primero esbozará un plan y te pedirá tu aprobación. Léelo y aprueba la solicitud.

Tras la aprobación, Kimi generará el archivo completo index.html, incluyendo HTML, CSS y JavaScript, todo en un solo lugar.
Una vez generado el archivo, descárgalo o cópialo localmente y ábrelo en tu navegador. El juego se inicia inmediatamente.
El resultado es un juego Snake totalmente funcional con movimientos fluidos, gráficos nítidos y características de juego clásicas.
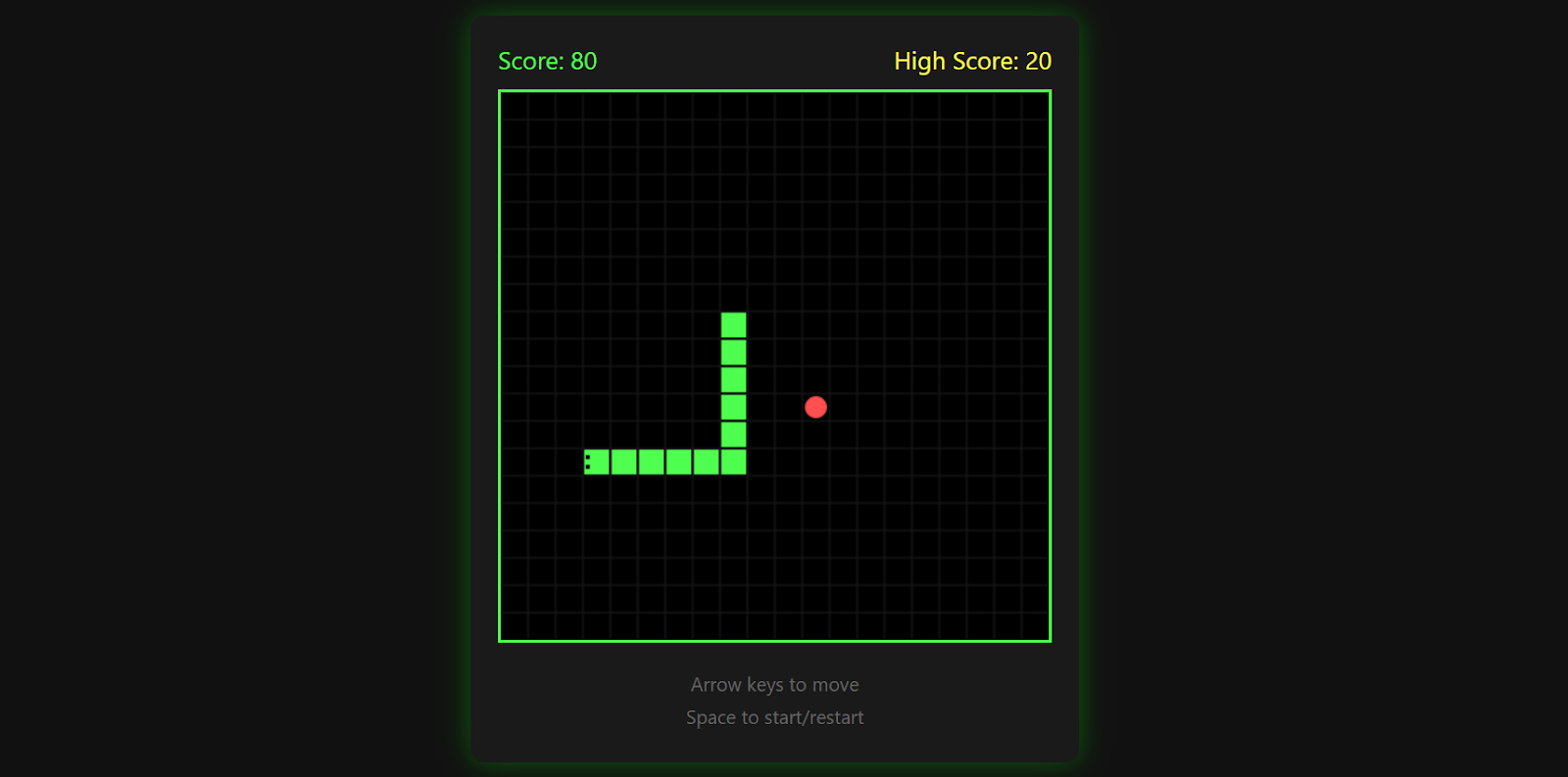
El juego registra tu puntuación más alta, termina cuando chocas contra una pared y te permite volver a empezar pulsando de nuevo la barra espaciadora.
Es sorprendentemente pulido para una sola indicación y una gran demostración de lo que Kimi K2.5 puede generar cuando se combina con Kimi CLI y una configuración de inferencia local.
Para ser completamente sincero, me resultó más frustrante de lo esperado crear un juego totalmente funcional en una sola sesión.
Aunque Kimi K2.5 es claramente capaz, el modelo a menudo tiene dificultades para decidir cuándo dejar de iterar en una tarea. En la práctica, tiende a sobrecargar el problema.
Por ejemplo, cuando se te pide que crees un juego Snake en Pygame, puede que vuelvas a una implementación HTML, y cuando se te pide HTML, puede que vuelvas a un enfoque basado en Python.
Este ir y venir significa que a menudo tienes que intervenir varias veces para mantener el modelo alineado con tu intención.
Gran parte de este comportamiento proviene de la cuantificación de 1,8 bits. Aunque los modos de 1 bit y sub-2 bits permiten ejecutar modelos extremadamente grandes en hardware limitado, tienen sus inconvenientes.
El modelo aún puede generar respuestas coherentes, pero tiene más dificultades con la finalización de tareas, el razonamiento a largo plazo, la planificación estructurada y la llamada de funciones. Estas son precisamente las áreas más importantes para los flujos de trabajo de tipo agente y las tareas de codificación de varios pasos.
Siendo realistas, Kimi K2.5 comienza a destacar en formatos demayor precisión, como 4 bits o superior. A ese nivel, la planificación mejora notablemente y el modelo se comporta de forma más predecible.
La desventaja es obvia. Una mayor precisión requiere una cantidad significativamente mayor de RAM y VRAM, lo que lo pone fuera del alcance de muchas configuraciones locales. Desde una perspectiva puramente basada en la relación entre tamaño y rendimiento con baja precisión, modelos como GLM 4.7 ofrecen actualmente una experiencia más fluida para muchos usuarios.
Dicho esto, si ignoras las limitaciones del hardware y ejecutas Kimi K2.5 con mayor precisión o a través de una API alojada, el modelo es realmente impresionante. Su profundidad de razonamiento, la calidad de la generación de código y el manejo de contextos largos son tan sólidos que pueden reemplazar a los modelos propietarios en muchos flujos de trabajo.
De hecho, cuando se utiliza a través de la API de Kimi AI, es lo suficientemente bueno como para justificar el cambio de todo un flujo de trabajo de codificación de vibraciones a él.
Para seguir aprendiendo más sobre los conceptos que hemos tratado aquí, recomiendo estos recursos:
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali


